您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“Dom树的重建方法教程”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Dom树的重建方法教程”吧!
这种情况下,通用爬虫一般会分成几个不同的部分,如下图所示:
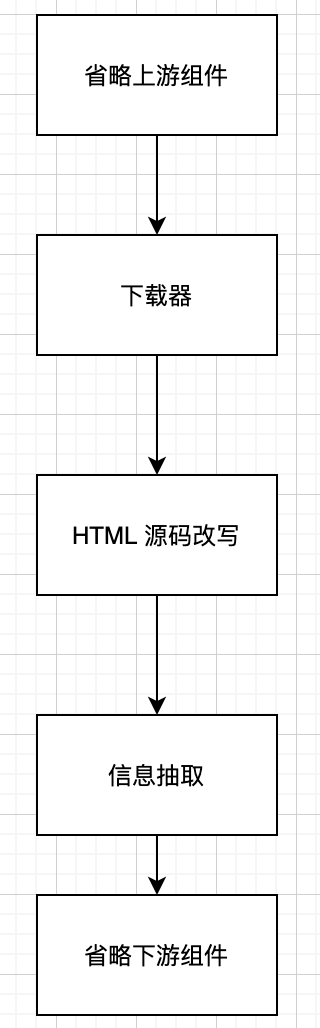
其中,HTML 源码改写这一个组件,会根据一定的策略对网页源代码进行修改,剔除无关的节点,合并复杂但没有必要的嵌套节点……改写以后,输出相对标准和统一的 HTML,传给下游的信息抽取组件进行内容抽取。
这位同学的问题,就涉及到对源代码进行改写。实际上,使用 lxml 在 DOM 树中插入一个节点,这本来根本不是什么问题。任何一个会使用 Google 的同学,只要搜索lxml html insert element,自然就能找到大量的解决方法,如下图所示:
但是,这个问题怪就怪在,它需要在文本节点的前面增加子节点。干讲可能不好描述,我用一个例子来说明这个问题。
大家先来看这段代码:
from lxml.html import fromstring, Element, etree from html import unescape html = ''' <div> <p>你好</p> </div> ''' node = fromstring(html) p_node = node.find('.//p') element = Element('span') element.text = '青南' p_node.insert(0, element) new_html = unescape(etree.tostring(node).decode()) print(new_html)根据我们使用 Python 列表的经验,如果一个列表a现在是['你好'],当我们执行a.insert(0, '青南')以后,得到的结果应该是['青南', '你好']。但是我们来看看上面这段代码的运行效果:
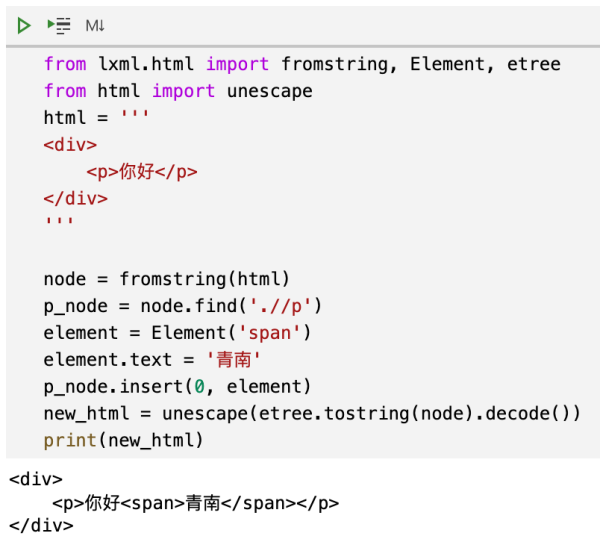
可以看到,青南是在你好后面的。大家再看本文最开头的图,提问者举出的例子中,他希望把子节点插入到文本之前。具体到这个例子中,应该是青南你好。
大家可以试一试,你在 Google 上面无论怎么搜索,都找不到如何把节点插入到文本前面的方法。
但实际上,只要回归官方文档,你就会发现整个问题的解决方法并不困难。我们需要使用的,是lxml.html.builder[1]。
还是上面的例子,如何把 span 标签弄到文本前面呢?我们用 builder来实现:
from lxml.html import builder from html import unescape html = ''' <div></div> ''' node = fromstring(html) new_node = builder.P(builder.SPAN('青南'), '你好') node.append(new_node) new_html = unescape(etree.tostring(node).decode()) print(new_html)运行效果如下图所示:
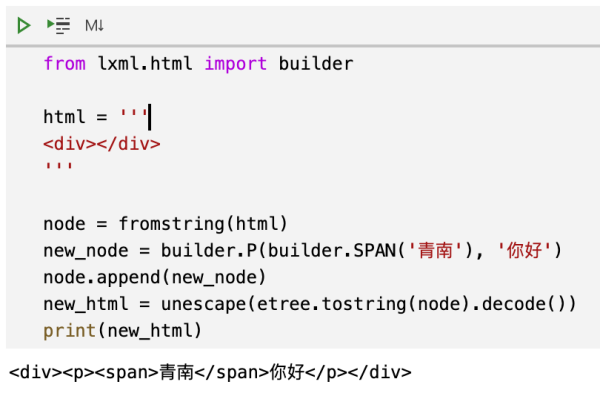
看到这里,可能有同学会觉得我在耍无赖。这就像是让我写一个程序,计算斐波那契数列前5项的值,于是我5秒钟写出了答案print(1, 1, 2, 3, 5)。上面的代码中,我直接使用builder.P(builder.SPAN('青南'), '你好'),这跟直接写<p><span>青南</span>你好</p>有什么区别?这不是在作弊吗?
我知道你很不服气,但是,这就是真实的情况。通用爬虫在做 HTML源码改写的时候,就是这样做的。因为直接对网页的 Dom 树进行改写是非常麻烦的事情。如果直接修改 Dom 树,经常会出现需要找一个节点的父节点,然后再找父节点的兄弟节点的子节点进行修改。或者要判断某个节点是否有子节点,有和没有,需要两种逻辑来处理,才能防止破坏 Dom 树。
所以,我们一般不会直接修改 Dom 树,而是一边扫描原始的 Dom 树,一边使用 builder 重建一个新的 Dom 树。重建 Dom 树的过程比修改 Dom 树的过程要简单很多,毕竟写过代码的人都知道,写新代码比改别人的代码容易很多。
感谢各位的阅读,以上就是“Dom树的重建方法教程”的内容了,经过本文的学习后,相信大家对Dom树的重建方法教程这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。