жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңNode.jsжЁЎеқ—зі»з»ҹжәҗз ҒеҲҶжһҗвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁNode.jsжЁЎеқ—зі»з»ҹжәҗз ҒеҲҶжһҗй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқNode.jsжЁЎеқ—зі»з»ҹжәҗз ҒеҲҶжһҗвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
CommonJS 规иҢғ
Node жңҖеҲқйҒөеҫӘ CommonJS 规иҢғжқҘе®һзҺ°иҮӘе·ұзҡ„жЁЎеқ—зі»з»ҹпјҢеҗҢж—¶еҒҡдәҶдёҖйғЁеҲҶеҢәеҲ«дәҺ规иҢғзҡ„е®ҡеҲ¶гҖӮCommonJS 规иҢғжҳҜдёәдәҶи§ЈеҶі JavaScript зҡ„дҪңз”Ёеҹҹй—®йўҳиҖҢе®ҡд№үзҡ„жЁЎеқ—еҪўејҸпјҢе®ғеҸҜд»ҘдҪҝжҜҸдёӘжЁЎеқ—еңЁе®ғиҮӘиә«зҡ„е‘ҪеҗҚз©әй—ҙдёӯжү§иЎҢгҖӮ
иҜҘ规иҢғејәи°ғжЁЎеқ—еҝ…йЎ»йҖҡиҝҮ module.exports еҜјеҮәеҜ№еӨ–зҡ„еҸҳйҮҸжҲ–еҮҪж•°пјҢйҖҡиҝҮ require() жқҘеҜје…Ҙе…¶д»–жЁЎеқ—зҡ„иҫ“еҮәеҲ°еҪ“еүҚжЁЎеқ—дҪңз”ЁеҹҹдёӯпјҢеҗҢж—¶пјҢйҒөеҫӘд»ҘдёӢзәҰе®ҡпјҡ
еңЁжЁЎеқ—дёӯпјҢеҝ…йЎ»жҡҙйңІдёҖдёӘ require еҸҳйҮҸпјҢе®ғжҳҜдёҖдёӘеҮҪж•°пјҢrequire еҮҪж•°жҺҘеҸ—дёҖдёӘжЁЎеқ—ж ҮиҜҶз¬ҰпјҢrequire иҝ”еӣһеӨ–йғЁжЁЎеқ—зҡ„еҜјеҮәзҡ„ APIгҖӮеҰӮжһңиҰҒжұӮзҡ„жЁЎеқ—дёҚиғҪиў«иҝ”еӣһеҲҷ require еҝ…йЎ»жҠӣеҮәдёҖдёӘй”ҷиҜҜгҖӮ
еңЁжЁЎеқ—дёӯпјҢеҝ…йЎ»жңүдёҖдёӘиҮӘз”ұеҸҳйҮҸеҸ«еҒҡ exportsпјҢе®ғжҳҜдёҖдёӘеҜ№иұЎпјҢжЁЎеқ—еңЁжү§иЎҢж—¶еҸҜд»ҘеңЁ exports дёҠжҢӮиҪҪжЁЎеқ—зҡ„еұһжҖ§гҖӮжЁЎеқ—еҝ…йЎ»дҪҝз”Ё exports еҜ№иұЎдҪңдёәе”ҜдёҖзҡ„еҜјеҮәж–№ејҸгҖӮ
еңЁжЁЎеқ—дёӯпјҢеҝ…йЎ»жңүдёҖдёӘиҮӘз”ұеҸҳйҮҸ moduleпјҢе®ғд№ҹжҳҜдёҖдёӘеҜ№иұЎгҖӮmodule еҜ№иұЎеҝ…йЎ»жңүдёҖдёӘ id еұһжҖ§пјҢе®ғжҳҜиҝҷдёӘжЁЎеқ—зҡ„йЎ¶еұӮ idгҖӮid еұһжҖ§еҝ…йЎ»жҳҜиҝҷж ·зҡ„пјҢrequire(module.id) дјҡд»ҺжәҗеҮә module.id зҡ„йӮЈдёӘжЁЎеқ—иҝ”еӣһ exports еҜ№иұЎпјҲе°ұжҳҜиҜҙ module.id еҸҜд»Ҙиў«дј йҖ’еҲ°еҸҰдёҖдёӘжЁЎеқ—пјҢиҖҢдё”еңЁиҰҒжұӮе®ғж—¶еҝ…йЎ»иҝ”еӣһжңҖеҲқзҡ„жЁЎеқ—пјүгҖӮ
Node еҜ№ CommonJS 规иҢғзҡ„е®һзҺ°
е®ҡд№үдәҶжЁЎеқ—еҶ…йғЁзҡ„ module.require еҮҪж•°е’Ңе…ЁеұҖзҡ„ require еҮҪж•°пјҢз”ЁжқҘеҠ иҪҪжЁЎеқ—гҖӮ
еңЁ Node жЁЎеқ—зі»з»ҹдёӯпјҢжҜҸдёӘж–Ү件йғҪиў«и§ҶдёәдёҖдёӘзӢ¬з«Ӣзҡ„жЁЎеқ—гҖӮжЁЎеқ—иў«еҠ иҪҪж—¶пјҢйғҪдјҡеҲқе§ӢеҢ–дёә Module еҜ№иұЎзҡ„е®һдҫӢпјҢModule еҜ№иұЎзҡ„еҹәжң¬е®һзҺ°е’ҢеұһжҖ§еҰӮдёӢжүҖзӨәпјҡ
function Module(id = "", parent) { // жЁЎеқ— id,йҖҡеёёдёәжЁЎеқ—зҡ„з»қеҜ№и·Ҝеҫ„ this.id = id; this.path = path.dirname(id); this.exports = {}; // еҪ“еүҚжЁЎеқ—и°ғз”ЁиҖ… this.parent = parent; updateChildren(parent, this, false); this.filename = null; // жЁЎеқ—жҳҜеҗҰеҠ иҪҪе®ҢжҲҗ this.loaded = false; // еҪ“еүҚжЁЎеқ—жүҖеј•з”Ёзҡ„жЁЎеқ— this.children = []; }жҜҸдёҖдёӘжЁЎеқ—йғҪеҜ№еӨ–жҡҙйңІиҮӘе·ұзҡ„ exports еұһжҖ§дҪңдёәдҪҝз”ЁжҺҘеҸЈгҖӮ
жЁЎеқ—еҜјеҮәд»ҘеҸҠеј•з”Ё
еңЁ Node дёӯпјҢеҸҜдҪҝз”Ё module.exports еҜ№иұЎж•ҙдҪ“еҜјеҮәдёҖдёӘеҸҳйҮҸжҲ–иҖ…еҮҪж•°пјҢд№ҹеҸҜе°ҶйңҖиҰҒеҜјеҮәзҡ„еҸҳйҮҸжҲ–еҮҪж•°жҢӮиҪҪеҲ° exports еҜ№иұЎзҡ„еұһжҖ§дёҠпјҢд»Јз ҒеҰӮдёӢжүҖзӨәпјҡ
// 1. дҪҝз”Ё exports: 笔иҖ…д№ жғҜйҖҡеёёз”ЁдҪңеҜ№е·Ҙе…·еә“еҮҪж•°жҲ–еёёйҮҸзҡ„еҜјеҮә exports.name = 'xiaoxiang'; exports.add = (a, b) => a + b; // 2. дҪҝз”Ё module.exportsпјҡеҜјеҮәдёҖж•ҙдёӘеҜ№иұЎжҲ–иҖ…еҚ•дёҖеҮҪж•° ... module.exports = { add, minus }йҖҡиҝҮе…ЁеұҖ require еҮҪж•°еј•з”ЁжЁЎеқ—пјҢеҸҜдј е…ҘжЁЎеқ—еҗҚз§°гҖҒзӣёеҜ№и·Ҝеҫ„жҲ–иҖ…з»қеҜ№и·Ҝеҫ„пјҢеҪ“жЁЎеқ—ж–Ү件еҗҺзјҖдёә js / json / node ж—¶пјҢеҸҜзңҒз•ҘеҗҺзјҖпјҢеҰӮдёӢд»Јз ҒжүҖзӨәпјҡ
// еј•з”ЁжЁЎеқ— const { add, minus } = require('./module'); const a = require('/usr/app/module'); const http = require('http');жіЁж„ҸдәӢйЎ№пјҡ
exports еҸҳйҮҸжҳҜеңЁжЁЎеқ—зҡ„ж–Ү件зә§дҪңз”ЁеҹҹеҶ…еҸҜз”Ёзҡ„пјҢдё”еңЁжЁЎеқ—жү§иЎҢд№ӢеүҚиөӢеҖјз»ҷ module.exportsгҖӮ
exports.name = 'test'; console.log(module.exports.name); // test module.export.name = 'test'; console.log(exports.name); // test
еҰӮжһңдёә exports иөӢдәҲдәҶж–°еҖјпјҢеҲҷе®ғе°ҶдёҚеҶҚз»‘е®ҡеҲ° module.exportsпјҢеҸҚд№ӢдәҰ然пјҡ
exports = { name: 'test' }; console.log(module.exports.name, exports.name); // undefined, testеҪ“ module.exports еұһжҖ§иў«ж–°еҜ№иұЎе®Ңе…ЁжӣҝжҚўж—¶пјҢйҖҡеёёд№ҹйңҖиҰҒйҮҚж–°иөӢеҖј exportsпјҡ
module.exports = exports = { name: 'test' }; console.log(module.exports.name, exports.name) // test, testжЁЎеқ—зі»з»ҹе®һзҺ°еҲҶжһҗ
жЁЎеқ—е®ҡдҪҚ
д»ҘдёӢжҳҜ require еҮҪж•°зҡ„д»Јз Ғе®һзҺ°пјҡ
// require е…ҘеҸЈеҮҪж•° Module.prototype.require = function(id) { //... requireDepth++; try { return Module._load(id, this, /* isMain */ false); // еҠ иҪҪжЁЎеқ— } finally { requireDepth--; } };дёҠиҝ°д»Јз ҒжҺҘ收з»ҷе®ҡзҡ„жЁЎеқ—и·Ҝеҫ„пјҢе…¶дёӯзҡ„ requireDepth з”ЁжқҘи®°иҪҪжЁЎеқ—еҠ иҪҪзҡ„ж·ұеәҰгҖӮе…¶дёӯ Module зҡ„зұ»ж–№жі• _load е®һзҺ°дәҶ Node еҠ иҪҪжЁЎеқ—зҡ„дё»иҰҒйҖ»иҫ‘пјҢдёӢйқўжҲ‘们жқҘи§Јжһҗ Module._load еҮҪж•°зҡ„жәҗз Ғе®һзҺ°пјҢдёәдәҶж–№дҫҝеӨ§е®¶зҗҶи§ЈпјҢжҲ‘жҠҠжіЁйҮҠеҠ еңЁдәҶж–ҮдёӯгҖӮ
Module._load = function(request, parent, isMain) { // жӯҘйӘӨдёҖпјҡи§ЈжһҗеҮәжЁЎеқ—зҡ„е…Ёи·Ҝеҫ„ const filename = Module._resolveFilename(request, parent, isMain); // жӯҘйӘӨдәҢпјҡеҠ иҪҪжЁЎеқ—пјҢе…·дҪ“еҲҶдёүз§Қжғ…еҶөеӨ„зҗҶ // жғ…еҶөдёҖпјҡеӯҳеңЁзј“еӯҳзҡ„жЁЎеқ—пјҢзӣҙжҺҘиҝ”еӣһжЁЎеқ—зҡ„ exports еұһжҖ§ const cachedModule = Module._cache[filename]; if (cachedModule !== undefined) return cachedModule.exports; // жғ…еҶөдәҢпјҡеҠ иҪҪеҶ…е»әжЁЎеқ— const mod = loadNativeModule(filename, request); if (mod && mod.canBeRequiredByUsers) return mod.exports; // жғ…еҶөдёүпјҡжһ„е»әжЁЎеқ—еҠ иҪҪ const module = new Module(filename, parent); // еҠ иҪҪиҝҮд№ӢеҗҺе°ұиҝӣиЎҢжЁЎеқ—е®һдҫӢзј“еӯҳ Module._cache[filename] = module; // жӯҘйӘӨдёүпјҡеҠ иҪҪжЁЎеқ—ж–Ү件 module.load(filename); // жӯҘйӘӨеӣӣпјҡиҝ”еӣһеҜјеҮәеҜ№иұЎ return module.exports; };еҠ иҪҪзӯ–з•Ҙ
дёҠйқўзҡ„д»Јз ҒдҝЎжҒҜйҮҸжҜ”иҫғеӨ§пјҢжҲ‘们主иҰҒзңӢд»ҘдёӢеҮ дёӘй—®йўҳпјҡ
жЁЎеқ—зҡ„зј“еӯҳзӯ–з•ҘжҳҜд»Җд№Ҳпјҹ
еҲҶжһҗдёҠиҝ°д»Јз ҒжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢ _load еҠ иҪҪеҮҪж•°й’ҲеҜ№дёүз§Қжғ…еҶөз»ҷеҮәдәҶдёҚеҗҢзҡ„еҠ иҪҪзӯ–з•ҘпјҢеҲҶеҲ«жҳҜпјҡ
жғ…еҶөдёҖпјҡзј“еӯҳе‘ҪдёӯпјҢзӣҙжҺҘиҝ”еӣһгҖӮ
жғ…еҶөдәҢпјҡеҶ…е»әжЁЎеқ—пјҢиҝ”еӣһжҡҙйңІеҮәжқҘзҡ„ exports еұһжҖ§пјҢд№ҹе°ұжҳҜ module.exports зҡ„еҲ«еҗҚгҖӮ
жғ…еҶөдёүпјҡдҪҝз”Ёж–Ү件жҲ–第дёүж–№д»Јз Ғз”ҹжҲҗжЁЎеқ—пјҢжңҖеҗҺиҝ”еӣһпјҢ并且缓еӯҳпјҢиҝҷж ·дёӢж¬ЎеҗҢж ·зҡ„и®ҝй—®е°ұдјҡеҺ»дҪҝз”Ёзј“еӯҳиҖҢдёҚжҳҜйҮҚж–°еҠ иҪҪгҖӮ
2. Module._resolveFilename(request, parent, isMain) жҳҜжҖҺд№Ҳи§ЈжһҗеҮәж–Ү件еҗҚз§°зҡ„пјҹ
жҲ‘们зңӢеҰӮдёӢе®ҡд№үзҡ„зұ»ж–№жі•пјҡ
Module._resolveFilename = function(request, parent, isMain, options) { if (NativeModule.canBeRequiredByUsers(request)) { // дјҳе…ҲеҠ иҪҪеҶ…е»әжЁЎеқ— return request; } let paths; // node require.resolve еҮҪж•°дҪҝз”Ёзҡ„ optionsпјҢoptions.paths з”ЁдәҺжҢҮе®ҡжҹҘжүҫи·Ҝеҫ„ if (typeof options === "object" && options !== null) { if (ArrayIsArray(options.paths)) { const isRelative = request.startsWith("./") || request.startsWith("../") || (isWindows && request.startsWith(".\\")) || request.startsWith("..\\"); if (isRelative) { paths = options.paths; } else { const fakeParent = new Module("", null); paths = []; for (let i = 0; i < options.paths.length; i++) { const path = options.paths[i]; fakeParent.paths = Module._nodeModulePaths(path); const lookupPaths = Module._resolveLookupPaths(request, fakeParent); for (let j = 0; j < lookupPaths.length; j++) { if (!paths.includes(lookupPaths[j])) paths.push(lookupPaths[j]); } } } } else if (options.paths === undefined) { paths = Module._resolveLookupPaths(request, parent); } else { //... } } else { // жҹҘжүҫжЁЎеқ—еӯҳеңЁи·Ҝеҫ„ paths = Module._resolveLookupPaths(request, parent); } // дҫқжҚ®з»ҷеҮәзҡ„жЁЎеқ—е’ҢйҒҚеҺҶең°еқҖж•°з»„пјҢд»ҘеҸҠжҳҜеҗҰдёәе…ҘеҸЈжЁЎеқ—жқҘжҹҘжүҫжЁЎеқ—и·Ҝеҫ„ const filename = Module._findPath(request, paths, isMain); if (!filename) { const requireStack = []; for (let cursor = parent; cursor; cursorcursor = cursor.parent) { requireStack.push(cursor.filename || cursor.id); } // жңӘжүҫеҲ°жЁЎеқ—пјҢжҠӣеҮәејӮеёёпјҲжҳҜдёҚжҳҜеҫҲзҶҹжӮүзҡ„й”ҷиҜҜпјү let message = `Cannot find module '${request}'`; if (requireStack.length > 0) { messagemessage = message + "\nRequire stack:\n- " + requireStack.join("\n- "); } const err = new Error(message); err.code = "MODULE_NOT_FOUND"; err.requireStack = requireStack; throw err; } // жңҖз»Ҳиҝ”еӣһеҢ…еҗ«ж–Ү件еҗҚзҡ„е®Ңж•ҙи·Ҝеҫ„ return filename; };дёҠйқўзҡ„д»Јз ҒдёӯжҜ”иҫғзӘҒеҮәзҡ„жҳҜдҪҝз”ЁдәҶ _resolveLookupPaths е’Ң _findPath дёӨдёӘж–№жі•гҖӮ
_resolveLookupPaths: йҖҡиҝҮжҺҘеҸ—жЁЎеқ—еҗҚз§°е’ҢжЁЎеқ—и°ғз”ЁиҖ…пјҢиҝ”еӣһжҸҗдҫӣ _findPath дҪҝз”Ёзҡ„йҒҚеҺҶиҢғеӣҙж•°з»„гҖӮ
// жЁЎеқ—ж–Ү件еҜ»еқҖзҡ„ең°еқҖж•°з»„ж–№жі• Module._resolveLookupPaths = function(request, parent) { if (NativeModule.canBeRequiredByUsers(request)) { debug("looking for %j in []", request); return null; } // еҰӮжһңдёҚжҳҜзӣёеҜ№и·Ҝеҫ„ if ( request.charAt(0) !== "." || (request.length > 1 && request.charAt(1) !== "." && request.charAt(1) !== "/" && (!isWindows || request.charAt(1) !== "\\")) ) { /** * жЈҖжҹҘ node_modules ж–Ү件еӨ№ * modulePaths дёәз”ЁжҲ·зӣ®еҪ•пјҢnode_path зҺҜеўғеҸҳйҮҸжҢҮе®ҡзӣ®еҪ•гҖҒе…ЁеұҖ node е®үиЈ…зӣ®еҪ• */ let paths = modulePaths; if (parent != null && parent.paths && parent.paths.length) { // зҲ¶жЁЎеқ—зҡ„ modulePath д№ҹиҰҒеҠ еҲ°еӯҗжЁЎеқ—зҡ„ modulePath йҮҢйқўпјҢеҫҖдёҠеӣһжәҜжҹҘжүҫ paths = parent.paths.concat(paths); } return paths.length > 0 ? paths : null; } // дҪҝз”Ё repl дәӨдә’ж—¶пјҢдҫқж¬ЎжҹҘжүҫ ./ ./node_modules д»ҘеҸҠ modulePaths if (!parent || !parent.id || !parent.filename) { const mainPaths = ["."].concat(Module._nodeModulePaths("."), modulePaths); return mainPaths; } // еҰӮжһңжҳҜзӣёеҜ№и·Ҝеҫ„еј•е…ҘпјҢеҲҷе°ҶзҲ¶зә§ж–Ү件еӨ№и·Ҝеҫ„еҠ е…ҘжҹҘжүҫи·Ҝеҫ„ const parentDir = [path.dirname(parent.filename)]; return parentDir; };_findPath: дҫқжҚ®зӣ®ж ҮжЁЎеқ—е’ҢдёҠиҝ°еҮҪж•°жҹҘжүҫеҲ°зҡ„иҢғеӣҙпјҢжүҫеҲ°еҜ№еә”зҡ„ filename 并иҝ”еӣһгҖӮ
// дҫқжҚ®з»ҷеҮәзҡ„жЁЎеқ—е’ҢйҒҚеҺҶең°еқҖж•°з»„пјҢд»ҘеҸҠжҳҜеҗҰйЎ¶еұӮжЁЎеқ—жқҘеҜ»жүҫжЁЎеқ—зңҹе®һи·Ҝеҫ„ Module._findPath = function(request, paths, isMain) { const absoluteRequest = path.isAbsolute(request); if (absoluteRequest) { // з»қеҜ№и·Ҝеҫ„пјҢзӣҙжҺҘе®ҡдҪҚеҲ°е…·дҪ“жЁЎеқ— paths = [""]; } else if (!paths || paths.length === 0) { return false; } const cacheKey = request + "\x00" + (paths.length === 1 ? paths[0] : paths.join("\x00")); // зј“еӯҳи·Ҝеҫ„ const entry = Module._pathCache[cacheKey]; if (entry) return entry; let exts; let trailingSlash = request.length > 0 && request.charCodeAt(request.length - 1) === CHAR_FORWARD_SLASH; // '/' if (!trailingSlash) { trailingSlash = /(?:^|\/)\.?\.$/.test(request); } // For each path for (let i = 0; i < paths.length; i++) { const curPath = paths[i]; if (curPath && stat(curPath) < 1) continue; const basePath = resolveExports(curPath, request, absoluteRequest); let filename; const rc = stat(basePath); if (!trailingSlash) { if (rc === 0) { // stat зҠ¶жҖҒиҝ”еӣһ 0пјҢеҲҷдёәж–Ү件 // File. if (!isMain) { if (preserveSymlinks) { // еҪ“и§Јжһҗе’Ңзј“еӯҳжЁЎеқ—ж—¶пјҢе‘Ҫд»ӨжЁЎеқ—еҠ иҪҪеҷЁдҝқжҢҒз¬ҰеҸ·иҝһжҺҘгҖӮ filename = path.resolve(basePath); } else { // дёҚдҝқжҢҒз¬ҰеҸ·й“ҫжҺҘ filename = toRealPath(basePath); } } else if (preserveSymlinksMain) { filename = path.resolve(basePath); } else { filename = toRealPath(basePath); } } if (!filename) { if (exts === undefined) exts = ObjectKeys(Module._extensions); // и§ЈжһҗеҗҺзјҖеҗҚ filename = tryExtensions(basePath, exts, isMain); } } if (!filename && rc === 1) { /** * stat зҠ¶жҖҒиҝ”еӣһ 1 дё”ж–Ү件еҗҚдёҚеӯҳеңЁпјҢеҲҷи®ӨдёәжҳҜж–Ү件еӨ№ * еҰӮжһңж–Ү件еҗҺзјҖдёҚеӯҳеңЁпјҢеҲҷе°қиҜ•еҠ иҪҪиҜҘзӣ®еҪ•дёӢзҡ„ package.json дёӯ main е…ҘеҸЈжҢҮе®ҡзҡ„ж–Ү件 * еҰӮжһңдёҚеӯҳеңЁпјҢ然еҗҺе°қиҜ• index[.js, .node, .json] ж–Ү件 */ if (exts === undefined) exts = ObjectKeys(Module._extensions); filename = tryPackage(basePath, exts, isMain, request); } if (filename) { // еҰӮжһңеӯҳеңЁиҜҘж–Ү件пјҢе°Ҷж–Ү件еҗҚеҲҷеҠ е…Ҙзј“еӯҳ Module._pathCache[cacheKey] = filename; return filename; } } const selfFilename = trySelf(paths, exts, isMain, trailingSlash, request); if (selfFilename) { // и®ҫзҪ®и·Ҝеҫ„зҡ„зј“еӯҳ Module._pathCache[cacheKey] = selfFilename; return selfFilename; } return false; };жЁЎеқ—еҠ иҪҪ
ж ҮеҮҶжЁЎеқ—еӨ„зҗҶ
йҳ…иҜ»е®ҢдёҠйқўзҡ„д»Јз ҒпјҢжҲ‘们еҸ‘зҺ°пјҢеҪ“йҒҮеҲ°жЁЎеқ—жҳҜдёҖдёӘж–Ү件еӨ№зҡ„ж—¶еҖҷдјҡжү§иЎҢ tryPackage еҮҪж•°зҡ„йҖ»иҫ‘пјҢдёӢйқўз®ҖиҰҒеҲҶжһҗдёҖдёӢе…·дҪ“е®һзҺ°гҖӮ
// е°қиҜ•еҠ иҪҪж ҮеҮҶжЁЎеқ— function tryPackage(requestPath, exts, isMain, originalPath) { const pkg = readPackageMain(requestPath); if (!pkg) { // еҰӮжһңжІЎжңү package.json иҝҷзӣҙжҺҘдҪҝз”Ё index дҪңдёәй»ҳи®Өе…ҘеҸЈж–Ү件 return tryExtensions(path.resolve(requestPath, "index"), exts, isMain); } const filename = path.resolve(requestPath, pkg); let actual = tryFile(filename, isMain) || tryExtensions(filename, exts, isMain) || tryExtensions(path.resolve(filename, "index"), exts, isMain); //... return actual; } // иҜ»еҸ– package.json дёӯзҡ„ main еӯ—ж®ө function readPackageMain(requestPath) { const pkg = readPackage(requestPath); return pkg ? pkg.main : undefined; }readPackage еҮҪж•°иҙҹиҙЈиҜ»еҸ–е’Ңи§Јжһҗ package.json ж–Ү件дёӯзҡ„еҶ…е®№пјҢе…·дҪ“жҸҸиҝ°еҰӮдёӢпјҡ
function readPackage(requestPath) { const jsonPath = path.resolve(requestPath, "package.json"); const existing = packageJsonCache.get(jsonPath); if (existing !== undefined) return existing; // и°ғз”Ё libuv uv_fs_open зҡ„жү§иЎҢйҖ»иҫ‘пјҢиҜ»еҸ– package.json ж–Ү件пјҢ并且缓еӯҳ const json = internalModuleReadJSON(path.toNamespacedPath(jsonPath)); if (json === undefined) { // жҺҘзқҖзј“еӯҳж–Ү件 packageJsonCache.set(jsonPath, false); return false; } //... try { const parsed = JSONParse(json); const filtered = { name: parsed.name, main: parsed.main, exports: parsed.exports, type: parsed.type }; packageJsonCache.set(jsonPath, filtered); return filtered; } catch (e) { //... } }дёҠйқўзҡ„дёӨж®өд»Јз Ғе®ҢзҫҺең°и§ЈйҮҠ package.json ж–Ү件зҡ„дҪңз”ЁпјҢжЁЎеқ—зҡ„й…ҚзҪ®е…ҘеҸЈпјҲ package.json дёӯзҡ„ main еӯ—ж®өпјүд»ҘеҸҠжЁЎеқ—зҡ„й»ҳи®Өж–Ү件дёәд»Җд№ҲжҳҜ indexпјҢе…·дҪ“жөҒзЁӢеҰӮдёӢеӣҫжүҖзӨәпјҡ
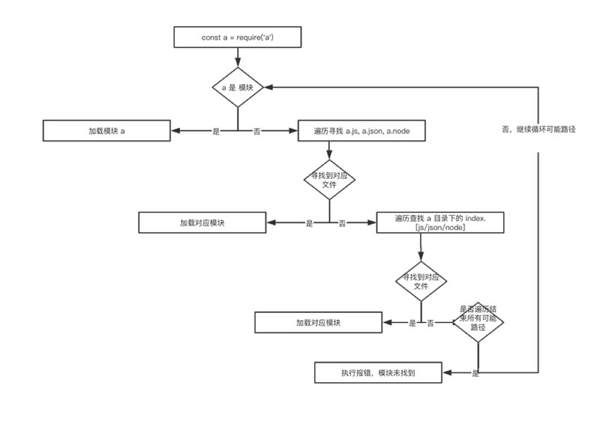
жЁЎеқ—ж–Ү件еӨ„зҗҶ
е®ҡдҪҚеҲ°еҜ№еә”жЁЎеқ—д№ӢеҗҺпјҢиҜҘеҰӮдҪ•еҠ иҪҪе’Ңи§Јжһҗе‘ўпјҹд»ҘдёӢжҳҜе…·дҪ“д»Јз ҒеҲҶжһҗпјҡ
Module.prototype.load = function(filename) { // дҝқиҜҒжЁЎеқ—жІЎжңүеҠ иҪҪиҝҮ assert(!this.loaded); this.filename = filename; // жүҫеҲ°еҪ“еүҚж–Ү件еӨ№зҡ„ node_modules this.paths = Module._nodeModulePaths(path.dirname(filename)); const extension = findLongestRegisteredExtension(filename); //... // жү§иЎҢзү№е®ҡж–Ү件еҗҺзјҖеҗҚи§ЈжһҗеҮҪж•° еҰӮ js / json / node Module._extensions[extension](this, filename); // иЎЁзӨәиҜҘжЁЎеқ—еҠ иҪҪжҲҗеҠҹ this.loaded = true; // ... зңҒз•Ҙ esm жЁЎеқ—зҡ„ж”ҜжҢҒ };еҗҺзјҖеӨ„зҗҶ
еҸҜд»ҘзңӢеҮәпјҢй’ҲеҜ№дёҚеҗҢзҡ„ж–Ү件еҗҺзјҖпјҢNode.js зҡ„еҠ иҪҪж–№ејҸжҳҜдёҚеҗҢзҡ„пјҢдёҖдёӢй’ҲеҜ№ .js, .json, .node з®ҖеҚ•иҝӣиЎҢеҲҶжһҗгҖӮ
.js еҗҺзјҖ js ж–Ү件иҜ»еҸ–дё»иҰҒйҖҡиҝҮ Node еҶ…зҪ® API fs.readFileSync е®һзҺ°гҖӮ
Module._extensions[".js"] = function(module, filename) { // иҜ»еҸ–ж–Ү件еҶ…е®№ const content = fs.readFileSync(filename, "utf8"); // зј–иҜ‘жү§иЎҢд»Јз Ғ module._compile(content, filename); };.json еҗҺзјҖ JSON ж–Ү件зҡ„еӨ„зҗҶйҖ»иҫ‘жҜ”иҫғз®ҖеҚ•пјҢиҜ»еҸ–ж–Ү件еҶ…е®№еҗҺжү§иЎҢ JSONParse еҚіеҸҜжӢҝеҲ°з»“жһңгҖӮ
Module._extensions[".json"] = function(module, filename) { // зӣҙжҺҘжҢүз…§ utf-8 ж јејҸеҠ иҪҪж–Ү件 const content = fs.readFileSync(filename, "utf8"); //... try { // д»Ҙ JSON еҜ№иұЎж јејҸеҜјеҮәж–Ү件еҶ…е®№ module.exports = JSONParse(stripBOM(content)); } catch (err) { //... } };.node еҗҺзјҖ .node ж–Ү件жҳҜдёҖз§Қз”ұ C / C++ е®һзҺ°зҡ„еҺҹз”ҹжЁЎеқ—пјҢйҖҡиҝҮ process.dlopen еҮҪж•°иҜ»еҸ–пјҢиҖҢ process.dlopen еҮҪж•°е®һйҷ…дёҠи°ғз”ЁдәҶ C++ д»Јз Ғдёӯзҡ„ DLOpen еҮҪж•°пјҢиҖҢ DLOpen дёӯеҸҲи°ғз”ЁдәҶ uv_dlopen, еҗҺиҖ…еҠ иҪҪ .node ж–Ү件пјҢзұ»дјј OS еҠ иҪҪзі»з»ҹзұ»еә“ж–Ү件гҖӮ
Module._extensions[".node"] = function(module, filename) { //... return process.dlopen(module, path.toNamespacedPath(filename)); };д»ҺдёҠйқўзҡ„дёүж®өжәҗз ҒпјҢжҲ‘们зңӢеҮәжқҘ并且еҸҜд»ҘзҗҶи§ЈпјҢеҸӘжңү JS еҗҺзјҖжңҖеҗҺдјҡжү§иЎҢе®һдҫӢж–№жі• _compile,жҲ‘们еҺ»йҷӨдёҖдәӣе®һйӘҢзү№жҖ§е’Ңи°ғиҜ•зӣёе…ізҡ„йҖ»иҫ‘жқҘз®ҖиҰҒзҡ„еҲҶжһҗдёҖдёӢиҝҷж®өд»Јз ҒгҖӮ
зј–иҜ‘жү§иЎҢ
жЁЎеқ—еҠ иҪҪе®ҢжҲҗеҗҺпјҢNode дҪҝз”Ё V8 еј•ж“ҺжҸҗдҫӣзҡ„ж–№жі•жһ„е»әиҝҗиЎҢжІҷз®ұпјҢ并жү§иЎҢеҮҪж•°д»Јз ҒпјҢд»Јз ҒеҰӮдёӢжүҖзӨәпјҡ
Module.prototype._compile = function(content, filename) { let moduleURL; let redirects; // еҗ‘жЁЎеқ—еҶ…йғЁжіЁе…Ҙе…¬е…ұеҸҳйҮҸ __dirname / __filename / module / exports / requireпјҢ并且编иҜ‘еҮҪж•° const compiledWrapper = wrapSafe(filename, content, this); const dirname = path.dirname(filename); const require = makeRequireFunction(this, redirects); let result; const exports = this.exports; const thisValue = exports; const module = this; if (requireDepth === 0) statCache = new Map(); //... // жү§иЎҢжЁЎеқ—дёӯзҡ„еҮҪж•° result = compiledWrapper.call( thisValue, exports, require, module, filename, dirname ); hasLoadedAnyUserCJSModule = true; if (requireDepth === 0) statCache = null; return result; }; // жіЁе…ҘеҸҳйҮҸзҡ„ж ёеҝғйҖ»иҫ‘ function wrapSafe(filename, content, cjsModuleInstance) { if (patched) { const wrapper = Module.wrap(content); // vm жІҷз®ұиҝҗиЎҢ пјҢзӣҙжҺҘиҝ”еӣһиҝҗиЎҢз»“жһңпјҢenv -> SetProtoMethod(script_tmpl, "runInThisContext", RunInThisContext); return vm.runInThisContext(wrapper, { filename, lineOffset: 0, displayErrors: true, // еҠЁжҖҒеҠ иҪҪ importModuleDynamically: async specifier => { const loader = asyncESM.ESMLoader; return loader.import(specifier, normalizeReferrerURL(filename)); } }); } let compiled; try { compiled = compileFunction( content, filename, 0, 0, undefined, false, undefined, [], ["exports", "require", "module", "__filename", "__dirname"] ); } catch (err) { //... } const { callbackMap } = internalBinding("module_wrap"); callbackMap.set(compiled.cacheKey, { importModuleDynamically: async specifier => { const loader = asyncESM.ESMLoader; return loader.import(specifier, normalizeReferrerURL(filename)); } }); return compiled.function; }дёҠиҝ°д»Јз ҒдёӯпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°еңЁ _compile еҮҪж•°дёӯи°ғз”ЁдәҶ wrapwrapSafe еҮҪж•°пјҢжү§иЎҢдәҶ __dirname / __filename / module / exports / require е…¬е…ұеҸҳйҮҸзҡ„жіЁе…ҘпјҢ并且и°ғз”ЁдәҶ C++ зҡ„ runInThisContext ж–№жі•пјҲдҪҚдәҺ src/node_contextify.cc ж–Ү件пјүжһ„е»әдәҶжЁЎеқ—д»Јз ҒиҝҗиЎҢзҡ„жІҷз®ұзҺҜеўғпјҢ并иҝ”еӣһдәҶ compiledWrapper еҜ№иұЎпјҢжңҖз»ҲйҖҡиҝҮ compiledWrapper.call ж–№жі•иҝҗиЎҢжЁЎеқ—гҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңNode.jsжЁЎеқ—зі»з»ҹжәҗз ҒеҲҶжһҗвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ