жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңдёҖиЎҢPythonе‘Ҫд»Өжҗһе®ҡеүҚжңҹж•°жҚ®жҺўзҙўжҖ§зҡ„ж–№жі•жҳҜд»Җд№ҲвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңдёҖиЎҢPythonе‘Ҫд»Өжҗһе®ҡеүҚжңҹж•°жҚ®жҺўзҙўжҖ§зҡ„ж–№жі•жҳҜд»Җд№ҲвҖқеҗ§пјҒ
еҜ№дәҺжҜҸдёӘд»ҺдәӢе’Ңж•°жҚ®з§‘еӯҰжңүе…ізҡ„дәәжқҘиҜҙпјҢеүҚжңҹзҡ„ж•°жҚ®жё…жҙ—е’ҢжҺўзҙўдёҖе®ҡжҳҜдёӘиҠұиҙ№ж—¶й—ҙзҡ„е·ҘдҪңгҖӮжҜ«дёҚеӨёеј зҡ„иҜҙпјҢ80%зҡ„ж—¶й—ҙжҲ‘们йғҪиҠұеңЁдәҶеүҚжңҹзҡ„ж•°жҚ®е·ҘдҪңдёӯпјҢеҢ…жӢ¬жё…жҙ—гҖҒеӨ„зҗҶгҖҒEDAпјҲExploratory Data AnalysisпјҢжҺўзҙўжҖ§ж•°жҚ®еҲҶжһҗпјүзӯүгҖӮеүҚжңҹзҡ„е·ҘдҪңдёҚд»…е…ід№Һж•°жҚ®зҡ„иҙЁйҮҸпјҢд№ҹе…ід№ҺжңҖз»ҲжЁЎеһӢйў„жөӢж•Ҳжһңзҡ„еҘҪеқҸгҖӮ
жҜҸеҪ“жҲ‘们жүӢдёҠеҮәзҺ°дёҖд»Ҫж–°зҡ„ж•°жҚ®ж—¶пјҢжҲ‘们йғҪйңҖиҰҒдәӢе…ҲйҖҡиҝҮдәәдёәең°и§ӮеҜҹгҖҒеӯ—ж®өйҮҠд№үзӯүж–№ејҸйў„е…ҲеҜ№ж•°жҚ®иҝӣиЎҢзҶҹжӮүдёҺзҗҶи§ЈгҖӮеңЁжё…жҙ—гҖҒеӨ„зҗҶе®Ңж•°жҚ®д№ӢеҗҺжүҚдјҡејҖе§ӢзңҹжӯЈзҡ„ EDA иҝҮзЁӢгҖӮ
иҝҷдёӘиҝҮзЁӢжңҖйҖҡз”Ёзҡ„ж“ҚдҪңж— йқһе°ұжҳҜеҜ№зҺ°жңүзҡ„ж•°жҚ®еҒҡеҹәжң¬жҖ§зҡ„з»ҹи®ЎгҖҒжҸҸиҝ°пјҢеҢ…жӢ¬е№іеқҮеҖјгҖҒж–№е·®гҖҒжңҖеӨ§еҖјдёҺжңҖе°ҸеҖјгҖҒйў‘ж•°гҖҒеҲҶдҪҚж•°гҖҒеҲҶеёғзӯүгҖӮе®һйҷ…дёҠеҫҖеҫҖйғҪжҳҜжҜ”иҫғеӣәе®ҡдё”жңәжў°зҡ„гҖӮ
еңЁ R иҜӯиЁҖдёӯ skimr еҢ…жҸҗдҫӣдәҶдё°еҜҢзҡ„ж•°жҚ®жҺўзҙўжҖ§з»ҹи®ЎдҝЎжҒҜпјҢжҜ” Pandas дёӯзҡ„ describe() еҹәжң¬з»ҹи®ЎдҝЎжҒҜжӣҙдёәдё°еҜҢдёҖдәӣгҖӮ
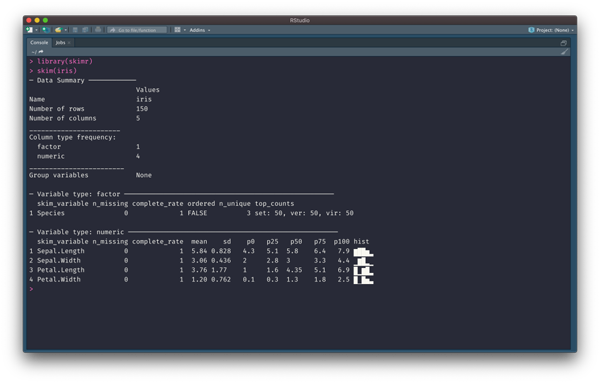
01-skmir
дҪҶеңЁ Python зӨҫеҢәдёӯпјҢжҲ‘们еҗҢж ·д№ҹеҸҜд»Ҙе®һзҺ° skmir зҡ„еҠҹиғҪпјҢз”ҡиҮіжҜ” skmir жңүиҝҮд№ӢиҖҢж— дёҚеҸҠгҖӮйӮЈе°ұжҳҜдҪҝз”Ё pandas-profiling еә“жқҘеё®еҠ©жҲ‘们жҗһе®ҡеүҚжңҹзҡ„ж•°жҚ®жҺўзҙўе·ҘдҪңгҖӮ
еҝ«йҖҹдҪҝз”Ё
йҖҡиҝҮ pip install pandas-profiling д№ӢеҗҺжҲ‘们е°ұеҸҜд»ҘзӣҙжҺҘеҜје…Ҙ并дҪҝз”ЁдәҶгҖӮжҲ‘们еҸӘйңҖиҰҒйҖҡиҝҮе…¶дёҖиЎҢж ёеҝғд»Јз Ғ ProfileReport(df, **kwargs) еҚіеҸҜе®һзҺ°пјҡ
import pandas as pd import seaborn as sns from pandas_profiling import ProfileReport titanic = sns.load_dataset("Titanic") ProfileReport(titanic, title = "The EDA of Titanic Dataset")еҰӮжһңжҲ‘们жҳҜеңЁ Jupyter Notebook дёӯдҪҝз”ЁпјҢеҲҷдјҡеңЁ Jupyter Notebook дёӯжёІжҹ“жңҖеҗҺзӣҙжҺҘиҫ“еҮәеҲ°еҚ•е…ғж јдёӯгҖӮ
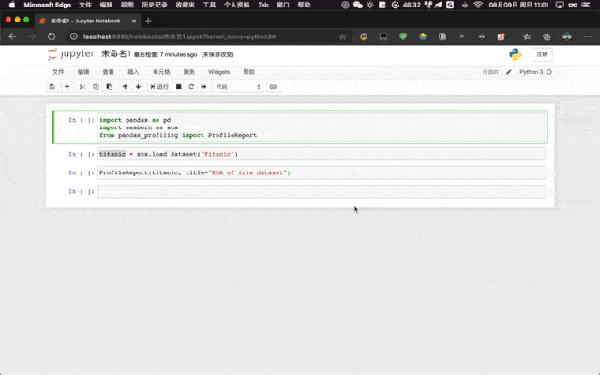
02-profile
pandas-profiling еә“д№ҹжү©еұ•дәҶ DataFrame еҜ№иұЎж–№жі•пјҢиҝҷж„Ҹе‘ізқҖжҲ‘们д№ҹеҸҜд»ҘйҖҡиҝҮеғҸи°ғз”Ёж–№жі•дёҖж ·дҪҝз”Ё DataFrame.profile_report() жқҘе®һзҺ°е’ҢдёҠиҝ°дёҖж ·зҡ„ж•ҲжһңгҖӮ
ж— и®әдҪҝз”Ёе“Әз§Қж–№ејҸпјҢжңҖеҗҺйғҪжҳҜз”ҹжҲҗдёҖдёӘ ProfileReport еҜ№иұЎпјӣеҰӮжһңиҰҒиҝӣдёҖжӯҘиҙҙеҗҲ Jupyter NotebookпјҢеҸҜд»ҘзӣҙжҺҘи°ғз”Ё to_widgets() е’Ң to_notebook_iframe() жқҘеҲҶеҲ«з”ҹжҲҗжҢӮжһ¶жҲ–еҜ№еә”зҡ„组件пјҢеңЁеұ•зӨәж•ҲжһңдёҠдјҡжӣҙеҠ зҫҺи§ӮпјҢиҖҢдёҚжҳҜеңЁиҫ“еҮәж ҸиҝӣиЎҢеұ•зӨәгҖӮ
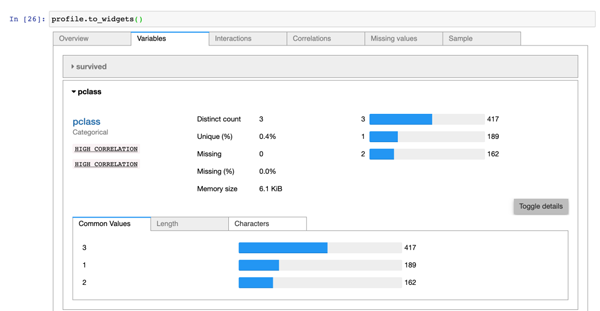
03-widgets
еҰӮжһңдёҚеңЁ Jupyter Notebook дёӯзӣҙжҺҘдҪҝз”ЁпјҢиҖҢжҳҜдҪҝз”Ёе…¶д»– IDEпјҢйӮЈд№ҲжҲ‘们еҸҜд»ҘйҖҡиҝҮ to_file() ж–№жі•жқҘзӣҙжҺҘе°ҶжҠҘе‘Ҡиҫ“еҮәпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜжңҖеҗҺдҝқеӯҳзҡ„ж–Ү件еҗҚйңҖиҰҒеҠ дёҠжү©еұ•еҗҚ .htmlгҖӮ
еҸҰеӨ–пјҢPandas-profiling иҝҳе’ҢеӨҡдёӘжЎҶжһ¶гҖҒдә‘дёҠе№іеҸ°зӯүиҝӣиЎҢдәҶйӣҶжҲҗпјҢиғҪеӨҹи®©жҲ‘们方дҫҝзҡ„иҝӣиЎҢи°ғз”ЁпјҢиҜҰжғ…и§Ғе®ҳзҪ‘пјҲhttps://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/pages/integrations.htmlпјүгҖӮ
иҝӣдёҖжӯҘе®ҡеҲ¶жҠҘе‘ҠдҝЎжҒҜ
иҷҪ然з”ҹжҲҗзҡ„жҺўзҙўжҖ§жҠҘе‘Ҡеҹәжң¬дёҠе·Із»ҸиғҪж»Ўи¶іжҲ‘们дәҶи§Јж•°жҚ®зҡ„з®ҖеҚ•йңҖжұӮпјҢдҪҶжҳҜеҪ“дёӯиҫ“еҮәзҡ„дҝЎжҒҜд№ҹжңүдәӣдёҚи¶іжҲ–жҳҜеҶ—дҪҷгҖӮеҘҪеңЁ pandas-profiling д№ҹз»ҷжҲ‘们жҸҗдҫӣдәҶиҮӘе·ұе®ҡеҲ¶зҡ„еҸҜиғҪгҖӮиҝҷдәӣе®ҡеҲ¶зҡ„й…ҚзҪ®жңҖз»ҲдјҡеҶҷе…ҘеҲ° yaml ж–Ү件дёӯгҖӮ
еңЁе®ҳж–№ж–ҮжЎЈдёӯеҲ—еҮәдәҶеҮ дёӘжҲ‘们иғҪеӨҹиҝӣдёҖжӯҘи°ғж•ҙзҡ„йғЁеҲҶпјҢеҲҶеҲ«еҜ№еә”дәҶжҠҘе‘Ҡ Tab ж Ҹзҡ„еҗ„йғЁеҲҶж Үзӯҫпјҡ
varsпјҡдё»иҰҒз”ЁдәҺи°ғж•ҙж•°жҚ®дёӯеӯ—ж®өжҲ–еҸҳйҮҸеңЁжҠҘе‘Ҡдёӯзҡ„е‘ҲзҺ°зҡ„з»ҹи®ЎжҢҮж Ү
missing_diagramsпјҡдё»иҰҒж¶үеҸҠеҲ°е…ідәҺзјәеӨұеҖјеӯ—ж®өзҡ„еҸҜи§ҶеҢ–еұ•зӨә
correlationsпјҡйЎҫеҗҚжҖқд№үеҚіи°ғж•ҙжңүе…іеҗ„еӯ—ж®өжҲ–еҸҳйҮҸд№Ӣй—ҙзӣёе…іе…ізі»зҡ„йғЁеҲҶпјҢеҢ…жӢ¬жҳҜеҗҰи®Ўз®—зӣёе…ізі»ж•°гҖҒд»ҘеҸҠзӣёе…ізҡ„йҳҲеҖјзӯү
interactionsпјҡдё»иҰҒж¶үеҸҠдёӨдёӨеӯ—ж®өжҲ–еҸҳйҮҸд№ӢеүҚзҡ„зӣёе…іе…ізі»еӣҫе‘ҲзҺ°
samplesпјҡеҲҶеҲ«еҜ№еә”дәҶ Pandas дёӯ head() е’Ң tail() ж–№жі•пјҢеҚійў„и§ҲеүҚеҗҺеӨҡе°‘жқЎж•°жҚ®
иҝҷдәӣйғЁеҲҶиҝҳжңүи®ёеӨҡеҸҜд»ҘжҢҮе®ҡзҡ„еҸӮж•°пјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘзӣҙжҺҘеҸӮиҖғе®ҳж–№ж–ҮжЎЈпјҲhttps://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/pages/advanced_usage.htmlпјүпјҢжң¬ж–Үе°ұдёҚеӨҡеҠ иөҳиҝ°дәҶгҖӮ
дәҺжҳҜжҲ‘们еҸҜд»ҘзӣҙжҺҘеңЁд»Јз ҒдёӯжүӢеҠЁеҶҷе…Ҙ并иҝӣиЎҢи°ғж•ҙпјҢе°ұеғҸиҝҷж ·пјҡ
profile_config = { "progress_bar": False, "sort": "ascending", "vars": { "num": {"chi_squared_threshold": 0.95}, "cat": {"n_obs": 10} }, "missing_diagrams": { 'heatmap': False, 'dendrogram': False, } } profile = titanic.profile_report(**profile_config) profile.to_file("titanic-EDA-report.html")е°ҶжүҖжңүй…ҚзҪ®зҡ„дҝЎжҒҜеҶҷеңЁдёҖдёӘеӯ—е…ёеҸҳйҮҸдёӯпјҢеҶҚйҖҡиҝҮ **variable зҡ„еҪўејҸе°Ҷй”®еҖјеҜ№иҝӣиЎҢи§ЈеҢ…дҪҝе…¶иғҪеӨҹж №жҚ®й”®жқҘеҜ№еә”еҲ°зӣёеә”зҡ„еҸӮж•°дёӯгҖӮ
йҷӨдәҶд»Јз Ғдёӯзҡ„й…ҚзҪ®еҶҷжі•еӨ–пјҢеҰӮжһңдҪ зЁҚеҫ®дәҶи§ЈдёҖзӮ№ yaml й…ҚзҪ®ж–Ү件зҡ„еҶҷжі•пјҢйӮЈд№ҲжҲ‘们д№ҹж— йңҖеңЁд»Јз ҒдёӯйҖҗдёӘеҶҷе…ҘпјҢиҖҢжҳҜеҸҜд»ҘйҖҡиҝҮеңЁ yaml ж–Ү件дёӯдҝ®ж”№гҖӮдҝ®ж”№зҡ„дёҚд»…е®ҳж–№ж–ҮжЎЈдёӯжүҖеҲ—еҮәзҡ„й…ҚзҪ®йҖүйЎ№пјҢиҝҳиғҪдҝ®ж”№жңӘеҲ—еҮәзҡ„еҸӮж•°гҖӮз”ұдәҺй…ҚзҪ®ж–Ү件иҝҮй•ҝпјҢиҝҷйҮҢжҲ‘еҸӘж”ҫеҮәеҹәдәҺе®ҳж–№й»ҳи®Өй…ҚзҪ®ж–Ү件 config_default.yaml иҮӘе·ұеҒҡеҮәдҝ®ж”№зҡ„йғЁеҲҶпјҡ
# profile_config.yml vars: num: quantiles: - 0.25 - 0.5 - 0.75 skewness_threshold: 10 low_categorical_threshold: 5 chi_squared_threshold: 0.95 cat: length: True unicode: True cardinality_threshold: 50 n_obs: 5 chi_squared_threshold: 0.95 coerce_str_to_date: False bool: n_obs: 3 file: active: False image: active: False exif: True hash: True sort: "desceding"
дҝ®ж”№е®Ң yaml ж–Ү件д№ӢеҗҺпјҢжҲ‘们еҸӘйңҖеңЁз”ҹжҲҗжҠҘе‘Ҡж—¶йҖҡиҝҮ config_file еҸӮж•°жҢҮе®ҡй…ҚзҪ®ж–Ү件жүҖеңЁзҡ„и·Ҝеҫ„еҚіеҸҜпјҢе°ұеғҸиҝҷж ·пјҡ
df.profile_report(config_file = "дҪ зҡ„ж–Ү件и·Ҝеҫ„.yml")
йҖҡиҝҮе°Ҷй…ҚзҪ®ж–Ү件дёҺж ёеҝғд»Јз ҒзӣёеҲҶзҰ»пјҢд»ҘжҸҗй«ҳжҲ‘们代з Ғзҡ„з®ҖжҙҒжҖ§дёҺеҸҜиҜ»жҖ§гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңдёҖиЎҢPythonе‘Ҫд»Өжҗһе®ҡеүҚжңҹж•°жҚ®жҺўзҙўжҖ§зҡ„ж–№жі•жҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№дёҖиЎҢPythonе‘Ҫд»Өжҗһе®ҡеүҚжңҹж•°жҚ®жҺўзҙўжҖ§зҡ„ж–№жі•жҳҜд»Җд№ҲиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ