您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“如何理解序列化”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
本文主要内容

背景
在Java语言中,程序运行的时候,会产生很多对象,而对象信息也只是在程序运行的时候才在内存中保持其状态,一旦程序停止,内存释放,对象也就不存在了。
怎么能让对象永久的保存下来呢?--------对象序列化 。
何为序列化和反序列化?
序列化:对象到IO数据流

反序列化:IO数据流到对象

有哪些使用场景?
Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能。
使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的"状态",即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
除了在持久化对象时会用到对象序列化之外,当使用RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。
Java序列化API为处理对象序列化提供了一个标准机制,该API简单易用。
很多框架中都有用到,比如典型的dubbo框架中使用了序列化。
序列化有什么作用?
序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
序列化实现方式
Java语言中,常见实现序列化的方式有两种:
实现Serializable接口
实现Externalizable接口
下面我们就来详细的说说这两种实现方式。
实现Serializable接口
创建一个User类实现Serializable接口 ,实现序列化,大致步骤为:
鸿蒙官方战略合作共建——HarmonyOS技术社区
对象实体类实现Serializable 标记接口。
创建序列化输出流对象ObjectOutputStream,该对象的创建依赖于其它输出流对象,通常我们将对象序列化为文件存储,所以这里用文件相关的输出流对象 FileOutputStream。
通过ObjectOutputStream 的 writeObject()方法将对象序列化为文件。
关闭流。
以下就是code:
package com.tian.my_code.test.clone; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.io.Serializable; public class User implements Serializable { private int age; private String name; public User() { } public User(int age, String name) { this.age = age; this.name = name; } //set get省略 public static void main(String[] args) { try { ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt")); User user=new User(22,"老田"); objectOutputStream.writeObject(user); } catch (IOException e) { e.printStackTrace(); } } }创建一个User对象,然后把User对象保存的user.txt中了。
反序列化
大致有以下三个步骤:
鸿蒙官方战略合作共建——HarmonyOS技术社区
创建输入流对象ObjectOutputStream。同样依赖于其它输入流对象,这里是文件输入流 FileInputStream。
通过 ObjectInputStream 的 readObject()方法,将文件中的对象读取到内存。
关闭流。
下面我们再进行反序列化code:
package com.tian.my_code.test.clone; import java.io.*; public class SeriTest { public static void main(String[] args) { try { ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.txt")); User user=(User) ois.readObject(); System.out.println(user.getName()); } catch (Exception e) { e.printStackTrace(); } } }运行这段代码,输出结果:

使用IDEA打开user.tst文件:

使用编辑器16机制查看
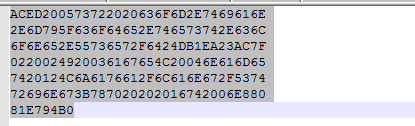
关于文件内容咱们就不用太关心了,继续说我们的重点。
序列化是把User对象存放到文件里了,然后反序列化就是读取文件内容并创建对象。
A端把对象User保存到文件user.txt中,B端就可以通过网络或者其他方式读取到这个文件,再进行反序列化,获得A端创建的User对象。
拓展
如果B端拿到的User属性如果有变化呢?比如说:增加一个字段
private String address;
再次进行反序列化就会报错

添加serialVersionUID
package com.tian.my_code.test.clone; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.io.Serializable; public class User implements Serializable{ private static final long serialVersionUID = 2012965743695714769L; private int age; private String name; public User() { } public User(int age, String name) { this.age = age; this.name = name; } // set get 省略 public static void main(String[] args) { try { ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt")); User user=new User(22,"老田"); objectOutputStream.writeObject(user); } catch (IOException e) { e.printStackTrace(); } } }再次执行反序列化,运行结果正常

然后我们再次加上字段和对应的get/set方法
private String address;
再次执行反序列化

反序列化成功。
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java(TM) 对象序列化规范”中所述。
不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。
因此,为保证 serialVersionUID值跨不同 Java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID值。
强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 -- serialVersionUID字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID值的要求。
所以,尽量显示的声明,这样序列化的类即使有字段的修改,因为 serialVersionUID的存在,也能保证反序列化成功。保证了更好的兼容性。
IDEA中如何快捷添加serialVersionUID?
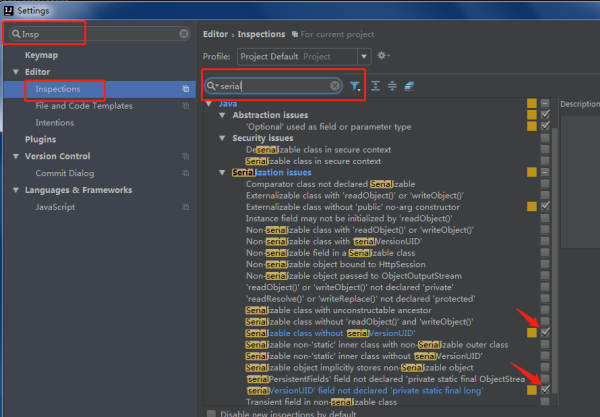
我们的类实现Serializable接口,鼠标放在类上,Alt+Enter键就可以添加了。
实现Externalizable接口
通过实现Externalizable接口,必须实现writeExternal、readExternal方法。

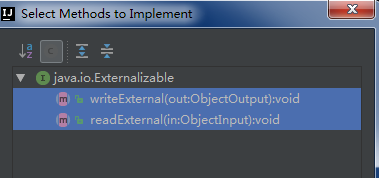
@Override public void writeExternal(ObjectOutput out) throws IOException { } @Override public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { }Externalizable是Serializable的子接口。
public interface Externalizable extends java.io.Serializable {
继续使用前面的User,代码进行改造:
package com.tian.my_code.test.clone; import java.io.*; public class User implements Externalizable { private int age; private String name; public User() { } public User(int age, String name) { this.age = age; this.name = name; } //set get public static void main(String[] args) { try { ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt")); User user = new User(22, "老田"); objectOutputStream.writeObject(user); } catch (IOException e) { e.printStackTrace(); } } @Override public void writeExternal(ObjectOutput out) throws IOException { //将name反转后写入二进制流 StringBuffer reverse = new StringBuffer(name).reverse(); out.writeObject(reverse); out.writeInt(age); } @Override public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { //将读取的字符串反转后赋值给name实例变量 this.name = ((StringBuffer) in.readObject()).reverse().toString(); //将读取到的int类型值付给age this.age = in.readInt(); } }执行序列化,然后再次执行反序列化,输出:

注意
Externalizable接口不同于Serializable接口,实现此接口必须实现接口中的两个方法实现自定义序列化,这是强制性的;特别之处是必须提供public的无参构造器,因为在反序列化的时候需要反射创建对象。
两种方式对比
下图为两种实现方式的对比:

序列化只有两种方式吗?
当然不是。根据序列化的定义,不管通过什么方式,只要你能把内存中的对象转换成能存储或传输的方式,又能反过来恢复它,其实都可以称为序列化。因此,我们常用的Fastjson、Jackson等第三方类库将对象转成Json格式文件,也可以算是一种序列化,用JAXB实现XML格式文件输出,也可以算是序列化。所以,千万不要被思维局限,其实现实当中我们进行了很多序列化和反序列化的操作,涉及不同的形态、数据格式等。
序列化算法
所有保存到磁盘的对象都有一个序列化编码号。
当程序试图序列化一个对象时,会先检查此对象是否已经序列化过,只有此对象从未(在此虚拟机)被序列化过,才会将此对象序列化为字节序列输出。
如果此对象已经序列化过,则直接输出编号即可。
自定义序列化
有些时候,我们有这样的需求,某些属性不需要序列化。使用transient关键字选择不需要序列化的字段。
继续使用前面的代码进行改造,在age字段上添加transient修饰:
package com.tian.my_code.test.clone; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.io.Serializable; public class User implements Serializable{ private transient int age; private String name; public User() { } public User(int age, String name) { this.age = age; this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public static void main(String[] args) { try { ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt")); User user=new User(22,"老田"); objectOutputStream.writeObject(user); } catch (IOException e) { e.printStackTrace(); } } } ``` 序列化,然后进行反序列化: ```java package com.tian.my_code.test.clone; import java.io.*; public class SeriTest { public static void main(String[] args) { try { ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.txt")); User user=(User) ois.readObject(); System.out.println(user.getName()); System.out.println(user.getAge()); } catch (Exception e) { e.printStackTrace(); } } }运行输出:
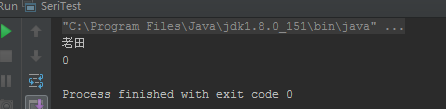
从输出我们看到,使用transient修饰的属性,Java序列化时,会忽略掉此字段,所以反序列化出的对象,被transient修饰的属性是默认值。
对于引用类型,值是null;基本类型,值是0;boolean类型,值是false。
探索
到此序列化内容算讲完了,但是,如果只停留在这个层面,是无法应对实际工作中的问题的。
比如模型对象持有其它对象的引用怎么处理,引用类型如果是复杂些的集合类型怎么处理?
上面的User中持有String引用类型的,照样序列化没问题,那么如果是我们自定义的引用类呢?
比如下面的场景:
package com.tian.my_code.test.clone; public class UserAddress { private int provinceCode; private int cityCode; public UserAddress() { } public UserAddress(int provinceCode, int cityCode) { this.provinceCode = provinceCode; this.cityCode = cityCode; } public int getProvinceCode() { return provinceCode; } public void setProvinceCode(int provinceCode) { this.provinceCode = provinceCode; } public int getCityCode() { return cityCode; } public void setCityCode(int cityCode) { this.cityCode = cityCode; } }然后在User中添加一个UserAddress的属性:
package com.tian.my_code.test.clone; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.io.Serializable; public class User implements Serializable{ private static final long serialVersionUID = -2445226500651941044L; private int age; private String name; private UserAddress userAddress; public User() { } public User(int age, String name) { this.age = age; this.name = name; } //get set public static void main(String[] args) { try { ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt")); User user=new User(22,"老田"); UserAddress userAddress=new UserAddress(10001,10001001); user.setUserAddress(userAddress); objectOutputStream.writeObject(user); } catch (IOException e) { e.printStackTrace(); } } }运行上面代码:
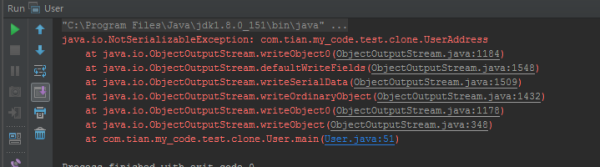
抛出了 java.io.NotSerializableException 异常。很明显在告诉我们,UserAddress没有实现序列化接口。待UserAddress类实现序列化接口后:
package com.tian.my_code.test.clone;
import java.io.Serializable;
public class UserAddress implements Serializable {
private static final long serialVersionUID = 5128703296815173156L;
private int provinceCode;
private int cityCode;
public UserAddress() {
}
public UserAddress(int provinceCode, int cityCode) {
this.provinceCode = provinceCode;
this.cityCode = cityCode;
}
//get set
}
再次运行,正常不报错了。
反序列化代码:
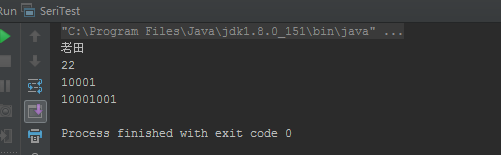
package com.tian.my_code.test.clone; import java.io.*; public class SeriTest { public static void main(String[] args) { try { ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.txt")); User user=(User) ois.readObject(); System.out.println(user.getName()); System.out.println(user.getAge()); System.out.println(user.getUserAddress().getProvinceCode()); System.out.println(user.getUserAddress().getCityCode()); } catch (Exception e) { e.printStackTrace(); } } }运行结果:
典型运用场景
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { private static final long serialVersionUID = -6849794470754667710L; } public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { private static final long serialVersionUID = 362498820763181265L; } public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{ private static final long serialVersionUID = 8683452581122892189L; } .....很多常用类都实现了序列化接口。
再次拓展
上面说的transient 反序列化的时候是默认值,但是你会发现,几种常用集合类ArrayList、HashMap、LinkedList等数据存储字段,竟然都被 transient 修饰了,然而在实际操作中我们用集合类型存储的数据却可以被正常的序列化和反序列化?
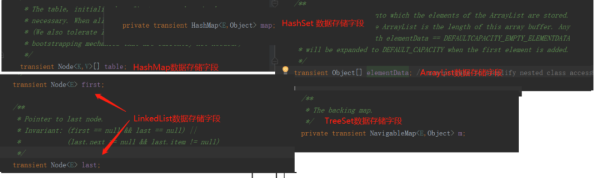
真相当然还是在源码里。实际上,各个集合类型对于序列化和反序列化是有单独的实现的,并没有采用虚拟机默认的方式。这里以 ArrayList中的序列化和反序列化源码部分为例分析:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{ int expectedModCount = modCount; //序列化当前ArrayList中非transient以及非静态字段 s.defaultWriteObject(); //序列化数组实际个数 s.writeInt(size); // 逐个取出数组中的值进行序列化 for (int i=0; i<size; i++) { s.writeObject(elementData[i]); } //防止在并发的情况下对元素的修改 if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } } private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { elementData = EMPTY_ELEMENTDATA; // 反序列化非transient以及非静态修饰的字段,其中包含序列化时的数组大小 size s.defaultReadObject(); // 忽略的操作 s.readInt(); // ignored if (size > 0) { // 容量计算 int capacity = calculateCapacity(elementData, size); SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity); //检测是否需要对数组扩容操作 ensureCapacityInternal(size); Object[] a = elementData; // 按顺序反序列化数组中的值 for (int i=0; i<size; i++) { a[i] = s.readObject(); } } }读源码可以知道,ArrayList的序列化和反序列化主要思路就是根据集合中实际存储的元素个数来进行操作,这样做估计是为了避免不必要的空间浪费(因为ArrayList的扩容机制决定了,集合中实际存储的元素个数肯定比集合的可容量要小)。为了验证,我们可以在单元测试序列化和返序列化的时候,在ArrayLIst的两个方法中打上断点,以确认这两个方法在序列化和返序列化的执行流程中(截图为反序列化过程):
原来,我们之前自以为集合能成功序列化也只是简单的实现了标记接口都只是表象,表象背后有各个集合类有不同的深意。所以,同样的思路,读者朋友可以自己去分析下 HashMap以及其它集合类中自行控制序列化和反序列化的个中门道了,感兴趣的小伙伴可以自行去查看一番。
序列化注意事项
1、序列化时,只对对象的状态进行保存,而不管对象的方法;
2、当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
3、当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
4、并非所有的对象都可以序列化,至于为什么不可以,有很多原因了,比如:
安全方面的原因,比如一个对象拥有private,public等field,对于一个要传输的对象,比如写到文件,或者进行RMI传输等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的;
资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分配,而且,也是没有必要这样实现;
5、声明为static和transient类型的成员数据不能被序列化。因为static代表类的状态,transient代表对象的临时数据。
6、序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。为它赋予明确的值。显式地定义serialVersionUID有两种用途:
在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
7、Java有很多基础类已经实现了serializable接口,比如String,Vector等。但是也有一些没有实现serializable接口的;
8、如果一个对象的成员变量是一个对象,那么这个对象的数据成员也会被保存!这是能用序列化解决深拷贝的重要原因;
“如何理解序列化”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。