жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
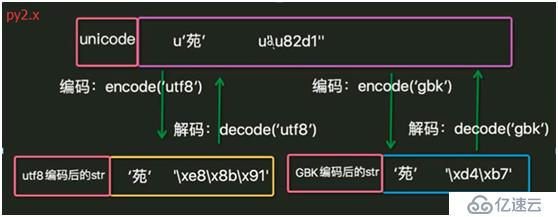
1. еӯ—з¬ҰеңЁеҶ…еӯҳдёӯйғҪжҳҜд»Ҙunicodeзұ»еһӢеӯҳеңЁгҖӮ
2. еҪ“ж•°жҚ®иҰҒдҝқеӯҳеҲ°зЈҒзӣҳжҲ–иҖ…зҪ‘з»ңдј иҫ“ж—¶пјҢдјҡиҪ¬дёәutf-8зӯүзј–з ҒеҶҚдҝқеӯҳжҲ–дј иҫ“гҖӮ
3. еңЁpythonж–Ү件第дёҖиЎҢжҢҮе®ҡзҡ„зј–з Ғж–№ејҸз”ЁдәҺеҗ‘pythonи§ЈйҮҠеҷЁжҢҮеҮәи§Јз Ғж–№ејҸгҖӮ
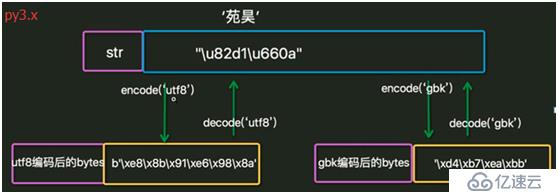
4. Pythonдёӯеӯ—з¬Ұзҡ„еӯҳеӮЁзұ»еһӢжңүbytesе’Ңunicode,еңЁpy2.xдёӯиў«з§°дёәstrе’Ңunicode, еңЁpy3.xдёӯиў«з§°дёәbytesе’Ңstr.
5. Py2.xе’Ңpy3.xдёӯеӯ—з¬Ұзҡ„зұ»еһӢйғҪдёәstr, еӣ жӯӨеңЁpy2.xдёӯжҳҜbytesзұ»еһӢпјҢеңЁpy3.xдёӯжҳҜunicodeзұ»еһӢгҖӮ
6. py2.xдёӯж–Ү件й»ҳи®Өи§Јз Ғж–№ејҸпјҲеҚіpythonж–Ү件第дёҖиЎҢдёҚжҢҮе®ҡж—¶пјүдёәASCII, py3.xдёӯдёәUTF-8. дҪҝз”Ёsys.getdefaultencoding()иҺ·еҫ—гҖӮ
7. зј–з ҒгҖҒи§Јз ҒиҝҮзЁӢгҖӮ
8. IDEеңЁзЁӢеәҸиҝҗиЎҢеүҚе…ҲжҢүж–ҮжЎЈеұһжҖ§и®ҫе®ҡзҡ„зј–з Ғж–№ејҸжҠҠж•°жҚ®дҝқеӯҳеҲ°зЈҒзӣҳпјҢ然еҗҺpythonи§ЈйҮҠеҷЁжҢүж–Ү件第дёҖиЎҢзҡ„и§Јз Ғж–№ејҸжҠҠзЈҒзӣҳдёӯеӯҳеӮЁзҡ„дәҢиҝӣеҲ¶еәҸеҲ—иҜ»еҸ–并解з ҒдёәunicodeеҠ иҪҪеҲ°еҶ…еӯҳдёӯгҖӮ
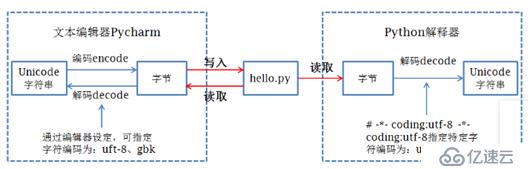
зј–з ҒпјҡжҠҠдәәзұ»еҸ‘жҳҺзҡ„ж–Үеӯ—еҸҠз¬ҰеҸ·иҪ¬еҢ–дёәи®Ўз®—жңәиғҪеӨҹиҜҶеҲ«зҡ„дәҢиҝӣеҲ¶еәҸеҲ—зҡ„иҝҮзЁӢгҖӮ
и§Јз ҒпјҡжҠҠи®Ўз®—жңәеҶ…йғЁеӯҳеӮЁзҡ„дәҢиҝӣеҲ¶еәҸеҲ—иҪ¬еҢ–дёәдәәзұ»иғҪеӨҹи®ӨиҜҶзҡ„ж–Үеӯ—еҸҠз¬ҰеҸ·зҡ„иҝҮзЁӢгҖӮ
ASCII: еҚ дёҖдёӘеӯ—иҠӮпјҢдҝқз•ҷжңҖй«ҳдҪҚпјҢе…¶дҪҷ7дҪҚз»„жҲҗдәҶ128дёӘеӯ—з¬Ұзҡ„еӯ—з¬ҰйӣҶгҖӮ
unicode: unicodeзј–з ҒдәҶдё–з•ҢдёҠжүҖжңүзҡ„ж–Үеӯ—гҖӮ
utf-8: еҜ№unicodeиҝӣиЎҢдәҶеҺӢзј©е’ҢдјҳеҢ–гҖӮASCIIз Ғдёӯзҡ„еҶ…е®№з”Ё1дёӘеӯ—иҠӮдҝқеӯҳгҖҒ欧жҙІзҡ„еӯ—з¬Ұз”Ё2дёӘеӯ—иҠӮдҝқеӯҳпјҢдёңдәҡзҡ„еӯ—з¬Ұз”Ё3дёӘеӯ—иҠӮдҝқеӯҳгҖӮ
GBK: жұүеӯ—зҡ„еӣҪж Үз ҒпјҢз”Ё2дёӘеӯ—иҠӮдҝқеӯҳгҖӮ
1. йӘҢиҜҒPy2.xдёӯзҡ„еӯ—з¬Ұзұ»еһӢгҖӮ
Py2.x: #coding:utf-8 s = 'дёӯеӣҪhello' print s print type(s) print len(s) print repr(s) жү§иЎҢз»“жһңпјҡ дёӯеӣҪhello <type 'str'> 11 '\xe4\xb8\xad\xe5\x9b\xbdhello'
еҸҜи§ҒжҳҜstrзұ»еһӢпјҢеҚіbytesзұ»еһӢгҖӮlen()жҳҜеҚ з”Ёзҡ„еӯ—иҠӮж•°гҖӮ
Py2.x: #coding:utf-8 s = u'дёӯеӣҪhello' print s print type(s) print len(s) print repr(s) жү§иЎҢз»“жһңпјҡ дёӯеӣҪhello <type 'unicode'> 7 u'\u4e2d\u56fdhello'
жҢҮе®ҡдәҶдҪҝз”Ёunicodeзұ»еһӢгҖӮ u4e2dжҳҜunicodeеӯ—з¬ҰйӣҶдёӯеӯ—з¬ҰвҖңдёӯвҖқзҡ„д»Јз ҒгҖӮlen()жҳҜеӯ—з¬Ұзҡ„дёӘж•°гҖӮ
2. bytesе’Ңunicodeзҡ„иҪ¬жҚўгҖӮ
#coding:utf-8
s = 'дёӯеӣҪ'
print type(s)
print len(s)
s2 = s.decode('utf-8')
type(s2)
print len(s2)
жү§иЎҢз»“жһңпјҡ
<type 'str'>
6
<type 'unicode'>
23. дёҚеҗҢзј–з Ғзұ»еһӢзҡ„еӯ—з¬ҰдёІжӢјжҺҘгҖӮ
Py2.x: #coding:utf-8 print 'cisco'+u'google' жү§иЎҢз»“жһңпјҡ ciscogoogle д№ӢжүҖд»ҘиӢұж–Үеӯ—з¬ҰеҸҜд»ҘжҠҠдёӨз§Қзұ»еһӢзҡ„иҝӣиЎҢжӢјжҺҘпјҢжҳҜеӣ дёәеңЁpython2.xдёӯпјҢеҸӘиҰҒж•°жҚ®е…ЁйғЁжҳҜ ASCII зҡ„иҜқпјҢpythonи§ЈйҮҠеҷЁиҮӘеҠЁжҠҠ byte иҪ¬жҚўдёә unicode гҖӮдҪҶжҳҜдёҖж—ҰдёҖдёӘйқһ ASCII еӯ—з¬ҰеҒ·еҒ·иҝӣе…ҘдҪ зҡ„зЁӢеәҸпјҢйӮЈд№Ҳй»ҳи®Өзҡ„и§Јз Ғе°ҶдјҡеӨұж•ҲпјҢд»ҺиҖҢйҖ жҲҗ UnicodeDecodeError зҡ„й”ҷиҜҜгҖӮpython2.xзј–з Ғи®©зЁӢеәҸеңЁеӨ„зҗҶ ASCII зҡ„ж—¶еҖҷжӣҙеҠ з®ҖеҚ•гҖӮдҪ д»ҳеҮәзҡ„д»Јд»·е°ұжҳҜеңЁеӨ„зҗҶйқһ ASCII зҡ„ж—¶еҖҷе°ҶдјҡеӨұиҙҘгҖӮ Py2.x: #coding:utf-8 s = 'hello'+'china' print s print type(s) print repr(s) жү§иЎҢз»“жһңпјҡ hellochina <type 'str'> 'hellochina' жҹҘзңӢдёҚеҗҢзј–з Ғзұ»еһӢжӢјжҺҘеҗҺзҡ„еӯҳеӮЁзұ»еһӢпјҡ Py2.x: #coding:utf-8 s = 'hello'+u'china' print s print type(s) print repr(s) жү§иЎҢз»“жһңпјҡ hellochina <type 'unicode'> u'hellochina' еҸҜи§ҒPy2.xиҝӣиЎҢдәҶиҮӘеҠЁиҪ¬жҚўгҖӮ Py2.x: #coding:utf-8 print 'дёӯеӣҪ'+'зҫҺеӣҪ' жү§иЎҢз»“жһңпјҡ дёӯеӣҪзҫҺеӣҪ Py2.x: #coding:utf-8 print 'дёӯеӣҪ'+u'зҫҺеӣҪ' жү§иЎҢз»“жһңпјҡ Traceback (most recent call last): File "E:\python\study\test\index.py", line 14, in <module> print 'дёӯеӣҪ'+u'зҫҺеӣҪ' UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
Py3.xдёӯеҚідҪҝйғҪжҳҜASCIIиҢғеӣҙеҶ…пјҢд№ҹдёҚиғҪиҝӣиЎҢжӢјжҺҘпјҡ
#coding:utf-8 s1 = 'cisco' print(type(s1)) s2 = b'google' print(type(s2)) print(s1+s2) жү§иЎҢз»“жһңпјҡ <class 'str'> <class 'bytes'> Traceback (most recent call last): File "E:\python\study\test\index.py", line 6, in <module> print(s1+s2) TypeError: can only concatenate str (not "bytes") to str
1. йӘҢиҜҒPy3.xдёӯзҡ„еӯ—з¬Ұзұ»еһӢгҖӮ
#coding:utf-8
import json
s1 = 'дёӯеӣҪ'
print(type(s1))
print(len(s1))
print(json.dumps(s1))
print(s1)
s2 = s1.encode('utf-8')
print(type(s2))
print(len(s2))
print(s2)
жү§иЎҢз»“жһңпјҡ
<class 'str'>
2
"\u4e2d\u56fd"
дёӯеӣҪ
<class 'bytes'>
6
b'\xe4\xb8\xad\xe5\x9b\xbd'#coding:utf-8 s = u'дёӯ' print(s) print(type(s)) print(len(s)) print(repr(s)) print(ord(s)) print(bin(ord(s))) дёӯ <class 'str'> 1 'дёӯ' 20013 0b100111000101101
2. bytesе’Ңunicodeзҡ„иҪ¬жҚўгҖӮйҷӨдәҶencodeе’Ңdecodeзҡ„иҪ¬жҚўж–№жі•пјҢиҝҳеҸҜд»Ҙпјҡ
#coding:utf-8 s1 = 'дёӯеӣҪ' print(type(s1)) s2 = bytes(s1,encoding='utf-8') print(type(s2)) s3 = str(s2,encoding='utf-8') print(type(s3)) жү§иЎҢз»“жһңпјҡ <class 'str'> <class 'bytes'> <class 'str'>
1. py2.xдёӯй»ҳи®Өзҡ„и§Јз Ғж–№ејҸжҳҜASCII, py3.xдёӯй»ҳи®Өзҡ„жҳҜutf-8, еҪ“еңЁpy2.xдёӯжҢҮе®ҡи§Јз Ғж–№ејҸдёәutf-8ж—¶пјҢpy2.xе’Ңpy3.xеә”иҜҘжҳҜжІЎжңүеҢәеҲ«пјҢеҸҜдёәдҪ•еңЁpy2.xдёӯй»ҳи®Өзҡ„еӯ—з¬Ұзұ»еһӢжҳҜbytes, иҖҢеңЁpy3.xдёӯзЎ®жҳҜunicode, йғҪжҳҜutf-8пјҢдёҚеә”иҜҘйғҪжҳҜbytesеҗ—пјҹжҲ–иҖ…既然йғҪеҠ иҪҪеңЁеҶ…еӯҳдәҶпјҢдёҚиҜҘйғҪжҳҜunicodeеҗ—пјҹ
зӯ”пјҡpythonи§ЈйҮҠеҷЁд»ҺзЈҒзӣҳиҜ»еҸ–ж–Ү件пјҢд»Ҙunicodeзј–з Ғж–№ејҸжҠҠж•ҙдёӘд»Јз ҒеҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢ然еҗҺйҖҗжқЎжү§иЎҢпјҢеҪ“иҜҶеҲ«еҲ°еӯ—з¬ҰдёІж—¶пјҢpy2.xй»ҳи®Өзҡ„strзұ»еһӢжҳҜbytes, иҖҢpy3.xй»ҳи®Өзҡ„strзұ»еһӢжҳҜunicode, дҪҶеҪ“жңүжҳҺзЎ®жҢҮе®ҡеӯ—з¬Ұзұ»еһӢж—¶пјҢжҢүжҢҮе®ҡзҡ„зј–з ҒпјҢеҰӮpy2.xдёӯзҡ„u'china', py3.xдёӯзҡ„b'google'.
2. Py2.xдёӯдёҚжҢҮе®ҡutf-8зј–з Ғж–№ејҸж—¶пјҢprintжұүеӯ—дјҡжҠҘй”ҷпјҡ
Py2.x: s = 'дёӯеӣҪ' print s з»“жһңпјҡ File "E:\python\study\test\index.py", line 3 SyntaxError: Non-ASCII character '\xe4' in file E:\python\study\test\index.py on line 3, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
иҝҷжҳҜеӣ дёәpy2.xдёӯй»ҳи®Өзҡ„и§Јз Ғж–№ејҸдёәASCII, иҖҢж–Ү件дҝқеӯҳзҡ„зј–з Ғж–№ејҸдёәUTF-8, дёӨиҖ…дёҚеҢ№й…ҚпјҢеӣ жӯӨжҠҘй”ҷгҖӮ
3. Py2.xдёӯеӯ—з¬ҰдёІsжң¬жқҘеә”иҜҘжҳҜеӯ—иҠӮзұ»еһӢпјҢдҪҶдёәдҪ•printж—¶еҚҙжҳҫзӨәдёәжҳҺж–ҮдәҶе‘ўпјҹ
Py2.xдёӯпјҡ >>> s = 'дёӯеӣҪ' >>> s '\xd6\xd0\xb9\xfa' >>> print s дёӯеӣҪ >>>print '\xd6\xd0\xb9\xfa' дёӯеӣҪ
иҝҷжҳҜеӣ дёәprintеңЁжү§иЎҢж—¶и°ғз”ЁдәҶstrеҮҪж•°пјҢstrеҮҪж•°жү§иЎҢдәҶbytesеҲ°unicodeзҡ„ж“ҚдҪңгҖӮдҪҶpy3.xдёӯдёҚеӯҳеңЁиҝҷз§ҚзҺ°иұЎпјҡ
#coding:utf-8
import json
s1 = 'дёӯеӣҪ'
print(type(s1))
print(len(s1))
print(json.dumps(s1))
print(s1)
s2 = s1.encode('utf-8')
print(type(s2))
print(len(s2))
print(s2)
жү§иЎҢз»“жһңпјҡ
<class 'str'>
2
"\u4e2d\u56fd"
дёӯеӣҪ
<class 'bytes'>
6
b'\xe4\xb8\xad\xe5\x9b\xbd'жҺ§еҲ¶еҸ°дёӯпјҡ >>> s = 'дёӯеӣҪ' >>> print(type(s)) <class 'str'> >>> s 'дёӯеӣҪ' >>> print(s) дёӯеӣҪ >>> s1 = bytes(s,encoding='gbk') >>> s1 b'\xd6\xd0\xb9\xfa' >>> print(s1) b'\xd6\xd0\xb9\xfa' >>>
4. д»Ҙutf-8дҝқеӯҳж–Ү件пјҢеңЁwindowsдёӯжү§иЎҢпјҢиҫ“еҮәдёҚеҗҢпјҡ
#coding:utf-8 s = 'дёӯеӣҪ' print(s) D:\Python37-32>python d:\index.py дёӯеӣҪ D:\Python27>python d:\index.py 涓о…һжө—
еӣ дёәpy3.xдёӯеӯ—з¬ҰдёІиў«иҜҶеҲ«дёәunicode, дј з»ҷcmd.exeж—¶иў«зј–з ҒдёәGBKпјҢеҶҚд»ҘGBKи§Јз Ғиҫ“еҮәгҖӮдҪҶpy2.xдёӯеӯ—з¬ҰдёІиў«иҜҶеҲ«дёәbytes, utf-8зј–з Ғзҡ„дёӨдёӘжұүеӯ—жңү6дёӘеӯ—иҠӮпјҢдј з»ҷcmd.exeж—¶жҢүGBKи§Јз ҒпјҢиҜҶеҲ«жҲҗдёәдәҶ3дёӘд№ұз ҒпјҢеҶҚд»ҘGBKи§Јз Ғиҫ“еҮәгҖӮ
5. Py3.xдҪҝз”Ёopenзҡ„rж–№жі•жү“ејҖutf-8зј–з Ғзҡ„ж–Ү件时дјҡжҠҘй”ҷпјҡ
#coding:utf-8
f = open('index.py','r')
print(f.read())
жү§иЎҢз»“жһңпјҡ
Traceback (most recent call last):
File "E:\python\study\test\test.py", line 5, in <module>
print(f.read())
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence
дҪҝз”Ёrbж—¶иҫ“еҮәпјҡ
b'\xe4\xb8\xad\xe5\x9b\xbd'py2.xдёӯдёҚдјҡжҠҘй”ҷгҖӮopen()ж–№жі•жү“ејҖж–Ү件时пјҢread()иҜ»еҸ–зҡ„жҳҜstr(py2.xдёӯеҚіжҳҜbytes)пјҢиҜ»еҸ–еҗҺйңҖиҰҒдҪҝз”ЁжӯЈзЎ®зҡ„зј–з Ғж јејҸиҝӣиЎҢdecode().
Py2.x:
f = open('index.py','r')
s = f.read()
print type(s)
print len(s)
print s
жү§иЎҢз»“жһңпјҡ
<type 'str'>
6
дёӯеӣҪ
еҸҜи§ҒпјҢжӯӨеӨ„дҪҝз”Ёutf-8иҝӣиЎҢи§Јз Ғ,еҰӮжһңжҢҮе®ҡдёәGBKе‘ў?
#coding:gbk
f = open('index.py','r')
s = f.read()
print s
иҫ“еҮәжҳҜ涓о…һжө—пјҢж”№дёәASCIIеҗҺеҗҢж ·жҠҘй”ҷгҖӮеҸҜжҹҘзңӢpy3.xдҪҝз”Ёзҡ„жҳҜGBKиҝӣиЎҢи§Јз Ғпјҡ
Py3.x:
>>> f = open('index.py','r')
>>> f
<_io.TextIOWrapper name='index.py' mode='r' encoding='cp936'>
дҪҶpy2.xжІЎжңүжҳҫзӨәзј–з Ғж–№ејҸпјҡ
>>> f = open(r'e:\python\study\test\index.py','r')
>>> s = f.read()
>>> f
<open file 'e:\\python\\study\\test\\index.py', mode 'r' at 0x016BD1D8>еҸҜдҪҝз”Ёopen('index.py','r',encoding='utf-8')жҢҮе®ҡзј–з Ғж–№ејҸгҖӮ
https://www.cnblogs.com/OldJack/p/6658779.html
http://www.cnblogs.com/yuanchenqi/articles/5938733.html
https://www.cnblogs.com/shine-lee/p/4504559.html
https://blog.csdn.net/nyyjs/article/details/56667626
https://blog.csdn.net/nyyjs/article/details/56670080
https://www.jianshu.com/p/19c74e76ee0a
https://www.jb51.net/article/59599.htm
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ