жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жҖҺж ·дҪҝз”ЁPythonеҲҶжһҗж–°еһӢеҶ зҠ¶з—…жҜ’зҡ„еҸ‘еұ•и¶ӢеҠҝпјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
иҝҷж¬Ўз–«жғ…зҡ„жғ…еҶөеӨ§е®¶д№ҹйғҪдәҶи§ЈдәҶпјҢеҗ„ең°д№ҹйғҪ延иҝҹејҖеӯҰжҲ–иҖ…延иҝҹејҖе·ҘпјҢеҜ№дәҺжҲ‘们жқҘиҜҙпјҢжӯЈеҘҪжҳҜдёҖж¬Ўж·ұе…ҘеӯҰд№ зҡ„жңәдјҡгҖӮд»ҠеӨ©пјҢжҲ‘е°ұеёҰйўҶеӨ§е®¶еҲҶжһҗдёҖдёӢж–°еһӢеҶ зҠ¶з—…жҜ’зҡ„зҲҶеҸ‘и¶ӢеҠҝпјҢд№ҹеҖҹжӯӨдҪңдёәдёҖж¬Ўж•°жҚ®еҲҶжһҗиҜҫзЁӢзҡ„е®һжҲҳжЎҲдҫӢпјҢд»Һ ж•°жҚ®иҺ·еҸ–гҖҒж•°жҚ®жё…жҙ—гҖҒж•°жҚ®еҸҜи§ҶеҢ–еҶҚеҲ°дә§еҮәж•°жҚ®з»“и®әпјҢе®Ңж•ҙзҡ„иө°дёҖйҒҚж•°жҚ®еҲҶжһҗжөҒзЁӢгҖӮ
иҝҷж¬ЎдҪҝз”Ёзҡ„ж•°жҚ®жҳҜйңҚжҷ®йҮ‘ж–ҜеӨ§еӯҰ收йӣҶзҡ„дё–з•ҢиҢғеӣҙеҶ…зҡ„з—…жҜ’зҲҶеҸ‘ж•°жҚ®гҖӮ
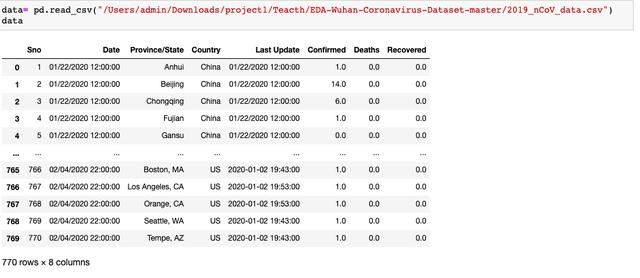
第дёҖпјҡеҲ йҷӨдёҚйңҖиҰҒзҡ„ж•°жҚ®еҲ—
д»Һж•°жҚ®дёӯжҲ‘们еҸҜд»ҘзңӢеҮәпјҢ第дёҖеҲ—зӣёеҪ“дәҺзј–еҸ·пјҢ第дә”еҲ—жҳҜж•°жҚ®жӣҙж–°зҡ„жңҖеҗҺж—¶й—ҙпјҢиҝҷдёӨеҲ—еҜ№жҲ‘们зҡ„еҲҶжһҗжқҘиҜҙжІЎжңүе®һйҷ…ж„Ҹд№үпјҢжүҖд»Ҙе…ҲжҠҠиҝҷдёӨеҲ—иҝӣиЎҢеҲ йҷӨж“ҚдҪңпјҡ
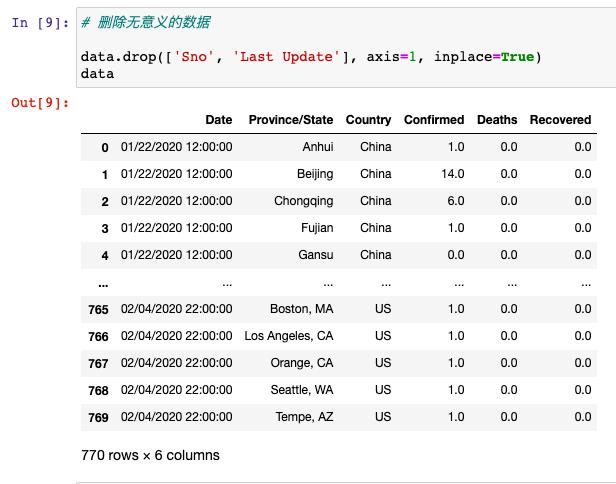
第дәҢпјҡеҜ№ж•°жҚ®йӣҶдёӯзҡ„з©әеҖјиҝӣиЎҢеӨ„зҗҶ
е…ҲжқҘзңӢдёҖдёӢж•°жҚ®зҡ„ж•ҙдҪ“жғ…еҶөпјҡ
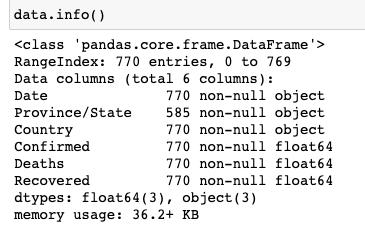
жҲ‘们еҸ‘зҺ°пјҢеҸӘжңүзңҒд»ҪиҝҷдёҖдёӘеӯ—ж®өжҳҜжңүз©әеҖјзҡ„пјҢйӮЈжҲ‘们еҶҚжқҘзңӢдёҖдёӢе…·дҪ“зҡ„з©әеҖјжңүе“Әдәӣпјҡ
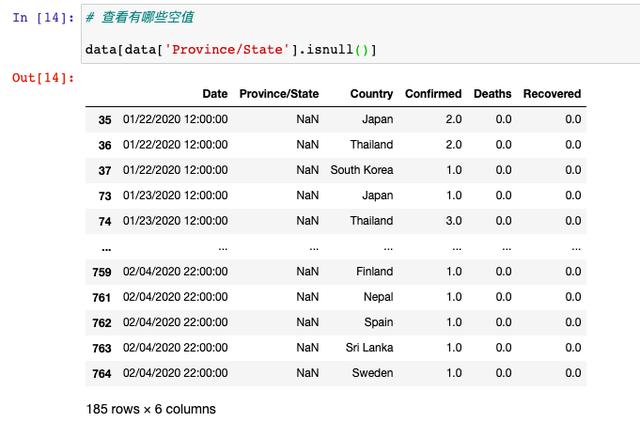
з»ҸиҝҮзӯӣйҖүеҸ‘зҺ°пјҢз©әзјәзҡ„йғҪжҳҜдёҖдәӣеӣҪеӨ–зҡ„зңҒд»ҪпјҢиҝҷжҳҜз”ұдәҺж•°жҚ®ж”¶йӣҶиҝҮзЁӢдёӯдә§з”ҹзҡ„пјҢ并且жҲ‘д»¬ж— д»ҺжҺЁж–ӯеҲ°еә•жҳҜд»Җд№ҲпјҢжүҖд»ҘпјҢиҝҷйҮҢзҡ„з©әеҖјжҲ‘们йҖүжӢ©дёҚеӨ„зҗҶгҖӮ
第дёүпјҡеҲ йҷӨйҮҚеӨҚж•°жҚ®
йҖҡиҝҮдҪҝз”Ёdumplicateж–№жі•пјҢжҲ‘们еҸ‘зҺ°иҝҷдёӘдәәе·Ҙж•ҙзҗҶзҡ„ж•°жҚ®йӣҶдёҚеӯҳеңЁйҮҚеӨҚжғ…еҶөпјҢжүҖд»Ҙд№ҹдёҚйңҖиҰҒиҝӣиЎҢеҺ»йҮҚж“ҚдҪңгҖӮ
жҲ‘们йҰ–е…ҲжқҘзңӢдёҖдёӢпјҢжҲӘжӯўеҲ°ж•°жҚ®е®ҢжҲҗж—¶й—ҙпјҢдё–з•ҢдёҠжҖ»е…ұжңүеӨҡе°‘еӣҪ家已з»ҸгҖҢжІҰйҷ·гҖҚдәҶпјҡ

йҖҡиҝҮз»ҹи®ЎеҸ‘зҺ°пјҢжҖ»е…ұеҸӘжңү32дёӘеӣҪ家已з»ҸжңүдәҶзЎ®иҜҠжӮЈиҖ…пјҢдҪҶжҳҜпјҢз»Ҷеҝғзҡ„еҗҢеӯҰеҸҜиғҪдјҡеҸ‘зҺ°пјҢеӣҪ家еҲ—иЎЁеҪ“дёӯжңүгҖҢChinaгҖҚе’ҢгҖҢMainland ChinaгҖҚпјҢ第дәҢдёӘиЎЁзӨәзҡ„жҳҜгҖҢдёӯеӣҪеӨ§йҷҶгҖҚпјҢе…¶е®һд№ҹжҳҜдёӯеӣҪпјҢжүҖд»ҘжҲ‘们еә”иҜҘжҠҠгҖҢMainland ChinaгҖҚд№ҹж”№дёәгҖҢChinaгҖҚз»ҹдёҖеҸЈеҫ„пјҢеңЁе®һйҷ…е·ҘдҪңиҝҮзЁӢдёӯпјҢи·ЁйғЁй—Ёзҡ„ж•°жҚ®з»ҸеёёдјҡеҮәзҺ°иҝҷз§Қжғ…еҶөпјҢжүҖд»ҘпјҢеӨ„зҗҶиҝҷз§Қж•°жҚ®еҷӘйҹід№ҹжҳҜж•°жҚ®еҲҶжһҗеёҲзҡ„ж—Ҙеёёе·ҘдҪңд№ӢдёҖгҖӮ
жҺҘзқҖпјҢжҲ‘们зңӢдёҖдёӢж—¶й—ҙеӯ—ж®өпјҢж—¶й—ҙеӯ—ж®өзҡ„еӨ„зҗҶд№ҹжҳҜж•°жҚ®еҲҶжһҗиҝҮзЁӢдёӯдёҚеҸҜжҲ–зјәзҡ„дёҖдёӘжӯҘйӘӨпјҡ

иҝҷйҮҢзҡ„ж—¶й—ҙпјҢйғҪжҳҜзІҫзЎ®еҲ°гҖҢе°Ҹж—¶гҖҚзҡ„пјҢдёәдәҶдҫҝдәҺз»ҹи®ЎпјҢжҲ‘们жҠҠе®ғж”№жҲҗзІҫзЎ®еҲ°гҖҢж—ҘгҖҚпјҡ
жҺҘдёӢжқҘпјҢжҲ‘们д»ҘеӣҪ家дҪңдёәз»ҙеәҰпјҢжқҘз»ҹи®ЎдёҖдёӢжҜҸдёӘеӣҪ家зҡ„зЎ®иҜҠдәәж•°пјҡ
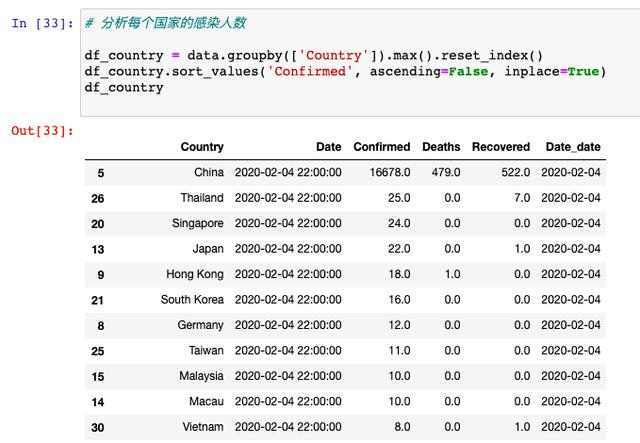
жҺ’еҗҚ第дёҖзҡ„иӮҜе®ҡжҳҜдёӯеӣҪпјҢжҺ’еҗҚйқ еүҚзҡ„еҹәжң¬йғҪжҳҜдёӯеӣҪдёҙиҝ‘зҡ„дәҡжҙІеӣҪ家пјҢ欧зҫҺеӣҪ家еҪ“дёӯпјҢжҺ’еҗҚ第дёҖзҡ„жҳҜеҫ·еӣҪпјҢеҰӮжһңжҳҜзңҹжӯЈе·ҘдҪңиҝҮзЁӢдёӯпјҢеҫ·еӣҪиҝҷдёҖзӮ№е°ұжҳҜгҖҢејӮеёёзӮ№гҖҚпјҢиӮҜе®ҡиҰҒж·ұе…ҘжҢ–жҺҳпјҢеңЁиҝҷйҮҢжҲ‘们еҸӘжҳҜеҒҡдёҖдёӘзӨәдҫӢгҖӮ
д№ӢеҗҺжҲ‘们д»Ҙж—¶й—ҙдҪңдёәз»ҙеәҰпјҢеҲҶжһҗдёҖдёӢжҜҸеӨ©зҡ„ж„ҹжҹ“дәәзҫӨж•°йҮҸзҡ„еҸҳеҢ–пјҡ
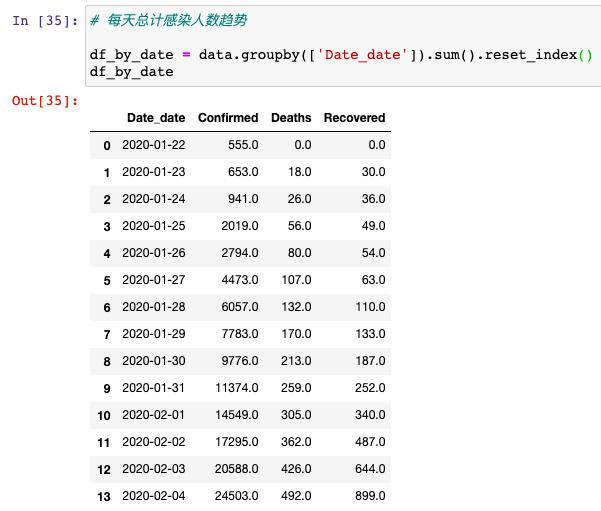
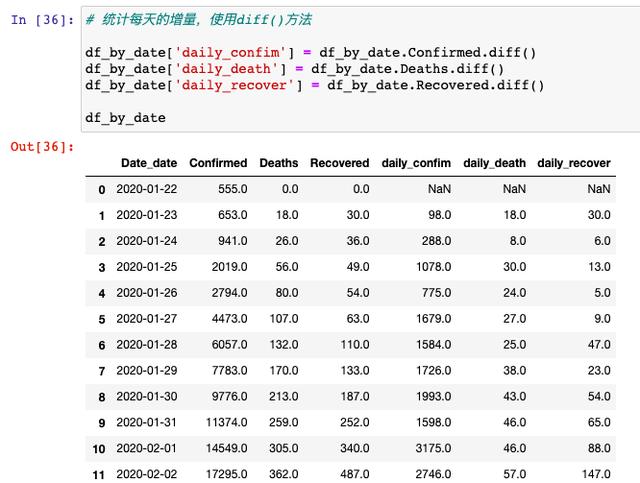
д»ҺиҝҷйҮҢеҸҜд»ҘзңӢеҲ°пјҢ14еӨ©д№ӢеҶ…ж„ҹжҹ“дәәж•°е°ұд»Һ555дәәеўһй•ҝеҲ°24503дёӘдәәпјҢеўһй•ҝйҖҹеәҰиҝҳжҳҜеҫҲеҝ«зҡ„пјҢйӮЈжҲ‘们жҺҘзқҖд№ҹиҰҒе…·дҪ“еҲҶжһҗдёҖдёӢпјҢжҜҸеӨ©ж–°еўһзҡ„зЎ®иҜҠдәәж•°жңүеӨҡе°‘дәәпјҢиҝҷйҮҢжҲ‘们йңҖиҰҒз”ЁеҲ°diff( )ж–№жі•пјҡ
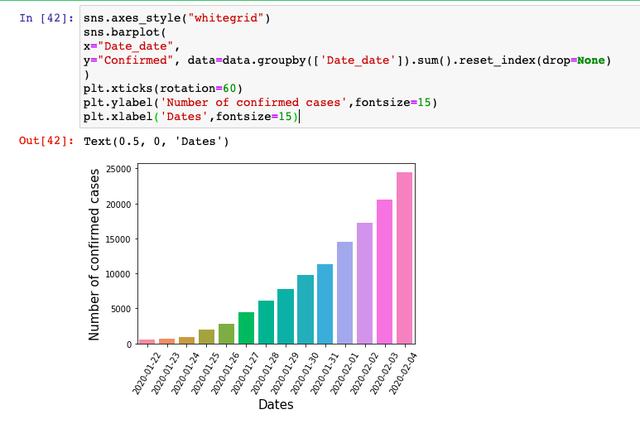
йҰ–е…ҲжқҘзңӢжҜҸеӨ©зҡ„зЎ®иҜҠдәәж•°пјҢеҹәжң¬дёҠжҳҜжҢҮж•°еўһй•ҝзҡ„дёҖдёӘиө°еҠҝпјҢз¬ҰеҗҲдј жҹ“з—…зҡ„зҲҶеҸ‘规еҫӢпјҢжҲ‘们иҰҒеҒҡзҡ„е°ұжҳҜж №жҚ®д№ӢеҗҺзҡ„ж•°жҚ®пјҢжҙһеҜҹжӢҗзӮ№зҡ„еҲ°жқҘгҖӮ
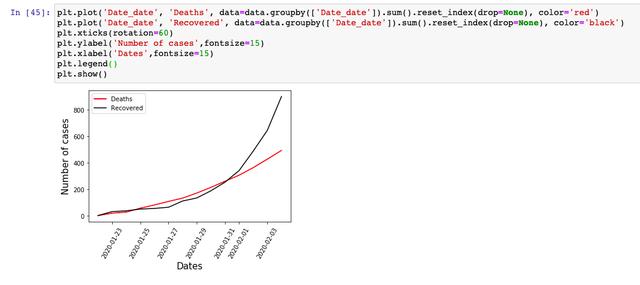
жҺҘзқҖпјҢжҲ‘们зңӢдёҖдёӢпјҢжҜҸеӨ©зҡ„гҖҢжӯ»дәЎдәәж•°гҖҚе’ҢгҖҢжІ»ж„Ҳдәәж•°гҖҚзҡ„иө°еҠҝпјҢд»ҺиҝҷдёӘж•°жҚ®дёҠжқҘзңӢпјҢжІ»ж„Ҳдәәж•°зҡ„еўһй•ҝи¶ӢеҠҝе·Із»Ҹи¶…иҝҮзҡ„жӯ»дәЎдәәж•°пјҢжүҖд»ҘпјҢд»ҺгҖҢжңҖеҘҪгҖҚе’ҢгҖҢжңҖеқҸгҖҚдёӨдёӘж–№йқўжқҘиҜҙзҡ„иҜқпјҢжҖ»дҪ“и¶ӢеҠҝиҝҳжҳҜеҗ‘еҘҪеҸ‘еұ•пјҢеӨ§е®¶д№ҹдёҚеҝ…иҝҮдәҺжӢ…еҝғгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎжҖҺж ·дҪҝз”ЁPythonеҲҶжһҗж–°еһӢеҶ зҠ¶з—…жҜ’зҡ„еҸ‘еұ•и¶ӢеҠҝзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ