жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңPythonжңүе“ӘдәӣејҖеҸ‘жҠҖе·§вҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңPythonжңүе“ӘдәӣејҖеҸ‘жҠҖе·§вҖқеҗ§пјҒ
1. еҰӮдҪ•еңЁиҝҗиЎҢзҠ¶жҖҒжҹҘзңӢжәҗд»Јз Ғ?
жҹҘзңӢеҮҪж•°зҡ„жәҗд»Јз ҒпјҢжҲ‘们йҖҡеёёдјҡдҪҝз”Ё IDE жқҘе®ҢжҲҗгҖӮ
жҜ”еҰӮеңЁ PyCharm дёӯпјҢдҪ еҸҜд»Ҙ Ctrl + йј ж ҮзӮ№еҮ» иҝӣе…ҘеҮҪж•°зҡ„жәҗд»Јз ҒгҖӮ
йӮЈеҰӮжһңжІЎжңү IDE е‘ў?
еҪ“жҲ‘们жғідҪҝз”ЁдёҖдёӘеҮҪж•°ж—¶пјҢеҰӮдҪ•зҹҘйҒ“иҝҷдёӘеҮҪж•°йңҖиҰҒжҺҘ收е“ӘдәӣеҸӮж•°е‘ў?
еҪ“жҲ‘们еңЁдҪҝз”ЁеҮҪж•°ж—¶еҮәзҺ°й—®йўҳзҡ„ж—¶еҖҷпјҢеҰӮдҪ•йҖҡиҝҮйҳ…иҜ»жәҗд»Јз ҒжқҘжҺ’жҹҘй—®йўҳжүҖеңЁе‘ў?
иҝҷж—¶еҖҷпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ё inspect жқҘд»Јжӣҝ IDE её®еҠ©дҪ е®ҢжҲҗиҝҷдәӣдәӢ
# demo.py import inspect def add(x, y): return x + y print("===================") print(inspect.getsource(add))иҝҗиЎҢз»“жһңеҰӮдёӢ
$ python demo.py =================== def add(x, y): return x + y
2. еҰӮдҪ•е…ій—ӯејӮеёёиҮӘеҠЁе…іиҒ”дёҠдёӢж–Ү?
еҪ“дҪ еңЁеӨ„зҗҶејӮеёёж—¶пјҢз”ұдәҺеӨ„зҗҶдёҚеҪ“жҲ–иҖ…е…¶д»–й—®йўҳпјҢеҶҚж¬ЎжҠӣеҮәеҸҰдёҖдёӘејӮеёёж—¶пјҢеҫҖеӨ–жҠӣеҮәзҡ„ејӮеёёд№ҹдјҡжҗәеёҰеҺҹе§Ӣзҡ„ејӮеёёдҝЎжҒҜгҖӮ
е°ұеғҸиҝҷж ·еӯҗгҖӮ
try: print(1 / 0) except Exception as exc: raise RuntimeError("Something bad happened")д»Һиҫ“еҮәеҸҜд»ҘзңӢеҲ°дёӨдёӘејӮеёёдҝЎжҒҜ
Traceback (most recent call last): File "demo.py", line 2, in <module> print(1 / 0) ZeroDivisionError: division by zero During handling of the above exception, another exception occurred: Traceback (most recent call last): File "demo.py", line 4, in <module> raise RuntimeError("Something bad happened") RuntimeError: Something bad happenedеҰӮжһңеңЁејӮеёёеӨ„зҗҶзЁӢеәҸжҲ– finally еқ—дёӯеј•еҸ‘ејӮеёёпјҢй»ҳи®Өжғ…еҶөдёӢпјҢејӮеёёжңәеҲ¶дјҡйҡҗејҸе·ҘдҪңдјҡе°Ҷе…ҲеүҚзҡ„ејӮеёёйҷ„еҠ дёәж–°ејӮеёёзҡ„ __context__еұһжҖ§гҖӮиҝҷе°ұжҳҜ Python й»ҳи®ӨејҖеҗҜзҡ„иҮӘеҠЁе…іиҒ”ејӮеёёдёҠдёӢж–ҮгҖӮ
еҰӮжһңдҪ жғіиҮӘе·ұжҺ§еҲ¶иҝҷдёӘдёҠдёӢж–ҮпјҢеҸҜд»ҘеҠ дёӘ from е…ій”®еӯ—(from иҜӯжі•дјҡжңүдёӘйҷҗеҲ¶пјҢе°ұжҳҜ第дәҢдёӘиЎЁиҫҫејҸеҝ…йЎ»жҳҜеҸҰдёҖдёӘејӮеёёзұ»жҲ–е®һдҫӢгҖӮ)пјҢжқҘиЎЁжҳҺдҪ зҡ„ж–°ејӮеёёжҳҜзӣҙжҺҘз”ұе“ӘдёӘејӮеёёеј•иө·зҡ„гҖӮ
try: print(1 / 0) except Exception as exc: raise RuntimeError("Something bad happened") from excиҫ“еҮәеҰӮдёӢ
Traceback (most recent call last): File "demo.py", line 2, in <module> print(1 / 0) ZeroDivisionError: division by zero The above exception was the direct cause of the following exception: Traceback (most recent call last): File "demo.py", line 4, in <module> raise RuntimeError("Something bad happened") from exc RuntimeError: Something bad happenedеҪ“然пјҢдҪ д№ҹеҸҜд»ҘйҖҡиҝҮwith_traceback()ж–№жі•дёәејӮеёёи®ҫзҪ®дёҠдёӢж–Ү__context__еұһжҖ§пјҢиҝҷд№ҹиғҪеңЁtracebackжӣҙеҘҪзҡ„жҳҫзӨәејӮеёёдҝЎжҒҜгҖӮ
try: print(1 / 0) except Exception as exc: raise RuntimeError("bad thing").with_traceback(exc)жңҖеҗҺпјҢеҰӮжһңжҲ‘жғіеҪ»еә•е…ій—ӯиҝҷдёӘиҮӘеҠЁе…іиҒ”ејӮеёёдёҠдёӢж–Үзҡ„жңәеҲ¶?жңүд»Җд№ҲеҠһжі•е‘ў?
еҸҜд»ҘдҪҝз”Ё raise...from NoneпјҢд»ҺдёӢйқўзҡ„дҫӢеӯҗдёҠзңӢпјҢе·Із»ҸжІЎжңүдәҶеҺҹе§ӢејӮеёё
$ cat demo.py try: print(1 / 0) except Exception as exc: raise RuntimeError("Something bad happened") from None $ $ python demo.py Traceback (most recent call last): File "demo.py", line 4, in <module> raise RuntimeError("Something bad happened") from None RuntimeError: Something bad happened (PythonCodingTime)03. жңҖеҝ«жҹҘзңӢеҢ…жҗңзҙўи·Ҝеҫ„зҡ„ж–№ејҸ
еҪ“дҪ дҪҝз”Ё import еҜје…ҘдёҖдёӘеҢ…жҲ–жЁЎеқ—ж—¶пјҢPython дјҡеҺ»дёҖдәӣзӣ®еҪ•дёӢжҹҘжүҫпјҢиҖҢиҝҷдәӣзӣ®еҪ•жҳҜжңүдјҳе…Ҳзә§йЎәеәҸзҡ„пјҢжӯЈеёёдәәдјҡдҪҝз”Ё sys.path жҹҘзңӢгҖӮ
>>> import sys >>> from pprint import pprint >>> pprint(sys.path) ['', '/usr/local/Python3.7/lib/python37.zip', '/usr/local/Python3.7/lib/python3.7', '/usr/local/Python3.7/lib/python3.7/lib-dynload', '/home/wangbm/.local/lib/python3.7/site-packages', '/usr/local/Python3.7/lib/python3.7/site-packages'] >>>
йӮЈжңүжІЎжңүжӣҙеҝ«зҡ„ж–№ејҸе‘ў?
жҲ‘иҝҷжңүдёҖз§Қиҝһ console жЁЎејҸйғҪдёҚз”Ёиҝӣе…Ҙзҡ„ж–№жі•е‘ў?
дҪ еҸҜиғҪдјҡжғіеҲ°иҝҷз§ҚпјҢдҪҶиҝҷжң¬иҙЁдёҠдёҺдёҠйқўе№¶ж— еҢәеҲ«
[wangbm@localhost ~]$ python -c "print('\n'.join(__import__('sys').path))" /usr/lib/python2.7/site-packages/pip-18.1-py2.7.egg /usr/lib/python2.7/site-packages/redis-3.0.1-py2.7.egg /usr/lib64/python27.zip /usr/lib64/python2.7 /usr/lib64/python2.7/plat-linux2 /usr/lib64/python2.7/lib-tk /usr/lib64/python2.7/lib-old /usr/lib64/python2.7/lib-dynload /home/wangbm/.local/lib/python2.7/site-packages /usr/lib64/python2.7/site-packages /usr/lib64/python2.7/site-packages/gtk-2.0 /usr/lib/python2.7/site-packagesиҝҷйҮҢжҲ‘иҰҒд»Ӣз»Қзҡ„жҳҜжҜ”дёҠйқўдёӨз§ҚйғҪж–№дҫҝзҡ„еӨҡзҡ„ж–№жі•пјҢдёҖиЎҢе‘Ҫд»ӨеҚіеҸҜи§ЈеҶі
[wangbm@localhost ~]$ python3 -m site sys.path = [ '/home/wangbm', '/usr/local/Python3.7/lib/python37.zip', '/usr/local/Python3.7/lib/python3.7', '/usr/local/Python3.7/lib/python3.7/lib-dynload', '/home/wangbm/.local/lib/python3.7/site-packages', '/usr/local/Python3.7/lib/python3.7/site-packages', ] USER_BASE: '/home/wangbm/.local' (exists) USER_SITE: '/home/wangbm/.local/lib/python3.7/site-packages' (exists) ENABLE_USER_SITE: True
д»Һиҫ“еҮәдҪ еҸҜд»ҘеҸ‘зҺ°пјҢиҝҷдёӘеҲ—зҡ„и·Ҝеҫ„дјҡжҜ” sys.path жӣҙе…ЁпјҢе®ғеҢ…еҗ«дәҶз”ЁжҲ·зҺҜеўғзҡ„зӣ®еҪ•гҖӮ
4. е°ҶеөҢеҘ— for еҫӘзҺҜеҶҷжҲҗеҚ•иЎҢ
жҲ‘们з»ҸеёёдјҡеҰӮдёӢиҝҷз§ҚеөҢеҘ—зҡ„ for еҫӘзҺҜд»Јз Ғ
list1 = range(1,3) list2 = range(4,6) list3 = range(7,9) for item1 in list1: for item2 in list2: for item3 in list3: print(item1+item2+item3)
иҝҷйҮҢд»…д»…жҳҜдёүдёӘ for еҫӘзҺҜпјҢеңЁе®һйҷ…зј–з ҒдёӯпјҢжңүеҸҜиғҪдјҡжңүжӣҙеұӮгҖӮ
иҝҷж ·зҡ„д»Јз ҒпјҢеҸҜиҜ»жҖ§йқһеёёзҡ„е·®пјҢеҫҲеӨҡдәәдёҚжғіиҝҷд№ҲеҶҷпјҢеҸҜеҸҲжІЎжңүжӣҙеҘҪзҡ„еҶҷжі•гҖӮ
иҝҷйҮҢд»Ӣз»ҚдёҖз§ҚжҲ‘еёёз”Ёзҡ„еҶҷжі•пјҢдҪҝз”Ё itertools иҝҷдёӘеә“жқҘе®һзҺ°жӣҙдјҳйӣ…жҳ“иҜ»зҡ„д»Јз ҒгҖӮ
from itertools import product list1 = range(1,3) list2 = range(4,6) list3 = range(7,9) for item1,item2,item3 in product(list1, list2, list3): print(item1+item2+item3)
иҫ“еҮәеҰӮдёӢ
$ python demo.py 12 13 13 14 13 14 14 15
5. еҰӮдҪ•дҪҝз”Ё print иҫ“еҮәж—Ҙеҝ—
еҲқеӯҰиҖ…е–ңж¬ўдҪҝз”Ё print жқҘи°ғиҜ•д»Јз ҒпјҢ并记еҪ•зЁӢеәҸиҝҗиЎҢиҝҮзЁӢгҖӮ
дҪҶжҳҜ print еҸӘдјҡе°ҶеҶ…е®№иҫ“еҮәеҲ°з»Ҳз«ҜдёҠпјҢдёҚиғҪжҢҒд№…еҢ–еҲ°ж—Ҙеҝ—ж–Ү件дёӯпјҢ并дёҚеҲ©дәҺй—®йўҳзҡ„жҺ’жҹҘгҖӮ
еҰӮжһңдҪ зғӯиЎ·дәҺдҪҝз”Ё print жқҘи°ғиҜ•д»Јз Ғ(иҷҪ然иҝҷ并дёҚжҳҜжңҖдҪіеҒҡжі•)пјҢи®°еҪ•зЁӢеәҸиҝҗиЎҢиҝҮзЁӢпјҢйӮЈд№ҲдёӢйқўд»Ӣз»Қзҡ„иҝҷдёӘ print з”Ёжі•пјҢеҸҜиғҪдјҡеҜ№дҪ жңүз”ЁгҖӮ
Python 3 дёӯзҡ„ print дҪңдёәдёҖдёӘеҮҪж•°пјҢз”ұдәҺеҸҜд»ҘжҺҘ收жӣҙеӨҡзҡ„еҸӮж•°пјҢжүҖд»ҘеҠҹиғҪеҸҳдёәжӣҙеҠ ејәеӨ§пјҢжҢҮе®ҡдёҖдәӣеҸӮж•°еҸҜд»Ҙе°Ҷ print зҡ„еҶ…е®№иҫ“еҮәеҲ°ж—Ҙеҝ—ж–Ү件дёӯ
д»Јз ҒеҰӮдёӢпјҡ
>>> with open('test.log', mode='w') as f: ... print('hello, python', file=f, flush=True) >>> exit() $ cat test.log hello, python6. еҰӮдҪ•еҝ«йҖҹи®Ўз®—еҮҪж•°иҝҗиЎҢж—¶й—ҙ
и®Ўз®—дёҖдёӘеҮҪж•°зҡ„иҝҗиЎҢж—¶й—ҙпјҢдҪ еҸҜиғҪдјҡиҝҷж ·еӯҗеҒҡ
import time start = time.time() # run the function end = time.time() print(end-start)
дҪ зңӢзңӢдҪ дёәдәҶи®Ўз®—еҮҪж•°иҝҗиЎҢж—¶й—ҙпјҢеҶҷдәҶеҮ иЎҢд»Јз ҒдәҶгҖӮ
жңүжІЎжңүдёҖз§Қж–№жі•еҸҜд»Ҙжӣҙж–№дҫҝзҡ„и®Ўз®—иҝҷдёӘиҝҗиЎҢж—¶й—ҙе‘ў?
жңүгҖӮ
жңүдёҖдёӘеҶ…зҪ®жЁЎеқ—еҸ« timeit
дҪҝз”Ёе®ғпјҢеҸӘз”ЁдёҖиЎҢд»Јз ҒеҚіеҸҜ
import time import timeit def run_sleep(second): print(second) time.sleep(second) # еҸӘз”ЁиҝҷдёҖиЎҢ print(timeit.timeit(lambda :run_sleep(2), number=5))
иҝҗиЎҢз»“жһңеҰӮдёӢ
2 2 2 2 2 10.020059824
7. еҲ©з”ЁиҮӘеёҰзҡ„зј“еӯҳжңәеҲ¶жҸҗй«ҳж•ҲзҺҮ
зј“еӯҳжҳҜдёҖз§Қе°Ҷе®ҡйҮҸж•°жҚ®еҠ д»ҘдҝқеӯҳпјҢд»ҘеӨҮиҝҺеҗҲеҗҺз»ӯиҺ·еҸ–йңҖжұӮзҡ„еӨ„зҗҶж–№ејҸпјҢж—ЁеңЁеҠ еҝ«ж•°жҚ®иҺ·еҸ–зҡ„йҖҹеәҰгҖӮ
ж•°жҚ®зҡ„з”ҹжҲҗиҝҮзЁӢеҸҜиғҪйңҖиҰҒз»ҸиҝҮи®Ўз®—пјҢ规ж•ҙпјҢиҝңзЁӢиҺ·еҸ–зӯүж“ҚдҪңпјҢеҰӮжһңжҳҜеҗҢдёҖд»Ҫж•°жҚ®йңҖиҰҒеӨҡж¬ЎдҪҝз”ЁпјҢжҜҸж¬ЎйғҪйҮҚж–°з”ҹжҲҗдјҡеӨ§еӨ§жөӘиҙ№ж—¶й—ҙгҖӮжүҖд»ҘпјҢеҰӮжһңе°Ҷи®Ўз®—жҲ–иҖ…иҝңзЁӢиҜ·жұӮзӯүж“ҚдҪңиҺ·еҫ—зҡ„ж•°жҚ®зј“еӯҳдёӢжқҘпјҢдјҡеҠ еҝ«еҗҺз»ӯзҡ„ж•°жҚ®иҺ·еҸ–йңҖжұӮгҖӮ
дёәдәҶе®һзҺ°иҝҷдёӘйңҖжұӮпјҢPython 3.2 + дёӯз»ҷжҲ‘们жҸҗдҫӣдәҶдёҖдёӘжңәеҲ¶пјҢеҸҜд»ҘеҫҲж–№дҫҝзҡ„е®һзҺ°пјҢиҖҢдёҚйңҖиҰҒдҪ еҺ»еҶҷиҝҷж ·зҡ„йҖ»иҫ‘д»Јз ҒгҖӮ
иҝҷдёӘжңәеҲ¶е®һзҺ°дәҺ functool жЁЎеқ—дёӯзҡ„ lru_cache иЈ…йҘ°еҷЁгҖӮ
@functools.lru_cache(maxsize=None, typed=False)
еҸӮж•°и§ЈиҜ»пјҡ
maxsizeпјҡжңҖеӨҡеҸҜд»Ҙзј“еӯҳеӨҡе°‘дёӘжӯӨеҮҪж•°зҡ„и°ғз”Ёз»“жһңпјҢеҰӮжһңдёәNoneпјҢеҲҷж— йҷҗеҲ¶пјҢи®ҫзҪ®дёә 2 зҡ„е№Ӯж—¶пјҢжҖ§иғҪжңҖдҪі
typedпјҡиӢҘдёә TrueпјҢеҲҷдёҚеҗҢеҸӮж•°зұ»еһӢзҡ„и°ғз”Ёе°ҶеҲҶеҲ«зј“еӯҳгҖӮ
дёҫдёӘдҫӢеӯҗ
from functools import lru_cache @lru_cache(None) def add(x, y): print("calculating: %s + %s" % (x, y)) return x + y print(add(1, 2)) print(add(1, 2)) print(add(2, 3))иҫ“еҮәеҰӮдёӢпјҢеҸҜд»ҘзңӢеҲ°з¬¬дәҢж¬Ўи°ғ用并没жңүзңҹжӯЈзҡ„жү§иЎҢеҮҪж•°дҪ“пјҢиҖҢжҳҜзӣҙжҺҘиҝ”еӣһзј“еӯҳйҮҢзҡ„з»“жһң
calculating: 1 + 2 3 3 calculating: 2 + 3 5
дёӢйқўиҝҷдёӘжҳҜз»Ҹе…ёзҡ„ж–җжіўйӮЈеҘ‘ж•°еҲ—пјҢеҪ“дҪ жҢҮе®ҡзҡ„ n иҫғеӨ§ж—¶пјҢдјҡеӯҳеңЁеӨ§йҮҸзҡ„йҮҚеӨҚи®Ўз®—
def fib(n): if n < 2: return n return fib(n - 2) + fib(n - 1)
第е…ӯзӮ№д»Ӣз»Қзҡ„ timeitпјҢзҺ°еңЁеҸҜд»Ҙз”Ёе®ғжқҘжөӢиҜ•дёҖдёӢеҲ°еә•еҸҜд»ҘжҸҗй«ҳеӨҡе°‘зҡ„ж•ҲзҺҮгҖӮ
дёҚдҪҝз”Ё lru_cache зҡ„жғ…еҶөдёӢпјҢиҝҗиЎҢж—¶й—ҙ 31 з§’
import timeit def fib(n): if n < 2: return n return fib(n - 2) + fib(n - 1) print(timeit.timeit(lambda :fib(40), number=1)) # output: 31.2725698948
з”ұдәҺдҪҝз”ЁдәҶ lru_cache еҗҺпјҢиҝҗиЎҢйҖҹеәҰе®һеңЁеӨӘеҝ«дәҶпјҢжүҖд»ҘжҲ‘е°Ҷ n еҖјз”ұ 30 и°ғеҲ° 500пјҢеҸҜеҚідҪҝжҳҜиҝҷж ·пјҢиҝҗиЎҢж—¶й—ҙд№ҹжүҚ 0.0004 з§’гҖӮжҸҗй«ҳйҖҹеәҰйқһеёёжҳҫи‘—гҖӮ
import timeit from functools import lru_cache @lru_cache(None) def fib(n): if n < 2: return n return fib(n - 2) + fib(n - 1) print(timeit.timeit(lambda :fib(500), number=1)) # output: 0.0004921059880871326
8. еңЁзЁӢеәҸйҖҖеҮәеүҚжү§иЎҢд»Јз Ғзҡ„жҠҖе·§
дҪҝз”Ё atexit иҝҷдёӘеҶ…зҪ®жЁЎеқ—пјҢеҸҜд»ҘеҫҲж–№дҫҝзҡ„жіЁеҶҢйҖҖеҮәеҮҪж•°гҖӮ
дёҚз®ЎдҪ еңЁе“ӘдёӘең°ж–№еҜјиҮҙзЁӢеәҸеҙ©жәғпјҢйғҪдјҡжү§иЎҢйӮЈдәӣдҪ жіЁеҶҢиҝҮзҡ„еҮҪж•°гҖӮ
зӨәдҫӢеҰӮдёӢ
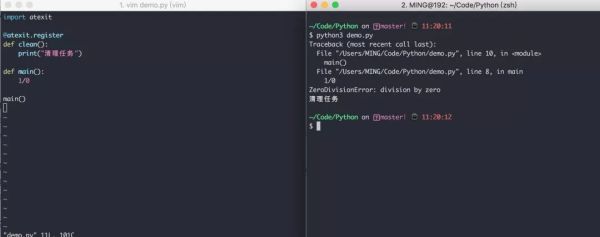
еҰӮжһңclean()еҮҪж•°жңүеҸӮж•°пјҢйӮЈд№ҲдҪ еҸҜд»ҘдёҚз”ЁиЈ…йҘ°еҷЁпјҢиҖҢжҳҜзӣҙжҺҘи°ғз”Ёatexit.register(clean_1, еҸӮж•°1, еҸӮж•°2, еҸӮж•°3='xxx')гҖӮ
еҸҜиғҪдҪ жңүе…¶д»–ж–№жі•еҸҜд»ҘеӨ„зҗҶиҝҷз§ҚйңҖжұӮпјҢдҪҶиӮҜе®ҡжҜ”дёҠдёҚдҪҝз”Ё atexit жқҘеҫ—дјҳйӣ…пјҢжқҘеҫ—ж–№дҫҝпјҢ并且е®ғеҫҲе®№жҳ“жү©еұ•гҖӮ
дҪҶжҳҜдҪҝз”Ё atexit д»Қ然жңүдёҖдәӣеұҖйҷҗжҖ§пјҢжҜ”еҰӮпјҡ
еҰӮжһңзЁӢеәҸжҳҜиў«дҪ жІЎжңүеӨ„зҗҶиҝҮзҡ„зі»з»ҹдҝЎеҸ·жқҖжӯ»зҡ„пјҢйӮЈд№ҲжіЁеҶҢзҡ„еҮҪж•°ж— жі•жӯЈеёёжү§иЎҢгҖӮ
еҰӮжһңеҸ‘з”ҹдәҶдёҘйҮҚзҡ„ Python еҶ…йғЁй”ҷиҜҜпјҢдҪ жіЁеҶҢзҡ„еҮҪж•°ж— жі•жӯЈеёёжү§иЎҢгҖӮ
еҰӮжһңдҪ жүӢеҠЁи°ғз”ЁдәҶos._exit()пјҢдҪ жіЁеҶҢзҡ„еҮҪж•°ж— жі•жӯЈеёёжү§иЎҢгҖӮ
9. е®һзҺ°зұ»дјј defer зҡ„延иҝҹи°ғз”Ё
еңЁ Golang дёӯжңүдёҖз§Қ延иҝҹи°ғз”Ёзҡ„жңәеҲ¶пјҢе…ій”®еӯ—жҳҜ deferпјҢдҫӢеҰӮдёӢйқўзҡ„зӨәдҫӢ
import "fmt" func myfunc() { fmt.Println("B") } func main() { defer myfunc() fmt.Println("A") }иҫ“еҮәеҰӮдёӢпјҢmyfunc зҡ„и°ғз”ЁдјҡеңЁеҮҪж•°иҝ”еӣһеүҚдёҖжӯҘе®ҢжҲҗпјҢеҚідҪҝдҪ е°Ҷ myfunc зҡ„и°ғз”ЁеҶҷеңЁеҮҪж•°зҡ„第дёҖиЎҢпјҢиҝҷе°ұжҳҜ延иҝҹи°ғз”ЁгҖӮ
A B
йӮЈд№ҲеңЁ Python дёӯеҗҰжңүиҝҷз§ҚжңәеҲ¶е‘ў?
еҪ“然д№ҹжңүпјҢеҸӘдёҚиҝҮ并没жңү Golang иҝҷз§Қз®ҖдҫҝгҖӮ
еңЁ Python еҸҜд»ҘдҪҝз”Ё дёҠдёӢж–Үз®ЎзҗҶеҷЁ иҫҫеҲ°иҝҷз§Қж•Ҳжһң
import contextlib def callback(): print('B') with contextlib.ExitStack() as stack: stack.callback(callback) print('A')иҫ“еҮәеҰӮдёӢ
A B
10. еҰӮдҪ•жөҒејҸиҜ»еҸ–ж•°Gи¶…еӨ§ж–Ү件
дҪҝз”Ё with...open... еҸҜд»Ҙд»ҺдёҖдёӘж–Ү件дёӯиҜ»еҸ–ж•°жҚ®пјҢиҝҷжҳҜжүҖжңү Python ејҖеҸ‘иҖ…йғҪйқһеёёзҶҹжӮүзҡ„ж“ҚдҪңгҖӮ
дҪҶжҳҜеҰӮжһңдҪ дҪҝз”ЁдёҚеҪ“пјҢд№ҹдјҡеёҰжқҘеҫҲеӨ§зҡ„йә»зғҰгҖӮ
жҜ”еҰӮеҪ“дҪ дҪҝз”ЁдәҶ read еҮҪж•°пјҢе…¶е®һ Python дјҡе°Ҷж–Ү件зҡ„еҶ…е®№дёҖж¬ЎжҖ§зҡ„е…ЁйғЁиҪҪе…ҘеҶ…еӯҳдёӯпјҢеҰӮжһңж–Ү件жңү 10 дёӘGз”ҡиҮіжӣҙеӨҡпјҢйӮЈд№ҲдҪ зҡ„з”өи„‘е°ұиҰҒж¶ҲиҖ—зҡ„еҶ…еӯҳйқһеёёе·ЁеӨ§гҖӮ
# дёҖж¬ЎжҖ§иҜ»еҸ– with open("big_file.txt", "r") as fp: content = fp.read()еҜ№дәҺиҝҷдёӘй—®йўҳпјҢдҪ д№ҹи®ёдјҡжғіеҲ°дҪҝз”Ё readline еҺ»еҒҡдёҖдёӘз”ҹжҲҗеҷЁжқҘйҖҗиЎҢиҝ”еӣһгҖӮ
def read_from_file(filename): with open(filename, "r") as fp: yield fp.readline()
еҸҜеҰӮжһңиҝҷдёӘж–Ү件еҶ…е®№е°ұдёҖиЎҢе‘ўпјҢдёҖиЎҢе°ұ 10дёӘGпјҢе…¶е®һдҪ иҝҳжҳҜдјҡдёҖж¬ЎжҖ§иҜ»еҸ–е…ЁйғЁеҶ…е®№гҖӮ
жңҖдјҳйӣ…зҡ„и§ЈеҶіж–№жі•жҳҜпјҢеңЁдҪҝз”Ё read ж–№жі•ж—¶пјҢжҢҮе®ҡжҜҸж¬ЎеҸӘиҜ»еҸ–еӣәе®ҡеӨ§е°Ҹзҡ„еҶ…е®№пјҢжҜ”еҰӮдёӢйқўзҡ„д»Јз ҒдёӯпјҢжҜҸж¬ЎеҸӘиҜ»еҸ– 8kb иҝ”еӣһгҖӮ
def read_from_file(filename, block_size = 1024 * 8): with open(filename, "r") as fp: while True: chunk = fp.read(block_size) if not chunk: break yield chunk
дёҠйқўзҡ„д»Јз ҒпјҢеҠҹиғҪдёҠе·Із»ҸжІЎжңүй—®йўҳдәҶпјҢдҪҶжҳҜд»Јз ҒзңӢиө·жқҘд»Јз ҒиҝҳжҳҜжңүдәӣиҮғиӮҝгҖӮ
еҖҹеҠ©еҒҸеҮҪж•° е’Ң iter еҮҪж•°еҸҜд»ҘдјҳеҢ–дёҖдёӢд»Јз Ғ
from functools import partial def read_from_file(filename, block_size = 1024 * 8): with open(filename, "r") as fp: for chunk in iter(partial(fp.read, block_size), ""): yield chunk
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңPythonжңүе“ӘдәӣејҖеҸ‘жҠҖе·§вҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№Pythonжңүе“ӘдәӣејҖеҸ‘жҠҖе·§иҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ