您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关如何解析Python深拷贝与浅拷贝问题,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
在平时工作中,经常涉及到数据的传递,在数据传递使用过程中,可能会发生数据被修改的问题。为了防止数据被修改,就需要在传递一个副本,即使副本被修改,也不会影响原数据的使用。为了生成这个副本,就产生了拷贝。今天就说一下Python中的深拷贝与浅拷贝的问题。
概念普及:对象、可变类型、引用
数据拷贝会涉及到Python中对象、可变类型、引用这3个概念,先来看看这几个概念,只有明白了他们才能更好的理解深拷贝与浅拷贝到底是怎么一回事。
Python对象
在Python中,对对象有一种很通俗的说法,万物皆对象。说的就是构造的任何数据类型都是一个对象,无论是数字,字符串,还是函数,甚至是模块,Python都对当做对象处理。
所有Python对象都拥有三个属性:身份、类型、值。
看一个简单的例子:
In [1]: name = "laowang" # name对象 In [2]: id(name) # id:身份的唯一标识 Out[2]: 1698668550104 In [3]: type(name) # type:对象的类型,决定了该对象可以保存什么类型的值 Out[3]: str In [4]: name # 对象的值,表示的数据 Out[4]: 'laowang'
可变与不可变对象
在Python中,按更新对象的方式,可以将对象分为2大类:可变对象与不可变对象。
可变对象: 列表、字典、集合
所谓可变是指可变对象的值可变,身份是不变的。
不可变对象:数字、字符串、元组
不可变对象就是对象的身份和值都不可变。新创建的对象被关联到原来的变量名,旧对象被丢弃,垃圾回收器会在适当的时机回收这些对象。
In [7]: var1 = "python" In [8]: id(var1) Out[8]: 1700782038408 #由于var1是不可变的,重新创建了java对象,随之id改变,旧对象python会在某个时刻被回收 In [9]: var1 = "java" In [10]: id(var1) Out[10]: 1700767578296
引用
在 Python 程序中,每个对象都会在内存中申请开辟一块空间来保存该对象,该对象在内存中所在位置的地址被称为引用。在开发程序时,所定义的变量名实际就对象的地址引用。
引用实际就是内存中的一个数字地址编号,在使用对象时,只要知道这个对象的地址,就可以操作这个对象,但是因为这个数字地址不方便在开发时使用和记忆,所以使用变量名的形式来代替对象的数字地址。 在 Python 中,变量就是地址的一种表示形式,并不开辟开辟存储空间。
就像 IP 地址,在访问网站时,实际都是通过 IP 地址来确定主机,而 IP 地址不方便记忆,所以使用域名来代替 IP 地址,在使用域名访问网站时,域名被解析成 IP 地址来使用。
通过一个例子来说明变量和变量指向的引用就是一个东西。
In [11]: age = 18 In [12]: id(age) Out[12]: 1730306752 In [13]: id(18) Out[13]: 1730306752
逐步深入:引用赋值
上边已经明白,引用就是对象在内存中的数字地址编号,变量就是方便对引用的表示而出现的,变量指向的就是此引用。赋值的本质就是让多个变量同时引用同一个对象的地址。 那么在对数据修改时会发生什么问题呢?
不可变对象的引用赋值。
对不可变对象赋值,实际就是在内存中开辟一片空间指向新的对象,原不可变对象不会被修改。
原理图如下:
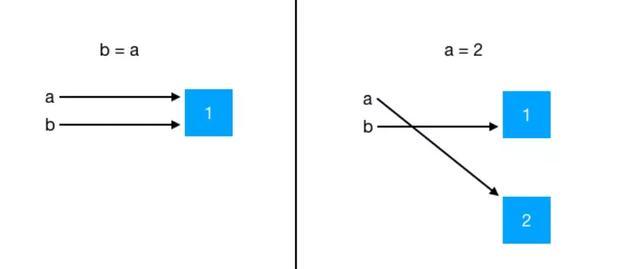
下面通过案例来理解一下:
a与b在内存中都是指向1的引用,所以a、b的引用是相同的。
In [1]: a = 1 In [2]: b = a In [3]: id(a) Out[3]: 1730306496 In [4]: id(b) Out[4]: 1730306496
现在再给a重新赋值,看看会发生什么变化?
从下面不难看出:当给a 赋新的对象时,将指向现在的引用,不在指向旧的对象引用。
In [1]: a = 1 In [2]: b = a In [5]: a = 2 In [6]: id(a) Out[6]: 1730306816 In [7]: id(b) Out[7]: 1730306496
可变对象的引用赋值。
可变对象保存的并不是真正的对象数据,而是对象的引用。当对可变对象进行赋值时,只是将可变对象中保存的引用指向了新的对象。
原理图如下:
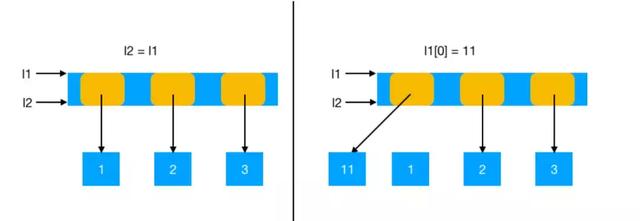
仍然通过一个实例来体会一下,可变对象引用赋值的过程。
当改变l1时,整个列表的引用会指新的对象,但是l1与l2都是指向保存的同一个列表的引用,所以引用地址不会变。
In [3]: l1 = [1, 2, 3] In [4]: l2 = l1 In [5]: id(l1) Out[5]: 1916633584008 In [6]: id(l2) Out[6]: 1916633584008 In [7]: l1[0] = 11 In [8]: id(l1) Out[8]: 1916633584008 In [9]: id(l2) Out[9]: 1916633584008
主旨详解:浅拷贝、深拷贝
经过前2部分的解读,大家对对象的引用赋值应该有了一个清晰的认识了。
下面大家思考一个这样的问题:Python中如何解决原始数据在函数传递之后不受影响了?
这个问题Python已经帮我们解决了,使用对象的拷贝或者深拷贝就可以愉快的解决了。
下面具体来看看Python中的浅拷贝与深拷贝是如何实现的。
浅拷贝:
为了解决函数传递后被修改的问题,就需要拷贝一份副本,将副本传递给函数使用,就算是副本被修改,也不会影响原始数据 。
不可变对象的拷贝
不可变对象只在修改的时候才会在内存中开辟新的空间, 而拷贝实际上是让多个对象同时指向一个引用,和对象的赋值没区别。
同样的,通过一个实例来感受一下:不难看出,a与b指向相同的引用,不可变对象的拷贝就是对象赋值。
In [11]: import copy In [12]: a = 10 In [13]: b = copy.copy(a) In [14]: id(a) Out[14]: 1730306496 In [15]: id(b) Out[15]: 1730306496
可变对象的拷贝
对于不可变对象的拷贝,对象的引用并没有发生变化,那么可变对象的拷贝会不会和不可变对象一样了?我们接着往下看。
通过下面这个实例可以看出:可变对象的拷贝,会在内存中开辟一个新的空间来保存拷贝的数据。当再改变之前的对象时,对拷贝之后的对象没有任何影响。
In [24]: import copy In [25]: l1 = [1, 2, 3] In [26]: l2 = copy.copy(l1) In [27]: id(l1) Out[27]: 1916631742088 In [28]: id(l2) Out[28]: 1916636282952 In [29]: l1[0] = 11 In [30]: id(l1) Out[30]: 1916631742088 In [31]: id(l2) Out[31]: 1916636282952
原理图如下:
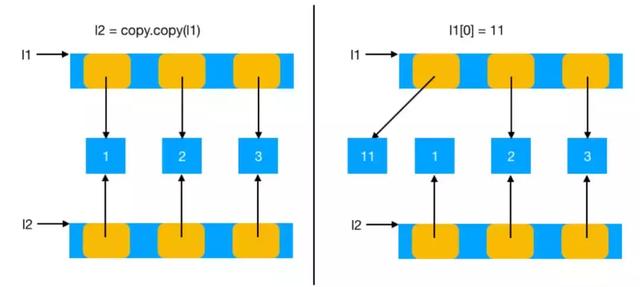
现在再回到刚才那个问题,是不是浅拷贝就可以解决原始数据在函数传递之后不变的问题了?下面看一个稍微复杂一点的数据结构。
通过下面这个实例可以发现:复杂对象在拷贝时,并没有解决数据在传递之后,数据改变的问题。 出现这种原因,是copy() 函数在拷贝对象时,只是将指定对象中的所有引用拷贝了一份,如果这些引用当中包含了一个可变对象的话,那么数据还是会被改变。 这种拷贝方式,称为浅拷贝。
In [35]: a = [1, 2] In [36]: l1 = [3, 4, a] In [37]: l2 = copy.copy(l1) In [38]: id(l1) Out[38]: 1916631704520 In [39]: id(l2) Out[39]: 1916631713736 In [40]: a[0] = 11 In [41]: id(l1) Out[41]: 1916631704520 In [42]: id(l2) Out[42]: 1916631713736 In [43]: l1 Out[43]: [3, 4, [11, 2]] In [44]: l2 Out[44]: [3, 4, [11, 2]]
原理图如下:
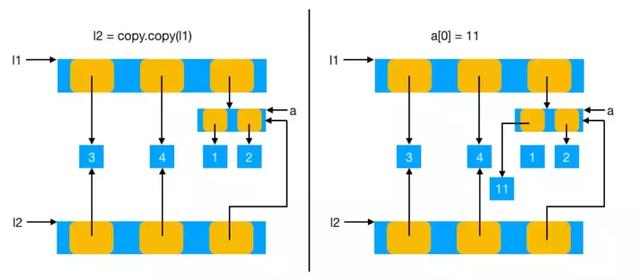
对于上边这种状况,Python还提供了另一种拷贝方式(深拷贝)来解决。
深拷贝
区别于浅拷贝只拷贝顶层引用,深拷贝会逐层进行拷贝,直到拷贝的所有引用都是不可变引用为止。
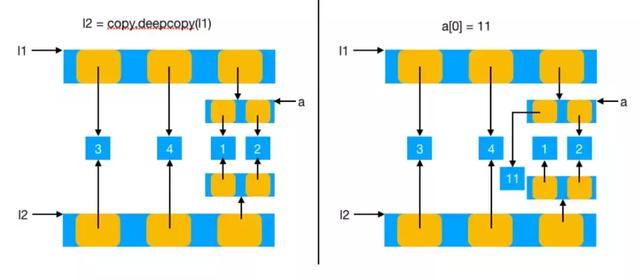
接下来我们看看,要是将上边的拷贝实例用使用深拷贝的话,原始数据改变的问题还会不会存在了?
下面的实例清楚的告诉我们:之前的问题就可以***解决了。
import copy l1 = [3, 4, a] In [47]: l2 = copy.deepcopy(li) In [48]: id(l1) Out[48]: 1916632194312 In [49]: id(l2) Out[49]: 1916634281416 In [50]: a[0] = 11 In [51]: id(l1) Out[51]: 1916632194312 In [52]: id(l2) Out[52]: 1916634281416 In [54]: l1 Out[54]: [3, 4, [11, 2]] In [55]: l2 Out[55]: [1, 2, 3]
原理图如下:
查漏补缺
为什么Python默认的拷贝方式是浅拷贝?
时间角度:浅拷贝花费时间更少。
空间角度:浅拷贝花费内存更少。
效率角度:浅拷贝只拷贝顶层数据,一般情况下比深拷贝效率高。
知识点总结:
不可变对象在赋值时会开辟新空间。
可变对象在赋值时,修改一个的值,另一个也会发生改变。
深、浅拷贝对不可变对象拷贝时,不开辟新空间,相当于赋值操作。
浅拷贝在拷贝时,只拷贝***层中的引用,如果元素是可变对象,并且被修改,那么拷贝的对象也会发生变化。
深拷贝在拷贝时,会逐层进行拷贝,直到所有的引用都是不可变对象为止。
Python 中有多种方式实现浅拷贝,copy模块的copy 函数 ,对象的 copy 函数 ,工厂方法,切片等。
大多数情况下,编写程序时,都是使用浅拷贝,除非有特定的需求。
浅拷贝的优点:拷贝速度快,占用空间少,拷贝效率高。
关于如何解析Python深拷贝与浅拷贝问题就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。