您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“Python编程常用技巧有哪些”,在日常操作中,相信很多人在Python编程常用技巧有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python编程常用技巧有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
一、字符串处理技巧
1. 清理用户输入
对输入的的值进行清理处理,是常见的程序要求。比如要做大小写转化、要验证输入字符的注入,通常可以通过写正则用Regex来做专项任务。但是对于复杂的情况,可以用一些技巧,比如下面:
user_input = "This\nstring has\tsome whitespaces...\r\n" character_map = { ord('\n') : ' ', ord('\t') : ' ', ord('\r') : None }在此示例中,可以看到空格字符"\n"和"\t"都被替换为空格,而 "\r"被删除。
这是一个简单的示例,我们还可以使用unicodedata包和combinin()函数来生成大的映射表,以生成映射来替换字符串。
2. 提示用户输入
命令行工具或脚本需要输入用户名和密码才能操作。要用这个功能,一个很有用的技巧是使用getpass模块:
import getpass user = getpass.getuser() password = getpass.getpass()
这三行代码就可以让我们优雅的交互提醒用户输入输入密码并捕获当前的系统用户和输入的密码,而且输入密码时候会自动屏蔽显示,以防止被人窃取。
3. 查找字符串频率
如果需要使用查找类似于某些输入字符串的单词,可以使用difflib来实现:
import difflib difflib.get_close_matches('appel', ['ape', 'apple', 'peach', 'puppy'], n=2)# 返回['apple', 'ape']
difflib.get_close_matches会查找相似度最匹配的字串。本例中,第一个参数与第二个参数匹配。提供可选参数n,该参数指定要返回的最大匹配数,以及参数cutoff(默认值为0.6)设置为thr确定匹配字符串的分数。
4. 多行字符串
Python中可以使用反斜杠:
In [20]: multistr = " select * from test \ ...: where id < 5" In [21]: multistr Out[21]: ' select * from test where id < 5'
还可以使用三引号:
In [23]: multistr ="""select * from test ...: where id < 5""" In [24]: multistr Out[24]: 'select * test where id < 5'
上面方法共有的问题是缺少合适的缩进,如果我们尝试缩进会在字符串中插入空格。所以最后的解决方案是将字符串分为多行并且将整个字符串包含在括号中:
In [25]: multistr = ("select * from multi_row " ...: "where row_id < 5 " ...: "order by age") In [26]: multistr Out[26]: 'select * from multi_row where row_id < 5 order by age'5. 处理IP地址
日常常用的一个是验证和匹配IP地址,这个功能有个专门的模块ipaddress可以来处理。比如我们要用IP网段(CIDR用IP和掩码位)生成一个IP地址列表:
import ipaddress net = ipaddress.ip_network('192.168.1.0/27')结果:
#192.168.1.0 #192.168.1.1 #192.168.1.2 #192.168.1.3 #...
另一个不错的功能IP地址是否在IP段的验证:
ip = ipaddress.ip_address("192.168.1.2") ip in net # True ip = ipaddress.ip_address("192.168.1. 253") ip in net # Falseip地址转字符串、整数值的互转:
>>> str(ipaddress.IPv4Address('192.168.0.1')) '192.168.0.1' >>> int(ipaddress.IPv4Address('192.168.0.1')) 3232235521 >>> str(ipaddress.IPv6Address('::1')) '::1' >>> int(ipaddress.IPv6Address('::1')) 1注意ipaddress还支持很多其他的功能,比如支持ipv4和ipv6等,具体可以参考模块的文档。
二、性能优化技巧
1. 限制CPU和内存使用量
如果Python程序占用资源太大,想限制资源的使用,可以使用resource包。
# CPU限制 def time_exceeded(signo, frame): print("CPU 超额...") raise SystemExit(1) def set_max_runtime(seconds): soft, hard = resource.getrlimit(resource.RLIMIT_CPU) resource.setrlimit(resource.RLIMIT_CPU, (seconds, hard)) signal.signal(signal.SIGXCPU, time_exceeded) # 限制内存使用 def set_max_memory(size): soft, hard = resource.getrlimit(resource.RLIMIT_AS) resource.setrlimit(resource.RLIMIT_AS, (size, hard))对CPU限制时候,先获取特定资源(RLIMIT_CPU)的软限制和硬限制,然后使用参数指定的秒数和获取的硬限制来设置。如果超过CPU时间,将注册导致系统退出的信号。
对内存限制,也先获取软限制和硬限制,并用带有size参数的setrlimit对其进行设置。
2. 通过__slots__节省内存
如果程序中有一个类需要创建大量实例,那么可能会对内存占用会非常大。因为Python使用字典来表示类实例的属性,这可以加速执行,但内存效率很差,通常这不是问题。可以使用__slots__来优化:
import sys class FileSystem(object):
def __init__(self, files, folders, devices): self.files = files self.folders = folders self.devices = devices print(sys.getsizeof( FileSystem )) class FileSystem1(object): __slots__ = ['files', 'folders', 'devices'] def __init__(self, files, folders, devices): self.files = files self.folders = folders self.devices = devices print(sys.getsizeof( FileSystem1 ))

# Python 3.5下
#1-> 1016
#2-> 888
当定义__slots__属性时,Python使用固定大小的数组作为属性,而不用字典,这大大减少了每个实例所需的内存。当然使用__slots__也有缺点,比如,无法声明任何新属性,而且只能在__slots__上使用它们,__slots__的类也不能使用多重继承。
3. 用lru_cache缓存函数调用
都说Python性能差,尤其是一些计算的时候,其实是有一些通用的方法可以解决程序能的问题,比如缓存和记忆术。使用functools中的lru_cache可以解决迭代计算中大量重复迭代调用问题:

# CacheInfo(hits=2, misses=4, maxsize=32, currsize=4)
在上例中,我们执行正在缓存的GET请求(最多3个缓存结果)。还使用cache_info方法检查函数的缓存信息。装饰器还提供了clear_cache方法,用于删除缓存。
4. __all__控制import
某些语言支持import成员(变量,方法,接口)的机制。在Python中,默认所有内容都会import,但是可以使用__all__来限制
def foo(): pass def bar(): pass __all__ = ["bar"]
通过这样的方式我们可以限制从some_module import *使用时可以导入的内容。该实例中,则仅import bar函数。如果将__all__保留为空,并且在使用通配符import时,不会import任何东西,会触发AttributeError错误。
三、面向对象
1. 创建支持With语句的对象
我们都知道如何使用打开或关闭语句,例如打开文件或获取锁,但是如何实现自己的方法呢?
可以使用__enter__和__exit__方法实现:
class Connection: def __init__(self): ... def __enter__(self): # Initialize connection... def __exit__(self, type, value, traceback): # Close connection... with Connection() as c: # __enter__() executes ... # conn.__exit__() executes
这是在Python中实现上下文管理的最常见方法,但是有一种更简单的方法:
from contextlib import contextmanager @contextmanager def tag(name): print(f"<{name}>") yield print(f"</{name}>") with tag("h2"): print("This is Title.")上面的代码段使用contextmanager管理器装饰器实现了内容管理协议。进入with块时,执行标记函数的第一部分(在yield之前),然后执行该块,最后执行其余的标记函数。
2. 重载运算符号的技巧
考虑到有很多比较运算符:__lt__ , __le__ , __gt__,对于一个类实现所有比较运算符可能会很烦人。这时候可以使用functools.total_ordering:
from functools import total_ordering @total_ordering class Number: def __init__(self, value): self.value = value def __lt__(self, other): return self.value < other.value def __eq__(self, other): return self.value == other.value print(Number(20) > Number(3)) print(Number(1) < Number(5)) print(Number(15) >= Number(15)) print(Number(10) <= Number(2))
该代码使用total_ordering装饰器用于简化为类实现实例排序的过程。只需要定义__lt__和__eq__。
3. 在一个类中定义多个构造函数
函数重载是编程语言中非常常见的功能。即使Python不能重载正常的函数,我们也可以使用类方法重载构造函数:
import datetime class Date: def __init__(self, year, month, day): self.year = year self.month = month self.day = day @classmethod def today(cls): t = datetime.datetime.now() return cls(t.year, t.month, t.day) d = Date.today() print(f"{d.day}/{d.month}/{d.year}")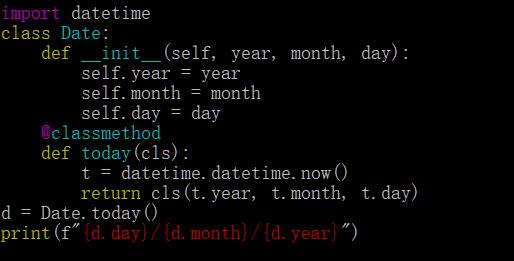
# 14/9/2019
可以不使用构造函数将所有逻辑都放入__init__并使用*args,**kwargs和一堆if语句来解决,但是比较丑陋,没有可读性和可维护性。
4. 获取对象信息
Python提供了几个函数以便我们更好的获取对象的信息,这些函数包括:type、isinstance和dir。
其中type():用于判断对象类型:
>>> type(None) <class 'NoneType'> >>> type(abs) <class 'builtin_function_or_method'>
对类对象type()返回的是对应class类型。下面是判断两个变量的type类型是否相同:
>>> type(11) == type(22) True >>> type('abc') == str True >>> type('abc') == type(33) Falseisinstance():可以显示对象是否是某种类型
>>> class Husty(Dog): ... pass ... >>> a = Animal() >>> b = Dog() >>> c = Husty() >>> isinstance(c,Husty) True >>> isinstance(c,Dog) True >>> isinstance(c,Animal) True >>> isinstance(b,Husty) False
Husty是Husty、Dog、Animal类型的对象,却不能说Dog是Husty的对象。
dir():用于获取一个对象的所有方法和属性。返回值是一个包含字符串的list:
>>> dir('abc') ['__add__', '__class__',…… '__hash__', '__init__', '__i ……'isalnum 'isidentifier', 'islower', …… 'translate', 'upper', 'zfill']其中,类似__xx__的属性和方法都是有特殊用途的。如果调用len()函数视图获取一个对象的长度,其实在len()函数内部会自动去调用该对象的__len__()方法。
5. Iterator和切片
如果直接对Iterator切片,则会得到TypeError,指出生成器对象不可下标反问,但是有一个技巧:
import itertools s = itertools.islice(range(50), 10, 20) for val in s: ...
使用itertools.islice,可以创建一个islice对象,该对象是生成所需项目的迭代器。但是,这会消耗所有生成器项,直到分片开始为止,而且还会消耗islice对象中的所有项。
6. 跳过一些行
有时,必须使用已知以可变数量的不需要的行(例如注释)。也可以使用itertools:
string_from_file = """ // Author: ... // License: ... // // Date: ... Actual content... """ import itertools for line in itertools.dropwhile(lambda line: line.startswith("//"), string_from_file.split("\n")): print(line)该代码段仅在初始注释部分之后产生行。如果只想在迭代器的开头丢弃并且不知道其中有多少个项目,则此方法很有用。
7. 命名切片
使用大量硬编码的索引值会很容易引起代码繁琐和破坏代码可读性。常用的技巧是对索引值使用常量,除此之外我们可以使用命名切片:
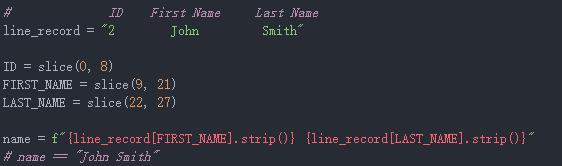
示例中,可以看到可以索引,方法是先使用slice函数命名它们,然后在切出一部分字符串时使用它们。还可以使用切片对象的属性.start,.stop和.step获得更多信息。
四、调试技巧
1. 脚本调试
Python的脚本调试可以是使用pdb模块。它可以让我们在脚本中随意设置设置断点:
import pdb pdb.set_trace()
可以在脚本中任何位置指定pdb.set_trace()并设置断点,非常便捷
2. 在shell中调试程序
在shell中,可以使用python的-i选项就可以启动交互式环境,在该环境下可以打印运行时变量值并调用函数的操作等,比如下面的test.py脚本
def func(): return 0 / 0 func()
在shell中通过python -i test.py运行脚本

我们import pdb然后调用pdb.pm()启动调试器

会显示程序到崩溃的地方,我们退出程序的在该处设置一个断点:
import pdb; def func(): pdb.set_trace() return 0 / 0 func()
再次运行它,会在断点处停止,step到下一步

用这样的方法,我们可以调试和回溯程序的执行。通过设置断点,然后在运行程序时,执行将在断点处停止,可以检查程序,例如列出函数参数,对表达式求值,列出变量或step逐步执行等。
五、有用的小工具
1. 一键web服务共享
在Python中可以使用http.server一键启用一个 HTTP 服务器,这是一个非常方便的共享工具:
python -m http.server
在默认监听端口为 8000 开启一个服务器,可以自定义端口,比如8888
python -m http.server 8888
代码自动补齐Jedi

Jedi是一个用于Python代码自动补齐和静态分析的库。Jedi可以让我们高效的敲代码。

目前Jedi已经提供了绝大多数的编辑器插件,包括Vim(jedi-vim),VSC,Emacs,Sublime,Atom等。
2. 美化异常输出pretty-errors
Python默认的报错输出非常乱,看的人头大,可读性差。这时候就需要用pretty-errors这个错误美化工具了。

到此,关于“Python编程常用技巧有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。