жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңд»Җд№ҲдәӢIOжөҒвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
дј з»ҹзҡ„ BIO
Java IOжөҒжҳҜдёҖдёӘеәһеӨ§зҡ„з”ҹжҖҒзҺҜеўғпјҢе…¶еҶ…йғЁжҸҗдҫӣдәҶеҫҲеӨҡдёҚеҗҢзҡ„иҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒпјҢз»ҶеҲҶдёӢеҺ»иҝҳжңүеӯ—иҠӮжөҒе’Ңеӯ—з¬ҰжөҒпјҢз”ҡиҮіиҝҳжңүзј“еҶІжөҒжҸҗй«ҳ IO жҖ§иғҪпјҢиҪ¬жҚўжөҒе°Ҷеӯ—иҠӮжөҒиҪ¬жҚўдёәеӯ—з¬ҰжөҒ······зңӢеҲ°иҝҷдәӣе°ұе·Із»ҸеҜ№ IO дә§з”ҹжҒҗжғ§дәҶпјҢеңЁж—ҘеёёејҖеҸ‘дёӯе°‘дёҚдәҶеҜ№ж–Ү件зҡ„ IO ж“ҚдҪңпјҢиҷҪ然 apache е·Із»ҸжҸҗдҫӣдәҶ Commons IO иҝҷз§Қе°ҒиЈ…еҘҪзҡ„组件пјҢдҪҶйқўеҜ№зү№ж®ҠеңәжҷҜж—¶пјҢжҲ‘们д»ҚйңҖиҰҒиҮӘе·ұеҺ»е°ҒиЈ…дёҖдёӘй«ҳжҖ§иғҪзҡ„ж–Ү件 IO е·Ҙе…·зұ»пјҢжң¬ж–Үе°Ҷдјҡи§Јжһҗ Java IO дёӯж¶үеҸҠеҲ°зҡ„еҗ„дёӘзұ»пјҢд»ҘеҸҠи®Іи§ЈеҰӮдҪ•жӯЈзЎ®гҖҒй«ҳж•Ҳең°дҪҝз”Ёе®ғ们гҖӮ
BIO NIO е’Ң AIO зҡ„еҢәеҲ«
жҲ‘们дјҡд»ҘдёҖдёӘз»Ҹе…ёзҡ„зғ§ејҖж°ҙзҡ„дҫӢеӯҗйҖҡдҝ—ең°и®Іи§Је®ғ们д№Ӣй—ҙзҡ„еҢәеҲ«
| зұ»еһӢ | зғ§ејҖж°ҙ |
|---|---|
| BIO | дёҖзӣҙзӣ‘жөӢзқҖжҹҗдёӘж°ҙеЈ¶пјҢиҜҘж°ҙеЈ¶зғ§ејҖж°ҙеҗҺеҶҚзӣ‘жөӢдёӢдёҖдёӘж°ҙеЈ¶ |
| NIO | жҜҸйҡ”дёҖж®өж—¶й—ҙе°ұзңӢзңӢжүҖжңүж°ҙеЈ¶зҡ„зҠ¶жҖҒпјҢе“ӘдёӘж°ҙеЈ¶зғ§ејҖж°ҙе°ұеҺ»еӨ„зҗҶе“ӘдёӘж°ҙеЈ¶ |
| AIO | дёҚз”Ёзӣ‘жөӢж°ҙеЈ¶пјҢжҜҸдёӘж°ҙеЈ¶зғ§ејҖж°ҙеҗҺйғҪдјҡдё»еҠЁйҖҡзҹҘзәҝзЁӢиҜҙпјҡвҖңжҲ‘зҡ„ж°ҙзғ§ејҖдәҶпјҢжқҘеӨ„зҗҶжҲ‘еҗ§вҖқ |
BIO (еҗҢжӯҘйҳ»еЎһ I/O)
иҝҷйҮҢеҒҮи®ҫдёҖдёӘзғ§ејҖж°ҙзҡ„еңәжҷҜпјҢжңүдёҖжҺ’ж°ҙеЈ¶еңЁзғ§ејҖж°ҙпјҢBIOзҡ„е·ҘдҪңжЁЎејҸе°ұжҳҜпјҢ е°ҸиҸ иҗқдёҖзӣҙзңӢзқҖзқҖиҝҷдёӘж°ҙеЈ¶пјҢзӣҙеҲ°иҝҷдёӘж°ҙеЈ¶зғ§ејҖпјҢжүҚеҺ»еӨ„зҗҶдёӢдёҖдёӘж°ҙеЈ¶гҖӮзәҝзЁӢеңЁзӯүеҫ…ж°ҙеЈ¶зғ§ејҖзҡ„ж—¶й—ҙж®өд»Җд№ҲйғҪжІЎжңүеҒҡгҖӮ
NIO(еҗҢжӯҘйқһйҳ»еЎһ I/O)
иҝҳжӢҝзғ§ејҖж°ҙжқҘиҜҙпјҢNIOзҡ„еҒҡжі•жҳҜе°ҸиҸ иҗқдёҖиҫ№зҺ©зқҖжүӢжңәпјҢжҜҸйҡ”дёҖж®өж—¶й—ҙе°ұзңӢдёҖзңӢжҜҸдёӘж°ҙеЈ¶зҡ„зҠ¶жҖҒпјҢзңӢзңӢжҳҜеҗҰжңүж°ҙеЈ¶зҡ„зҠ¶жҖҒеҸ‘з”ҹдәҶж”№еҸҳпјҢеҰӮжһңжҹҗдёӘж°ҙеЈ¶зғ§ејҖдәҶпјҢеҸҜд»Ҙе…ҲеӨ„зҗҶйӮЈдёӘж°ҙеЈ¶пјҢ然еҗҺ继з»ӯзҺ©жүӢжңәпјҢ继з»ӯйҡ”дёҖж®өж—¶й—ҙеҸҲзңӢзңӢжҜҸдёӘж°ҙеЈ¶зҡ„зҠ¶жҖҒгҖӮ
AIO (ејӮжӯҘйқһйҳ»еЎһ I/O)
е°ҸиҸ иҗқи§үеҫ—жҜҸйҡ”дёҖж®өж—¶й—ҙе°ұеҺ»зңӢдёҖзңӢж°ҙеЈ¶еӨӘиҙ№еҠІдәҶпјҢдәҺжҳҜиҙӯд№°дәҶдёҖжү№зғ§ејҖж°ҙж—¶еҸҜд»Ҙе“”е“”е“Қзҡ„ж°ҙеЈ¶пјҢдәҺжҳҜејҖе§Ӣзғ§ж°ҙеҗҺпјҢе°ҸиҸ иҗқе°ұзӣҙжҺҘеҺ»е®ўеҺ…зҺ©жүӢжңәдәҶпјҢж°ҙзғ§ејҖж—¶пјҢе°ұеҸ‘еҮәвҖңе“”е“”вҖқзҡ„е“ҚеЈ°пјҢйҖҡзҹҘе°ҸиҸ иҗқжқҘе…іжҺүж°ҙеЈ¶гҖӮ
д»Җд№ҲжҳҜжөҒ
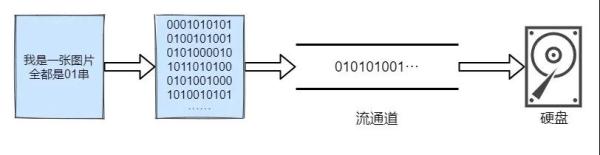
зҹҘиҜҶ科жҷ®пјҡжҲ‘们зҹҘйҒ“д»»дҪ•дёҖдёӘж–Ү件йғҪжҳҜд»ҘдәҢиҝӣеҲ¶еҪўејҸеӯҳеңЁдәҺи®ҫеӨҮдёӯпјҢи®Ўз®—жңәе°ұеҸӘжңү 0 е’Ң1пјҢдҪ иғҪзңӢи§Ғзҡ„дёңиҘҝе…ЁйғЁйғҪжҳҜз”ұиҝҷдёӨдёӘж•°еӯ—з»„жҲҗпјҢдҪ зңӢиҝҷзҜҮж–Үз« ж—¶пјҢиҝҷзҜҮж–Үз« д№ҹжҳҜз”ұ01з»„жҲҗпјҢеҸӘдёҚиҝҮиҝҷдәӣдәҢиҝӣеҲ¶дёІз»ҸиҝҮеҗ„з§ҚиҪ¬жҚўжј”еҸҳжҲҗдёҖдёӘдёӘж–Үеӯ—гҖҒдёҖеј еј еӣҫзүҮи·ғ然еұҸ幕дёҠгҖӮ
иҖҢжөҒе°ұжҳҜе°ҶиҝҷдәӣдәҢиҝӣеҲ¶дёІеңЁеҗ„з§Қи®ҫеӨҮд№Ӣй—ҙиҝӣиЎҢдј иҫ“пјҢеҰӮжһңдҪ и§үеҫ—жңүдәӣжҠҪиұЎпјҢжҲ‘дёҫдёӘдҫӢеӯҗе°ұдјҡеҘҪзҗҶи§ЈдёҖдәӣпјҡ
вҖңдёӢеӣҫжҳҜдёҖеј еӣҫзүҮпјҢе®ғз”ұ01дёІз»„жҲҗпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮзЁӢеәҸжҠҠдёҖеј еӣҫзүҮжӢ·иҙқеҲ°дёҖдёӘж–Ү件еӨ№дёӯпјҢ
жҠҠеӣҫзүҮиҪ¬еҢ–жҲҗдәҢиҝӣеҲ¶ж•°жҚ®йӣҶпјҢжҠҠж•°жҚ®дёҖзӮ№дёҖзӮ№ең°дј йҖ’еҲ°ж–Ү件еӨ№дёӯ , зұ»дјјдәҺж°ҙзҡ„жөҒеҠЁ , иҝҷж ·ж•ҙдҪ“зҡ„ж•°жҚ®е°ұжҳҜдёҖдёӘж•°жҚ®жөҒвҖқ
IO жөҒиҜ»еҶҷж•°жҚ®зҡ„зү№зӮ№пјҡ
йЎәеәҸиҜ»еҶҷгҖӮиҜ»еҶҷж•°жҚ®ж—¶пјҢеӨ§йғЁеҲҶжғ…еҶөдёӢйғҪжҳҜжҢүз…§йЎәеәҸиҜ»еҶҷпјҢиҜ»еҸ–ж—¶д»Һж–Ү件ејҖеӨҙзҡ„第дёҖдёӘеӯ—иҠӮеҲ°жңҖеҗҺдёҖдёӘеӯ—иҠӮпјҢеҶҷеҮәж—¶д№ҹжҳҜд№ҹеҰӮжӯӨ(RandomAccessFile еҸҜд»Ҙе®һзҺ°йҡҸжңәиҜ»еҶҷ)
еӯ—иҠӮж•°з»„гҖӮиҜ»еҶҷж•°жҚ®ж—¶жң¬иҙЁдёҠйғҪжҳҜеҜ№еӯ—иҠӮж•°з»„еҒҡиҜ»еҸ–е’ҢеҶҷеҮәж“ҚдҪңпјҢеҚідҪҝжҳҜеӯ—з¬ҰжөҒпјҢд№ҹжҳҜеңЁеӯ—иҠӮжөҒеҹәзЎҖдёҠиҪ¬еҢ–дёәдёҖдёӘдёӘеӯ—з¬ҰпјҢжүҖд»Ҙеӯ—иҠӮж•°з»„жҳҜ IO жөҒиҜ»еҶҷж•°жҚ®зҡ„жң¬иҙЁгҖӮ
жөҒзҡ„еҲҶзұ»
ж №жҚ®ж•°жҚ®жөҒеҗ‘дёҚеҗҢеҲҶзұ»пјҡиҫ“е…ҘжөҒ е’Ң иҫ“еҮәжөҒ
иҫ“е…ҘжөҒпјҡд»ҺзЈҒзӣҳжҲ–иҖ…е…¶е®ғи®ҫеӨҮдёӯе°Ҷж•°жҚ®иҫ“е…ҘеҲ°иҝӣзЁӢдёӯ
иҫ“еҮәжөҒпјҡе°ҶиҝӣзЁӢдёӯзҡ„ж•°жҚ®иҫ“еҮәеҲ°зЈҒзӣҳжҲ–е…¶е®ғи®ҫеӨҮдёҠдҝқеӯҳ

еӣҫзӨәдёӯзҡ„зЎ¬зӣҳеҸӘжҳҜе…¶дёӯдёҖз§Қи®ҫеӨҮпјҢиҝҳжңүйқһеёёеӨҡзҡ„и®ҫеӨҮйғҪеҸҜд»Ҙеә”з”ЁеңЁIOжөҒдёӯпјҢдҫӢеҰӮпјҡжү“еҚ°жңәгҖҒзЎ¬зӣҳгҖҒжҳҫзӨәеҷЁгҖҒжүӢжңә······
ж №жҚ®еӨ„зҗҶж•°жҚ®зҡ„еҹәжң¬еҚ•дҪҚдёҚеҗҢеҲҶзұ»пјҡеӯ—иҠӮжөҒ е’Ң еӯ—з¬ҰжөҒ
еӯ—иҠӮжөҒпјҡд»Ҙеӯ—иҠӮ(8 bit)дёәеҚ•дҪҚеҒҡж•°жҚ®зҡ„дј иҫ“
еӯ—з¬ҰжөҒпјҡд»Ҙеӯ—з¬ҰдёәеҚ•дҪҚ(1еӯ—з¬Ұ = 2еӯ—иҠӮ)еҒҡж•°жҚ®зҡ„дј иҫ“
вҖңеӯ—з¬ҰжөҒзҡ„жң¬иҙЁд№ҹжҳҜйҖҡиҝҮеӯ—иҠӮжөҒиҜ»еҸ–пјҢJava дёӯзҡ„еӯ—з¬ҰйҮҮз”Ё Unicode ж ҮеҮҶпјҢеңЁиҜ»еҸ–е’Ңиҫ“еҮәзҡ„иҝҮзЁӢдёӯпјҢйҖҡиҝҮд»Ҙеӯ—з¬ҰдёәеҚ•дҪҚпјҢжҹҘжүҫеҜ№еә”зҡ„з ҒиЎЁе°Ҷеӯ—иҠӮиҪ¬жҚўдёәеҜ№еә”зҡ„еӯ—з¬ҰгҖӮвҖқ
йқўеҜ№еӯ—иҠӮжөҒе’Ңеӯ—з¬ҰжөҒпјҢеҫҲеӨҡиҜ»иҖ…йғҪжңүз–‘жғ‘пјҡд»Җд№Ҳж—¶еҖҷйңҖиҰҒз”Ёеӯ—иҠӮжөҒпјҢд»Җд№Ҳж—¶еҖҷеҸҲиҰҒз”Ёеӯ—з¬ҰжөҒ?
жҲ‘иҝҷйҮҢеҒҡдёҖдёӘз®ҖеҚ•зҡ„жҰӮжӢ¬пјҢдҪ еҸҜд»ҘжҢүз…§иҝҷдёӘж ҮеҮҶеҺ»дҪҝз”Ёпјҡ
еӯ—з¬ҰжөҒеҸӘй’ҲеҜ№еӯ—з¬Ұж•°жҚ®иҝӣиЎҢдј иҫ“пјҢжүҖд»ҘеҰӮжһңжҳҜж–Үжң¬ж•°жҚ®пјҢдјҳе…ҲйҮҮз”Ёеӯ—з¬ҰжөҒдј иҫ“;йҷӨжӯӨд№ӢеӨ–пјҢе…¶е®ғзұ»еһӢзҡ„ж•°жҚ®(еӣҫзүҮгҖҒйҹійў‘зӯү)пјҢжңҖеҘҪиҝҳжҳҜд»Ҙеӯ—иҠӮжөҒдј иҫ“гҖӮ
ж №жҚ®иҝҷдёӨз§ҚдёҚеҗҢзҡ„еҲҶзұ»пјҢжҲ‘们е°ұеҸҜд»ҘеҒҡеҮәдёӢйқўиҝҷдёӘиЎЁж јпјҢйҮҢйқўеҢ…еҗ«дәҶ IO дёӯжңҖж ёеҝғзҡ„ 4 дёӘйЎ¶еұӮжҠҪиұЎзұ»пјҡ
| ж•°жҚ®жөҒеҗ‘ / ж•°жҚ®зұ»еһӢ | еӯ—иҠӮжөҒ | еӯ—з¬ҰжөҒ |
|---|---|---|
| иҫ“е…ҘжөҒ | InputStream | Reader |
| иҫ“еҮәжөҒ | OutputStream | Writer |
зҺ°еңЁзңӢ IO жҳҜдёҚжҳҜжңүдёҖдәӣжҖқи·ҜдәҶпјҢдёҚдјҡи§үеҫ—еҫҲж··д№ұдәҶпјҢжҲ‘们жқҘзңӢиҝҷеӣӣдёӘзұ»дёӢзҡ„жүҖжңүжҲҗе‘ҳгҖӮ
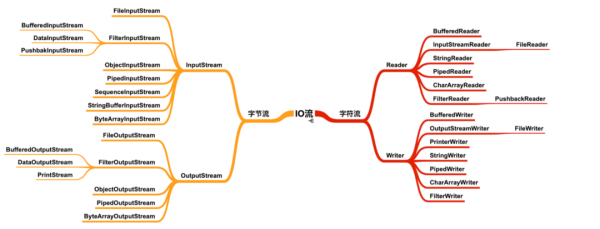
[жқҘиҮӘдәҺ cxuan зҡ„ гҖҠJavaеҹәзЎҖж ёеҝғжҖ»з»“гҖӢ]
зңӢеҲ°иҝҷд№ҲеӨҡзҡ„зұ»жҳҜдёҚжҳҜеҸҲејҖе§Ӣи§үеҫ—ж··д№ұдәҶпјҢдёҚиҰҒж…ҢпјҢеӯ—иҠӮжөҒе’Ңеӯ—з¬ҰжөҒдёӢзҡ„иҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒеӨ§йғЁеҲҶйғҪжҳҜдёҖдёҖеҜ№еә”зҡ„пјҢжңүдәҶдёҠйқўзҡ„иЎЁж јж”Ҝж’‘пјҢжҲ‘们дёҚйңҖиҰҒеҶҚжӢ…еҝғзңӢи§ҒжҹҗдёӘзұ»дјҡжҮөйҖјзҡ„жғ…еҶөдәҶгҖӮ
зңӢеҲ° Stream е°ұзҹҘйҒ“жҳҜеӯ—иҠӮжөҒпјҢзңӢеҲ° Reader / Writer е°ұзҹҘйҒ“жҳҜеӯ—з¬ҰжөҒгҖӮ
иҝҷйҮҢиҝҳиҰҒйўқеӨ–иЎҘе……дёҖзӮ№пјҡJava IO жҸҗдҫӣдәҶеӯ—иҠӮжөҒиҪ¬жҚўдёәеӯ—з¬ҰжөҒзҡ„иҪ¬жҚўзұ»пјҢз§°дёәиҪ¬жҚўжөҒгҖӮ
| иҪ¬жҚўжөҒ / ж•°жҚ®зұ»еһӢ | еӯ—иҠӮжөҒдёҺеӯ—з¬ҰжөҒд№Ӣй—ҙзҡ„иҪ¬жҚў |
|---|---|
| пјҲиҫ“е…Ҙпјүеӯ—иҠӮжөҒ => еӯ—з¬ҰжөҒ | InputStreamReader |
| пјҲиҫ“еҮәпјүеӯ—з¬ҰжөҒ => еӯ—иҠӮжөҒ | OutputStreamWriter |
жіЁж„Ҹеӯ—иҠӮжөҒдёҺеӯ—з¬ҰжөҒд№Ӣй—ҙзҡ„иҪ¬жҚўжҳҜжңүдёҘж је®ҡд№үзҡ„пјҡ
иҫ“е…ҘжөҒпјҡеҸҜд»Ҙе°Ҷеӯ—иҠӮжөҒ => еӯ—з¬ҰжөҒ
иҫ“еҮәжөҒпјҡеҸҜд»Ҙе°Ҷеӯ—з¬ҰжөҒ => еӯ—иҠӮжөҒ
дёәд»Җд№ҲеңЁиҫ“е…ҘжөҒдёҚиғҪеӯ—з¬ҰжөҒ => еӯ—иҠӮжөҒпјҢиҫ“еҮәжөҒдёҚиғҪеӯ—иҠӮжөҒ => еӯ—з¬ҰжөҒ?
вҖңеңЁеӯҳеӮЁи®ҫеӨҮдёҠпјҢжүҖжңүж•°жҚ®йғҪжҳҜд»Ҙеӯ—иҠӮдёәеҚ•дҪҚеӯҳеӮЁзҡ„пјҢжүҖд»Ҙиҫ“е…ҘеҲ°еҶ…еӯҳж—¶еҝ…е®ҡжҳҜд»Ҙеӯ—иҠӮдёәеҚ•дҪҚиҫ“е…ҘпјҢиҫ“еҮәеҲ°еӯҳеӮЁи®ҫеӨҮж—¶еҝ…йЎ»жҳҜд»Ҙеӯ—иҠӮдёәеҚ•дҪҚиҫ“еҮәпјҢеӯ—иҠӮжөҒжүҚжҳҜи®Ўз®—жңәжңҖж №жң¬зҡ„еӯҳеӮЁж–№ејҸпјҢиҖҢеӯ—з¬ҰжөҒжҳҜеңЁеӯ—иҠӮжөҒзҡ„еҹәзЎҖдёҠеҜ№ж•°жҚ®иҝӣиЎҢиҪ¬жҚўпјҢиҫ“еҮәеӯ—з¬ҰпјҢдҪҶжҜҸдёӘеӯ—з¬Ұдҫқж—§жҳҜд»Ҙеӯ—иҠӮдёәеҚ•дҪҚеӯҳеӮЁзҡ„гҖӮвҖқ
иҠӮзӮ№жөҒе’ҢеӨ„зҗҶжөҒ
еңЁиҝҷйҮҢйңҖиҰҒйўқеӨ–жҸ’е…ҘдёҖдёӘе°ҸиҠӮи®Іи§ЈиҠӮзӮ№жөҒе’ҢеӨ„зҗҶжөҒгҖӮ
иҠӮзӮ№жөҒпјҡиҠӮзӮ№жөҒжҳҜзңҹжӯЈдј иҫ“ж•°жҚ®зҡ„жөҒеҜ№иұЎпјҢз”ЁдәҺеҗ‘зү№е®ҡзҡ„дёҖдёӘең°ж–№(иҠӮзӮ№)иҜ»еҶҷж•°жҚ®пјҢз§°дёәиҠӮзӮ№жөҒгҖӮдҫӢеҰӮ FileInputStream
еӨ„зҗҶжөҒпјҡеӨ„зҗҶжөҒжҳҜеҜ№иҠӮзӮ№жөҒзҡ„е°ҒиЈ…пјҢдҪҝз”ЁеӨ–еұӮзҡ„еӨ„зҗҶжөҒиҜ»еҶҷж•°жҚ®пјҢжң¬иҙЁдёҠжҳҜеҲ©з”ЁиҠӮзӮ№жөҒзҡ„еҠҹиғҪпјҢеӨ–еұӮзҡ„еӨ„зҗҶжөҒеҸҜд»ҘжҸҗдҫӣйўқеӨ–зҡ„еҠҹиғҪгҖӮеӨ„зҗҶжөҒзҡ„еҹәзұ»йғҪжҳҜд»Ҙ Filter ејҖеӨҙгҖӮ
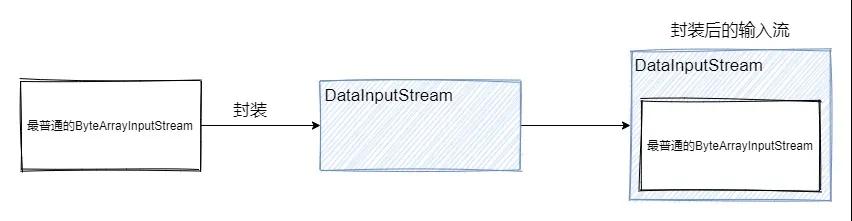
дёҠеӣҫе°Ҷ ByteArrayInputStream е°ҒиЈ…жҲҗ DataInputStreamпјҢеҸҜд»Ҙе°Ҷиҫ“е…Ҙзҡ„еӯ—иҠӮж•°з»„иҪ¬жҚўдёәеҜ№еә”ж•°жҚ®зұ»еһӢзҡ„ж•°жҚ®гҖӮдҫӢеҰӮеёҢжңӣиҜ»е…Ҙintзұ»еһӢж•°жҚ®пјҢе°ұдјҡд»Ҙ2дёӘеӯ—иҠӮдёәеҚ•дҪҚиҪ¬жҚўдёәдёҖдёӘж•°еӯ—гҖӮ
Java IO зҡ„ж ёеҝғзұ» File
Java жҸҗдҫӣдәҶ Fileзұ»пјҢе®ғжҢҮеҗ‘и®Ўз®—жңәж“ҚдҪңзі»з»ҹдёӯзҡ„ж–Ү件е’Ңзӣ®еҪ•пјҢйҖҡиҝҮиҜҘзұ»еҸӘиғҪи®ҝй—®ж–Ү件е’Ңзӣ®еҪ•пјҢж— жі•и®ҝй—®еҶ…е®№гҖӮе®ғеҶ…йғЁдё»иҰҒжҸҗдҫӣдәҶ 3 з§Қж“ҚдҪңпјҡ
и®ҝй—®ж–Ү件зҡ„еұһжҖ§пјҡз»қеҜ№и·Ҝеҫ„гҖҒзӣёеҜ№и·Ҝеҫ„гҖҒж–Ү件еҗҚ······
ж–Ү件жЈҖжөӢпјҡжҳҜеҗҰж–Ү件гҖҒжҳҜеҗҰзӣ®еҪ•гҖҒж–Ү件жҳҜеҗҰеӯҳеңЁгҖҒж–Ү件зҡ„иҜ»/еҶҷ/жү§иЎҢжқғйҷҗ······
ж“ҚдҪңж–Ү件пјҡеҲӣе»әзӣ®еҪ•гҖҒеҲӣе»әж–Ү件гҖҒеҲ йҷӨж–Ү件······
дёҠйқўдёҫдҫӢзҡ„ж“ҚдҪңйғҪжҳҜеңЁејҖеҸ‘дёӯйқһеёёеёёз”Ёзҡ„пјҢFile зұ»иҝңдёҚжӯўиҝҷдәӣж“ҚдҪңпјҢжӣҙеӨҡзҡ„ж“ҚдҪңеҸҜд»ҘзӣҙжҺҘеҺ» API ж–ҮжЎЈдёӯж №жҚ®йңҖжұӮжҹҘжүҫгҖӮ
и®ҝй—®ж–Ү件зҡ„еұһжҖ§пјҡ
| API | еҠҹиғҪ |
|---|---|
| String getAbsolutePath() | иҝ”еӣһиҜҘж–Ү件еӨ„дәҺзі»з»ҹдёӯзҡ„з»қеҜ№и·Ҝеҫ„еҗҚ |
| String getPath() | иҝ”еӣһиҜҘж–Ү件зҡ„зӣёеҜ№и·Ҝеҫ„пјҢйҖҡеёёдёҺ new File() дј е…Ҙзҡ„и·Ҝеҫ„зӣёеҗҢ |
| String getName() | иҝ”еӣһиҜҘж–Ү件зҡ„ж–Ү件еҗҚ |
ж–Ү件жЈҖжөӢпјҡ
| API | еҠҹиғҪ |
|---|---|
| boolean isFIle() | ж ЎйӘҢиҜҘи·Ҝеҫ„жҢҮеҗ‘жҳҜеҗҰдёҖдёӘж–Ү件 |
| boolean isDirectory() | ж ЎйӘҢиҜҘи·Ҝеҫ„жҢҮеҗ‘жҳҜеҗҰдёҖдёӘзӣ®еҪ• |
| boolean isExist() | ж ЎйӘҢиҜҘи·Ҝеҫ„жҢҮеҗ‘зҡ„ж–Ү件/зӣ®еҪ•жҳҜеҗҰеӯҳеңЁ |
| boolean canWrite() | ж ЎйӘҢиҜҘж–Ү件жҳҜеҗҰеҸҜеҶҷ |
| boolean canRead() | ж ЎйӘҢиҜҘж–Ү件жҳҜеҗҰеҸҜиҜ» |
| boolean canExecute() | ж ЎйӘҢиҜҘж–Ү件/зӣ®еҪ•жҳҜеҗҰеҸҜд»Ҙиў«жү§иЎҢ |
ж“ҚдҪңж–Ү件пјҡ
| API | еҠҹиғҪ |
|---|---|
| mkdirs() | йҖ’еҪ’еҲӣе»әеӨҡдёӘж–Ү件еӨ№пјҢи·Ҝеҫ„дёӯй—ҙжңүеҸҜиғҪжҹҗдәӣж–Ү件еӨ№дёҚеӯҳеңЁ |
| createNewFile() | еҲӣе»әж–°ж–Ү件пјҢе®ғжҳҜдёҖдёӘеҺҹеӯҗж“ҚдҪңпјҢжңүдёӨжӯҘпјҡжЈҖжҹҘж–Ү件жҳҜеҗҰеӯҳеңЁгҖҒеҲӣе»әж–°ж–Ү件 |
| delete() | еҲ йҷӨж–Ү件жҲ–зӣ®еҪ•пјҢеҲ йҷӨзӣ®еҪ•ж—¶еҝ…йЎ»дҝқиҜҒиҜҘзӣ®еҪ•дёәз©ә |
еӨҡдәҶи§ЈдёҖдәӣ
ж–Ү件зҡ„иҜ»/еҶҷ/жү§иЎҢжқғйҷҗпјҢеңЁ Windows дёӯйҖҡеёёиЎЁзҺ°дёҚеҮәжқҘпјҢиҖҢеңЁ Linux дёӯеҸҜд»ҘеҫҲеҘҪең°дҪ“зҺ°иҝҷдёҖзӮ№пјҢеҺҹеӣ жҳҜ Linux жңүдёҘж јзҡ„з”ЁжҲ·жқғйҷҗеҲҶз»„пјҢдёҚеҗҢеҲҶз»„дёӢзҡ„з”ЁжҲ·еҜ№ж–Ү件жңүдёҚеҗҢзҡ„ж“ҚдҪңжқғйҷҗпјҢжүҖд»Ҙиҝҷдәӣж–№жі•еңЁ Linux дёӢдјҡжҜ”еңЁ Windows дёӢжӣҙеҘҪзҗҶи§ЈгҖӮдёӢеӣҫжҳҜ redis ж–Ү件еӨ№дёӯзҡ„дёҖдәӣж–Ү件зҡ„иҜҰз»ҶдҝЎжҒҜпјҢиў«зәўжЎҶж ҮжіЁзҡ„жҳҜдёҚеҗҢз”ЁжҲ·зҡ„жү§иЎҢжқғйҷҗпјҡ
r(Read)пјҡд»ЈиЎЁиҜҘж–Ү件еҸҜд»Ҙиў«еҪ“еүҚз”ЁжҲ·иҜ»пјҢж“ҚдҪңжқғйҷҗзҡ„еәҸеҸ·жҳҜ 4
w(Write)пјҡд»ЈиЎЁиҜҘж–Ү件еҸҜд»Ҙиў«еҪ“еүҚз”ЁжҲ·еҶҷпјҢж“ҚдҪңжқғйҷҗзҡ„еәҸеҸ·жҳҜ 2
x(Execute)пјҡиҜҘж–Ү件еҸҜд»Ҙиў«еҪ“еүҚз”ЁжҲ·жү§иЎҢпјҢж“ҚдҪңжқғйҷҗзҡ„еәҸеҸ·жҳҜ 1
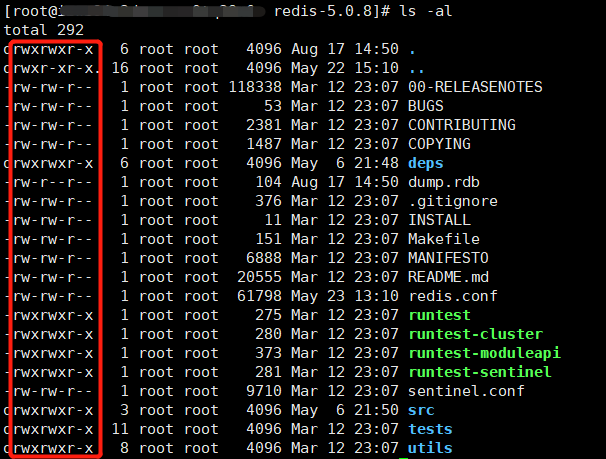
root root еҲҶеҲ«д»ЈиЎЁпјҡеҪ“еүҚж–Ү件зҡ„жүҖжңүиҖ…пјҢеҪ“еүҚж–Ү件жүҖеұһзҡ„з”ЁжҲ·еҲҶз»„гҖӮLinux дёӢж–Ү件зҡ„ж“ҚдҪңжқғйҷҗеҲҶдёәдёүз§Қз”ЁжҲ·пјҡ
ж–Ү件жүҖжңүиҖ…пјҡжӢҘжңүзҡ„жқғйҷҗжҳҜзәўжЎҶдёӯзҡ„еүҚдёүдёӘеӯ—жҜҚпјҢ-д»ЈиЎЁжІЎжңүжҹҗдёӘжқғйҷҗ
ж–Ү件жүҖеңЁз»„зҡ„жүҖжңүз”ЁжҲ·пјҡжӢҘжңүзҡ„жқғйҷҗжҳҜзәўжЎҶдёӯзҡ„дёӯй—ҙдёүдёӘеӯ—жҜҚ
е…¶е®ғз»„зҡ„жүҖжңүз”ЁжҲ·пјҡжӢҘжңүзҡ„жқғйҷҗжҳҜзәўжЎҶдёӯзҡ„жңҖеҗҺдёүдёӘеӯ—жҜҚ
Java IO жөҒеҜ№иұЎ
еӣһйЎҫжөҒзҡ„еҲҶзұ»жңү2з§Қпјҡ
ж №жҚ®ж•°жҚ®жөҒеҗ‘еҲҶдёәиҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒ
ж №жҚ®ж•°жҚ®зұ»еһӢеҲҶдёәеӯ—иҠӮжөҒе’Ңеӯ—з¬ҰжөҒ
жүҖд»ҘпјҢжң¬е°ҸиҠӮе°Ҷд»Ҙеӯ—иҠӮжөҒе’Ңеӯ—з¬ҰжөҒдҪңдёәдё»иҰҒеҲҶеүІзӮ№пјҢеңЁе…¶еҶ…йғЁеҶҚз»ҶеҲҶдёәиҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒиҝӣиЎҢи®Іи§ЈгҖӮ
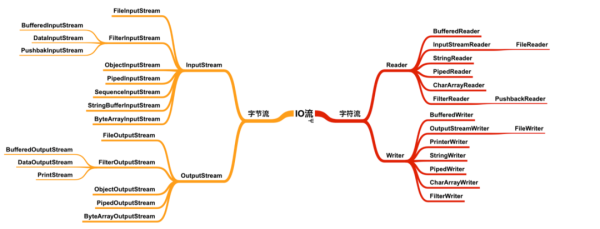
еӯ—иҠӮжөҒеҜ№иұЎ
еӯ—иҠӮжөҒеҜ№иұЎеӨ§йғЁеҲҶиҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒйғҪжҳҜжҲҗеҸҢжҲҗеҜ№ең°еҮәзҺ°пјҢжүҖд»ҘеӯҰд№ зҡ„ж—¶еҖҷеҸҜд»Ҙе°Ҷиҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒдёҖдёҖеҜ№еә”зҡ„жөҒеҜ№иұЎе…іиҒ”иө·жқҘпјҢиҫ“е…ҘжөҒе’Ңиҫ“еҮәжөҒеҸӘжҳҜж•°жҚ®жөҒеҗ‘дёҚеҗҢпјҢиҖҢеӨ„зҗҶж•°жҚ®зҡ„ж–№ејҸеҸҜд»ҘжҳҜзӣёеҗҢзҡ„гҖӮ
жіЁж„ҸдёҚиҰҒи®Өдёәз”Ёд»Җд№ҲжөҒиҜ»е…Ҙж•°жҚ®пјҢе°ұйңҖиҰҒз”ЁеҜ№еә”зҡ„жөҒеҶҷеҮәж•°жҚ®пјҢеңЁ Java дёӯжІЎжңүиҝҷд№Ҳ规е®ҡпјҢдёӢеӣҫеҸӘжҳҜеҗ„дёӘеҜ№иұЎд№Ӣй—ҙзҡ„дёҖдёӘеҜ№еә”е…ізі»пјҢдёҚжҳҜдёӨдёӘзұ»дҪҝз”Ёж—¶еҝ…йЎ»ејәеҲ¶е…іиҒ”дҪҝз”ЁгҖӮ
вҖңдёӢйқўжңүйқһеёёеӨҡзҡ„зұ»пјҢжҲ‘дјҡд»Ӣз»Қеҹәзұ»зҡ„ж–№жі•пјҢдәҶи§Јиҝҷдәӣж–№жі•жҳҜйқһеёёжңүеҝ…иҰҒзҡ„пјҢеӯҗзұ»зҡ„еҠҹиғҪеҹәдәҺзҲ¶зұ»еҺ»жү©еұ•пјҢеҸӘжңүзңҹжӯЈдәҶи§ЈзҲ¶зұ»еңЁеҒҡд»Җд№ҲпјҢеӯҰд№ еӯҗзұ»зҡ„жҲҗжң¬е°ұдјҡдёӢйҷҚгҖӮвҖқ
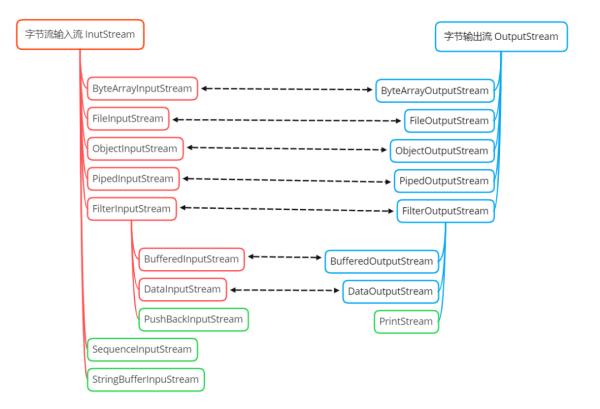
InputStream
InputStream жҳҜеӯ—иҠӮиҫ“е…ҘжөҒзҡ„жҠҪиұЎеҹәзұ»пјҢжҸҗдҫӣдәҶйҖҡз”Ёзҡ„иҜ»ж–№жі•пјҢи®©еӯҗзұ»дҪҝз”ЁжҲ–йҮҚеҶҷе®ғ们гҖӮдёӢйқўжҳҜ InputStream еёёз”Ёзҡ„йҮҚиҰҒзҡ„ж–№жі•гҖӮ
| йҮҚиҰҒж–№жі• | еҠҹиғҪ |
|---|---|
| public abstract int read() | д»Һиҫ“е…ҘжөҒдёӯиҜ»еҸ–дёӢдёҖдёӘеӯ—иҠӮпјҢиҜ»еҲ°е°ҫйғЁж—¶иҝ”еӣһ -1 |
| public int read(byte b[]) | д»Һиҫ“е…ҘжөҒдёӯиҜ»еҸ–й•ҝеәҰдёә b.length дёӘеӯ—иҠӮж”ҫе…Ҙеӯ—иҠӮж•°з»„ b дёӯ |
| public int read(byte b[], int off, int len) | д»Һиҫ“е…ҘжөҒдёӯиҜ»еҸ–жҢҮе®ҡиҢғеӣҙзҡ„еӯ—иҠӮж•°жҚ®ж”ҫе…Ҙеӯ—иҠӮж•°з»„ b дёӯ |
| public void close() | е…ій—ӯжӯӨиҫ“е…ҘжөҒ并йҮҠж”ҫдёҺиҜҘиҫ“е…ҘжөҒзӣёе…ізҡ„жүҖжңүиө„жәҗ |
иҝҳжңүе…¶е®ғдёҖдәӣдёҚеӨӘеёёз”Ёзҡ„ж–№жі•пјҢжҲ‘д№ҹеҲ—еҮәжқҘдәҶгҖӮ
| е…¶е®ғж–№жі• | еҠҹиғҪ |
|---|---|
| public long skip(long n) | и·іиҝҮжҺҘдёӢжқҘзҡ„ n дёӘеӯ—иҠӮпјҢиҝ”еӣһе®һйҷ…дёҠи·іиҝҮзҡ„еӯ—иҠӮж•° |
| public long available() | иҝ”еӣһдёӢдёҖж¬ЎеҸҜиҜ»еҸ–пјҲи·іиҝҮпјүдё”дёҚдјҡиў«ж–№жі•йҳ»еЎһзҡ„еӯ—иҠӮж•°зҡ„дј°и®ЎеҖј |
| public synchronized void mark(int readlimit) | ж Үи®°жӯӨиҫ“е…ҘжөҒзҡ„еҪ“еүҚдҪҚзҪ®пјҢеҜ№ reset() ж–№жі•зҡ„еҗҺз»ӯи°ғз”Ёе°ҶдјҡйҮҚж–°е®ҡдҪҚеңЁ mark() ж Үи®°зҡ„дҪҚзҪ®пјҢеҸҜд»ҘйҮҚж–°иҜ»еҸ–зӣёеҗҢзҡ„еӯ—иҠӮ |
| public boolean markSupported() | еҲӨж–ӯиҜҘиҫ“е…ҘжөҒжҳҜеҗҰж”ҜжҢҒ mark() е’Ң reset() ж–№жі•пјҢеҚіиғҪеҗҰйҮҚеӨҚиҜ»еҸ–еӯ—иҠӮ |
| public synchronized void reset() | е°ҶжөҒзҡ„дҪҚзҪ®йҮҚж–°е®ҡдҪҚеңЁжңҖеҗҺдёҖж¬Ўи°ғз”Ё mark() ж–№жі•ж—¶зҡ„дҪҚзҪ® |
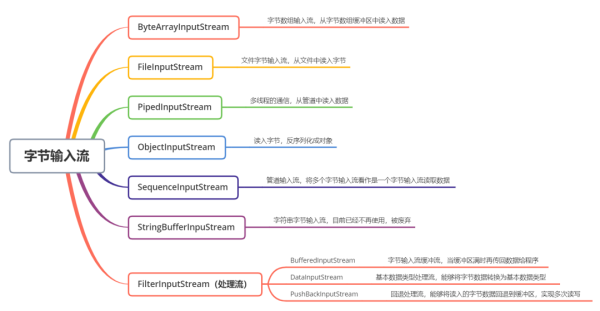
(1)ByteArrayInputStream
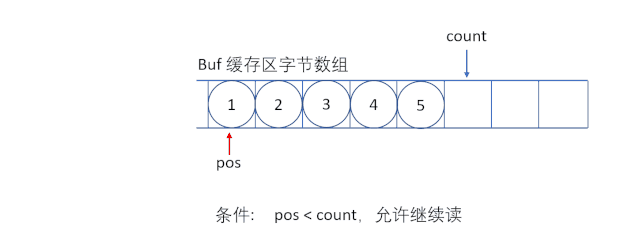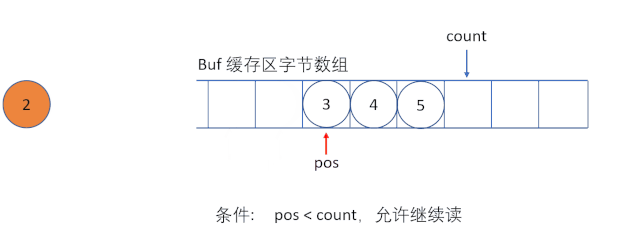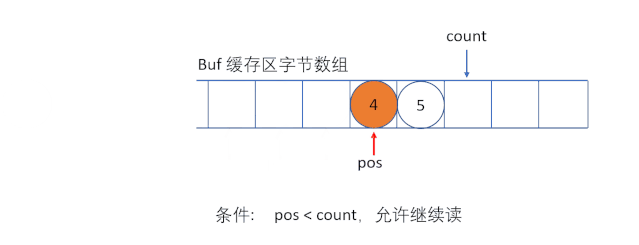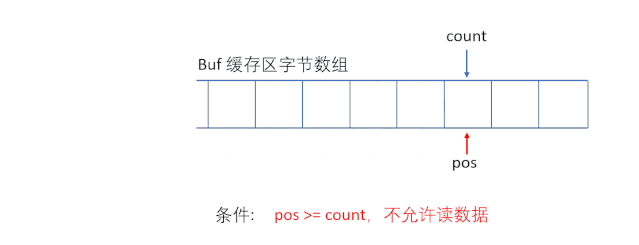
ByteArrayInputStream еҶ…йғЁеҢ…еҗ«дёҖдёӘ buf еӯ—иҠӮж•°з»„зј“еҶІеҢәпјҢиҜҘзј“еҶІеҢәеҸҜд»Ҙд»ҺжөҒдёӯиҜ»еҸ–зҡ„еӯ—иҠӮж•°пјҢдҪҝз”Ё pos жҢҮй’ҲжҢҮеҗ‘иҜ»еҸ–дёӢдёҖдёӘеӯ—иҠӮзҡ„дёӢж ҮдҪҚзҪ®пјҢеҶ…йғЁиҝҳз»ҙжҠӨдәҶдёҖдёӘcount еұһжҖ§пјҢд»ЈиЎЁиғҪеӨҹиҜ»еҸ– count дёӘеӯ—иҠӮгҖӮ
bytearrayinputstream
вҖңеҝ…йЎ»дҝқиҜҒ pos дёҘж је°ҸдәҺ countпјҢиҖҢ count дёҘж је°ҸдәҺ buf.length ж—¶пјҢжүҚиғҪеӨҹд»Һзј“еҶІеҢәдёӯиҜ»еҸ–ж•°жҚ®вҖқ
(2)FileInputStream
ж–Ү件иҫ“е…ҘжөҒпјҢд»Һж–Ү件дёӯиҜ»е…Ҙеӯ—иҠӮпјҢйҖҡеёёеҜ№ж–Ү件зҡ„жӢ·иҙқгҖҒ移еҠЁзӯүж“ҚдҪңпјҢеҸҜд»ҘдҪҝз”ЁиҜҘиҫ“е…ҘжөҒжҠҠж–Ү件зҡ„еӯ—иҠӮиҜ»е…ҘеҶ…еӯҳдёӯпјҢ然еҗҺеҶҚеҲ©з”Ёиҫ“еҮәжөҒиҫ“еҮәеҲ°жҢҮе®ҡзҡ„дҪҚзҪ®дёҠгҖӮ
(3)PipedInputStream
з®ЎйҒ“иҫ“е…ҘжөҒпјҢе®ғдёҺ PipedOutputStream жҲҗеҜ№еҮәзҺ°пјҢеҸҜд»Ҙе®һзҺ°еӨҡзәҝзЁӢдёӯзҡ„з®ЎйҒ“йҖҡдҝЎгҖӮPipedOutputStream дёӯжҢҮе®ҡдёҺзү№е®ҡзҡ„ PipedInputStream иҝһжҺҘпјҢPipedInputStream д№ҹйңҖиҰҒжҢҮе®ҡзү№е®ҡзҡ„ PipedOutputStream иҝһжҺҘпјҢд№ӢеҗҺиҫ“еҮәжөҒдёҚж–ӯең°еҫҖиҫ“е…ҘжөҒзҡ„ buffer зј“еҶІеҢәеҶҷж•°жҚ®пјҢиҖҢиҫ“е…ҘжөҒеҸҜд»Ҙд»Һзј“еҶІеҢәдёӯиҜ»еҸ–ж•°жҚ®гҖӮ
(4)ObjectInputStream
еҜ№иұЎиҫ“е…ҘжөҒпјҢз”ЁдәҺеҜ№иұЎзҡ„еҸҚеәҸеҲ—еҢ–пјҢе°ҶиҜ»е…Ҙзҡ„еӯ—иҠӮж•°жҚ®еҸҚеәҸеҲ—еҢ–дёәдёҖдёӘеҜ№иұЎпјҢе®һзҺ°еҜ№иұЎзҡ„жҢҒд№…еҢ–еӯҳеӮЁгҖӮ
(5)PushBackInputStream
е®ғжҳҜ FilterInputStream зҡ„еӯҗзұ»пјҢжҳҜдёҖдёӘеӨ„зҗҶжөҒпјҢе®ғеҶ…йғЁз»ҙжҠӨдәҶдёҖдёӘзј“еҶІж•°з»„bufгҖӮ
еңЁиҜ»е…Ҙеӯ—иҠӮзҡ„иҝҮзЁӢдёӯеҸҜд»Ҙе°ҶиҜ»еҸ–еҲ°зҡ„еӯ—иҠӮж•°жҚ®еӣһйҖҖз»ҷзј“еҶІеҢәдёӯдҝқеӯҳпјҢдёӢж¬ЎеҸҜд»ҘеҶҚж¬Ўд»Һзј“еҶІеҢәдёӯиҜ»еҮәиҜҘеӯ—иҠӮж•°жҚ®гҖӮжүҖд»ҘPushBackInputStream е…Ғи®ёеӨҡж¬ЎиҜ»еҸ–иҫ“е…ҘжөҒзҡ„еӯ—иҠӮж•°жҚ®пјҢеҸӘиҰҒе°ҶиҜ»еҲ°зҡ„еӯ—иҠӮж”ҫеӣһзј“еҶІеҢәеҚіеҸҜгҖӮ
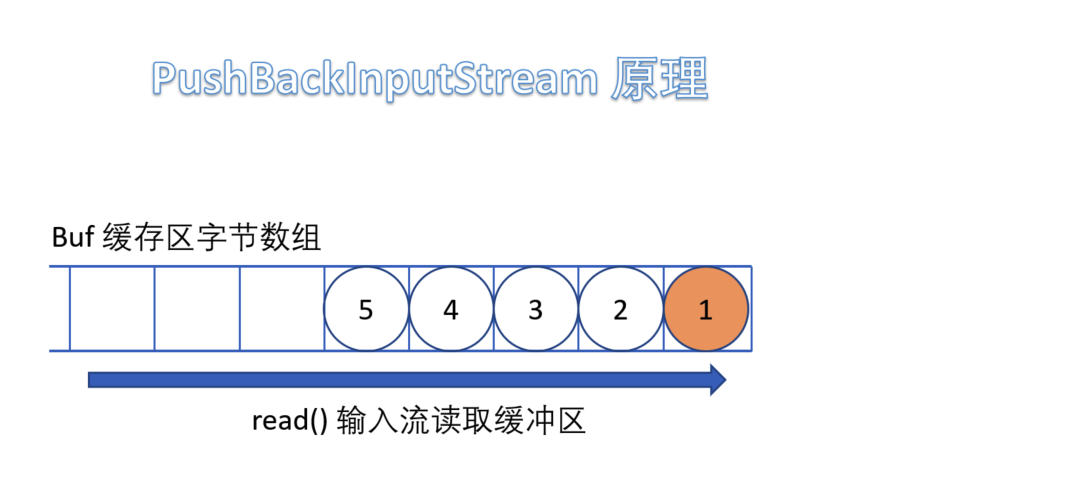
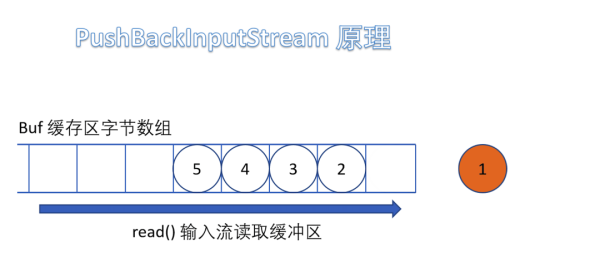
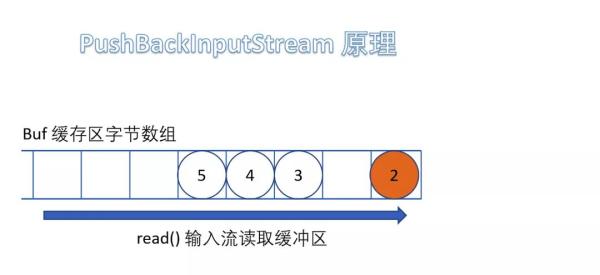
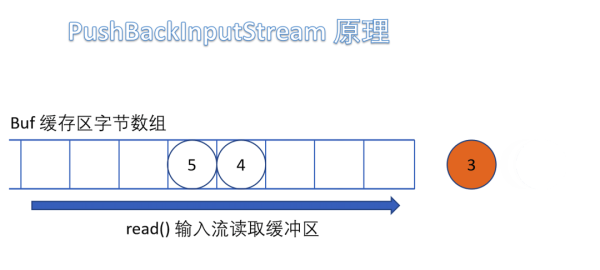
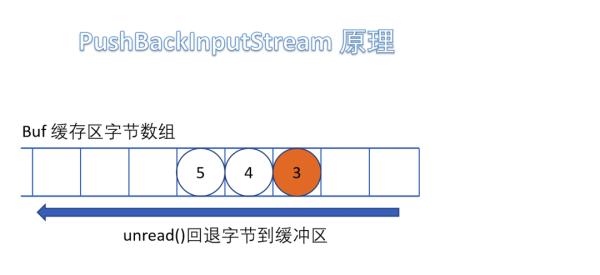
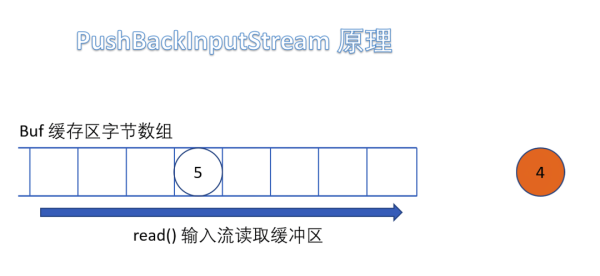
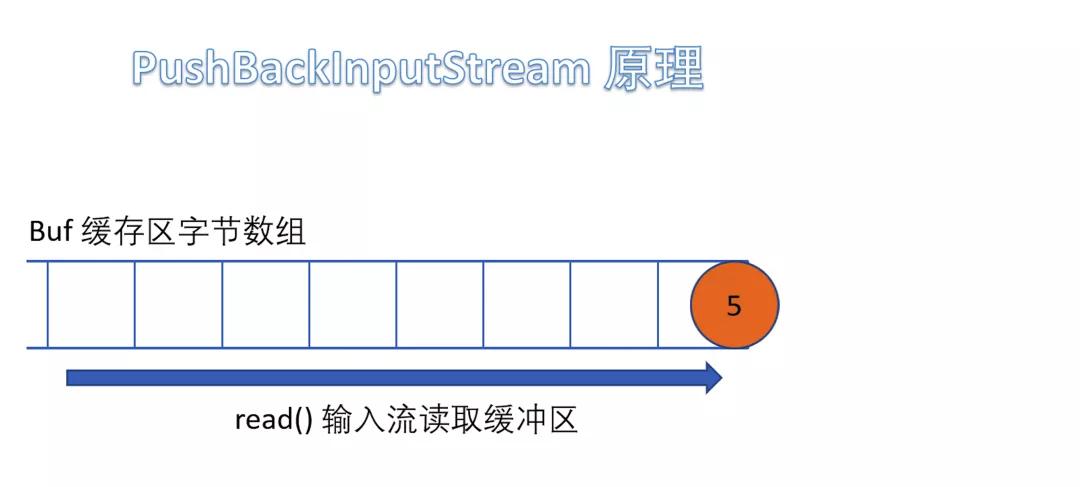
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜеҰӮжһңеӣһжҺЁеӯ—иҠӮж—¶пјҢеҰӮжһңзј“еҶІеҢәе·Іж»ЎпјҢдјҡжҠӣеҮә IOException ејӮеёёгҖӮ
е®ғзҡ„еә”з”ЁеңәжҷҜпјҡеҜ№ж•°жҚ®иҝӣиЎҢеҲҶзұ»и§„ж•ҙгҖӮ
еҒҮеҰӮдёҖдёӘж–Ү件дёӯеӯҳеӮЁдәҶж•°еӯ—е’Ңеӯ—жҜҚдёӨз§Қзұ»еһӢзҡ„ж•°жҚ®пјҢжҲ‘们йңҖиҰҒе°Ҷе®ғ们дәӨз»ҷдёӨз§ҚзәҝзЁӢеҗ„иҮӘеҺ»ж”¶йӣҶиҮӘе·ұиҙҹиҙЈзҡ„ж•°жҚ®пјҢеҰӮжһңйҮҮз”Ёдј з»ҹзҡ„еҒҡжі•пјҢжҠҠжүҖжңүзҡ„ж•°жҚ®е…ЁйғЁиҜ»е…ҘеҶ…еӯҳдёӯпјҢеҶҚе°Ҷж•°жҚ®иҝӣиЎҢеҲҶзҰ»пјҢйқўеҜ№еӨ§ж–Ү件зҡ„жғ…еҶөдёӢпјҢдҫӢеҰӮ1GгҖҒ2GпјҢдј з»ҹзҡ„иҫ“е…ҘжөҒеңЁиҜ»е…Ҙж•°з»„еҗҺпјҢз”ұдәҺжІЎжңүзј“еҶІеҢәпјҢеҸӘиғҪеҜ№ж•°жҚ®иҝӣиЎҢжҠӣејғпјҢиҝҷж ·жҜҸдёӘзәҝзЁӢйғҪиҰҒиҜ»дёҖйҒҚж–Ү件гҖӮ
дҪҝз”Ё PushBackInputStream еҸҜд»Ҙи®©дёҖдёӘдё“й—Ёзҡ„зәҝзЁӢиҜ»еҸ–ж–Ү件пјҢе”ӨйҶ’дёҚеҗҢзҡ„зәҝзЁӢиҜ»еҸ–еӯ—з¬Ұпјҡ
第дёҖж¬ЎиҜ»еҸ–зј“еҶІеҢәзҡ„ж•°жҚ®пјҢеҲӨж–ӯиҜҘж•°жҚ®з”ұе“ӘдәӣзәҝзЁӢиҜ»еҸ–
еӣһйҖҖж•°жҚ®пјҢе”ӨйҶ’еҜ№еә”зҡ„зәҝзЁӢиҜ»еҸ–ж•°жҚ®
йҮҚеӨҚеүҚдёӨжӯҘ
е…ій—ӯиҫ“е…ҘжөҒ
еҲ°иҝҷйҮҢпјҢдҪ жҳҜеҗҰдјҡжғіеҲ° AQS зҡ„ Condition зӯүеҫ…йҳҹеҲ—пјҢеӨҡдёӘзәҝзЁӢеҸҜд»ҘеңЁдёҚеҗҢзҡ„жқЎд»¶дёҠзӯүеҫ…иў«е”ӨйҶ’гҖӮ
(6)BufferedInputStream
зј“еҶІжөҒпјҢе®ғжҳҜдёҖз§ҚеӨ„зҗҶжөҒпјҢеҜ№иҠӮзӮ№жөҒиҝӣиЎҢе°Ғ装并еўһејәпјҢе…¶еҶ…йғЁжӢҘжңүдёҖдёӘ buffer зј“еҶІеҢәпјҢз”ЁдәҺзј“еӯҳжүҖжңүиҜ»е…Ҙзҡ„еӯ—иҠӮпјҢеҪ“зј“еҶІеҢәж»Ўж—¶пјҢжүҚдјҡе°ҶжүҖжңүеӯ—иҠӮеҸ‘йҖҒз»ҷе®ўжҲ·з«ҜиҜ»еҸ–пјҢиҖҢдёҚжҳҜжҜҸж¬ЎйғҪеҸӘеҸ‘йҖҒдёҖйғЁеҲҶж•°жҚ®пјҢжҸҗй«ҳдәҶж•ҲзҺҮгҖӮ
(7)DataInputStream
ж•°жҚ®иҫ“е…ҘжөҒпјҢе®ғеҗҢж ·жҳҜдёҖз§ҚеӨ„зҗҶжөҒпјҢеҜ№иҠӮзӮ№жөҒиҝӣиЎҢе°ҒиЈ…еҗҺпјҢиғҪеӨҹеңЁеҶ…йғЁеҜ№иҜ»е…Ҙзҡ„еӯ—иҠӮиҪ¬жҚўдёәеҜ№еә”зҡ„ Java еҹәжң¬ж•°жҚ®зұ»еһӢгҖӮ
(8)SequenceInputStream
е°ҶдёӨдёӘжҲ–еӨҡдёӘиҫ“е…ҘжөҒзңӢдҪңжҳҜдёҖдёӘиҫ“е…ҘжөҒдҫқж¬ЎиҜ»еҸ–пјҢиҜҘзұ»зҡ„еӯҳеңЁдёҺеҗҰ并дёҚеҪұе“Қж•ҙдёӘ IO з”ҹжҖҒпјҢеңЁзЁӢеәҸдёӯд№ҹиғҪеӨҹеҒҡеҲ°иҝҷз§Қж•Ҳжһң
(9)StringBufferInputStream
е°Ҷеӯ—з¬ҰдёІдёӯжҜҸдёӘеӯ—з¬Ұзҡ„дҪҺ 8 дҪҚиҪ¬жҚўдёәеӯ—иҠӮиҜ»е…ҘеҲ°еӯ—иҠӮж•°з»„дёӯпјҢзӣ®еүҚе·ІиҝҮжңҹ
InputStream жҖ»з»“пјҡ
InputStream жҳҜжүҖжңүиҫ“е…Ҙеӯ—иҠӮжөҒзҡ„жҠҪиұЎеҹәзұ»
ByteArrayInputStream е’Ң FileInputStream жҳҜдёӨз§Қеҹәжң¬зҡ„иҠӮзӮ№жөҒпјҢ他们еҲҶеҲ«д»Һеӯ—иҠӮж•°з»„ е’Ң жң¬ең°ж–Ү件дёӯиҜ»еҸ–ж•°жҚ®
DataInputStreamгҖҒBufferedInputStream е’Ң PushBackInputStream йғҪжҳҜеӨ„зҗҶжөҒпјҢеҜ№еҹәжң¬зҡ„иҠӮзӮ№жөҒиҝӣиЎҢе°Ғ装并еўһејә
PipiedInputStream з”ЁдәҺеӨҡзәҝзЁӢйҖҡдҝЎпјҢеҸҜд»ҘдёҺе…¶е®ғзәҝзЁӢе…¬з”ЁдёҖдёӘз®ЎйҒ“пјҢиҜ»еҸ–з®ЎйҒ“дёӯзҡ„ж•°жҚ®гҖӮ
ObjectInputStream з”ЁдәҺеҜ№иұЎзҡ„еҸҚеәҸеҲ—еҢ–пјҢе°ҶеҜ№иұЎзҡ„еӯ—иҠӮж•°жҚ®иҜ»е…ҘеҶ…еӯҳдёӯпјҢйҖҡиҝҮиҜҘжөҒеҜ№иұЎеҸҜд»Ҙе°Ҷеӯ—иҠӮж•°жҚ®иҪ¬жҚўжҲҗеҜ№еә”зҡ„еҜ№иұЎ
OutputStream
OutputStream жҳҜеӯ—иҠӮиҫ“еҮәжөҒзҡ„жҠҪиұЎеҹәзұ»пјҢжҸҗдҫӣдәҶйҖҡз”Ёзҡ„еҶҷж–№жі•пјҢ让继жүҝзҡ„еӯҗзұ»йҮҚеҶҷе’ҢеӨҚз”ЁгҖӮ
| ж–№жі• | еҠҹиғҪ |
|---|---|
| public abstract void write(int b) | е°ҶжҢҮе®ҡзҡ„еӯ—иҠӮеҶҷеҮәеҲ°иҫ“еҮәжөҒпјҢеҶҷе…Ҙзҡ„еӯ—иҠӮжҳҜеҸӮж•° b зҡ„дҪҺ 8 дҪҚ |
| public void write(byte b[]) | е°ҶжҢҮе®ҡеӯ—иҠӮж•°з»„дёӯзҡ„жүҖжңүеӯ—иҠӮеҶҷе…ҘеҲ°иҫ“еҮәжөҒеҪ“дёӯ |
| public void write(byte b[], int off, int len) | жҢҮе®ҡеҶҷе…Ҙзҡ„иө·е§ӢдҪҚзҪ® offerпјҢеӯ—иҠӮж•°дёә len зҡ„еӯ—иҠӮж•°з»„еҶҷе…ҘеҲ°иҫ“еҮәжөҒеҪ“дёӯ |
| public void flush() | еҲ·ж–°жӯӨиҫ“еҮәжөҒпјҢ并ејәеҲ¶еҶҷеҮәжүҖжңүзј“еҶІзҡ„иҫ“еҮәеӯ—иҠӮеҲ°жҢҮе®ҡдҪҚзҪ®пјҢжҜҸж¬ЎеҶҷе®ҢйғҪиҰҒи°ғз”Ё |
| public void close() | е…ій—ӯжӯӨиҫ“еҮәжөҒ并йҮҠж”ҫдёҺжӯӨжөҒе…іиҒ”зҡ„жүҖжңүзі»з»ҹиө„жәҗ |
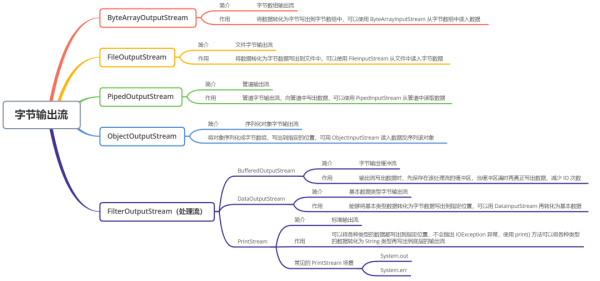
OutputStream дёӯеӨ§еӨҡж•°зҡ„зұ»е’Ң InputStream жҳҜеҜ№еә”зҡ„пјҢеҸӘдёҚиҝҮж•°жҚ®зҡ„жөҒеҗ‘дёҚеҗҢиҖҢе·ІгҖӮд»ҺдёҠйқўзҡ„еӣҫеҸҜд»ҘзңӢеҮәпјҡ
OutputStream жҳҜжүҖжңүиҫ“еҮәеӯ—иҠӮжөҒзҡ„жҠҪиұЎеҹәзұ»
ByteArrayOutputStream е’Ң FileOutputStream жҳҜдёӨз§Қеҹәжң¬зҡ„иҠӮзӮ№жөҒпјҢе®ғ们еҲҶеҲ«еҗ‘еӯ—иҠӮж•°з»„е’Ңжң¬ең°ж–Ү件еҶҷеҮәж•°жҚ®
DataOutputStreamгҖҒBufferedOutputStream жҳҜеӨ„зҗҶжөҒпјҢеүҚиҖ…еҸҜд»Ҙе°Ҷеӯ—иҠӮж•°жҚ®иҪ¬жҚўжҲҗеҹәжң¬ж•°жҚ®зұ»еһӢеҶҷеҮәеҲ°ж–Ү件дёӯ;еҗҺиҖ…жҳҜзј“еҶІеӯ—иҠӮж•°з»„пјҢеҸӘжңүеңЁзј“еҶІеҢәж»Ўж—¶пјҢжүҚдјҡе°ҶжүҖжңүзҡ„еӯ—иҠӮеҶҷеҮәеҲ°зӣ®зҡ„ең°пјҢеҮҸе°‘дәҶ IO ж¬Ўж•°гҖӮ
PipedOutputStream з”ЁдәҺеӨҡзәҝзЁӢйҖҡдҝЎпјҢеҸҜд»Ҙе’Ңе…¶е®ғзәҝзЁӢе…ұз”ЁдёҖдёӘз®ЎйҒ“пјҢеҗ‘з®ЎйҒ“дёӯеҶҷе…Ҙж•°жҚ®
ObjectOutputStream з”ЁдәҺеҜ№иұЎзҡ„еәҸеҲ—еҢ–пјҢе°ҶеҜ№иұЎиҪ¬жҚўжҲҗеӯ—иҠӮж•°з»„еҗҺпјҢе°ҶжүҖжңүзҡ„еӯ—иҠӮйғҪеҶҷе…ҘеҲ°жҢҮе®ҡдҪҚзҪ®дёӯ
PrintStream еңЁ OutputStream еҹәзЎҖд№ӢдёҠжҸҗдҫӣдәҶеўһејәзҡ„еҠҹиғҪпјҢеҚіеҸҜд»Ҙж–№дҫҝең°иҫ“еҮәеҗ„з§Қзұ»еһӢзҡ„ж•°жҚ®(иҖҢдёҚд»…йҷҗдәҺbyteеһӢ)зҡ„ж јејҸеҢ–иЎЁзӨәеҪўејҸпјҢдё” PrintStream зҡ„ж–№жі•д»ҺдёҚжҠӣеҮә IOEceptionпјҢе…¶еҺҹзҗҶжҳҜеҶҷеҮәж—¶е°Ҷеҗ„дёӘж•°жҚ®зұ»еһӢзҡ„ж•°жҚ®з»ҹдёҖиҪ¬жҚўдёә String зұ»еһӢпјҢжҲ‘дјҡеңЁи®Іи§Је®Ң
еӯ—з¬ҰжөҒеҜ№иұЎ
еӯ—з¬ҰжөҒеҜ№иұЎд№ҹдјҡжңүеҜ№еә”е…ізі»пјҢеӨ§еӨҡж•°зҡ„зұ»еҸҜд»Ҙи®ӨдёәжҳҜж“ҚдҪңзҡ„ж•°жҚ®д»Һеӯ—иҠӮж•°з»„еҸҳдёәеӯ—з¬ҰпјҢзұ»зҡ„еҠҹиғҪе’Ңеӯ—иҠӮжөҒеҜ№иұЎжҳҜзӣёдјјзҡ„гҖӮ
вҖңеӯ—з¬Ұиҫ“е…ҘжөҒе’Ңеӯ—иҠӮиҫ“е…ҘжөҒзҡ„з»„жҲҗйқһеёёзӣёдјјпјҢеӯ—з¬Ұиҫ“е…ҘжөҒжҳҜеҜ№еӯ—иҠӮиҫ“е…ҘжөҒзҡ„дёҖеұӮиҪ¬жҚўпјҢжүҖжңүж–Ү件зҡ„еӯҳеӮЁйғҪжҳҜеӯ—иҠӮзҡ„еӯҳеӮЁпјҢеңЁзЈҒзӣҳдёҠдҝқз•ҷзҡ„дёҚжҳҜж–Ү件зҡ„еӯ—з¬ҰпјҢиҖҢжҳҜе…ҲжҠҠеӯ—з¬Ұзј–з ҒжҲҗеӯ—иҠӮпјҢеҶҚдҝқеӯҳеҲ°ж–Ү件дёӯгҖӮеңЁиҜ»еҸ–ж–Ү件时пјҢиҜ»е…Ҙзҡ„д№ҹжҳҜдёҖдёӘдёҖдёӘеӯ—иҠӮз»„жҲҗзҡ„еӯ—иҠӮеәҸеҲ—пјҢиҖҢ Java иҷҡжӢҹжңәйҖҡиҝҮе°Ҷеӯ—иҠӮеәҸеҲ—пјҢжҢүз…§2дёӘеӯ—иҠӮдёәеҚ•дҪҚиҪ¬жҚўдёә Unicode еӯ—з¬ҰпјҢе®һзҺ°еӯ—иҠӮеҲ°еӯ—з¬Ұзҡ„жҳ е°„гҖӮвҖқ
Reader
Reader жҳҜеӯ—з¬Ұиҫ“е…ҘжөҒзҡ„жҠҪиұЎеҹәзұ»пјҢе®ғеҶ…йғЁзҡ„йҮҚиҰҒж–№жі•еҰӮдёӢжүҖзӨәгҖӮ
| йҮҚиҰҒж–№жі• | ж–№жі•еҠҹиғҪ |
|---|---|
| public int read(java.nio.CharBuffer target) | е°ҶиҜ»е…Ҙзҡ„еӯ—з¬Ұеӯҳе…ҘжҢҮе®ҡзҡ„еӯ—з¬Ұзј“еҶІеҢәдёӯ |
| public int read() | иҜ»еҸ–дёҖдёӘеӯ—з¬Ұ |
| public int read(char cbuf[]) | иҜ»е…Ҙеӯ—з¬Ұж”ҫе…Ҙж•ҙдёӘеӯ—з¬Ұж•°з»„дёӯ |
| abstract public int read(char cbuf[], int off, int len) | е°Ҷеӯ—з¬ҰиҜ»е…Ҙеӯ—з¬Ұж•°з»„дёӯзҡ„жҢҮе®ҡиҢғеӣҙдёӯ |
иҝҳжңүе…¶е®ғдёҖдәӣйўқеӨ–зҡ„ж–№жі•пјҢдёҺеӯ—иҠӮиҫ“е…ҘжөҒеҹәзұ»жҸҗдҫӣзҡ„ж–№жі•жҳҜзӣёеҗҢзҡ„пјҢеҸӘжҳҜдҪңз”Ёзҡ„еҜ№иұЎдёҚеҶҚжҳҜеӯ—иҠӮпјҢиҖҢжҳҜеӯ—з¬ҰгҖӮ
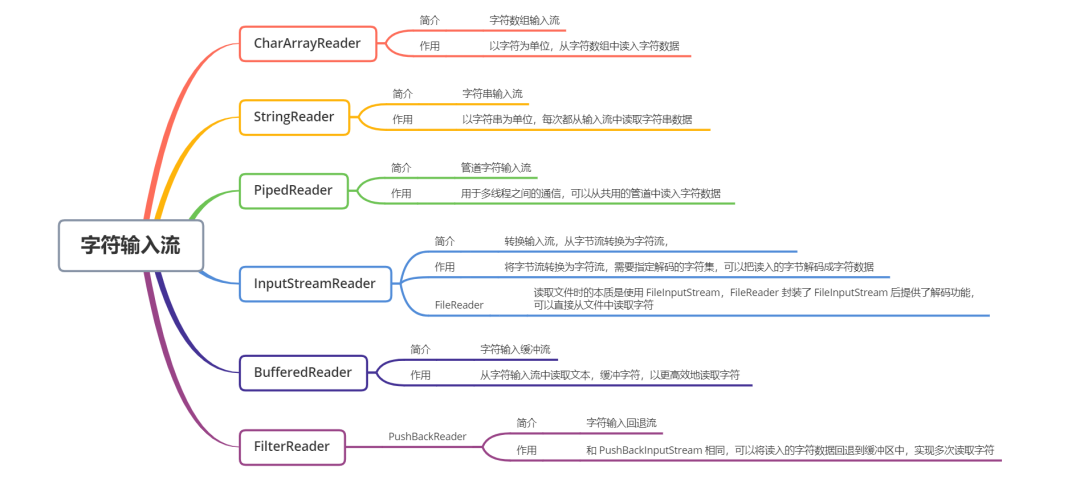
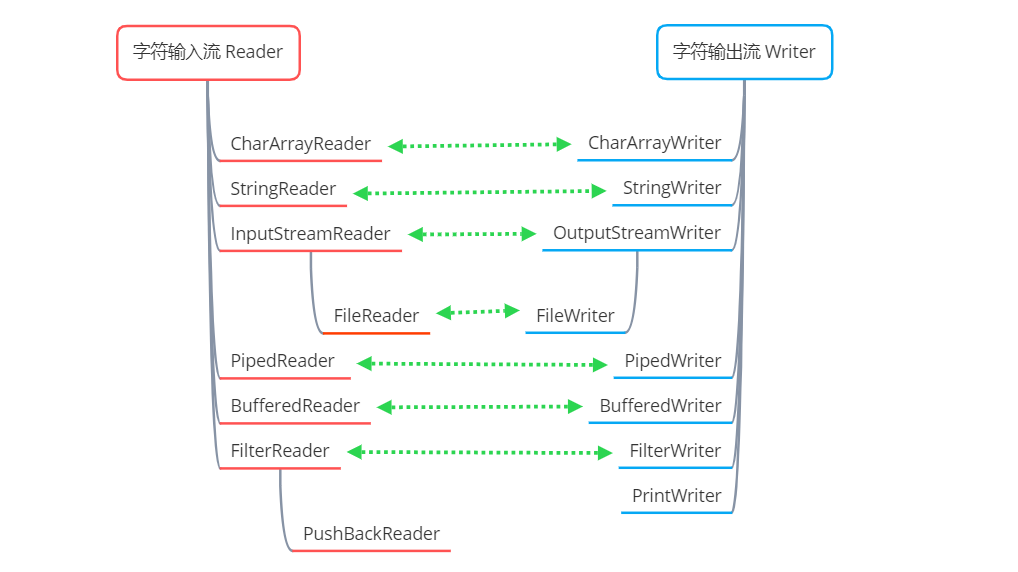
Reader жҳҜжүҖжңүеӯ—з¬Ұиҫ“е…ҘжөҒзҡ„жҠҪиұЎеҹәзұ»
CharArrayReader е’Ң StringReader жҳҜдёӨз§Қеҹәжң¬зҡ„иҠӮзӮ№жөҒпјҢе®ғ们еҲҶеҲ«д»ҺиҜ»еҸ– еӯ—з¬Ұж•°з»„е’Ң еӯ—з¬ҰдёІ ж•°жҚ®пјҢStringReader еҶ…йғЁжҳҜдёҖдёӘ String еҸҳйҮҸеҖјпјҢйҖҡиҝҮйҒҚеҺҶиҜҘеҸҳйҮҸзҡ„еӯ—з¬ҰпјҢе®һзҺ°иҜ»еҸ–еӯ—з¬ҰдёІпјҢжң¬иҙЁдёҠд№ҹжҳҜеңЁиҜ»еҸ–еӯ—з¬Ұж•°з»„
PipedReader з”ЁдәҺеӨҡзәҝзЁӢдёӯзҡ„йҖҡдҝЎпјҢд»Һе…ұз”Ёең°з®ЎйҒ“дёӯиҜ»еҸ–еӯ—з¬Ұж•°жҚ®
BufferedReader жҳҜеӯ—з¬Ұиҫ“е…Ҙзј“еҶІжөҒпјҢе°ҶиҜ»е…Ҙзҡ„ж•°жҚ®ж”ҫе…Ҙеӯ—з¬Ұзј“еҶІеҢәдёӯпјҢе®һзҺ°й«ҳж•Ҳең°иҜ»еҸ–еӯ—з¬Ұ
InputStreamReader жҳҜдёҖз§ҚиҪ¬жҚўжөҒпјҢеҸҜд»Ҙе®һзҺ°д»Һеӯ—иҠӮжөҒиҪ¬жҚўдёәеӯ—з¬ҰжөҒпјҢе°Ҷеӯ—иҠӮж•°жҚ®иҪ¬жҚўдёәеӯ—з¬Ұ
Writer
Reader жҳҜеӯ—з¬Ұиҫ“еҮәжөҒзҡ„жҠҪиұЎеҹәзұ»пјҢе®ғеҶ…йғЁзҡ„йҮҚиҰҒж–№жі•еҰӮдёӢжүҖзӨәгҖӮ
| йҮҚиҰҒж–№жі• | ж–№жі•еҠҹиғҪ |
|---|---|
| public void write(char cbuf[]) | е°Ҷ cbuf еӯ—з¬Ұж•°з»„еҶҷеҮәеҲ°иҫ“еҮәжөҒ |
| abstract public void write(char cbuf[], int off, int len) | е°ҶжҢҮе®ҡиҢғеӣҙзҡ„ cbuf еӯ—з¬Ұж•°з»„еҶҷеҮәеҲ°иҫ“еҮәжөҒ |
| public void write(String str) | е°Ҷеӯ—з¬ҰдёІ str еҶҷеҮәеҲ°иҫ“еҮәжөҒпјҢstr еҶ…йғЁд№ҹжҳҜеӯ—з¬Ұж•°з»„ |
| public void write(String str, int off, int len) | е°Ҷеӯ—з¬ҰдёІ str зҡ„жҹҗдёҖйғЁеҲҶеҶҷеҮәеҲ°иҫ“еҮәжөҒ |
| abstract public void flush() | еҲ·ж–°пјҢеҰӮжһңж•°жҚ®дҝқеӯҳеңЁзј“еҶІеҢәпјҢи°ғз”ЁиҜҘж–№жі•жүҚдјҡзңҹжӯЈеҶҷеҮәеҲ°жҢҮе®ҡдҪҚзҪ® |
| abstract public void close() | е…ій—ӯжөҒеҜ№иұЎпјҢжҜҸж¬Ў IO жү§иЎҢе®ҢжҜ•еҗҺйғҪйңҖиҰҒе…ій—ӯжөҒеҜ№иұЎпјҢйҮҠж”ҫзі»з»ҹиө„жәҗ |
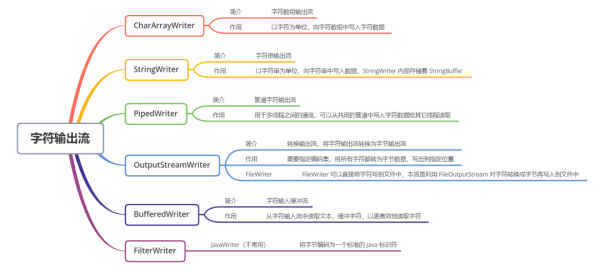
Writer жҳҜжүҖжңүзҡ„иҫ“еҮәеӯ—з¬ҰжөҒзҡ„жҠҪиұЎеҹәзұ»
CharArrayWriterгҖҒStringWriter жҳҜдёӨз§Қеҹәжң¬зҡ„иҠӮзӮ№жөҒпјҢе®ғ们еҲҶеҲ«еҗ‘Char ж•°з»„гҖҒеӯ—з¬ҰдёІдёӯеҶҷе…Ҙж•°жҚ®гҖӮStringWriter еҶ…йғЁдҝқеӯҳдәҶ StringBuffer еҜ№иұЎпјҢеҸҜд»Ҙе®һзҺ°еӯ—з¬ҰдёІзҡ„еҠЁжҖҒеўһй•ҝ
PipedWriter еҸҜд»Ҙеҗ‘е…ұз”Ёзҡ„з®ЎйҒ“дёӯеҶҷе…Ҙеӯ—з¬Ұж•°жҚ®пјҢз»ҷе…¶е®ғзәҝзЁӢиҜ»еҸ–гҖӮ
BufferedWriter жҳҜзј“еҶІиҫ“еҮәжөҒпјҢеҸҜд»Ҙе°ҶеҶҷеҮәзҡ„ж•°жҚ®зј“еӯҳиө·жқҘпјҢзј“еҶІеҢәж»Ўж—¶еҶҚи°ғз”Ё flush() еҶҷеҮәж•°жҚ®пјҢеҮҸе°‘ IO ж¬Ўж•°гҖӮ
PrintWriter е’Ң PrintStream зұ»дјјпјҢеҠҹиғҪе’ҢдҪҝз”Ёд№ҹйқһеёёзӣёдјјпјҢеҸӘжҳҜеҶҷеҮәзҡ„ж•°жҚ®жҳҜеӯ—з¬ҰиҖҢдёҚжҳҜеӯ—иҠӮгҖӮ
OutputStreamWriter е°Ҷеӯ—з¬ҰжөҒиҪ¬жҚўдёәеӯ—иҠӮжөҒпјҢе°Ҷеӯ—з¬ҰеҶҷеҮәеҲ°жҢҮе®ҡдҪҚзҪ®
еӯ—иҠӮжөҒдёҺеӯ—з¬ҰжөҒзҡ„иҪ¬жҚў
д»Һд»»дҪ•ең°ж–№жҠҠж•°жҚ®иҜ»е…ҘеҲ°еҶ…еӯҳйғҪжҳҜе…Ҳд»Ҙеӯ—иҠӮжөҒеҪўејҸиҜ»еҸ–пјҢеҚідҪҝжҳҜдҪҝз”Ёеӯ—з¬ҰжөҒеҺ»иҜ»еҸ–ж•°жҚ®пјҢдҫқ然жҲҗз«ӢпјҢеӣ дёәж•°жҚ®ж°ёиҝңжҳҜд»Ҙеӯ—иҠӮзҡ„еҪўејҸеӯҳеңЁдәҺдә’иҒ”зҪ‘е’Ң硬件и®ҫеӨҮдёӯпјҢеӯ—з¬ҰжөҒжҳҜйҖҡиҝҮеӯ—з¬ҰйӣҶзҡ„жҳ е°„пјҢжүҚиғҪеӨҹе°Ҷеӯ—иҠӮиҪ¬жҚўдёәеӯ—з¬ҰгҖӮ
жүҖд»Ҙ Java жҸҗдҫӣдәҶдёӨз§ҚиҪ¬жҚўжөҒпјҡ
InputStreamReaderпјҡд»Һеӯ—иҠӮжөҒиҪ¬жҚўдёәеӯ—з¬ҰжөҒпјҢе°Ҷеӯ—иҠӮж•°жҚ®иҪ¬жҚўдёәеӯ—з¬Ұж•°жҚ®иҜ»е…ҘеҲ°еҶ…еӯҳ
OutputStreamWriterпјҡд»Һеӯ—з¬ҰжөҒиҪ¬жҚўдёәеӯ—иҠӮжөҒпјҢе°Ҷеӯ—з¬Ұж•°жҚ®иҪ¬жҚўдёәеӯ—иҠӮж•°жҚ®еҶҷеҮәеҲ°жҢҮе®ҡдҪҚзҪ®
вҖң
дәҶи§ЈдәҶ Java дј з»ҹзҡ„ BIO дёӯеӯ—з¬ҰжөҒе’Ңеӯ—иҠӮжөҒзҡ„дё»иҰҒжҲҗе‘ҳд№ӢеҗҺпјҢиҮіе°‘иҰҒжҺҢжҸЎд»ҘдёӢдёӨдёӘе…ій”®зӮ№пјҡ
(1)дј з»ҹзҡ„ BIO жҳҜд»ҘжөҒдёәеҹәжң¬еҚ•дҪҚеӨ„зҗҶж•°жҚ®зҡ„пјҢжғіиұЎжҲҗж°ҙжөҒпјҢдёҖзӮ№зӮ№ең°дј иҫ“еӯ—иҠӮж•°жҚ®пјҢIO жөҒдј иҫ“зҡ„иҝҮзЁӢж°ёиҝңжҳҜд»Ҙеӯ—иҠӮеҪўејҸдј иҫ“гҖӮ
(2)еӯ—иҠӮжөҒе’Ңеӯ—з¬ҰжөҒзҡ„еҢәеҲ«еңЁдәҺж“ҚдҪңзҡ„ж•°жҚ®еҚ•дҪҚдёҚзӣёеҗҢпјҢеӯ—з¬ҰжөҒжҳҜйҖҡиҝҮе°Ҷеӯ—иҠӮж•°жҚ®йҖҡиҝҮеӯ—з¬ҰйӣҶжҳ е°„жҲҗеҜ№еә”зҡ„еӯ—з¬ҰпјҢеӯ—з¬ҰжөҒжң¬иҙЁдёҠд№ҹжҳҜеӯ—иҠӮжөҒгҖӮ
вҖқ
жҺҘдёӢжқҘжҲ‘们еҶҚ继з»ӯеӯҰд№ NIO зҹҘиҜҶпјҢNIO жҳҜеҪ“дёӢйқһеёёзҒ«зғӯзҡ„дёҖз§Қ IO е·ҘдҪңж–№ејҸпјҢе®ғиғҪеӨҹи§ЈеҶідј з»ҹ BIO зҡ„з—ӣзӮ№пјҡйҳ»еЎһгҖӮ
BIO еҰӮжһңйҒҮеҲ° IO йҳ»еЎһж—¶пјҢзәҝзЁӢе°Ҷдјҡиў«жҢӮиө·пјҢзӣҙеҲ° IO е®ҢжҲҗеҗҺжүҚе”ӨйҶ’зәҝзЁӢпјҢзәҝзЁӢеҲҮжҚўеёҰжқҘдәҶйўқеӨ–зҡ„ејҖй”ҖгҖӮ
BIO дёӯжҜҸдёӘ IO йғҪйңҖиҰҒжңүеҜ№еә”зҡ„дёҖдёӘзәҝзЁӢеҺ»дё“й—ЁеӨ„зҗҶиҜҘж¬Ў IO иҜ·жұӮпјҢдјҡи®©жңҚеҠЎеҷЁзҡ„еҺӢеҠӣиҝ…йҖҹжҸҗй«ҳгҖӮ
жҲ‘们еёҢжңӣеҒҡеҲ°зҡ„жҳҜеҪ“зәҝзЁӢзӯүеҫ… IO е®ҢжҲҗж—¶иғҪеӨҹеҺ»е®ҢжҲҗе…¶е®ғдәӢжғ…пјҢеҪ“ IO е®ҢжҲҗж—¶зәҝзЁӢеҸҜд»ҘеӣһжқҘ继з»ӯеӨ„зҗҶ IO зӣёе…іж“ҚдҪңпјҢдёҚеҝ…е№Іе№Ізҡ„еқҗзӯү IO е®ҢжҲҗгҖӮеңЁ IO еӨ„зҗҶзҡ„иҝҮзЁӢдёӯпјҢиғҪеӨҹжңүдёҖдёӘдё“й—Ёзҡ„зәҝзЁӢиҙҹиҙЈзӣ‘еҗ¬иҝҷдәӣ IO ж“ҚдҪңпјҢйҖҡзҹҘжңҚеҠЎеҷЁиҜҘеҰӮдҪ•ж“ҚдҪңгҖӮжүҖд»ҘпјҢжҲ‘们иҒҠеҲ° IOпјҢдёҚеҫ—дёҚеҺ»жҺҘи§Ұ NIO иҝҷдёҖеқ—зЎ¬йӘЁеӨҙгҖӮ
ж–°жҪ®зҡ„ NIO
жҲ‘们жқҘзңӢзңӢ BIO е’Ң NIO зҡ„еҢәеҲ«пјҢBIO жҳҜйқўеҗ‘жөҒзҡ„ IOпјҢе®ғе»әз«Ӣзҡ„йҖҡйҒ“йғҪжҳҜеҚ•еҗ‘зҡ„пјҢжүҖд»Ҙиҫ“е…Ҙе’Ңиҫ“еҮәжөҒзҡ„йҖҡйҒ“дёҚзӣёеҗҢпјҢеҝ…йЎ»е»әз«Ӣ2дёӘйҖҡйҒ“пјҢйҖҡйҒ“еҶ…зҡ„йғҪжҳҜдј иҫ“==0101001···==зҡ„еӯ—иҠӮж•°жҚ®гҖӮ
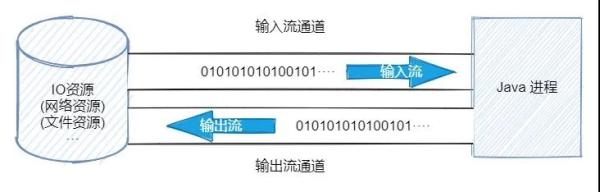
иҖҢеңЁ NIO дёӯпјҢдёҚеҶҚжҳҜйқўеҗ‘жөҒзҡ„ IO дәҶпјҢиҖҢжҳҜйқўеҗ‘зј“еҶІеҢәпјҢе®ғдјҡе»әз«ӢдёҖдёӘйҖҡйҒ“(Channel)пјҢиҜҘйҖҡйҒ“жҲ‘们еҸҜд»ҘзҗҶи§Јдёәй“Ғи·ҜпјҢиҜҘй“Ғи·ҜдёҠеҸҜд»Ҙиҝҗиҫ“еҗ„з§Қиҙ§зү©пјҢиҖҢйҖҡйҒ“дёҠдјҡжңүдёҖдёӘзј“еҶІеҢә(Buffer)з”ЁдәҺеӯҳеӮЁзңҹжӯЈзҡ„ж•°жҚ®пјҢзј“еҶІеҢәжҲ‘们еҸҜд»ҘзҗҶи§ЈдёәдёҖиҫҶзҒ«иҪҰгҖӮ
йҖҡйҒ“(й“Ғи·Ҝ)еҸӘжҳҜдҪңдёәиҝҗиҫ“ж•°жҚ®зҡ„дёҖдёӘиҝһжҺҘиө„жәҗпјҢиҖҢзңҹжӯЈеӯҳеӮЁж•°жҚ®зҡ„жҳҜзј“еҶІеҢә(зҒ«иҪҰ)гҖӮеҚійҖҡйҒ“иҙҹиҙЈдј иҫ“пјҢзј“еҶІеҢәиҙҹиҙЈеӯҳеӮЁгҖӮ
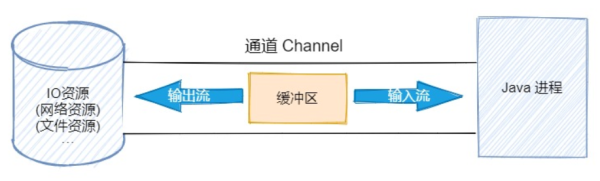
зҗҶи§ЈдәҶдёҠйқўзҡ„еӣҫд№ӢеҗҺпјҢBIO е’Ң NIO зҡ„дё»иҰҒеҢәеҲ«е°ұеҸҜд»Ҙз”ЁдёӢйқўиҝҷдёӘиЎЁж јз®ҖеҚ•жҰӮжӢ¬гҖӮ
| BIO | NIO |
|---|---|
| йқўеҗ‘жөҒпјҲStreamпјү | йқўеҗ‘зј“еҶІеҢәпјҲBufferпјү |
| еҚ•еҗ‘йҖҡйҒ“ | еҸҢеҗ‘йҖҡйҒ“ |
| йҳ»еЎһ IO | йқһйҳ»еЎһ IO |
| йҖүжӢ©еҷЁпјҲSelectorsпјү |
зј“еҶІеҢә(Buffer)
зј“еҶІеҢәжҳҜеӯҳеӮЁж•°жҚ®зҡ„еҢәеҹҹпјҢеңЁ Java дёӯпјҢзј“еҶІеҢәе°ұжҳҜж•°з»„пјҢдёәдәҶеҸҜд»Ҙж“ҚдҪңдёҚеҗҢж•°жҚ®зұ»еһӢзҡ„ж•°жҚ®пјҢJava жҸҗдҫӣдәҶи®ёеӨҡдёҚеҗҢзұ»еһӢзҡ„зј“еҶІеҢәпјҢйҷӨдәҶеёғе°”зұ»еһӢд»ҘеӨ–пјҢе…¶е®ғеҹәжң¬ж•°жҚ®зұ»еһӢйғҪжңүеҜ№еә”зҡ„зј“еҶІеҢәж•°з»„еҜ№иұЎгҖӮ
вҖңдёәд»Җд№ҲжІЎжңүеёғе°”зұ»еһӢзҡ„зј“еҶІеҢәе‘ў?
еңЁ Java дёӯпјҢboolean зұ»еһӢж•°жҚ®еҸӘеҚ з”Ё 1 bitпјҢиҖҢеңЁ IO дј иҫ“иҝҮзЁӢдёӯпјҢйғҪжҳҜд»Ҙеӯ—иҠӮдёәеҚ•дҪҚиҝӣиЎҢдј иҫ“зҡ„пјҢжүҖд»Ҙ boolean зҡ„ 1 bit е®Ңе…ЁеҸҜд»ҘдҪҝз”Ё byte зұ»еһӢзҡ„жҹҗдёҖдҪҚпјҢжҲ–иҖ… int зұ»еһӢзҡ„жҹҗдёҖдҪҚжқҘиЎЁзӨәпјҢжІЎжңүеҝ…иҰҒдёәдәҶиҝҷ 1 bit иҖҢдё“й—ЁжҸҗдҫӣеӨҡдёҖдёӘзј“еҶІеҢәгҖӮвҖқ
| зј“еҶІеҢә | и§ЈйҮҠ |
|---|---|
| ByteBuffer | еӯҳеӮЁеӯ—иҠӮж•°жҚ®зҡ„зј“еҶІеҢә |
| CharBuffer | еӯҳеӮЁеӯ—з¬Ұж•°жҚ®зҡ„зј“еҶІеҢә |
| ShortBuffer | еӯҳеӮЁзҹӯж•ҙеһӢж•°жҚ®зҡ„зј“еҶІеҢә |
| IntBuffer | еӯҳеӮЁж•ҙеһӢж•°жҚ®зҡ„зј“еҶІеҢә |
| LongBuffer | еӯҳеӮЁй•ҝж•ҙеһӢж•°жҚ®зҡ„зј“еҶІеҢә |
| FloatBuffer | еӯҳеӮЁеҚ•зІҫеәҰжө®зӮ№еһӢж•°жҚ®зҡ„зј“еҶІеҢә |
| DoubleBuffer | еӯҳеӮЁеҸҢзІҫеәҰжө®зӮ№еһӢж•°жҚ®зҡ„зј“еҶІеҢә |
еҲҶй…ҚдёҖдёӘзј“еҶІеҢәзҡ„ж–№ејҸйғҪй«ҳеәҰдёҖиҮҙпјҡдҪҝз”Ёallocate(int capacity)ж–№жі•гҖӮ
дҫӢеҰӮйңҖиҰҒеҲҶй…ҚдёҖдёӘ 1024 еӨ§е°Ҹзҡ„еӯ—иҠӮж•°з»„пјҢд»Јз Ғе°ұжҳҜдёӢйқўиҝҷж ·еӯҗгҖӮ
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
зј“еҶІеҢәиҜ»еҶҷж•°жҚ®зҡ„дёӨдёӘж ёеҝғж–№жі•пјҡ
put()пјҡе°Ҷж•°жҚ®еҶҷе…ҘеҲ°зј“еҶІеҢәдёӯ
get()пјҡд»Һзј“еҶІеҢәдёӯиҜ»еҸ–ж•°жҚ®
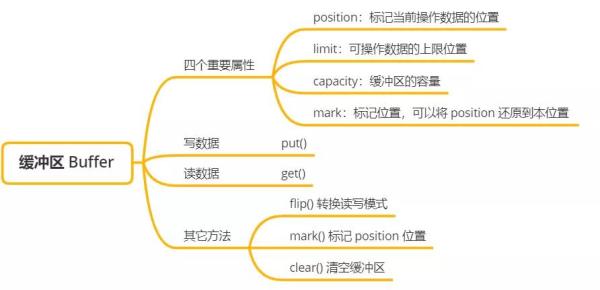
зј“еҶІеҢәзҡ„йҮҚиҰҒеұһжҖ§пјҡ
capacityпјҡзј“еҶІеҢәдёӯжңҖеӨ§еӯҳеӮЁж•°жҚ®зҡ„е®№йҮҸпјҢдёҖж—ҰеЈ°жҳҺеҲҷж— жі•ж”№еҸҳ
limitпјҡиЎЁзӨәзј“еҶІеҢәдёӯеҸҜд»Ҙж“ҚдҪңж•°жҚ®зҡ„еӨ§е°ҸпјҢlimit д№ӢеҗҺзҡ„ж•°жҚ®ж— жі•иҝӣиЎҢиҜ»еҶҷгҖӮеҝ…йЎ»ж»Ўи¶і limit <= capacity
positionпјҡеҪ“еүҚзј“еҶІеҢәдёӯжӯЈеңЁж“ҚдҪңж•°жҚ®зҡ„дёӢж ҮдҪҚзҪ®пјҢеҝ…йЎ»ж»Ўи¶і position <= limit
markпјҡж Үи®°дҪҚзҪ®пјҢи°ғз”Ё reset() е°Ҷ position дҪҚзҪ®и°ғж•ҙеҲ° mark еұһжҖ§жҢҮеҗ‘зҡ„дёӢж ҮдҪҚзҪ®пјҢе®һзҺ°еӨҡж¬ЎиҜ»еҸ–ж•°жҚ®
зј“еҶІеҢәдёәй«ҳж•ҲиҜ»еҶҷж•°жҚ®иҖҢжҸҗдҫӣзҡ„е…¶е®ғиҫ…еҠ©ж–№жі•пјҡ
flip()пјҡеҸҜд»Ҙе®һзҺ°иҜ»еҶҷжЁЎејҸзҡ„еҲҮжҚўпјҢжҲ‘们еҸҜд»ҘзңӢзңӢйҮҢйқўзҡ„жәҗз Ғ
public final Buffer flip() { limit = position; position = 0; mark = -1; return this; }и°ғз”Ё flip() дјҡе°ҶеҸҜж“ҚдҪңзҡ„еӨ§е°Ҹ limit и®ҫзҪ®дёәеҪ“еүҚеҶҷзҡ„дҪҚзҪ®пјҢж“ҚдҪңж•°жҚ®зҡ„иө·е§ӢдҪҚзҪ® position и®ҫзҪ®дёә 0пјҢеҚід»ҺеӨҙејҖе§ӢиҜ»еҸ–ж•°жҚ®гҖӮ
rewind()пјҡеҸҜд»Ҙе°Ҷ position дҪҚзҪ®и®ҫзҪ®дёә 0пјҢеҶҚж¬ЎиҜ»еҸ–зј“еҶІеҢәдёӯзҡ„ж•°жҚ®
clear()пјҡжё…з©әж•ҙдёӘзј“еҶІеҢәпјҢе®ғдјҡе°Ҷ position и®ҫзҪ®дёә 0пјҢlimit и®ҫзҪ®дёә capacityпјҢеҸҜд»ҘеҶҷж•ҙдёӘзј“еҶІеҢә
вҖңжӣҙеӨҡзҡ„ж–№жі•еҸҜд»ҘеҺ»жҹҘйҳ… API ж–ҮжЎЈпјҢжң¬ж–ҮзўҚдәҺзҜҮе№…еҺҹеӣ е°ұдёҚиҙҙеҮәе…¶е®ғж–№жі•дәҶпјҢдё»иҰҒжҳҜиҰҒзҗҶи§Јзј“еҶІеҢәзҡ„дҪңз”ЁвҖқ
жҲ‘们жқҘзңӢдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗ
public Class Main { public static void main(String[] args) { // еҲҶй…ҚеҶ…еӯҳеӨ§е°Ҹдёә11зҡ„ж•ҙеһӢзј“еӯҳеҢә IntBuffer buffer = IntBuffer.allocate(11); // еҫҖbufferйҮҢеҶҷе…Ҙ2дёӘж•ҙеһӢж•°жҚ® for (int i = 0; i < 2; ++i) { int randomNum = new SecureRandom().nextInt(); buffer.put(randomNum); } // е°ҶBufferд»ҺеҶҷжЁЎејҸеҲҮжҚўеҲ°иҜ»жЁЎејҸ buffer.flip(); System.out.println("position >> " + buffer.position() + "limit >> " + buffer.limit() + "capacity >> " + buffer.capacity()); // иҜ»еҸ–bufferйҮҢзҡ„ж•°жҚ® while (buffer.hasRemaining()) { System.out.println(buffer.get()); } System.out.println("position >> " + buffer.position() + "limit >> " + buffer.limit() + "capacity >> " + buffer.capacity()); } }жү§иЎҢз»“жһңеҰӮдёӢеӣҫжүҖзӨәпјҢйҰ–е…ҲжҲ‘们еҫҖзј“еҶІеҢәдёӯеҶҷе…Ҙ 2 дёӘж•°жҚ®пјҢposition еңЁеҶҷжЁЎејҸдёӢжҢҮеҗ‘дёӢж Ү 2пјҢ然еҗҺи°ғз”Ё flip() ж–№жі•еҲҮжҚўдёәиҜ»жЁЎејҸпјҢlimit жҢҮеҗ‘дёӢж Ү 2пјҢposition д»Һ 0 ејҖе§ӢиҜ»ж•°жҚ®пјҢиҜ»еҲ°дёӢж Үдёә 2 ж—¶еҸ‘зҺ°еҲ°иҫҫ limit дҪҚзҪ®пјҢдёҚеҸҜ继з»ӯиҜ»гҖӮ
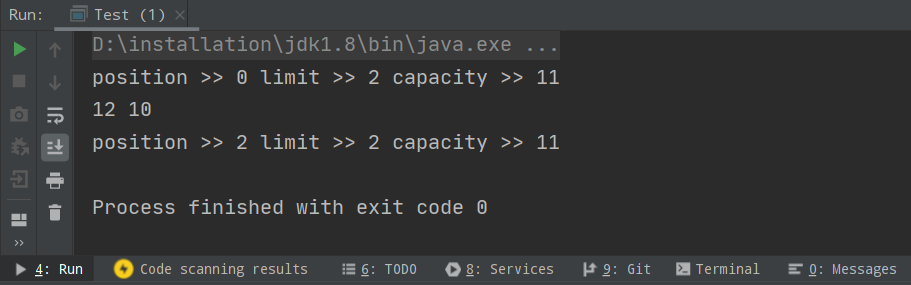
ж•ҙдёӘиҝҮзЁӢеҸҜд»Ҙз”ЁдёӢеӣҫжқҘзҗҶи§ЈпјҢи°ғз”Ё flip() ж–№жі•д»ҘеҗҺпјҢиҜ»еҮәж•°жҚ®зҡ„еҗҢж—¶ position жҢҮй’ҲдёҚж–ӯеҫҖеҗҺжҢӘеҠЁпјҢеҲ°иҫҫ limit жҢҮй’Ҳзҡ„дҪҚзҪ®ж—¶пјҢиҜҘж¬ЎиҜ»еҸ–ж“ҚдҪңз»“жқҹгҖӮ
вҖңд»Ӣз»Қе®Ңзј“еҶІеҢәеҗҺпјҢжҲ‘们зҹҘйҒ“е®ғжҳҜеӯҳеӮЁж•°жҚ®зҡ„з©әй—ҙпјҢиҝӣзЁӢеҸҜд»Ҙе°Ҷзј“еҶІеҢәдёӯзҡ„ж•°жҚ®иҜ»еҸ–еҮәжқҘпјҢд№ҹеҸҜд»ҘеҶҷе…Ҙж–°зҡ„ж•°жҚ®еҲ°зј“еҶІеҢәпјҢйӮЈзј“еҶІеҢәзҡ„ж•°жҚ®д»Һе“ӘйҮҢжқҘпјҢеҸҲжҖҺд№ҲеҶҷеҮәеҺ»е‘ў?жҺҘдёӢжқҘжҲ‘们йңҖиҰҒеӯҰд№ дј иҫ“ж•°жҚ®зҡ„д»ӢиҙЁпјҡйҖҡйҒ“(Channel)вҖқ
йҖҡйҒ“(Channel)
дёҠйқўжҲ‘们д»Ӣз»ҚиҝҮпјҢйҖҡйҒ“жҳҜдҪңдёәдёҖз§ҚиҝһжҺҘиө„жәҗпјҢдҪңз”ЁжҳҜдј иҫ“ж•°жҚ®пјҢиҖҢзңҹжӯЈеӯҳеӮЁж•°жҚ®зҡ„жҳҜзј“еҶІеҢәпјҢжүҖд»Ҙд»Ӣз»Қе®Ңзј“еҶІеҢәеҗҺпјҢжҲ‘们жқҘеӯҰд№ йҖҡйҒ“иҝҷдёҖеқ—гҖӮ
йҖҡйҒ“жҳҜеҸҜд»ҘеҸҢеҗ‘иҜ»еҶҷзҡ„пјҢдј з»ҹзҡ„ BIO йңҖиҰҒдҪҝз”Ёиҫ“е…Ҙ/иҫ“еҮәжөҒиЎЁзӨәж•°жҚ®зҡ„жөҒеҗ‘пјҢеңЁ NIO дёӯеҸҜд»ҘеҮҸе°‘йҖҡйҒ“иө„жәҗзҡ„ж¶ҲиҖ—гҖӮ
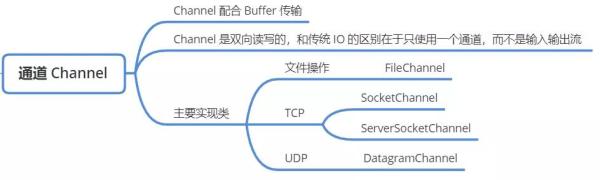
йҖҡйҒ“зұ»йғҪдҝқеӯҳеңЁ java.nio.channels еҢ…дёӢпјҢжҲ‘们ж—Ҙеёёз”ЁеҲ°зҡ„еҮ дёӘйҮҚиҰҒзҡ„зұ»жңү 4 дёӘпјҡ
| IO йҖҡйҒ“зұ»еһӢ | е…·дҪ“зұ» |
|---|---|
| ж–Ү件 IO | FileChannelпјҲз”ЁдәҺж–Ү件иҜ»еҶҷгҖҒж“ҚдҪңж–Ү件зҡ„йҖҡйҒ“пјү |
| TCP зҪ‘з»ң IO | SocketChannelпјҲз”ЁдәҺиҜ»еҶҷж•°жҚ®зҡ„ TCP йҖҡйҒ“пјүгҖҒServerSocketChannelпјҲзӣ‘еҗ¬е®ўжҲ·з«Ҝзҡ„иҝһжҺҘпјү |
| UDP зҪ‘з»ң IO | DatagramChannelпјҲ收еҸ‘ UDP ж•°жҚ®жҠҘзҡ„йҖҡйҒ“пјү |
еҸҜд»ҘйҖҡиҝҮ getChannel() ж–№жі•иҺ·еҸ–дёҖдёӘйҖҡйҒ“пјҢж”ҜжҢҒиҺ·еҸ–йҖҡйҒ“зҡ„зұ»еҰӮдёӢпјҡ
ж–Ү件 IOпјҡFileInputStreamгҖҒFileOutputStreamгҖҒRandomAccessFile
TCP зҪ‘з»ң IOпјҡSocketгҖҒServerSocket
UDP зҪ‘з»ң IOпјҡDatagramSocket
зӨәдҫӢпјҡж–Ү件жӢ·иҙқжЎҲдҫӢ
жҲ‘们жқҘзңӢдёҖдёӘеҲ©з”ЁйҖҡйҒ“жӢ·иҙқж–Ү件зҡ„дҫӢеӯҗпјҢйңҖиҰҒдёӢйқўеҮ дёӘжӯҘйӘӨпјҡ
жү“ејҖеҺҹж–Ү件зҡ„иҫ“е…ҘжөҒйҖҡйҒ“пјҢе°Ҷеӯ—иҠӮж•°жҚ®иҜ»е…ҘеҲ°зј“еҶІеҢәдёӯ
жү“ејҖзӣ®зҡ„ж–Ү件зҡ„иҫ“еҮәжөҒйҖҡйҒ“пјҢе°Ҷзј“еҶІеҢәдёӯзҡ„ж•°жҚ®еҶҷеҲ°зӣ®зҡ„ең°
е…ій—ӯжүҖжңүжөҒе’ҢйҖҡйҒ“(йҮҚиҰҒ!)
иҝҷжҳҜдёҖеј е°ҸиҸ иҗқзҡ„з…§зүҮпјҢе®ғеӯҳеңЁдәҺd:\е°ҸиҸ иҗқ\ж–Ү件еӨ№дёӢпјҢжҲ‘们е°Ҷе®ғжӢ·иҙқеҲ° d:\е°ҸиҸ иҗқеҲҶиә«\ж–Ү件еӨ№дёӢгҖӮ

public class Test { /** зј“еҶІеҢәзҡ„еӨ§е°Ҹ */ public static final int SIZE = 1024; public static void main(String[] args) throws IOException { // жү“ејҖж–Ү件иҫ“е…ҘжөҒ FileChannel inChannel = new FileInputStream("d:\е°ҸиҸ иҗқ\е°ҸиҸ иҗқ.jpg").getChannel(); // жү“ејҖж–Ү件иҫ“еҮәжөҒ FileChannel outChannel = new FileOutputStream("d:\е°ҸиҸ иҗқеҲҶиә«\е°ҸиҸ иҗқ-жӢ·иҙқ.jpg").getChannel(); // еҲҶй…Қ 1024 дёӘеӯ—иҠӮеӨ§е°Ҹзҡ„зј“еҶІеҢә ByteBuffer dsts = ByteBuffer.allocate(SIZE); // е°Ҷж•°жҚ®д»ҺйҖҡйҒ“иҜ»е…Ҙзј“еҶІеҢә while (inChannel.read(dsts) != -1) { // еҲҮжҚўзј“еҶІеҢәзҡ„иҜ»еҶҷжЁЎејҸ dsts.flip(); // е°Ҷзј“еҶІеҢәзҡ„ж•°жҚ®йҖҡиҝҮйҖҡйҒ“еҶҷеҲ°зӣ®зҡ„ең° outChannel.write(dsts); // жё…з©әзј“еҶІеҢәпјҢеҮҶеӨҮдёӢдёҖж¬ЎиҜ» dsts.clear(); } inChannel.close(); outChannel.close(); } }жҲ‘з”»дәҶдёҖеј еӣҫеё®еҠ©дҪ зҗҶи§ЈдёҠйқўзҡ„иҝҷдёҖдёӘиҝҮзЁӢгҖӮ
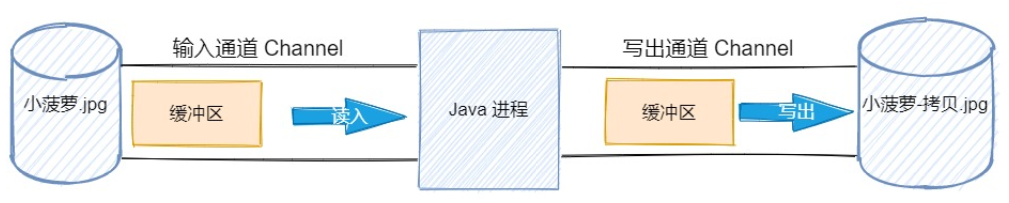
вҖңжңүдәәдјҡй—®пјҢNIO зҡ„ж–Ү件жӢ·иҙқе’Ңдј з»ҹ IO жөҒзҡ„ж–Ү件жӢ·иҙқжңүдҪ•дёҚеҗҢе‘ў?жҲ‘们еңЁзј–зЁӢж—¶ж„ҹи§үе®ғ们没жңүд»Җд№ҲеҢәеҲ«е‘ҖпјҢиІҢдјјеҸӘжҳҜ API дёҚеҗҢзҪўдәҶпјҢжҲ‘们жҺҘдёӢжқҘе°ұеҺ»зңӢзңӢиҝҷдёӨиҖ…д№Ӣй—ҙзҡ„еҢәеҲ«еҗ§гҖӮвҖқ
BIO е’Ң NIO жӢ·иҙқж–Ү件зҡ„еҢәеҲ«
иҝҷдёӘж—¶еҖҷе°ұиҰҒжқҘдәҶи§ЈдәҶи§Јж“ҚдҪңзі»з»ҹеә•еұӮжҳҜжҖҺд№ҲеҜ№ IO е’Ң NIO иҝӣиЎҢеҢәеҲ«зҡ„пјҢжҲ‘дјҡз”Ёе°ҪйҮҸйҖҡдҝ—зҡ„ж–Үеӯ—еёҰдҪ зҗҶи§ЈпјҢеҸҜиғҪ并дёҚжҳҜйӮЈд№ҲдёҘи°ЁгҖӮ
ж“ҚдҪңзі»з»ҹжңҖйҮҚиҰҒзҡ„е°ұжҳҜеҶ…ж ёпјҢе®ғж—ўеҸҜд»Ҙи®ҝй—®еҸ—дҝқжҠӨзҡ„еҶ…еӯҳпјҢд№ҹеҸҜд»Ҙи®ҝй—®еә•еұӮ硬件и®ҫеӨҮпјҢжүҖд»ҘдёәдәҶдҝқжҠӨеҶ…ж ёзҡ„е®үе…ЁпјҢж“ҚдҪңзі»з»ҹе°Ҷеә•еұӮзҡ„иҷҡжӢҹз©әй—ҙеҲҶдёәдәҶз”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙпјҢе…¶дёӯз”ЁжҲ·з©әй—ҙе°ұжҳҜз»ҷз”ЁжҲ·иҝӣзЁӢдҪҝз”Ёзҡ„пјҢеҶ…ж ёз©әй—ҙе°ұжҳҜдё“й—Ёз»ҷж“ҚдҪңзі»з»ҹеә•еұӮеҺ»дҪҝз”Ёзҡ„гҖӮ
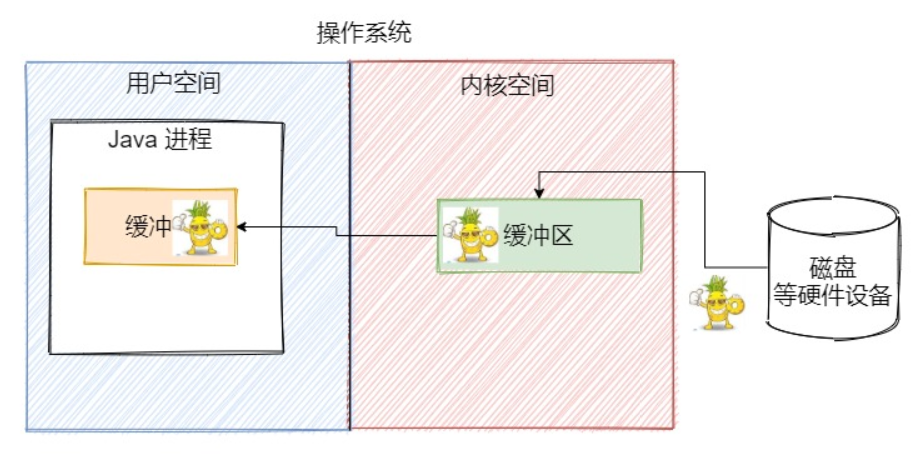
жҺҘдёӢжқҘпјҢжңүдёҖдёӘ Java иҝӣзЁӢеёҢжңӣжҠҠе°ҸиҸ иҗқиҝҷеј еӣҫзүҮд»ҺзЈҒзӣҳдёҠжӢ·иҙқпјҢйӮЈд№ҲеҶ…ж ёз©әй—ҙе’Ңз”ЁжҲ·з©әй—ҙйғҪдјҡжңүдёҖдёӘзј“еҶІеҢә
иҝҷеј з…§зүҮе°ұдјҡд»ҺзЈҒзӣҳдёӯиҜ»еҮәеҲ°еҶ…ж ёзј“еҶІеҢәдёӯдҝқеӯҳпјҢ然еҗҺж“ҚдҪңзі»з»ҹе°ҶеҶ…ж ёзј“еҶІеҢәдёӯзҡ„иҝҷеј еӣҫзүҮеӯ—иҠӮж•°жҚ®жӢ·иҙқеҲ°з”ЁжҲ·иҝӣзЁӢзҡ„зј“еҶІеҢәдёӯдҝқеӯҳдёӢжқҘпјҢеҜ№еә”зқҖдёӢйқўиҝҷе№…еӣҫ
然еҗҺз”ЁжҲ·иҝӣзЁӢдјҡеёҢжңӣжҠҠзј“еҶІеҢәдёӯзҡ„еӯ—иҠӮж•°жҚ®еҶҷеҲ°зЈҒзӣҳдёҠзҡ„еҸҰеӨ–дёҖдёӘең°ж–№пјҢдјҡе°Ҷж•°жҚ®жӢ·иҙқеҲ° Socket зј“еҶІеҢәдёӯпјҢжңҖз»Ҳж“ҚдҪңзі»з»ҹеҶҚе°Ҷ Socket зј“еҶІеҢәзҡ„ж•°жҚ®еҶҷеҲ°зЈҒзӣҳзҡ„жҢҮе®ҡдҪҚзҪ®дёҠгҖӮ
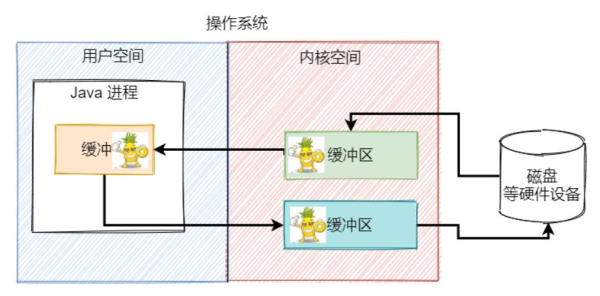
иҝҷдёҖиҪ®ж“ҚдҪңдёӢжқҘпјҢжҲ‘们数数з»ҸиҝҮдәҶеҮ ж¬Ўж•°жҚ®зҡ„жӢ·иҙқ?4 ж¬ЎгҖӮжңү 2 ж¬ЎжҳҜеҶ…ж ёз©әй—ҙе’Ңз”ЁжҲ·з©әй—ҙд№Ӣй—ҙзҡ„ж•°жҚ®жӢ·иҙқпјҢиҝҷдёӨж¬ЎжӢ·иҙқж¶үеҸҠеҲ°з”ЁжҲ·жҖҒе’ҢеҶ…ж ёжҖҒзҡ„еҲҮжҚўпјҢйңҖиҰҒCPUеҸӮдёҺиҝӣжқҘпјҢиҝӣиЎҢдёҠдёӢж–ҮеҲҮжҚўгҖӮиҖҢеҸҰеӨ– 2 ж¬ЎжҳҜзЎ¬зӣҳе’ҢеҶ…ж ёз©әй—ҙд№Ӣй—ҙзҡ„ж•°жҚ®жӢ·иҙқпјҢиҝҷдёӘиҝҮзЁӢеҲ©з”ЁеҲ° DMAдёҺзі»з»ҹеҶ…еӯҳдәӨжҚўж•°жҚ®пјҢдёҚйңҖиҰҒ CPU зҡ„еҸӮдёҺгҖӮ
еҜјиҮҙ IO жҖ§иғҪ瓶йўҲзҡ„еҺҹеӣ пјҡеҶ…ж ёз©әй—ҙдёҺз”ЁжҲ·з©әй—ҙд№Ӣй—ҙж•°жҚ®иҝҮеӨҡж— ж„Ҹд№үзҡ„жӢ·иҙқпјҢд»ҘеҸҠеӨҡж¬ЎдёҠдёӢж–ҮеҲҮжҚў
| ж“ҚдҪң | зҠ¶жҖҒ |
|---|---|
| з”ЁжҲ·иҝӣзЁӢиҜ·жұӮиҜ»еҸ–ж•°жҚ® | з”ЁжҲ·жҖҒ -> еҶ…ж ёжҖҒ |
| ж“ҚдҪңзі»з»ҹеҶ…ж ёиҝ”еӣһж•°жҚ®з»ҷз”ЁжҲ·иҝӣзЁӢ | еҶ…ж ёжҖҒ -> з”ЁжҲ·жҖҒ |
| з”ЁжҲ·иҝӣзЁӢиҜ·жұӮеҶҷж•°жҚ®еҲ°зЎ¬зӣҳ | з”ЁжҲ·жҖҒ -> еҶ…ж ёжҖҒ |
| ж“ҚдҪңзі»з»ҹиҝ”еӣһж“ҚдҪңз»“жһңз»ҷз”ЁжҲ·иҝӣзЁӢ | еҶ…ж ёжҖҒ -> з”ЁжҲ·жҖҒ |
вҖңеңЁз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙд№Ӣй—ҙзҡ„ж“ҚдҪңпјҢдјҡж¶үеҸҠеҲ°дёҠдёӢж–Үзҡ„еҲҮжҚўпјҢиҝҷйҮҢйңҖиҰҒ CPU зҡ„е№Ійў„пјҢиҖҢж•°жҚ®еңЁдёӨдёӘз©әй—ҙд№Ӣй—ҙжқҘеӣһжӢ·иҙқпјҢд№ҹйңҖиҰҒ CPU зҡ„е№Ійў„пјҢиҝҷж— з–‘дјҡеўһеӨ§ CPU зҡ„еҺӢеҠӣпјҢNIO жҳҜеҰӮдҪ•еҮҸиҪ» CPU зҡ„еҺӢеҠӣ?иҝҗз”Ёж“ҚдҪңзі»з»ҹзҡ„йӣ¶жӢ·иҙқжҠҖжңҜгҖӮвҖқ
ж“ҚдҪңзі»з»ҹзҡ„йӣ¶жӢ·иҙқ
жүҖд»ҘпјҢж“ҚдҪңзі»з»ҹеҮәзҺ°дәҶдёҖдёӘе…Ёж–°зҡ„жҰӮеҝөпјҢи§ЈеҶідәҶ IO 瓶йўҲпјҡйӣ¶жӢ·иҙқгҖӮйӣ¶жӢ·иҙқжҢҮзҡ„жҳҜеҶ…ж ёз©әй—ҙдёҺз”ЁжҲ·з©әй—ҙд№Ӣй—ҙзҡ„йӣ¶ж¬ЎжӢ·иҙқгҖӮ
йӣ¶жӢ·иҙқеҸҜд»ҘиҜҙжҳҜ IO зҡ„дёҖеӨ§ж•‘жҳҹпјҢж“ҚдҪңзі»з»ҹеә•еұӮжңүи®ёеӨҡз§Қйӣ¶жӢ·иҙқжңәеҲ¶пјҢжҲ‘иҝҷйҮҢд»…й’ҲеҜ№ Java NIO дёӯдҪҝз”ЁеҲ°зҡ„е…¶дёӯдёҖз§Қйӣ¶жӢ·иҙқжңәеҲ¶еұ•ејҖи®Іи§ЈгҖӮ
еңЁ Java NIO дёӯпјҢйӣ¶жӢ·иҙқжҳҜйҖҡиҝҮз”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙзҡ„зј“еҶІеҢәе…ұдә«дёҖеқ—зү©зҗҶеҶ…еӯҳе®һзҺ°зҡ„пјҢд№ҹе°ұжҳҜиҜҙдёҠйқўзҡ„еӣҫеҸҜд»Ҙжј”еҸҳжҲҗиҝҷдёӘж ·еӯҗгҖӮ
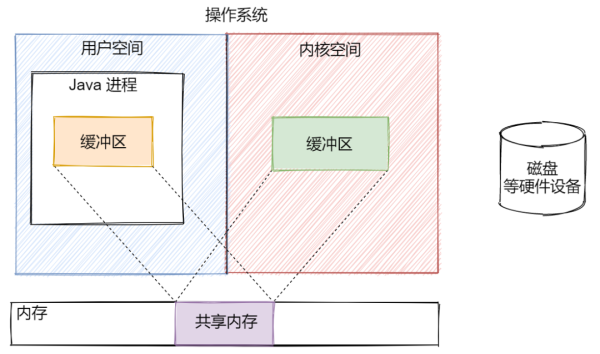
иҝҷж—¶пјҢж— и®әжҳҜз”ЁжҲ·з©әй—ҙиҝҳжҳҜеҶ…ж ёз©әй—ҙж“ҚдҪңиҮӘе·ұзҡ„зј“еҶІеҢәпјҢжң¬иҙЁдёҠйғҪжҳҜж“ҚдҪңиҝҷдёҖеқ—е…ұдә«еҶ…еӯҳдёӯзҡ„зј“еҶІеҢәж•°жҚ®пјҢзңҒеҺ»дәҶз”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙд№Ӣй—ҙзҡ„ж•°жҚ®жӢ·иҙқж“ҚдҪңгҖӮ
зҺ°еңЁжҲ‘们йҮҚж–°жқҘжӢ·иҙқж–Ү件пјҢе°ұдјҡеҸҳжҲҗдёӢйқўиҝҷдёӘжӯҘйӘӨпјҡ
з”ЁжҲ·иҝӣзЁӢйҖҡиҝҮзі»з»ҹи°ғз”Ё read() иҜ·жұӮиҜ»еҸ–ж–Ү件еҲ°з”ЁжҲ·з©әй—ҙзј“еҶІеҢә(第дёҖж¬ЎдёҠдёӢж–ҮеҲҮжҚў)пјҢз”ЁжҲ·жҖҒ -> ж ёеҝғжҖҒпјҢж•°жҚ®д»ҺзЎ¬зӣҳиҜ»еҸ–еҲ°еҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯ(第дёҖж¬Ўж•°жҚ®жӢ·иҙқ)
зі»з»ҹи°ғз”Ёиҝ”еӣһеҲ°з”ЁжҲ·иҝӣзЁӢ(第дәҢж¬ЎдёҠдёӢж–ҮеҲҮжҚў)пјҢжӯӨж—¶з”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙе…ұдә«иҝҷдёҖеқ—еҶ…еӯҳ(зј“еҶІеҢә)пјҢжүҖд»ҘдёҚйңҖиҰҒд»ҺеҶ…ж ёзј“еҶІеҢәжӢ·иҙқеҲ°з”ЁжҲ·зј“еҶІеҢә
з”ЁжҲ·иҝӣзЁӢеҸ‘еҮә write() зі»з»ҹи°ғз”ЁиҜ·жұӮеҶҷж•°жҚ®еҲ°зЎ¬зӣҳдёҠ(第дёүж¬ЎдёҠдёӢж–ҮеҲҮжҚў)пјҢжӯӨж—¶йңҖиҰҒе°ҶеҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯзҡ„ж•°жҚ®жӢ·иҙқеҲ°еҶ…ж ёзҡ„ Socket зј“еҶІеҢәдёӯ(第дәҢж¬Ўж•°жҚ®жӢ·иҙқ)
з”ұ DMA е°Ҷ Socket зј“еҶІеҢәзҡ„еҶ…е®№еҶҷеҲ°зЎ¬зӣҳдёҠ(第дёүж¬Ўж•°жҚ®жӢ·иҙқ)пјҢwrite() зі»з»ҹи°ғз”Ёиҝ”еӣһ(第еӣӣж¬ЎдёҠдёӢж–ҮеҲҮжҚў)
ж•ҙдёӘиҝҮзЁӢе°ұеҰӮдёӢйқўиҝҷе№…еӣҫжүҖзӨәгҖӮ
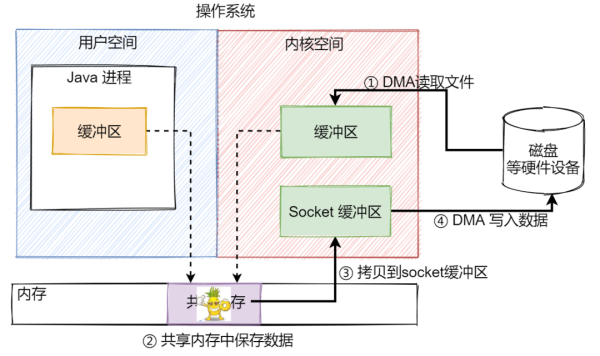
еӣҫдёӯпјҢйңҖиҰҒ CPU еҸӮдёҺе·ҘдҪңзҡ„жӯҘйӘӨеҸӘжңү第③дёӘжӯҘйӘӨпјҢеҜ№жҜ”дәҺдј з»ҹзҡ„ IOпјҢCPU йңҖиҰҒеңЁз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙд№Ӣй—ҙеҸӮдёҺжӢ·иҙқе·ҘдҪңпјҢйңҖиҰҒж— ж„Ҹд№үең°еҚ з”Ё 2 ж¬Ў CPU иө„жәҗпјҢеҜјиҮҙ CPU иө„жәҗзҡ„жөӘиҙ№гҖӮ
дёӢйқўжҖ»з»“дёҖдёӢж“ҚдҪңзі»з»ҹдёӯйӣ¶жӢ·иҙқзҡ„дјҳзӮ№пјҡ
йҷҚдҪҺ CPU зҡ„еҺӢеҠӣпјҡйҒҝе…Қ CPU йңҖиҰҒеҸӮдёҺеҶ…ж ёз©әй—ҙдёҺз”ЁжҲ·з©әй—ҙд№Ӣй—ҙзҡ„ж•°жҚ®жӢ·иҙқе·ҘдҪң
еҮҸе°‘дёҚеҝ…иҰҒзҡ„жӢ·иҙқпјҡйҒҝе…Қз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙд№Ӣй—ҙйңҖиҰҒиҝӣиЎҢж•°жҚ®жӢ·иҙқ
дёҠйқўзҡ„еӣҫзӨәеҸҜиғҪ并дёҚдёҘи°ЁпјҢеҜ№дәҺдҪ зҗҶи§Јйӣ¶жӢ·иҙқдјҡжңүдёҖе®ҡзҡ„её®еҠ©пјҢе…ідәҺйӣ¶жӢ·иҙқзҡ„зҹҘиҜҶзӮ№еҸҜд»ҘеҺ»жҹҘйҳ…жӣҙеӨҡиө„ж–ҷе“ҰпјҢиҝҷжҳҜдёҖй—ЁеӨ§еӯҰй—®гҖӮ
вҖңд»Ӣз»Қе®ҢйҖҡйҒ“еҗҺпјҢжҲ‘们зҹҘйҒ“е®ғжҳҜз”ЁдәҺдј иҫ“ж•°жҚ®зҡ„дёҖз§Қд»ӢиҙЁпјҢиҖҢдё”жҳҜеҸҜд»ҘеҸҢеҗ‘иҜ»еҶҷзҡ„пјҢйӮЈд№ҲеҰӮжһңж”ҫеңЁзҪ‘з»ң IO дёӯпјҢиҝҷдәӣйҖҡйҒ“еҰӮжһңжңүж•°жҚ®е°ұз»Әж—¶пјҢжңҚеҠЎеҷЁжҳҜеҰӮдҪ•еҸ‘зҺ°е№¶еӨ„зҗҶзҡ„е‘ў?жҺҘдёӢжқҘжҲ‘们еҺ»еӯҰд№ NIO дёӯзҡ„жңҖеҗҺдёҖдёӘйҮҚиҰҒзҹҘиҜҶзӮ№пјҡйҖүжӢ©еҷЁ(Selector)вҖқ
йҖүжӢ©еҷЁ(Selectors)
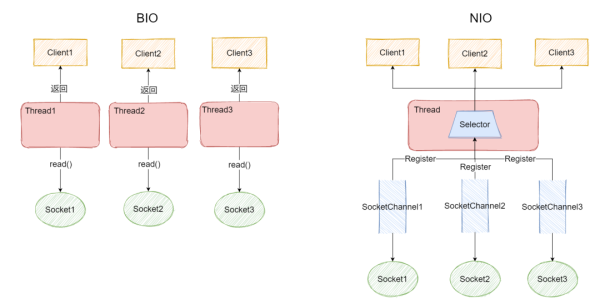
йҖүжӢ©еҷЁжҳҜжҸҗеҚҮ IO жҖ§иғҪзҡ„зҒөйӯӮд№ӢдёҖпјҢе®ғеә•еұӮеҲ©з”ЁдәҶеӨҡи·ҜеӨҚз”Ё IOжңәеҲ¶пјҢи®©йҖүжӢ©еҷЁеҸҜд»Ҙзӣ‘еҗ¬еӨҡдёӘ IO иҝһжҺҘпјҢж №жҚ® IO зҡ„зҠ¶жҖҒе“Қеә”еҲ°жңҚеҠЎеҷЁз«ҜиҝӣиЎҢеӨ„зҗҶгҖӮйҖҡдҝ—ең°иҜҙпјҡйҖүжӢ©еҷЁеҸҜд»Ҙзӣ‘еҗ¬еӨҡдёӘ IO иҝһжҺҘпјҢиҖҢдј з»ҹзҡ„ BIO жҜҸдёӘ IO иҝһжҺҘйғҪйңҖиҰҒжңүдёҖдёӘзәҝзЁӢеҺ»зӣ‘еҗ¬е’ҢеӨ„зҗҶгҖӮ

еӣҫдёӯеҫҲжҳҺжҳҫзҡ„жҳҫзӨәдәҶеңЁ BIO дёӯпјҢжҜҸдёӘ Socket йғҪйңҖиҰҒжңүдёҖдёӘдё“й—Ёзҡ„зәҝзЁӢеҺ»еӨ„зҗҶжҜҸдёӘиҜ·жұӮпјҢиҖҢеңЁ NIO дёӯпјҢеҸӘйңҖиҰҒдёҖдёӘ Selector еҚіеҸҜзӣ‘еҗ¬еҗ„дёӘ Socket иҜ·жұӮпјҢиҖҢдё” Selector 并дёҚжҳҜйҳ»еЎһзҡ„пјҢжүҖд»ҘдёҚдјҡеӣ дёәеӨҡдёӘзәҝзЁӢд№Ӣй—ҙеҲҮжҚўеҜјиҮҙдёҠдёӢж–ҮеҲҮжҚўеёҰжқҘзҡ„ејҖй”ҖгҖӮ
еңЁ Java NIO дёӯпјҢйҖүжӢ©еҷЁжҳҜдҪҝз”Ё Selector зұ»иЎЁзӨәпјҢSelector еҸҜд»ҘжҺҘ收еҗ„з§Қ IO иҝһжҺҘпјҢеңЁ IO зҠ¶жҖҒеҮҶеӨҮе°ұз»Әж—¶пјҢдјҡйҖҡзҹҘиҜҘйҖҡйҒ“жіЁеҶҢзҡ„ SelectorпјҢSelector еңЁдёӢдёҖж¬ЎиҪ®иҜўж—¶дјҡеҸ‘зҺ°иҜҘ IO иҝһжҺҘе°ұз»ӘпјҢиҝӣиҖҢеӨ„зҗҶиҜҘиҝһжҺҘгҖӮ
Selector йҖүжӢ©еҷЁдё»иҰҒз”ЁдәҺзҪ‘з»ң IOеҪ“дёӯпјҢеңЁиҝҷйҮҢжҲ‘дјҡе°Ҷдј з»ҹзҡ„ BIO Socket зј–зЁӢе’ҢдҪҝз”Ё NIO еҗҺзҡ„ Socket зј–зЁӢдҪңеҜ№жҜ”пјҢеҲҶжһҗ NIO дёәдҪ•жӣҙеҸ—ж¬ўиҝҺгҖӮйҰ–е…Ҳе…ҲжқҘдәҶи§Ј Selector зҡ„еҹәжң¬з»“жһ„гҖӮ
| йҮҚиҰҒж–№жі• | ж–№жі•и§Јжһҗ |
|---|---|
| open() | жү“ејҖдёҖдёӘ Selector йҖүжӢ©еҷЁ |
| int select() | йҳ»еЎһең°зӯүеҫ…е°ұз»Әзҡ„йҖҡйҒ“ |
| int select(long timeout) | жңҖеӨҡйҳ»еЎһ timeout жҜ«з§’пјҢеҰӮжһңжҳҜ 0 еҲҷдёҖзӣҙйҳ»еЎһзӯүеҫ…пјҢеҰӮжһңжҳҜ 1 еҲҷд»ЈиЎЁжңҖеӨҡйҳ»еЎһ 1 жҜ«з§’ |
| int selectNow() | йқһйҳ»еЎһең°иҪ®иҜўе°ұз»Әзҡ„йҖҡйҒ“ |
еңЁиҝҷйҮҢпјҢдҪ дјҡзңӢеҲ° select() е’Ңе®ғзҡ„йҮҚиҪҪж–№жі•жҳҜдјҡйҳ»еЎһзҡ„пјҢеҰӮжһңз”ЁжҲ·иҝӣзЁӢиҪ®иҜўж—¶еҸ‘зҺ°жІЎжңүе°ұз»Әзҡ„йҖҡйҒ“пјҢж“ҚдҪңзі»з»ҹжңүдёӨз§ҚеҒҡжі•пјҡ
дёҖзӣҙзӯүеҫ…зӣҙеҲ°дёҖдёӘе°ұз»Әзҡ„йҖҡйҒ“пјҢеҶҚиҝ”еӣһз»ҷз”ЁжҲ·иҝӣзЁӢ
з«ӢеҚіиҝ”еӣһдёҖдёӘй”ҷиҜҜзҠ¶жҖҒз Ғз»ҷз”ЁжҲ·иҝӣзЁӢпјҢи®©з”ЁжҲ·иҝӣзЁӢ继з»ӯиҝҗиЎҢпјҢдёҚдјҡйҳ»еЎһ
иҝҷдёӨз§Қж–№жі•еҜ№еә”дәҶеҗҢжӯҘйҳ»еЎһ IO е’Ң еҗҢжӯҘйқһйҳ»еЎһ IO пјҢиҝҷйҮҢиҜ»иҖ…зҡ„дёҖзӮ№е°Ҹзҡ„и§ӮзӮ№пјҢиҜ·еҗ„дҪҚеӨ§зҘһжү№еҲӨйҳ…иҜ»
вҖңJava дёӯзҡ„ NIO дёҚиғҪзңҹжӯЈж„Ҹд№үдёҠз§°дёә Non-Blocking IOпјҢжҲ‘们йҖҡиҝҮ API зҡ„и°ғз”ЁеҸҜд»ҘеҸ‘зҺ°пјҢselect() ж–№жі•иҝҳжҳҜдјҡеӯҳеңЁйҳ»еЎһзҡ„зҺ°иұЎпјҢж №жҚ®дј е…Ҙзҡ„еҸӮж•°дёҚеҗҢпјҢж“ҚдҪңзі»з»ҹзҡ„иЎҢдёәд№ҹдјҡжңүжүҖдёҚеҗҢпјҢдёҚеҗҢд№ӢеӨ„е°ұжҳҜйҳ»еЎһиҝҳжҳҜйқһйҳ»еЎһпјҢжүҖд»ҘжҲ‘жӣҙеҖҫеҗ‘дәҺжҠҠ NIO з§°дёә New IOпјҢеӣ дёәе®ғдёҚд»…жҸҗдҫӣдәҶ Non-Blocking IOпјҢиҖҢдё”дҝқз•ҷеҺҹжңүзҡ„ Blocking IO зҡ„еҠҹиғҪгҖӮвҖқ
дәҶи§ЈдәҶйҖүжӢ©еҷЁд№ӢеҗҺпјҢе®ғзҡ„дҪңз”Ёе°ұжҳҜпјҡзӣ‘еҗ¬еӨҡдёӘ IO йҖҡйҒ“пјҢеҪ“жңүйҖҡйҒ“е°ұз»Әж—¶йҖүжӢ©еҷЁдјҡиҪ®иҜўеҸ‘зҺ°иҜҘйҖҡйҒ“пјҢ并еҒҡзӣёеә”зҡ„еӨ„зҗҶгҖӮйӮЈд№Ҳ IO зҠ¶жҖҒеҲҶдёәеҫҲеӨҡз§ҚпјҢжҲ‘们еҰӮдҪ•еҺ»иҜҶеҲ«е°ұз»Әзҡ„йҖҡйҒ“жҳҜеӨ„дәҺе“Әз§ҚзҠ¶жҖҒе‘ў?еңЁ Java дёӯжҸҗдҫӣдәҶйҖүжӢ©й”®(SelectionKey)гҖӮ
йҖүжӢ©й”®(SelectionKey)
еңЁ Java дёӯжҸҗдҫӣдәҶ 4 з§ҚйҖүжӢ©й”®пјҡ
SelectionKey.OP_READпјҡеҘ—жҺҘеӯ—йҖҡйҒ“еҮҶеӨҮеҘҪиҝӣиЎҢиҜ»ж“ҚдҪң
SelectionKey.OP_WRITEпјҡеҘ—жҺҘеӯ—йҖҡйҒ“еҮҶеӨҮеҘҪиҝӣиЎҢеҶҷж“ҚдҪң
SelectionKey.OP_ACCEPTпјҡжңҚеҠЎеҷЁеҘ—жҺҘеӯ—йҖҡйҒ“жҺҘеҸ—е…¶е®ғйҖҡйҒ“
SelectionKey.OP_CONNECTпјҡеҘ—жҺҘеӯ—йҖҡйҒ“еҮҶеӨҮе®ҢжҲҗиҝһжҺҘ
еңЁ SelectionKey дёӯеҢ…еҗ«дәҶи®ёеӨҡеұһжҖ§
channelпјҡиҜҘйҖүжӢ©й”®з»‘е®ҡзҡ„йҖҡйҒ“
selectorпјҡиҪ®иҜўеҲ°иҜҘйҖүжӢ©й”®зҡ„йҖүжӢ©еҷЁ
readyOpsпјҡеҪ“еүҚе°ұз»ӘйҖүжӢ©й”®зҡ„еҖј
interesOpsпјҡиҜҘйҖүжӢ©еҷЁеҜ№иҜҘйҖҡйҒ“ж„ҹе…ҙи¶Јзҡ„жүҖжңүйҖүжӢ©й”®
йҖүжӢ©й”®зҡ„дҪңз”ЁжҳҜпјҡеңЁйҖүжӢ©еҷЁиҪ®иҜўеҲ°жңүе°ұз»ӘйҖҡйҒ“ж—¶пјҢдјҡиҝ”еӣһиҝҷдәӣйҖҡйҒ“зҡ„е°ұз»ӘйҖүжӢ©й”®(SelectionKey)пјҢйҖҡиҝҮйҖүжӢ©й”®еҸҜд»ҘиҺ·еҸ–еҲ°йҖҡйҒ“иҝӣиЎҢж“ҚдҪңгҖӮ
з®ҖеҚ•дәҶи§ЈдәҶйҖүжӢ©еҷЁеҗҺпјҢжҲ‘们еҸҜд»Ҙз»“еҗҲзј“еҶІеҢәгҖҒйҖҡйҒ“е’ҢйҖүжӢ©еҷЁжқҘе®ҢжҲҗдёҖдёӘз®Җжҳ“зҡ„иҒҠеӨ©е®Өеә”з”ЁгҖӮ
зӨәдҫӢпјҡз®Җжҳ“зҡ„е®ўжҲ·з«ҜжңҚеҠЎеҷЁйҖҡдҝЎ
вҖңе…ҲиҜҙжҳҺпјҢиҝҷйҮҢзҡ„д»Јз Ғйқһеёёзҡ„иҮӯе’Ңй•ҝпјҢдёҚжҺЁиҚҗз»ҶзңӢпјҢзӣҙжҺҘзңӢжіЁйҮҠйҷ„иҝ‘зҡ„д»Јз ҒеҚіеҸҜгҖӮвҖқ
жҲ‘们еңЁжңҚеҠЎеҷЁз«ҜдјҡејҖиҫҹдёӨдёӘзәҝзЁӢ
Thread1пјҡдё“й—Ёзӣ‘еҗ¬е®ўжҲ·з«Ҝзҡ„иҝһжҺҘпјҢ并жҠҠйҖҡйҒ“жіЁеҶҢеҲ°е®ўжҲ·з«ҜйҖүжӢ©еҷЁдёҠ
Thread2пјҡдё“й—Ёзӣ‘еҗ¬е®ўжҲ·з«Ҝзҡ„е…¶е®ғ IO зҠ¶жҖҒ(иҜ»зҠ¶жҖҒ)пјҢеҪ“е®ўжҲ·з«Ҝзҡ„ IO зҠ¶жҖҒе°ұз»Әж—¶пјҢиҜҘйҖүжӢ©еҷЁдјҡиҪ®иҜўеҸ‘зҺ°пјҢ并дҪңзӣёеә”еӨ„зҗҶ
public class NIOServer { Selector serverSelector = Selector.open(); Selector clientSelector = Selector.open(); public static void main(String[] args) throws IOException { NIOServer server = nwe NIOServer(); new Thread(() -> { try { // еҜ№еә”IOзј–зЁӢдёӯжңҚеҠЎз«ҜеҗҜеҠЁ ServerSocketChannel listenerChannel = ServerSocketChannel.open(); listenerChannel.socket().bind(new InetSocketAddress(3333)); listenerChannel.configureBlocking(false); listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT); server.acceptListener(); } catch (IOException ignored) { } }).start(); new Thread(() -> { try { server.clientListener(); } catch (IOException ignored) { } }).start(); } } // зӣ‘еҗ¬е®ўжҲ·з«ҜиҝһжҺҘ public void acceptListener() { while (true) { if (serverSelector.select(1) > 0) { Set<SelectionKey> set = serverSelector.selectedKeys(); Iterator<SelectionKey> keyIterator = set.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); if (key.isAcceptable()) { try { // (1) жҜҸжқҘдёҖдёӘж–°иҝһжҺҘпјҢжіЁеҶҢеҲ°clientSelector SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept(); clientChannel.configureBlocking(false); clientChannel.register(clientSelector, SelectionKey.OP_READ); } finally { // д»Һе°ұз»Әзҡ„еҲ—иЎЁдёӯ移йҷӨиҝҷдёӘkey keyIterator.remove(); } } } } } } // зӣ‘еҗ¬е®ўжҲ·з«Ҝзҡ„ IO зҠ¶жҖҒе°ұз»Ә public void clientListener() { while (true) { // жү№йҮҸиҪ®иҜўжҳҜеҗҰжңүе“ӘдәӣиҝһжҺҘжңүж•°жҚ®еҸҜиҜ» if (clientSelector.select(1) > 0) { Set<SelectionKey> set = clientSelector.selectedKeys(); Iterator<SelectionKey> keyIterator = set.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); // еҲӨж–ӯиҜҘйҖҡйҒ“жҳҜеҗҰиҜ»е°ұз»ӘзҠ¶жҖҒ if (key.isReadable()) { try { // иҺ·еҸ–е®ўжҲ·з«ҜйҖҡйҒ“иҜ»е…Ҙж•°жҚ® SocketChannel clientChannel = (SocketChannel) key.channel(); ByteBuffer byteBuffer = ByteBuffer.allocate(1024); clientChannel.read(byteBuffer); byteBuffer.flip(); System.out.println( LocalDateTime.now().toString() + " Server з«ҜжҺҘ收еҲ°жқҘиҮӘ Client з«Ҝзҡ„ж¶ҲжҒҜ: " + Charset.defaultCharset().decode(byteBuffer).toString()); } finally { // д»Һе°ұз»Әзҡ„еҲ—иЎЁдёӯ移йҷӨиҝҷдёӘkey keyIterator.remove(); key.interestOps(SelectionKey.OP_READ); } } } } } }еңЁе®ўжҲ·з«ҜпјҢжҲ‘们еҸҜд»Ҙз®ҖеҚ•зҡ„иҫ“е…ҘдёҖдәӣж–Үеӯ—пјҢеҸ‘йҖҒз»ҷжңҚеҠЎеҷЁ
public class NIOClient { public static final int CAPACITY = 1024; public static void main(String[] args) throws Exception { ByteBuffer dsts = ByteBuffer.allocate(CAPACITY); SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("127.0.0.1", 3333)); socketChannel.configureBlocking(false); Scanner sc = new Scanner(System.in); while (true) { String msg = sc.next(); dsts.put(msg.getBytes()); dsts.flip(); socketChannel.write(dsts); dsts.clear(); } } }дёӢеӣҫеҸҜд»ҘзңӢи§ҒпјҢеңЁе®ўжҲ·з«Ҝз»ҷжңҚеҠЎеҷЁз«ҜеҸ‘йҖҒдҝЎжҒҜпјҢжңҚеҠЎеҷЁжҺҘ收еҲ°ж¶ҲжҒҜеҗҺпјҢеҸҜд»Ҙе°ҶиҜҘжқЎж¶ҲжҒҜеҲҶеҸ‘з»ҷе…¶е®ғе®ўжҲ·з«ҜпјҢе°ұеҸҜд»Ҙе®һзҺ°дёҖдёӘз®ҖеҚ•зҡ„зҫӨиҒҠзі»з»ҹпјҢжҲ‘们иҝҳеҸҜд»Ҙз»ҷиҝҷдәӣе®ўжҲ·з«ҜиҙҙдёҠж ҮзӯҫдҫӢеҰӮз”ЁжҲ·е§“еҗҚпјҢиҒҠеӨ©зӯүзә§······пјҢе°ұеҸҜд»Ҙж ҮиҜҶжҜҸдёӘе®ўжҲ·з«Ҝе•ҰгҖӮеңЁиҝҷйҮҢз”ұдәҺзҜҮе№…еҺҹеӣ пјҢжҲ‘жІЎжңүеҶҷеҮәжүҖжңүеҠҹиғҪпјҢеӣ дёәдҪҝз”ЁеҺҹз”ҹзҡ„ NIO е®һеңЁжҳҜдёҚеӨӘдҫҝжҚ·гҖӮ
жҲ‘зӣёдҝЎдҪ 们йғҪжҳҜзӣҙжҺҘж»‘дёӢжқҘзңӢиҝҷйҮҢзҡ„пјҢжҲ‘еңЁеҶҷиҝҷж®өд»Јз Ғзҡ„ж—¶еҖҷд№ҹйқһеёёз—ӣиӢҰпјҢз”ҡиҮіжңүзӮ№еҺҢзғҰ Java еҺҹз”ҹзҡ„ NIO зј–зЁӢгҖӮе®һйҷ…дёҠжҲ‘们еңЁж—ҘеёёејҖеҸ‘дёӯеҫҲе°‘зӣҙжҺҘз”Ё NIO иҝӣиЎҢзј–зЁӢпјҢйҖҡеёёйғҪдјҡз”Ё NettyпјҢMina иҝҷз§ҚжңҚеҠЎеҷЁжЎҶжһ¶пјҢе®ғ们йғҪжҳҜеҫҲеҘҪең° NIO жҠҖжңҜпјҢеҜ№ Java еҺҹз”ҹзҡ„ NIO иҝӣиЎҢдәҶдёҠеұӮзҡ„е°ҒиЈ…гҖҒдјҳеҢ–пјҢз®ҖеҢ–ејҖеҸ‘йҡҫеәҰпјҢдҪҶжҳҜеңЁеӯҰд№ жЎҶжһ¶д№ӢеүҚпјҢжҲ‘们йңҖиҰҒдәҶи§Је®ғеә•еұӮеҺҹз”ҹзҡ„жҠҖжңҜпјҢе°ұеғҸ Spring AOP зҡ„еҠЁжҖҒд»ЈзҗҶпјҢSpring IOC е®№еҷЁзҡ„ Map е®№еҷЁеӯҳеӮЁеҜ№иұЎпјҢNetty еә•еұӮзҡ„ NIO еҹәзЎҖ
вҖңд»Җд№ҲдәӢIOжөҒвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ