жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іLinuxдёӢеёёз”Ёзі»з»ҹеҲҶжһҗе·Ҙе…·жңүе“Әдәӣзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
1.CPU
еҜ№дәҺcpuжҲ‘们主иҰҒд»Ӣз»ҚtopпјҢstraceпјҢperfпјҢvmstatгҖӮ
1.1 top
topе‘Ҫд»ӨеҸҜд»Ҙе®һж—¶еҠЁжҖҒең°жҹҘзңӢзі»з»ҹзҡ„ж•ҙдҪ“иҝҗиЎҢжғ…еҶөпјҢжҳҜдёҖдёӘз»јеҗҲдәҶеӨҡж–№дҝЎжҒҜзӣ‘жөӢзі»з»ҹжҖ§иғҪе’ҢиҝҗиЎҢдҝЎжҒҜзҡ„е®һз”Ёе·Ҙе…·гҖӮ
Topеёёз”Ёзҡ„еҸҜйҖүеҸӮж•°е’Ңе…¶еҜ№еә”зҡ„еҗ«д№үеҰӮдёӢпјҡ
(1)-cпјҡжҳҫзӨәе®Ңж•ҙзҡ„е‘Ҫд»Ө;
(2)-dпјҡеұҸ幕еҲ·ж–°й—ҙйҡ”ж—¶й—ҙ;
(3)-i<ж—¶й—ҙ>пјҡи®ҫзҪ®й—ҙйҡ”ж—¶й—ҙ;
(4)-u<з”ЁжҲ·еҗҚ>пјҡжҢҮе®ҡз”ЁжҲ·еҗҚ;
(5)-p<иҝӣзЁӢеҸ·>пјҡжҢҮе®ҡиҝӣзЁӢ;
(6)-n<ж¬Ўж•°>пјҡеҫӘзҺҜжҳҫзӨәзҡ„ж¬Ўж•°гҖӮ
topжү§иЎҢиө·жқҘзҡ„ж•ҲжһңеҰӮдёӢпјҡ
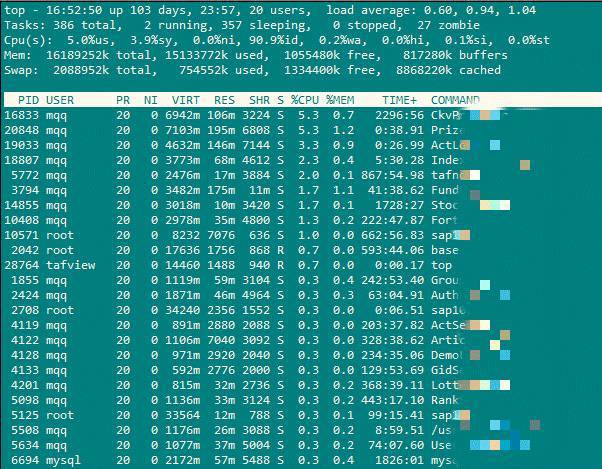
еүҚдә”иЎҢжҳҜзі»з»ҹж•ҙдҪ“зҡ„з»ҹи®ЎдҝЎжҒҜгҖӮ***иЎҢжҳҜд»»еҠЎйҳҹеҲ—дҝЎжҒҜпјҢ第дәҢиЎҢе’Ң第дёүиЎҢдёәиҝӣзЁӢе’ҢCPUзҡ„дҝЎжҒҜпјҢ***дёӨиЎҢдёәеҶ…еӯҳдҝЎжҒҜгҖӮдёӢйқўеҜ№дёҖдәӣжҜ”иҫғйҮҚиҰҒзҡ„еҸӮж•°иҝӣиЎҢиҜҙжҳҺгҖӮ
Load averageпјҡ0.60,0.94,1.04гҖӮload averageиЎЁзӨәзі»з»ҹеңЁиҝҮеҺ»1еҲҶй’ҹ5еҲҶй’ҹ15еҲҶй’ҹзҡ„д»»еҠЎйҳҹеҲ—зҡ„е№іеқҮй•ҝеәҰгҖӮиҝҷдёӘеҖји¶ҠеӨ§е°ұиЎЁзӨәзі»з»ҹCPUи¶Ҡз№ҒеҝҷгҖӮ
Cpu(s):5.0%us(з”ЁжҲ·з©әй—ҙеҚ з”Ёзҡ„cpu***)пјҢ3.9%sy(зі»з»ҹз©әй—ҙеҚ з”Ёзҡ„cpuзҷҫеҲҶжҜ”)пјҢ0.0%ni(з”ЁжҲ·иҝӣзЁӢз©әй—ҙеҶ…ж”№еҸҳиҝҮдјҳе…Ҳзә§зҡ„з”ЁжҲ·еҚ з”Ёзҡ„cpuзҷҫеҲҶжҜ”)пјҢ90.9%id(з©әй—Іcpuзҡ„зҷҫеҲҶжҜ”)пјҢ0.2%wa(зӯүеҫ…иҫ“е…Ҙиҫ“еҮәcpuзҡ„зҷҫеҲҶжҜ”)гҖӮ
Memпјҡ817280k buffers(з”ЁдҪңеҶ…ж ёзј“еӯҳзҡ„еҶ…еӯҳйҮҸ)гҖӮ
SwapпјҡзЈҒзӣҳдәӨжҚўеҢәе®№йҮҸгҖӮ
1.2 strace
straceеҸҜд»Ҙи·ҹиёӘеҲ°дёҖдёӘиҝӣзЁӢдә§з”ҹзҡ„зі»з»ҹи°ғз”ЁпјҢеҢ…еҗ«еҸӮж•°гҖҒиҝ”еӣһеҖјгҖҒжү§иЎҢж¶ҲиҖ—зҡ„ж—¶й—ҙгҖӮ
straceзҡ„еёёз”Ёзҡ„йҖүйЎ№д»ҘеҸҠйҖүйЎ№еҜ№еә”зҡ„еҗ«д№үеҰӮдёӢпјҡ
(1)-c з»ҹи®ЎжҜҸдёҖзі»з»ҹи°ғз”Ёзҡ„жүҖжү§иЎҢзҡ„ж—¶й—ҙ,ж¬Ўж•°е’ҢеҮәй”ҷзҡ„ж¬Ўж•°зӯү
(2)-f и·ҹиёӘз”ұforkи°ғз”ЁжүҖдә§з”ҹзҡ„еӯҗиҝӣзЁӢ
(3)-t еңЁиҫ“еҮәдёӯзҡ„жҜҸдёҖиЎҢеүҚеҠ дёҠж—¶й—ҙдҝЎжҒҜ
(4)-tt еңЁиҫ“еҮәдёӯзҡ„жҜҸдёҖиЎҢеүҚеҠ дёҠж—¶й—ҙдҝЎжҒҜ(еҫ®еҰҷзә§)
(5)-T жҳҫзӨәжҜҸдёҖи°ғз”ЁжүҖиҖ—зҡ„ж—¶й—ҙ
(6)-e trace=set еҸӘи·ҹиёӘжҢҮе®ҡзҡ„зі»з»ҹи°ғз”ЁгҖӮдҫӢеҰӮ:-e trace=open,close,read,writeиЎЁзӨәеҸӘи·ҹиёӘиҝҷеӣӣдёӘзі»з»ҹи°ғз”ЁгҖӮй»ҳи®Өзҡ„дёәset=all
(7)-e trace=file еҸӘи·ҹиёӘжңүе…іж–Ү件ж“ҚдҪңзҡ„зі»з»ҹи°ғз”Ё
(8)-e trace=process еҸӘи·ҹиёӘжңүе…іиҝӣзЁӢжҺ§еҲ¶зҡ„зі»з»ҹи°ғз”Ё
(9)-e trace=network и·ҹиёӘдёҺзҪ‘з»ңжңүе…ізҡ„жүҖжңүзі»з»ҹи°ғз”Ё
(10)-e strace=signal и·ҹиёӘжүҖжңүдёҺзі»з»ҹдҝЎеҸ·жңүе…ізҡ„ зі»з»ҹи°ғз”Ё
(11)-e trace=ipc и·ҹиёӘжүҖжңүдёҺиҝӣзЁӢйҖҡи®Ҝжңүе…ізҡ„зі»з»ҹи°ғз”Ё
(12)-o filename е°Ҷstraceзҡ„иҫ“еҮәеҶҷе…Ҙж–Ү件filename -p pid и·ҹиёӘжҢҮе®ҡзҡ„иҝӣзЁӢpid
дҫӢеҰӮжү§иЎҢ strace cat /dev/nullпјҢдјҡеҫ—еҲ°еҰӮдёӢиҫ“еҮәпјҡ
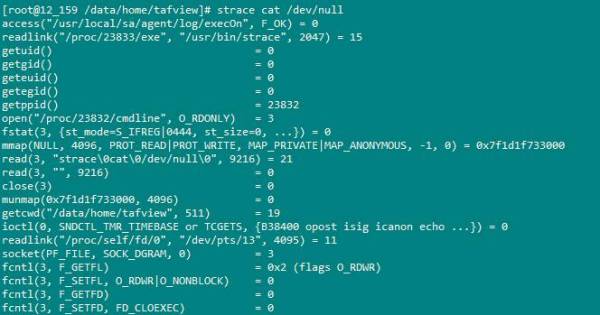
жҜҸдёҖиЎҢйғҪжҳҜдёҖжқЎзі»з»ҹи°ғз”ЁпјҢзӯүеҸ·е·Ұиҫ№жҳҜзі»з»ҹи°ғз”Ёзҡ„еҮҪж•°еҗҚеҸҠе…¶еҸӮж•°пјҢеҸіиҫ№жҳҜиҜҘи°ғз”Ёзҡ„иҝ”еӣһеҖјгҖӮеҰӮжһңдҪ зҹҘйҒ“дҪ иҰҒжүҫзҡ„жҳҜд»Җд№ҲпјҢдҪ еҸҜд»Ҙи®©straceеҸӘи·ҹиёӘдёҖдәӣзұ»еһӢзҡ„зі»з»ҹи°ғз”ЁгҖӮдҫӢеҰӮдҪ йңҖиҰҒзңӢзңӢеңЁloadconfigureи„ҡжң¬йҮҢйқўжү§иЎҢзҡ„зЁӢеәҸйҮҢйқўзі»з»ҹи°ғз”Ёececveзҡ„и°ғз”Ёжғ…еҶөпјҢеҲҷеҸӘйңҖиҰҒиҫ“е…Ҙиҝҷж ·дёҖжқЎshellе‘Ҫд»Өпјҡstrace -f -o loadconfigure-strace.txt -e execve ./loadconfigure
еҶҚдҫӢеҰӮпјҢжҲ‘们зҹҘйҒ“ActLogicSvrзҡ„иҝӣзЁӢеҸ·жҳҜ16789пјҢеҲҷеҸҜд»Ҙжү§иЎҢstrace -p 16789 -cжқҘз»ҹи®ЎActLogicSvrеңЁжҹҗдёҖж®өж—¶й—ҙзі»з»ҹи°ғз”Ёзҡ„з»ҹи®Ўжғ…еҶөгҖӮз»“жһңеҰӮдёӢжүҖзӨәпјҡ
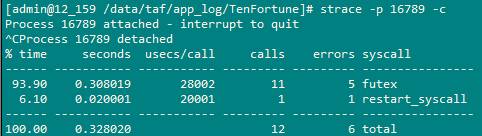
иҝҷйҮҢеҫҲжё…жҘҡзҡ„е‘ҠиҜүдҪ и°ғз”ЁдәҶйӮЈдәӣзі»з»ҹеҮҪж•°пјҢи°ғз”Ёж¬Ўж•°еӨҡе°‘пјҢж¶ҲиҖ—дәҶеӨҡе°‘ж—¶й—ҙзӯүзӯүиҝҷдәӣдҝЎжҒҜпјҢиҝҷдёӘеҜ№жҲ‘们еҲҶжһҗдёҖдёӘзЁӢеәҸжқҘиҜҙжҳҜйқһеёёжңүз”Ёзҡ„гҖӮ
1.3 Perf
perfжҳҜLinuxзҡ„жҖ§иғҪи°ғдјҳе·Ҙе…·гҖӮperfе·Ҙе…·зҡ„еёёз”Ёе‘Ҫд»ӨеҢ…жӢ¬topпјҢrecordпјҢreportзӯүгҖӮ
perf topе‘Ҫд»Өз”ЁжқҘжҳҫзӨәзЁӢеәҸиҝҗиЎҢзҡ„ж•ҙдҪ“зҠ¶еҶөгҖӮиҜҘе‘Ҫд»Өдё»иҰҒз”ЁжқҘи§ӮеҜҹж•ҙдёӘзі»з»ҹеҪ“еүҚзҡ„зҠ¶жҖҒпјҢжҜ”еҰӮеҸҜд»ҘйҖҡиҝҮжҹҘзңӢиҜҘе‘Ҫд»Өзҡ„иҫ“еҮәжқҘжҹҘзңӢеҪ“еүҚзі»з»ҹжңҖиҖ—ж—¶зҡ„еҶ…ж ёеҮҪж•°жҲ–жҹҗдёӘз”ЁжҲ·иҝӣзЁӢгҖӮPerf statзҡ„иҝҗиЎҢж•ҲжһңеҰӮдёӢпјҡ
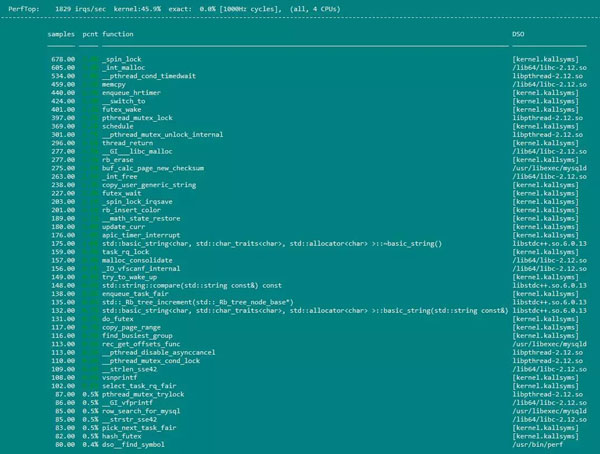
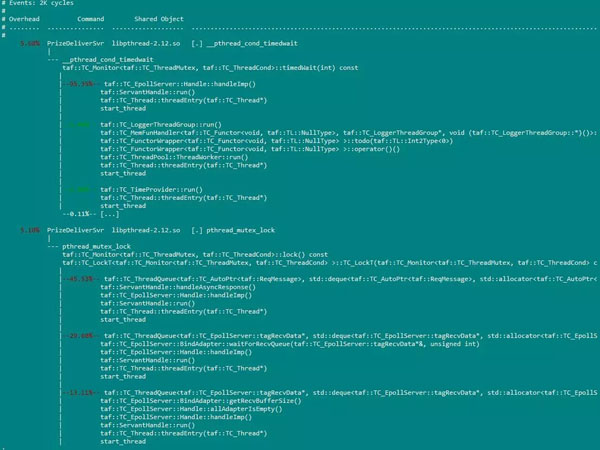
perf recordе‘Ҫд»ӨеҲҷз”ЁжқҘи®°еҪ•жҢҮе®ҡдәӢ件еңЁзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯзҡ„дҝЎжҒҜпјҢиҖҢPerf reportе‘Ҫд»ӨеҲҷз”ЁжқҘжҠҘе‘ҠеҹәдәҺеүҚйқўrecordе‘Ҫд»Өи®°еҪ•зҡ„дәӢ件дҝЎжҒҜз”ҹжҲҗзҡ„зЁӢеәҸиҝҗиЎҢзҠ¶еҶөжҠҘе‘ҠгҖӮжҲ‘们йҖҡеёёз”Ёе‘Ҫд»Өperf record -g -p pidе°ҶиҝӣзЁӢеңЁе‘Ҫд»ӨиҝҗиЎҢжңҹй—ҙзҡ„еҗ„йЎ№жҢҮд»ӨиҝҗиЎҢжүҖеҚ CPUзҡ„жҜ”дҫӢеӯҳеңЁperf.dataйҮҢйқў(-gиЎЁзӨәи®°еҪ•еҮҪж•°д№Ӣй—ҙзҡ„и°ғз”Ёе…ізі»)гҖӮеҶҚз”Ёperf report --call-graph --stdioе°ҶеҲҡеҲҡзҡ„з»ҹи®Ўз»“жһңеұ•зӨәеҮәжқҘгҖӮ
perf recordеёҰ-gйҖүйЎ№ж—¶пјҢperf reportзҡ„иҝҗиЎҢж•Ҳжһңпјҡ
perf recordдёҚеёҰ-gйҖүйЎ№ж—¶пјҢperf reportзҡ„иҝҗиЎҢж•Ҳжһңпјҡ
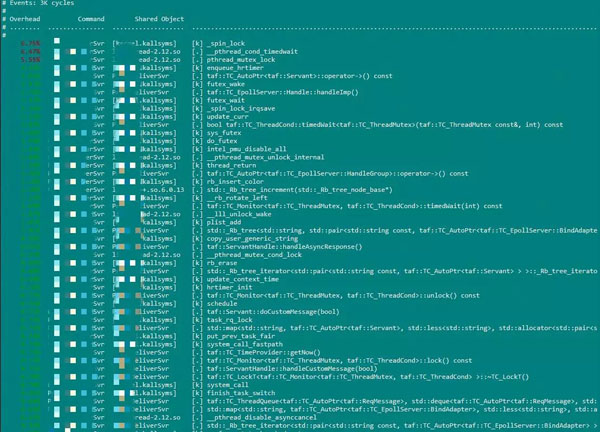
1.4 vmstat
vmstatжҳҜдёҖдёӘеҫҲе…Ёйқўзҡ„жҖ§иғҪеҲҶжһҗе·Ҙе…·пјҢеҸҜд»Ҙи§ӮеҜҹеҲ°зі»з»ҹзҡ„иҝӣзЁӢзҠ¶жҖҒгҖҒеҶ…еӯҳдҪҝз”ЁгҖҒиҷҡжӢҹеҶ…еӯҳдҪҝз”ЁгҖҒзЈҒзӣҳзҡ„ IOгҖҒдёӯж–ӯгҖҒдёҠдёӢй—®еҲҮжҚўгҖҒCPUдҪҝз”ЁзӯүгҖӮ
vmstatзҡ„иҫ“еҮәеҰӮдёӢпјҡ

procsпјҡ
- rпјҡиҝҗиЎҢйҳҹеҲ—дёӯиҝӣзЁӢж•°йҮҸпјҢиҝҷдёӘеҖјд№ҹеҸҜд»ҘеҲӨж–ӯжҳҜеҗҰйңҖиҰҒеўһеҠ CPUгҖӮ(й•ҝжңҹеӨ§дәҺ1)
- bпјҡеӣ дёәioеӨ„дәҺйҳ»еЎһзҠ¶жҖҒзҡ„иҝӣзЁӢж•°гҖӮ
memoryпјҡ
-swapпјҡдҪҝз”ЁиҷҡжӢҹеҶ…еӯҳеӨ§е°Ҹ
-freeпјҡз©әй—Ізү©зҗҶеҶ…еӯҳеӨ§е°Ҹ
-buffпјҡз”ЁдҪңзј“еҶІзҡ„еҶ…еӯҳеӨ§е°Ҹ
-cacheпјҡз”ЁдҪңзј“еӯҳзҡ„еҶ…еӯҳеӨ§е°Ҹ
swapпјҡ
siпјҡжҜҸз§’д»ҺдәӨжҚўеҢәеҶҷеҲ°еҶ…еӯҳзҡ„еӨ§е°ҸпјҢз”ұзЈҒзӣҳи°ғе…ҘеҶ…еӯҳ
soпјҡжҜҸз§’еҶҷе…ҘдәӨжҚўеҢәзҡ„еҶ…еӯҳеӨ§е°ҸпјҢз”ұеҶ…еӯҳи°ғе…ҘзЈҒзӣҳ
ioпјҡ
- biпјҡд»Һеқ—и®ҫеӨҮиҜ»е…Ҙзҡ„ж•°жҚ®жҖ»йҮҸ(иҜ»зЈҒзӣҳ)(KB/s)
- boпјҡеҶҷе…ҘеҲ°еқ—и®ҫеӨҮзҡ„ж•°жҚ®жҖ»йҮҸ(еҶҷзЈҒзӣҳ)(KB/s)
systemпјҡ
- in:жҜҸз§’дә§з”ҹзҡ„дёӯж–ӯж¬Ўж•°
- csпјҡжҜҸз§’дә§з”ҹзҡ„дёҠдёӢж–ҮеҲҮжҚўж¬Ўж•°
cpuпјҡ
- usпјҡз”ЁжҲ·иҝӣзЁӢж¶ҲиҖ—зҡ„CPUж—¶й—ҙзҷҫеҲҶжҜ”
- syпјҡеҶ…ж ёиҝӣзЁӢж¶ҲиҖ—зҡ„CPUж—¶й—ҙзҷҫеҲҶжҜ”
- waпјҡIOзӯүеҫ…ж¶ҲиҖ—зҡ„CPUж—¶й—ҙзҷҫеҲҶжҜ”
- idпјҡCPUеӨ„еңЁз©әй—ІзҠ¶жҖҒж—¶й—ҙзҷҫеҲҶжҜ”
2.зҪ‘з»ң
2.1 netstatе‘Ҫд»Ө
netstatе‘Ҫд»Өз”ЁжқҘжү“еҚ°LinuxдёӯзҪ‘з»ңзі»з»ҹзҡ„зҠ¶жҖҒдҝЎжҒҜпјҢеҸҜи®©дҪ еҫ—зҹҘж•ҙдёӘLinuxзі»з»ҹзҡ„зҪ‘з»ңжғ…еҶөгҖӮ
netstatзҡ„еёёз”Ёзҡ„йҖүйЎ№еҰӮдёӢпјҡ
(1)-a(all)жҳҫзӨәжүҖжңүйҖүйЎ№
(2)-t(tcp)д»…жҳҫзӨәtcpзӣёе…ійҖүйЎ№
(3)-u(udp)д»…жҳҫзӨәudpзӣёе…ійҖүйЎ№
(4)-l(listen)д»…еҲ—еҮәжңүеңЁListen(зӣ‘еҗ¬)зҡ„жңҚеҠЎзҠ¶жҖҒ
(5)-p(program)жҳҫзӨәе»әз«Ӣзӣёе…ій“ҫжҺҘзҡ„зЁӢеәҸеҗҚ
(6)-r(route)жҳҫзӨәи·Ҝз”ұдҝЎжҒҜпјҢи·Ҝз”ұиЎЁ
(7)-e(extend)жҳҫзӨәжү©еұ•дҝЎжҒҜ
(8)-c жҜҸйҡ”дёҖдёӘеӣәе®ҡж—¶й—ҙпјҢжү§иЎҢиҜҘnetstatе‘Ҫд»ӨгҖӮ
еңЁиҝҷйҮҢжҲ‘们з®ҖеҚ•еӨҚд№ дёҖдёӢTCPдёүж¬ЎжҸЎжүӢе’Ңеӣӣж¬ЎжҢҘжүӢзҡ„иҝҮзЁӢпјҢдҫҝдәҺдёӢйқўи§ЈйҮҠnetstatдёӯtcpзҡ„еҗ„з§ҚзҠ¶жҖҒгҖӮ
TCPдёүж¬ЎжҸЎжүӢзҡ„иҝҮзЁӢеҰӮдёӢпјҡ
(1)дё»еҠЁиҝһжҺҘз«ҜеҸ‘йҖҒдёҖдёӘSYNеҢ…з»ҷиў«еҠЁиҝһжҺҘз«Ҝ;
(2)иў«еҠЁиҝһжҺҘз«Ҝ收еҲ°SYNеҢ…еҗҺпјҢеҸ‘йҖҒдёҖдёӘеёҰACKзҡ„SYNеҢ…з»ҷдё»еҠЁиҝһжҺҘз«ҜгҖӮ
(3)дё»еҠЁиҝһжҺҘз«ҜеҸ‘йҖҒдёҖдёӘеёҰACKж Үеҝ—зҡ„еҢ…з»ҷиў«еҠЁиҝһжҺҘз«ҜпјҢжҸЎжүӢеҠЁдҪңе®ҢжҲҗгҖӮ
TCPзҡ„еӣӣж¬ЎжҢҘжүӢиҝҮзЁӢеҰӮдёӢпјҡ
(1)дё»еҠЁе…ій—ӯз«ҜеҸ‘йҖҒдёҖдёӘFINеҢ…з»ҷиў«еҠЁе…ій—ӯз«ҜгҖӮ
(2)иў«еҠЁе…ій—ӯз«Ҝ收еҲ°FINеҢ…еҗҺпјҢеҸ‘йҖҒдёҖдёӘACKеҢ…з»ҷдё»еҠЁе…ій—ӯз«ҜгҖӮ
(3)иў«еҠЁе…ій—ӯз«ҜеҸ‘йҖҒдәҶACKеҢ…еҗҺпјҢеҶҚеҸ‘йҖҒдёҖдёӘFINеҢ…з»ҷдё»еҠЁе…ій—ӯз«ҜгҖӮ
(4)дё»еҠЁе…ій—ӯз«Ҝ收еҲ°FINеҢ…еҗҺпјҢеҸ‘йҖҒдёҖдёӘACKеҢ…гҖӮеҪ“иў«еҠЁе…ій—ӯз«Ҝ收еҲ°ACKеҗҺпјҢеӣӣж¬ЎжҢҘжүӢеҠЁдҪңе®ҢжҲҗпјҢиҝһжҺҘж–ӯејҖгҖӮ
дёӢйқўжҲ‘们解йҮҠдёҖдёӢnetstatдёӯtcpиҝһжҺҘеҜ№еә”зҡ„еҗ„з§ҚзҠ¶жҖҒгҖӮ
(1)LISTENпјҡдҫҰеҗ¬зҠ¶жҖҒпјҢзӯүеҫ…иҝңзЁӢжңәеҷЁзҡ„иҝһжҺҘиҜ·жұӮгҖӮ
(2)SYN_SENDпјҡеңЁTCPдёүж¬ЎжҸЎжүӢжңҹй—ҙпјҢдё»еҠЁиҝһжҺҘз«ҜеҸ‘йҖҒдәҶSYNеҢ…еҗҺпјҢиҝӣе…ҘSYN_SENDзҠ¶жҖҒпјҢзӯүеҫ…еҜ№ж–№зҡ„ACKеҢ…гҖӮ
(3)SYN_RECVпјҡеңЁTCPдёүж¬ЎжҸЎжүӢжңҹй—ҙпјҢдё»еҠЁжҺҘ收з«Ҝ收еҲ°SYNеҢ…еҗҺпјҢиҝӣе…ҘSYN_RECVзҠ¶жҖҒгҖӮ
(4)ESTABLISHEDпјҡе®ҢжҲҗTCPдёүж¬ЎжҸЎжүӢеҗҺпјҢдё»еҠЁиҝһжҺҘз«Ҝиҝӣе…ҘESTABLISHEDзҠ¶жҖҒгҖӮжӯӨж—¶пјҢTCPиҝһжҺҘе·Із»Ҹе»әз«ӢпјҢеҸҜд»ҘиҝӣиЎҢйҖҡдҝЎгҖӮ
(5)FIN_WAIT_1пјҡеңЁTCPеӣӣж¬ЎжҢҘжүӢж—¶пјҢдё»еҠЁе…ій—ӯз«ҜеҸ‘йҖҒFINеҢ…еҗҺпјҢиҝӣе…ҘFIN_WAIT_1зҠ¶жҖҒгҖӮ
(6)FIN_WAIT_2пјҡеңЁTCPеӣӣж¬ЎжҢҘжүӢж—¶пјҢдё»еҠЁе…ій—ӯз«Ҝ收еҲ°ACKеҢ…еҗҺпјҢиҝӣе…ҘFIN_WAIT_2зҠ¶жҖҒгҖӮ
(7)TIME_WAITпјҡеңЁTCPеӣӣж¬ЎжҢҘжүӢж—¶пјҢдё»еҠЁе…ій—ӯз«ҜеҸ‘йҖҒдәҶACKеҢ…д№ӢеҗҺпјҢиҝӣе…ҘTIME_WAITзҠ¶жҖҒпјҢзӯүеҫ…жңҖеӨҡ2MSLж—¶й—ҙпјҢи®©иў«еҠЁе…ій—ӯз«Ҝ收еҲ°ACKеҢ…гҖӮ
(8)CLOSINGпјҡеңЁTCPеӣӣж¬ЎжҢҘжүӢжңҹй—ҙпјҢдё»еҠЁе…ій—ӯз«ҜеҸ‘йҖҒдәҶFINеҢ…еҗҺпјҢжІЎжңү收еҲ°еҜ№еә”зҡ„ACKеҢ…пјҢеҚҙ收еҲ°дәҶеҜ№ж–№зҡ„FINеҢ…пјҢжӯӨж—¶иҝӣе…ҘCLOSINGзҠ¶жҖҒгҖӮ
(9)CLOSE_WAITпјҡеңЁTCPеӣӣж¬ЎжҢҘжүӢжңҹй—ҙпјҢиў«еҠЁе…ій—ӯз«Ҝ收еҲ°FINеҢ…еҗҺпјҢиҝӣе…ҘCLOSE_WAITзҠ¶жҖҒгҖӮ
(10)LAST_ACKпјҡеңЁTCPеӣӣж¬ЎжҢҘжүӢж—¶пјҢиў«еҠЁе…ій—ӯз«ҜеҸ‘йҖҒFINеҢ…еҗҺпјҢиҝӣе…ҘLAST_ACKзҠ¶жҖҒпјҢзӯүеҫ…еҜ№ж–№зҡ„ACKеҢ…гҖӮ
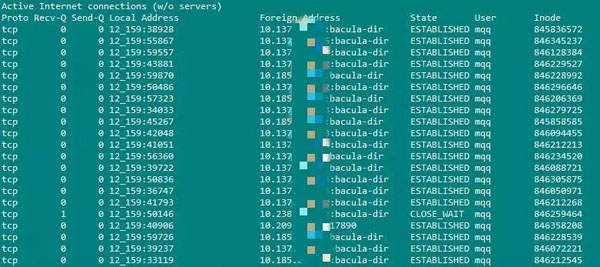
netstat -te(жҳҫзӨәеҮәжүҖжңүзҡ„tcpиҝһжҺҘ)жү§иЎҢиө·жқҘзҡ„ж•ҲжһңеҰӮдёӢпјҡ
netstatзҡ„еёёз”Ёж–№жі•пјҡ
(1)netstat -p | grep 19626пјҡеҫ—еҲ°иҝӣзЁӢеҸ·19626зҡ„иҝӣзЁӢжүҖжү“ејҖзҡ„жүҖжңүз«ҜеҸЈ
(2)netstat -tplпјҡжҹҘзңӢеҪ“еүҚtcpзӣ‘еҗ¬з«ҜеҸЈ, йңҖиҰҒжҳҫзӨәзӣ‘еҗ¬зҡ„зЁӢеәҸеҗҚгҖӮ
(3)netstat -c 2пјҡйҡ”дёӨз§’жү§иЎҢдёҖж¬ЎnetstatпјҢжҢҒз»ӯиҫ“еҮә
2.2 lsof
lsofе‘Ҫд»Өз”ЁдәҺжҹҘзңӢиҝӣзЁӢејҖжү“зҡ„ж–Ү件пјҢжү“ејҖж–Ү件зҡ„иҝӣзЁӢпјҢиҝӣзЁӢжү“ејҖзҡ„з«ҜеҸЈ(TCPгҖҒUDP)гҖӮеңЁlinuxзҺҜеўғдёӢпјҢд»»дҪ•дәӢзү©йғҪд»Ҙж–Ү件зҡ„еҪўејҸеӯҳеңЁпјҢйҖҡиҝҮж–Ү件дёҚд»…д»…еҸҜд»Ҙи®ҝ问常规数жҚ®пјҢиҝҳеҸҜд»Ҙи®ҝй—®зҪ‘з»ңиҝһжҺҘе’Ң硬件гҖӮеңЁдҪҝз”ЁTCPзҡ„UDPзҡ„ж—¶еҖҷпјҢзі»з»ҹеңЁеҗҺеҸ°йғҪдёәиҜҘеә”з”ЁзЁӢеәҸеҲҶй…ҚдәҶдёҖдёӘж–Ү件жҸҸиҝ°з¬ҰгҖӮж— и®әиҝҷдёӘж–Ү件зҡ„жң¬иҙЁеҰӮдҪ•пјҢиҜҘж–Ү件жҸҸиҝ°з¬Ұдёәеә”з”ЁзЁӢеәҸдёҺеҹәзЎҖж“ҚдҪңзі»з»ҹд№Ӣй—ҙзҡ„дәӨдә’жҸҗдҫӣдәҶйҖҡз”ЁжҺҘеҸЈгҖӮ
lsofзҡ„дҪҝз”ЁзӨәдҫӢеҰӮдёӢпјҡ
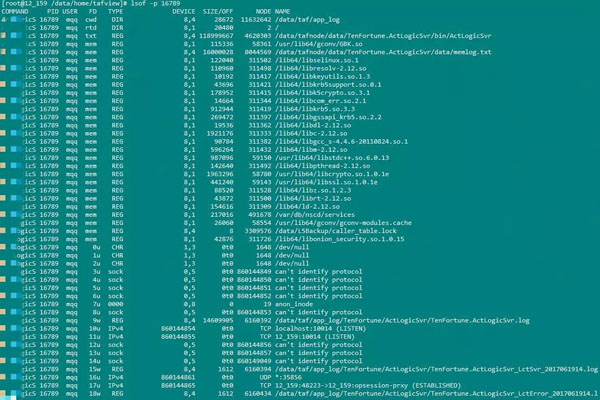
иҫ“еҮәзҡ„еҗ„йЎ№зҡ„еҗ«д№үеҰӮдёӢпјҡ
COMMANDпјҡиҝӣзЁӢзҡ„еҗҚз§°
PIDпјҡиҝӣзЁӢж ҮиҜҶз¬Ұ
USERпјҡиҝӣзЁӢжүҖжңүиҖ…
FDпјҡж–Ү件жҸҸиҝ°з¬ҰпјҢеә”з”ЁзЁӢеәҸйҖҡиҝҮж–Ү件жҸҸиҝ°з¬ҰиҜҶеҲ«иҜҘж–Ү件гҖӮеҰӮcwdгҖҒtxtзӯү
TYPEпјҡж–Ү件зұ»еһӢпјҢеҰӮDIRгҖҒREGзӯү
DEVICEпјҡжҢҮе®ҡзЈҒзӣҳзҡ„еҗҚз§°
SIZEпјҡж–Ү件зҡ„еӨ§е°Ҹ
NODEпјҡзҙўеј•иҠӮзӮ№(ж–Ү件еңЁзЈҒзӣҳдёҠзҡ„ж ҮиҜҶ)
NAMEпјҡжү“ејҖж–Ү件зҡ„зЎ®еҲҮеҗҚз§°
Lsofзҡ„еёёз”Ёж–№жі•пјҡ
(1)lsof abc.txtпјҡжҹҘзңӢжүҖжңүжү“ејҖдәҶж–Ү件abc.txtзҡ„иҝӣзЁӢгҖӮ
(2)lsof -p pidпјҡжҳҫзӨәиҝӣзЁӢжү“ејҖзҡ„жүҖжңүзҡ„ж–Ү件гҖӮ
2.3 tcpdump
tcpdumpеҸҜд»Ҙе°ҶзҪ‘з»ңдёӯдј йҖҒзҡ„ж•°жҚ®еҢ…е®Ңе…ЁжҲӘиҺ·дёӢжқҘжҸҗдҫӣеҲҶжһҗгҖӮе®ғж”ҜжҢҒй’ҲеҜ№зҪ‘з»ңеұӮгҖҒеҚҸи®®гҖҒдё»жңәгҖҒзҪ‘з»ңжҲ–з«ҜеҸЈзҡ„иҝҮж»ӨпјҢ并жҸҗдҫӣandгҖҒorгҖҒnotзӯүйҖ»иҫ‘иҜӯеҸҘжқҘеё®еҠ©дҪ еҺ»жҺүж— з”Ёзҡ„дҝЎжҒҜгҖӮ
tcpdumpзҡ„еёёз”ЁеҸӮж•°пјҡ
(1)-nnпјҢзӣҙжҺҘд»Ҙ IP еҸҠ Port Number жҳҫзӨәпјҢиҖҢйқһдё»жңәеҗҚдёҺжңҚеҠЎеҗҚз§°гҖӮ
(2)-iпјҢеҗҺйқўжҺҘиҰҒгҖҢзӣ‘еҗ¬гҖҚзҡ„зҪ‘з»ңжҺҘеҸЈпјҢдҫӢеҰӮ eth0, lo, ppp0 зӯүзӯүзҡ„жҺҘеҸЈгҖӮ
(3)-wпјҢеҰӮжһңдҪ иҰҒе°Ҷзӣ‘еҗ¬жүҖеҫ—зҡ„ж•°жҚ®еҢ…ж•°жҚ®еӮЁеӯҳдёӢжқҘпјҢз”ЁиҝҷдёӘеҸӮж•°е°ұеҜ№дәҶгҖӮеҗҺйқўжҺҘж–Ү件еҗҚгҖӮ
(4)-cпјҢзӣ‘еҗ¬зҡ„ж•°жҚ®еҢ…ж•°пјҢеҰӮжһңжІЎжңүиҝҷдёӘеҸӮж•°пјҢ tcpdump дјҡжҢҒз»ӯдёҚж–ӯзҡ„зӣ‘еҗ¬пјҢзӣҙеҲ°з”ЁжҲ·иҫ“е…Ҙ [ctrl]-c дёәжӯўгҖӮ
(***пјҢж•°жҚ®еҢ…зҡ„еҶ…е®№д»Ҙ ASCII жҳҫзӨәпјҢйҖҡеёёз”ЁжқҘжҚүеҸ– WWW зҡ„зҪ‘йЎөж•°жҚ®еҢ…иө„ж–ҷгҖӮ
(6)-eпјҢдҪҝз”Ёиө„ж–ҷиҝһжҺҘеұӮ (OSI 第дәҢеұӮ) зҡ„ MAC ж•°жҚ®еҢ…ж•°жҚ®жқҘжҳҫзӨәгҖӮ
(7)-qпјҢд»…еҲ—еҮәиҫғдёәз®Җзҹӯзҡ„ж•°жҚ®еҢ…дҝЎжҒҜпјҢжҜҸдёҖиЎҢзҡ„еҶ…е®№жҜ”иҫғзІҫз®ҖгҖӮ
(8)-XпјҢеҸҜд»ҘеҲ—еҮәеҚҒе…ӯиҝӣеҲ¶ (hex) д»ҘеҸҠ ASCII зҡ„ж•°жҚ®еҢ…еҶ…е®№пјҢеҜ№дәҺзӣ‘еҗ¬ж•°жҚ®еҢ…еҶ…е®№еҫҲжңүз”ЁгҖӮ
(9)-rпјҢд»ҺеҗҺйқўжҺҘзҡ„ж–Ү件е°Ҷж•°жҚ®еҢ…ж•°жҚ®иҜ»еҮәжқҘгҖӮйӮЈдёӘгҖҢж–Ү件гҖҚжҳҜе·Із»ҸеӯҳеңЁзҡ„ж–Ү件пјҢ并且иҝҷдёӘгҖҢж–Ү件гҖҚжҳҜз”ұ -w жүҖеҲ¶дҪңеҮәжқҘзҡ„гҖӮ
tcpdumpзҡ„еёёи§Ғз”Ёжі•пјҡ
(1)tcpdump -i eth2 host ***.***.***.***пјҡжҠ“еҸ–жүҖжңүз»ҸиҝҮ eth2пјҢзӣ®зҡ„жҲ–жәҗең°еқҖжҳҜ***.***.***.***зҡ„зҪ‘з»ңж•°жҚ®гҖӮ
(2)tcpdump -i eth2 dst host ***.***.***.***пјҡжҠ“еҸ–жүҖжңүз»ҸиҝҮ eth2пјҢзӣ®зҡ„ең°еқҖжҳҜ***.***.***.***зҡ„зҪ‘з»ңж•°жҚ®гҖӮ
(3)tcpdump -i eth2 src host ***.***.***.***пјҡжҠ“еҸ–жүҖжңүз»ҸиҝҮ eth2пјҢжәҗең°еқҖжҳҜ***.***.***.***зҡ„зҪ‘з»ңж•°жҚ®гҖӮ
(4)tcpdump -i eth2 port 36000пјҡжҠ“еҸ–жүҖжңүз»ҸиҝҮ eth2пјҢзӣ®зҡ„з«ҜеҸЈжҲ–жәҗз«ҜеҸЈжҳҜ36000зҡ„зҪ‘з»ңж•°жҚ®гҖӮ
(5)tcpdump -i eth2 src port 36000пјҡжҠ“еҸ–жүҖжңүз»ҸиҝҮ eth2пјҢжәҗз«ҜеҸЈжҳҜ36000зҡ„зҪ‘з»ңж•°жҚ®гҖӮ
(6)tcpdump -i eth2 dst port 36000пјҡжҠ“еҸ–жүҖжңүз»ҸиҝҮ eth2пјҢзӣ®зҡ„з«ҜеҸЈжҳҜ36000зҡ„зҪ‘з»ңж•°жҚ®гҖӮ
(7)tcpdump -i eth2 'src host ***.***.***.*** && src port 36000'пјҡжҠ“еҸ–жүҖжңүз»ҸиҝҮ eth2пјҢзӣ®зҡ„ең°еқҖжҳҜ10.136.12.1дё”зӣ®зҡ„з«ҜеҸЈжҳҜ36000зҡ„зҪ‘з»ңж•°жҚ®гҖӮ
(8)еңЁ10.136.12.1жңәеҷЁдёҠжҲ‘们йҖҡиҝҮtopзҹҘйҒ“дәҶActLogicSvrзҡ„иҝӣзЁӢidдёә16789гҖӮ然еҗҺйҖҡиҝҮnetstat -ap | grep 16789еҫ—еҲ°ActLogicSvrзӣ‘еҗ¬зҡ„з«ҜеҸЈжҳҜ10014гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ

然еҗҺжҲ‘们йҖҡиҝҮ tcpdump -i eth2 'port 10014' -xxxжҠ“еҸ–йҖҡиҝҮ10014з«ҜеҸЈзҡ„жүҖжңүзҡ„еҢ…гҖӮжҲ‘们йҖҡиҝҮжЁЎжӢҹжҺҘеҸЈжөӢиҜ•зҡ„ж–№жі•з»ҷActLogicSvrеҸ‘дёҖжқЎиҜ·жұӮгҖӮжҠ“еҲ°зҡ„еҢ…з»“жһңеҰӮдёӢпјҡ

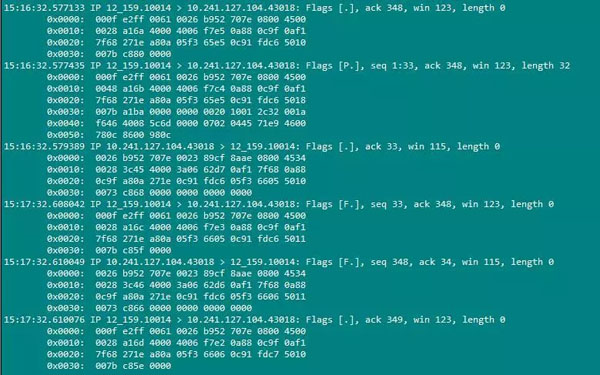
д»ҺжҠ“еҲ°зҡ„еҢ…дёҠжҲ‘们еҸҜд»Ҙжё…жҘҡзҡ„зңӢеҲ°tcpиҝһжҺҘе»әз«Ӣзҡ„дёүж¬ЎжҸЎжүӢеҲ°ж•°жҚ®дј иҫ“еҲ°tcpиҝһжҺҘж–ӯејҖеӣӣж¬ЎжҢҘжүӢзҡ„иҝҮзЁӢ(еүҚдёүдёӘж•°жҚ®еҢ…жҳҜдёүж¬ЎжҸЎжүӢзҡ„иҝҮзЁӢпјҢ***еӣӣдёӘж•°жҚ®еҢ…жҳҜеӣӣж¬ЎжҢҘжүӢзҡ„иҝҮзЁӢпјҢдёӯй—ҙзҡ„дёәж•°жҚ®дј иҫ“жүҖдә§з”ҹзҡ„зҪ‘з»ңж•°жҚ®еҢ…)гҖӮ
3 еҶ…еӯҳ
3.1 valgrind
valgrind жҳҜеңЁLinuxзЁӢеәҸдёӯе№ҝжіӣдҪҝз”Ёзҡ„и°ғиҜ•еә”з”ЁзЁӢеәҸгҖӮе®ғе°Өе…¶ж“…й•ҝеҸ‘зҺ°еҶ…еӯҳз®ЎзҗҶзҡ„й—®йўҳпјҢеҸҜд»ҘжЈҖжҹҘзЁӢеәҸиҝҗиЎҢж—¶зҡ„еҶ…еӯҳжі„жјҸй—®йўҳзӯүгҖӮжҲ‘们еңЁдҪҝз”Ёvalgrindж—¶д№ҹдё»иҰҒз”ЁеҲ°е®ғзҡ„еҶ…еӯҳжі„жјҸжЈҖжөӢеҠҹиғҪпјҢеҚіmemcheckеҠҹиғҪгҖӮе®ғжЈҖжҹҘжүҖжңүеҜ№еҶ…еӯҳзҡ„иҜ»/еҶҷж“ҚдҪңпјҢ并жҲӘеҸ–жүҖжңүзҡ„malloc/new/free/deleteи°ғз”ЁгҖӮеӣ жӯӨmemcheckе·Ҙе…·иғҪеӨҹжҺўжөӢеҲ°д»ҘдёӢй—®йўҳпјҡ
(1)дҪҝз”ЁжңӘеҲқе§ӢеҢ–зҡ„еҶ…еӯҳ
(2)иҜ»/еҶҷе·Із»Ҹиў«йҮҠж”ҫзҡ„еҶ…еӯҳ
(3)иҜ»/еҶҷеҶ…еӯҳи¶Ҡз•Ң
(4)иҜ»/еҶҷдёҚжҒ°еҪ“зҡ„еҶ…еӯҳж Ҳз©әй—ҙ
(5)еҶ…еӯҳжі„жјҸ
(6)дҪҝз”Ёmalloc/new/new[]е’Ңfree/delete/delete[]дёҚеҢ№й…ҚгҖӮ
(7)srcе’Ңdstзҡ„йҮҚеҸ valgrindзҡ„еҸҜйҖүзҡ„еҸӮж•°д»ҘеҸҠеҜ№еә”зҡ„еҗ«д№үеҰӮдёӢжүҖзӨәпјҡ
(1)-version жҳҫзӨәvalgrindеҶ…ж ёзҡ„зүҲжң¬пјҢжҜҸдёӘе·Ҙе…·йғҪжңүеҗ„иҮӘзҡ„зүҲжң¬гҖӮ
(2)q –quiet е®үйқҷең°иҝҗиЎҢпјҢеҸӘжү“еҚ°й”ҷиҜҜдҝЎгҖӮ
(3)v –verbose жӣҙиҜҰз»Ҷзҡ„дҝЎжҒҜ, еўһеҠ й”ҷиҜҜж•°з»ҹи®ЎгҖӮ
(4)-trace-children=no|yes и·ҹиёӘеӯҗзәҝзЁӢ
(5)-track-fds=no|yes и·ҹиёӘжү“ејҖзҡ„ж–Ү件жҸҸиҝ°
(6)-time-stamp=no|yes еўһеҠ ж—¶й—ҙжҲіеҲ°LOGдҝЎжҒҜ
(7)-log-fd=<number> иҫ“еҮәLOGеҲ°жҸҸиҝ°з¬Ұж–Ү
(8)-log-file=<file> е°Ҷиҫ“еҮәзҡ„дҝЎжҒҜеҶҷе…ҘеҲ°filename.PIDзҡ„ж–Ү件йҮҢпјҢPIDжҳҜиҝҗиЎҢзЁӢеәҸзҡ„иҝӣиЎҢID
(9)-log-file-exactly=<file> иҫ“еҮәLOGдҝЎжҒҜеҲ° file
(10)-log-file-qualifier=<VAR> еҸ–еҫ—зҺҜеўғеҸҳйҮҸзҡ„еҖјжқҘеҒҡдёәиҫ“еҮәдҝЎжҒҜзҡ„ж–Ү件еҗҚгҖӮ
(11)-log-socket=ipaddr:port иҫ“еҮәLOGеҲ°socket пјҢipaddr:port
LOGдҝЎжҒҜиҫ“еҮәпјҡ
(1)-xml=yes е°ҶдҝЎжҒҜд»Ҙxmlж јејҸиҫ“еҮәпјҢеҸӘжңүmemcheckеҸҜз”Ё
(2)-num-callers=<number> show <number> callers in stack traces [12]
(3)-error-limit=no|yes еҰӮжһңеӨӘеӨҡй”ҷиҜҜпјҢеҲҷеҒңжӯўжҳҫзӨәж–°й”ҷиҜҜ? [yes]
(4)-error-exitcode=<number> еҰӮжһңеҸ‘зҺ°й”ҷиҜҜеҲҷиҝ”еӣһй”ҷиҜҜд»Јз Ғ [0=disable]
(5)-db-attach=no|yes еҪ“еҮәзҺ°й”ҷиҜҜпјҢvalgrindдјҡиҮӘеҠЁеҗҜеҠЁи°ғиҜ•еҷЁgdbгҖӮ[no]
(6)-db-command=<command> еҗҜеҠЁи°ғиҜ•еҷЁзҡ„е‘Ҫд»ӨиЎҢйҖүйЎ№[gdb -nw %f %p]йҖӮз”ЁдәҺMemcheckе·Ҙе…·зҡ„зӣёе…ійҖүйЎ№пјҡ
(1)--leak-check=no|summary|full иҰҒжұӮеҜ№leakз»ҷеҮәиҜҰз»ҶдҝЎжҒҜ? [summary]
(2)--leak-resolution=low|med|high how much bt merging in leak check [low]
(3)--show-reachable=no|yes show reachable blocks in leak check? [no]
зӨәдҫӢпјҡvalgrind --leak-check=full /usr/local/app/taf/tafnode/data/TenFortune.WeChatProxySvr/bin/WeChatProxySvr --config=/usr/local/app/taf/tafnode/data/TenFortune.WeChatProxySvr/conf/TenFortune.WeChatProxySvr.config.conf -trace-child=yesгҖӮжү§иЎҢзҡ„з»“жһңпјҡ
4 зЈҒзӣҳ
4.1 iotop
iotopе‘Ҫд»ӨжҳҜдёҖдёӘз”ЁжқҘзӣ‘и§ҶзЈҒзӣҳI/OдҪҝз”ЁзҠ¶еҶөзҡ„topзұ»е·Ҙе…·гҖӮiotopе…·жңүдёҺtopзӣёдјјзҡ„UIпјҢе…¶дёӯеҢ…жӢ¬PIDгҖҒз”ЁжҲ·гҖҒI/OгҖҒиҝӣзЁӢзӯүзӣёе…ідҝЎжҒҜгҖӮLinuxдёӢзҡ„IOз»ҹи®Ўе·Ҙе…·еҰӮiostatпјҢnmonзӯүеӨ§еӨҡж•°жҳҜеҸӘиғҪз»ҹи®ЎеҲ°perи®ҫеӨҮзҡ„иҜ»еҶҷжғ…еҶөпјҢеҰӮжһңдҪ жғізҹҘйҒ“жҜҸдёӘиҝӣзЁӢжҳҜеҰӮдҪ•дҪҝз”ЁIOзҡ„е°ұжҜ”иҫғйә»зғҰпјҢдҪҝз”Ёiotopе‘Ҫд»ӨеҸҜд»ҘеҫҲж–№дҫҝзҡ„жҹҘзңӢгҖӮ
iostatе‘Ҫд»ӨйҖүйЎ№пјҡ
-oпјҡеҸӘжҳҫзӨәжңүioж“ҚдҪңзҡ„иҝӣзЁӢ
-n NUMпјҡжҳҫзӨәNUMж¬ЎпјҢдё»иҰҒз”ЁдәҺйқһдәӨдә’ејҸжЁЎејҸгҖӮ
-d SECпјҡй—ҙйҡ”SECз§’жҳҫзӨәдёҖж¬ЎгҖӮ
-p PIDпјҡзӣ‘жҺ§зҡ„иҝӣзЁӢpidгҖӮ
-u USERпјҡзӣ‘жҺ§зҡ„иҝӣзЁӢз”ЁжҲ·гҖӮ
iotopзҡ„жү§иЎҢж•Ҳжһңпјҡ

ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңLinuxдёӢеёёз”Ёзі»з»ҹеҲҶжһҗе·Ҙе…·жңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ