жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№ҲзҗҶи§ЈKubernetesе®№еҷЁзҪ‘з»ңжЁЎеһӢвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№ҲзҗҶи§ЈKubernetesе®№еҷЁзҪ‘з»ңжЁЎеһӢвҖқеҗ§пјҒ
и®Ўз®—гҖҒеӯҳеӮЁе’ҢзҪ‘з»ңжҳҜдә‘ж—¶д»Јзҡ„дёүеӨ§еҹәзЎҖжңҚеҠЎпјҢдҪңдёәж–°дёҖд»ЈеҹәзЎҖжһ¶жһ„зҡ„ Kubernetes д№ҹдёҚдҫӢеӨ–гҖӮиҖҢиҝҷдёүиҖ…д№ӢдёӯпјҢзҪ‘з»ңеҸҲжҳҜдёҖдёӘжңҖйҡҫжҺҢжҸЎе’ҢжңҖе®№жҳ“еҮәй—®йўҳзҡ„жңҚеҠЎ;жң¬ж–ҮйҖҡиҝҮеҜ№KubernetesзҪ‘з»ңжөҒйҮҸжЁЎеһӢиҝӣиЎҢз®ҖеҚ•жўізҗҶпјҢеёҢжңӣеҜ№еҲқеӯҰиҖ…иғҪеӨҹжҸҗдҫӣдёҖе®ҡжҖқи·ҜгҖӮе…ҲзңӢдёҖдёӢkubernetes жҖ»дҪ“жЁЎеһӢпјҡ
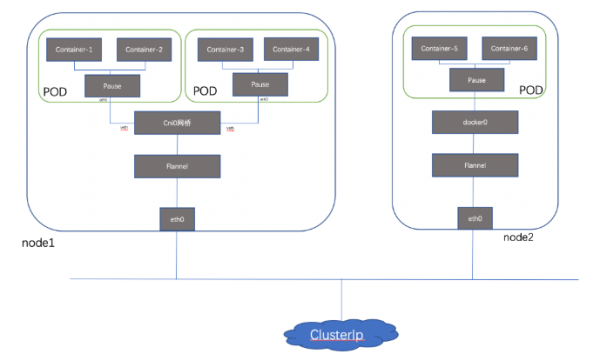
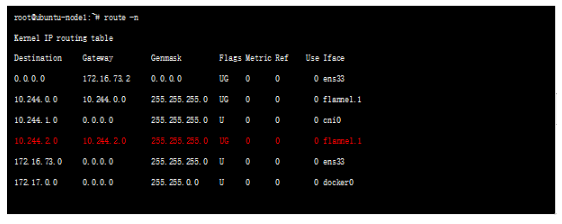
е®№еҷЁзҪ‘з»ңдёӯж¶үеҸҠзҡ„еҮ дёӘең°еқҖпјҡ
Node Ipпјҡзү©зҗҶжңәең°еқҖгҖӮ
POD IpпјҡKubernetesзҡ„жңҖе°ҸйғЁзҪІеҚ•е…ғжҳҜPodпјҢдёҖдёӘpod еҸҜиғҪеҢ…еҗ«дёҖдёӘжҲ–еӨҡдёӘе®№еҷЁпјҢз®ҖеҚ•жқҘи®Іе®№еҷЁжІЎжңүиҮӘе·ұеҚ•зӢ¬зҡ„ең°еқҖпјҢ他们е…ұдә«POD зҡ„ең°еқҖе’Ңз«ҜеҸЈеҢәй—ҙгҖӮ
ClusterIpпјҡServiceзҡ„Ipең°еқҖпјҢеӨ–йғЁзҪ‘з»ңж— жі•pingйҖҡж”№ең°еқҖпјҢеӣ дёәе®ғжҳҜиҷҡжӢҹIPең°еқҖпјҢжІЎжңүзҪ‘з»ңи®ҫеӨҮдёәиҝҷдёӘең°еқҖиҙҹиҙЈпјҢеҶ…йғЁе®һзҺ°жҳҜдҪҝз”ЁIptables规еҲҷйҮҚж–°е®ҡеҗ‘еҲ°е…¶жң¬ең°з«ҜеҸЈпјҢеҶҚеқҮиЎЎеҲ°еҗҺз«ҜPod;еҸӘжңүKubernetesйӣҶзҫӨеҶ…йғЁи®ҝй—®дҪҝз”ЁгҖӮ
Public Ip пјҡServiceеҜ№иұЎеңЁCluster IP rangeжұ дёӯеҲҶй…ҚеҲ°зҡ„IPеҸӘиғҪеңЁеҶ…йғЁи®ҝй—®пјҢйҖӮеҗҲдҪңдёәдёҖдёӘеә”з”ЁзЁӢеәҸеҶ…йғЁзҡ„еұӮж¬ЎгҖӮеҰӮжһңиҝҷдёӘServiceдҪңдёәеүҚз«ҜжңҚеҠЎпјҢеҮҶеӨҮдёәйӣҶзҫӨеӨ–зҡ„е®ўжҲ·жҸҗдҫӣдёҡеҠЎпјҢжҲ‘们е°ұйңҖиҰҒз»ҷиҝҷдёӘжңҚеҠЎжҸҗдҫӣе…¬е…ұIPгҖӮ
е®№еҷЁзҪ‘з»ңиҮіе°‘йңҖиҰҒи§ЈеҶіеҰӮдёӢеҮ з§ҚеңәжҷҜзҡ„йҖҡдҝЎпјҡв‘ PODеҶ…е®№еҷЁй—ҙйҖҡдҝЎ
в‘ЎеҗҢдё»жңәPODй—ҙ йҖҡдҝЎ
в‘ўи·Ёдё»жңәPODй—ҙ йҖҡдҝЎ
в‘ЈйӣҶзҫӨеҶ…Service Cluster Ipе’ҢеӨ–йғЁи®ҝй—®дёӢйқўе…·дҪ“д»Ӣз»Қе®һзҺ°ж–№ејҸ
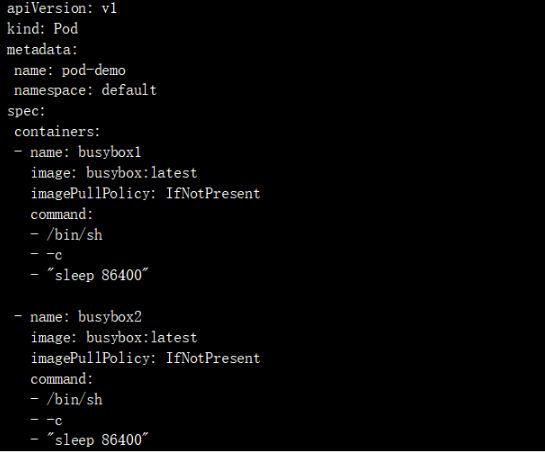
Podдёӯзҡ„е®№еҷЁеҸҜд»ҘйҖҡиҝҮвҖңlocalhostвҖқжқҘдә’зӣёйҖҡдҝЎпјҢ他们дҪҝз”ЁеҗҢдёҖдёӘзҪ‘з»ңе‘ҪеҗҚз©әй—ҙпјҢеҜ№е®№еҷЁжқҘиҜҙпјҢhostnameе°ұжҳҜPodзҡ„еҗҚз§°гҖӮPodдёӯзҡ„жүҖжңүе®№еҷЁе…ұдә«еҗҢдёҖдёӘIPең°еқҖе’Ңз«ҜеҸЈз©әй—ҙпјҢдҪ йңҖиҰҒдёәжҜҸдёӘйңҖиҰҒжҺҘ收иҝһжҺҘзҡ„е®№еҷЁеҲҶй…ҚдёҚеҗҢзҡ„з«ҜеҸЈгҖӮд№ҹе°ұжҳҜиҜҙпјҢPodдёӯзҡ„еә”з”ЁйңҖиҰҒиҮӘе·ұеҚҸи°ғз«ҜеҸЈзҡ„дҪҝз”ЁгҖӮе®һйӘҢеҰӮдёӢпјҡйҰ–е…ҲжҲ‘们еҲӣе»әдёҖдёӘPod пјҢеҢ…еҗ«дёӨдёӘе®№еҷЁпјҢе®№еҷЁеҸӮж•°еҰӮдёӢпјҡ
жҹҘзңӢпјҡ

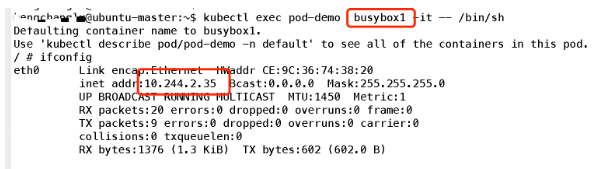
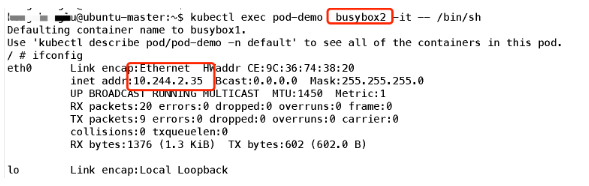
еҸҜд»ҘзңӢеҲ°е®№еҷЁе…ұдә«Pod зҡ„ең°еқҖпјҢйӮЈд№Ҳ他们жҳҜеҗҰдҪҝз”ЁеҗҢдёҖз«ҜеҸЈиө„жәҗе‘ўпјҢжҲ‘们еҸҜд»Ҙз®ҖеҚ•е®һйӘҢдёҖдёӢпјҡйҰ–е…ҲеңЁе®№еҷЁ1зӣ‘еҗ¬дёҖдёӘз«ҜеҸЈпјҡ

然еҗҺеңЁе®№еҷЁ2жҹҘзңӢиҜҘз«ҜеҸЈжҳҜеҗҰиў«еҚ з”Ёпјҡ

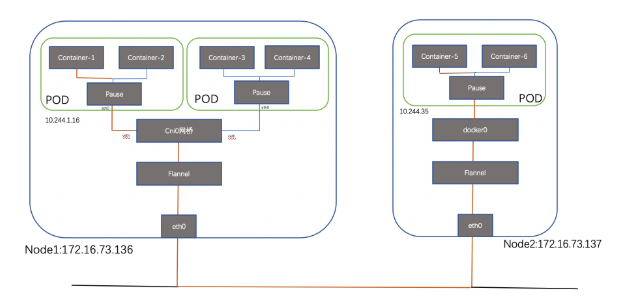
еҸҜи§Ғз«ҜеҸЈд№ҹжҳҜе…ұдә«зҡ„;жүҖд»Ҙз®ҖеҚ•зҗҶи§ЈпјҢеҸҜд»ҘжҠҠPodзңӢеҒҡдёҖдёӘе°Ҹзі»з»ҹпјҢе®№еҷЁеҪ“еҒҡзі»з»ҹдёӯзҡ„дёҚеҗҢиҝӣзЁӢ;еҶ…йғЁе®һзҺ°пјҡеҗҢPOD еҶ…зҡ„е®№еҷЁе®һйҷ…е…ұдә«еҗҢдёҖдёӘNamespaceпјҢеӣ жӯӨдҪҝз”ЁзӣёеҗҢзҡ„Ipе’ҢPortз©әй—ҙпјҢиҜҘNamespace жҳҜз”ұдёҖдёӘеҸ«Pauseзҡ„е°Ҹе®№еҷЁжқҘе®һзҺ°пјҢжҜҸеҪ“дёҖдёӘPodиў«еҲӣе»әпјҢйӮЈд№ҲйҰ–е…ҲеҲӣе»әдёҖдёӘpauseе®№еҷЁпјҢ д№ӢеҗҺиҝҷдёӘpodйҮҢйқўзҡ„е…¶д»–е®№еҷЁйҖҡиҝҮе…ұдә«иҝҷдёӘpauseе®№еҷЁзҡ„зҪ‘з»ңж ҲпјҢе®һзҺ°еӨ–йғЁpodиҝӣиЎҢйҖҡдҝЎ,еӣ жӯӨеҜ№дәҺеҗҢPodйҮҢйқўзҡ„жүҖжңүе®№еҷЁжқҘиҜҙпјҢ他们зңӢеҲ°зҡ„зҪ‘з»ңи§ҶеӣҫжҳҜдёҖж ·зҡ„пјҢжҲ‘们еңЁе®№еҷЁдёӯзңӢзҡ„ең°еқҖпјҢд№ҹе°ұжҳҜPodең°еқҖе®һйҷ…жҳҜPauseе®№еҷЁзҡ„IPең°еқҖгҖӮжҖ»дҪ“жЁЎеһӢеҰӮдёӢпјҡ
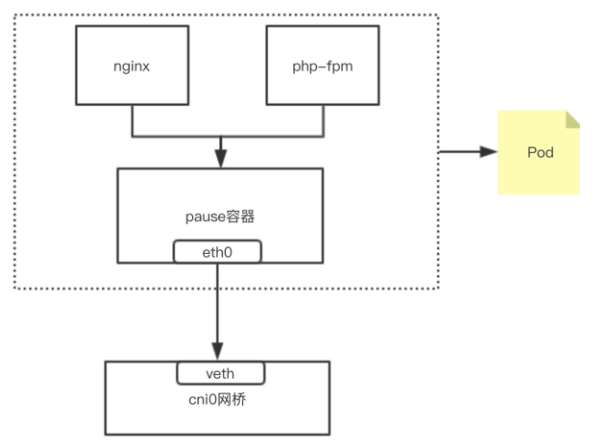
жҲ‘们еңЁnode иҠӮзӮ№жҹҘзңӢд№ӢеүҚеҲӣе»әзҡ„PODпјҢеҸҜд»ҘзңӢеҲ°иҜҘpauseе®№еҷЁ пјҡ
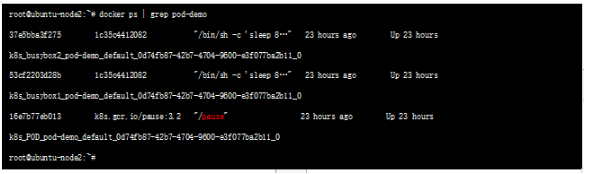
иҝҷз§Қж–°еҲӣе»әзҡ„е®№еҷЁе’Ңе·Із»ҸеӯҳеңЁзҡ„дёҖдёӘе®№еҷЁ(pause)е…ұдә«дёҖдёӘ Network Namespace(иҖҢдёҚжҳҜе’Ңе®ҝдё»жңәе…ұдә«) е°ұжҳҜжҲ‘们常иҜҙзҡ„container жЁЎејҸгҖӮ
жҜҸдёӘиҠӮзӮ№дёҠзҡ„жҜҸдёӘPodйғҪжңүиҮӘе·ұзҡ„namespaceпјҢеҗҢдё»жңәдёҠзҡ„PODд№Ӣй—ҙжҖҺд№ҲйҖҡдҝЎе‘ў?жҲ‘们еҸҜд»ҘеңЁдёӨдёӘPODд№Ӣй—ҙе»әз«ӢVet PairиҝӣиЎҢйҖҡдҝЎпјҢдҪҶеҰӮжһңжңүеӨҡдёӘе®№еҷЁпјҢдёӨдёӨе»әз«ӢVeth е°ұдјҡйқһеёёйә»зғҰпјҢеҒҮеҰӮжңүN дёӘPOD пјҢйӮЈд№ҲжҲ‘们йңҖиҰҒеҲӣе»әn(n-1)/2дёӘVeth PairпјҢжү©еұ•жҖ§йқһеёёе·®пјҢеҰӮжһңжҲ‘们еҸҜд»Ҙе°ҶиҝҷдәӣVeth Pair иҝһжҺҘеҲ°дёҖдёӘйӣҶдёӯзҡ„иҪ¬еҸ‘зӮ№пјҢз”ұе®ғжқҘз»ҹдёҖиҪ¬еҸ‘е°ұе°ұдјҡйқһеёёдҫҝжҚ·пјҢиҝҷдёӘйӣҶдёӯиҪ¬еҸ‘зӮ№е°ұжҳҜжҲ‘们常иҜҙзҡ„bridge;еҰӮдёӢжүҖзӨә(з®ҖеҚ•иө·и§ҒпјҢиҝҷйҮҢжҠҠpauseеҝҪз•Ҙ)пјҡ
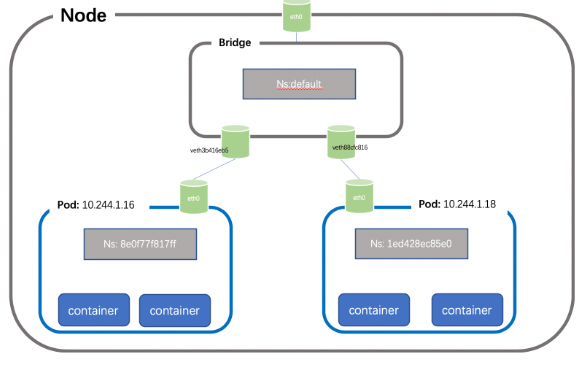
д»Қ然д»ҘжҲ‘们зҡ„жөӢиҜ•зҺҜеўғдёәдҫӢпјҢеҲӣе»әpod1 е’Ңpod2ең°еқҖеҲҶеҲ«дёәпјҡ10.244.1.16гҖҒ10.244.1.18пјҢдҪҚдәҺnode1 иҠӮзӮ№
жҹҘзңӢиҠӮзӮ№дёӢзҡ„namespaceпјҡ
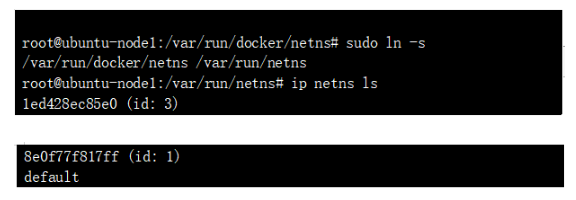
иҝҷдёӨдёӘNSе°ұжҳҜдёҠиҝ°дёӨдёӘPOD еҜ№еә”зҡ„namespaceпјҢжҹҘиҜўеҜ№еә”namespace дёӢзҡ„жҺҘеҸЈпјҡ
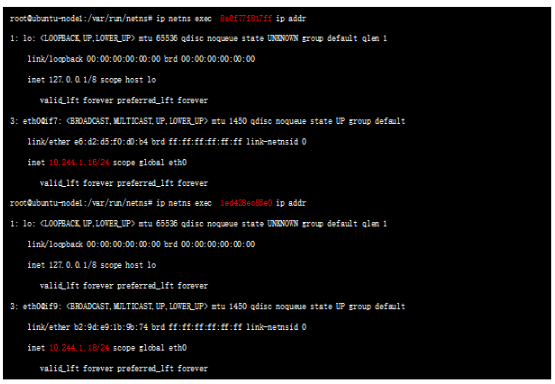
еҸҜд»ҘзңӢеҲ°ж ҮзәўеӨ„зҡ„ең°еқҖпјҢе®һйҷ…е°ұжҳҜPOD зҡ„ipең°еқҖ;NS е’ҢеҜ№еә”зҡ„POD ең°еқҖйғҪжүҫеҲ°дәҶпјҢйӮЈд№ҲеҰӮдҪ•зЎ®и®ӨиҝҷдёӨдёӘns дёӢзҡ„иҷҡжҺҘеҸЈзҡ„еҸҰдёҖз«Ҝе‘ў? жҜ”иҫғзӣҙи§Ӯзҡ„зЎ®и®Өж–№ејҸдёәпјҡдёҠиҝ°жҺҘеҸЈеҰӮ 3: eth0@if7пјҢиЎЁзӨәжң¬з«ҜжҺҘеҸЈid дёә3 пјҢеҜ№з«ҜжҺҘеҸЈidжҳҜ7пјҢжҲ‘们зңӢдёӢdefault namespace(жҲ‘们平时зңӢзҡ„й»ҳи®ӨйғҪеңЁdefaultдёӢ) зҡ„vethеҸЈпјҡ
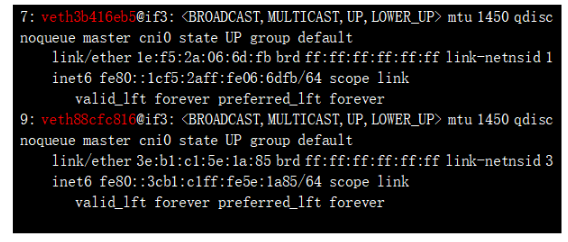
7: veth4b416eb5@if3 пјҢиҜҘжҺҘеҸЈзҡ„id жӯЈжҳҜжҲ‘们иҰҒжүҫзҡ„id дёә7зҡ„жҺҘеҸЈ пјҢжҳҜveth pairзҡ„еҸҰдёҖз«Ҝ;
з®ҖеҚ•жқҘзңӢпјҢеҜ№дәҺзҪ‘з»ңдёҠдёӨдёӘз«ҜзӮ№д№Ӣй—ҙзҡ„дә’йҖҡж— йқһдёӨз§Қж–№жЎҲпјҢдёҖз§ҚжҳҜunderlay зӣҙжҺҘдә’йҖҡпјҢйӮЈд№Ҳе°ұйңҖиҰҒеҸҢж–№жңүеҪјжӯӨзҡ„и·Ҝз”ұдҝЎжҒҜ并且иҜҘи·Ҝз”ұдҝЎжҒҜеңЁunderlayзҡ„и·Ҝеҫ„дёҠеӯҳеңЁпјҢдёҖз§ҚжҳҜoverlay ж–№жЎҲпјҢйҖҡиҝҮйҡ§йҒ“е®һзҺ°дә’йҖҡпјҢunderlay еұӮйқўдҝқиҜҒдё»жңәеҸҜиҫҫеҚіеҸҜ,еүҚиҖ…д»ЈиЎЁж–№жЎҲжңү Calico(directжЁЎејҸ)е’ҢMacvlanпјҢеҗҺиҖ…жңүOverlayпјҢOVSпјҢFlannelе’ҢWeaveгҖӮжҲ‘们еҸ–д»ЈиЎЁжҖ§зҡ„Flannel е’Ңcalico жҸ’件иҝӣиЎҢд»Ӣз»Қ;
2.3.1 Flannel
жҖ»дҪ“йҖҡдҝЎжөҒзЁӢеҰӮдёӢпјҡ
йҖҡдҝЎиҝҮзЁӢ
2.3.1.1ең°еқҖеҲҶй…Қ
flanneld第дёҖж¬ЎеҗҜеҠЁж—¶пјҢд»Һ etcd иҺ·еҸ–й…ҚзҪ®зҡ„ Pod зҪ‘ж®өдҝЎжҒҜпјҢдёәжң¬иҠӮзӮ№еҲҶй…ҚдёҖдёӘжңӘдҪҝз”Ёзҡ„ең°еқҖж®өпјҢ然еҗҺеҲӣе»ә flannedl.1 зҪ‘з»ңжҺҘеҸЈ(д№ҹеҸҜиғҪжҳҜе…¶е®ғеҗҚз§°пјҢеҰӮ flannel1 зӯү)пјҢflannel е°ҶеҲҶй…Қз»ҷиҮӘе·ұзҡ„ Pod зҪ‘ж®өдҝЎжҒҜеҶҷе…Ҙ /run/flannel/docker ж–Ү件(дёҚеҗҢk8sзүҲжң¬ж–Ү件еҗҚеӯҳеңЁе·®ејӮ)пјҢdocker еҗҺз»ӯдҪҝз”ЁиҝҷдёӘж–Ү件дёӯзҡ„зҺҜеўғеҸҳйҮҸи®ҫзҪ® docker0 зҪ‘жЎҘпјҢд»ҺиҖҢдҪҝиҝҷдёӘең°еқҖж®өдёәжң¬иҠӮзӮ№зҡ„жүҖжңү;
жҹҘзңӢflannel дёәdocker еҲҶй…Қзҡ„ең°еқҖж®өпјҡ

иЎЁзӨәиҜҘиҠӮзӮ№еҲӣе»әзҡ„POD ең°еқҖйғҪд»Һ10.244.1.1/24дёӯеҲҶй…ҚпјҢжҜ”еҰӮnode1 иҠӮзӮ№зҡ„еҰӮдёӢ2дёӘpodгҖӮ

2.3.1.2и·Ҝз”ұдёӢеҸ‘
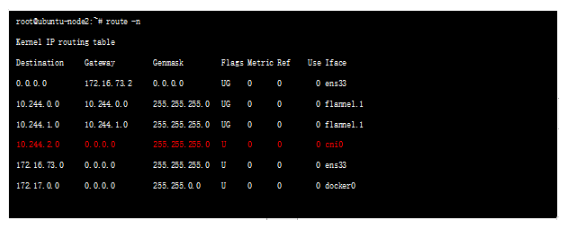
жҜҸеҸ°дё»жңәдёҠпјҢflannel иҝҗиЎҢдёҖдёӘdaemon иҝӣзЁӢеҸ«flanneldпјҢе®ғеҸҜд»ҘеңЁеҶ…ж ёдёӯеҲӣе»әи·Ҝз”ұиЎЁпјҢжҹҘзңӢnode1иҠӮзӮ№зҡ„и·Ҝз”ұиЎЁеҰӮдёӢпјҡ
еҸҜд»ҘзңӢеҲ°node2 иҠӮзӮ№зҡ„и·Ҝз”ұmatch 10.244.2.0 дёҖиЎҢ规еҲҷпјҢеҮәжҺҘеҸЈдёәflannel.1 еҸЈ(жҺҘеҸЈеҗҚflannelеҗҺж•°еӯ—еҸҜиғҪдёҚдёҖж ·) flannel.1 жҳҜflanneldзЁӢеәҸеҲӣе»әзҡ„дёҖдёӘйҡ§йҒ“еҸЈ;иҝҷйҮҢжңүдёҖдёӘй—®йўҳпјҢе°ұжҳҜеҰӮдҪ•еҲӨж–ӯйҡ§йҒ“жү“еҲ°йӮЈйҮҢе‘ўпјҢеҫҲжҳҫ然пјҢflannldеӯҳеӮЁдәҶзұ»дјје®№еҷЁ-зү©зҗҶиҠӮзӮ№д№Ӣй—ҙзҡ„жҳ е°„е…ізі»пјҢиҝҷз§ҚдҝЎжҒҜеӯҳж”ҫеңЁetcdйҮҢйқўпјҢflannldиҝӣзЁӢйҖҡиҝҮиҜ»еҸ–etcdдёӯзҡ„жҳ е°„е…ізі»дҝЎжҒҜпјҢеҶіе®ҡйҡ§йҒ“еӨ–еұӮе°ҒиЈ…гҖӮ
2.3.1.3ж•°жҚ®йқўе°ҒиЈ…
Flannel зҹҘйҒ“еӨ–еұӮе°ҒиЈ…ең°еқҖеҗҺпјҢеҜ№жҠҘж–ҮиҝӣиЎҢе°ҒиЈ…пјҢжәҗйҮҮз”ЁиҮӘе·ұзҡ„зү©зҗҶip ең°еқҖпјҢзӣ®зҡ„йҮҮз”ЁеҜ№з«Ҝзҡ„пјҢvxlan еӨ–еұӮзҡ„udp port 8472(еҰӮжһңжҳҜUDPе°ҒиЈ…дҪҝз”Ё8285дҪңдёәй»ҳи®Өзӣ®зҡ„з«ҜеҸЈпјҢдёӢж–ҮдјҡжҸҗеҲ°)пјҢеҜ№з«ҜеҸӘйңҖзӣ‘жҺ§port еҚіеҸҜпјҢеҪ“ж”№з«ҜеҸЈж”¶еҲ°жҠҘж–ҮеҗҺе°ҶжҠҘж–ҮйҖҒеҲ°flannedld иҝӣзЁӢпјҢиҝӣзЁӢе°ҶжҠҘж–ҮйҖҒеҲ°flanned жҺҘеҸЈжҺҘе°ҒиЈ…пјҢ然еҗҺжҹҘиҜўжң¬ең°и·Ҝз”ұиЎЁпјҡ
еҸҜд»ҘзңӢеҲ°зӣ®зҡ„ең°еқҖдёәcni0 ;FlannelеҠҹиғҪеҶ…йғЁж”ҜжҢҒдёүз§ҚдёҚеҗҢеҗҺз«Ҝе®һзҺ°пјҢеҲҶеҲ«жҳҜпјҡ
Host-gwпјҡйңҖиҰҒдёӨеҸ°host еңЁеҗҢдёҖзҪ‘ж®өпјҢдёҚж”ҜжҢҒи·ЁзҪ‘пјҢеӣ жӯӨдёҚйҖӮеҗҲеӨ§и§„жЁЎйғЁзҪІ
UDPпјҡдёҚе»әи®®дҪҝз”ЁпјҢйҷӨйқһеҶ…ж ёдёҚж”ҜжҢҒvxlan жҲ–иҖ…debuggж—¶еҖҷдҪҝз”ЁпјҢеҪ“еүҚд№ҹе·Із»Ҹеәҹејғ;
Vxlan : vxlan е°ҒиЈ…пјҢflannel дҪҝз”Ё vxlan жҠҖжңҜдёәеҗ„иҠӮзӮ№еҲӣе»әдёҖдёӘеҸҜд»Ҙдә’йҖҡзҡ„ Pod зҪ‘з»ңпјҢдҪҝз”Ёзҡ„з«ҜеҸЈдёә UDP 8472(йңҖиҰҒејҖж”ҫиҜҘз«ҜеҸЈпјҢеҰӮе…¬жңүдә‘ AWS зӯү)гҖӮ
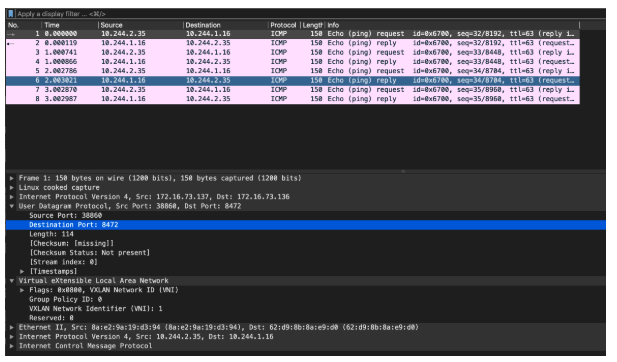
жҲ‘们еңЁnode иҠӮзӮ№иҝӣиЎҢжҠ“еҢ…йӘҢиҜҒдёҖдёӢпјҡ
(жіЁпјҡеӣ дёәеңЁlinux зҺҜеўғдёӯпјҢFlannelзҡ„vxlan е°ҒиЈ…дёӯUDP зӣ®зҡ„port жҳҜ 8472 пјҢж ҮеҮҶVxlan жҠҘж–Үзҡ„иҜҶеҲ«дҫқжҚ®жҳҜзӣ®зҡ„з«ҜеҸЈ4789пјҢеӣ жӯӨйңҖиҰҒжүӢеҠЁжҢҮе®ҡжҢүз…§vxlan жқҘи§ЈжһҗпјҢеҗҰеҲҷж— жі•иҜҶеҲ«еҶ…еұӮдҝЎжҒҜ)

2.3.2 CalicoCalicoж”ҜжҢҒ3з§Қи·Ҝз”ұжЁЎејҸпјҡ
Direct: и·Ҝз”ұиҪ¬еҸ‘пјҢжҠҘж–ҮдёҚеҒҡе°ҒиЈ…;
Ip-In-Ip:Calico й»ҳи®Өзҡ„и·Ҝз”ұжЁЎејҸ,ж•°жҚ®йқўйҮҮз”Ёipipе°ҒиЈ…;
Vxlanпјҡvxlan е°ҒиЈ…;
иҝҷйҮҢдё»иҰҒд»Ӣз»ҚDirectжЁЎејҸпјҢйҮҮз”ЁиҪҜи·Ҝз”ұе»әз«ӢBGP е®Је‘Ҡе®№еҷЁзҪ‘ж®ө,дҪҝеҫ—е…ЁзҪ‘жүҖжңүзҡ„Nodeе’ҢзҪ‘з»ңи®ҫеӨҮйғҪжңүеҲ°еҪјжӯӨзҡ„и·Ҝз”ұзҡ„дҝЎжҒҜпјҢ然еҗҺзӣҙжҺҘйҖҡиҝҮunderlay иҪ¬еҸ‘гҖӮCalicoе®һзҺ°зҡ„жҖ»дҪ“з»“жһ„еҰӮдёӢпјҡ

组件еҢ…еҗ«пјҡ
FelixпјҡCalico agentпјҡиҝҗиЎҢеңЁжҜҸеҸ°nodeдёҠпјҢдёәе®№еҷЁи®ҫзҪ®зҪ‘з»ңдҝЎжҒҜпјҡIP,и·Ҝз”ұ规еҲҷпјҢiptable规еҲҷзӯүBIRD:
BGP Clientпјҡзӣ‘еҗ¬ HostдёҠз”ұ Felix жіЁе…Ҙзҡ„и·Ҝз”ұдҝЎжҒҜпјҢ然еҗҺйҖҡиҝҮ BGP еҚҸи®®е№ҝж’ӯе‘ҠиҜүе…¶д»–HostиҠӮзӮ№пјҢд»ҺиҖҢе®һзҺ°зҪ‘з»ңдә’йҖҡ
BGP Route Reflectorпјҡ BGP peerе»әз«Ӣж–№ејҸеӨҡж ·пјҢеҸҜд»ҘеңЁnode д№Ӣй—ҙдёӨдёӨе»әз«Ӣbgp peer(й»ҳи®ӨжЁЎејҸ)пјҢе’Ңдј з»ҹibgp peerй—®йўҳзұ»дјјпјҢиҝҷдјҡеёҰжқҘn*(n-1)/2 зҡ„йӮ»еұ…йҮҸпјҢеӣ жӯӨд№ҹеҸҜд»ҘиҮӘе»әRR еҸҚе°„еҷЁ(дёҠеӣҫдёӯз»“жһ„)пјҢnode иҠӮзӮ№е’ҢRR е»әз«ӢpeerпјҢеҪ“然nodeд№ҹеҸҜд»Ҙе’ҢTor е»әpeerпјҢиҜҰз»Ҷзҡ„з»„зҪ‘и®Ёи®әеҸҜд»ҘеҸӮиҖғе®ҳзҪ‘пјҡ
https://docs.projectcalico.org/reference/architecture/design/l3-interconnect-fabric
Calicoctlпјҡ calicoе‘Ҫд»ӨиЎҢз®ЎзҗҶе·Ҙе…·гҖӮ
е…·дҪ“йҖүжӢ©е“Әз§Қpeerж–№ејҸжІЎжңүеӣәе®ҡж ҮеҮҶпјҢиҰҒйҖӮй…ҚжҖ»дҪ“зҪ‘з»ң规еҲ’пјҢеҸӘиҰҒжңҖз»ҲдҝқиҜҒе®№еҷЁзҪ‘з»ңеҸҜжӯЈзЎ®еҸ‘еёғеҲ°зү©зҗҶзҪ‘з»ңеҚіеҸҜ;
ж•°жҚ®йҖҡдҝЎзҡ„жөҒзЁӢдёәпјҡж•°жҚ®еҢ…е…Ҳд»Һvethи®ҫеӨҮеҜ№еҸҰдёҖеҸЈеҸ‘еҮәпјҢеҲ°иҫҫе®ҝдё»жңәдёҠзҡ„CaliејҖеӨҙзҡ„иҷҡжӢҹзҪ‘еҚЎдёҠпјҢеҲ°иҫҫиҝҷдёҖеӨҙд№ҹе°ұеҲ°иҫҫдәҶе®ҝдё»жңәдёҠзҡ„зҪ‘з»ңеҚҸи®®ж ҲпјҢ然еҗҺжҹҘиҜўи·Ҝз”ұиЎЁиҪ¬еҸ‘;еӣ дёәжң¬жңәйҖҡиҝҮbird е’ҢRR е»әз«Ӣbgp йӮ»еұ…е…ізі»пјҢдјҡе°Ҷжң¬ең°зҡ„е®№еҷЁең°еқҖеҸ‘йҖҒеҲ°RR д»ҺиҖҢеҸҚе°„еҲ°зҪ‘з»ңе…¶е®ғиҠӮзӮ№пјҢеҗҢж ·пјҢе…¶е®ғиҠӮзӮ№зҡ„зҪ‘з»ңең°еқҖд№ҹдјҡдј йҖҒеҲ°жң¬ең°пјҢ然еҗҺз”ұFelix иҝӣзЁӢиҝӣиЎҢз®ЎзҗҶ并дёӢеҸ‘еҲ°и·Ҝз”ұиЎЁдёӯпјҢжҠҘж–ҮеҢ№й…Қи·Ҝз”ұ规еҲҷеҗҺжӯЈеёёиҝӣиЎҢиҪ¬еҸ‘еҚіеҸҜ(е®һйҷ…иҝҳжңүеӨҚжқӮзҡ„iptables 规еҲҷпјҢиҝҷйҮҢдёҚеҒҡеұ•ејҖ)
дёӢйқўйҖҡиҝҮз®ҖеҚ•е®һйӘҢеӯҰд№ дёӢпјҡ
е…·дҪ“е®үиЈ…иҝҮзЁӢдёҚеҶҚи®Ёи®әпјҢеҸҜеҸӮиҖғе®ҳзҪ‘пјҡhttps://www.projectcalico.org/иҝӣиЎҢе®үиЈ…йғЁзҪІ;
NodeиҠӮзӮ№bgpй…ҚзҪ®еҰӮдёӢпјҡ
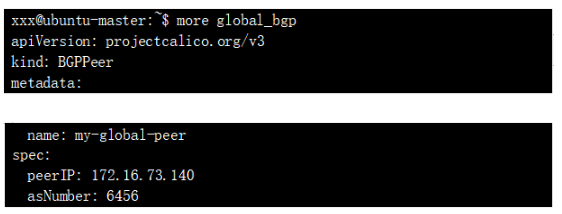
дёәдәҶз®ҖеҢ–е®һйӘҢпјҢжҲ‘们еҶҚеҗҜз”ЁдёҖеҸ°жңәеҷЁиҝҗиЎҢFRR жқҘе……еҪ“RR(е…ідәҺFrrеҸӮиҖғе®ҳзҪ‘https://frrouting.org/) пјҢRRй…ҚзҪ®еҰӮдёӢпјҡ
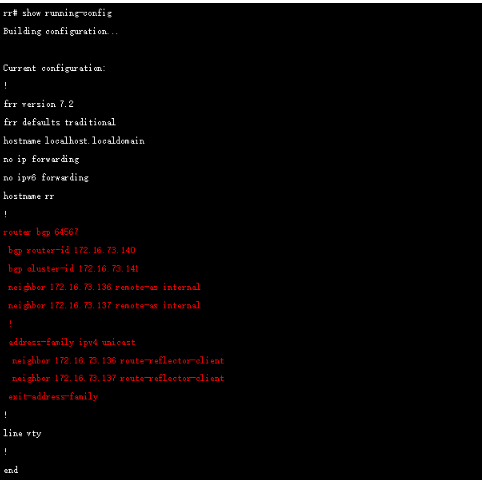
иҝҷж ·жүҖжңүиҠӮзӮ№йғҪе’ҢRR е»әз«ӢдәҶbgp йӮ»еұ…пјҢйҖҡиҝҮеҰӮдёӢж–№ејҸжЈҖжҹҘйӮ»еұ…зҠ¶жҖҒ:
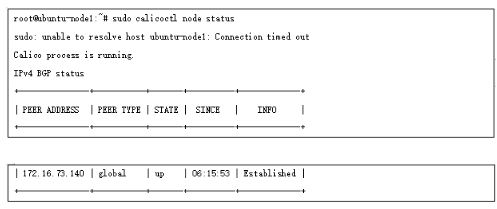
жҲ‘们新е»әдёӨдёӘpod пјҢеҲҶеҲ«дҪҚдәҺдёӨдёӘnodeиҠӮзӮ№пјҡ

й»ҳи®Өжғ…еҶөдёӢпјҢеҪ“зҪ‘з»ңдёӯеҮәзҺ°з¬¬дёҖдёӘе®№еҷЁпјҢcalicoдјҡдёәе®№еҷЁеҲҶй…ҚдёҖж®өеӯҗзҪ‘(еӯҗзҪ‘жҺ©з Ғ/26)пјҢеҗҺз»ӯеҮәзҺ°иҜҘиҠӮзӮ№дёҠзҡ„podйғҪд»ҺиҝҷдёӘеӯҗзҪ‘дёӯеҲҶй…Қipең°еқҖпјҢиҝҷж ·еҒҡзҡ„еҘҪеӨ„жҳҜиғҪеӨҹзј©еҮҸиҠӮзӮ№дёҠзҡ„и·Ҝз”ұиЎЁзҡ„规模.иҝӣе…Ҙе®№еҷЁжҹҘзңӢи·Ҝз”ұжҲ‘们еҸ‘зҺ°зҪ‘е…іең°еқҖдёә169.254.1.1
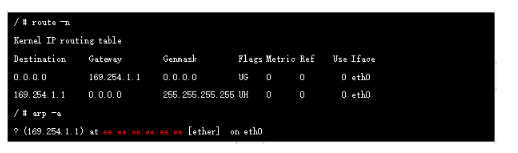
е®һйҷ…дёҠеңЁcalico зҪ‘з»ңдёӯпјҢе®№еҷЁзҪ‘е…іе§Ӣз»ҲжҳҜ169.254.1.1пјҢиҜҘең°еқҖеңЁе®һйҷ…зҪ‘з»ңдёӯдёҚеӯҳеңЁзҡ„пјҢжҳҜзӣҙжҺҘиҝӣиЎҢзҡ„ARP д»ЈзҗҶ(ee:ee:ee:ee:ee:ee)пјҢжҲ‘们еңЁеҲӣе»әPodзҡ„ж—¶еҖҷзі»з»ҹдјҡеңЁеҜ№еә”зҡ„node дёҠж–°еўһдёҖдёӘcaliејҖеӨҙзҡ„иҷҡжӢҹзҪ‘еҚЎпјҢе®ғе°ұжҳҜveth Pairзҡ„еҸҰдёҖз«Ҝ(жң¬з«ҜжҳҜе®№еҷЁжң¬ең°eth0еҸЈ)пјҢе®ғзҡ„mac е°ұжҳҜдёҠйқўзҡ„169.254.1.1 еҜ№еә”зҡ„macең°еқҖ
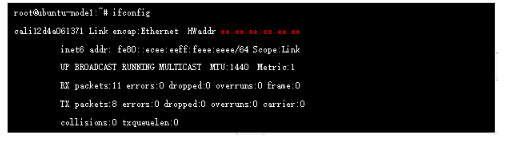
жӯӨж—¶зҡ„жҠҘж–Үе·Із»Ҹиҝӣе…Ҙdefault namespace пјҢиҝҷйҮҢејҖе§ӢжҹҘзңӢи·Ҝз”ұиЎЁпјҡ

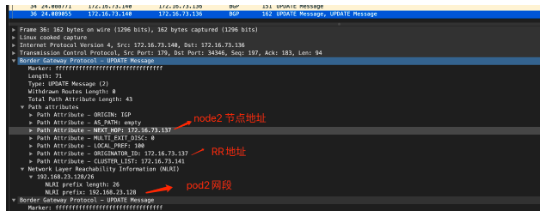
е…¶дёӯ192.168.23.128/26 жҳҜnode2дёҠзҡ„ең°еқҖз©әй—ҙпјҢиҜҘи·Ҝз”ұз”ұnode2 иҠӮзӮ№birdеҸ‘йҖҒеҲ°RRпјҢRR еҸҚе°„еҲ°node1иҠӮзӮ№зҡ„bird пјҢ然еҗҺз”ұfelixжқҘиҝӣиЎҢз®ЎзҗҶе’ҢдёӢеҸ‘еҲ°и·Ҝз”ұиЎЁдёӯпјҢжҲ‘们еҸҜд»ҘеңЁnode1иҠӮзӮ№жҠ“еҢ…иҝӣдёҖжӯҘзЎ®и®Өпјҡ
еҗҢж—¶еӣ дёәcalico зҡ„д»ЈзҗҶж–№ејҸпјҢдҪҝеҫ—еҗҢnodeзҡ„дёҚеҗҢPODйҖҡдҝЎд№ҹжҜ”иҫғзү№ж®ҠпјҢе®ғд№ҹжҳҜйҖҡиҝҮдёүеұӮиҪ¬еҸ‘жқҘе®һзҺ°пјҢжҜ”еҰӮnode2 иҠӮзӮ№зҡ„2дёӘең°еқҖпјҢеңЁи·Ҝз”ұиЎЁдёӯйғҪжҳҜ/32дҪҚеӯҳеңЁпјҢдёӢдёҖи·іжҺҘеҸЈдёәveth-pairзҡ„дёҖз«ҜпјҢеҸҰдёҖз«Ҝе°ұжҳҜеҜ№еә”зҡ„podеҶ…жҺҘеҸЈ;
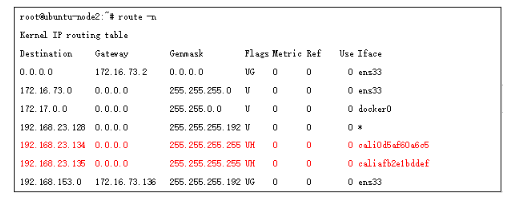
иҝҷе’Ңflannel з»ҸиҝҮbridge ж–№ејҸе®һзҺ°жҳҜдёҚдёҖж ·зҡ„;
2.3.3 жҖ»з»“
иҝҷйҮҢжҲ‘们д»ҺзҪ‘з»ңи§’еәҰеҜ№flannel е’Ңcalico иҝӣиЎҢз®ҖеҚ•еҜ№жҜ”пјҡ
жҖ»дҪ“жқҘзңӢпјҢеҜ№жҖ§иғҪж•Ҹж„ҹгҖҒзӯ–з•ҘйңҖжұӮиҫғй«ҳж—¶еҒҸеҗ‘дәҺCalioж–№жЎҲпјҢеҗҰеҲҷзҡ„иҜқпјҢйҮҮз”ЁFlannelдјҡжҳҜжӣҙеҘҪзҡ„йҖүжӢ©;
Serice е’ҢеӨ–йғЁйҖҡдҝЎеңәжҷҜе®һзҺ°ж¶үеҸҠиҫғеӨҡiptables иҪ¬еҸ‘еҺҹзҗҶпјҢйҷҗдәҺзҜҮе№…иҝҷйҮҢдёҚеҶҚеұ•ејҖпјҢз®ҖеҚ•д»Ӣз»ҚеҰӮдёӢпјҡ
PodдёҺserviceйҖҡдҝЎпјҡ Podй—ҙеҸҜд»ҘзӣҙжҺҘйҖҡиҝҮIPең°еқҖйҖҡдҝЎпјҢдҪҶеүҚжҸҗжҳҜPodзҹҘйҒ“еҜ№ж–№зҡ„IPгҖӮеңЁ KubernetesйӣҶзҫӨдёӯпјҢPodеҸҜиғҪдјҡйў‘з№Ғең°й”ҖжҜҒе’ҢеҲӣе»әпјҢд№ҹе°ұжҳҜиҜҙPodзҡ„IP дёҚжҳҜеӣәе®ҡзҡ„гҖӮдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢServiceжҸҗдҫӣдәҶи®ҝй—®Podзҡ„жҠҪиұЎеұӮгҖӮ ж— и®әеҗҺз«Ҝзҡ„PodеҰӮдҪ•еҸҳеҢ–пјҢServiceйғҪдҪңдёәзЁіе®ҡзҡ„еүҚз«ҜеҜ№еӨ–жҸҗдҫӣжңҚеҠЎгҖӮ еҗҢж—¶пјҢServiceиҝҳжҸҗдҫӣдәҶй«ҳеҸҜз”Ёе’ҢиҙҹиҪҪеқҮиЎЎеҠҹиғҪпјҢServiceиҙҹиҙЈе°ҶиҜ·жұӮиҪ¬ з»ҷжӯЈзЎ®зҡ„Pod;
еӨ–йғЁйҖҡдҝЎпјҡж— и®әжҳҜPodзҡ„IPиҝҳжҳҜServiceзҡ„Cluster IPпјҢе®ғ们еҸӘиғҪеңЁKubernetesйӣҶзҫӨдёӯеҸҜи§ҒпјҢеҜ№йӣҶзҫӨд№ӢеӨ–зҡ„дё–з•ҢпјҢиҝҷдәӣIPйғҪжҳҜз§Ғжңүзҡ„KubernetesжҸҗдҫӣдәҶдёӨз§Қж–№ејҸи®©еӨ–з•ҢиғҪеӨҹдёҺPodйҖҡдҝЎ:
NodePortпјҡServiceйҖҡиҝҮClusterиҠӮзӮ№зҡ„йқҷжҖҒз«ҜеҸЈеҜ№еӨ–жҸҗдҫӣжңҚеҠЎпјҢ еӨ–йғЁеҸҜд»ҘйҖҡиҝҮ:и®ҝй—®ServiceгҖӮ
LoadBalancerпјҡServiceеҲ©з”Ёcloud providerжҸҗдҫӣзҡ„load balancerеҜ№еӨ–жҸҗдҫӣжңҚеҠЎпјҢcloud providerиҙҹиҙЈе°Ҷload balancer зҡ„жөҒйҮҸеҜјеҗ‘ServiceгҖӮзӣ®еүҚж”ҜжҢҒзҡ„cloud providerжңүGCPгҖҒAWSгҖҒ AzurзӯүгҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№ҲзҗҶи§ЈKubernetesе®№еҷЁзҪ‘з»ңжЁЎеһӢвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№ҲзҗҶи§ЈKubernetesе®№еҷЁзҪ‘з»ңжЁЎеһӢиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ