жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңKubernetesдёӯй”ҒжңәеҲ¶зҡ„и®ҫи®ЎдёҺе®һзҺ°ж–№жі•жҳҜд»Җд№ҲвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңKubernetesдёӯй”ҒжңәеҲ¶зҡ„и®ҫи®ЎдёҺе®һзҺ°ж–№жі•жҳҜд»Җд№ҲвҖқеҗ§пјҒ
йқўеҗ‘з»ҲжҖҒзҡ„й”ҒеҹәзЎҖзҜҮ
еңЁеҲҶеёғејҸзі»з»ҹдёӯйҖҡеёёз”ұеҗ„з§Қеҗ„ж ·зҡ„й”ҒпјҢжҲ‘们е…ҲжқҘзңӢдёӢпјҢдё»жөҒзҡ„й”ҒйҮҢйқўжңүе“Әдәӣе…ұжҖ§пјҢд»ҘеҸҠжҳҜеҰӮдҪ•иҝӣиЎҢи®ҫи®Ўзҡ„гҖӮ
еҲҶеёғејҸзі»з»ҹдёӯзҡ„й”Ғ
еңЁеҲҶеёғејҸзі»з»ҹдёӯй”ҒжңүеҫҲеӨҡз§Қе®һзҺ°ж–№ејҸпјҡ еҹәдәҺCPжЁЎеһӢзҡ„гҖҒеҹәдәҺAPжЁЎеһӢзҡ„ пјҢдҪҶжҳҜиҝҷдәӣй”ҒжңәеҲ¶йғҪжңүдёҖдәӣйҖҡз”Ёзҡ„и®ҫи®ЎеҺҹеҲҷпјҢжҺҘдёӢжқҘжҲ‘们е…ҲзңӢдёӢиҝҷйғЁеҲҶгҖӮ
1. й”ҒеҮӯиҜҒ
й”ҒеҮӯиҜҒдё»иҰҒжқҘиҜҒжҳҺи°ҒжҢҒжңүй”ҒпјҢдёҚеҗҢзі»з»ҹйҮҢйқўзҡ„е®һзҺ°еҗ„дёҚзӣёеҗҢпјҢжҜ”еҰӮеңЁzookeeperдёӯжҳҜдёҙж—¶йЎәеәҸиҠӮзӮ№пјҢиҖҢеңЁredissionдёӯеҲҷжҳҜйҖҡиҝҮuuid+threadIDз»„жҲҗпјҢиҖҢK8sдёӯеҲҷжҳҜLeaderElectionRecord, йҖҡиҝҮиҜҘеҮӯиҜҒжқҘиҜҶеҲ«еҪ“еүҚжҳҜе“ӘдёӘе®ўжҲ·з«ҜеҠ зҡ„й”ҒгҖӮ
2. й”Ғи¶…ж—¶
еҪ“жңүleaderиҠӮзӮ№жҢҒжңүй”Ғд№ӢеҗҺпјҢе…¶дҪҷзҡ„иҠӮзӮ№е°ұйңҖиҰҒе°қиҜ•з«һдәүй”ҒпјҢеңЁCPзі»з»ҹдёӯйҖҡеёёдјҡз”ұжңҚеҠЎз«ҜиҝӣиЎҢз»ҙжҠӨпјҢеҚіеҰӮжһңеҸ‘зҺ°еҜ№еә”зҡ„иҠӮзӮ№жІЎжңүеҝғи·іпјҢеҲҷдјҡиҝӣиЎҢиҠӮзӮ№зҡ„иёўеҮәпјҢ并且йҖҡиҝҮwatchиҝҷз§ҚжңәеҲ¶иҝӣиЎҢеӣһи°ғпјҢиҖҢеңЁAPзі»з»ҹдёӯеҲҷйңҖиҰҒе®ўжҲ·з«ҜиҮӘе·ұз»ҙжҠӨпјҢжҜ”еҰӮredissionйҮҢйқўзҡ„ж—¶й—ҙжҲігҖӮ
3. ж—¶й’ҹ
еңЁеҲҶеёғејҸзі»з»ҹдёӯйҖҡеёёжҲ‘д»¬ж— жі•дҝқиҜҒеҗ„дёӘиҠӮзӮ№зҡ„зү©зҗҶж—¶й’ҹе®Ңе…ЁдёҖиҮҙпјҢйҖҡеёёе°ұдјҡжңүдёҖдёӘйҖ»иҫ‘ж—¶й’ҹзҡ„жҰӮеҝөпјҢеңЁеҫҲеӨҡзі»з»ҹдёӯжҜ”еҰӮraftе’Ңzabдёӯе…¶е®һе°ұжҳҜдёҖдёӘйҖ’еўһзҡ„е…ЁеұҖи®Ўж•°еҷЁпјҢдҪҶжҳҜеңЁredissionдёӯеҲҷжҳҜйҖҡиҝҮзү©зҗҶж—¶й’ҹпјҢеҚійңҖиҰҒдҝқиҜҒеӨ§е®¶зҡ„зү©зҗҶж—¶й’ҹе°ҪеҸҜиғҪеҗҢжӯҘпјҢдёҚиғҪи¶…иҝҮй”Ғи¶…ж—¶зҡ„ж—¶й—ҙгҖӮ
зҪ‘з»ңеҲҶеҢәй—®йўҳ
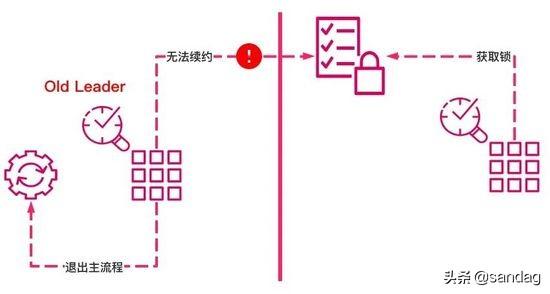
ж— и®әжҳҜCPиҝҳжҳҜAPпјҢеңЁеҲҶеёғејҸзі»з»ҹдёӯйҖҡеёёжҲ‘们йғҪиҰҒдҝқиҜҒPеҚіеҲҶеҢәеҸҜз”ЁжҖ§пјҢйӮЈеҰӮжһңжҢҒжңүй”Ғзҡ„LeaderиҠӮзӮ№еҸ‘з”ҹзҪ‘з»ңеҲҶеҢәзҡ„жғ…еҶөпјҢеҲҷйңҖиҰҒдёҖз§ҚдҝқжҠӨжңәеҲ¶пјҢеҚіLeaderиҠӮзӮ№йңҖиҰҒдё»еҠЁйҖҖеҮәгҖӮ
еңЁzookeeperдёӯеӣ дёәleaderиҠӮзӮ№йңҖиҰҒйҖҡиҝҮsessionжқҘиҝӣиЎҢеҝғи·ізҡ„з»ҙжҠӨпјҢеҰӮжһңиҜҙеҜ№еә”зҡ„leaderиҠӮзӮ№еҸ‘з”ҹеҲҶеҢәпјҢеҲҷsessionе°ұж— жі•иҝӣиЎҢеҝғи·ізҡ„еҸ‘з”ҹпјҢе°ұдјҡйҖҖеҮәпјҢе°ұйңҖиҰҒйҖҡзҹҘжҲ‘们зҡ„дё»жөҒзЁӢжқҘиҝӣиЎҢйҖҖеҮәжё…зҗҶе·ҘдҪңгҖӮ
иө„жәҗй”Ғзҡ„е®һзҺ°жңәеҲ¶
иө„жәҗй”Ғе…¶е®һе°ұжҳҜеҸҜд»ҘйҖҡиҝҮж“ҚдҪңдёҖдёӘиө„жәҗ(йЎәеәҸдёҖиҮҙжҖ§)пјҢеҖҹеҠ©еүҚйқўиҜҙзҡ„й”Ғзҡ„жҖқжғіжқҘе®һзҺ°еҲҶеёғејҸй”ҒпјҢе…¶йҰ–е…Ҳж ёеҝғжөҒзЁӢеҰӮдёӢпјҡ
йҖҡиҝҮиө„жәҗеҜ№иұЎжқҘеӯҳеӮЁй”ҒеҮӯиҜҒдҝЎжҒҜ
еҚіе°Ҷж ҮиҜҶеҪ“еүҚLeaderиҠӮзӮ№зҡ„дҝЎжҒҜж”ҫе…ҘеҲ°еҜ№еә”зҡ„еҮӯиҜҒйҮҢйқўпјҢ并е°қиҜ•иҝӣиЎҢй”Ғз«һдәүпјҢиҝӣиЎҢй”Ғзҡ„иҺ·еҸ–зҡ„е°қиҜ•гҖӮ
й”Ғи¶…ж—¶
K8sзҡ„й”Ғи¶…ж—¶зҡ„жңәеҲ¶жҜ”иҫғжңүи¶ЈпјҢеҚід»–并дёҚе…іеҝғдҪ зҡ„йҖ»иҫ‘ж—¶й’ҹпјҢиҖҢжҳҜд»Ҙжң¬ең°ж—¶й’ҹдёәеҮҶпјҢеҚіжҜҸдёӘиҠӮзӮ№дјҡеӯҳеӮЁи§ӮжөӢеҲ°leaderиҠӮзӮ№еҸҳжӣҙзҡ„ж—¶й—ҙпјҢ然еҗҺж №жҚ®жң¬ең°зҡ„й”Ғи¶…ж—¶ж—¶й—ҙжқҘжЈҖжөӢпјҢжҳҜеҗҰйҮҚж–°еҸ‘иө·leaderзҡ„з«һдәүгҖӮ
ж ёеҝғжәҗз Ғеү–жһҗ
еӣ дёәзҜҮе№…еҺҹеӣ иҝҷйҮҢеҸӘд»Ӣз»ҚеҹәдәҺconfigMapзҡ„resourceLock, е…¶д»–зҡ„йғҪеӨ§еҗҢе°ҸејӮгҖӮ
LeaderElectionRecord
еңЁжҲ‘зҡ„зҗҶи§ЈдёҠиҝҷдёӘж•°з»“жһ„зҡ„и®ҫи®ЎпјҢжүҚжҳҜзңҹжӯЈзҡ„йӮЈжҠҠй”Ғ(е°ұеҘҪеғҸз”ҹжҙ»дёӯжҲ‘们еҸҜд»ҘйҡҸдҫҝд№°жҠҠй”ҒпјҢй”Ғеҗ„з§Қй—Ё)гҖӮйҖҡиҝҮиҝҷдёӘй”ҒеұҸи”Ҫеә•еұӮзҡ„еҗ„з§Қй”Ғе®һзҺ°зі»з»ҹзҡ„е®һзҺ°з»ҶиҠӮпјҢдҪҶжіЁж„ҸиҝҷжҠҠй”Ғ并дёҚжҳҜдёҘж јзҡ„еҲҶеёғејҸдә’ж–Ҙй”ҒгҖӮ
ж•°жҚ®з»“жһ„
еңЁй”Ғзҡ„е®һзҺ°дёӯпјҢж•°жҚ®дё»иҰҒеҲҶдёәдёүзұ»пјҡиә«д»ҪеҮӯиҜҒгҖҒж—¶й—ҙжҲігҖҒе…ЁеұҖи®Ўж•°еҷЁпјҢ然еҗҺжҲ‘们дҫқж¬ЎжқҘзңӢзҢңдёӢеҜ№еә”зҡ„и®ҫи®ЎжҖқи·ҜгҖӮ
type LeaderElectionRecord struct { HolderIdentity string `json:"holderIdentity"` LeaseDurationSeconds int `json:"leaseDurationSeconds"` AcquireTime metav1.Time `json:"acquireTime"` RenewTime metav1.Time `json:"renewTime"` LeaderTransitions int `json:"leaderTransitions"` }иә«д»ҪеҮӯиҜҒпјҡHolderIdentity
иә«д»ҪеҮӯиҜҒдё»иҰҒжҳҜз”ЁдәҺж ҮиҜҶдёҖдёӘиҠӮзӮ№дҝЎжҒҜпјҢеңЁдёҖдәӣеҲҶеёғејҸеҚҸи°ғзі»з»ҹдёӯйҖҡеёёйғҪжҳҜзі»з»ҹиҮӘеёҰзҡ„жңәеҲ¶пјҢжҜ”еҰӮzookeeperдёӯзҡ„session, еңЁжӯӨеӨ„иө„жәҗй”Ғзҡ„еңәжҷҜдёӢпјҢдё»иҰҒжҳҜдёәдәҶз”ЁдәҺеҗҺз»ӯжөҒзЁӢйҮҢйӘҢиҜҒеҪ“еүҚиҠӮзӮ№жҳҜеҗҰиҺ·еҸ–еҲ°й”ҒгҖӮ
ж—¶й—ҙжҲіпјҡLeaseDurationSecondsгҖҒAcquireTimeгҖҒRenewTime
еӣ дёәд№ӢеүҚиҜҙзҡ„ж—¶й—ҙеҗҢжӯҘзҡ„й—®йўҳпјҢиҝҷйҮҢзҡ„ж—¶й—ҙзӣёе…ізҡ„дё»иҰҒжҳҜз”ЁдәҺleaderиҠӮзӮ№и§ҰеҸ‘иҠӮзӮ№еҸҳжӣҙжқҘдҪҝз”Ё(Leaseзұ»еһӢд№ҹеңЁдҪҝз”Ё)пјҢйқһLeaderиҠӮзӮ№еҲҷж №жҚ®еҪ“еүҚи®°еҪ•жҳҜеҗҰеҸҳжӣҙжқҘжЈҖжөӢleaderиҠӮзӮ№жҳҜеҗҰеӯҳжҙ»гҖӮ
LeaderTransitions
и®Ўж•°еҷЁдё»иҰҒе°ұжҳҜйҖҡиҝҮи®Ўж•°жқҘи®°еҪ•leaderиҠӮзӮ№еҲҮжҚўзҡ„ж¬Ўж•°гҖӮ
ConfigMapLock
жүҖи°“зҡ„иө„жәҗй”Ғе…¶е®һе°ұжҳҜйҖҡиҝҮеҲӣе»әдёҖдёӘConfigMapе®һдҫӢжқҘдҝқеӯҳжҲ‘们зҡ„й”ҒдҝЎжҒҜпјҢ并йҖҡиҝҮиҝҷдёӘе®һдҫӢдҝЎжҒҜзҡ„з»ҙжҠӨпјҢжқҘе®һзҺ°й”Ғзҡ„з«һдәүе’ҢйҮҠж”ҫгҖӮ
1. еҲӣе»әй”Ғ
йҖҡиҝҮеҲ©з”Ёetcdзҡ„е№ӮзӯүжҖ§ж“ҚдҪңпјҢеҸҜд»ҘдҝқиҜҒеҗҢж—¶еҸӘдјҡжңүдёҖдёӘleaderиҠӮзӮ№иҝӣиЎҢй”ҒеҲӣе»әжҲҗеҠҹпјҢ并且йҖҡиҝҮAnnotationsжқҘжҸҗдәӨдёҠйқўиҜҙзҡ„LeaderElectionRecordжқҘиҝӣиЎҢй”Ғзҡ„жҸҗдәӨгҖӮ
func (cml *ConfigMapLock) Create(ler LeaderElectionRecord) error { cml.cm, err = cml.Client.ConfigMaps(cml.ConfigMapMeta.Namespace).Create(&v1.ConfigMap{ ObjectMeta: metav1.ObjectMeta{ Name: cml.ConfigMapMeta.Name, Namespace: cml.ConfigMapMeta.Namespace, Annotations: map[string]string{ LeaderElectionRecordAnnotationKey: string(recordBytes), }, }, }) return err }2. иҺ·еҸ–й”Ғ
func (cml *ConfigMapLock) Get() (*LeaderElectionRecord, []byte, error) { cml.cm, err = cml.Client.ConfigMaps(cml.ConfigMapMeta.Namespace).Get(cml.ConfigMapMeta.Name, metav1.GetOptions{}) recordBytes, found := cml.cm.Annotations[LeaderElectionRecordAnnotationKey] if found { if err := json.Unmarshal([]byte(recordBytes), &record); err != nil { return nil, nil, err } } return &record, []byte(recordBytes), nil }3. жӣҙж–°й”Ғ
func (cml *ConfigMapLock) Update(ler LeaderElectionRecord) error { cml.cm.Annotations[LeaderElectionRecordAnnotationKey] = string(recordBytes) cml.cm, err = cml.Client.ConfigMaps(cml.ConfigMapMeta.Namespace).Update(cml.cm) return err }LeaderElector
LeaderElectorзҡ„ж ёеҝғжөҒзЁӢеҲҶдёәдёүйғЁеҲҶпјҡз«һдәүй”ҒгҖҒи¶…ж—¶жЈҖжөӢгҖҒеҝғи·із»ҙжҠӨпјҢйҰ–е…ҲжүҖжңүиҠӮзӮ№йғҪдјҡиҝӣиЎҢиө„жәҗй”Ғзҡ„з«һдәүпјҢдҪҶжҳҜжңҖз»ҲеҸӘдјҡжңүдёҖдёӘиҠӮзӮ№жҲҗдёәLeaderиҠӮзӮ№пјҢ 然еҗҺж ёеҝғжөҒзЁӢе°ұдјҡжҢүз…§и§’иүІеҲҶжҲҗдёӨдёӘдё»жөҒзЁӢ, и®©жҲ‘们дёҖиө·жқҘзңӢдёӢе…¶е®һзҺ°гҖӮ
1. ж ёеҝғжөҒзЁӢ
еҰӮжһңиҠӮзӮ№жІЎжңүacquireжҲҗеҠҹеҲҷдјҡдёҖзӣҙиҝӣиЎҢе°қиҜ•пјҢзӣҙиҮіеҸ–ж¶ҲжҲ–иҖ…з«һйҖүжҲҗеҠҹпјҢиҖҢleaderиҠӮзӮ№еҲҷдјҡжү§иЎҢжҲҗдёә leaderиҠӮзӮ№зҡ„еӣһи°ғ(иЎҘе……еҹәдәҺleaderзҡ„zookeeperзҡ„е®һзҺ°жңәеҲ¶)
func (le *LeaderElector) Run(ctx context.Context) { defer func() { runtime.HandleCrash() le.config.Callbacks.OnStoppedLeading() }() if !le.acquire(ctx) { // зІҫйҖүй”Ғ return // ctx signalled done } // еҰӮжһңй”Ғз«һйҖүжҲҗеҠҹпјҢеҲҷleaderиҠӮзӮ№дјҡжү§иЎҢеү©дҪҷжөҒзЁӢпјҢиҖҢйқһleaderиҠӮзӮ№еҲҷ继з»ӯе°қиҜ•acquire ctx, cancel := context.WithCancel(ctx) defer cancel() go le.config.Callbacks.OnStartedLeading(ctx) le.renew(ctx) }2. й”Ғзҡ„з»ӯзәҰ
еҰӮжһңз«һйҖүдёәleaderиҠӮзӮ№пјҢеҲҷе°ұйңҖиҰҒиҝӣиЎҢй”Ғзҡ„з»ӯзәҰж“ҚдҪңпјҢе°ұжҳҜйҖҡиҝҮи°ғз”ЁдёҠйқўжҸҗеҲ°зҡ„жӣҙж–°й”Ғзҡ„ж“ҚдҪңжқҘпјҢе‘ЁжңҹжҖ§зҡ„жӣҙж–°й”Ғи®°еҪ•дҝЎжҒҜеҚіLeaderElectionRecordпјҢд»ҺиҖҢиҫҫеҲ°з»ӯзәҰзҡ„зӣ®ж ҮгҖӮ
func (le *LeaderElector) renew(ctx context.Context) { ctx, cancel := context.WithCancel(ctx) defer cancel() wait.Until(func() { timeoutCtx, timeoutCancel := context.WithTimeout(ctx, le.config.RenewDeadline) defer timeoutCancel() err := wait.PollImmediateUntil(le.config.RetryPeriod, func() (bool, error) { done := make(chan bool, 1) go func() { defer close(done) // й”Ғзҡ„з»ӯзәҰ done <- le.tryAcquireOrRenew() }() select { case <-timeoutCtx.Done(): return false, fmt.Errorf("failed to tryAcquireOrRenew %s", timeoutCtx.Err()) case result := <-done: return result, nil } }, timeoutCtx.Done()) cancel() }, le.config.RetryPeriod, ctx.Done()) // if we hold the lease, give it up if le.config.ReleaseOnCancel { // йҮҠж”ҫй”Ғ le.release() } }3. й”Ғзҡ„йҮҠж”ҫ
й”Ғзҡ„йҮҠж”ҫеҲҷжҜ”иҫғеҘҪзҺ©пјҢе°ұжҳҜжӣҙж–°еҜ№еә”зҡ„иө„жәҗпјҢеҺ»жҺүannotationsйҮҢйқўзҡ„дҝЎжҒҜпјҢиҝҷж ·еңЁиҺ·еҸ–й”Ғзҡ„ж—¶еҖҷпјҢеӣ дёәжЈҖжөӢеҲ°еҪ“еүҚиө„жәҗжІЎжңүиў«д»»дҪ•еҮӯиҜҒдҝЎжҒҜпјҢе°ұдјҡе°қиҜ•иҝӣиЎҢз«һйҖүгҖӮ
func (le *LeaderElector) release() bool { if !le.IsLeader() { return true } leaderElectionRecord := rl.LeaderElectionRecord{ LeaderTransitions: le.observedRecord.LeaderTransitions, } if err := le.config.Lock.Update(leaderElectionRecord); err != nil { klog.Errorf("Failed to release lock: %v", err) return false } le.observedRecord = leaderElectionRecord le.observedTime = le.clock.Now() return true }4. й”Ғзҡ„з«һдәү

й”Ғзҡ„з«һдәүж•ҙдҪ“еҲҶдёәеӣӣдёӘйғЁеҲҶ: 1)иҺ·еҸ–й”Ғ 2)еҲӣе»әй”Ғ 3)жЈҖжөӢй”Ғ 4)жӣҙж–°й”ҒпјҢдёӢйқўжқҘдҫқж¬ЎзңӢдёӢеҜ№еә”зҡ„е®һзҺ°гҖӮ
иҺ·еҸ–й”Ғ
йҰ–е…Ҳдјҡе°қиҜ•иҺ·еҸ–еҜ№еә”зҡ„й”ҒпјҢеңЁиҺ·еҸ–й”ҒдёӯдјҡжЈҖжөӢеҜ№еә”зҡ„annotationsдёӯжҳҜеҗҰеӯҳеңЁпјҢеҰӮжһңдёҚеӯҳеңЁеҲҷoldLeaderElectionRecordе°ұдёәз©әпјҢеҚіеҪ“еүҚиө„жәҗй”ҒжІЎжңүиў«дәәжҢҒжңүгҖӮ
oldLeaderElectionRecord, oldLeaderElectionRawRecord, err := le.config.Lock.Get()
еҲӣе»әй”Ғ
еҰӮжһңжЈҖжөӢеҲ°еҜ№еә”зҡ„й”ҒдёҚеӯҳеңЁпјҢеҲҷе°ұдјҡзӣҙжҺҘиҝӣиЎҢй”Ғзҡ„еҲӣе»әпјҢеҰӮжһңеҲӣе»әжҲҗеҠҹеҲҷиЎЁжҳҺеҪ“еүҚиҠӮзӮ№иҺ·еҸ–й”ҒпјҢеҲҷе°ұжҲҗдёәleaderпјҢжү§иЎҢleaderзҡ„еӣһи°ғйҖ»иҫ‘гҖӮ
if err != nil { if !errors.IsNotFound(err) { klog.Errorf("error retrieving resource lock %v: %v", le.config.Lock.Describe(), err) return false } // еҲӣе»әй”Ғ if err = le.config.Lock.Create(leaderElectionRecord); err != nil { klog.Errorf("error initially creating leader election record: %v", err) return false } // и®°еҪ•еҪ“еүҚзҡ„йҖүдёҫи®°еҪ•пјҢиҝҳжңүж—¶й’ҹ le.observedRecord = leaderElectionRecord le.observedTime = le.clock.Now() return true }жЈҖжҹҘй”Ғ
еңЁK8sйҮҢйқўе№¶жІЎжңүдҪҝз”ЁйҖ»иҫ‘ж—¶й’ҹиҖҢжҳҜдҪҝз”Ёжң¬ең°ж—¶й—ҙпјҢйҖҡиҝҮеҜ№жҜ”жҜҸж¬Ўй”ҒеҮӯиҜҒжҳҜеҗҰжӣҙж–°пјҢжқҘиҝӣиЎҢжң¬ең°observedTimeзҡ„жӣҙж–°пјҢеҰӮжһңleaderжІЎжңүеңЁLeaseDurationеҶ…жқҘжӣҙж–°еҜ№еә”зҡ„й”ҒеҮӯиҜҒдҝЎжҒҜпјҢеҲҷеҪ“еүҚиҠӮзӮ№е°ұдјҡе°қиҜ•жҲҗдёәleaderгҖӮ
еҗҢж—¶иҝҷйҮҢиҝҳдјҡдҝқйҡңжңҖз»Ҳзҡ„дёҖиҮҙжҖ§й”ҒпјҢеӣ дёәеҗҺз»ӯзҡ„renewе…¶е®һд№ҹжҳҜиө°зҡ„иҝҷдёӘйҖ»иҫ‘пјҢеҰӮжһңиҜҙеҪ“еүҚиҠӮзӮ№жңҖејҖе§ӢжҢҒжңүй”ҒпјҢдҪҶжҳҜиў«еҲ«зҡ„иҠӮзӮ№жҠўеҚ пјҢеҲҷеҪ“еүҚиҠӮзӮ№дјҡдё»еҠЁи®©еҮәй”ҒгҖӮ
if !bytes.Equal(le.observedRawRecord, oldLeaderElectionRawRecord) { le.observedRecord = *oldLeaderElectionRecord le.observedRawRecord = oldLeaderElectionRawRecord le.observedTime = le.clock.Now() // жӯӨеӨ„жӣҙж–°зҡ„жҳҜжң¬ең°зҡ„ж—¶й’ҹ } if len(oldLeaderElectionRecord.HolderIdentity) > 0 && le.observedTime.Add(le.config.LeaseDuration).After(now.Time) && !le.IsLeader() { // еҰӮжһңеҪ“еүҚLeaderд»»жңҹжІЎжңүи¶…ж—¶пјҢеҲҷеҪ“еүҚз«һйҖүй”ҒеӨұиҙҘ klog.V(4).Infof("lock is held by %v and has not yet expired", oldLeaderElectionRecord.HolderIdentity) return false }жӣҙж–°й”Ғ
ж ёеҝғйҖ»иҫ‘е…¶е®һе°ұжҳҜLock.UpdateиҝҷдёӘең°ж–№пјҢи®ҫи®Ўзҡ„жҜ”иҫғжңүж„ҸжҖқпјҢдёҚеҗҢдәҺејәдёҖиҮҙжҖ§зҡ„й”ҒпјҢеңЁK8sдёӯжҲ‘们еҸҜд»ҘеҗҢж—¶жңүеӨҡдёӘиҠӮзӮ№йғҪиө°еҲ°иҝҷйҮҢпјҢдҪҶжҳҜеӣ дёәжӣҙж–°etcdжҳҜдёҖдёӘеҺҹеӯҗзҡ„ж“ҚдҪңпјҢжңҖз»ҲеҸӘдјҡжңүдёҖдёӘиҠӮзӮ№жӣҙж–°жҲҗеҠҹпјҢйӮЈеҰӮдҪ•дҝқиҜҒжңҖз»Ҳзҡ„й”Ғзҡ„иҜӯд№үе‘ўпјҢе…¶е®һе°ұиҰҒй…ҚеҗҲдёҠйқўзҡ„жЈҖжөӢй”ҒпјҢиҝҷж ·е°ұеҸҜд»Ҙе®һзҺ°дёҖдёӘйқўеҗ‘з»ҲжҖҒзҡ„жңҖз»Ҳзҡ„й”ҒжңәеҲ¶гҖӮ
if le.IsLeader() { leaderElectionRecord.AcquireTime = oldLeaderElectionRecord.AcquireTime leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions } else { leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions + 1 } // update the lock itself if err = le.config.Lock.Update(leaderElectionRecord); err != nil { klog.Errorf("Failed to update lock: %v", err) return false } le.observedRecord = leaderElectionRecord le.observedTime = le.clock.Now() return trueз–‘й—®
еӣһиҝҮжқҘзңӢй”ҒжҳҜеӣ дёәжңҖиҝ‘еңЁеҒҡзі»з»ҹи®ҫи®Ўзҡ„ж—¶еҖҷпјҢжғіеҲ°зҡ„дёҖдёӘй—®йўҳгҖӮеңЁPAASзі»з»ҹдёӯйҖҡеёёдјҡжңүNеӨҡзҡ„OperatorпјҢйӮЈеңЁдёҖдәӣеҶІзӘҒзҡ„еңәжҷҜиҜҘеҰӮдҪ•и§ЈеҶіе‘ў?жҜ”еҰӮжү©зј©е®№гҖҒеҸ‘еёғгҖҒе®№зҒҫиҝҷеҮ дёӘжҺ§еҲ¶еҷЁпјҢеҰӮжһңиҰҒж“ҚдҪңеҗҢдёҖдёӘappдёӢйқўзҡ„podиҜҘеҰӮдҪ•иў«и°ғеәҰе‘ў?
е…¶е®һжҲ‘зҗҶи§ЈиҝҷдёӘжөҒзЁӢдёӯжҳҜж— жі•еҒҡеҲ°еҗ„з§Қе®ҢзҫҺcoverеҗ„з§ҚејӮеёёеҶІзӘҒзҡ„пјҢдҪҶжҳҜжҲ‘们еҸҜд»ҘзҺ©еҸҰеӨ–дёҖз§Қжңүж„ҸжҖқзҡ„дәӢжғ…пјҢжҜ”еҰӮжҲ‘们еҸҜд»ҘеҠ дёҖдёӘдҝқжҠӨзҠ¶жҖҒпјҢеӣ дёәеҜ№з”ҹдә§зЁіе®ҡеҺӢеҖ’дёҖиө·гҖӮеҚіеҜ№еә”зҡ„жҺ§еҲ¶еҷЁпјҢе…іжіЁеҪ“еүҚзҡ„зҠ¶жҖҒжҳҜеҗҰеӨ„дәҺзЁіе®ҡзҠ¶жҖҒпјҢеҰӮжһңжҳҜйқһзЁіе®ҡзҠ¶жҖҒпјҢеҲҷе°ұеә”иҜҘиҮӘиә«еҶ»з»“пјҢзӯүеҪ“еүҚеә”з”ЁеӨ„дәҺйқһдҝқжҠӨзҠ¶жҖҒеҶҚиҝӣиЎҢж“ҚдҪңпјҢдҝқиҜҒSLAзҡ„еҗҢж—¶д№ҹдёҚеҪұе“Қеҗ„з§ҚеҘҪзҺ©зҡ„ж“ҚдҪңгҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңKubernetesдёӯй”ҒжңәеҲ¶зҡ„и®ҫи®ЎдёҺе®һзҺ°ж–№жі•жҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№Kubernetesдёӯй”ҒжңәеҲ¶зҡ„и®ҫи®ЎдёҺе®һзҺ°ж–№жі•жҳҜд»Җд№ҲиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ