жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңйӣҶз®—еҷЁжҖҺд№ҲеҚҸеҠ©JavaеӨ„зҗҶз»“жһ„еҢ–ж–Үжң¬е®һзҺ°жқЎд»¶иҝҮж»ӨвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңйӣҶз®—еҷЁжҖҺд№ҲеҚҸеҠ©JavaеӨ„зҗҶз»“жһ„еҢ–ж–Үжң¬е®һзҺ°жқЎд»¶иҝҮж»ӨвҖқеҗ§пјҒ
зӣҙжҺҘз”ЁJavaе®һзҺ°ж–Үжң¬ж–Ү件дёӯж•°жҚ®жҢүжқЎд»¶иҝҮж»ӨдјҡжңүеҰӮдёӢзҡ„йә»зғҰ:
1гҖҒж–Ү件дёҚжҳҜж•°жҚ®еә“пјҢдёҚиғҪз”ЁSQLи®ҝй—®гҖӮеҪ“иҝҮж»ӨжқЎд»¶еҸҳеҢ–ж—¶йңҖиҰҒж”№еҶҷд»Јз ҒгҖӮеҰӮжһңиҰҒе®һзҺ°иұЎSQLйӮЈж ·зҒөжҙ»зҡ„жқЎд»¶иҝҮж»ӨпјҢеҲҷйңҖиҰҒиҮӘе·ұе®һзҺ°еҠЁжҖҒиЎЁиҫҫејҸи§Јжһҗе’ҢжұӮеҖјпјҢзј–зЁӢе·ҘдҪңйҮҸйқһеёёеӨ§гҖӮ
2гҖҒж–Ү件еӨӘеӨ§ж—¶дёҚиғҪдёҖж¬ЎжҖ§иЈ…е…ҘеҶ…еӯҳеӨ„зҗҶпјҢиҖҢйҮҮз”ЁйҖҗжӯҘиҜ»е…Ҙж–№ејҸеңЁиҖғиҷ‘еҲ°жҖ§иғҪж—¶еҸҲдјҡж¶үеҸҠеҲ°ж–Ү件缓еҶІеҢәз®ЎзҗҶгҖҒжӢҶиЎҢи®Ўз®—зӯүеӨҚжқӮзј–зЁӢгҖӮ
дҪҝз”ЁйӣҶз®—еҷЁжқҘиҫ…еҠ©Javaзј–зЁӢпјҢиҝҷдәӣй—®йўҳйғҪдёҚйңҖиҰҒиҮӘе·ұеҶҷд»Јз Ғи§ЈеҶігҖӮдёӢйқўжҲ‘们йҖҡиҝҮдҫӢеӯҗжқҘзңӢдёҖдёӢе…·дҪ“дҪңжі•гҖӮ
ж–Үжң¬ж–Ү件employee.txtдёӯдҝқеӯҳдәҶе‘ҳе·Ҙж•°жҚ®гҖӮжҲ‘们иҰҒиҜ»еҸ–е‘ҳе·ҘдҝЎжҒҜпјҢд»ҺдёӯжүҫеҮә1981е№ҙ1жңҲ1ж—ҘпјҲеҗ«пјүд№ӢеҗҺеҮәз”ҹзҡ„еҘіе‘ҳе·ҘгҖӮ
ж–Үжң¬ж–Ү件empolyee.txtзҡ„ж јејҸеҰӮдёӢпјҡ
EID NAME SURNAME GENDER STATE BIRTHDAY HIREDATE DEPT SALARY
1 Rebecca Moore F California 1974-11-20 2005-03-11 R&D 7000
2 Ashley Wilson F New York 1980-07-19 2008-03-16 Finance 11000
3 Rachel Johnson F New Mexico 1970-12-17 2010-12-01 Sales 9000
4 Emily Smith F Texas 1985-03-07 2006-08-15 HR 7000
***shley Smith F Texas 1975-05-13 2004-07-30 R&D 16000
6 Matthew Johnson M California 1984-07-07 2005-07-07 Sales 11000
7 Alexis Smith F Illinois 1972-08-16 2002-08-16 Sales 9000
8 Megan Wilson F California 1979-04-19 1984-04-19 Marketing 11000
9 Victoria Davis F Texas 1983-12-07 2009-12-07 HR 3000
10 Ryan Johnson M Pennsylvania 1976-03-12 2006-03-12 R&D 13000
11 Jacob Moore M Texas 1974-12-16 2004-12-16 Sales 12000
12 Jessica Davis F New York 1980-09-11 2008-09-11 Sales 7000
13 Daniel Davis M Florida 1982-05-14 2010-05-14 Finance 10000
…
е®һзҺ°зҡ„жҖқи·ҜжҳҜпјҡз”ЁJavaзЁӢеәҸи°ғз”ЁйӣҶз®—еҷЁи„ҡжң¬пјҢиҜ»еҸ–е’Ңи®Ўз®—ж•°жҚ®пјҢд№ӢеҗҺе°Ҷз»“жһңд»ҘResultSetзҡ„ж–№ејҸиҝ”еӣһз»ҷJavaзЁӢеәҸгҖӮз”ұдәҺйӣҶз®—еҷЁж”ҜжҢҒеҠЁжҖҒиЎЁиҫҫејҸи§Јжһҗе’ҢжұӮеҖјпјҢдҪҝеҫ—JavaзЁӢеәҸеҸҜд»ҘеғҸдҪҝз”ЁsqlйӮЈж ·пјҢзҒөжҙ»зҡ„иҝҮж»Өж–Үжң¬ж–Ү件дёӯзҡ„ж•°жҚ®гҖӮ
дҫӢеҰӮпјҢжҲ‘们йңҖиҰҒжҹҘиҜў1981е№ҙ1жңҲ1ж—ҘпјҲеҗ«пјүд№ӢеҗҺеҮәз”ҹзҡ„еҘіе‘ҳе·ҘпјҢesProcзЁӢеәҸеҸҜд»Ҙд»ҺеӨ–йғЁиҺ·еҫ—дёҖдёӘиҫ“е…ҘеҸӮж•°вҖңwhereвҖқдҪңдёәжқЎд»¶пјҢеҰӮдёӢеӣҫпјҡ
whereжҳҜдёӘеӯ—дёІпјҢеҸ–еҖјжҳҜпјҡBIRTHDAY>=date(1981,1,1) && GENDER==вҖқFвҖқгҖӮ
esProcд»Јз ҒеҰӮдёӢпјҡ
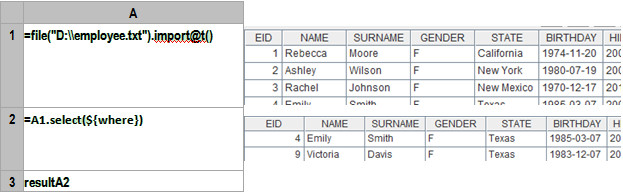
A1пјҡе®ҡд№үдёҖдёӘfileеҜ№иұЎпјҢиҜ»е…Ҙж•°жҚ®пјҢ***иЎҢжҳҜж ҮйўҳпјҢеӯ—ж®өеҲҶйҡ”з¬Ұй»ҳи®ӨжҳҜtabгҖӮesProcзҡ„йӣҶжҲҗејҖеҸ‘зҺҜеўғеҸҜд»Ҙзӣҙи§Ӯзҡ„жҳҫзӨәеҮәеҜје…Ҙзҡ„ж•°жҚ®пјҢеҰӮдёҠеӣҫеҸіиҫ№йғЁеҲҶгҖӮ
A2пјҡжҢүз…§жқЎд»¶иҝҮж»ӨгҖӮиҝҷйҮҢдҪҝз”Ёе®ҸжқҘе®һзҺ°еҠЁжҖҒи§ЈжһҗиЎЁиҫҫејҸпјҢе…¶дёӯзҡ„whereе°ұжҳҜдј е…ҘеҸӮж•°гҖӮйӣҶз®—еҷЁе…Ҳи®Ўз®—${…}йҮҢзҡ„иЎЁиҫҫејҸпјҢе°Ҷи®Ўз®—з»“жһңдҪңдёәе®Ҹеӯ—з¬ҰдёІеҖј жӣҝжҚў${…}д№ӢеҗҺи§ЈйҮҠжү§иЎҢгҖӮиҝҷдёӘдҫӢеӯҗдёӯжңҖз»Ҳжү§иЎҢзҡ„жҳҜпјҡ=A1.select(BIRTHDAY>=date(1981,1,1) && GENDER==вҖқFвҖқ)гҖӮ
A3пјҡеҗ‘еӨ–йғЁзЁӢеәҸиҝ”еӣһз¬ҰеҗҲжқЎд»¶зҡ„з»“жһңйӣҶгҖӮ
иҝҮж»ӨжқЎд»¶еҸ‘з”ҹеҸҳеҢ–ж—¶дёҚз”Ёж”№еҸҳд»Јз ҒпјҢеҸӘйңҖж”№еҸҳwhereеҸӮж•°еҚіеҸҜгҖӮдҫӢеҰӮпјҢжқЎд»¶еҸҳдёәпјҡжҹҘиҜў1981е№ҙ1жңҲ1ж—ҘпјҲеҗ«пјүд№ӢеҗҺеҮәз”ҹзҡ„еҘіе‘ҳе·ҘпјҢжҲ–иҖ… NAME+SURNAMEзӯүдәҺвҖқRebeccaMooreвҖқзҡ„е‘ҳе·ҘгҖӮWhereзҡ„еҸӮж•°еҖјеҸҜд»ҘеҶҷ дёәпјҡBIRTHDAY>=date(1981,1,1) && GENDER==вҖқFвҖқ || NAME+SURNAME==вҖқRebeccaMooreвҖқгҖӮжү§иЎҢд№ӢеҗҺпјҢA2дёӯзҡ„з»“жһңйӣҶеҰӮдёӢеӣҫпјҡ

еңЁJavaзЁӢеәҸдёӯдҪҝз”ЁesProc JDBCи°ғз”Ёиҝҷж®өзЁӢеәҸиҺ·еҫ—з»“жһңзҡ„д»Јз ҒеҰӮдёӢпјҡпјҲе°ҶдёҠиҝ°esProcзЁӢеәҸдҝқеӯҳдёәtest.dfxпјүпјҡ
//е»әз«ӢesProc jdbcиҝһжҺҘ
Class.forName(вҖңcom.esproc.jdbc.InternalDriverвҖқ);
con= DriverManager.getConnection(вҖңjdbc:esproc:local://вҖқ);
//и°ғз”ЁesProc зЁӢеәҸпјҲеӯҳеӮЁиҝҮзЁӢпјүпјҢе…¶дёӯtestжҳҜdfxзҡ„ж–Ү件еҗҚ
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(вҖңcall test(?)вҖқ);
//и®ҫзҪ®еҸӮж•°
st.setObject(1,вҖқ BIRTHDAY>=date(1981,1,1) && GENDER==\вҖқF\вҖқ ||NAME+SURNAME==\вҖқRebeccaMoore\вҖқ");//еҸӮж•°е°ұжҳҜеҠЁжҖҒзҡ„иҝҮж»ӨжқЎд»¶
//жү§иЎҢesProcеӯҳеӮЁиҝҮзЁӢ
st.execute();
//иҺ·еҸ–з»“жһңйӣҶпјҡз¬ҰеҗҲжқЎд»¶зҡ„е‘ҳе·ҘйӣҶеҗҲ
ResultSet set = st.getResultSet();
еҜ№дәҺд»Јз Ғиҫғз®ҖеҚ•зҡ„и„ҡжң¬пјҢиҝҳеҸҜд»ҘжҠҠд»Јз ҒзӣҙжҺҘеҶҷеңЁи°ғз”ЁйӣҶз®—еҷЁJDBCзҡ„JavaзЁӢеәҸдёӯпјҢиҖҢдёҚеҝ…дё“й—Ёзј–еҶҷи„ҡжң¬ж–Ү件пјҲtest.dfxпјүпјҡ
st=(com. esproc.jdbc.InternalCStatement)con.createStatement();
ResultSet set= st.executeQuery(вҖң=file(\вҖқD:/employee.txt\вҖқ).import@t().select(BIRTHDAY>=date(1981,1,1)&&GENDER==\вҖқF\вҖқ || NAME+SURNAME==\вҖқRebeccaMoore\вҖқ)вҖқ);
иҝҷж®өJavaд»Јз ҒзӣҙжҺҘи°ғз”ЁдәҶйӣҶз®—еҷЁзҡ„дёҖеҸҘи„ҡжң¬пјҡд»Һж–Үжң¬ж–Ү件дёӯеҸ–еҫ—ж•°жҚ®пјҢ并жҢүз…§жҢҮе®ҡзҡ„жқЎд»¶иҝҮж»ӨгҖӮз»“жһңйӣҶиҝ”еӣһз»ҷResultSetеҜ№иұЎsetгҖӮ
дёҠйқўж–№жі•дёӯеҒҮе®ҡж–Ү件иҫғе°ҸпјҢеҸҜд»Ҙе…ЁйғЁиҜ»е…ҘеҶ…еӯҳгҖӮдҪҶе®һйҷ…дёҠеҸҜиғҪеҸ‘з”ҹж–Ү件иҫғеӨ§ж— жі•иҜ»е…ҘеҶ…е®№зҡ„жғ…еҶөпјҢиҖҢдё”еҚідҪҝеҸҜд»ҘиҜ»е…Ҙд№ҹжІЎеҝ…иҰҒеҚ еӨӘеӨҡеҶ…еӯҳпјҢиҝҷж—¶еҸҜд»ҘдҪҝз”Ёж–Ү件游ж Үзҡ„ж–№ејҸжқҘеӨ„зҗҶгҖӮйӣҶз®—еҷЁзЁӢеәҸи°ғж•ҙеҰӮдёӢпјҡ
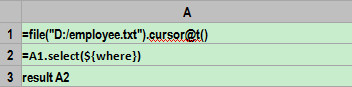
A1пјҡе®ҡд№үдёҖдёӘfileеҜ№иұЎжёёж ҮпјҢ***иЎҢжҳҜж ҮйўҳпјҢеӯ—ж®өеҲҶйҡ”з¬Ұй»ҳи®ӨжҳҜtabгҖӮ
A2пјҡжҢүз…§жқЎд»¶иҝҮж»Өжёёж ҮгҖӮиҝҷйҮҢдҪҝз”Ёе®ҸжқҘе®һзҺ°еҠЁжҖҒи§ЈжһҗиЎЁиҫҫејҸпјҢе…¶дёӯзҡ„whereе°ұжҳҜдј е…ҘеҸӮж•°гҖӮйӣҶз®—еҷЁе°Ҷе…Ҳи®Ўз®—${…}йҮҢзҡ„иЎЁиҫҫејҸпјҢе°Ҷи®Ўз®—з»“жһңдҪңдёәе®Ҹеӯ— з¬ҰдёІеҖјжӣҝжҚў${…}д№ӢеҗҺи§ЈйҮҠжү§иЎҢгҖӮиҝҷдёӘдҫӢеӯҗдёӯжңҖз»Ҳжү§иЎҢзҡ„жҳҜпјҡ=A1.select(BIRTHDAY>=date(1981,1,1) && GENDER==вҖқFвҖқ)гҖӮ
A3пјҡиҝ”еӣһжёёж ҮгҖӮ
иҷҪ然йӣҶз®—еҷЁз»ҷJavaиҝ”еӣһзҡ„жҳҜжёёж ҮпјҢдҪҶжҳҜJavaи°ғз”Ёзҡ„зЁӢеәҸдёҚз”Ёдҝ®ж”№гҖӮеңЁJavaдҪҝз”ЁResultSetйҒҚеҺҶж•°жҚ®зҡ„ж—¶еҖҷйӣҶз®—еҷЁдјҡиҮӘеҠЁеҸ–еҮәжёёж ҮеҜ№еә”зҡ„еҶ…е®№гҖӮ
еҰӮжһңйңҖиҰҒе°ҶиҝҮж»ӨеҗҺзҡ„ж•°жҚ®еҶҷе…ҘеҸҰдёҖдёӘж–Ү件иҖҢдёҚжҳҜиҝ”еӣһз»ҷдё»зЁӢеәҸпјҢеҸӘиҰҒе°ҶA3ж јзҡ„иЎЁиҫҫејҸж”№жҲҗпјҡ=file(вҖңD:/employee_group.txtвҖқ).export@t(A2)еҚіеҸҜпјҢйӣҶз®—еҷЁе°ҶжҠҠжёёж Үж•°жҚ®еҶҷеҮәжҲҗж–Ү件гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңйӣҶз®—еҷЁжҖҺд№ҲеҚҸеҠ©JavaеӨ„зҗҶз»“жһ„еҢ–ж–Үжң¬е®һзҺ°жқЎд»¶иҝҮж»ӨвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№йӣҶз®—еҷЁжҖҺд№ҲеҚҸеҠ©JavaеӨ„зҗҶз»“жһ„еҢ–ж–Үжң¬е®һзҺ°жқЎд»¶иҝҮж»ӨиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ