您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“web数组与链表到单链表的反转怎么理解”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“web数组与链表到单链表的反转怎么理解”吧!
数组与链表
数组最大的一个特点就是,需要一块连续的内存空间。假设现在内存空间剩余了 1MB ,但是它不是连续的,这个时候申请一个大小为 1MB 的数组,会告诉你申请失败,因为这个内存空间不连续。
链表最大的一个特点是,不需要一块连续的内存空间。还是上面那个例子,如果申请的不是大小为 1MB 的数组,而是链表,就会申请成功。
如果只是理解到了这个层面,你是不是会觉得,我以后一直用链表这种数据结构就可以了?不不不,数组也有它自己的优势。
阿粉在查阅相关资料时,发现数组简单易用,又因为它使用的是连续内存空间,就可以借助 CPU 的缓存机制,预读数组中的数据,因而访问效率更高,所以在插入,删除操作比较少,而查询比较多的情况下,使用数组是比较有优势的。
链表
在内存中不是连续存储,对 CPU 缓存机制不够友好,也就没办法进行有效预读。所以链表适用于在插入,删除操作比较多的情况下使用。
链表链表分为单链表,循环链表,和双向链表。
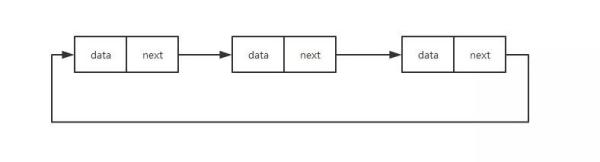
对于单链表来说,它的第一个节点也就是头结点记录着链表的基地址,而最后一个节点也就是尾节点则指向一个空地址 NULL ,循环链表也可以理解成特殊的单链表,只不过尾节点由原来指向一个空地址 NULL 改为了指向头结点。
单链表是这样的:

循环链表是这样的:
但是在实际开发中,更加常用的链表结构是:双向链表。
它的结构是这样的:

我们能够看到它的特点是:占用内存较多,支持双向遍历。因为它有两个指针,所以相对单链表,一个数据就会多占用一些内存。
既然它占用内存较多,为什么在实际开发中还比较常用呢,这里面有一个思想在里面,咱们具体来讲讲。
我们知道,单链表,双链表在删除的时候,时间复杂度为 O(1) ,但是在实际开发中它的时间复杂度并不是这样,为什么呢?
这样想,一般在做数据删除的时候,你的操作是怎样的?
首先,查找在节点中「值等于给定某个值」的节点,找到之后再做删除对吧?也就是说在删除之前,是需要做查找这个工作的。而单向链表和双向链表在查找的时候时间复杂度为 O(n) ,因为它为了找到这个要删除的元素,需要将所有的元素都遍历一遍。将上面过程梳理一下就是,查找时间复杂度为 O(n) ,删除时间复杂度为 O(1) ,总的时间复杂度为 O(n) 。
以上过程在双链表中是怎样的呢?因为双链表支持双向遍历,所以查找这个操作对它来说时间复杂度为 O(1) ,因为它是双向遍历,所以在查找元素时,不需要将所有的元素进行遍历,删除时时间复杂度为 O(1) ,总的时间复杂度为 O(1) 。
因为双向链表的时间复杂度为 O(1) ,所以在开发中它是比较受欢迎的。而在这其中体现的一个最重要的思想就是:空间换时间。
当内存空间相对时间来说不是那么重要的话,那我们是不是就可以忽略次要的因素,着重解决主要矛盾?
光说不做不符合阿粉的风格啊。阿粉今天实现了一个比较常见的单链表操作---单链表反转
单链表反转代码实现
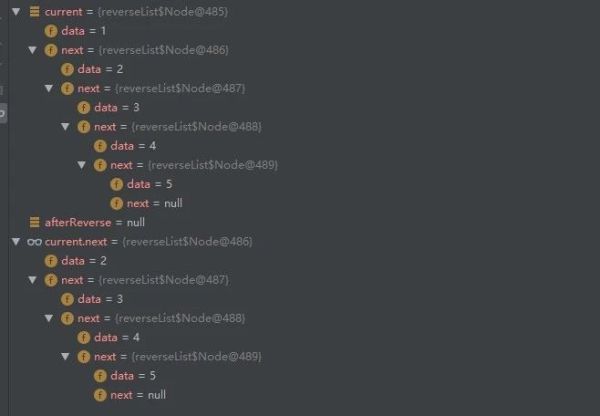
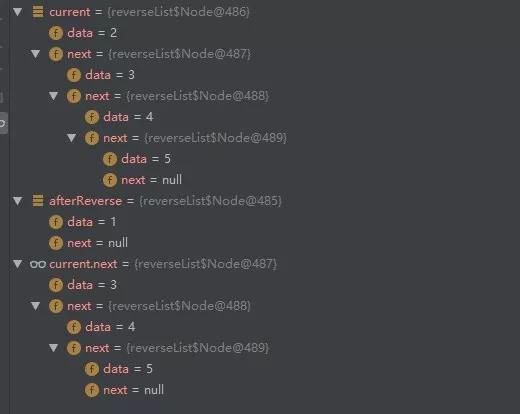
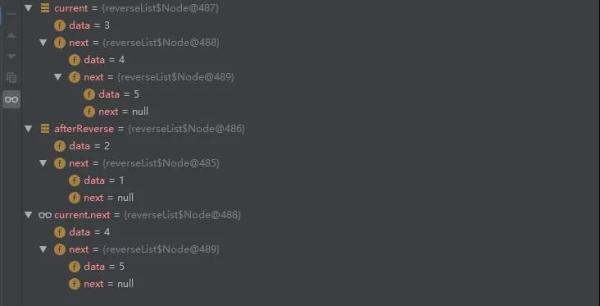
/** * 链表反转 */ public class ReverseList { public static class Node{ private int data; private Node next; public Node(int data , Node next){ this.data=data; this.next=next; } public int getData(){ return data; } } public static void main(String[] args){ // 初始化单链表 Node node5=new Node(5,null); Node node4=new Node(4,node5); Node node3=new Node(3,node4); Node node2=new Node(2,node3); Node node1=new Node(1,node2); // 调用反转方法 Node reverse=reverse(node1); System.out.println(reverse); } /** *单链表反转 * @param list 为传入的单链表 */ public static Node reverse(Node list){ Node current=list, // 定义 current 为当前链表 afterReverse=null; // 定义 afterReverse 为转换之后的新链表,初始为 null // 当前链表不为空,进行反转操作 while (current!=null){ // 1. 保存当前节点的 next 指针指向的链表 Node next=current.next; // 2. 将当前节点的 next 指针指向反转之后的新链表 current.next=afterReverse; // 3. 保存当前的链表状态到新链表中 afterReverse=current; // 4. 将当前节点指针后移一位,进行下一次循环 current=next; } return afterReverse; } }接下来咱们断点调试,看看每次结果:
初始状态:
第一次循环结束
第二次循环结束
第三次循环结束
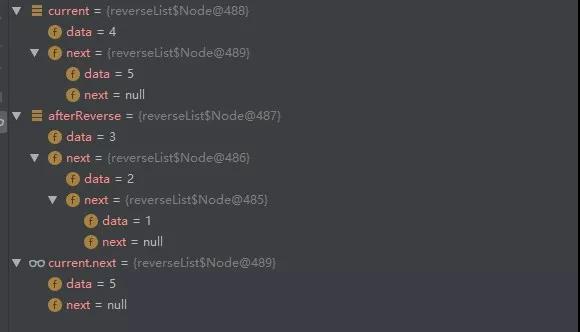
第四次循环结束
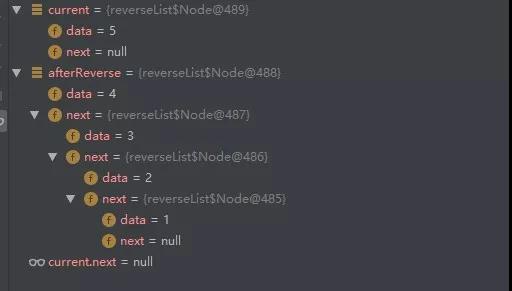
第五次循环结束
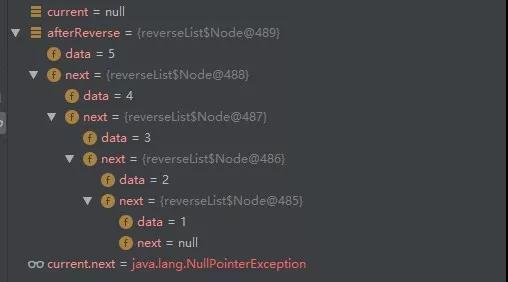
到此,相信大家对“web数组与链表到单链表的反转怎么理解”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。