您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“Linux调度器BFS有哪些作用”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Linux调度器BFS有哪些作用”吧!
BFS 是一个进程调度器,可以解释为“脑残调度器”。这古怪的名字有多重含义,比较容易被接受的一个说法为:它如此简单,却如此出色,这会让人对自己的思维能力产生怀疑。
BFS 不会被合并进入 Linus 维护的 Linux mainline,BFS 本身也不打算这么做。但 BFS 拥有众多的拥趸,这只有一个原因:BFS 非常出色,它让用户的桌面环境达到了前所未有的流畅。在硬件越来越先进,系统却依然常显得迟钝的时代,这实在让人兴奋。
进入 2010 年,Android 使用 BFS 作为其操作系统的标准调度器,这也证明了 BFS 的价值。
BFS vs CFS,性能测试比拼
BFS 出现后得到了很多用户的好评,得到了诸如“快,感觉的到的快”,“桌面的急速未来”等评价。这些词让人侧目,于是我便开始四下寻找关于 BFS 的测试数据,希望能找到说明这一切的数字或者曲线。但结果却颇令人失望。。。
Jens Axboe 的测试
BFS 发布后不久,即 2009 年 9 月,Ingo Molnar 发布了他的测评报告,比较了 CFS 和 BFS。作为 CFS 的作者 , 他所宣称的测试结果并不让人觉得意外:CFS 在各个方面优于 BFS。不过人们对他的测评结果有不同的反应,有人认同,也有人心存疑惑。Jens Axboe 就是心存怀疑的一位,他自己写了一个名为 Latt.c 的程序,试图测试调度器的两个神秘属性:”Interactivity”和 “Fluidness”。
他的测试结果刚好相反,表明 BFS 在交互性方面优于 CFS,而且其 CPU 利用率更高。不过 BFS 稳定性较差,并且在某些情况下也表现出了糟糕的交互性问题。
从 Jens 的测试数据来看,BFS 稍微优于 CFS,但优势并非如同坊间流传的那样夸张。感兴趣的读者可以在 lkml 的邮件列表中找到 Jens 测试的详细数据:http://thread.gmane.org/gmane.linux.kernel/886319/focus=887636
结果让翘首以盼的我有些失望,并没有看到 BFS 遥遥领先。反而有些类似奥运会男子百米的决赛,究竟谁是冠军一时竟难以分辨。但值得注意的是,该测试意外地让人们认识到了 CFS 本身的一个严重问题。
CFS 的 sleeper fairness 特性导致在一些情况下将出现严重的调度延迟,在 Jens 的 xmodmap测试中甚至出现了 10s 的延迟。并且围绕 Jens 的测试,人们纷纷发表声明,使用 CFS 时有很多交互性问题,比如编译内核时,同时的音频视频会出现严重的停顿,而使用 BFS 则没有这些问题。不过这些 CFS 的问题都在关闭了 sleeper fairness 特性后神秘地消失了。
这让 CFS 调度器的开发者不得不暂时关闭了 sleeper fairness 特性,并一度曾号称将在即将发布的 2.6.32 中正式关闭该特性,直到问题被解决为止。令人吃惊的是,Ingo 在一周之内就抛出了新的 patch,即 Gentle Fairness。使用这个 patch,10s 延迟消失了,其他的关于鼠标滞后,视频停顿的关于 CFS 的负面报告也都消失了。。。
Phoronix 的测试
您可以在 http://www.phoronix.com/scan.php?page=article&item=bfs_scheduler_benchmarks&num=1和 http://global.phoronix-test-suite.com/?k=profile&u=zero-9274-28890-6247看到 Phoronix 对 BFS 的专业测试。该测试也是在 2009 年 9 月完成的,如前所述,此后 BFS 和 CFS 都有了一些更新,因此该测试也不能完全反映这两款调度器最新的状态。但作为权威的测评机构,该测评结果还是值得一看。
从 Phoronix 的测试结果来看,BFS 在多项测试中稍微领先,CFS 则在其余一些测试项目中反超。我不禁又有些黯然。
唯一能体现 BFS“急速”的测试项目来自针对网络服务器吞吐量的测试,特在此处张贴这张最具有说服力和震撼力的直方图。
图 1. 网络吞吐量测试
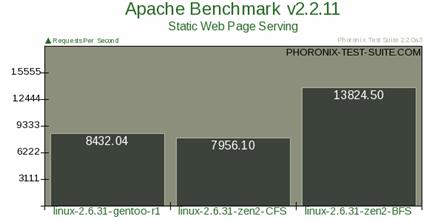
但除此一项之外,总的来讲,Phoronix 的测试结果终究只是表明 BFS 和 CFS 旗鼓相当。
University of New Mexico 计算机系的测评
新墨西哥大学的 Taylor Groves, Je Knockel, Eric Schulte 在 2009 年 12 月也发布了一个 BFS vs. CFS 的评测报告。
他们的测评关注于三个方面:延迟 , Turnaround Time 还有交互性。下面摘录他们的测试结果。
图 2. 延迟
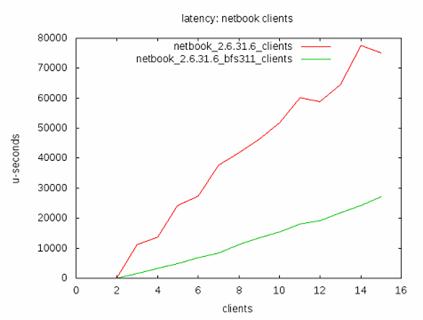
图 3. Turnaround Time
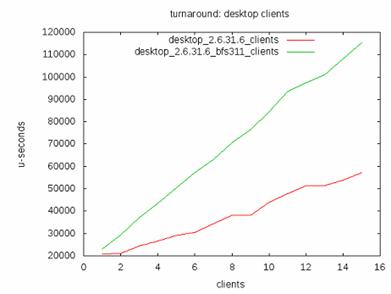
图 4. 交互性
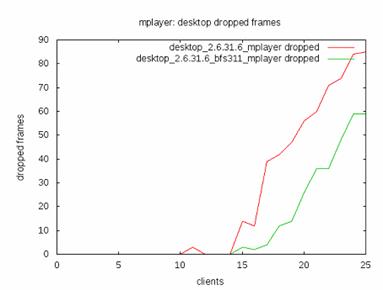
这三张图总算聊以安慰我四处找寻的辛苦,根据这个评测结果,终于可以得到这样的结论:
在 turnaround time 方面,CFS 优于 BFS。但是 BFS 的调度延迟小于 CFS。这说明 BFS 更加适应于交互式应用环境。CFS 更加适合于批处理作业环境。这跟许多用户的体验相同。
小结
以上三个测评都是在 Linux2.6.32 发布前完成的。然而 CFS 在 Linux2.6.32 中引入了 GENTLE_FAIR_SLEEPERS 特性,正如 2.1 节中所说,这个 patch 据说是极大地提高了交互性。不幸的是,在那以后,却似乎再也没有人做关于 CFS 和 BFS 的比较测试了。因此在 Linux 已经进入 2.6.35 的时代,我们更无法轻易得出 BFS 和 CFS 孰优孰劣的结论。
从另一方面讲,虽然专业评测没有显示出 BFS 的明显优势,但从 Internet 上能收集到的信息来看,大多数用户都觉得 BFS 能够显著地提高交互式应用的体验,这是一种个人的体验,比如鼠标的移动是否流畅等等。在这类体验中,两款调度器的差异却是相当大,这无法用前面的测试数据来加以说明。
因此我认为,目前人们并没有理解影响交互性的真正原因,专业测试所关注的数据尚无法准确描述诸如“流畅”这类主观的感觉。因此,对于 BFS,我们不妨相信感觉一次吧。
那么 BFS 究竟做了哪些改进,如果这些改进如此有效,为什么主流内核不愿意接纳 BFS 呢?
BFS vs CFS,设计上的不同
白天 Con Kolivas 在医院里当麻醉师,为人们解除痛苦,业余的时候借 Linux 解除自己的痛苦。额,Kolivas 学习 Linux 并不是为了解决痛苦,我臆测而已。但据 Kolivas 自述,他接触 Linux 内核时连 C 语言也没有学习过。。。这个事实证明,语言只是一项工具,对问题本质的深入理解才是写程序的关键。可能还有执着,CFS 和 RSDL 之争导致 Kolivas 离开 Linux 社区,此去经年,当 Kolivas 再次开始看内核代码的时候,他立即发现 CFS 存在以下几个设计上的问题:
CFS 的目标是支持从桌面到高端服务器的所有应用场景,这种大而全的设计思路导致其必须做一些实现上的折中,此外,那些只有在高端机器中才需要的特性将引入不必要的复杂代码。
其次,为了维护多 CPU 上的公平性,CFS 采用了负载平衡机制,Kolivas 认为,这些复杂代码抵消了 per cpu queue 曾带来的好处。
最后,主流内核的 CFS 还是对睡眠进程存在一些偏好,这意味着“不公平”。
设计目标的不同
在现实中,调度算法类似一个处境尴尬的主妇,满足孩子对晚餐的要求便有可能伤害到老人的食欲。Linux 内核一直试图做出一道让全家老少都喜欢的菜,在这方面,CFS 已经做的很好。但一道能被所有人接受的菜,或许就意味着稍许平淡。而 BFS 只打算满足一种口味,以便将这种口味发展到极限。
根据 Linux Magazine 的说法,Con Kolivas 是看到了下面这则来自 xkcd 的漫画而开始思考 BFS 的。
图 5. 讥讽 Linux 调度器的 xkcd 漫画

事情源于一些 Linux 用户,他们发现 Linux 虽然号称能够充分发挥 4096 颗 CPU 系统的计算能力,但在普通的 laptop 上却无法流畅地播放 Youtube 视频。
这让人们开始思考,对于 Desktop 环境来讲,CFS 哪些复杂的特性究竟是否还有意义?人们是否有必要在自己的个人电脑中使用一个支持 4096 个 CPU 的调度器?
BFS 正是对这种质疑的自然反应。它不打算支持 4096 个 CPU 的庞然大物,BFS 的目标是普通人使用的桌面电脑。此外,BFS 还删除了那些只有在服务器上才需要的特性。比如,BFS 抛弃了 CFS 的组调度特性,类似 CGROUP 这样的特性对于普通的桌面用户是多余的技术。
这很容易理解:在只有一个 CPU 的系统中,谁还会设计多个 CGroup,哪里还能用到 NUMA domain 等概念呢?
此外 BFS 使用单一的 run queue,不再需要复杂的负载均衡机制。由于不再有 CGROUP 概念,也不再需要 Group 间的负载均衡。
这些简单的裁剪使得 BFS 的代码极大地简化,简化的代码意味着执行一次调度所需要的指令数减少了,相应的 footprint 自然也减少了。
当然简化代码只是一个显而易见的方面,更重要的是,这种理念的不同会对最终的调度器实现产生更加深远的影响,这实在是难以尽述。
多队列 vs 单一队列
在 Linux 内核进入 2.6 时,调度器采用 per cpu run queue 从而克服了单一 run queue 的局限。在多 CPU 系统中,单一 run queue 意味着 run queue 成为了系统的瓶颈,因为在同一时刻,一个 CPU 访问 run queue 时,其他的 CPU 即使空闲也必须等待。当使用 per CPU 的 run queue 之后,每个 CPU 不必再使用大锁,从而能够并行地处理调度。
但很多事情都不像第一眼看上去那样简单。
Kolivas 发现,采用 per cpu run queue 所带来的好处会被追求公平性的 load balance 代码所抵消。在目前的 CFS 调度器中,每颗 CPU 只维护本地 run queue 中所有进程的公平性,为了实现跨 CPU 的调度公平性,CFS 必须定时进行 load balance,将一些进程从繁忙的 CPU 的 run queue 中移到其他空闲的 run queue 中。
这个 load balance 的过程需要获得其他 run queue 的锁,这种操作降低了多运行队列带来的并行性。
并且在复杂情况下,这种因 load balance 而引入的 footprint 将非常可观。
当然,load balance 引入的加锁操作依然比全局锁的代价要低,这种代价差异随着 CPU 个数的增加而更加显著。但请您注意,BFS 并不打算为那些拥有 1024 个 CPU 的系统工作,假若系统中的 CPU 个数有限时,多 run queue 的优势便不明显了。
而 BFS 采用单一队列之后,每一个需要调度的新进程都可以在全局范围内查找最合适的 CPU,而无需 CFS 那样等待 load balance 代码来决定,这减少了多 CPU 之间裁决的延迟,最终的结果是更小的调度延迟。
向前看还是向后看?
多年来 Kolivas 一直关注着 Linux 在 desktop 上的表现。对于 desktop 的用户,最注重的不是系统的吞吐量,而是交互性程序的流畅体验。从 SD 开始,Kolivas 就告诉内核黑客们,完全公平能够从根本上保证交互性。他始终坚持一个基本观点:调度器应该 forward look only。决不要去考虑一个进程的过去。
CFS 却偏偏要考虑进程的过去。2.6.23 的时候,CFS 记录并使用 sleep time。之后不久,在 2.6.24 发布的时候,CFS 合并了“Real Fair Scheduler”,删除了 sleep time。因此在 2.6.24 之后的内核中,CFS 终于也不再考虑进程过去的睡眠时间。
但 CFS 还是保留了 sleeper fairness 的思想,当进程 wakeup 的时候,在 place_entity() 函数中,CFS 将对 sleeper 进行奖励,以便其能尽快得到 CPU。这个策略是非常微妙的,我们在 2.1 节中详细介绍了 sleeper fairness 的演进过程。假如您花些时间回头再看看,就会发现 sleeper fairness 曾造成怎样严重的延迟问题。虽然 Ingo 自称 Gentle fairness 解决了延迟问题,但从代码上看,Gentle Fairness 只是对 sleeper 的奖励减半而已。因此我们可以说,CFS 依然对 Sleeper 进程进行奖励,这代表着一种偏好,一种“不公平”。而这,正是 BFS 所反对的。
BFS 中,当一个进程 wakeup 时,调度器将根据进程的 deadline 来进行选择(关于 deadline 本文将在第 4 章中详细描述),其结果是,更早睡眠的进程能更快地得到调度;CFS 的 sleeper fairness 则意味着要根据 wakeup 的时间来选择下一个被调度的进程,更早 wakeup 的进程会更快得到调度。
这种不同究竟会对桌面应用造成何种影响尚没有理论依据可以参考。但我个人认为,BFS 的策略更加合理。
您现在可能已经读得有些烦躁了 ( 这些英文加中文的说些啥啊 ),所以我还是尽快介绍一下 BFS 的实现细节吧。然后或许您会理解我,有些词还是不翻译更好。
BFS 实现原理
调度器是非常复杂的话题,尤其是 CFS 调度器,想要描述清楚,需要一支非凡的笔,我还没有找到。但 BFS 非常简单,所以我才有勇气在这里写点儿 BFS 的实现原理什么的。首先介绍几个关键概念。
虚拟 Deadline ( Virtual Deadline )
当一个进程被创建时,它被赋予一个固定的时间片,和一个虚拟 Deadline。该虚拟 deadline 的计算公式非常简单:
Virtual Deadline = jiffies + (user_priority * rr_interval) 公式一
其中 jiffies 是当前时间 , user_priority 是进程的优先级,rr_interval 代表 round-robin interval,近似于一个进程必须被调度的最后期限,所谓 Deadline 么。不过在这个 Deadline 之前还有一个形容词为 Virtual,因此这个 Deadline 只是表达一种愿望而已,并非很多领导们常说的那种 deadline。
虚拟 Deadline 将用于调度器的 picknext 决策,这将在后续章节详细描述。
进程队列的表示方法和调度策略
在操作系统内部,所有的 Ready 进程都被存放在进程队列中,调度器从进程队列中选取下一个被调度的进程。因此如何设计进程队列是我们研究调度器的一个重要话题。BFS 采用了非常传统的进程队列表示方法,即 bitmap 加 queue。
BFS 将所有进程分成 4 类,分别表示不同的调度策略 :
●Realtime,实时进程
●SCHED_ISO,isochronous 进程,用于交互式任务
●SCHED_NORMAL,普通进程
●SCHED_IDELPRO,低优先级任务
实时进程总能获得 CPU,采用 Round Robin 或者 FIFO 的方法来选择同样优先级的实时进程。他们需要 superuser 的权限,通常限于那些占用 CPU 时间不多却非常在乎 Latency 的进程。
SCHED_ISO 在主流内核中至今仍未实现,Con 早在 2003 年就提出了这个 patch,但一直无法进入主流内核,这种调度策略是为了那些 near-realtime 的进程设计的。如前所述,实时进程需要用户有 superuser 的权限,这类进程能够独占 CPU,因此只有很少的进程可以被配置为实时进程。对于那些对交互性要求比较高的,又无法成为实时进程的进程,BFS 将采用 SCHED_ISO,这些进程能够抢占 SCHED_NORMAL 进程。他们的优先级比 SCHED_NORMAL 高,但又低于实时进程。此外当 SCHED_ISO 进程占用 CPU 时间达到一定限度后,会被降级为 SCHED_NORMAL,防止其独占整个系统资源。
SCHED_NORMAL 类似于主流调度器 CFS 中的 SCHED_OTHER,是基本的分时调度策略。
SCHED_IDELPRO 类似于 CFS 中的 SCHED_IDLE,即只有当 CPU 即将处于 IDLE 状态时才被调度的进程。
在这些不同的调度策略中,实时进程分成 100 个不同的优先级,加上其他三个调度策略,一共有 103 个不同的进程类型。对于每个进程类型,系统中都有可能有多个进程同时 Ready,比如很可能有两个优先级为 10 的 RT 进程同时 Ready,所以对于每个类型,还需要一个队列来存储属于该类型的 ready 进程。
BFS 用 103 个 bitmap 来表示是否有相应类型的进程准备进行调度。如下图所示:
图 6. BFS 进程队列
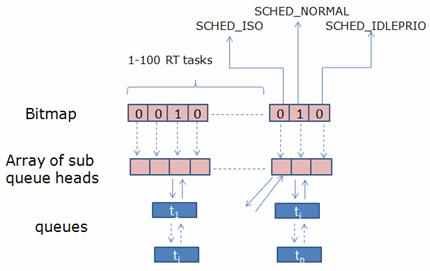
当任何一种类型的进程队列非空时,即存在 Ready 进程时,相应的 bitmap 位被设置为 1。
调度器如何在这样一个 bitmap 加 queue 的复杂结构中选择下一个被调度的进程的问题被称为 Task Selection 或者 pick next。
Task Selection i.e. Pick Next
当调度器决定进行进程调度的时候,BFS 将按照下面的原则来进行任务的选择:
图 7. Task Selection
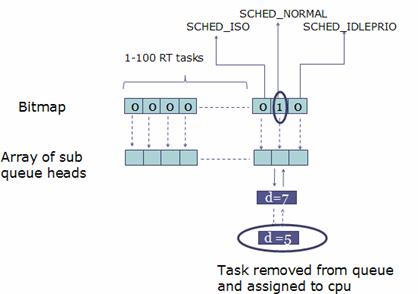
首先查看 bitmap 是否有置位的比特。比如上图,对应于 SCHED_NORMAL 的 bit 被置位,表明有类型为 SCHED_NORMAL 的进程 ready。如果有 SCHED_ISO 或者 RT task 的比特被置位,则优先处理他们。
选定了相应的 bit 位之后,便需要遍历其相应的子队列。假如是一个 RT 进程的子队列,则选取其中的第一个进程。如果是其他的队列,那么就采用 EEVDF 算法来选取合适的进程。
EEVDF,即 earliest eligible virtual deadline first。BFS 将遍历该子队列,一个双向列表,比较队列中的每一个进程的 Virtual Deadline 值,找到最小的那个。最坏情况下,这是一个 O(n) 的算法,即需要遍历整个双向列表,假如其中有 n 个进程,就需要进行 n 此读取和比较。
但实际上,往往不需要遍历整个 n 个进程,这是因为 BFS 还有这样一个搜索条件:
当某个进程的 Virtual Deadline 小于当前的 jiffies 值时,直接返回该进程。并将其从就绪队列中删除,下次再 insert 时会放到队列的尾部,从而保证每个进程都有可能被选中,而不会出现饥饿现象。
这条规则对应于这样一种情况,即进程已经睡眠了比较长的时间,以至于已经睡过了它的 Virtual Deadline,如下图所示:
图 8. 睡眠和唤醒
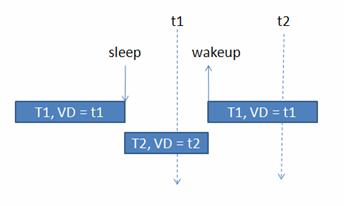
T1 本来的 virtual deadline 为 t1,它 sleep 之后,其他的进程比如 T2 开始运行,等到 T1 再次 wakeup 的时候,当时的 jiffies 已经大于 t1,在这种情况下,T1 无需和其他进程的 virtual deadline 相比较,而直接被 BFS 调度器选取。
基本的调度场景
三个基本的 scenario 可以概括多数的调度情景。系统中发生的每一次调度都属于以下三种情景之一。
进程 wakeup:Task Insertion
睡眠进程 wakeup 时,调度器需要执行 task insertion 的操作,将该进程插入到 run queue 中。BFS 将进程插入相应队列的操作就是执行一个双向队列的插入操作,计算机常用算法结构告诉我们,这个操作是 O(1) 的。不过,BFS 在执行插入操作之前需要首先查看当前进程是否可以抢占当前正在系统中运行的进程。因此它会用新进程的 virtual deadline 值和当前在每个 CPU 上正在运行的进程的 virtual deadline 值进行比较,如果新进程的值小,则直接抢占该 CPU 上正在运行的进程。这个算法是 O(m) 的,其中 m 是 CPU 的个数,假如系统中有 16 个 CPU,那么每次都需要进行 16 次比较。但这个设计却保证了非常好的 low-latency 特性。
进程 Sleep
当前正在运行的进程有可能主动睡眠,此时,调度器需要将该进程从 run queue 中移除,并选择另外一个进程运行。但该进程的 virtual deadline 的值保持不变。
这样该进程 wakeup 时,其 virtual deadline 将相对较小,因为 jiffies 随着时间流逝而不断增加。较小的 Virtual Deadline 可以保证该进程能更快得到调度。
仍然以图 8 为例,系统中有两个进程,T1 和 T2,T1 进入 sleep 状态后其 virtual deadline 仍然为 t1。T2 此时被调度,根据公式一,计算得出其 virtual deadline 为 t2。此后,T1 进程 wakeup 了,此时虽然 T2 的时间片尚未用完,但由于 T1 的 virtual deadline 小于 T2 的,(t1
进程用完自己的时间片
每个进程都拥有自己的时间片,即使不被其他进程抢占,假如属于自己的时间片用完时,当前进程也一定会被剥夺 CPU 时间,以便让别的进程有机会执行。
当前进程的时间片用完后就必须让出 CPU, 此时将它的 virtual deadline 按照公式一重新计算。
这保证了一个特性:只有其他就绪进程都获得 CPU 之后,用完当前时间片的进程才可以再次得到运行,这避免了饥饿。
此时此刻我有一种力不从心之感,介绍似乎不该在此处就戛然截止,但我的确已经讲完了我想要讲的。唯一能做的,便是想在这里抓住最后一个机会进行一个小小的总结。
BFS 专注于单一的目标,因此能够将代码精简到极致。它采用单一 Queue,从而免除了 load balance 的需要,虽然并发性减低,但对于少量 CPU 的桌面系统而言,其快速切换 CPU 的能力应该能够补偿并发的损失,说不定还有盈余。
BFS 只关注未来,它完全公平,一个进程的睡眠习惯以及其过去的种种都不能影响它下一次调度的时机。在 BFS 世界中,调度器严格按照每个进程的 Deadline 进行公平调度,简单,严肃甚至有些单调。
嗯,我必须承认,无法从这些描述中看出什么先进的思想或者特性,但广大用户的真实体验说明了那一切。我想,这或许也正说明用于描述桌面交互性的理论基础还极其缺乏,我只能通过感性而非理性来总结它了。想说的是,我的使用体验是“快,真的很快”。
到此,相信大家对“Linux调度器BFS有哪些作用”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。