您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何用Python做一份旅游攻略,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
旅游是调节心情的有效途径,越来越多的上班族和学生期待利用假期时间外出游 玩来开拓眼界、舒缓压力。然而真正有了假期,许多人却会因“去哪玩”的问题倍感困惑,六月份正是出行的好时节,就让我们一起来学习如何利用python来安排自己的出行计划吧。
一.数据的获取
最近几年,既省钱又休闲的自助游逐渐成为年轻人出行的最爱,这里推荐一个我个人比较喜欢的旅游网站蚂蜂窝,这次通过分析“驴友”们的出行计划来规划我们自己的行程,第一步当然是爬取网站数据啦
1.分析目标网页
为了获取大家的出行信息,我们进入网站的“结伴”板块,查看“一个月以内”的出行计划,可以看到随着页面的更改url并没有发生变化,初步判断该网页是通过js加载的,要想爬取首先得找到真实url和返回的数据格式。
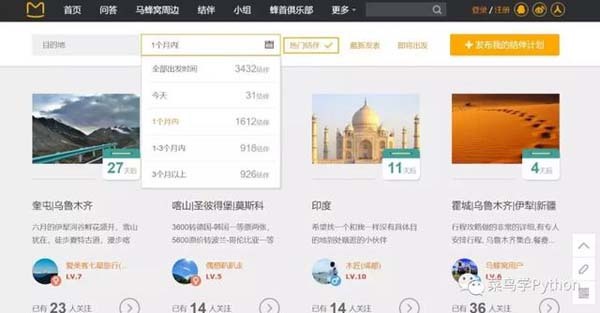
经过一番尝试,我们成功找到了请求返回的真实url和关键参数,这里返回的是json格式的数据,里面包含了一个html文本。
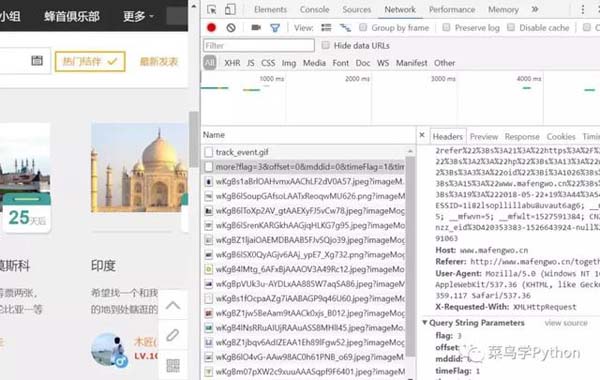
2.确定抓取内容
在正式开始爬取数据之前,我们要先确定需要爬取哪些数据。行程的列表页清晰地展现了目的地、行程简介、发起人ID和性别(呵呵),虽然这些信息非常有参考价值,但是如果能获取更多信息无疑会对我们的行程规划更有帮助,所以还是要进入详情页来看一看。
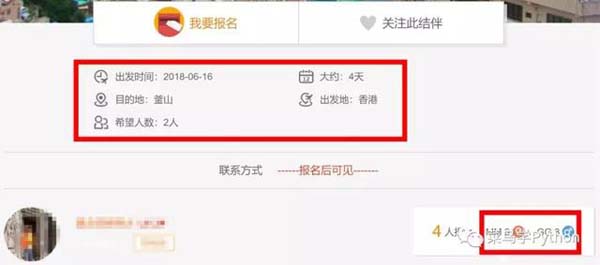
可以看到,详情页中对出发时间、行程历时、出发地点等都有详细说明,此外还有报名结伴人员情况,这项数据能在很大程度上反映小伙伴们的出行意向,所以一定要拿下来。
3.正式爬取数据
总体思路是爬取索引页中每一个行程的发起人和详情页url,之后进入详情页抓取出发时间、历史、目的地、出发城市、希望人数以及报名人员情况等数据,每个行程的索引页数据和详情页数据合 并后作为该行程的完整数据进行存储。以下是爬虫程序的总入口:
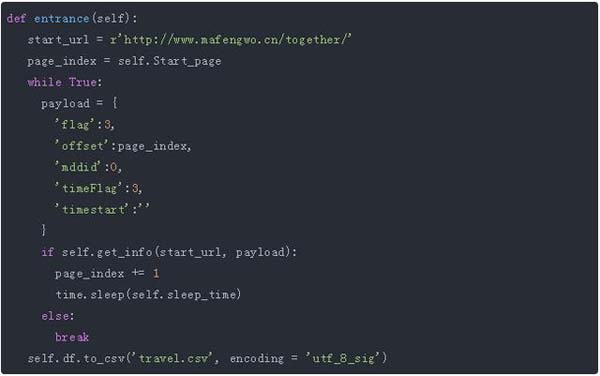
payload参数:flag决定了行程的排序方式,可选值为1、2、3,分别代表“即将出发”、“***发布”、“热门结 伴”;
offset表示当前页数,默认从0开始;middid表示行程目的地,不确定目的地值为0;timeFlage代表出 发时间,值为3表示选取一个月内的行程。
get_info()方法:抓取每一页的行程信息并翻页,如果无法获取有效信息则说明爬取结束。
数据存储:由于数据量不大,可以先全部存储到一个dataframe数据结构中,再一次性写入csv文件。
二. 数据清洗
我们来看看获取到的数据是什么样子的,可以看到,每条数据中都有很多干扰信息:
“出发时间”一栏我们想要 的仅仅是日期数据;
“报名人数”一栏我们想要的仅仅是数字,而不需要多余的修饰文字等等;
“部分出行” 计划涵盖了多个目的地,这对我们的旅游目的地分析是非常不利的

所以,我们必须先对获取到的数据进行清洗, 以期为正式的数据分析奠定基础。
1.规范格式
首先对历时、希望人数、报名人数(女)、报名人数(男)这几项数据进行清洗,仅保留数字部分;其次对出发是 按、出发地点相关数据进行情况,取到“:”及前面的内容。感谢pandas.Series.str方法,使我们可以非常简单地完 成上述工作,功能函数如下:

only_num(self, col_list):去除数据中的非数字部分。
no_colon(self, col_list):去除数据中的“:”及其前面的内容。
2.拆分目的地
刚才说到过,一个行程中包含多个目的地会对我们的分析造成干扰,这里的解决思路是对目的地数据进行拆分。
将一列数据拆分成X列(X为该行程包含的目的地个数),同样是使用pandas.Series.str方法,代码如下:

三.数据分析
现在我们可以对数据进行分析查找六月份的旅行规律了,为了便于观察,这里使用pyecharts进行可视化处理。
1.男女比例
首先对参与出行计划的人员性别进行分析,利用dataframe的sum()和groupby().count()方法可以很容易获得行程 发布者和参与者的性别分布:
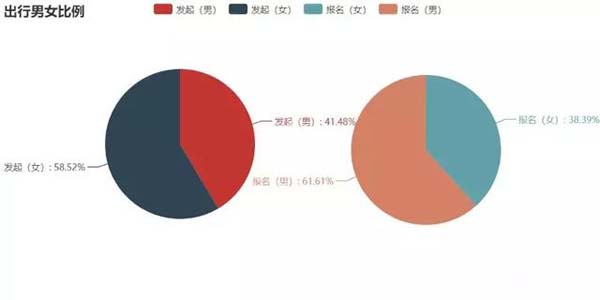
从图中可以看出,发起人以女性居多,约占总数的60%,而参与者刚好相反,男性比 例约为60%,估计是女同胞们更擅长精心策划行程,而男同胞们大多比较“懒”吧~
2.出发时间
这里我们首先用dataframen的groupby()方法,以“出行时间”为关键字对数据进行分组,分别统计每天的行程数量 和参与者数量,然后画出折线图。
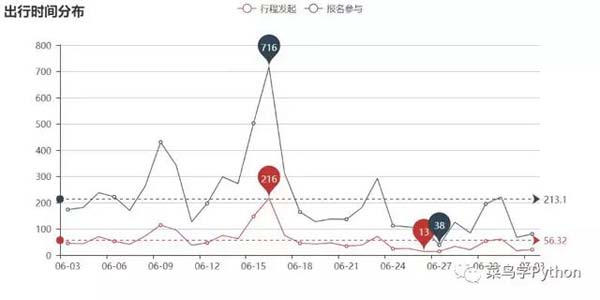
从结果来看,6月15、16两天是六月份出行的高峰期(这个时间刚好开始端午节假期),端午节有出行计划的朋友 们记得提前准备哈。除此之外的几个波峰也都出现在周末,看来喜欢自助游的朋友中还是上班族(也可能是大学 生)居多啊。
3.目的地选择
先来分析行程发布数据,首先将数据中所有的目的地加入到一个list中(包含重复数据),然后使用collections中的Counter()方法统计每个目的地出现的频次,***制图。

图中列出了频次较高的几个目的地,彩条越长表示出现的频次越多。稍微留意下我们会发现,大家比较青睐的都是一些商业化程度比较低的地区,比如拉萨,新疆!
其实作为一名自由行爱好者,我同样比较喜欢更加原始和纯粹的风光,对于沉淀心情确实会起到更好的效果,大家如果有出行计划又不知道去哪玩的话,不妨从上面的目的地中选一下。

4.参与者情况如何
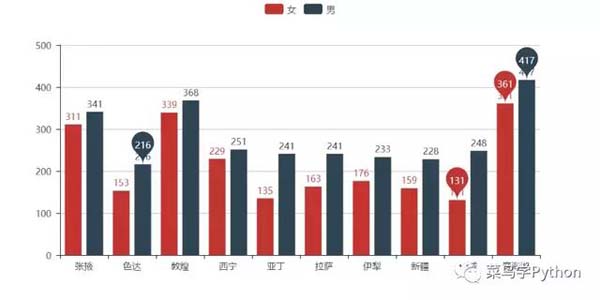
首先分别统计出各个目的地报名的男性数量和女性数量储存到两个dict中,分别取参与 人数最多的10个目的地,***将两组数据合并、去重......
然后我们会惊奇地发现,虽然两个序列中具体排名不尽相 同,但是男性和女性最想去的10个目的地居然完全一致。
不过各个地点的男女人数还是有较大差异的,如果想来一场***的邂逅,或许下面这张图会有点帮助哈。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。