жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңжҖҺд№Ҳз”ЁScrapyзҲ¬иҷ«жЎҶжһ¶зҲ¬еҸ–йЈҹе“Ғи®әеқӣж•°жҚ®е№¶еӯҳе…Ҙж•°жҚ®еә“вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁжҖҺд№Ҳз”ЁScrapyзҲ¬иҷ«жЎҶжһ¶зҲ¬еҸ–йЈҹе“Ғи®әеқӣж•°жҚ®е№¶еӯҳе…Ҙж•°жҚ®еә“й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқжҖҺд№Ҳз”ЁScrapyзҲ¬иҷ«жЎҶжһ¶зҲ¬еҸ–йЈҹе“Ғи®әеқӣж•°жҚ®е№¶еӯҳе…Ҙж•°жҚ®еә“вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
зҪ‘з»ңзҲ¬иҷ«(еҸҲз§°дёәзҪ‘йЎөиңҳиӣӣпјҢзҪ‘з»ңжңәеҷЁдәә)пјҢжҳҜдёҖз§ҚжҢүз…§дёҖе®ҡзҡ„规еҲҷпјҢиҮӘеҠЁең°жҠ“еҸ–дёҮз»ҙзҪ‘дҝЎжҒҜзҡ„зЁӢеәҸжҲ–иҖ…и„ҡжң¬гҖӮеҸҰеӨ–дёҖдәӣдёҚеёёдҪҝз”Ёзҡ„еҗҚеӯ—иҝҳжңүиҡӮиҡҒгҖҒиҮӘеҠЁзҙўеј•гҖҒжЁЎжӢҹзЁӢеәҸжҲ–иҖ…и •иҷ«гҖӮ------зҷҫеәҰзҷҫ科
иҜҙдәәиҜқе°ұжҳҜпјҢзҲ¬иҷ«жҳҜз”ЁжқҘжө·йҮҸ规еҲҷеҢ–иҺ·еҸ–ж•°жҚ®пјҢ然еҗҺиҝӣиЎҢеӨ„зҗҶе’Ңиҝҗз”ЁпјҢеңЁеӨ§ж•°жҚ®гҖҒйҮ‘иһҚгҖҒжңәеҷЁеӯҰд№ зӯүзӯүж–№йқўйғҪжҳҜеҝ…йЎ»зҡ„ж”Ҝж’‘жқЎд»¶д№ӢдёҖгҖӮ
зӣ®еүҚеңЁдёҖзәҝеҹҺеёӮдёӯпјҢзҲ¬иҷ«зҡ„еІ—дҪҚи–Әиө„еҫ…йҒҮйғҪжҳҜжҜ”иҫғе®ўи§Ӯзҡ„пјҢд№ӢеҗҺжҸҗеҚҮеҲ°дёӯгҖҒй«ҳзә§зҲ¬иҷ«е·ҘзЁӢеёҲпјҢж•°жҚ®еҲҶжһҗеёҲгҖҒеӨ§ж•°жҚ®ејҖеҸ‘еІ—дҪҚзӯүпјҢйғҪжҳҜеҫҲеҘҪзҡ„иҝҮжёЎгҖӮ
жң¬жӯӨд»Ӣз»Қзҡ„йЎ№зӣ®е…¶е®һдёҚз”Ёжғізҡ„еӨӘиҝҮеӨҚжқӮпјҢжңҖз»ҲиҰҒе®һзҺ°зҡ„зӣ®ж Үд№ҹе°ұжҳҜе°Ҷеё–еӯҗзҡ„жҜҸжқЎиҜ„и®әзҲ¬еҸ–еҲ°ж•°жҚ®еә“дёӯпјҢ并且еҒҡеҲ°еҸҜд»Ҙжӣҙж–°ж•°жҚ®пјҢйҳІжӯўйҮҚеӨҚзҲ¬еҸ–пјҢеҸҚзҲ¬зӯүжҺӘж–ҪгҖӮ
иҝҷйғЁеҲҶдё»иҰҒжҳҜд»Ӣз»Қжң¬ж–ҮйңҖиҰҒз”ЁеҲ°зҡ„е·Ҙе…·пјҢж¶үеҸҠзҡ„еә“пјҢзҪ‘йЎөзӯүдҝЎжҒҜзӯү
иҪҜ件пјҡPyCharm
йңҖиҰҒзҡ„еә“пјҡScrapyпјҢ seleniumпјҢ pymongoпјҢ user_agentпјҢdatetime
зӣ®ж ҮзҪ‘з«ҷпјҡ
http://bbs.foodmate.net
жҸ’件пјҡchromedriver(зүҲжң¬иҰҒеҜ№)
1гҖҒзЎ®е®ҡзҲ¬еҸ–зҪ‘з«ҷзҡ„з»“жһ„
з®ҖиҖҢиЁҖд№ӢпјҡзЎ®е®ҡзҪ‘з«ҷзҡ„еҠ иҪҪж–№ејҸпјҢжҖҺж ·жүҚиғҪжӯЈзЎ®зҡ„дёҖзә§дёҖзә§зҡ„иҝӣе…ҘеҲ°её–еӯҗдёӯжҠ“еҸ–ж•°жҚ®пјҢдҪҝз”Ёд»Җд№Ҳж јејҸдҝқеӯҳж•°жҚ®зӯүгҖӮ
е…¶ж¬ЎпјҢи§ӮеҜҹзҪ‘з«ҷзҡ„еұӮзә§з»“жһ„пјҢд№ҹе°ұжҳҜиҜҙпјҢжҖҺд№Ҳж №жҚ®жқҝеқ—пјҢдёҖзӮ№зӮ№иҝӣе…ҘеҲ°её–еӯҗйЎөйқўдёӯпјҢиҝҷеҜ№жң¬ж¬ЎзҲ¬иҷ«д»»еҠЎйқһеёёйҮҚиҰҒпјҢд№ҹжҳҜдё»иҰҒзј–еҶҷд»Јз Ғзҡ„йғЁеҲҶгҖӮ
2гҖҒеҰӮдҪ•йҖүжӢ©еҗҲйҖӮзҡ„ж–№ејҸзҲ¬еҸ–ж•°жҚ®?
зӣ®еүҚжҲ‘зҹҘйҒ“зҡ„зҲ¬иҷ«ж–№жі•еӨ§жҰӮжңүеҰӮдёӢ(дёҚе…ЁпјҢдҪҶжҳҜжҜ”иҫғеёёз”Ё)пјҡ
1)requestжЎҶжһ¶пјҡиҝҗз”ЁиҝҷдёӘhttpеә“еҸҜд»ҘеҫҲзҒөжҙ»зҡ„зҲ¬еҸ–йңҖиҰҒзҡ„ж•°жҚ®пјҢз®ҖеҚ•дҪҶжҳҜиҝҮзЁӢзЁҚеҫ®з№ҒзҗҗпјҢ并且еҸҜд»Ҙй…ҚеҗҲжҠ“еҢ…е·Ҙе…·еҜ№ж•°жҚ®иҝӣиЎҢиҺ·еҸ–гҖӮдҪҶжҳҜйңҖиҰҒзЎ®е®ҡheadersеӨҙд»ҘеҸҠзӣёеә”зҡ„иҜ·жұӮеҸӮж•°пјҢеҗҰеҲҷж— жі•иҺ·еҸ–ж•°жҚ®;еҫҲеӨҡappзҲ¬еҸ–гҖҒеӣҫзүҮи§Ҷйў‘зҲ¬еҸ–йҡҸзҲ¬йҡҸеҒңпјҢжҜ”иҫғиҪ»йҮҸзҒөжҙ»пјҢ并且й«ҳ并еҸ‘дёҺеҲҶеёғејҸйғЁзҪІд№ҹйқһеёёзҒөжҙ»пјҢеҜ№дәҺеҠҹиғҪеҸҜд»ҘжӣҙеҘҪе®һзҺ°гҖӮ
2)scrapyжЎҶжһ¶пјҡscrapyжЎҶжһ¶еҸҜд»ҘиҜҙжҳҜзҲ¬иҷ«жңҖеёёз”ЁпјҢжңҖеҘҪз”Ёзҡ„зҲ¬иҷ«жЎҶжһ¶дәҶпјҢдјҳзӮ№еҫҲеӨҡпјҡscrapy жҳҜејӮжӯҘзҡ„;йҮҮеҸ–еҸҜиҜ»жҖ§жӣҙејәзҡ„ xpath д»ЈжӣҝжӯЈеҲҷ;ејәеӨ§зҡ„з»ҹи®Ўе’Ң log зі»з»ҹ;еҗҢж—¶еңЁдёҚеҗҢзҡ„ url дёҠзҲ¬иЎҢ;ж”ҜжҢҒ shell ж–№ејҸпјҢж–№дҫҝзӢ¬з«Ӣи°ғиҜ•;ж”ҜжҢҒеҶҷ middlewareж–№дҫҝеҶҷдёҖдәӣз»ҹдёҖзҡ„иҝҮж»ӨеҷЁ;еҸҜд»ҘйҖҡиҝҮз®ЎйҒ“зҡ„ж–№ејҸеӯҳе…Ҙж•°жҚ®еә“зӯүзӯүгҖӮиҝҷд№ҹжҳҜжң¬ж¬Ўж–Үз« жүҖиҰҒд»Ӣз»Қзҡ„жЎҶжһ¶(з»“еҗҲseleniumеә“)гҖӮ
1гҖҒ第дёҖжӯҘпјҡзЎ®е®ҡзҪ‘з«ҷзұ»еһӢ
йҰ–е…Ҳи§ЈйҮҠдёҖдёӢжҳҜд»Җд№Ҳж„ҸжҖқпјҢзңӢд»Җд№ҲзҪ‘з«ҷпјҢйҰ–е…ҲиҰҒзңӢзҪ‘з«ҷзҡ„еҠ иҪҪж–№ејҸпјҢжҳҜйқҷжҖҒеҠ иҪҪпјҢиҝҳжҳҜеҠЁжҖҒеҠ иҪҪ(jsеҠ иҪҪ)пјҢиҝҳжҳҜеҲ«зҡ„ж–№ејҸ;ж №жҚ®дёҚдёҖж ·зҡ„еҠ иҪҪж–№ејҸйңҖиҰҒдёҚеҗҢзҡ„еҠһжі•еә”еҜ№гҖӮ然еҗҺжҲ‘们и§ӮеҜҹд»ҠеӨ©зҲ¬еҸ–зҡ„зҪ‘з«ҷпјҢеҸ‘зҺ°иҝҷжҳҜдёҖдёӘжңүе№ҙд»Јж„ҹзҡ„и®әеқӣпјҢйҰ–е…ҲзҢңжөӢжҳҜйқҷжҖҒеҠ иҪҪзҡ„зҪ‘з«ҷ;жҲ‘们ејҖеҗҜз»„з»Ү js еҠ иҪҪзҡ„жҸ’件пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
еҲ·ж–°д№ӢеҗҺеҸ‘зҺ°зЎ®е®һжҳҜйқҷжҖҒзҪ‘з«ҷ(еҰӮжһңеҸҜд»ҘжӯЈеёёеҠ иҪҪеҹәжң¬йғҪжҳҜйқҷжҖҒеҠ иҪҪзҡ„)гҖӮ
2гҖҒ第дәҢжӯҘпјҡзЎ®е®ҡеұӮзә§е…ізі»
е…¶ж¬ЎпјҢжҲ‘们д»ҠеӨ©иҰҒзҲ¬еҸ–зҡ„зҪ‘з«ҷжҳҜйЈҹе“Ғи®әеқӣзҪ‘з«ҷпјҢжҳҜйқҷжҖҒеҠ иҪҪзҡ„зҪ‘з«ҷпјҢеңЁд№ӢеүҚеҲҶжһҗзҡ„ж—¶еҖҷе·Із»ҸдәҶи§ЈдәҶпјҢ然еҗҺжҳҜеұӮзә§з»“жһ„пјҡ

еӨ§жҰӮжҳҜдёҠйқўзҡ„жөҒзЁӢпјҢжҖ»е…ұжңүдёүзә§йҖ’иҝӣи®ҝй—®пјҢд№ӢеҗҺеҲ°иҫҫеё–еӯҗйЎөйқўпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

йғЁеҲҶд»Јз Ғеұ•зӨәпјҡ
дёҖзә§з•Ңйқўпјҡ
def parse(self, response): self.logger.info("е·Іиҝӣе…ҘзҪ‘йЎөпјҒ") self.logger.info("жӯЈеңЁиҺ·еҸ–зүҲеқ—еҲ—иЎЁпјҒ") column_path_list = response.css('#ct > div.mn > div:nth-child(2) > div')[:-1] for column_path in column_path_list: col_paths = column_path.css('div > table > tbody > tr > td > div > a').xpath('@href').extract() for path in col_paths: block_url = response.urljoin(path) yield scrapy.Request( url=block_url, callback=self.get_next_path, )дәҢзә§з•Ңйқўпјҡ
def get_next_path(self, response): self.logger.info("е·Іиҝӣе…ҘзүҲеқ—пјҒ") self.logger.info("жӯЈеңЁиҺ·еҸ–ж–Үз« еҲ—иЎЁпјҒ") if response.url == 'http://www.foodmate.net/know/': pass else: try: nums = response.css('#fd_page_bottom > div > label > span::text').extract_first().split(' ')[-2] except: nums = 1 for num in range(1, int(nums) + 1): tbody_list = response.css('#threadlisttableid > tbody') for tbody in tbody_list: if 'normalthread' in str(tbody): item = LunTanItem() item['article_url'] = response.urljoin( tbody.css('* > tr > th > a.s.xst').xpath('@href').extract_first()) item['type'] = response.css( '#ct > div > div.bm.bml.pbn > div.bm_h.cl > h2 > a::text').extract_first() item['title'] = tbody.css('* > tr > th > a.s.xst::text').extract_first() item['spider_type'] = "и®әеқӣ" item['source'] = "йЈҹе“Ғи®әеқӣ" if item['article_url'] != 'http://bbs.foodmate.net/': yield scrapy.Request( url=item['article_url'], callback=self.get_data, meta={'item': item, 'content_info': []} ) try: callback_url = response.css('#fd_page_bottom > div > a.nxt').xpath('@href').extract_first() callback_url = response.urljoin(callback_url) yield scrapy.Request( url=callback_url, callback=self.get_next_path, ) except IndexError: passдёүзә§з•Ңйқўпјҡ
def get_data(self, response): self.logger.info("жӯЈеңЁзҲ¬еҸ–и®әеқӣж•°жҚ®пјҒ") item = response.meta['item'] content_list = [] divs = response.xpath('//*[@id="postlist"]/div') user_name = response.css('div > div.pi > div:nth-child(1) > a::text').extract() publish_time = response.css('div.authi > em::text').extract() floor = divs.css('* strong> a> em::text').extract() s_id = divs.xpath('@id').extract() for i in range(len(divs) - 1): content = '' try: strong = response.css('#postmessage_' + s_id[i].split('_')[-1] + '').xpath('string(.)').extract() for s in strong: content += s.split(';')[-1].lstrip('\r\n') datas = dict(content=content, # еҶ…е®№ reply_id=0, # еӣһеӨҚзҡ„жҘјеұӮ,й»ҳи®Ө0 user_name=user_name[i], # вҪӨжҲ·еҗҚ publish_time=publish_time[i].split('дәҺ ')[-1], # %Y-%m-%d %H:%M:%S' id='#' + floor[i], # жҘјеұӮ ) content_list.append(datas) except IndexError: pass item['content_info'] = response.meta['content_info'] item['scrawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S') item['content_info'] += content_list data_url = response.css('#ct > div.pgbtn > a').xpath('@href').extract_first() if data_url != None: data_url = response.urljoin(data_url) yield scrapy.Request( url=data_url, callback=self.get_data, meta={'item': item, 'content_info': item['content_info']} ) else: item['scrawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S') self.logger.info("жӯЈеңЁеӯҳеӮЁпјҒ") print('еӮЁеӯҳжҲҗеҠҹ') yield item3гҖҒ第дёүжӯҘпјҡзЎ®е®ҡзҲ¬еҸ–ж–№жі•
з”ұдәҺжҳҜйқҷжҖҒзҪ‘йЎөпјҢйҰ–е…ҲеҶіе®ҡйҮҮз”Ёзҡ„жҳҜscrapyжЎҶжһ¶зӣҙжҺҘиҺ·еҸ–ж•°жҚ®пјҢ并且йҖҡиҝҮеүҚжңҹжөӢиҜ•еҸ‘зҺ°ж–№жі•зЎ®е®һеҸҜиЎҢпјҢдёҚиҝҮеҪ“ж—¶е№ҙе°‘иҪ»зӢӮпјҢе°ҸзңӢдәҶзҪ‘з«ҷзҡ„дҝқжҠӨжҺӘж–ҪпјҢз”ұдәҺиҖҗеҝғжңүйҷҗпјҢжІЎжңүеҠ дёҠе®ҡж—¶еҷЁйҷҗеҲ¶зҲ¬еҸ–йҖҹеәҰпјҢеҜјиҮҙжҲ‘иў«зҪ‘з«ҷеҠ дәҶйҷҗеҲ¶пјҢ并且зҪ‘з«ҷз”ұйқҷжҖҒеҠ иҪҪзҪ‘йЎөеҸҳдёәпјҡеҠЁжҖҒеҠ иҪҪзҪ‘йЎөйӘҢиҜҒз®—жі•д№ӢеҗҺеҶҚиҝӣе…ҘеҲ°иҜҘзҪ‘йЎөпјҢзӣҙжҺҘи®ҝй—®дјҡиў«еҗҺеҸ°жӢ’з»қгҖӮ
дҪҶжҳҜиҝҷз§Қй—®йўҳжҖҺд№ҲдјҡйҡҫйҒ“жҲ‘иҝҷе°ҸиҒӘжҳҺпјҢз»ҸиҝҮжҲ‘зҹӯжҡӮең°жҖқиҖғ(1еӨ©)пјҢжҲ‘е°Ҷж–№жЎҲж”№дёәscrapyжЎҶжһ¶ + seleniumеә“зҡ„ж–№жі•пјҢйҖҡиҝҮи°ғз”ЁchromedriverпјҢжЁЎжӢҹи®ҝй—®зҪ‘з«ҷпјҢзӯүзҪ‘з«ҷеҠ иҪҪе®ҢдәҶеҶҚзҲ¬еҸ–дёҚе°ұе®ҢдәҶпјҢеҗҺз»ӯиҜҒжҳҺиҝҷдёӘж–№жі•зЎ®е®һеҸҜиЎҢпјҢ并且ж•ҲзҺҮд№ҹдёҚй”ҷгҖӮ
е®һзҺ°йғЁеҲҶд»Јз ҒеҰӮдёӢпјҡ
def process_request(self, request, spider): chrome_options = Options() chrome_options.add_argument('--headless') # дҪҝз”Ёж— еӨҙи°·жӯҢжөҸи§ҲеҷЁжЁЎејҸ chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--no-sandbox') # жҢҮе®ҡи°·жӯҢжөҸи§ҲеҷЁи·Ҝеҫ„ self.driver = webdriver.Chrome(chrome_options=chrome_options, executable_path='E:/pycharm/workspace/зҲ¬иҷ«/scrapy/chromedriver') if request.url != 'http://bbs.foodmate.net/': self.driver.get(request.url) html = self.driver.page_source time.sleep(1) self.driver.quit() return scrapy.http.HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8', request=request)4гҖҒ第еӣӣжӯҘпјҡзЎ®е®ҡзҲ¬еҸ–ж•°жҚ®зҡ„еӮЁеӯҳж јејҸ
иҝҷйғЁеҲҶдёҚз”ЁеӨҡиҜҙпјҢж №жҚ®иҮӘе·ұйңҖжұӮпјҢе°ҶйңҖиҰҒзҲ¬еҸ–зҡ„ж•°жҚ®ж јејҸи®ҫзҪ®еңЁitems.pyдёӯгҖӮеңЁе·ҘзЁӢдёӯеј•з”ЁиҜҘж јејҸдҝқеӯҳеҚіеҸҜпјҡ
class LunTanItem(scrapy.Item): """ и®әеқӣеӯ—ж®ө """ title = Field() # str: еӯ—з¬Ұзұ»еһӢ | и®әеқӣж Үйўҳ content_info = Field() # str: listзұ»еһӢ | зұ»еһӢlist: [LunTanContentInfoItem1, LunTanContentInfoItem2] article_url = Field() # str: url | ж–Үз« й“ҫжҺҘ scrawl_time = Field() # str: ж—¶й—ҙж јејҸ еҸӮз…§еҰӮдёӢж јејҸ 2019-08-01 10:20:00 | ж•°жҚ®зҲ¬еҸ–ж—¶й—ҙ source = Field() # str: еӯ—з¬Ұзұ»еһӢ | и®әеқӣеҗҚз§° eg: жңӘеҗҚBBS, ж°ҙжңЁзӨҫеҢә, еӨ©ж¶Ҝи®әеқӣ type = Field() # str: еӯ—з¬Ұзұ»еһӢ | жқҝеқ—зұ»еһӢ eg: 'иҙўз»Ҹ', 'дҪ“иӮІ', 'зӨҫдјҡ' spider_type = Field() # str: forum | еҸӘиғҪеҶҷ 'forum'
5гҖҒ第дә”жӯҘпјҡзЎ®е®ҡдҝқеӯҳж•°жҚ®еә“
жң¬ж¬ЎйЎ№зӣ®йҖүжӢ©дҝқеӯҳзҡ„ж•°жҚ®еә“дёәmongodbпјҢз”ұдәҺжҳҜйқһе…ізі»еһӢж•°жҚ®еә“пјҢдјҳзӮ№жҳҫиҖҢжҳ“и§ҒпјҢеҜ№ж јејҸиҰҒжұӮжІЎжңүйӮЈд№Ҳй«ҳпјҢеҸҜд»ҘзҒөжҙ»еӮЁеӯҳеӨҡз»ҙж•°жҚ®пјҢдёҖиҲ¬жҳҜзҲ¬иҷ«дјҳйҖүж•°жҚ®еә“(дёҚиҰҒе’ҢжҲ‘иҜҙredisпјҢдјҡдәҶжҲ‘д№ҹз”ЁпјҢдё»иҰҒжҳҜдёҚдјҡ)
д»Јз Ғпјҡ
import pymongo class FMPipeline(): def __init__(self): super(FMPipeline, self).__init__() # client = pymongo.MongoClient('139.217.92.75') client = pymongo.MongoClient('localhost') db = client.scrapy_FM self.collection = db.FM def process_item(self, item, spider): query = { 'article_url': item['article_url'] } self.collection.update_one(query, {"$set": dict(item)}, upsert=True) return itemиҝҷж—¶пјҢжңүиҒӘжҳҺзҡ„зӣҶеҸӢе°ұдјҡй—®пјҡеҰӮжһңиҝҗиЎҢдёӨж¬ЎзҲ¬еҸ–еҲ°дәҶдёҖж ·зҡ„ж•°жҚ®жҖҺд№ҲеҠһе‘ў?(жҚўеҸҘиҜқиҜҙе°ұжҳҜжҹҘйҮҚеҠҹиғҪ)
иҝҷдёӘй—®йўҳд№ӢеүҚжҲ‘д№ҹжІЎжңүиҖғиҷ‘пјҢеҗҺжқҘеңЁжҲ‘иҜўй—®еӨ§дҪ¬зҡ„иҝҮзЁӢдёӯзҹҘйҒ“дәҶпјҢеңЁжҲ‘们еӯҳж•°жҚ®зҡ„ж—¶еҖҷе°ұе·Із»ҸеҒҡе®Ңиҝҷ件дәӢдәҶпјҢе°ұжҳҜиҝҷеҸҘпјҡ
query = { 'article_url': item['article_url'] } self.collection.update_one(query, {"$set": dict(item)}, upsert=True)йҖҡиҝҮеё–еӯҗзҡ„й“ҫжҺҘзЎ®е®ҡжҳҜеҗҰжңүж•°жҚ®зҲ¬еҸ–йҮҚеӨҚпјҢеҰӮжһңйҮҚеӨҚеҸҜд»ҘзҗҶи§Јдёәе°Ҷе…¶иҰҶзӣ–пјҢиҝҷж ·д№ҹеҸҜд»ҘеҒҡеҲ°жӣҙж–°ж•°жҚ®гҖӮ
6гҖҒе…¶д»–и®ҫзҪ®
еғҸеӨҡзәҝзЁӢгҖҒheadersеӨҙпјҢз®ЎйҒ“дј иҫ“йЎәеәҸзӯүй—®йўҳпјҢйғҪеңЁsettings.pyж–Ү件дёӯи®ҫзҪ®пјҢе…·дҪ“еҸҜд»ҘеҸӮиҖғе°Ҹзј–зҡ„йЎ№зӣ®еҺ»зңӢпјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°гҖӮ
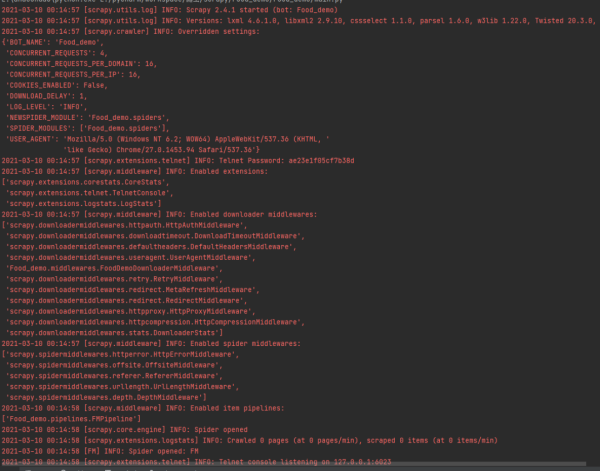
1гҖҒзӮ№еҮ»иҝҗиЎҢпјҢз»“жһңжҳҫзӨәеңЁжҺ§еҲ¶еҸ°пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

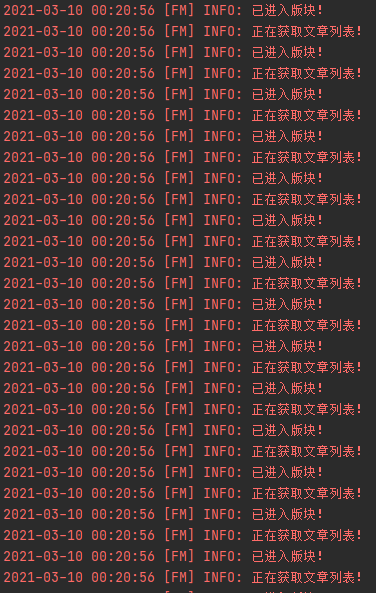
2гҖҒдёӯй—ҙдјҡдёҖзӣҙеҗ‘йҳҹеҲ—дёӯе ҶеҫҲеӨҡеё–еӯҗзҡ„зҲ¬еҸ–д»»еҠЎпјҢ然еҗҺеӨҡзәҝзЁӢеӨ„зҗҶпјҢжҲ‘и®ҫзҪ®зҡ„жҳҜ16зәҝзЁӢпјҢйҖҹеәҰиҝҳжҳҜеҫҲеҸҜи§Ӯзҡ„гҖӮ
3гҖҒж•°жҚ®еә“ж•°жҚ®еұ•зӨәпјҡ

content_infoдёӯеӯҳж”ҫзқҖжҜҸдёӘеё–еӯҗзҡ„е…ЁйғЁз•ҷиЁҖд»ҘеҸҠзӣёе…із”ЁжҲ·зҡ„е…¬ејҖдҝЎжҒҜгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңжҖҺд№Ҳз”ЁScrapyзҲ¬иҷ«жЎҶжһ¶зҲ¬еҸ–йЈҹе“Ғи®әеқӣж•°жҚ®е№¶еӯҳе…Ҙж•°жҚ®еә“вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ