您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
首先跟大家简单唠叨两句为什么要学习正则表达式,为什么在网络爬虫的时候离不开正则表达式。正则表达式在处理字符串的时候扮演着非常重要的角色,在网络爬虫的时候也十分常用,大家可以把它学的简单一些,但是不能不学。

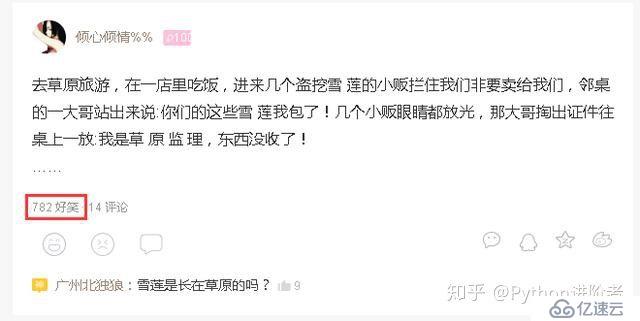
尽管网络爬虫相关库给我们提供了丰富的库如css、bs4、lxml等等,让我们可以通过选择器去匹配字符串,但是在HTML中数据往往存在标签之中。通过选择器确实可以匹配到标签的内容,但是有时候标签中存在的许多内容是冗余的,而我们只需要匹配其中部分内容即可(如匹配数字、时间等),如下图所示。通过选择器,我们一般可以获取到“782好笑”这个字符串,但是我们只需要“782”这个数字的话,此时正则表达式就要派上用场了
正则表达式可以帮我们判断某个字符串是否符合某一个模式,其次正则表达式可以帮我们提取某个字符串中的重要部分,做子字符串的提取。今天简单的给大家讲解几个正则表达式的特殊字符—— “^”、“.”、“*”,并且用实例进行演示,让大家对正则表达式有个初步的了解。
小编用的Python是3版本,开发环境用的是pycharm,首先在本地新建一个demo.py文件,接下来开始进行演示。
1、正则表达式在Python中有个专门的库叫re模块,首先进行导入模块。再定义一个字符串str,然后定义一个正则表达式匹配规则regex。
2、“^d”代表的意思是以d元素开头的任意一个字符串,也就是说只要是以d开头的字符串,后面的元素不论是什么,都是符合规则的,总之必须要以d开头。
3、“.” 较为常用,其代表的意思是任意字符,其表示的范围非常广,可以接任意字符,不论是中英文,还是下划线之类的特殊字符,都是可以代表的。举个栗子,正则表达式“^d.”就是代表以d开头的字符串,b后边接任意字符都可以。
4、“*” 也十分常用,其代表的意思是前面的字符可以重复任意多遍,可以是0次,1次,2次等任意多次。
5、了解好这几个特殊字符的用法之后,接下来通过代码简单的感受一下。如下图所示,如果匹配成功,则返回yes;如果没有匹配成功,则不返回任何东西。
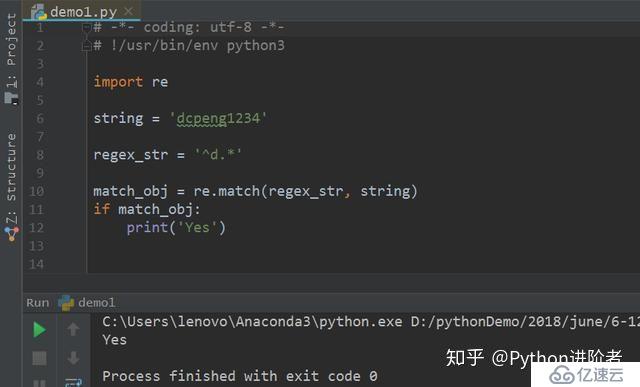
可以看到程序运行之后,返回的结果为yes,说明匹配成功。正则表达式“^d.*”代表的意思是以d开头的字符串,后面跟着任意字符,出现任意多遍。显然,通过匹配可以得知该正则表达式匹配的结果和原始字符串一致,之后if判断返回值为true,所以打印出结果为yes。
6、为了进一步验证这个模式是否正确,我们将b改为a,其代表的意思该模式下的字符串是否以a开头的。之后再次运行程序,如下图所示。
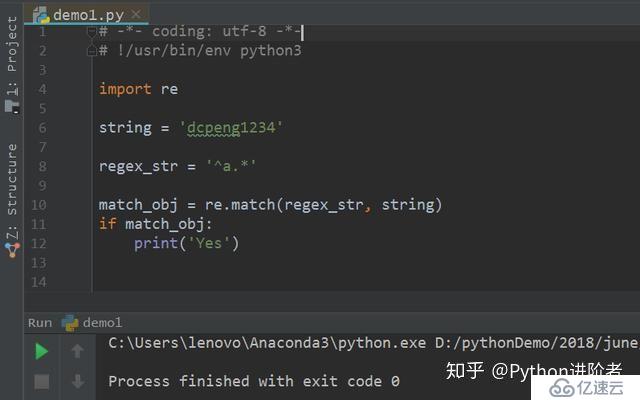
此时可以看到无任何输出,说明特殊字符“^”起到了作用。
小伙伴们,快去打开Python,感受一下正则表达式的大法吧~~~
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。