жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңJDKжҳҜеҰӮдҪ•е®һзҺ°ж Ҳзҡ„вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
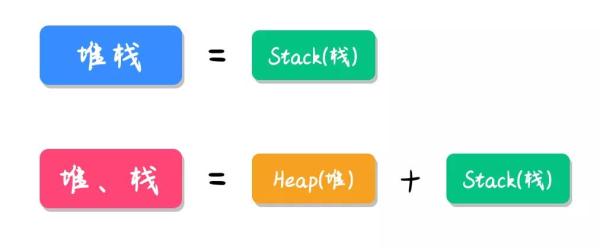
Stack зҝ»иҜ‘дёәдёӯж–ҮжҳҜе Ҷж Ҳзҡ„ж„ҸжҖқпјҢдҪҶдёәдәҶиғҪе’Ң Heap(е Ҷ)еҢәеҲҶејҖпјҢеӣ жӯӨжҲ‘们дёҖиҲ¬е°Ҷ Stack з®Җз§°дёәж ҲгҖӮеӣ жӯӨеҪ“вҖңе Ҷж ҲвҖқиҝһеңЁдёҖиө·ж—¶жңүеҸҜиғҪиЎЁзӨәзҡ„жҳҜ StackпјҢиҖҢеҪ“вҖңе ҶгҖҒж ҲвҖқдёӯй—ҙжңүеҲҶеҸ·ж—¶пјҢеҲҷиЎЁзӨә Heap(е Ҷ)е’Ң Stack(ж Ҳ)пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
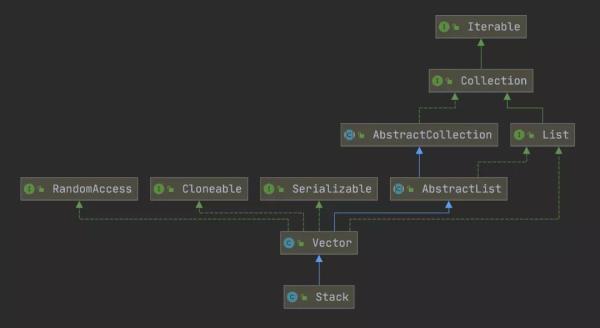
JDK ж Ҳзҡ„е®һзҺ°
иҒҠдјҡжӯЈйўҳпјҢжҺҘдёӢжқҘжҲ‘们жқҘзңӢ JDK дёӯжҳҜеҰӮдҪ•е®һзҺ°ж Ҳзҡ„?
еңЁ JDK дёӯпјҢж Ҳзҡ„е®һзҺ°зұ»жҳҜ StackпјҢе®ғзҡ„继жүҝе…ізі»еҰӮдёӢеӣҫжүҖзӨәпјҡ
Stack еҢ…еҗ«зҡ„ж–№жі•еҰӮдёӢеӣҫжүҖзӨәпјҡ
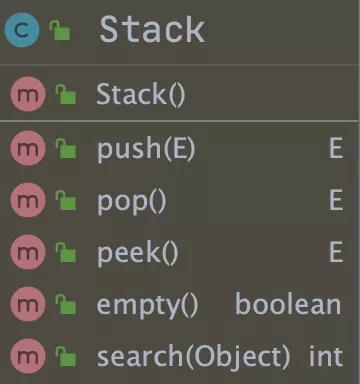
е…¶дёӯжңҖйҮҚиҰҒзҡ„ж–№жі•жңүпјҡ
pushпјҡе…Ҙж Ҳж–№жі•(ж·»еҠ ж•°жҚ®);
popпјҡеҮәж Ҳ并иҝ”еӣһеҪ“еүҚе…ғзҙ (移йҷӨж•°жҚ®);
peekпјҡжҹҘиҜўж ҲйЎ¶е…ғзҙ гҖӮ
Stack е®һзҺ°жәҗз ҒеҰӮдёӢпјҡ
public class Stack<E> extends Vector<E> { /** * еҲӣе»әдёҖдёӘз©әж Ҳ */ public Stack() { } /** * е…Ҙж Ҳж–№жі•пјҢи°ғз”Ёзҡ„жҳҜ Vector#addElement зҡ„ж·»еҠ ж–№жі• */ public E push(E item) { addElement(item); return item; } /** * еҮәж Ҳ并иҝ”еӣһеҪ“еүҚе…ғзҙ пјҢи°ғз”Ёзҡ„жҳҜ Vector#removeElementAt зҡ„移йҷӨе…ғзҙ ж–№жі• */ public synchronized E pop() { E obj; // иҝ”еӣһеҪ“еүҚиҰҒ移йҷӨзҡ„ж ҲйЎ¶е…ғзҙ дҝЎжҒҜ int len = size(); obj = peek(); // жҹҘиҜўеҪ“еүҚж ҲйЎ¶е…ғзҙ removeElementAt(len - 1); // 移йҷӨж ҲйЎ¶е…ғзҙ return obj; } /** * жҹҘиҜўж ҲйЎ¶е…ғзҙ пјҢи°ғз”Ё Vector#elementAt зҡ„жҹҘиҜўж–№жі• */ public synchronized E peek() { int len = size(); // жҹҘиҜўеҪ“еүҚж Ҳзҡ„й•ҝеәҰ if (len == 0) // еҰӮжһңдёәз©әж ҲпјҢзӣҙжҺҘжҠӣеҮәејӮеёё throw new EmptyStackException(); return elementAt(len - 1); // жҹҘиҜўж ҲйЎ¶е…ғзҙ зҡ„дҝЎжҒҜ } /** * еҲӨж–ӯж ҲжҳҜеҗҰдёәз©ә */ public boolean empty() { return size() == 0; } // еҝҪз•Ҙе…¶д»–ж–№жі•... }д»ҺдёҠиҝ°жәҗз ҒеҸҜд»ҘзңӢеҮәпјҢ Stack дёӯзҡ„ж ёеҝғж–№жі•дёӯйғҪи°ғз”ЁдәҶзҲ¶зұ» Vector зұ»дёӯзҡ„ж–№жі•пјҢVector зұ»зҡ„ж ёеҝғжәҗз Ғпјҡ
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { protected Object[] elementData; // еӯҳеӮЁж•°жҚ®зҡ„е®№еҷЁ protected int elementCount; // еӯҳеӮЁж•°жҚ®зҡ„е®№йҮҸеҖј /** * ж·»еҠ ж•°жҚ® */ public synchronized void addElement(E obj) { modCount++; // з»ҹи®Ўе®№еҷЁиў«жӣҙж”№зҡ„еҸӮж•° ensureCapacityHelper(elementCount + 1); // зЎ®и®Өе®№еҷЁеӨ§е°ҸпјҢеҰӮжһңе®№йҮҸи¶…еҮәеҲҷиҝӣиЎҢжү©е®№ elementData[elementCount++] = obj; // е°Ҷж•°жҚ®еӯҳеӮЁеҲ°ж•°з»„ } /** * 移йҷӨе…ғзҙ пјҲж №жҚ®дёӢж Ү移йҷӨпјү */ public synchronized void removeElementAt(int index) { modCount++; // з»ҹи®Ўе®№еҷЁиў«жӣҙж”№зҡ„еҸӮж•° // ж•°жҚ®жӯЈзЎ®жҖ§ж•ҲйӘҢ if (index >= elementCount) { throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount); } else if (index < 0) { throw new ArrayIndexOutOfBoundsException(index); } int j = elementCount - index - 1; if (j > 0) { // еҲ йҷӨзҡ„дёҚжҳҜжңҖеҗҺдёҖдёӘе…ғзҙ // жҠҠеҲ йҷӨе…ғзҙ д№ӢеҗҺзҡ„жүҖжңүе…ғзҙ еҫҖеүҚ移еҠЁ System.arraycopy(elementData, index + 1, elementData, index, j); } elementCount--; // ж•°з»„е®№йҮҸ -1 elementData[elementCount] = null; // е°Ҷжң«е°ҫзҡ„е…ғзҙ иөӢеҖјдёә nullпјҲеҲ йҷӨе°ҫйғЁе…ғзҙ пјү } /** * жҹҘиҜўе…ғзҙ пјҲж №жҚ®дёӢж Үпјү */ public synchronized E elementAt(int index) { // е®үе…ЁжҖ§йӘҢиҜҒ if (index >= elementCount) { throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount); } // ж №жҚ®дёӢж Үиҝ”еӣһж•°з»„дёӯзҡ„е…ғзҙ return elementData(index); } // еҝҪз•Ҙе…¶д»–ж–№жі•... }еҜ№дәҺдёҠиҝ°жәҗз ҒдёӯпјҢеҸҜд»ҘжңҖдёҚеҘҪзҗҶи§Јзҡ„е°ұжҳҜ System#arraycopy иҝҷдёӘж–№жі•пјҢе®ғзҡ„дҪңз”Ёе…¶е®һе°ұжҳҜе°ҶеҲ йҷӨзҡ„е…ғзҙ (йқһжң«е°ҫе…ғзҙ )зҡ„еҗҺз»ӯе…ғзҙ дҫқж¬ЎеҫҖеүҚ移еҠЁзҡ„пјҢжҜ”еҰӮд»ҘдёӢд»Јз Ғпјҡ
Object[] elementData = {"Java", "Hello", "world", "JDK", "JRE"}; int index = 3; int j = elementData.length - index - 1; System.arraycopy(elementData, index + 1, elementData, index, j); // System.arraycopy(elementData, 4, elementData, 3, 1); System.out.println(Arrays.toString(elementData));е®ғзҡ„иҝҗиЎҢз»“жһңжҳҜпјҡ
[Java, Hello, world, JRE, JRE]
д№ҹе°ұжҳҜиҜҙеҪ“жҲ‘们иҰҒеҲ йҷӨдёӢж Үдёә 3 зҡ„е…ғзҙ ж—¶пјҢйңҖиҰҒжҠҠ 3 д»ҘеҗҺзҡ„е…ғзҙ еҫҖеүҚ移еҠЁпјҢжүҖд»Ҙж•°з»„зҡ„еҖје°ұд»Һ {"Java", "Hello", "world", "JDK", "JRE"} еҸҳдёәдәҶ [Java, Hello, world, JRE, JRE]пјҢжңҖеҗҺжҲ‘们еҸӘйңҖиҰҒжҠҠе°ҫйғЁе…ғзҙ еҲ йҷӨжҺүпјҢе°ұеҸҜд»Ҙе®һзҺ°ж•°з»„дёӯеҲ йҷӨйқһжң«е°ҫе…ғзҙ зҡ„еҠҹиғҪдәҶгҖӮ
е°Ҹз»“
йҖҡиҝҮд»ҘдёҠжәҗз ҒеҸҜд»Ҙеҫ—зҹҘпјҢJDK дёӯзҡ„ж Ҳ(Stack)д№ҹжҳҜйҖҡиҝҮзү©зҗҶз»“жһ„ж•°з»„е®һзҺ°зҡ„пјҢжҲ‘们йҖҡиҝҮж“ҚдҪңзү©зҗҶж•°з»„жқҘе®һзҺ°йҖ»иҫ‘з»“жһ„ж Ҳзҡ„еҠҹиғҪгҖӮ
ж Ҳзҡ„еә”з”Ё
з»ҸиҝҮеүҚйқўзҡ„еӯҰд№ жҲ‘们еҜ№ж Ҳе·Із»ҸжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈдәҶпјҢйӮЈж ҲеңЁжҲ‘们зҡ„е№іеёёе·ҘдҪңдёӯжңүе“Әдәӣеә”з”Ёе‘ў?жҺҘдёӢйҮҢжҲ‘们дёҖиө·жқҘзңӢгҖӮ
жөҸи§ҲеҷЁеӣһйҖҖ
ж Ҳзҡ„зү№жҖ§дёә LIFO(Last In First OutпјҢLIFO)еҗҺиҝӣе…ҲеҮәпјҢеӣ жӯӨеҖҹеҠ©жӯӨзү№жҖ§е°ұеҸҜд»Ҙе®һзҺ°жөҸи§ҲеҷЁзҡ„еӣһйҖҖеҠҹиғҪпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ

еҮҪж•°и°ғз”Ёж Ҳ
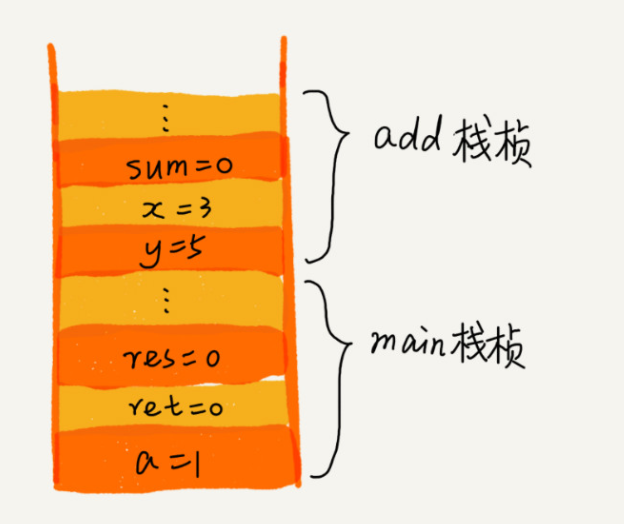
ж ҲеңЁзЁӢеәҸдёӯжңҖз»Ҹе…ёзҡ„дёҖдёӘеә”з”Ёе°ұжҳҜеҮҪж•°и°ғз”Ёж ҲдәҶ(жҲ–еҸ«ж–№жі•и°ғз”Ёж Ҳ)пјҢжҜ”еҰӮж“ҚдҪңзі»з»ҹз»ҷжҜҸдёӘзәҝзЁӢеҲҶй…ҚдәҶдёҖеқ—зӢ¬з«Ӣзҡ„еҶ…еӯҳз©әй—ҙпјҢиҝҷеқ—еҶ…еӯҳиў«з»„з»ҮжҲҗвҖңж ҲвҖқиҝҷз§Қз»“жһ„, з”ЁжқҘеӯҳеӮЁеҮҪж•°и°ғз”Ёж—¶зҡ„дёҙж—¶еҸҳйҮҸгҖӮжҜҸиҝӣе…ҘдёҖдёӘеҮҪж•°пјҢе°ұдјҡе°Ҷдёҙж—¶еҸҳйҮҸдҪңдёәдёҖдёӘж Ҳеё§е…Ҙж ҲпјҢеҪ“иў«и°ғз”ЁеҮҪж•°жү§иЎҢе®ҢжҲҗпјҢиҝ”еӣһд№ӢеҗҺпјҢе°ҶиҝҷдёӘеҮҪж•°еҜ№еә”зҡ„ж Ҳеё§еҮәж ҲгҖӮдёәдәҶи®©дҪ жӣҙеҘҪең°зҗҶи§ЈпјҢжҲ‘们дёҖеқ—жқҘзңӢдёӢиҝҷж®өд»Јз Ғзҡ„жү§иЎҢиҝҮзЁӢгҖӮ
int main() { int a = 1; int ret = 0; int res = 0; ret = add(3, 5); res = a + ret; System.out.println(res); reuturn 0; } int add(int x, int y) { int sum = 0; sum = x + y; return sum; }д»Һд»Јз ҒдёӯжҲ‘们еҸҜд»ҘзңӢеҮәпјҢ main() еҮҪж•°и°ғз”ЁдәҶ add() еҮҪж•°пјҢиҺ·еҸ–и®Ўз®—з»“жһңпјҢ并且дёҺдёҙж—¶еҸҳйҮҸ a зӣёеҠ пјҢжңҖеҗҺжү“еҚ° res зҡ„еҖјгҖӮдёәдәҶи®©дҪ жё…жҷ°ең°зңӢеҲ°иҝҷдёӘиҝҮзЁӢеҜ№еә”зҡ„еҮҪж•°ж ҲйҮҢеҮәж ҲгҖҒе…Ҙж Ҳзҡ„ж“ҚдҪңпјҢжҲ‘з”»дәҶдёҖеј еӣҫгҖӮеӣҫдёӯжҳҫзӨәзҡ„жҳҜпјҢеңЁжү§иЎҢеҲ° add() еҮҪж•°ж—¶пјҢеҮҪж•°и°ғз”Ёж Ҳзҡ„жғ…еҶөгҖӮ
ж Ҳзҡ„еӨҚжқӮеәҰ
еӨҚжқӮеәҰеҲҶдёәдёӨдёӘз»ҙеәҰпјҡ
ж—¶й—ҙз»ҙеәҰпјҡжҳҜжҢҮжү§иЎҢеҪ“еүҚз®—жі•жүҖж¶ҲиҖ—зҡ„ж—¶й—ҙпјҢжҲ‘们йҖҡеёёз”ЁгҖҢж—¶й—ҙеӨҚжқӮеәҰгҖҚжқҘжҸҸиҝ°;
з©әй—ҙз»ҙеәҰпјҡжҳҜжҢҮжү§иЎҢеҪ“еүҚз®—жі•йңҖиҰҒеҚ з”ЁеӨҡе°‘еҶ…еӯҳз©әй—ҙпјҢжҲ‘们йҖҡеёёз”ЁгҖҢз©әй—ҙеӨҚжқӮеәҰгҖҚжқҘжҸҸиҝ°гҖӮ
иҝҷдёӨз§ҚеӨҚжқӮеәҰйғҪжҳҜз”ЁеӨ§ O иЎЁзӨәжі•жқҘиЎЁзӨәзҡ„пјҢжҜ”еҰӮд»ҘдёӢд»Јз Ғпјҡ
int[] arr = {1, 2, 3, 4}; for (int i = 0; i < arr.length; i++) { System.out.println(i); }з”ЁеӨ§ O иЎЁзӨәжі•жқҘиЎЁзӨәзҡ„иҜқпјҢе®ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰе°ұжҳҜ O(n)пјҢиҖҢеҰӮдёӢд»Јз Ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰеҚҙдёә O(1)пјҡ
int[] arr = {1, 2, 3, 4}; System.out.println(arr[0]); // йҖҡиҝҮдёӢж ҮиҺ·еҸ–е…ғзҙ еӣ жӯӨеҰӮжһңдҪҝз”ЁеӨ§ O иЎЁзӨәжі•жқҘиЎЁзӨәж Ҳзҡ„еӨҚжқӮеәҰзҡ„иҜқпјҢз»“жһңеҰӮдёӢжүҖзӨәпјҡ

вҖңJDKжҳҜеҰӮдҪ•е®һзҺ°ж Ҳзҡ„вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ