您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章为大家展示了如何进行Celery的安装使用,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
Celery 是 Distributed Task Queue,分布式任务队列。分布式决定了可以有多个 worker 的存在,队列表示其是异步操作。
Celery有一下5个核心角色
Task
就是任务,有异步任务和定时任务
Broker
中间人,接收生产者发来的消息即Task,将任务存入队列。任务的消费者是Worker。Celery本身不提供队列服务,推荐用Redis或RabbitMQ实现队列服务。
Worker
执行任务的单元,它实时监控消息队列,如果有任务就获取任务并执行它。
Beat
定时任务调度器,根据配置定时将任务发送给Broler。
Backend
用于存储任务的执行结果。
各个角色间的关系看下面这张图理解一下: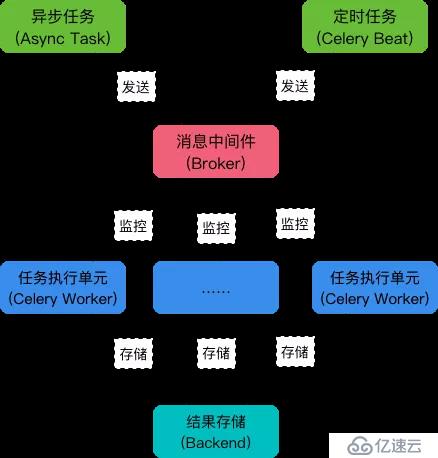
Celery4.x 开始不再支持Windows平台了。3.1.26是最后目前最新的3.x版本,下面装的是3.1.25。
pip install celery pip install celery==3.1.25
建议使用的Broker只有RabbitMQ和redis这两个。RabbitMQ只要准备好服务,不需要安装额外的模块。
如果要用redis,那么还要准备redis服务,以及安装redis模块:
pip install redis
上面的安装也可以用下面的命令把redis一起装上:
pip install -U 'celery[redis]'
使用命令 celery --version 查看版本,顺便验证:
>celery --version 'celery' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
这里报错是因为没有把celery加到环境变量里,所以找不到程序。不过我也不想加,所以把路径打全也好了:
>G:\Steed\Documents\PycharmProjects\venv\Celery\Scripts\celery --version 3.1.25 (Cipater)
这里跑一个简单的任务,最后再获取到任务的执行结果。
先按下面写一段代码:
# task1.py
from celery import Celery
# 创建Celery实例
app = Celery('tasks',
broker='redis://192.168.246.11:6379/0',
)
# 创建任务
@app.task
def add(x, y):
print("计算2个值的和: %s %s" % (x, y))
return x+y如果使用RabbitMQ,则把broker修改成这个 broker='amqp://192.168.3.108' 。
启动Celery Worker来开始监听并执行任务:
$ celery -A task1 worker --loglevel=info $ celery -A task1 worker --l debug # 或者可以这么起
参数 -A 后跟的是Celery实例,实例的名字可以省略,写全是 task1.app 。你要把目录切换到task1文件所在的目录执行命令,或者看看有没有参数能把文件目录加到python的环境变量中去。因为-A 之后的参数是作为python的模块来导入的。所以像下面这样,我也把Worker跑起来了:
G:\>G:\Steed\Documents\PycharmProjects\venv\Celery\Scripts\celery -A Steed.Documents.PycharmProjects.Celery.task1 worker --loglevel=info [2018-09-28 17:55:10,715: WARNING/MainProcess] g:\steed\documents\pycharmprojects\venv\celery\lib\site-packages\celery\apps\worker.py:161: CDeprecationWarning: Starting from version 3.2 Celery will refuse to accept pickle by default. The pickle serializer is a security concern as it may give attackers the ability to execute any command. It's important to secure your broker from unauthorized access when using pickle, so we think that enabling pickle should require a deliberate action and not be the default choice. If you depend on pickle then you should set a setting to disable this warning and to be sure that everything will continue working when you upgrade to Celery 3.2:: CELERY_ACCEPT_CONTENT = ['pickle', 'json', 'msgpack', 'yaml'] You must only enable the serializers that you will actually use. warnings.warn(CDeprecationWarning(W_PICKLE_DEPRECATED)) -------------- celery@IDX-xujf v3.1.25 (Cipater) ---- **** ----- --- * *** * -- Windows-10-10.0.17134-SP0 -- * - **** --- - ** ---------- [config] - ** ---------- .> app: tasks:0x1fb5056fda0 - ** ---------- .> transport: redis://192.168.246.11:6379/0 - ** ---------- .> results: disabled:// - *** --- * --- .> concurrency: 4 (prefork) -- ******* ---- --- ***** ----- [queues] -------------- .> celery exchange=celery(direct) key=celery [tasks] . Steed.Documents.PycharmProjects.Celery.task1.add [2018-09-28 17:55:10,864: INFO/MainProcess] Connected to redis://192.168.246.11:6379/0 [2018-09-28 17:55:10,922: INFO/MainProcess] mingle: searching for neighbors [2018-09-28 17:55:11,961: INFO/MainProcess] mingle: all alone [2018-09-28 17:55:11,980: WARNING/MainProcess] celery@IDX-xujf ready.
要给Worker发送任务,需要调用 delay() 方法,下面是在IDLE上操作的:
>>> import sys >>> dir = r"G:\Steed\Documents\PycharmProjects\Celery" >>> sys.path.append(dir) # 我的任务文件不在环境变量里,IDLE找不到 >>> from task1 import add >>> add.delay(1, 2) <AsyncResult: 4f6613cb-3d2c-4a5e-ae58-bf9f28c3ec0a> >>>
Worker显示了下面这些信息
[2018-09-29 11:10:33,103: INFO/MainProcess] Received task: task1.add[4f6613cb-3d2c-4a5e-ae58-bf9f28c3ec0a] [2018-09-29 11:10:33,107: WARNING/Worker-1] 计算2个值的和: 1 2 [2018-09-29 11:10:33,109: INFO/MainProcess] Task task1.add[4f6613cb-3d2c-4a5e-ae58-bf9f28c3ec0a] succeeded in 0s: 3
上面只是一个发送任务的调用,结果是拿不到的。上面也没有接收返回值,这次把返回值保存到起来:
>>> t = add.delay(3, 4) >>> type(t) # 查看返回值的类型 <class 'celery.result.AsyncResult'> >>> t.get() # 这句会报错 Traceback (most recent call last): File "<pyshell#16>", line 1, in <module> t.get() File "G:\Steed\Documents\PycharmProjects\venv\Celery\Lib\site-packages\celery\result.py", line 169, in get no_ack=no_ack, File "G:\Steed\Documents\PycharmProjects\venv\Celery\Lib\site-packages\celery\backends\base.py", line 616, in _is_disabled 'No result backend configured. ' NotImplementedError: No result backend configured. Please see the documentation for more information.
这里是实例化的时候,没有定义backend,就是保存任务结果的位置。
修改最初的任务的代码,在实例化的时候加上backend参数,指定保存任务结果的位置。这里把结果也存到同一个redis里:
from celery import Celery
app = Celery('tasks',
broker='redis://192.168.246.11',
backend='redis://192.168.246.11', # 这次把端口号什么的都省了
)
@app.task
def add(x, y):
print("计算2个值的和: %s %s" % (x, y))
return x+y然后要重启Worker,IDLE也要重启,现在可以获取到任务的返回结果了:
>>> t = add.delay(1, 1) >>> t.get() 2 >>>
如果是RabbitMQ,则app的初始话设置就这么写:
app = Celery('tasks',
broker='amqp://192.168.3.108',
backend='rpc://192.168.3.108', # 新版本rpc将初步替代amqp,用的还是RabbitMQ
# backend='amqp://192.168.3.108', # 如果是旧版本,没有rpc,那只能用amqp
)get进入阻塞
上面的任务执行的太快了,准备一个需要执行一段时间的任务:
import time @app.task def upper(v): for i in range(10): time.sleep(1) print(i) return v.upper()
用get调用任务会进入阻塞,直到任务返回结果,这样就没有异步的效果了:
>>> t = upper.delay("abc")
>>> t.get()
'ABC'ready获取任务是否完成,不阻塞
ready()方法可以返回任务是否执行完成,等到返回True了再去get,马上能拿到结果:
>>> t = upper.delay("abcd")
>>> t.ready()
False
>>> t.ready()
False
>>> t.ready()
False
>>> t.ready()
True
>>> t.get()
'ABCD'
>>get设置超时时间
还可以给get设置一个超时时间,如果超时,会抛出异常:
>>> t = upper.delay("abcde")
>>> t.get(timeout=11)
'ABCDE'
>>> t = upper.delay("abcde")
>>> t.get(timeout=1)
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
t.get(timeout=1)
File "G:\Steed\Documents\PycharmProjects\venv\Celery\lib\site-packages\celery\result.py", line 169, in get
no_ack=no_ack,
File "G:\Steed\Documents\PycharmProjects\venv\Celery\lib\site-packages\celery\backends\base.py", line 238, in wait_for
raise TimeoutError('The operation timed out.')
celery.exceptions.TimeoutError: The operation timed out.
>>>任务报错
如果任务执行报错,比如执行这个任务:
>>> t = upper.delay(123) >>>
那么Worker那边会显示错误的内容:
[2018-09-29 12:57:07,077: ERROR/MainProcess] Task task1.upper[11820ee6-6936-4680-93c2-462487ec927e] raised unexpected: AttributeError("'int' object has no attribute 'upper'",)
Traceback (most recent call last):
File "g:\steed\documents\pycharmprojects\venv\celery\lib\site-packages\celery\app\trace.py", line 240, in trace_task
R = retval = fun(*args, **kwargs)
File "g:\steed\documents\pycharmprojects\venv\celery\lib\site-packages\celery\app\trace.py", line 438, in __protected_call__
return self.run(*args, **kwargs)
File "G:\Steed\Documents\PycharmProjects\Celery\task1.py", line 25, in upper
return v.upper()
AttributeError: 'int' object has no attribute 'upper'然后再get结果的时候,会把这个错误作为异常抛出,这样很不友好:
>>> t = upper.delay(123) >>> t.get() Traceback (most recent call last): File "<pyshell#27>", line 1, in <module> t.get() File "G:\Steed\Documents\PycharmProjects\venv\Celery\lib\site-packages\celery\result.py", line 175, in get raise meta['result'] AttributeError: 'int' object has no attribute 'upper' >>>
get设置只获取错误结果,不触发异常
>>> t.get(propagate=False)
AttributeError("'int' object has no attribute 'upper'",)
>>>traceback 里面存着错误信息
>>> t.traceback 'Traceback (most recent call last):\n File "g:\\steed\\documents\\pycharmprojects\\venv\\celery\\lib\\site-packages\\celery\\app\\trace.py", line 240, in trace_task\n R = retval = fun(*args, **kwargs)\n File "g:\\steed\\documents\\pycharmprojects\\venv\\celery\\lib\\site-packages\\celery\\app\\trace.py", line 438, in __protected_call__\n return self.run(*args, **kwargs)\n File "G:\\Steed\\Documents\\PycharmProjects\\Celery\\task1.py", line 25, in upper\n return v.upper()\nAttributeError: \'int\' object has no attribute \'upper\'\n' >>>
启动Celery Worker来开始监听并执行任务
$ celery -A tasks worker --loglevel=info
调用任务
>>> from tasks import add >>> t = add.delay(4, 4)
同步拿结果
>>> t.get() >>> t.get(timeout=1)
检查任务是否完成
>>> t.ready()
如果出错,获取错误结果,不触发异常
>>> t.get(propagate=False) >>> t.traceback # 打印异常详细结果
可以把celery配置成一个应用,假设应用名字是CeleryPro,目录格式如下:
CeleryPro ├─__init.py ├─celery.py ├─tasks.py
这里的连接文件命名必须为celery.py,其他名字随意
这个文件名必须是celery.py:
from __future__ import absolute_import, unicode_literals
from celery import Celery
app = Celery('CeleryPro',
broker='redis://192.168.246.11',
backend='redis://192.168.246.11',
include=['CeleryPro.tasks'])
# Optional configuration, see the application user guide.
app.conf.update(
result_expires=3600,
)
if __name__ == '__main__':
app.start()第一句 from __future__ import absolute_import, unicode_literals ,后面的unicode_literals不知道是什么。不过前面的absolute_import是绝对引入。因为这个文件的文件名就是celery,所以默认后面的 form celery 是引入这个文件,但我们实际需要的是引入celery模块,所以用了绝对引入这个模块。如果要引入这个文件,可以这么写 from .celery ,加个点,下面的tasks里会用到
这个文件开始两行就多了一个点,这里要导入上面的celery.py文件。后面只要写各种任务加上装饰器就可以了:
from __future__ import absolute_import, unicode_literals
from .celery import app
import time
@app.task
def add(x, y):
print("计算2个值的和: %s %s" % (x, y))
return x+y
@app.task
def upper(v):
for i in range(10):
time.sleep(1)
print(i)
return v.upper()启动的时候,-A 参数后面用应用名称 CeleryPro 。你还需要cd到你CeleryPro的父级目录上启动,否则找不到:
>G:\Steed\Documents\PycharmProjects\venv\Celery\Scripts\celery -A CeleryPro worker -l info [2018-09-29 15:06:20,818: WARNING/MainProcess] g:\steed\documents\pycharmprojects\venv\celery\lib\site-packages\celery\apps\worker.py:161: CDeprecationWarning: Starting from version 3.2 Celery will refuse to accept pickle by default. The pickle serializer is a security concern as it may give attackers the ability to execute any command. It's important to secure your broker from unauthorized access when using pickle, so we think that enabling pickle should require a deliberate action and not be the default choice. If you depend on pickle then you should set a setting to disable this warning and to be sure that everything will continue working when you upgrade to Celery 3.2:: CELERY_ACCEPT_CONTENT = ['pickle', 'json', 'msgpack', 'yaml'] You must only enable the serializers that you will actually use. warnings.warn(CDeprecationWarning(W_PICKLE_DEPRECATED)) -------------- celery@IDX-xujf v3.1.25 (Cipater) ---- **** ----- --- * *** * -- Windows-10-10.0.17134-SP0 -- * - **** --- - ** ---------- [config] - ** ---------- .> app: CeleryPro:0x21deadaf470 - ** ---------- .> transport: redis://192.168.246.11:6379// - ** ---------- .> results: redis://192.168.246.11/ - *** --- * --- .> concurrency: 4 (prefork) -- ******* ---- --- ***** ----- [queues] -------------- .> celery exchange=celery(direct) key=celery [tasks] . CeleryPro.tasks.add . CeleryPro.tasks.upper [2018-09-29 15:06:20,953: INFO/MainProcess] Connected to redis://192.168.246.11:6379// [2018-09-29 15:06:20,983: INFO/MainProcess] mingle: searching for neighbors [2018-09-29 15:06:21,994: INFO/MainProcess] mingle: all alone [2018-09-29 15:06:22,055: WARNING/MainProcess] celery@IDX-xujf ready.
各种启动的姿势
这里注意用的都是CeleryPro:
celery -A CeleryPro worker -loglevel=info # 前台启动不推荐 celery -A CeleryPro worker -l info # 前台启动简写 celery multi start w1 -A CeleryPro -l info # 推荐用后台启动
调用任务也是在CeleryPro的父级目录下调用就好了,各种用法都一样。
操作都要在CeleryPro的父级目录下执行,就是说只要保证CeleryPro的父级目录在环境变量里。或者用 sys.path.append() 加到环境变量里去。
这里理解为把celery包装成了你项目里的一个应用,应用的内容都放在了CeleryPro这个文件夹下。而CeleryPro就作为你的项目里的一个模块。而你项目的主目录一定在项目启动的时候加到环境变量里的,所以其实这样包装好之后再项目里使用应该很方便。
启动命令:
celery -A 项目名 worker -loglevel=info : 前台启动命令
celery multi start w1 -A 项目名 -l info : 后台启动命令
celery multi restart w1 -A 项目名 -l info : 后台重启命令
celery multi stop w1 -A 项目名 -l info : 后台停止命令
前后台的区别:后台是通过mult启动的。
w1是worker的名称,可以后台启动多个worker,每个worker有一个一名称。
即便是所有的worker都已经done了,用户任然启动了任务,所有的任务都会保留,直到有worker来执行并返回结果。
如果前台启动的worker断开了,那么worker的任务会消失;如果后台启动的worker断开了,后台的任务仍然在。没太理解这句的意思。
查看当前还有多少个Celery的worker
似乎也就只能通过ps来查看了,下面先起了3个后台Worker,ps看一下,然后停掉了一个Worker,再用ps看了一下:
[root@Python3 ~]# celery multi start w1 -A CeleryPro -l info celery multi v4.2.1 (windowlicker) > Starting nodes... > w1@Python3: OK [root@Python3 ~]# celery multi start w2 -A CeleryPro -l info celery multi v4.2.1 (windowlicker) > Starting nodes... > w2@Python3: OK [root@Python3 ~]# celery multi start w3 -A CeleryPro -l info celery multi v4.2.1 (windowlicker) > Starting nodes... > w3@Python3: OK [root@Python3 ~]# ps -ef | grep celery root 1346 1 0 20:49 ? 00:00:01 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w1%I.log --pidfile=w1.pid --hostname=w1@Python3 root 1350 1346 0 20:49 ? 00:00:00 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w1%I.log --pidfile=w1.pid --hostname=w1@Python3 root 1360 1 0 20:49 ? 00:00:01 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w2%I.log --pidfile=w2.pid --hostname=w2@Python3 root 1364 1360 0 20:49 ? 00:00:00 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w2%I.log --pidfile=w2.pid --hostname=w2@Python3 root 1374 1 0 20:49 ? 00:00:01 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w3%I.log --pidfile=w3.pid --hostname=w3@Python3 root 1378 1374 0 20:49 ? 00:00:00 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w3%I.log --pidfile=w3.pid --hostname=w3@Python3 root 1391 1251 0 20:55 pts/0 00:00:00 grep --color=auto celery [root@Python3 ~]# celery multi stop w1 celery multi v4.2.1 (windowlicker) > Stopping nodes... > w1@Python3: TERM -> 1346 [root@Python3 ~]# ps -ef | grep celery root 1360 1 0 20:49 ? 00:00:01 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w2%I.log --pidfile=w2.pid --hostname=w2@Python3 root 1364 1360 0 20:49 ? 00:00:00 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w2%I.log --pidfile=w2.pid --hostname=w2@Python3 root 1374 1 0 20:49 ? 00:00:01 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w3%I.log --pidfile=w3.pid --hostname=w3@Python3 root 1378 1374 0 20:49 ? 00:00:00 /usr/bin/python3.6 -m celery worker -A CeleryPro -l info --logfile=w3%I.log --pidfile=w3.pid --hostname=w3@Python3 root 1398 1251 0 20:57 pts/0 00:00:00 grep --color=auto celery [root@Python3 ~]#
错误信息如下:
File "g:\steed\documents\pycharmprojects\venv\celery\lib\site-packages\celery\platforms.py", line 429, in detached
raise RuntimeError('This platform does not support detach.')
RuntimeError: This platform does not support detach.
> w1@IDX-xujf: * Child terminated with errorcode 1
FAILED根据错误信息查看一下429行的代码:
if not resource:
raise RuntimeError('This platform does not support detach.')这里判断了一下resource,然后就直接抛出异常了。resource具体是什么,可以在这个文件里搜索一下变量名(resource)
# 在开头获取了这个resource的值
resource = try_import('resource')
# 上面的try_import方法,在另外一个文件里
def try_import(module, default=None):
"""Try to import and return module, or return
None if the module does not exist."""
try:
return importlib.import_module(module)
except ImportError:
return default
# 下面有一个方法注释里表明resource为None代表是Windows
def get_fdmax(default=None):
"""Return the maximum number of open file descriptors
on this system.
:keyword default: Value returned if there's no file
descriptor limit.
"""
try:
return os.sysconf('SC_OPEN_MAX')
except:
pass
if resource is None: # Windows
return default
fdmax = resource.getrlimit(resource.RLIMIT_NOFILE)[1]
if fdmax == resource.RLIM_INFINITY:
return default
return fdmax上面做的就是要尝试导入一个模块 “resource” 。该模块只用于Unix。
3版本的定时任务和4版本还是有很大差别的。另外4版本里有更多的定时任务。
继续使用之前的2个任务,只需要为celery添加一些配置(conf),为任务设置计划。
app.conf里的参数都是全大写的,这里大小写敏感,不能用小写:
# CeleryPro/tasks.py
from __future__ import absolute_import, unicode_literals
from .celery import app
import time
@app.task
def add(x, y):
print("计算2个值的和: %s %s" % (x, y))
return x+y
@app.task
def upper(v):
for i in range(10):
time.sleep(1)
print(i)
return v.upper()
# CeleryPro/celery.py
from __future__ import absolute_import, unicode_literals
from celery import Celery
from celery.schedules import crontab
from datetime import timedelta
app = Celery('CeleryPro',
broker='redis://192.168.246.11',
backend='redis://192.168.246.11',
include=['CeleryPro.tasks'])
app.conf.CELERYBEAT_SCHEDULE = {
'add every 10 seconds': {
'task': 'CeleryPro.tasks.add',
'schedule': timedelta(seconds=10), # 可以用timedelta对象
# 'schedule': 10, # 也支持直接用数字表示秒数
'args': (1, 2)
},
'upper every 2 minutes': {
'task': 'CeleryPro.tasks.upper',
'schedule': crontab(minute='*/2'),
'args': ('abc', ),
},
}
# app.conf.CELERY_TIMEZONE = 'UTC'
app.conf.CELERY_TIMEZONE = 'Asia/Shanghai'
# Optional configuration, see the application user guide.
app.conf.update(
CELERY_TASK_RESULT_EXPIRES=3600,
)
if __name__ == '__main__':
app.start()任务结果过期设置 `CELERY_TASK_RESULT_EXPIRES=3600' 。默认设置是1天,官网介绍这是靠一个内置的周期性任务把超过时限的任务结果给清除的。
A built-in periodic task will delete the results after this time (celery.task.backend_cleanup).
设置完成后,启动Worker,启动Beat就OK了:
G:\Steed\Documents\PycharmProjects\Celery>G:\Steed\Documents\PycharmProjects\venv\Celery\Scripts\celery.exe -A CeleryPro worker -l info G:\Steed\Documents\PycharmProjects\Celery>G:\Steed\Documents\PycharmProjects\venv\Celery\Scripts\celery.exe -A CeleryPro beat -l info
3版本里的参数都是全大写的,到了4版本开始改用小写了,并且很多参数名也变了。这里有新旧参数的对应关系:
http://docs.celeryproject.org/en/latest/userguide/configuration.html#configuration
新版的好处是,可以把定时任务和普通的任务一样单独定义了。多了 @app.on_after_configure.connect 这个装饰器,3版本是没有这个装饰器的。
写代码
单独再创建一个py文件,存放定时任务:
# CeleryPro/periodic4.py
from __future__ import absolute_import, unicode_literals
from .celery import app
from celery.schedules import crontab
@app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
# 每10秒执行一次
sender.add_periodic_task(10.0, hello.s(), name='hello every 10') # 给任务取个名字
# 每30秒执行一次
sender.add_periodic_task(30, upper.s('abcdefg'), expires=10) # 设置任务超时时间10秒
# 执行周期和Linux的计划任务crontab设置一样
sender.add_periodic_task(
crontab(hour='*', minute='*/2', day_of_week='*'),
add.s(11, 22),
)
@app.task
def hello():
print('Hello World')
@app.task
def upper(arg):
return arg.upper()
@app.task
def add(x, y):
print("计算2个值的和: %s %s" % (x, y))
return x+y上面一共定了3个计划。
name参数给计划取名,这样这个任务报告的时候就会使用name的值,像这样:hello every 10。否则默认显示的是调用函数的命令,像这样:CeleryPro.periodic4.upper('abcdefg') 。
expires参数设置任务超时时间,超时未完成,可能就放弃了(没测试)。
修改一下之前的celery.py文件,把新写的任务文件添加到include的列表里。顺便我这里改用RabbitMQ玩一下:
# CeleryPro/celery.py
from __future__ import absolute_import, unicode_literals
from celery import Celery
app = Celery('CeleryPro',
broker='amqp://192.168.3.108',
backend='rpc',
include=['CeleryPro.tasks', 'CeleryPro.periodic4'])
app.conf.timezone = 'UTC' # 计划任务默认用的是UTC时间
# app.conf.timezone = 'Asia/Shanghai' # 也可以更改为北京时间
# Optional configuration, see the application user guide.
app.conf.update(
result_expires=3600,
)
if __name__ == '__main__':
app.start()启动worker
启动方法和之前一样:
[root@Python3 ~]# celery -A CeleryPro worker -l info /usr/local/lib/python3.6/site-packages/celery/platforms.py:796: RuntimeWarning: You're running the worker with superuser privileges: this is absolutely not recommended! Please specify a different user using the --uid option. User information: uid=0 euid=0 gid=0 egid=0 uid=uid, euid=euid, gid=gid, egid=egid, -------------- celery@Python3 v4.2.1 (windowlicker) ---- **** ----- --- * *** * -- Linux-3.10.0-862.el7.x86_64-x86_64-with-centos-7.5.1804-Core 2018-10-01 12:46:35 -- * - **** --- - ** ---------- [config] - ** ---------- .> app: CeleryPro:0x7ffb0c8b2908 - ** ---------- .> transport: amqp://guest:**@192.168.3.108:5672// - ** ---------- .> results: rpc:// - *** --- * --- .> concurrency: 1 (prefork) -- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker) --- ***** ----- -------------- [queues] .> celery exchange=celery(direct) key=celery [tasks] . CeleryPro.periodic4.add . CeleryPro.periodic4.hello . CeleryPro.periodic4.upper . CeleryPro.tasks.add . CeleryPro.tasks.upper [2018-10-01 12:46:35,187: INFO/MainProcess] Connected to amqp://guest:**@192.168.3.108:5672// [2018-10-01 12:46:35,216: INFO/MainProcess] mingle: searching for neighbors [2018-10-01 12:46:36,266: INFO/MainProcess] mingle: all alone [2018-10-01 12:46:36,307: INFO/MainProcess] celery@Python3 ready.
启动后看一下[tasks],新加的定时任务已经列出来了,之前的任务也都在。
启动Beat
这里-A后面要写全 CeleryPro.periodic4 ,和启动Worker的参数有点不一样:
[root@Python3 ~]# celery -A CeleryPro.periodic4 beat -l info
celery beat v4.2.1 (windowlicker) is starting.
__ - ... __ - _
LocalTime -> 2018-10-01 12:45:04
Configuration ->
. broker -> amqp://guest:**@192.168.3.108:5672//
. loader -> celery.loaders.app.AppLoader
. scheduler -> celery.beat.PersistentScheduler
. db -> celerybeat-schedule
. logfile -> [stderr]@%INFO
. maxinterval -> 5.00 minutes (300s)
[2018-10-01 12:45:04,934: INFO/MainProcess] beat: Starting...
[2018-10-01 12:45:05,006: INFO/MainProcess] Scheduler: Sending due task hello every 10 (CeleryPro.periodic4.hello)
[2018-10-01 12:45:05,356: INFO/MainProcess] Scheduler: Sending due task CeleryPro.periodic4.upper('abcdefg') (CeleryPro.periodic4.upper)启动之后马上就把2个每隔一段时间执行的任务发送给Worker执行了,之后会根据定义的间隔继续发送。
另外一个用crontab设置的任务需要等到时间匹配上了才会发送。当时是45分,等到46分就会执行了。
旧版本的做法一样可以用
上面说了,新版主要是多提供了一个装饰器。不用新提供的装饰器,依然可以把定时任务写在配置里:
# CeleryPro/celery.py
from __future__ import absolute_import, unicode_literals
from celery import Celery
app = Celery('CeleryPro',
broker='amqp://192.168.3.108',
backend='rpc',
include=['CeleryPro.tasks'])
app.conf.beat_schedule = {
'every 5 seconds': {
'task': 'CeleryPro.tasks.upper',
'schedule': 5,
'args': ('xyz',)
}
}
# Optional configuration, see the application user guide.
app.conf.update(
result_expires=3600,
)
if __name__ == '__main__':
app.start()这里就是在配置里设置,定时启动一个普通任务。这里把include里的CeleryPro.periodic4删掉了,留着也没影响。
任务文件tasks.py还是之前的那个,具体如下:
# CeleryPro/tasks.py
from __future__ import absolute_import, unicode_literals
from .celery import app
import time
@app.task
def add(x, y):
print("计算2个值的和: %s %s" % (x, y))
return x+y
@app.task
def upper(v):
for i in range(10):
time.sleep(1)
print(i)
return v.upper()最后启动Worker,启动Breat试一下:
[root@Python3 ~]# celery -A CeleryPro beat -l info
这里Beat的-A参数用 CeleryPro 也能启动这里的定时任务。CeleryPro.tasks 效果也是一样的。另外如果把periodic4.py加到include列表里去,用 CeleryPro.periodic4 参数启动的话,这里的定时任务也会启动。
这里也是支持用crontab的,用法和之前的一样,把schedule参数的值换成调用crontab的函数。
上面的两种定时任务的方法,各有应用场景。
如果要改任务执行的函数,只能改代码,然后重启Worker了。
这里要说的是改计划(包括新增、取消和修改计划周期),但是任务执行的函数不变。用@app.on_after_configure.connect装饰器,是把计划写死在一个函数里了。似乎无法动态添加新任务。不过好处是结构比较清晰。
而后一种方法,只要更新一下 app.conf.beat_schedule 这个字典里的配置信息,然后重启Beat就能生效了。
下面是crontab的一些例子:
| Example | Meaning |
|---|---|
| crontab() | Execute every minute. |
| crontab(minute=0, hour=0) | Execute daily at midnight. |
| crontab(minute=0, hour='*/3') | Execute every three hours: 3am, 6am, 9am, noon, 3pm, 6pm, 9pm. |
| crontab(minute=0,hour='0,3,6,9,12,15,18,21') | Same as previous. |
| crontab(minute='*/15') | Execute every 15 minutes. |
| crontab(day_of_week='sunday') | Execute every minute (!) at Sundays. |
| crontab(minute='',hour='', day_of_week='sun') | Same as previous. |
| crontab(minute='*/10',hour='3,17,22', day_of_week='thu,fri') | Execute every ten minutes, but only between 3-4 am, 5-6 pm and 10-11 pm on Thursdays or Fridays. |
| crontab(minute=0, hour='/2,/3') | Execute every even hour, and every hour divisible by three. This means: at every hour except: 1am, 5am, 7am, 11am, 1pm, 5pm, 7pm, 11pm |
| crontab(minute=0, hour='*/5') | Execute hour divisible by 5. This means that it is triggered at 3pm, not 5pm (since 3pm equals the 24-hour clock value of “15”, which is divisible by 5). |
| crontab(minute=0, hour='*/3,8-17') | Execute every hour divisible by 3, and every hour during office hours (8am-5pm). |
| crontab(day_of_month='2') | Execute on the second day of every month. |
| crontab(day_of_month='2-30/3') | Execute on every even numbered day. |
| crontab(day_of_month='1-7,15-21') | Execute on the first and third weeks of the month. |
| crontab(day_of_month='11',month_of_year='5') | Execute on 11th of May every year. |
| crontab(month_of_year='*/3') | Execute on the first month of every quarter. |
4版本里还提供这样的方法来指定计划
If you have a task that should be executed according to sunrise, sunset, dawn or dusk, you can use the solar schedule type:
如果你有一个任务,是根据日出,日落,黎明或黄昏来执行的,你可以使用日程表类型:
所有事件都是根据UTC时间计算的,所以不受时区设置影响。官网的例子:
from celery.schedules import solar
app.conf.beat_schedule = {
# Executes at sunset in Melbourne
'add-at-melbourne-sunset': {
'task': 'tasks.add',
'schedule': solar('sunset', -37.81753, 144.96715),
'args': (16, 16),
},
}这里solar函数要提供3个参数,事件、纬度、经度。经纬度使用的标志看下表:
| Sign | Argument | Meaning |
|---|---|---|
| + | latitude | North |
| - | latitude | South |
| + | longitude | East |
| - | longitude | West |
支持的事件类型如下:
| Event | Meaning |
|---|---|
| dawn_astronomical | Execute at the moment after which the sky is no longer completely dark. This is when the sun is 18 degrees below the horizon. |
| dawn_nautical | Execute when there’s enough sunlight for the horizon and some objects to be distinguishable; formally, when the sun is 12 degrees below the horizon. |
| dawn_civil | Execute when there’s enough light for objects to be distinguishable so that outdoor activities can commence; formally, when the Sun is 6 degrees below the horizon. |
| sunrise | Execute when the upper edge of the sun appears over the eastern horizon in the morning. |
| solar_noon | Execute when the sun is highest above the horizon on that day. |
| sunset | Execute when the trailing edge of the sun disappears over the western horizon in the evening. |
| dusk_civil | Execute at the end of civil twilight, when objects are still distinguishable and some stars and planets are visible. Formally, when the sun is 6 degrees below the horizon. |
| dusk_nautical | Execute when the sun is 12 degrees below the horizon. Objects are no longer distinguishable, and the horizon is no longer visible to the naked eye. |
| dusk_astronomical | Execute at the moment after which the sky becomes completely dark; formally, when the sun is 18 degrees below the horizon. |
在django中使用的话,可以把celery的配置直接写在django的settings.py文件里。另外任务函数则写在tasks.py文件里放在各个app的目录下。每个app下都可以有一个tasks.py,所有的任务都是共享的。
创建一个django的项目,项目名称就叫UsingCeleryWithDjango,app的名字就app01好了。创建好项目后,在项目目录下创建CeleryPro目录,目录下建一个celery.py文件。目录结构如下:
UsingCeleryWithDjango │ ├─manage.py │ ├─app01 │ │ admin.py │ │ apps.py │ │ models.py │ │ tests.py │ │ views.py │ └ __init__.py │ ├─CeleryPro │ │ celery.py │ └ __init__.py │ ├─templates │ └─UsingCeleryWithDjango │ settings.py │ urls.py │ wsgi.py └ __init__.py
上面只要关注一下CeleryPro的结构和位置就好了,其他都是创建django项目后的默认内容。
CeleryPro/celery.py 文件,是用来创建celery实例的。
CeleryPro/__init__.py 文件,需要确保当Django启动时加载celery。之后在app里会用到celery模块里的 @shared_task 这个装饰器。
具体的示例文件在官方的github里,3版本和4版本有一些的区别。
最新版的:https://github.com/celery/celery/tree/master/examples/django
3.1版本的:https://github.com/celery/celery/tree/3.1/examples/django
Github里也可以自行切换各个版本的分支查看。
下面我就在Windows上用3.1.25版本搞一遍了。
# UsingCeleryWithDjango/CeleryPro/__init__.py
from __future__ import absolute_import, unicode_literals
__author__ = '749B'
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ('celery_app',)
# UsingCeleryWithDjango/CeleryPro/celery.py
from __future__ import absolute_import
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'UsingCeleryWithDjango.settings')
from django.conf import settings # noqa
app = Celery('CeleryPro')
# Using a string here means the worker will not have to
# pickle the object when using Windows.
app.config_from_object('django.conf:settings')
# 自动发现所有app下的tasks
# 但是,新版django的INSTALLED_APPS的写法无法发现到
# app.autodiscover_tasks(lambda: settings.INSTALLED_APPS) # 这是官方示例的写法
'''
# 这里是setting.py里的INSTALLED_APPS部分
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config', # 这种写法自动发现找不到tasks
# 'app01', # 这种写法就能自动发现
]
'''
# 或者不想改settings.INSTALLED_APPS,那就自己把app的列表写在一个列表里作为参数吧
app.autodiscover_tasks(['app01']) # 这里我就这么
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))这里有个坑,我写了一段注释,写的应该比较清楚了。
在app下创建tasks.py文件(和models.py文件同一级目录),创建任务。
- app01/ - app01/tasks.py - app01/models.py
tasks.py文件里创建的函数用的是 @shared_task 这个装饰器。这些任务是所有app共享的。
# UsingCeleryWithDjango/app01/tasks.py # Create your tasks here from __future__ import absolute_import, unicode_literals from celery import shared_task @shared_task def add(x, y): return x + y @shared_task def mul(x, y): return x * y @shared_task def xsum(numbers): return sum(numbers)
这个是django的配置文件,不过现在celery的配置也都可以写在这里了:
# UsingCeleryWithDjango/UsingCeleryWithDjango/settings.py # 其他都是django的配置内容,就省了 # Celery settings BROKER_URL = 'redis://192.168.246.11/0' CELERY_RESULT_BACKEND = 'redis://192.168.246.11/0'
这里就做最基本的设置,用redis收任务和存任务结果,其他都默认了设置了。
启动命令是一样的,关键就是-A后面的参数:
G:\Steed\Documents\PycharmProjects\UsingCeleryWithDjango>G:\Steed\Documents\PycharmProjects\venv\UsingCeleryWithDjango\Scripts\celery -A CeleryPro worker -l info
[2018-10-02 20:55:56,411: WARNING/MainProcess] g:\steed\documents\pycharmprojects\venv\usingcelerywithdjango\lib\site-packages\celery\apps\worker.py:161: CDeprecationWarning:
Starting from version 3.2 Celery will refuse to accept pickle by default.
The pickle serializer is a security concern as it may give attackers
the ability to execute any command. It's important to secure
your broker from unauthorized access when using pickle, so we think
that enabling pickle should require a deliberate action and not be
the default choice.
If you depend on pickle then you should set a setting to disable this
warning and to be sure that everything will continue working
when you upgrade to Celery 3.2::
CELERY_ACCEPT_CONTENT = ['pickle', 'json', 'msgpack', 'yaml']
You must only enable the serializers that you will actually use.
warnings.warn(CDeprecationWarning(W_PICKLE_DEPRECATED))
-------------- celery@IDX-xujf v3.1.25 (Cipater)
---- **** -----
--- * *** * -- Windows-10-10.0.17134-SP0
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: CeleryPro:0x27f5e4dbe80
- ** ---------- .> transport: redis://192.168.246.11:6379/0
- ** ---------- .> results: redis://192.168.246.11/0
- *** --- * --- .> concurrency: 4 (prefork)
-- ******* ----
--- ***** ----- [queues]
-------------- .> celery exchange=celery(direct) key=celery
[tasks]
. CeleryPro.celery.debug_task
. app01.tasks.add
. app01.tasks.mul
. app01.tasks.xsum
[2018-10-02 20:55:56,548: INFO/MainProcess] Connected to redis://192.168.246.11:6379/0
[2018-10-02 20:55:56,576: INFO/MainProcess] mingle: searching for neighbors
[2018-10-02 20:55:57,596: INFO/MainProcess] mingle: all alone
[2018-10-02 20:55:57,647: WARNING/MainProcess] g:\steed\documents\pycharmprojects\venv\usingcelerywithdjango\lib\site-packages\celery\fixups\django.py:265: UserWarning: Using settings.DEBUG leads to a memory leak, never use this setting in production environments!
warnings.warn('Using settings.DEBUG leads to a memory leak, never '
[2018-10-02 20:55:57,653: WARNING/MainProcess] celery@IDX-xujf ready.上面这样就是成功启动了,确认一下[tasks]下面的任务是否都有就没问题了。
关于这个[tasks]下面的内容,就是所有我们自定义的任务的名字,下面研究了一下自己如何获取到这些任务名字
所有的tasks都可以通过app.tasks获取到。这个app就是 CeleryPro/celery.py 里 app = Celery('CeleryPro') 生成的实例。并且在 CeleryPro/__init__.py 里通过 from .celery import app as celery_app 换了个别名,所以在这个项目里应该是 celery_app.tasks 。
打印celery_app.tasks结果如下:
{'celery.chord_unlock': <@task: celery.chord_unlock of CeleryPro:0x2360b07fc88>, 'celery.group': <@task: celery.group of CeleryPro:0x2360b07fc88>, 'app01.tasks.xsum': <@task: app01.tasks.xsum of CeleryPro:0x2360b07fc88>, 'celery.backend_cleanup': <@task: celery.backend_cleanup of CeleryPro:0x2360b07fc88>, 'app01.tasks.add': <@task: app01.tasks.add of CeleryPro:0x2360b07fc88>, 'celery.map': <@task: celery.map of CeleryPro:0x2360b07fc88>, 'app01.tasks.mul': <@task: app01.tasks.mul of CeleryPro:0x2360b07fc88>, 'celery.chain': <@task: celery.chain of CeleryPro:0x2360b07fc88>, 'CeleryPro.celery.debug_task': <@task: CeleryPro.celery.debug_task of CeleryPro:0x2360b07fc88>, 'celery.starmap': <@task: celery.starmap of CeleryPro:0x2360b07fc88>, 'celery.chord': <@task: celery.chord of CeleryPro:0x2360b07fc88>, 'celery.chunks': <@task: celery.chunks of CeleryPro:0x2360b07fc88>}我们的任务都在里面了,但是还多了很多其他的任务(都是celery开头的)。之前启动Worker的时候都是用 -l info 参数,如果用 -l debug 参数也是能看到这些任务的。也就是说celery在启动Worker的时候做了个过滤,debug模式打印所有,info模式只打印用户自定义的任务。接下来现在就是去源码里找一下,看看是怎么做过滤的。
我在源码里截取了下面这些来分析一下:
# celery/apps/worker.py
# 首先是一些在启动时会打印到控制台的字符串内容
# 这个是LOGO,这个不是重点
ARTLINES = [
' --------------',
'---- **** -----',
'--- * *** * --',
'-- * - **** ---',
'- ** ----------',
'- ** ----------',
'- ** ----------',
'- ** ----------',
'- *** --- * ---',
'-- ******* ----',
'--- ***** -----',
' --------------',
]
# 这个字符串就是打印任务列表的字符串
# 输出到控制台之前,会用format做一下字符串格式化,这样任务列表就能动态的输出了
EXTRA_INFO_FMT = """
[tasks]
{tasks}
"""
# 这个类里有很多方法,这里就看看动态获取任务列表的恨啊
class Worker(WorkController):
# 这个就是生成任务列表的方法
# 逻辑也很简单就是判断是不是以 'celery' 开头
# include_builtins 为True就输出所有的task,为False就过滤掉'celery'开头的
# include_builtins 具体的值看下面的extra_info方法
def tasklist(self, include_builtins=True, sep='\n', int_='celery.'):
return sep.join(
' . {0}'.format(task) for task in sorted(self.app.tasks)
if (not task.startswith(int_) if not include_builtins else task)
)
# 这个方法是调用上面的tasklist方法的
# 先判断启动级别,根据级别是否小于等于debug,决定include_builtins参数
# 最后用tasklist返回的结果,格式化EXTRA_INFO_FMT
def extra_info(self):
if self.loglevel <= logging.INFO:
include_builtins = self.loglevel <= logging.DEBUG
tasklist = self.tasklist(include_builtins=include_builtins)
return EXTRA_INFO_FMT.format(tasks=tasklist)过滤方法很简单,就是用startswith过滤掉以celery开头的key就好了。另外过滤之前先用sorted做了个排序,顺便把字典变成了用key组成的列表。
所以用下面的方法就可以获取到任务列表:
from CeleryPro import celery_app
def celery_list(request):
task_list = []
for task in sorted(celery_app.tasks):
if not task.startswith('celery.'):
task_list.append(task)
print(task_list)
return HttpResponse('OK')上面的代码最终获得的是一个列表,可以直接用一个列表生成式搞定:
task_list = [task for task in sorted(celery_app.tasks) if not task.startswith('celery.')]这里拿到的只是任务的key,要调用任务的话,就用key在celery_app.tasks这个字典里获取到对应的value,调用这个value的方法:
task_name = task_list[1] t = celery_app.tasks[task_name].delay(1, 2)
调用任务的具体做法,上一节最后已经有了。但是获取任务执行结果还有些问题。
之前的做法都是在调用delay方法时获取返回值,就是这个任务的对象,有了返回的对象,就可以判断任务是否执行完成以及获取任务执行结果。
但是现在在views视图函数里提交任务后,函数就返回结束了,任务的对象就没有了,并且也是无法把这里的对象直接返回给浏览器的。这里就需要返回一个任务的id(就是为每个任务生成的uuid)。之后请求时,就通过这个uuid获取到之前的任务的对象。
# 要通过uuid获取对象,使用下面这个方法 from celery.result import AsyncResult task_obj = AsyncResult(uuid) # 通过uuid获取到任务对象 # 先获取到对象,之后的操作就和之前的一样了 task_obj.ready() # 检查任务是否执行完成 task_obj.get() # 阻塞的拿结果 task_obj.result # 任务执行完成后,结果就存在这里,就不要再用get方法获取了
下面是我测试写的示例代码
前端页面
这个页面可以选择任务,填好参数,提交后台执行。提交后会跳转到任务结果页面:
# UsingCeleryWithDjango/templates/celery_list.html
<body>
<form method="post">
{% csrf_token %}
<select name="task_name">
{% for task in task_list %}
<option value="{{ task }}">{{ task }}</option>
{% endfor %}
</select>
<input name="args" type="text" placeholder="参数" />
<input type="submit" value="提交任务" />
</form>
<h4>Tips: 后台会用json.loads把input提交的参数做一次反序列化,然后用*args传参</h4>
<p>debug_task方法,参数不填</p>
<p>add和mul方法,参数填个2个元素的列表。比如:[1, 2]</p>
<p>xsum方法,参数接收一个列表,所以要再包一层[]。比如:[[1, 2, 3, 4, 5]]</p>
</body>路由函数
有两个url,一个是提交任务页面的url。还有一个url是根据uuid拿任务结果的,这个视图没写html,直接用HttpResponse返回了:
# UsingCeleryWithDjango/UsingCeleryWithDjango/urls.py
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('celery_list/', views.celery_list),
path('celery_result/<uuid:uuid>/', views.celery_result),
]视图函数
# UsingCeleryWithDjango/app01/views.py
from django.shortcuts import render, redirect, HttpResponse
# Create your views here.
from CeleryPro import celery_app
from celery.result import AsyncResult
import json
def celery_list(request):
if request.method == 'POST':
task_name = request.POST.get('task_name')
args = request.POST.get('args')
if args:
t = celery_app.tasks[task_name].delay(*json.loads(args))
return redirect('/celery_result/%s/' % t.id)
else:
celery_app.tasks[task_name]()
# 参考源码的方法,获取到所有task名字的列表
task_list = [task for task in sorted(celery_app.tasks) if not task.startswith('celery.')]
return render(request, 'celery_list.html', {'task_list': task_list})
def celery_result(request, uuid):
uuid = str(uuid)
task_obj = AsyncResult(uuid)
if task_obj.ready():
return HttpResponse(task_obj.result)
else:
ele = "<input type='button' value='再次获取结果' onclick='location.reload();'>"
return HttpResponse('Not Ready %s' % ele)测试下来都很好,不过所有任务都是立刻会返回结果的。所以去修改一下tasks.py里的任务。找个任务加点延迟 time.sleep() ,如果任务没有执行完成,也不会卡住,而是先返回一个页面,可以再刷新,如果执行完成了,就能返回任务执行的结果。
要在django中使用定时任务,到这里需要再安装一个模块:
pip install django_celery_beat
这个模块是 django_celery_beat ,注意名字里是下划线,不过命令里用中横杠也认(大概是做了别名)。这个模块不仅仅只是做定时任务,它是通过把任务存到django的数据库里实现的,所以还可以很方便的通过django admin来设置和管理。
注意:安装这个模块的时候还会自动安装一些别的依赖模块,不过坑的地方是,会把原本的celery更新到最新版,也就是号称不支持windows的4版本。
既然升级了,就先在当前的环境下跑跑试试看。然后踩了2个坑。
我用的是win10系统,部分由于windows操作系统导致的问题,不知道通用性是如何的。
worker可以正常启动,页面也能打开,但是app里定义的任务都找不到了。
自动发放所有app下的tasks是在 "UsingCeleryWithDjango/CeleryPro/celery.py" 这个文件里配置的,具体是调用下面的这个方法:
# from django.conf import settings # noqa # app.autodiscover_tasks(lambda: settings.INSTALLED_APPS) # 从django的settings里获取app的路径 app.autodiscover_tasks(['app01'],) # 自己指定
去看了下这个方法的源码,一大段注释,不过内容很简单:
def autodiscover_tasks(self, packages=None, related_name='tasks', force=False): """Auto-discover task modules. Searches a list of packages for a "tasks.py" module (or use related_name argument). If the name is empty, this will be delegated to fix-ups (e.g., Django). For example if you have a directory layout like this: .. code-block:: text foo/__init__.py tasks.py models.py bar/__init__.py tasks.py models.py baz/__init__.py models.py Then calling ``app.autodiscover_tasks(['foo', 'bar', 'baz'])`` will result in the modules ``foo.tasks`` and ``bar.tasks`` being imported. Arguments: packages (List[str]): List of packages to search. This argument may also be a callable, in which case the value returned is used (for lazy evaluation). related_name (str): The name of the module to find. Defaults to "tasks": meaning "look for 'module.tasks' for every module in ``packages``." force (bool): By default this call is lazy so that the actual auto-discovery won't happen until an application imports the default modules. Forcing will cause the auto-discovery to happen immediately. """ if force: return self._autodiscover_tasks(packages, related_name) signals.import_modules.connect(starpromise( self._autodiscover_tasks, packages, related_name, ), weak=False, sender=self)
内容就是一个if,然后返回某个东西。关键是if的条件,是一个默认参数为false的变量,所以用默认方法调用,是不会执行任何语句的。解决办法就很简单了,调用的时候指定force参数:
app.autodiscover_tasks(['app01'], force=True) # 4版本有个force参数。默认是False,需要设为True
启动worker(-l info),打开网页,提交任务。然后报错。worker上的错误信息如下:
[2018-10-08 13:23:28,062: INFO/MainProcess] Received task: app01.tasks.add[ff0f5e76-6474-4f74-a93c-7b2486abe07e]
[2018-10-08 13:23:28,078: ERROR/MainProcess] Task handler raised error: ValueError('not enough values to unpack (expected 3, got 0)',)
Traceback (most recent call last):
File "g:\steed\documents\pycharmprojects\venv\usingcelerywithdjango\lib\site-packages\billiard\pool.py", line 358, in workloop
result = (True, prepare_result(fun(*args, **kwargs)))
File "g:\steed\documents\pycharmprojects\venv\usingcelerywithdjango\lib\site-packages\celery\app\trace.py", line 537, in _fast_trace_task
tasks, accept, hostname = _loc
ValueError: not enough values to unpack (expected 3, got 0)这个问题基本上判断下来就是4版本不支持windows系统导致的。
通过celery降级解决问题
这小段看看就好,因为后面有不降级的办法。
到这里我就没能力看懂错误信息然后找出真正的问题了,只能把celery的版本降回去再看看了:
pip uninstall celery pip install celery==3.1.25
所谓降级,其实就是先删了,然后再装一个旧版本。这条路我没继续走下去。
4版本的celery还是能用的
有发现个新的办法,可以解决这里的问题,还需要再装一个模块:
pip install eventlet
装完之后,加一个新的参数启动worker,"-P eventlet" :
G:\Steed\Documents\PycharmProjects\UsingCeleryWithDjango>G:\Steed\Documents\PycharmProjects\venv\UsingCeleryWithDjango\Scripts\celery -A CeleryPro worker -l info -P eventlet
-------------- celery@IDX-xujf v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Windows-10-10.0.17134-SP0 2018-10-08 13:33:21
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: CeleryPro:0x16ad81d16a0
- ** ---------- .> transport: redis://192.168.246.11:6379/0
- ** ---------- .> results: redis://192.168.246.11/0
- *** --- * --- .> concurrency: 4 (eventlet)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. CeleryPro.celery.debug_task
. app01.tasks.add
. app01.tasks.mul
. app01.tasks.xsum
[2018-10-08 13:33:21,430: INFO/MainProcess] Connected to redis://192.168.246.11:6379/0
[2018-10-08 13:33:21,457: INFO/MainProcess] mingle: searching for neighbors
[2018-10-08 13:33:22,488: INFO/MainProcess] mingle: all alone
[2018-10-08 13:33:22,502: WARNING/MainProcess] g:\steed\documents\pycharmprojects\venv\usingcelerywithdjango\lib\site-packages\celery\fixups\django.py:200: UserWarning: Using settings.DEBUG leads to a memory leak, never use this setting in production environments!
warnings.warn('Using settings.DEBUG leads to a memory leak, never '
[2018-10-08 13:33:22,504: INFO/MainProcess] celery@IDX-xujf ready.
[2018-10-08 13:33:22,519: INFO/MainProcess] pidbox: Connected to redis://192.168.246.11:6379/0.
[2018-10-08 13:34:13,596: INFO/MainProcess] Received task: app01.tasks.add[2b56d6b7-012f-44db-bf4b-2d85d22dcd8d]
[2018-10-08 13:34:13,611: INFO/MainProcess] Task app01.tasks.add[2b56d6b7-012f-44db-bf4b-2d85d22dcd8d] succeeded in 0.0s: 7上面是worker的日志,启动后,还提交了一个任务,这次正常处理完了。
先在settings的INSTALLED_APPS里注册一下:
INSTALLED_APPS = [ ...... 'django_celery_beat', ]
应用django_celery_beat的数据库,会自动创建几张表。只要直接migrate就好了:
>python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, django_celery_beat, sessions Running migrations: Applying django_celery_beat.0001_initial... OK Applying django_celery_beat.0002_auto_20161118_0346... OK Applying django_celery_beat.0003_auto_20161209_0049... OK Applying django_celery_beat.0004_auto_20170221_0000... OK Applying django_celery_beat.0005_add_solarschedule_events_choices... OK Applying django_celery_beat.0006_auto_20180210_1226... OK
登录django admin后,就能看下如下的几张表了: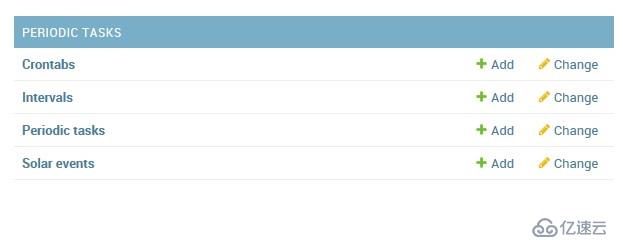
任务都是配置在Periodic tasks表里的。另外几张表就是各种任务执行周期的。
先进入 Intervals 表,新建任务周期。这里建一个每5秒的周期。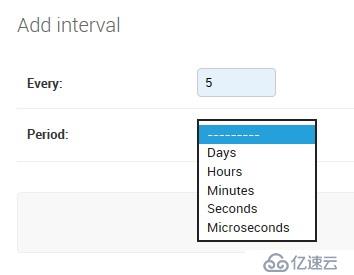
然后进入 Periodic tasks 表,选择要执行的任务,关联上某个周期。
这里能看到的任务就是通过自动发现注册的任务: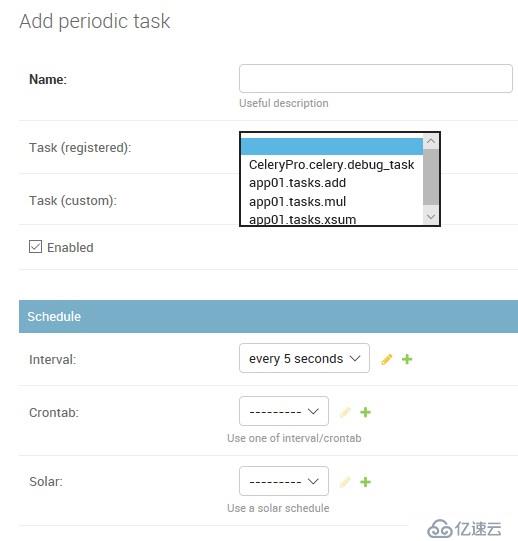
下面还有填写任务参数的部分,这里有两个框,里面写JSON。位置参数写上面,关键参数写下面:
这里的JSON会反序列化之后,以 "*args, **kwargs" 传递给任务函数的。
好了任务配置完了,其他任务周期也是一样的,就不试了。
这里依然需要启动一个Beat来定时发任务的。先把Worker起动起来,然后启动Beat需要多加一个参数 "-S django" :
G:\Steed\Documents\PycharmProjects\UsingCeleryWithDjango>G:\Steed\Documents\PycharmProjects\venv\UsingCeleryWithDjango\Scripts\celery -A CeleryPro beat -l info -S django celery beat v4.2.1 (windowlicker) is starting. __ - ... __ - _ LocalTime -> 2018-10-08 14:43:43 Configuration -> . broker -> redis://192.168.246.11:6379/0 . loader -> celery.loaders.app.AppLoader . scheduler -> django_celery_beat.schedulers.DatabaseScheduler . logfile -> [stderr]@%INFO . maxinterval -> 5.00 seconds (5s) [2018-10-08 14:43:43,907: INFO/MainProcess] beat: Starting... [2018-10-08 14:43:43,908: INFO/MainProcess] Writing entries... [2018-10-08 14:43:48,911: INFO/MainProcess] Writing entries... [2018-10-08 14:43:48,939: INFO/MainProcess] Scheduler: Sending due task add34 (app01.tasks.add) [2018-10-08 14:43:53,922: INFO/MainProcess] Scheduler: Sending due task add34 (app01.tasks.add) [2018-10-08 14:43:58,922: INFO/MainProcess] Scheduler: Sending due task add34 (app01.tasks.add) [2018-10-08 14:43:59,534: INFO/MainProcess] Writing entries... [2018-10-08 14:43:59,717: INFO/MainProcess] Writing entries... [2018-10-08 14:43:59,727: INFO/MainProcess] Writing entries... [2018-10-08 14:43:59,729: INFO/MainProcess] Writing entries... G:\Steed\Documents\PycharmProjects\UsingCeleryWithDjango>
注意:每次修改任务,都需要重启Beat,最新的配置才能生效。这个对 Intervals 的任务(每隔一段时间执行的),影响比较大。Crontab的任务问题貌似不是很大。
上述内容就是如何进行Celery的安装使用,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。