жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңPythonжҖҺд№ҲзҲ¬еҸ–дёҖдәӣз®ҖеҚ•зҡ„и®әеқӣгҖҒеё–еӯҗгҖҒзҪ‘йЎөвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңPythonжҖҺд№ҲзҲ¬еҸ–дёҖдәӣз®ҖеҚ•зҡ„и®әеқӣгҖҒеё–еӯҗгҖҒзҪ‘йЎөвҖқеҗ§пјҒ
з”ЁжңҖзҹӯзҡ„ж—¶й—ҙеҶҷдёҖдёӘжңҖз®ҖеҚ•зҡ„зҲ¬иҷ«пјҢеҸҜд»ҘжҠ“дёҖдәӣз®ҖеҚ•зҡ„и®әеқӣгҖҒеё–еӯҗгҖҒзҪ‘йЎөгҖӮ
1.еҮҶеӨҮе·ҘдҪң
е®үиЈ…Python
е®үиЈ…scrapyжЎҶжһ¶
дёҖдёӘIDEжҲ–иҖ…еҸҜд»Ҙз”ЁиҮӘеёҰзҡ„
2.ејҖе§ӢеҶҷзҲ¬иҷ«

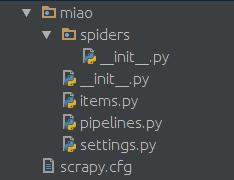
еңЁspidersж–Ү件еӨ№дёӯеҲӣе»әдёҖдёӘpythonж–Ү件пјҢжҜ”еҰӮmiao.pyпјҢжқҘдҪңдёәзҲ¬иҷ«зҡ„и„ҡжң¬гҖӮ
д»Јз ҒеҰӮдёӢпјҡ
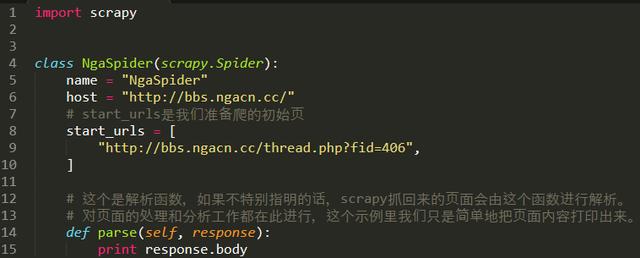
3.иҝҗиЎҢдёҖдёӢ
еҰӮжһңз”Ёе‘Ҫд»ӨиЎҢзҡ„иҜқе°ұиҝҷж ·пјҡ


1.иҜ•иҜ•зҘһеҘҮзҡ„xpath

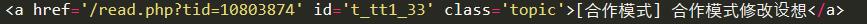

2.зңӢзңӢxpathзҡ„ж•Ҳжһң
еңЁжңҖдёҠйқўеҠ дёҠеј•з”Ёпјҡ
from scrapy import Selector
жҠҠparseеҮҪж•°ж”№жҲҗпјҡ
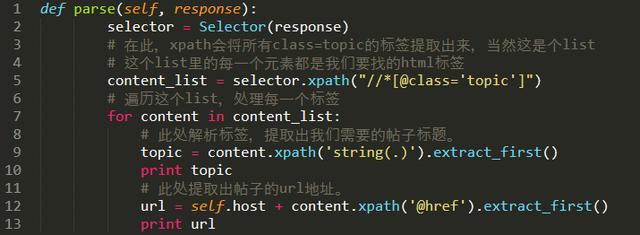
жҲ‘们еҶҚж¬ЎиҝҗиЎҢдёҖдёӢпјҢдҪ е°ұеҸҜд»ҘзңӢеҲ°иҫ“еҮәвҖңеқӣжҳҹйҷ…еҢәвҖқ***йЎөжүҖжңүеё–еӯҗзҡ„ж Үйўҳе’ҢurlдәҶгҖӮ

е®Ңж•ҙзҡ„д»Јз ҒеҰӮдёӢпјҡ
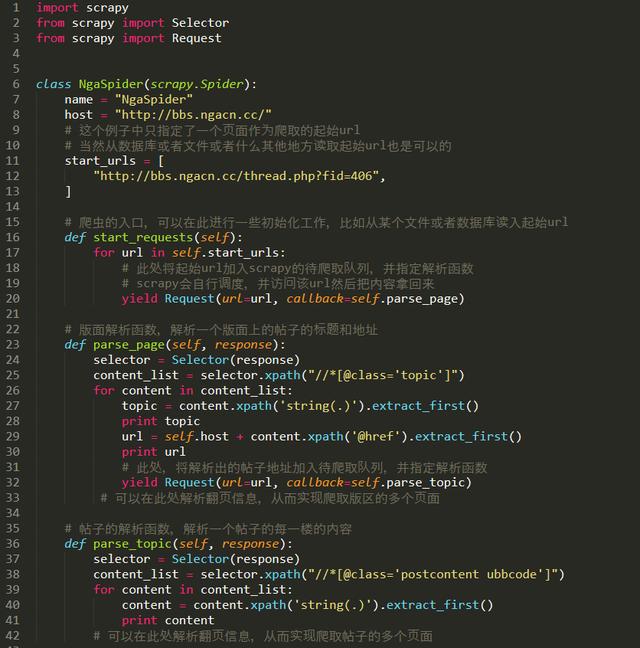

зҺ°еңЁжҳҜеҜ№е·ІжҠ“еҸ–гҖҒи§ЈжһҗеҗҺзҡ„еҶ…е®№зҡ„еӨ„зҗҶпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮз®ЎйҒ“еҶҷе…Ҙжң¬ең°ж–Ү件гҖҒж•°жҚ®еә“гҖӮ
1.е®ҡд№үдёҖдёӘItem
еңЁmiaoж–Ү件еӨ№дёӯеҲӣе»әдёҖдёӘitems.pyж–Ү件
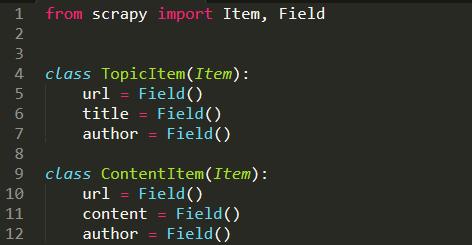
иҝҷйҮҢжҲ‘们е®ҡд№үдәҶдёӨдёӘз®ҖеҚ•зҡ„classз”ЁжқҘжҸҸиҝ°жҲ‘们зҲ¬еҸ–зҡ„з»“жһңгҖӮ
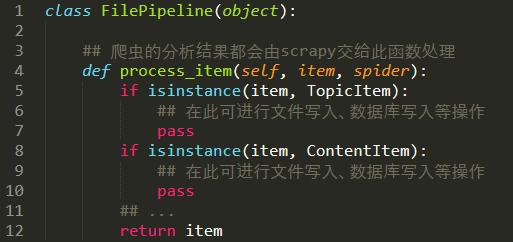
2. еӨ„зҗҶж–№жі•

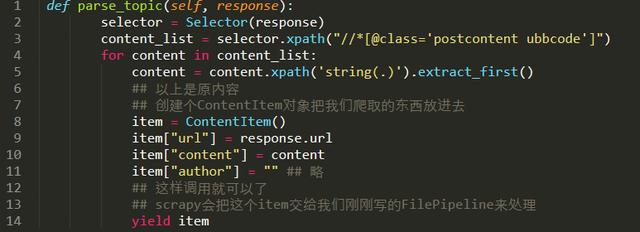
3.еңЁзҲ¬иҷ«дёӯи°ғз”ЁиҝҷдёӘеӨ„зҗҶж–№жі•гҖӮ

4.еңЁй…ҚзҪ®ж–Ү件йҮҢжҢҮе®ҡиҝҷдёӘpipeline
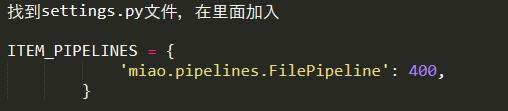

еҸҜд»Ҙиҝҷж ·й…ҚзҪ®еӨҡдёӘpipeline:
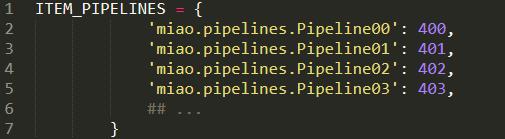

1.Middlewareзҡ„й…ҚзҪ®


2.з ҙзҪ‘з«ҷжҹҘUA, жҲ‘иҰҒжҚўUA

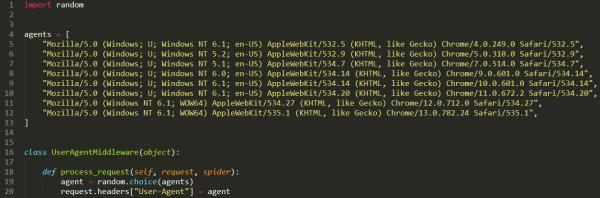
иҝҷйҮҢе°ұжҳҜдёҖдёӘз®ҖеҚ•зҡ„йҡҸжңәжӣҙжҚўUAзҡ„дёӯй—ҙ件пјҢagentsзҡ„еҶ…е®№еҸҜд»ҘиҮӘиЎҢжү©е……гҖӮ
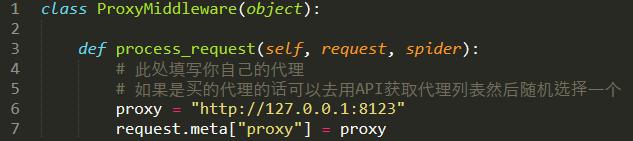
3.з ҙзҪ‘з«ҷе°ҒIPпјҢжҲ‘иҰҒз”Ёд»ЈзҗҶ


ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңPythonжҖҺд№ҲзҲ¬еҸ–дёҖдәӣз®ҖеҚ•зҡ„и®әеқӣгҖҒеё–еӯҗгҖҒзҪ‘йЎөвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№PythonжҖҺд№ҲзҲ¬еҸ–дёҖдәӣз®ҖеҚ•зҡ„и®әеқӣгҖҒеё–еӯҗгҖҒзҪ‘йЎөиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ