жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚHTTPдёӯжңүе“Әдәӣ规иҢғпјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
1.Referer
HTTP ж ҮеҮҶжҠҠ Referrer еҶҷжҲҗ RefererпјҲе°‘дәӣдәҶдёҖдёӘ rпјүпјҢеҸҜд»ҘиҜҙжҳҜи®Ўз®—жңәеҺҶеҸІдёҠжңҖи‘—еҗҚзҡ„дёҖдёӘй”ҷеҲ«еӯ—дәҶгҖӮ
Referer зҡ„дё»иҰҒдҪңз”ЁжҳҜжҗәеёҰеҪ“еүҚиҜ·жұӮзҡ„жқҘжәҗең°еқҖпјҢеёёз”ЁеңЁеҸҚзҲ¬иҷ«е’ҢйҳІзӣ—й“ҫдёҠгҖӮеүҚж®өж—¶й—ҙй—№зҡ„жІёжІёжү¬жү¬зҡ„ж–°жөӘеӣҫеәҠжҢӮеӣҫдәӢ件пјҢе°ұжҳҜеӣ дёәж–°жөӘеӣҫеәҠзӘҒ然ејҖе§ӢжЈҖжҹҘ HTTP Referer еӨҙпјҢйқһж–°жөӘеҹҹеҗҚе°ұдёҚиҝ”еӣһеӣҫзүҮпјҢеҜјиҮҙеҫҲеӨҡи№ӯжөҒйҮҸзҡ„дёӯе°ҸеҚҡе®ўеӣҫйғҪжҢӮдәҶгҖӮ
иҷҪ然 HTTP ж ҮеҮҶйҮҢжҠҠ Referer еҶҷй”ҷдәҶпјҢдҪҶжҳҜе…¶е®ғеҸҜд»ҘжҺ§еҲ¶ Referer зҡ„ж ҮеҮҶ并没жңүе°Ҷй”ҷе°ұй”ҷгҖӮ
дҫӢеҰӮзҰҒжӯўзҪ‘йЎөиҮӘеҠЁжҗәеёҰ Referer еӨҙзҡ„ <meta> ж ҮзӯҫпјҢзӣёе…іе…ій”®еӯ—жӢјеҶҷе°ұжҳҜжӯЈзЎ®зҡ„пјҡ
<!-- е…ЁеұҖзҰҒжӯўеҸ‘йҖҒ referrer --> <meta name="referrer" content="no-referrer" />
иҝҳжңүдёҖдёӘеҖјеҫ—жіЁж„Ҹзҡ„жҳҜжөҸи§ҲеҷЁзҡ„зҪ‘з»ңиҜ·жұӮгҖӮд»Һе®үе…ЁжҖ§е’ҢзЁіе®ҡжҖ§дёҠиҖғиҷ‘пјҢReferer зӯүиҜ·жұӮеӨҙеңЁзҪ‘з»ңиҜ·жұӮж—¶пјҢеҸӘиғҪз”ұжөҸи§ҲеҷЁжҺ§еҲ¶пјҢдёҚиғҪзӣҙжҺҘж“ҚдҪңпјҢжҲ‘们еҸӘиғҪйҖҡиҝҮдёҖдәӣеұһжҖ§иҝӣиЎҢжҺ§еҲ¶гҖӮжҜ”еҰӮиҜҙ Fetch еҮҪж•°пјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮ referrer е’Ң referrerPolicy жҺ§еҲ¶пјҢиҖҢе®ғ们зҡ„жӢјеҶҷд№ҹжҳҜжӯЈзЎ®зҡ„пјҡ
fetch('/page', { headers: { "Content-Type": "text/plain;charset=UTF-8" }, referrer: "https://demo.com/anotherpage", // <- referrerPolicy: "no-referrer-when-downgrade", // <- });дёҖеҸҘиҜқжҖ»з»“пјҡ
еҮЎжҳҜж¶үеҸҠеҲ° Referrer зҡ„пјҢйҷӨдәҶ HTTP еӯ—ж®өжҳҜй”ҷзҡ„пјҢжөҸи§ҲеҷЁзҡ„зӣёе…ій…ҚзҪ®еӯ—ж®өжӢјеҶҷйғҪжҳҜжӯЈзЎ®зҡ„гҖӮ
дәҢ.гҖҢзҒөејӮгҖҚзҡ„з©әж ј
1.%20 иҝҳжҳҜ + пјҹ
иҝҷдёӘжҳҜдёӘеҸІиҜ—зә§зҡ„еӨ§еқ‘пјҢжҲ‘жӣҫз»Ҹиў«иҝҷдёӘеҚҸи®®еҶІзӘҒеқ‘дәҶдёҖеӨ©гҖӮ
ејҖе§Ӣи®Іи§ЈеүҚе…ҲзңӢдёӘе°ҸжөӢиҜ•пјҢеңЁжөҸи§ҲеҷЁйҮҢиҫ“е…Ҙ blank testпјҲ blank е’Ң test й—ҙжңүдёӘз©әж јпјүпјҢжҲ‘们зңӢзңӢжөҸи§ҲеҷЁеҰӮдҪ•еӨ„зҗҶзҡ„пјҡ

д»ҺеҠЁеӣҫеҸҜд»ҘзңӢеҮәжөҸи§ҲеҷЁжҠҠз©әж ји§ЈжһҗдёәдёҖдёӘеҠ еҸ·гҖҢ+гҖҚгҖӮ
жҳҜдёҚжҳҜж„ҹи§үжңүдәӣеҘҮжҖӘпјҹжҲ‘们еҶҚеҒҡдёӘжөӢиҜ•пјҢз”ЁжөҸи§ҲеҷЁжҸҗдҫӣзҡ„еҮ дёӘеҮҪж•°иҜ•дёҖдёӢпјҡ
encodeURIComponent("blank test") // "blank%20test" encodeURI("q=blank test") // "q=blank%20test" new URLSearchParams("q=blank test").toString() // "q=blank+test"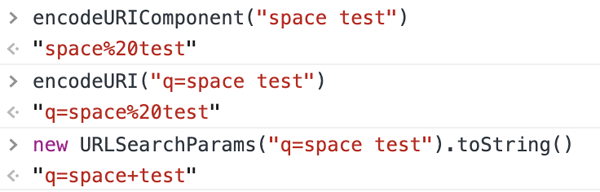
д»Јз ҒжҳҜдёҚдјҡиҜҙи°Һзҡ„пјҢе…¶е®һдёҠйқўзҡ„з»“жһңйғҪжҳҜжӯЈзЎ®зҡ„пјҢencode з»“жһңдёҚдёҖж ·пјҢжҳҜеӣ дёә URI 规иҢғе’Ң W3C 规иҢғеҶІзӘҒдәҶпјҢжүҚдјҡжҗһеҮәиҝҷз§Қи®©дәәз–‘жғ‘зҡ„д№ҢйҫҷдәӢ件гҖӮ
2.еҶІзӘҒзҡ„еҚҸи®®
жҲ‘们йҰ–е…ҲзңӢзңӢ URI дёӯзҡ„дҝқз•ҷеӯ—пјҢиҝҷдәӣдҝқз•ҷеӯ—дёҚеҸӮдёҺзј–з ҒгҖӮдҝқз•ҷеӯ—з¬ҰдёҖе…ұжңүдёӨеӨ§зұ»пјҡ
gen-delimsпјҡ: / ? # [ ] @
sub-delimsпјҡ! $ & ' ( ) * + , ; =
URI зҡ„зј–з Ғ规еҲҷд№ҹеҫҲз®ҖеҚ•пјҢе…ҲжҠҠйқһйҷҗе®ҡиҢғеӣҙзҡ„еӯ—з¬ҰиҪ¬дёә 16 иҝӣеҲ¶пјҢ然еҗҺеүҚйқўеҠ зҷҫеҲҶеҸ·гҖӮ
з©әж јиҝҷз§ҚдёҚе®үе…Ёеӯ—з¬ҰиҪ¬дёәеҚҒе…ӯиҝӣеҲ¶е°ұжҳҜ 0x20пјҢеүҚйқўеҶҚеҠ дёҠзҷҫеҲҶеҸ· % е°ұжҳҜ %20пјҡ
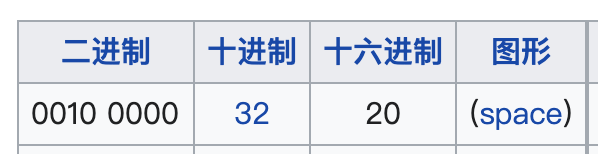
жүҖд»Ҙиҝҷж—¶еҖҷеҶҚзңӢ encodeURIComponent е’Ң encodeURI зҡ„зј–з Ғз»“жһңпјҢе°ұжҳҜе®Ңе…ЁжӯЈзЎ®зҡ„гҖӮ
既然з©әж јиҪ¬дёә%20 жҳҜжӯЈзЎ®зҡ„пјҢйӮЈиҪ¬дёә + жҳҜжҖҺд№ҲеӣһдәӢпјҹиҝҷж—¶еҖҷжҲ‘们е°ұиҰҒдәҶи§ЈдёҖдёӢ HTML form иЎЁеҚ•зҡ„еҺҶеҸІгҖӮ
ж—©жңҹзҡ„зҪ‘йЎөжІЎжңү AJAX зҡ„ж—¶еҖҷпјҢжҸҗдәӨж•°жҚ®йғҪжҳҜйҖҡиҝҮ HTML зҡ„ form иЎЁеҚ•гҖӮform иЎЁеҚ•зҡ„жҸҗдәӨж–№жі•еҸҜд»Ҙз”Ё GET д№ҹеҸҜд»Ҙз”Ё POSTпјҢеӨ§е®¶еҸҜд»ҘеңЁ MDN form иҜҚжқЎдёҠжөӢиҜ•пјҡ
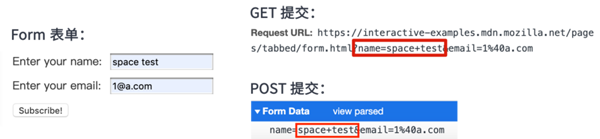
з»ҸиҝҮжөӢиҜ•жҲ‘们еҸҜд»ҘзңӢеҮәиЎЁеҚ•жҸҗдәӨзҡ„еҶ…е®№дёӯпјҢз©әж јйғҪжҳҜиҪ¬дёәеҠ еҸ·зҡ„пјҢиҝҷз§Қзј–з Ғзұ»еһӢе°ұжҳҜ application/x-www-form-urlencodedпјҢеңЁ WHATWG 规иҢғйҮҢжҳҜиҝҷж ·е®ҡд№үзҡ„пјҡ

еҲ°иҝҷйҮҢеҹәжң¬дёҠе°ұз ҙжЎҲдәҶпјҢURLSearchParams еҒҡ encode зҡ„ж—¶еҖҷпјҢе°ұжҢүиҝҷдёӘ规иҢғжқҘзҡ„гҖӮжҲ‘жүҫеҲ°дәҶ URLSearchParams зҡ„ Polyfill д»Јз ҒпјҢйҮҢйқўе°ұеҒҡдәҶ %20 еҲ° + зҡ„жҳ е°„пјҡ
replace = { '!': '%21', "'": '%27', '(': '%28', ')': '%29', '~': '%7E', '%20': '+', // <= е°ұжҳҜиҝҷдёӘ '%00': '\x00' }规иҢғйҮҢеҜ№иҝҷдёӘзј–з Ғзұ»еһӢиҝҳжңүи§ЈйҮҠиҜҙжҳҺпјҡ
The application/x-www-form-urlencoded format is in many ways an aberrant monstrosity, the result of many years of implementation accidents and compromises leading to a set of requirements necessary for interoperability, but in no way representing good design practices. In particular, readers are cautioned to pay close attention to the twisted details involving repeated (and in some cases nested) conversions between character encodings and byte sequences. Unfortunately the format is in widespread use due to the prevalence of HTML forms.
иҝҷз§Қзј–з Ғж–№ејҸе°ұдёҚжҳҜдёӘеҘҪзҡ„и®ҫи®ЎпјҢдёҚе№ёзҡ„жҳҜйҡҸзқҖ HTML form иЎЁеҚ•зҡ„жҷ®еҸҠпјҢиҝҷз§Қж јејҸе·Із»ҸжҺЁе№ҝејҖдәҶ
е…¶е®һдёҠйқўдёҖеӨ§ж®өеҸҘиҜқе°ұжҳҜдёҖдёӘж„ҸжҖқпјҡиҝҷзҺ©ж„Ҹе„ҝи®ҫи®Ўзҡ„е°ұжҳҜ ?пјҢдҪҶз§ҜйҮҚйҡҫиҝ”пјҢеӨ§е®¶иҝҳжҳҜеҝҚдёҖдёӢеҗ§
3.дёҖеҸҘиҜқжҖ»з»“
URI 规иҢғйҮҢпјҢз©әж ј encode дёә %20пјҢ application/x-www-form-urlencoded ж јејҸйҮҢпјҢз©әж ј encode дёә +
е®һйҷ…дёҡеҠЎејҖеҸ‘ж—¶пјҢжңҖеҘҪдҪҝз”ЁдёҡеҶ…жҲҗзҶҹзҡ„ HTTP иҜ·жұӮеә“е°ҒиЈ…иҜ·жұӮпјҢиҝҷдәӣжқӮжҙ»е„ҝзҙҜжҙ»е„ҝжЎҶжһ¶йғҪе№ІдәҶпјӣ
еҰӮжһңйқһиҰҒдҪҝз”ЁеҺҹз”ҹ AJAX жҸҗдәӨ application/x-www-form-urlencoded ж јејҸзҡ„ж•°жҚ®пјҢдёҚиҰҒжүӢеҠЁжӢјжҺҘеҸӮж•°пјҢиҰҒз”Ё URLSearchParams еӨ„зҗҶж•°жҚ®пјҢиҝҷж ·еҸҜд»ҘйҒҝе…Қеҗ„з§ҚжҒ¶еҝғзҡ„зј–з ҒеҶІзӘҒгҖӮ
дёү.X-Forwarded-For жӢҝеҲ°зҡ„е°ұжҳҜзңҹе®һ IP еҗ—пјҹ
1.ж•…дәӢ
еңЁиҝҷдёӘе°ҸиҠӮејҖе§ӢеүҚпјҢжҲ‘е…Ҳи®ІдёҖдёӘејҖеҸ‘дёӯзҡ„е°Ҹж•…дәӢпјҢеҸҜд»ҘеҠ ж·ұдёҖдёӢеӨ§е®¶еҜ№иҝҷдёӘеӯ—ж®өзҡ„зҗҶи§ЈгҖӮ
еүҚж®өж—¶й—ҙиҰҒеҒҡдёҖдёӘе’ҢйЈҺжҺ§зӣёе…ізҡ„йңҖжұӮпјҢйңҖиҰҒжӢҝеҲ°з”ЁжҲ·зҡ„ IPпјҢејҖеҸ‘еҗҺзҒ°еәҰдәҶдёҖе°ҸйғЁеҲҶз”ЁжҲ·пјҢжөӢиҜ•еҸ‘зҺ°еҗҺеҸ°ж—Ҙеҝ—йҮҢзҒ°еәҰзҡ„з”ЁжҲ· IP е…ЁжҳҜејӮеёёзҡ„пјҢе“Әжңүиҝҷд№Ҳе·§зҡ„дәӢжғ…гҖӮйҡҸеҗҺжөӢиҜ•еҸ‘иҝҮжқҘеҮ дёӘејӮеёё IPпјҡ
10.148.2.122 10.135.2.38 10.149.12.33 ...
дёҖзңӢ IP зү№еҫҒжҲ‘е°ұжҳҺзҷҪдәҶпјҢиҝҷеҮ дёӘ IP йғҪжҳҜ 10 ејҖеӨҙзҡ„пјҢеұһдәҺ A зұ» IP зҡ„з§Ғжңү IP иҢғеӣҙпјҲ10.0.0.0-10.255.255.255пјүпјҢеҗҺз«ҜжӢҝеҲ°зҡ„иӮҜе®ҡжҳҜд»ЈзҗҶжңҚеҠЎеҷЁзҡ„ IPпјҢиҖҢдёҚжҳҜз”ЁжҲ·зҡ„зңҹе®һ IPгҖӮ
2.еҺҹзҗҶ
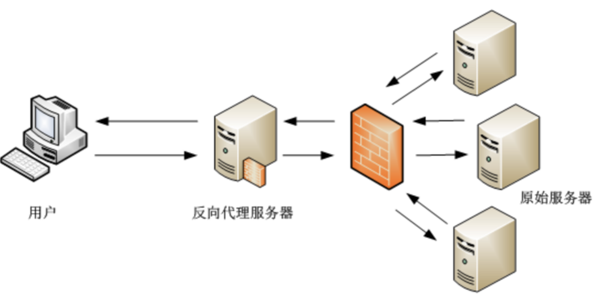
зҺ°еңЁжңүдәӣ规模зҡ„зҪ‘з«ҷеҹәжң¬йғҪдёҚжҳҜеҚ•зӮ№ Server дәҶпјҢдёәдәҶеә”еҜ№жӣҙй«ҳзҡ„жөҒйҮҸе’ҢжӣҙзҒөжҙ»зҡ„жһ¶жһ„пјҢеә”з”ЁжңҚеҠЎдёҖиҲ¬йғҪжҳҜйҡҗи—ҸеңЁд»ЈзҗҶжңҚеҠЎеҷЁд№ӢеҗҺзҡ„пјҢжҜ”еҰӮиҜҙ NginxгҖӮ
еҠ е…ҘжҺҘе…ҘеұӮеҗҺпјҢжҲ‘们е°ұиғҪжҜ”иҫғе®№жҳ“зҡ„е®һзҺ°еӨҡеҸ°жңҚеҠЎеҷЁзҡ„иҙҹиҪҪеқҮиЎЎе’ҢжңҚеҠЎеҚҮзә§пјҢеҪ“然иҝҳжңүе…¶д»–зҡ„еҘҪеӨ„пјҢжҜ”еҰӮиҜҙжӣҙеҘҪзҡ„еҶ…е®№зј“еӯҳе’Ңе®үе…ЁйҳІжҠӨпјҢдёҚиҝҮиҝҷдәӣдёҚжҳҜжң¬ж–Үзҡ„йҮҚзӮ№е°ұдёҚеұ•ејҖдәҶгҖӮ
зҪ‘з«ҷеҠ е…Ҙд»ЈзҗҶжңҚеҠЎеҷЁеҗҺпјҢйҷӨдәҶдёҠйқўзҡ„еҮ дёӘдјҳзӮ№пјҢеҗҢж—¶еј•е…ҘдәҶдёҖдәӣж–°зҡ„й—®йўҳгҖӮжҜ”еҰӮиҜҙд№ӢеүҚзҡ„еҚ•зӮ№ ServerпјҢжңҚеҠЎеҷЁжҳҜеҸҜд»ҘзӣҙжҺҘжӢҝеҲ°з”ЁжҲ·зҡ„ IP зҡ„пјҢеҠ е…Ҙд»ЈзҗҶеұӮеҗҺпјҢеҰӮдёҠеӣҫжүҖзӨәпјҢпјҲеә”з”ЁпјүеҺҹе§ӢжңҚеҠЎеҷЁжӢҝеҲ°зҡ„жҳҜд»ЈзҗҶжңҚеҠЎеҷЁзҡ„ IPпјҢжҲ‘еүҚйқўи®Ізҡ„ж•…дәӢзҡ„й—®йўҳе°ұеҮәеңЁиҝҷйҮҢгҖӮ
Web ејҖеҸ‘иҝҷд№ҲжҲҗзҶҹзҡ„йўҶеҹҹпјҢиӮҜе®ҡжҳҜжңүзҺ°жҲҗзҡ„и§ЈеҶіеҠһжі•зҡ„пјҢйӮЈе°ұжҳҜ X-Forwarded-For иҜ·жұӮеӨҙгҖӮ
X-Forwarded-For жҳҜдёҖдёӘдәӢе®һж ҮеҮҶпјҢиҷҪ然没жңүеҶҷе…Ҙ HTTP RFC 规иҢғйҮҢпјҢд»Һжҷ®еҸҠзЁӢеәҰдёҠзңӢе…¶е®һеҸҜд»Ҙз®— HTTP 规иҢғдәҶгҖӮ
иҝҷдёӘж ҮеҮҶжҳҜиҝҷж ·е®ҡд№үзҡ„пјҢжҜҸж¬Ўд»ЈзҗҶжңҚеҠЎеҷЁиҪ¬еҸ‘иҜ·жұӮеҲ°дёӢдёҖдёӘжңҚеҠЎеҷЁж—¶пјҢиҰҒжҠҠд»ЈзҗҶжңҚеҠЎеҷЁзҡ„ IP еҶҷе…Ҙ X-Forwarded-For дёӯпјҢиҝҷж ·еңЁжңҖжң«з«Ҝзҡ„еә”з”ЁжңҚеҠЎж”¶еҲ°иҜ·жұӮж—¶пјҢе°ұдјҡеҫ—еҲ°дёҖдёӘ IP еҲ—иЎЁпјҡ
X-Forwarded-For: client, proxy1, proxy2
еӣ дёә IP жҳҜдёҖдёӘдёҖдёӘдҫқж¬Ў push иҝӣеҺ»зҡ„пјҢйӮЈд№Ҳ第дёҖдёӘ IP е°ұжҳҜз”ЁжҲ·зҡ„зңҹе®һ IPпјҢеҸ–жқҘз”Ёе°ұеҘҪдәҶгҖӮ
дҪҶжҳҜпјҢдәӢе®һжңүиҝҷд№Ҳз®ҖеҚ•еҗ—пјҹ
3.ж”»еҮ»
д»Һе®үе…Ёзҡ„и§’еәҰдёҠиҖғиҷ‘пјҢж•ҙдёӘзі»з»ҹжңҖдёҚе®үе…Ёзҡ„е°ұжҳҜдәәпјҢз”ЁжҲ·з«ҜйғҪжҳҜжңҖеҘҪж”»з ҙжңҖеҘҪдјӘйҖ зҡ„гҖӮжңүдәӣз”ЁжҲ·е°ұејҖе§Ӣй’»еҚҸи®®зҡ„жјҸжҙһпјҡX-Forwarded-For жҳҜд»ЈзҗҶжңҚеҠЎеҷЁж·»еҠ зҡ„пјҢеҰӮжһңжҲ‘дёҖејҖе§ӢиҜ·жұӮзҡ„ Header еӨҙйҮҢе°ұеҠ дәҶ X-Forwarded-For пјҢдёҚе°ұйӘ—иҝҮжңҚеҠЎеҷЁдәҶеҗ—пјҹ
1. йҰ–е…Ҳд»Һе®ўжҲ·з«ҜеҸ‘еҮәиҜ·жұӮпјҢеёҰжңү X-Forwarded-For иҜ·жұӮеӨҙпјҢйҮҢйқўеҶҷдёҖдёӘдјӘйҖ зҡ„ IPпјҡ
X-Forwarded-For: fakeIP
2. жңҚеҠЎз«Ҝ第дёҖеұӮд»ЈзҗҶжңҚеҠЎж”¶еҲ°иҜ·жұӮпјҢеҸ‘зҺ°е·Із»Ҹжңү X-Forwarded-ForпјҢиҜҜжҠҠиҝҷдёӘиҜ·жұӮеҪ“жҲҗд»ЈзҗҶжңҚеҠЎеҷЁпјҢдәҺжҳҜеҗ‘иҝҷдёӘеӯ—ж®өиҝҪеҠ дәҶе®ўжҲ·з«Ҝзҡ„зңҹе®һ IPпјҡ
X-Forwarded-For: fakeIP, client
3. з»ҸиҝҮеҮ еұӮд»ЈзҗҶеҗҺпјҢжңҖз»Ҳзҡ„жңҚеҠЎеҷЁжӢҝеҲ°зҡ„ Header жҳҜиҝҷж ·зҡ„пјҡ
X-Forwarded-For: fakeIP, client, proxy1, proxy2
иҰҒжҳҜжҢүз…§еҸ– X-Forwarded-For 第дёҖдёӘ IP зҡ„жҖқи·ҜпјҢдҪ е°ұзқҖдәҶж”»еҮ»иҖ…зҡ„йҒ“дәҶпјҢдҪ жӢҝеҲ°зҡ„жҳҜ fakeIPпјҢиҖҢдёҚжҳҜ client IPгҖӮ
4.з ҙжӢӣ
жңҚеҠЎз«ҜеҰӮдҪ•з ҙжӢӣпјҹдёҠйқўдёүдёӘжӯҘйӘӨпјҡ
第дёҖжӯҘжҳҜе®ўжҲ·з«ҜйҖ еҒҮпјҢжңҚеҠЎеҷЁж— жі•д»Ӣе…Ҙ
第дәҢжӯҘжҳҜд»ЈзҗҶжңҚеҠЎеҷЁпјҢеҸҜжҺ§пјҢеҸҜйҳІиҢғ
第дёүжӯҘжҳҜеә”з”ЁжңҚеҠЎеҷЁпјҢеҸҜжҺ§пјҢеҸҜйҳІиҢғ
第дәҢжӯҘзҡ„з ҙжӢӣжҲ‘жӢҝ Nginx жңҚеҠЎеҷЁдёҫдҫӢгҖӮ
жҲ‘们еңЁжңҖеӨ–еұӮзҡ„ Nginx дёҠпјҢеҜ№ X-Forwarded-For зҡ„й…ҚзҪ®еҰӮдёӢпјҡ
proxy_set_header X-Forwarded-For $remote_addr;
д»Җд№Ҳж„ҸжҖқе‘ўпјҹе°ұжҳҜжңҖеӨ–еұӮд»ЈзҗҶжңҚеҠЎеҷЁдёҚдҝЎд»»е®ўжҲ·з«Ҝзҡ„ X-Forwarded-For иҫ“е…ҘпјҢзӣҙжҺҘиҰҶзӣ–пјҢиҖҢдёҚжҳҜиҝҪеҠ гҖӮ
йқһжңҖеӨ–еұӮзҡ„ Nginx жңҚеҠЎеҷЁпјҢжҲ‘们й…ҚзҪ®пјҡ
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
$proxy_add_x_forwarded_for е°ұжҳҜиҝҪеҠ IP зҡ„ж„ҸжҖқгҖӮйҖҡиҝҮиҝҷжӢӣпјҢе°ұеҸҜд»Ҙз ҙйҷӨз”ЁжҲ·з«Ҝзҡ„дјӘйҖ еҠһжі•гҖӮ
第дёүжӯҘзҡ„з ҙжӢӣжҖқи·Ҝд№ҹеҫҲе®№жҳ“пјҢжӯЈеёёжҖқи·ҜжҲ‘们жҳҜеҸ–X-Forwarded-For жңҖе·Ұдҫ§зҡ„ IPпјҢиҝҷж¬ЎжҲ‘们еҸҚе…¶йҒ“иҖҢиЎҢд№ӢпјҢд»ҺеҸіиҫ№ж•°пјҢеҮҸеҺ»д»ЈзҗҶжңҚеҠЎеҷЁзҡ„ж•°зӣ®пјҢйӮЈд№Ҳеү©дёӢзҡ„ IP йҮҢпјҢжңҖеҸіиҫ№зҡ„е°ұжҳҜзңҹе®һ IPгҖӮ
X-Forwarded-For: fakeIP, client, proxy1, proxy2
жҜ”еҰӮиҜҙжҲ‘们已зҹҘд»ЈзҗҶжңҚеҠЎжңүдёӨеұӮпјҢд»ҺеҸіеҗ‘е·Ұж•°пјҢжҠҠ proxy1 е’Ң proxy2 еҺ»жҺүпјҢеү©дёӢзҡ„ IP еҲ—иЎЁжңҖеҸіиҫ№зҡ„е°ұжҳҜзңҹе®һ IPгҖӮ
зӣёе…іжҖқи·Ҝе’Ңд»Јз Ғе®һзҺ°еҸҜеҸӮиҖғ Egg.js еүҚзҪ®д»ЈзҗҶжЁЎејҸгҖӮ
5.дёҖеҸҘиҜқжҖ»з»“жҖ»з»“
йҖҡиҝҮ X-Forwarded-For иҺ·еҸ–з”ЁжҲ·зңҹе®һ IP ж—¶пјҢжңҖеҘҪдёҚиҰҒеҸ–第дёҖдёӘ IPпјҢд»ҘйҳІжӯўз”ЁжҲ·дјӘйҖ IPгҖӮ
еӣӣ.з•Ҙжҳҫж··д№ұзҡ„еҲҶйҡ”з¬Ұ
1.HTTP ж ҮеҮҶ
HTTP иҜ·жұӮеӨҙеӯ—ж®өеҰӮжһңж¶үеҸҠеҲ°еӨҡдёӘ value ж—¶пјҢдёҖиҲ¬жқҘиҜҙжҜҸдёӘ value й—ҙжҳҜз”ЁйҖ—еҸ·гҖҢ,гҖҚеҲҶйҡ”зҡ„пјҢе°ұиҝһйқһ RFC ж ҮеҮҶзҡ„ X-Forwarded-ForпјҢд№ҹжҳҜз”ЁйҖ—еҸ·еҲҶйҡ” value зҡ„пјҡ
Accept-Encoding: gzip, deflate, br cache-control: public, max-age=604800, s-maxage=43200 X-Forwarded-For: fakeIP, client, proxy1, proxy2
еӣ дёәдёҖејҖе§Ӣз”ЁйҖ—еҸ·еҲҶйҡ” valueпјҢеҗҺйқўжғіеҶҚз”ЁдёҖдёӘеӯ—ж®өдҝ®йҘ° value ж—¶пјҢеҲҶйҡ”з¬Ұе°ұеҸҳжҲҗдәҶеҲҶеҸ·гҖҢ;гҖҚпјҢжңҖе…ёеһӢзҡ„иҜ·жұӮеӨҙе°ұжҳҜ Accept дәҶпјҡ
// q=0.9 дҝ®йҘ°зҡ„жҳҜ application/xmlпјҢиҷҪ然е®ғ们д№Ӣй—ҙз”ЁеҲҶеҸ·еҲҶйҡ” Accept: text/html, application/xml;q=0.9, */*;q=0.8
иҷҪ然 HTTP еҚҸи®®жҳ“дәҺйҳ…иҜ»пјҢдҪҶжҳҜиҝҷдёӘеҲҶйҡ”з¬Ұз”Ёзҡ„иҝҳжҳҜеҫҲдёҚз¬ҰеҗҲеёёиҜҶзҡ„гҖӮжҢүеёёзҗҶжқҘиҜҙпјҢеҲҶеҸ·зҡ„ж–ӯеҸҘиҜӯж°”жҳҜејәдәҺйҖ—еҸ·зҡ„пјҢдҪҶжҳҜеңЁ HTTP еҶ…е®№еҚҸе•Ҷзҡ„зӣёе…іеӯ—ж®өйҮҢеҚҙжҳҜеҸҚиҝҮжқҘзҡ„гҖӮиҝҷйҮҢзҡ„е®ҡд№үеҸҜд»ҘзңӢ RFC 7231пјҢеҶҷзҡ„иҝҳжҳҜжҜ”иҫғжё…жҘҡзҡ„гҖӮ
2.Cookie ж ҮеҮҶ
е’Ң常规и®ӨиҜҶдёҚеҗҢпјҢCookie е…¶е®һдёҚз®— HTTP ж ҮеҮҶпјҢе®ҡд№ү Cookie зҡ„规иҢғжҳҜ RFC 6265пјҢжүҖд»ҘеҲҶйҡ”з¬Ұ规еҲҷд№ҹдёҚдёҖж ·дәҶгҖӮ规иҢғйҮҢе®ҡд№үзҡ„ Cookie иҜӯ法规еҲҷжҳҜиҝҷж ·зҡ„пјҡ
cookie-header = "Cookie:" OWS cookie-string OWS cookiecookie-string = cookie-pair *( ";" SP cookie-pair )
еӨҡдёӘ cookie д№Ӣй—ҙжҳҜз”ЁеҲҶеҸ·гҖҢ;гҖҚеҲҶйҡ”зҡ„пјҢиҖҢдёҚжҳҜйҖ—еҸ·гҖҢ,гҖҚгҖӮжҲ‘йҡҸдҫҝжү’дәҶдёӘзҪ‘з«ҷзҡ„ cookieпјҢеҸҜи§ҒжҳҜз”ЁеҲҶеҸ·еҲҶйҡ”зҡ„пјҢиҝҷйҮҢйңҖиҰҒзү№еҲ«жіЁж„ҸдёҖдёӢпјҡ

е…ідәҺHTTPдёӯжңүе“Әдәӣ规иҢғе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ