您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了鲜为人知的Pandas技巧有哪些,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
Pandas为Python营造了一个高水平的操作环境,还提供了便于操作的数据结构和分析工具
对于pandas新手而言,Pandas为Python编程语言营造了一个高水平的操作环境,还提供了便于操作的数据结构和分析工具。Pandas这个名字是由“面板数据”(panel data)衍生而来,这是一个计量经济学中的术语,它是一个数据集,由同一个个体在多个时间段内所观察的结果组成。
1. 数据范围
从外部应用程序接口(API)或者数据库中抓取数据的时候,通常需要确定一个数据范围。Pandas可以很好地解决这一问题,它的data_range函数能够产出按日、月、年等方式递增的日期。
假设现在需要一组按天数递增的数据范围。
date_from ="2019-01-01" date_to = "2019-01-12" date_range = pd.date_range(date_from, date_to, freq="D") date_range

把产出的date_range转化为开始和结束日期,这一步可以用后续函数(subsequentfunction)完成。
for i, (date_from, date_to) inenumerate(zip(date_range[:-1], date_range[1:]), 1): date_from = date_from.date().isoformat() date_to = date_to.date().isoformat() print("%d. date_from: %s,date_to: %s" % (i, date_from, date_to))1. date_from: 2019-01-01,date_to: 2019-01-022. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. 使用指示符合并
合并两个数据集就是将它们变成一个数据集的过程,这需要根据它们的公共属性或栏来对齐其中的每一行。
合并函数中有许多arguments(对应于传递给函数的参数的类数组对象),其中指示符(indicator)argument可主要应用到合并过程中,它在左、右或者两边的数据帧(DataFrame)函数添加_merge栏,这一栏就显示了“数据行是哪里来的”。用_merge栏来处理更大的数据集会非常有用,尤其是需要检查合并操作的正确率时。
left = pd.DataFrame({"key":["key1", "key2", "key3", "key4"],"value_l": [1, 2, 3, 4]})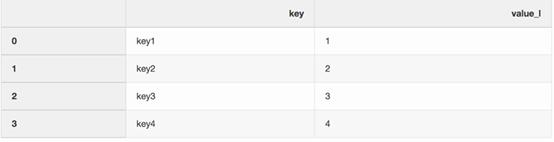
right = pd.DataFrame({"key":["key3", "key2", "key1", "key6"],"value_r": [3, 2, 1, 6]})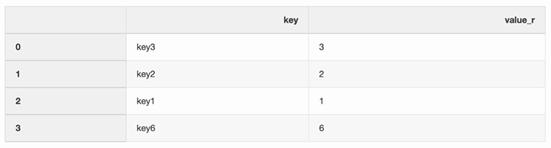
df_merge = left.merge(right,on='key', how='left',indicator=True)
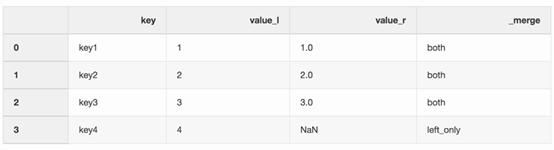
_merge栏可以用来检查是否得到了我们预期的行数,而且它反映的是来自两个数据框架的预期值。
df_merge._merge.value_counts()both 3 left_only 1 right_only 0 Name: _merge, dtype: int64
3. 最近合并(Nearest merge)
在处理像股票或者加密货币一类的金融数据时,还需要把报价(价格变化)与实际交易结合。现在,假设目的是希望将每笔交易与之前几毫秒产生的报价合并起来。Pandas有一个merge_asof函数,它能够通过最近的key(本文中指时间戳)来合并数据框架。有关报价和交易的数据集可以从pandas实例中获得。
报价数据框架包含了不同股票的价格变化。通常情况下,报价要比交易多得多。
quotes = pd.DataFrame( [ ["2016-05-2513:30:00.023", "GOOG", 720.50, 720.93], ["2016-05-2513:30:00.023", "MSFT", 51.95, 51.96], ["2016-05-2513:30:00.030", "MSFT", 51.97, 51.98], ["2016-05-2513:30:00.041", "MSFT", 51.99, 52.00], ["2016-05-2513:30:00.048", "GOOG", 720.50, 720.93], ["2016-05-2513:30:00.049", "AAPL", 97.99, 98.01], ["2016-05-2513:30:00.072", "GOOG", 720.50, 720.88], ["2016-05-2513:30:00.075", "MSFT", 52.01, 52.03], ], columns=["timestamp","ticker", "bid", "ask"], ) quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
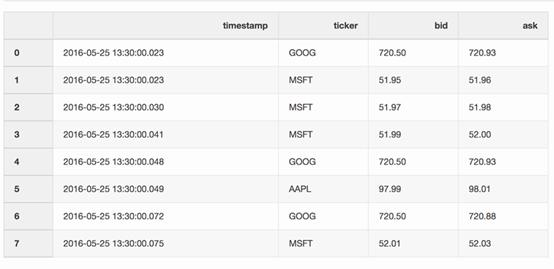
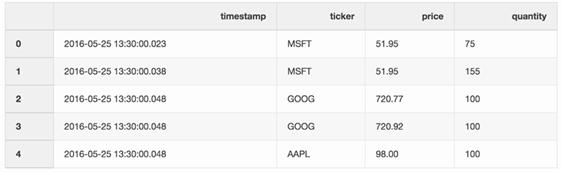
交易数据框架包含了不同股票的交易信息。
trades = pd.DataFrame( [ ["2016-05-2513:30:00.023", "MSFT", 51.95, 75], ["2016-05-2513:30:00.038", "MSFT", 51.95, 155], ["2016-05-2513:30:00.048", "GOOG", 720.77, 100], ["2016-05-2513:30:00.048", "GOOG", 720.92, 100], ["2016-05-2513:30:00.048", "AAPL", 98.00, 100], ], columns=["timestamp","ticker", "price", "quantity"], ) trades['timestamp'] = pd.to_datetime(trades['timestamp'])
通过股价报告(tickers)可以合并交易和报价信息,报告中报价可能只比交易迟了10毫秒。如果报价的时间差长于10毫秒,或者没有报价,任何出价和询问报价都是无效的(以苹果股价报告*为例)。
*苹果股价报告:AAPL ticker。
pd.merge_asof(trades,quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'),direction='backward')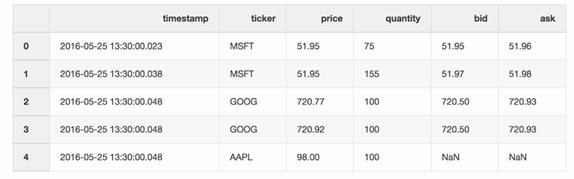
4. 创建Excel报告
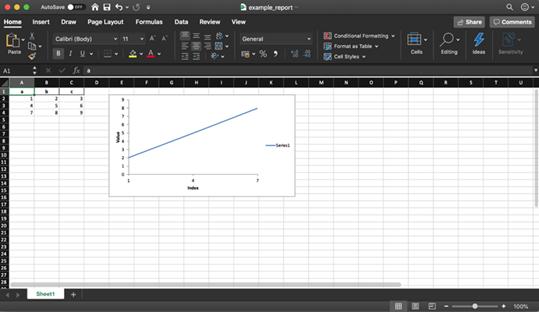
Pandas和XlsxWriter库同时使用能够帮助我们创建基于数据框架的Excel 报告。这能节省很多时间,不用再花时间先把数据框架存为csv格式,然后再导入Excel排版。还可以直接加入各种图表等多种便捷操作。
df = pd.DataFrame(pd.np.array([[1,2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b","c"])
以下的一小段代码就创建了一个Excel报告。要想将一个数据框架存储到Excel文件,需要反注释writer.save()行。
report_name ='example_report.xlsx' sheet_name = 'Sheet1'writer = pd.ExcelWriter(report_name,engine='xlsxwriter') df.to_excel(writer, sheet_name=sheet_name, index=False) # writer.save()
正如前文中提到的那样,这个数据库也支持添加图表到Excel报告中。这需要确定图表的类型(本文中是线形图表)以及图表所反映的数据序列,注意,这些数据序列应位于Excel的电子表格程序里(spreadsheet)。
# define the workbook workbook= writer.book worksheet = writer.sheets[sheet_name]# create a chart lineobject chart = workbook.add_chart({'type': 'line'})# configurethe series of the chart from the spreadsheet # using a list of values instead of category/value formulas: # [sheetname, first_row, first_col,last_row, last_col] chart.add_series({ 'categories': [sheet_name, 1, 0, 3,0], 'values': [sheet_name, 1, 1, 3, 1], })# configure the chart axes chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'}) chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible':False}})# place the chart on the worksheet worksheet.insert_chart('E2', chart)# output the excel file writer.save()5. 节省磁盘空间
同时处理几个数据科学项目,结束后通常会有很多从不同实验中得到的预处理数据集。这样笔记本电脑的固态硬盘很快就会被这些数据塞满。Pandas在保存数据集时发挥作用,压缩数据,读取这些数据时又是解压形式。
不妨创建一个随机数字的大Pandas数据框架。
df = pd.DataFrame(pd.np.random.randn(50000,300))
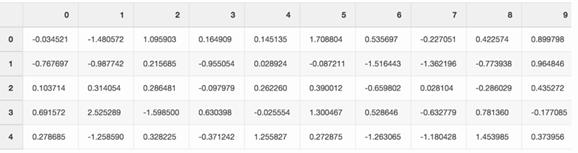
如果把这个文件存为csv格式,它会占掉硬盘驱动器上300MB的空间。
df.to_csv('random_data.csv',index=False)通过一个compression=‘gzip’argument,就可以将文件大小缩至136MB。
df.to_csv('random_data.gz',compression='gzip', index=False)同时,在数据框架上读取gzipped数据也很容易,所以功能上并不会有任何损失。
df = pd.read_csv('random_data.gz')感谢你能够认真阅读完这篇文章,希望小编分享的“鲜为人知的Pandas技巧有哪些”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。