您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Python中怎么利用网络爬虫获取招聘信息,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
1、定义一个class类继承object,定义init方法继承self,主函数main继承self。导入需要的库和网址,代码如下所示。
import requests from lxml import etree from fake_useragent import UserAgent class Zhaopin(object): def __init__(self): self.url = "https://gz.58.com/job/pn2/?param7503=1&from=yjz2_zhaopin&PGTID=0d302408-0000-3efd-48f6-ff64d26b4b1c&ClickID={}" # /zhuanchang/:搜索的名字的拼音缩写 def main(self): pass if __name__ == '__main__': Spider = Zhaopin() Spider.main()2、随机产生UserAgent。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }3、发送请求,获取响应, 页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html4、xpath解析找到对应的父节点。
def page_page(self, html): parse_html = etree.HTML(html) one = parse_html.xpath('//div[@class="main clearfix"]//div[@class="leftCon"]/ul/li')5、for遍历,定义一个变量food_info保存,获取到二级页面对应的菜 名、 原 料 、下 载 链 接。
for l in one: o = l.xpath('.//a/span[1]/text()')[0].strip() t = l.xpath('.//a//span[@class="name"]/text()')[0].strip() f = l.xpath('.//p[@class="job_salary"]/text()') thr = l.xpath('.//div[@class="comp_name"]//a/text()')[0].strip() for e in f: boss = ''' %s:||%s: 公司:%s, 工资:%s元/月 ========================================================= ''' % (o, t, thr, e) print(str(boss)6、将结果保存在txt文档中,如下所示。
f = open('g.txt', 'a', encoding='utf-8') # 以'w'方式打开文件 f.write(str(boss)) # print(house_dict) f.write("\n") # 键和值分行放,键在单数行,值在双数行 f.close()7、调用方法,实现功能。
html = self.get_page(url) self.page_page(html)
6.效果展示
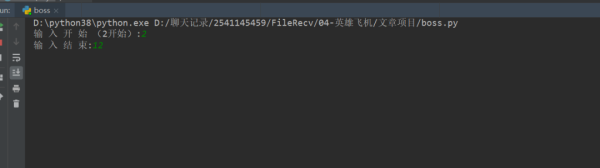
1、点击绿色小三角运行输入起始页,终止页。
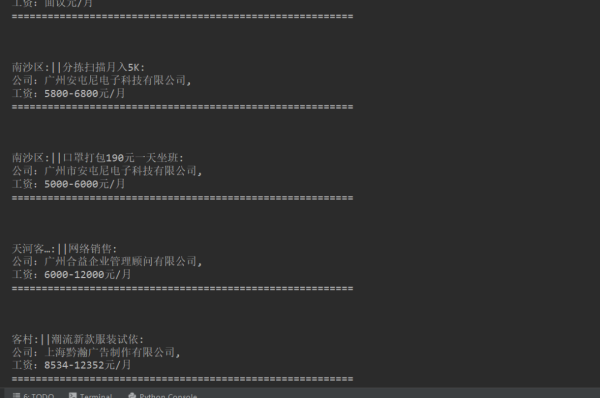
2、运行程序后,结果显示在控制台,如下图所示。
3、保存txt文档到本地,如下图所示。
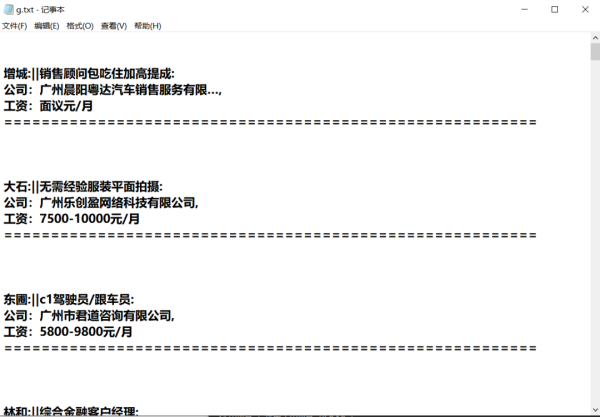
4、双击文件,内容如下图所示。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。