жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№ҲеңЁFedoraдёҠжҗӯе»әJupyterе’Ңж•°жҚ®з§‘еӯҰзҺҜеўғвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№ҲеңЁFedoraдёҠжҗӯе»әJupyterе’Ңж•°жҚ®з§‘еӯҰзҺҜеўғвҖқеҗ§пјҒ
еӨ§еӨҡж•°зҺ°д»Јж•°жҚ®з§‘еӯҰ家дҪҝз”Ё Python е·ҘдҪңгҖӮ他们е·ҘдҪңдёӯеҫҲйҮҚиҰҒзҡ„дёҖйғЁеҲҶжҳҜжҺўзҙўжҖ§ж•°жҚ®еҲҶжһҗпјҲEDAпјүгҖӮEDA жҳҜдёҖз§ҚжүӢеҠЁиҝӣиЎҢзҡ„гҖҒдәӨдә’жҖ§зҡ„иҝҮзЁӢпјҢеҢ…жӢ¬жҸҗеҸ–ж•°жҚ®гҖҒжҺўзҙўж•°жҚ®зү№еҫҒгҖҒеҜ»жүҫзӣёе…іжҖ§гҖҒйҖҡиҝҮз»ҳеҲ¶еӣҫеҪўиҝӣиЎҢж•°жҚ®еҸҜи§ҶеҢ–并зҗҶи§Јж•°жҚ®зҡ„еҲҶеёғзү№еҫҒпјҢд»ҘеҸҠе®һзҺ°еҺҹеһӢйў„жөӢжЁЎеһӢгҖӮ
Jupyter жҳҜиғҪеӨҹ***иғңд»»иҜҘе·ҘдҪңзҡ„дёҖдёӘ web еә”з”ЁгҖӮJupyter дҪҝз”Ёзҡ„ Notebook ж–Ү件ж”ҜжҢҒеҜҢж–Үжң¬пјҢеҢ…жӢ¬жёІжҹ“зІҫзҫҺзҡ„ж•°еӯҰе…¬ејҸпјҲеҫ—зӣҠдәҺ mathjaxпјүгҖҒд»Јз Ғеқ—е’Ңд»Јз Ғиҫ“еҮәпјҲеҢ…жӢ¬еӣҫеҪўиҫ“еҮәпјүгҖӮ
Notebook ж–Ү件зҡ„еҗҺзјҖжҳҜ .ipynbпјҢж„ҸжҖқжҳҜвҖңдәӨдә’ејҸ Python NotebookвҖқгҖӮ
йҰ–е…ҲпјҢдҪҝз”Ё sudo е®үиЈ… Jupyter ж ёеҝғиҪҜ件еҢ…пјҡ
$ sudo dnf install python3-notebook mathjax sscg
дҪ жҲ–и®ёйңҖиҰҒе®үиЈ…ж•°жҚ®з§‘еӯҰ家常用зҡ„дёҖдәӣйҷ„еҠ еҸҜйҖүжЁЎеқ—пјҡ
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
и®ҫзҪ®дёҖдёӘз”ЁжқҘзҷ»еҪ• Notebook зҡ„ web з•Ңйқўзҡ„еҜҶз ҒпјҢд»ҺиҖҢйҒҝе…ҚдҪҝз”ЁеҶ—й•ҝзҡ„д»ӨзүҢгҖӮдҪ еҸҜд»ҘеңЁз»Ҳз«ҜйҮҢд»»дҪ•дёҖдёӘдҪҚзҪ®иҝҗиЎҢдёӢйқўзҡ„е‘Ҫд»Өпјҡ
$ mkdir -p $HOME/.jupyter$ jupyter notebook password
然еҗҺиҫ“е…ҘдҪ зҡ„еҜҶз ҒпјҢиҝҷж—¶дјҡиҮӘеҠЁеҲӣе»ә $HOME/.jupyter/jupyter_notebook_config.json иҝҷдёӘж–Ү件пјҢеҢ…еҗ«дәҶдҪ зҡ„еҜҶз Ғзҡ„еҠ еҜҶеҗҺзүҲжң¬гҖӮ
жҺҘдёӢжқҘпјҢйҖҡиҝҮдҪҝз”Ё SSLby дёә Jupyter зҡ„ web жңҚеҠЎеҷЁз”ҹжҲҗдёҖдёӘиҮӘзӯҫеҗҚзҡ„ HTTPS иҜҒд№Ұпјҡ
$ cd $HOME/.jupyter; sscg
й…ҚзҪ® Jupyter зҡ„***дёҖжӯҘжҳҜзј–иҫ‘ $HOME/.jupyter/jupyter_notebook_config.json иҝҷдёӘж–Ү件гҖӮжҢүз…§дёӢйқўзҡ„жЁЎзүҲзј–иҫ‘иҜҘж–Ү件пјҡ
{ "NotebookApp": { "password": "sha1:abf58...87b", "ip": "*", "allow_origin": "*", "allow_remote_access": true, "open_browser": false, "websocket_compression_options": {}, "certfile": "/home/aviram/.jupyter/service.pem", "keyfile": "/home/aviram/.jupyter/service-key.pem", "notebook_dir": "/home/aviram/Notebooks" }}/home/aviram/ еә”иҜҘжӣҝжҚўдёәдҪ зҡ„ж–Ү件еӨ№гҖӮsha1:abf58...87b иҝҷдёӘйғЁеҲҶеңЁдҪ еҲӣе»әе®ҢеҜҶз Ғд№ӢеҗҺе°ұе·Із»ҸиҮӘеҠЁз”ҹжҲҗдәҶгҖӮservice.pem е’Ң service-key.pem жҳҜ sscg з”ҹжҲҗзҡ„е’ҢеҠ еҜҶзӣёе…ізҡ„ж–Ү件гҖӮ
жҺҘдёӢжқҘеҲӣе»әдёҖдёӘз”ЁжқҘеӯҳж”ҫ Notebook ж–Ү件зҡ„ж–Ү件еӨ№пјҢеә”иҜҘе’ҢдёҠйқўй…ҚзҪ®йҮҢ notebook_dir дёҖиҮҙпјҡ
$ mkdir $HOME/Notebooks
дҪ е·Із»Ҹе®ҢжҲҗдәҶй…ҚзҪ®гҖӮзҺ°еңЁеҸҜд»ҘеңЁзі»з»ҹйҮҢзҡ„д»»дҪ•дёҖдёӘең°ж–№йҖҡиҝҮд»ҘдёӢе‘Ҫд»ӨеҗҜеҠЁ Jupyter Notebookпјҡ
$ jupyter notebook
жҲ–иҖ…жҳҜе°ҶдёӢйқўиҝҷиЎҢд»Јз Ғж·»еҠ еҲ° $HOME/.bashrc ж–Ү件пјҢеҲӣе»әдёҖдёӘеҸ«еҒҡ jn зҡ„еҝ«жҚ·е‘Ҫд»Өпјҡ
alias jn='jupyter notebook'
иҝҗиЎҢ jn е‘Ҫд»Өд№ӢеҗҺпјҢдҪ еҸҜд»ҘйҖҡиҝҮзҪ‘з»ңеҶ…йғЁзҡ„д»»дҪ•дёҖдёӘжөҸи§ҲеҷЁи®ҝй—® <https://your-fedora-host.com:8888> пјҲLCTT иҜ‘жіЁпјҡиҜ·е°ҶеҹҹеҗҚжӣҝжҚўдёәжңҚеҠЎеҷЁзҡ„еҹҹеҗҚпјүпјҢе°ұеҸҜд»ҘзңӢеҲ° Jupyter зҡ„з”ЁжҲ·з•ҢйқўдәҶпјҢйңҖиҰҒдҪҝз”ЁеүҚйқўи®ҫзҪ®зҡ„еҜҶз Ғзҷ»еҪ•гҖӮдҪ еҸҜд»Ҙе°қиҜ•й”®е…ҘдёҖдәӣ Python д»Јз Ғе’Ңж Үи®°ж–Үжң¬пјҢзңӢиө·жқҘдјҡеғҸдёӢйқўиҝҷж ·пјҡ
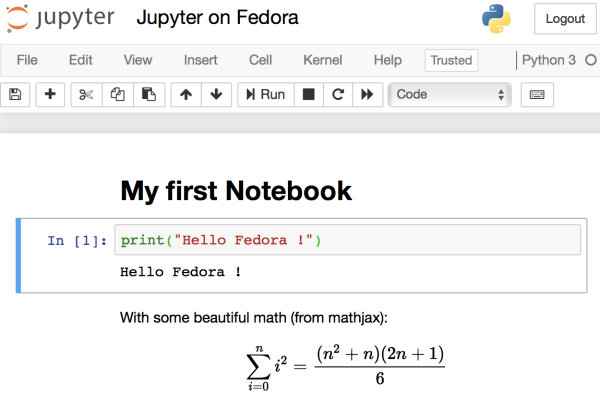
Jupyter with a simple notebook
йҷӨдәҶ IPython зҺҜеўғпјҢе®үиЈ…иҝҮзЁӢиҝҳдјҡз”ҹжҲҗдёҖдёӘз”ұ terminado жҸҗдҫӣзҡ„еҹәдәҺ web зҡ„ Unix з»Ҳз«ҜгҖӮжңүдәәи§үеҫ—иҝҷеҫҲе®һз”ЁпјҢд№ҹжңүдәәи§үеҫ—иҝҷж ·дёҚжҳҜеҫҲе®үе…ЁгҖӮдҪ еҸҜд»ҘеңЁй…ҚзҪ®ж–Ү件йҮҢзҰҒз”ЁиҝҷдёӘеҠҹиғҪгҖӮ
JupyterLab жҳҜдёӢдёҖд»Јзҡ„ JupyterпјҢжӢҘжңүжӣҙеҘҪзҡ„з”ЁжҲ·з•Ңйқўе’ҢеҜ№е·ҘдҪңз©әй—ҙжӣҙејәзҡ„ж“ҚжҺ§жҖ§гҖӮеңЁеҶҷиҝҷзҜҮж–Үз« зҡ„ж—¶еҖҷ JupyterLab иҝҳжІЎжңүеҸҜз”Ёзҡ„ RPM иҪҜ件еҢ…пјҢдҪҶжҳҜдҪ еҸҜд»ҘдҪҝз”Ё pip иҪ»жқҫе®ҢжҲҗе®үиЈ…пјҡ
$ pip3 install jupyterlab --user$ jupyter serverextension enable --py jupyterlab
然еҗҺиҝҗиЎҢ jupiter notebook е‘Ҫд»ӨжҲ–иҖ… jn еҝ«жҚ·е‘Ҫд»ӨгҖӮи®ҝй—® <http://your-linux-host.com:8888/lab> пјҲLCTT иҜ‘жіЁпјҡе°ҶеҹҹеҗҚжӣҝжҚўдёәжңҚеҠЎеҷЁзҡ„еҹҹеҗҚпјүе°ұеҸҜд»ҘдҪҝз”Ё JupyterLab дәҶгҖӮ
еңЁдёӢйқўиҝҷдёҖиҠӮйҮҢпјҢдҪ е°ҶдјҡдәҶи§ЈеҲ°ж•°жҚ®з§‘еӯҰ家дҪҝз”Ёзҡ„дёҖдәӣе·Ҙе…·еҸҠе…¶е®үиЈ…ж–№жі•гҖӮйҷӨйқһеҸҰдҪңиҜҙжҳҺпјҢиҝҷдәӣе·Ҙе…·еә”иҜҘе·Із»Ҹжңү Fedora иҪҜ件еҢ…зүҲжң¬пјҢ并且已з»ҸдҪңдёәеүҚйқўз»„件жүҖйңҖиҰҒзҡ„иҪҜ件еҢ…иҖҢиў«е®үиЈ…дәҶгҖӮ
Numpy жҳҜдёҖдёӘй’ҲеҜ№ C иҜӯиЁҖдјҳеҢ–иҝҮзҡ„й«ҳзә§еә“пјҢз”ЁжқҘеӨ„зҗҶеӨ§еһӢзҡ„еҶ…еӯҳж•°жҚ®йӣҶгҖӮе®ғж”ҜжҢҒй«ҳзә§еӨҡз»ҙзҹ©йҳөеҸҠе…¶иҝҗз®—пјҢ并且еҢ…еҗ«дәҶ log()гҖҒexp()гҖҒдёүи§’еҮҪж•°зӯүж•°еӯҰеҮҪж•°гҖӮ
еңЁжҲ‘зңӢжқҘпјҢжӯЈжҳҜ Pandas жҲҗе°ұдәҶ Python дҪңдёәж•°жҚ®з§‘еӯҰ***е№іеҸ°зҡ„ең°дҪҚгҖӮPandas жһ„е»әеңЁ Numpy д№ӢдёҠпјҢеҸҜд»Ҙи®©ж•°жҚ®еҮҶеӨҮе’Ңж•°жҚ®е‘ҲзҺ°е·ҘдҪңеҸҳеҫ—з®ҖеҚ•еҫҲеӨҡгҖӮдҪ еҸҜд»ҘжҠҠе®ғжғіиұЎжҲҗдёҖдёӘжІЎжңүз”ЁжҲ·з•Ңйқўзҡ„з”өеӯҗиЎЁж јзЁӢеәҸпјҢдҪҶжҳҜиғҪеӨҹеӨ„зҗҶзҡ„ж•°жҚ®йӣҶиҰҒеӨ§еҫ—еӨҡгҖӮPandas ж”ҜжҢҒд»Һ SQL ж•°жҚ®еә“жҲ–иҖ… CSV зӯүж јејҸзҡ„ж–Ү件дёӯжҸҗеҸ–ж•°жҚ®гҖҒжҢүеҲ—жҲ–иҖ…жҢүиЎҢиҝӣиЎҢж“ҚдҪңгҖҒж•°жҚ®зӯӣйҖүпјҢд»ҘеҸҠйҖҡиҝҮ Matplotlib е®һзҺ°ж•°жҚ®еҸҜи§ҶеҢ–зҡ„дёҖйғЁеҲҶеҠҹиғҪгҖӮ
Matplotlib жҳҜдёҖдёӘз”ЁжқҘз»ҳеҲ¶ 2D е’Ң 3D ж•°жҚ®еӣҫеғҸзҡ„еә“пјҢеңЁеӣҫиұЎжіЁи§ЈгҖҒж Үзӯҫе’ҢеҸ еҠ еұӮж–№йқўйғҪжҸҗдҫӣдәҶзӣёеҪ“дёҚй”ҷзҡ„ж”ҜжҢҒгҖӮ
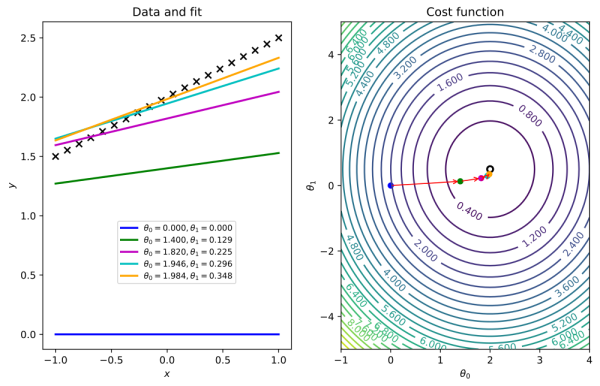
matplotlib pair of graphics showing a cost function searching its optimal value through a gradient descent algorithm
Seaborn жһ„е»әеңЁ Matplotlib д№ӢдёҠпјҢе®ғзҡ„з»ҳеӣҫеҠҹиғҪз»ҸиҝҮдәҶдјҳеҢ–пјҢжӣҙеҠ йҖӮеҗҲж•°жҚ®зҡ„з»ҹи®ЎеӯҰз ”з©¶пјҢжҜ”еҰӮиҜҙеҸҜд»ҘиҮӘеҠЁжҳҫзӨәжүҖз»ҳеҲ¶ж•°жҚ®зҡ„иҝ‘дјјеӣһеҪ’зәҝжҲ–иҖ…жӯЈжҖҒеҲҶеёғжӣІзәҝгҖӮ
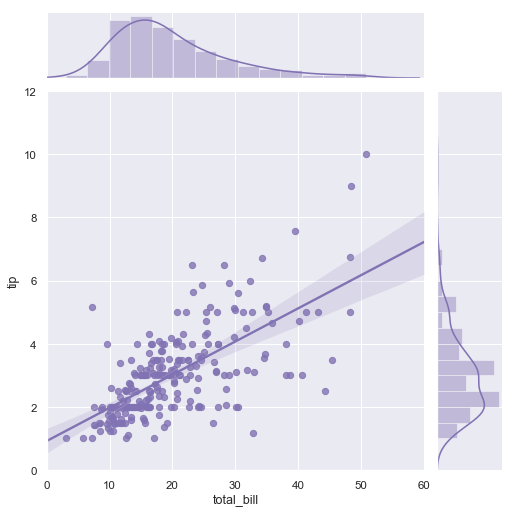
Linear regression visualised with SeaBorn
StatsModels дёәз»ҹи®ЎеӯҰе’Ңз»ҸжөҺи®ЎйҮҸеӯҰзҡ„ж•°жҚ®еҲҶжһҗй—®йўҳпјҲдҫӢеҰӮзәҝеҪўеӣһеҪ’е’ҢйҖ»иҫ‘еӣһеҪ’пјүжҸҗдҫӣз®—жі•ж”ҜжҢҒпјҢеҗҢж—¶жҸҗдҫӣз»Ҹе…ёзҡ„ ж—¶й—ҙеәҸеҲ—з®—жі• 家ж—Ҹ ARIMAгҖӮ
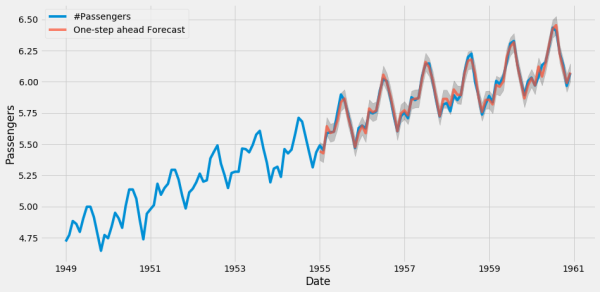
Normalized number of passengers across time \(blue\) and ARIMA-predicted number of passengers \(red\)
дҪңдёәжңәеҷЁеӯҰд№ з”ҹжҖҒзі»з»ҹзҡ„ж ёеҝғйғЁд»¶пјҢScikit дёәдёҚеҗҢзұ»еһӢзҡ„й—®йўҳжҸҗдҫӣйў„жөӢз®—жі•пјҢеҢ…жӢ¬ еӣһеҪ’й—®йўҳпјҲз®—жі•еҢ…жӢ¬ ElasticnetгҖҒGradient BoostingгҖҒйҡҸжңәжЈ®жһ—зӯүзӯүпјүгҖҒеҲҶзұ»й—®йўҳ е’ҢиҒҡзұ»й—®йўҳпјҲз®—жі•еҢ…жӢ¬ K-means е’Ң DBSCAN зӯүзӯүпјүпјҢ并且жӢҘжңүи®ҫи®ЎзІҫиүҜзҡ„ APIгҖӮScikit иҝҳе®ҡд№үдәҶдёҖдәӣдё“й—Ёзҡ„ Python зұ»пјҢз”ЁжқҘж”ҜжҢҒж•°жҚ®ж“ҚдҪңзҡ„й«ҳзә§жҠҖе·§пјҢжҜ”еҰӮе°Ҷж•°жҚ®йӣҶжӢҶеҲҶдёәи®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶгҖҒйҷҚз»ҙз®—жі•гҖҒж•°жҚ®еҮҶеӨҮз®ЎйҒ“жөҒзЁӢзӯүзӯүгҖӮ
XGBoost жҳҜзӣ®еүҚеҸҜд»ҘдҪҝз”Ёзҡ„***иҝӣзҡ„еӣһеҪ’еҷЁе’ҢеҲҶзұ»еҷЁгҖӮе®ғ并дёҚжҳҜ Scikit-learn зҡ„дёҖйғЁеҲҶпјҢдҪҶжҳҜеҚҙйҒөеҫӘдәҶ Scikit зҡ„ APIгҖӮXGBoost 并没жңүй’ҲеҜ№ Fedora зҡ„иҪҜ件еҢ…пјҢдҪҶеҸҜд»ҘдҪҝз”Ё pip е®үиЈ…гҖӮдҪҝз”ЁиӢұдјҹиҫҫжҳҫеҚЎеҸҜд»ҘжҸҗеҚҮ XGBoost з®—жі•зҡ„жҖ§иғҪпјҢдҪҶжҳҜиҝҷ并дёҚиғҪйҖҡиҝҮ pip иҪҜ件еҢ…жқҘе®һзҺ°гҖӮеҰӮжһңдҪ еёҢжңӣдҪҝз”ЁиҝҷдёӘеҠҹиғҪпјҢеҸҜд»Ҙй’ҲеҜ№ CUDA пјҲLCTT иҜ‘жіЁпјҡиӢұдјҹиҫҫејҖеҸ‘зҡ„并иЎҢи®Ўз®—е№іеҸ°пјүиҮӘе·ұиҝӣиЎҢзј–иҜ‘гҖӮдҪҝз”ЁдёӢйқўиҝҷдёӘе‘Ҫд»Өе®үиЈ… XGBoostпјҡ
$ pip3 install xgboost --user
Imbalanced-learn жҳҜдёҖдёӘи§ЈеҶіж•°жҚ®ж¬ йҮҮж ·е’ҢиҝҮйҮҮж ·й—®йўҳзҡ„е·Ҙе…·гҖӮжҜ”еҰӮеңЁеҸҚж¬әиҜҲй—®йўҳдёӯпјҢж¬әиҜҲж•°жҚ®зӣёеҜ№дәҺжӯЈеёёж•°жҚ®жқҘиҜҙж•°йҮҸйқһеёёе°ҸпјҢиҝҷдёӘж—¶еҖҷе°ұйңҖиҰҒеҜ№ж¬әиҜҲж•°жҚ®иҝӣиЎҢж•°жҚ®еўһејәпјҢд»ҺиҖҢи®©йў„жөӢеҷЁиғҪеӨҹжӣҙеҘҪең°йҖӮеә”ж•°жҚ®йӣҶгҖӮдҪҝз”Ё pip е®үиЈ…пјҡ
$ pip3 install imblearn --user
Natural Language toolkitпјҲз®Җз§° NLTKпјүжҳҜдёҖдёӘеӨ„зҗҶдәәзұ»иҜӯиЁҖж•°жҚ®зҡ„е·Ҙе…·пјҢдёҫдҫӢжқҘиҜҙпјҢе®ғеҸҜд»Ҙиў«з”ЁжқҘејҖеҸ‘дёҖдёӘиҒҠеӨ©жңәеҷЁдәәгҖӮ
жңәеҷЁеӯҰд№ з®—жі•жӢҘжңүејәеӨ§зҡ„йў„жөӢиғҪеҠӣпјҢдҪҶ并дёҚиғҪеӨҹеҫҲеҘҪең°и§ЈйҮҠдёәд»Җд№ҲеҒҡеҮәиҝҷж ·жҲ–йӮЈж ·зҡ„йў„жөӢгҖӮSHAP еҸҜд»ҘйҖҡиҝҮеҲҶжһҗи®ӯз»ғеҗҺзҡ„жЁЎеһӢжқҘи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
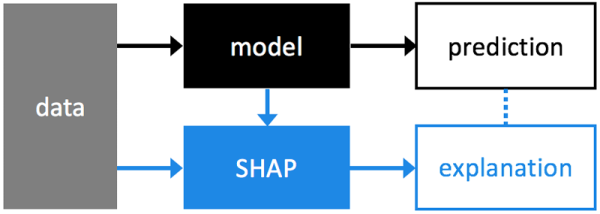
Where SHAP fits into the data analysis process
дҪҝз”Ё pip е®үиЈ…пјҡ
$ pip3 install shap --user
Keras жҳҜдёҖдёӘж·ұеәҰеӯҰд№ е’ҢзҘһз»ҸзҪ‘з»ңжЁЎеһӢзҡ„еә“пјҢдҪҝз”Ё pip е®үиЈ…пјҡ
$ sudo dnf install python3-h6py$ pip3 install keras --user
TensorFlow жҳҜдёҖдёӘйқһеёёжөҒиЎҢзҡ„зҘһз»ҸзҪ‘з»ңжЁЎеһӢжҗӯе»әе·Ҙе…·пјҢдҪҝз”Ё pip е®үиЈ…пјҡ
$ pip3 install tensorflow --user
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№ҲеңЁFedoraдёҠжҗӯе»әJupyterе’Ңж•°жҚ®з§‘еӯҰзҺҜеўғвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№ҲеңЁFedoraдёҠжҗӯе»әJupyterе’Ңж•°жҚ®з§‘еӯҰзҺҜеўғиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ