您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天就跟大家聊聊有关Science发表的超赞聚类算法是什么呢,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
作者提出了一种很简洁优美的聚类算法, 可以识别各种形状的类簇, 并且其超参数很容易确定.
算法思想
该算法的假设是类簇的中心由一些局部密度比较低的点围绕, 并且这些点距离其他有高局部密度的点的距离都比较大. 首先定义两个值: 局部密度ρi以及到高局部密度点的距离δi:
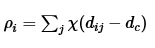
其中
dc是一个截断距离, 是一个超参数. 所以ρi相当于距离点i的距离小于dc的点的个数. 由于该算法只对ρi的相对值敏感, 所以对dc的选择比较鲁棒, 一种推荐做法是选择dc使得平均每个点的邻居数为所有点的1%-2%. 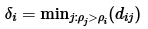
对于密度***的点, 设置 . 注意只有那些密度是局部或者全局***的点才会有远大于正常的相邻点间距.
. 注意只有那些密度是局部或者全局***的点才会有远大于正常的相邻点间距.
聚类过程
那些有着比较大的局部密度ρi和很大的δi的点被认为是类簇的中心. 局部密度较小但是δi较大的点是异常点.在确定了类簇中心之后, 所有其他点属于距离其最近的类簇中心所代表的类簇. 图例如下:

左图是所有点在二维空间的分布, 右图是以ρ为横坐标, 以δ为纵坐标, 这种图称作决策图(decision tree). 可以看到, 1和10两个点的ρi和δi都比较大, 作为类簇的中心点. 26, 27, 28三个点的δi也比较大, 但是ρi较小, 所以是异常点.
聚类分析
在聚类分析中, 通常需要确定每个点划分给某个类簇的可靠性. 在该算法中, 可以首先为每个类簇定义一个边界区域(border region), 亦即划分给该类簇但是距离其他类簇的点的距离小于dc的点. 然后为每个类簇找到其边界区域的局部密度***的点, 令其局部密度为ρh. 该类簇中所有局部密度大于ρh的点被认为是类簇核心的一部分(亦即将该点划分给该类簇的可靠性很大), 其余的点被认为是该类簇的光晕(halo), 亦即可以认为是噪音. 图例如下
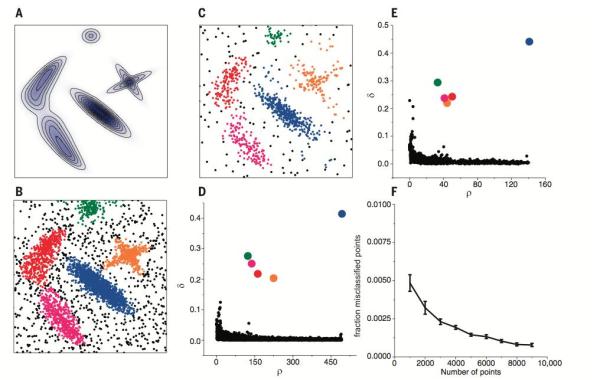
A图为生成数据的概率分布, B, C二图为分别从该分布中生成了4000, 1000个点. D, E分别是B, C两组数据的决策图(decision tree), 可以看到两组数据都只有五个点有比较大的ρi和很大的δi. 这些点作为类簇的中心, 在确定了类簇的中心之后, 每个点被划分到各个类簇(彩色点), 或者是划分到类簇光晕(黑色点). F图展示的是随着抽样点数量的增多, 聚类的错误率在逐渐下降, 说明该算法是鲁棒的.
***展示一下该算法在各种数据分布上的聚类效果, 非常赞.
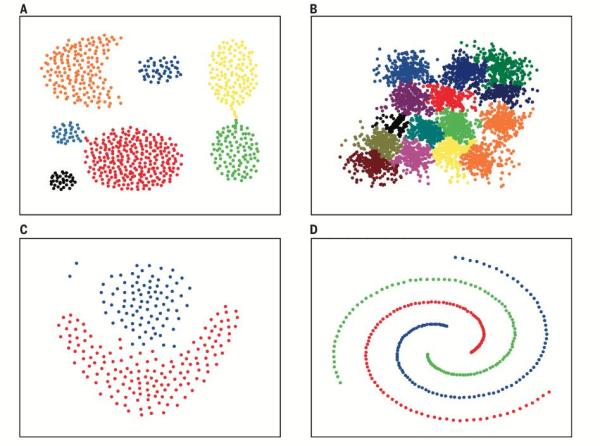
看完上述内容,你们对Science发表的超赞聚类算法是什么呢有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。