жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
PythonдёӯжҖҺд№ҲеҲ©з”ЁDBSCANе®һзҺ°дёҖдёӘеҜҶеәҰиҒҡзұ»з®—жі•пјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
еҹәдәҺеҜҶеәҰиҝҷзӮ№жңүд»Җд№ҲеҘҪеӨ„е‘ў?
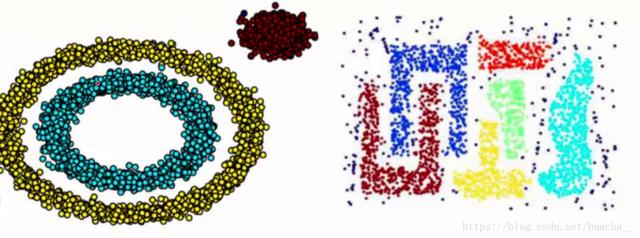
жҲ‘们зҹҘйҒ“kmeansиҒҡзұ»з®—жі•еҸӘиғҪеӨ„зҗҶзҗғеҪўзҡ„з°ҮпјҢд№ҹе°ұжҳҜдёҖдёӘиҒҡжҲҗе®һеҝғзҡ„еӣў(иҝҷжҳҜеӣ дёәз®—жі•жң¬иә«и®Ўз®—е№іеқҮи·қзҰ»зҡ„еұҖйҷҗ)гҖӮдҪҶеҫҖеҫҖзҺ°е®һдёӯиҝҳдјҡжңүеҗ„з§ҚеҪўзҠ¶пјҢжҜ”еҰӮдёӢйқўдёӨеј еӣҫпјҢзҺҜеҪўе’ҢдёҚ规еҲҷеҪўпјҢиҝҷдёӘж—¶еҖҷпјҢйӮЈдәӣдј з»ҹзҡ„иҒҡзұ»з®—жі•жҳҫ然е°ұжӮІеү§дәҶгҖӮ
дәҺжҳҜе°ұжҖқиҖғпјҢж ·жң¬еҜҶеәҰеӨ§зҡ„жҲҗдёҖзұ»е‘—пјҢиҝҷе°ұжҳҜDBSCANиҒҡзұ»з®—жі•гҖӮ
дёүгҖҒеҸӮж•°йҖүжӢ©
дёҠйқўжҸҗеҲ°дәҶзәўиүІеңҶеңҲж»ҡе•Ҡж»ҡзҡ„иҝҮзЁӢпјҢиҝҷдёӘиҝҮзЁӢе°ұеҢ…жӢ¬дәҶDBSCANз®—жі•зҡ„дёӨдёӘеҸӮж•°пјҢиҝҷдёӨдёӘеҸӮж•°жҜ”иҫғйҡҫжҢҮе®ҡпјҢе…¬и®Өзҡ„жҢҮе®ҡж–№жі•з®ҖеҚ•иҜҙдёҖдёӢпјҡ
еҚҠеҫ„пјҡеҚҠеҫ„жҳҜжңҖйҡҫжҢҮе®ҡзҡ„ пјҢеӨ§дәҶпјҢеңҲдҪҸзҡ„е°ұеӨҡдәҶпјҢз°Үзҡ„дёӘж•°е°ұе°‘дәҶ;еҸҚд№ӢпјҢз°Үзҡ„дёӘж•°е°ұеӨҡдәҶпјҢиҝҷеҜ№жҲ‘们жңҖеҗҺзҡ„з»“жһңжҳҜжңүеҪұе“Қзҡ„гҖӮжҲ‘们иҝҷдёӘж—¶еҖҷKи·қзҰ»еҸҜд»Ҙеё®еҠ©жҲ‘们жқҘи®ҫе®ҡеҚҠеҫ„rпјҢд№ҹе°ұжҳҜиҰҒжүҫеҲ°зӘҒеҸҳзӮ№пјҢжҜ”еҰӮпјҡ д»ҘдёҠиҷҪ然жҳҜдёҖдёӘеҸҜеҸ–зҡ„ж–№ејҸпјҢдҪҶжҳҜжңүж—¶еҖҷжҜ”иҫғйә»зғҰ пјҢеӨ§йғЁеҲҶиҝҳжҳҜйғҪиҜ•дёҖиҜ•иҝӣиЎҢи§ӮеҜҹпјҢз”Ёkи·қзҰ»йңҖиҰҒеҒҡеӨ§йҮҸе®һйӘҢжқҘи§ӮеҜҹпјҢеҫҲйҡҫдёҖж¬ЎжҖ§жҠҠиҝҷдәӣеҖјйғҪйҖүеҮҶгҖӮ
MinPts:иҝҷдёӘеҸӮж•°е°ұжҳҜеңҲдҪҸзҡ„зӮ№зҡ„дёӘж•°пјҢд№ҹзӣёеҪ“дәҺжҳҜдёҖдёӘеҜҶеәҰпјҢдёҖиҲ¬иҝҷдёӘеҖјйғҪжҳҜеҒҸе°ҸдёҖдәӣпјҢ然еҗҺиҝӣиЎҢеӨҡж¬Ўе°қиҜ•
еӣӣгҖҒDBSCANз®—жі•иҝӯд»ЈеҸҜи§ҶеҢ–еұ•зӨә
еӣҪеӨ–жңүдёҖдёӘзү№еҲ«жңүж„ҸжҖқзҡ„зҪ‘з«ҷпјҢе®ғеҸҜд»ҘжҠҠжҲ‘们DBSCANзҡ„иҝӯд»ЈиҝҮзЁӢеҠЁжҖҒеӣҫз”»еҮәжқҘгҖӮ
зҪ‘еқҖпјҡnaftaliharris[1]
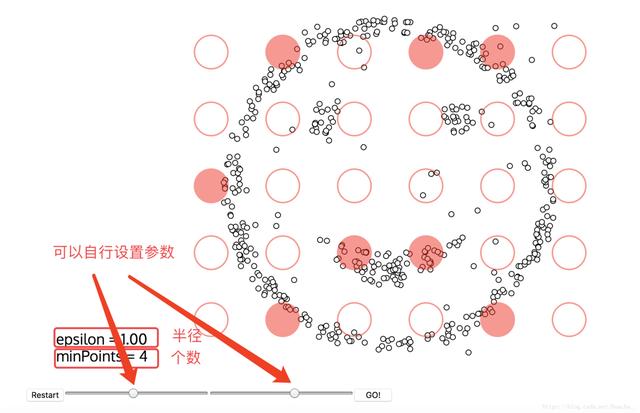
и®ҫзҪ®еҘҪеҸӮж•°пјҢзӮ№еҮ»GO! е°ұејҖе§ӢиҒҡзұ»дәҶ!
дә”гҖҒеёёз”ЁиҜ„дј°ж–№жі•пјҡиҪ®е»“зі»ж•°
иҝҷйҮҢжҸҗдёҖдёӢиҒҡзұ»з®—жі•дёӯжңҖеёёз”Ёзҡ„иҜ„дј°ж–№жі•——иҪ®е»“зі»ж•°(Silhouette Coefficient)пјҡ
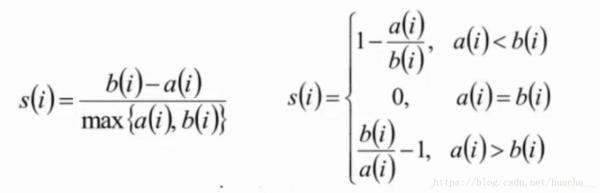
и®Ўз®—ж ·жң¬iеҲ°еҗҢз°Үе…¶е®ғж ·жң¬еҲ°е№іеқҮи·қзҰ»aiпјҢaiи¶Ҡе°ҸпјҢиҜҙжҳҺж ·жң¬iи¶Ҡеә”иҜҘиў«иҒҡзұ»еҲ°иҜҘз°Ү(е°Ҷaiз§°дёәж ·жң¬iеҲ°з°ҮеҶ…дёҚзӣёдјјеәҰ);
и®Ўз®—ж ·жң¬iеҲ°е…¶е®ғжҹҗз°ҮCjзҡ„жүҖжңүж ·жң¬зҡ„е№іеқҮи·қзҰ»bijпјҢз§°дёәж ·жң¬iдёҺз°ҮCjзҡ„дёҚзӣёдјјеәҰгҖӮе®ҡд№үдёәж ·жң¬iзҡ„з°Үй—ҙдёҚзӣёдјјеәҰпјҡbi=min(bi1,bi2,...,bik2);
иҜҙжҳҺпјҡ
siжҺҘиҝ‘1пјҢеҲҷиҜҙжҳҺж ·жң¬iиҒҡзұ»еҗҲзҗҶ;
siжҺҘиҝ‘-1пјҢеҲҷиҜҙжҳҺж ·жң¬iжӣҙеә”иҜҘеҲҶзұ»еҲ°еҸҰеӨ–зҡ„з°Ү;
иӢҘsiиҝ‘дјјдёә0пјҢеҲҷиҜҙжҳҺж ·жң¬iеңЁдёӨдёӘз°Үзҡ„иҫ№з•ҢдёҠ;
е…ӯгҖҒз”ЁPythonе®һзҺ°DBSCANиҒҡзұ»з®—жі•
еҜје…Ҙж•°жҚ®пјҡ
import pandas as pd from sklearn.datasets import load_iris # еҜје…Ҙж•°жҚ®,sklearnиҮӘеёҰйёўе°ҫиҠұж•°жҚ®йӣҶ iris = load_iris().data print(iris)
иҫ“еҮәпјҡ

дҪҝз”ЁDBSCANз®—жі•пјҡ
from sklearn.cluster import DBSCAN iris_db = DBSCAN(eps=0.6,min_samples=4).fit_predict(iris) # и®ҫзҪ®еҚҠеҫ„дёә0.6пјҢжңҖе°Ҹж ·жң¬йҮҸдёә2пјҢе»әжЁЎ db = DBSCAN(eps=10, min_samples=2).fit(iris) # з»ҹи®ЎжҜҸдёҖзұ»зҡ„ж•°йҮҸ counts = pd.value_counts(iris_db,sort=True) print(counts)

еҸҜи§ҶеҢ–пјҡ
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei'] fig,ax = plt.subplots(1,2,figsize=(12,12)) # з”»иҒҡзұ»еҗҺзҡ„з»“жһң ax1 = ax[0] ax1.scatter(x=iris[:,0],y=iris[:,1],s=250,c=iris_db) ax1.set_title('DBSCANиҒҡзұ»з»“жһң',fontsize=20) # з”»зңҹе®һж•°жҚ®з»“жһң ax2 = ax[1] ax2.scatter(x=iris[:,0],y=iris[:,1],s=250,c=load_iris().target) ax2.set_title('зңҹе®һеҲҶзұ»',fontsize=20) plt.show()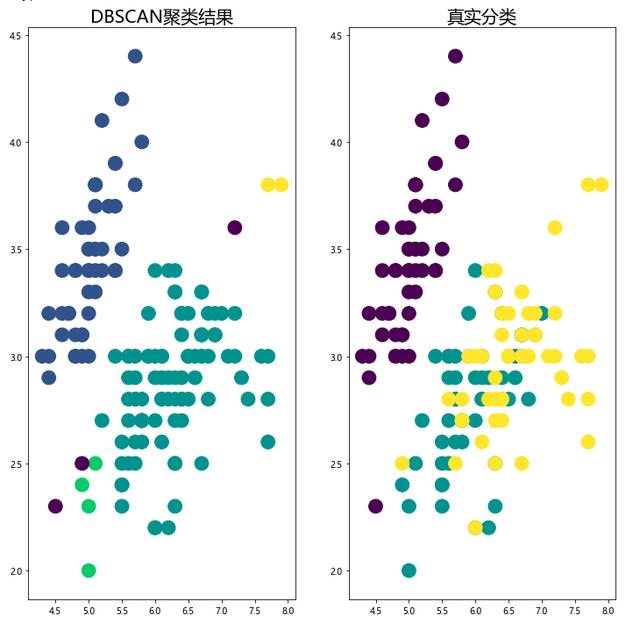
жҲ‘们еҸҜд»Ҙд»ҺдёҠйқўиҝҷдёӘеӣҫйҮҢи§ӮеҜҹиҒҡзұ»ж•Ҳжһңзҡ„еҘҪеқҸпјҢдҪҶжҳҜеҪ“ж•°жҚ®йҮҸеҫҲеӨ§пјҢжҲ–иҖ…жҢҮж ҮеҫҲеӨҡзҡ„ж—¶еҖҷпјҢи§ӮеҜҹиө·жқҘе°ұдјҡйқһеёёйә»зғҰгҖӮ
иҝҷж—¶еҖҷеҸҜд»ҘдҪҝз”ЁиҪ®е»“зі»ж•°жқҘеҲӨе®ҡз»“жһңеҘҪеқҸпјҢиҒҡзұ»з»“жһңзҡ„иҪ®е»“зі»ж•°пјҢе®ҡд№үдёәSпјҢжҳҜиҜҘиҒҡзұ»жҳҜеҗҰеҗҲзҗҶгҖҒжңүж•Ҳзҡ„еәҰйҮҸгҖӮ
иҒҡзұ»з»“жһңзҡ„иҪ®е»“зі»ж•°зҡ„еҸ–еҖјеңЁ[-1,1]д№Ӣй—ҙпјҢеҖји¶ҠеӨ§пјҢиҜҙжҳҺеҗҢзұ»ж ·жң¬зӣёи·қи¶Ҡиҝ‘пјҢдёҚеҗҢж ·жң¬зӣёи·қи¶ҠиҝңпјҢеҲҷиҒҡзұ»ж•Ҳжһңи¶ҠеҘҪгҖӮ
иҪ®е»“зі»ж•°д»ҘеҸҠе…¶д»–зҡ„иҜ„д»·еҮҪж•°йғҪе®ҡд№үеңЁsklearn.metricsжЁЎеқ—дёӯпјҢеңЁsklearnдёӯеҮҪж•°silhouette_score()и®Ўз®—жүҖжңүзӮ№зҡ„е№іеқҮиҪ®е»“зі»ж•°гҖӮ
from sklearn import metrics # е°ұжҳҜдёӢйқўиҝҷдёӘеҮҪж•°еҸҜд»Ҙи®Ўз®—иҪ®е»“зі»ж•°пјҲsklearnзңҹжҳҜдёҖдёӘејәеӨ§зҡ„еҢ…пјү score = metrics.silhouette_score(iris,iris_db) score
з»“жһңпјҡ 0.364
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎPythonдёӯжҖҺд№ҲеҲ©з”ЁDBSCANе®һзҺ°дёҖдёӘеҜҶеәҰиҒҡзұ»з®—жі•зҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ