您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章为大家展示了如何进行python中类的全面分析,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
面向对象重要的概念就是类(Class)和实例(Instance),类是抽象的模板,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
先回顾下 OOP 的常用术语:
类:对具有相同数据和方法的一组对象的描述或定义。
对象:对象是一个类的实例。
实例(instance):一个对象的实例化实现。
实例属性(instance attribute):一个对象就是一组属性的集合。
实例方法(instance method):所有存取或者更新对象某个实例一条或者多条属性的函数的集合。
类属性(classattribute):属于一个类中所有对象的属性,不会只在某个实例上发生变化
类方法(classmethod):那些无须特定的对象实例就能够工作的从属于类的函数。
类概述
在Python中,定义类是通过class关键字:
class Student(object): pass
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的。通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
定义好了Student类,就可以根据Student类创建出Student的实例,创建实例是通过类名+()实现的:
>>> bart = Student() >>> bart <__main__.Student object at 0x10a67a590> >>> Student <class '__main__.Student'>
可以看到,变量bart指向的就是一个Student的object,后面的0x10a67a590是内存地址,每个object的地址都不一样,而Student本身则是一个类。
可以自由地给一个实例变量绑定属性,比如,给实例bart绑定一个name属性:
>>> bart.name = 'Bart Simpson' >>> bart.name 'Bart Simpson'
由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的init方法,在创建实例的时候,就把name,score等属性绑上去。
class Student(object): def __init__(self, name, score): self.name = name self.score = score
注意到init方法的***个参数永远是self,表示创建的实例本身,因此,在init方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
有了init方法,在创建实例的时候,就不能传入空的参数了,必须传入与init方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去:
>>> bart = Student('Bart Simpson', 59) >>> bart.name 'Bart Simpson' >>> bart.score 59和普通的函数相比,在类中定义的对象函数(还有静态方法,类方法)只有一点不同,就是***个参数永远是实例变量self,并且,调用时不用传递该参数。
新式类、旧式类
python的新式类是2.2版本引进来的,之前的类叫做经典类或者旧类。Python 2.x 中如果一个类继承于一个基类(可以是自定义类或者其它类)或者继承自 object,则该类为新式类;没有继承的类为经典类。Python 3.x 则全部为新式类。
新式类被赋予了很多新的特性(如:统一了types和classes),并改变了以往经典类的一些内容(如:改变了多继承下方法的执行顺序)。
关于统一类(class)和类型(type),具体看下面的例子
class OldClass(): pass o = OldClass() print o.__class__ # __main__.OldClass print type(o) # <type 'instance'> class newClass(object): pass n = newClass() print n.__class__ # <class '__main__.newClass'> print type(n) # <class '__main__.newClass'>
对象属性
Python 中对象的属性包含对象的所有内容:方法和数据,注意方法也是对象的属性。查找对象的属性时,首先在对象的__dict__ 里面查找,然后是对象所属类的dict,再往后是继承体系中父类(MRO解析)的dict,任意一个地方查找到就终止查找,并且调用 __getattribute__(也有可能是__getattr__) 方法获得属性值。
方法
在 Python 类中有3种方法,即静态方法(staticmethod),类方法(classmethod)和实例方法:
对于实例方法,在类里每次定义实例方法的时候都需要指定实例(该方法的***个参数,名字约定成俗为self)。这是因为实例方法的调用离不开实例,我们必须给函数传递一个实例。假设对象a具有实例方法 foo(self, *args, **kwargs),那么调用的时候可以用 a.foo(*args, **kwargs),或者 A.foo(a, *args, **kwargs),在解释器看来它们是完全一样的。
类方法每次定义的时候需要指定类(该方法的***个参数,名字约定成俗为cls),调用时和实例方法类似需要指定一个类。
静态方法其实和普通的方法一样,只不过在调用的时候需要使用类或者实例。之所以需要静态方法,是因为有时候需要将一组逻辑上相关的函数放在一个类里面,便于组织代码结构。一般如果一个方法不需要用到self,那么它就适合用作静态方法。
具体的例子如下:
def foo(x): print "executing foo(%s)"%(x) class A(object): def foo(self): print "executing foo(%s)" % self @classmethod def class_foo(cls): print "executing class_foo(%s)" % cls @staticmethod def static_foo(): print "executing static_foo()" a = A() print a.foo print A.foo print a.class_foo print A.class_foo print A.static_foo print a.static_foo print foo # <bound method A.foo of <__main__.A object at 0x10d5f90d0>> # <unbound method A.foo> # <bound method type.class_foo of <class '__main__.A'>> # <bound method type.class_foo of <class '__main__.A'>> # <function static_foo at 0x10d5f32a8> # <function static_foo at 0x10d5f32a8> # <function foo at 0x10d5f1ed8>
在访问类方法的时候有两种方法,分别叫做 未绑定的方法(unbound method) 和 绑定的方法(bound method):
未绑定的方法:通过类来引用实例方法返回一个未绑定方法对象。要调用它,你必须显示地提供一个实例作为***个参数,比如 A.foo。
绑定的方法:通过实例访问方法返回一个绑定的方法对象。Python自动地给方法绑定一个实例,所以调用它时不用再传一个实例参数,比如 a.foo。
数据属性
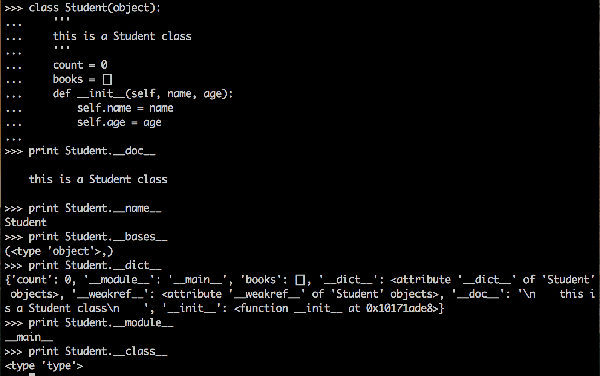
下面创建了一个Student的类,并且实现了这个类的初始化函数"__init__":
class Student(object): count = 0 books = [] def __init__(self, name, age): self.name = name self.age = age
在上面的Student类中,count, books, name 和 age 都被称为类的数据属性,但是它们又分为类数据属性和实例数据属性。直接定义在类体中的属性叫类属性,而在类的方法中定义的属性叫实例属性。
首先看下面代码,展示了对类数据属性和实例数据属性的访问:
Student.books.extend(["python", "javascript"]) print "Student book list: %s" %Student.books # class can add class attribute after class definition Student.hobbies = ["reading", "jogging", "swimming"] print "Student hobby list: %s" %Student.hobbies print dir(Student) # class instance attribute wilber = Student("Wilber", 28) print "%s is %d years old" %(wilber.name, wilber.age) # class instance can add new attribute # "gender" is the instance attribute only belongs to wilber wilber.gender = "male" print "%s is %s" %(wilber.name, wilber.gender) # class instance can access class attribute wilber.books.append("C#") print wilber.books通过内建函数dir(),或者访问类的字典属性__dict__,这两种方式都可以查看类或者实例有哪些属性。对于类数据属性和实例数据属性,可以总结为:
类数据属性属于类本身,可以通过类名进行访问/修改;
类数据属性也可以被类的所有实例访问/修改;
在类定义之后,可以通过类名动态添加类数据属性,新增的类属性也被类和所有实例共有;
实例数据属性只能通过实例访问;
在实例生成后,还可以动态添加实例数据属性,但是这些实例数据属性只属于该实例;
再看下面的程序
class Person: name="aaa" p1=Person() p2=Person() p1.name="bbb" print p1.name # bbb print p2.name # aaa print Person.name # aaa
上面程序中,p1.name="bbb"是实例调用了类变量,p1.name一开始是指向的类变量name="aaa",但是在实例的作用域里把类变量的引用改变了,就变成了一个实例变量。self.name不再引用Person的类变量name了。
class Person: name=[] p1=Person() p2=Person() p1.name.append(1) print p1.name # [1] print p2.name # [1] print Person.name # [1]
特殊的类属性
对于所有的类,都有一组特殊的属性:

通过这些属性,可以得到 Student类的一些信息,如下:
类的继承
Python 是面向对象语言,支持类的继承(包括单重和多重继承),继承的语法如下:
class DerivedClass(BaseClass1, [BaseClass2...]): <statement-1> . <statement-N>
子类可以覆盖父类的方法,此时有两种方法来调用父类中的函数:
调用父类的未绑定的构造方法。在调用一个实例的方法时,该方法的self参数会被自动绑定到实例上(称为绑定方法)。但如果直接调用类的方法(比如A.init),那么就没有实例会被绑定。这样就可以自由的提供需要的self参数,这种方法称为未绑定(unbound)方法。大多数情况下是可以正常工作的,但是多重继承的时候可能会重复调用父类。
通过 super(cls, inst).method() 调用 MRO中下一个类的函数,这里有一个非常不错的解释,看完后对 super 应该就熟悉了。
未绑定(unbound)方法调用如下:
class Base(object): def __init__(self): print("Base.__init__") class Derived(Base): def __init__(self): Base.__init__(self) print("Derived.__init__")supper 调用如下:
class Base(object): def __init__(self): print "Base.__init__" class Derived(Base): def __init__(self): super(Derived, self).__init__() print "Derived.__init__" class Derived_2(Derived): def __init__(self): super(Derived_2, self).__init__() print "Derived_2.__init__"
继承机制 MRO
MRO 主要用于在多继承时判断调用的属性来自于哪个类。Python2.2以前的类为经典类,它是一种没有继承的类,实例类型都是type类型,如果经典类被作为父类,子类调用父类的构造函数时会出错。这时MRO的方法为DFS(深度优先搜索),子节点顺序:从左到右。inspect.getmro(A)可以查看经典类的MRO顺序。

两种继承模式在DFS下的优缺点:
***种,两个互不相关的类的多继承,这种情况DFS顺序正常,不会引起任何问题;
第二种,棱形继承模式,存在公共父类(D)的多继承,这种情况下DFS必定经过公共父类(D)。如果这个公共父类(D)有一些初始化属性或者方法,但是子类(C)又重写了这些属性或者方法,那么按照DFS顺序必定是会先找到D的属性或方法,那么C的属性或者方法将永远访问不到,导致C只能继承无法重写(override)。这也就是新式类不使用DFS的原因,因为他们都有一个公共的祖先object。
为了使类和内置类型更加统一,Python2.2版本引入了新式类。新式类的每个类都继承于一个基类,可以是自定义类或者其它类,默认承于object,子类可以调用父类的构造函数。可以用 A.__mro__ 可以查看新式类的顺序。
在 2.2 中,有两种MRO的方法:
如果是经典类MRO为DFS;
如果是新式类MRO为BFS(广度优先搜索),子节点顺序:从左到右。
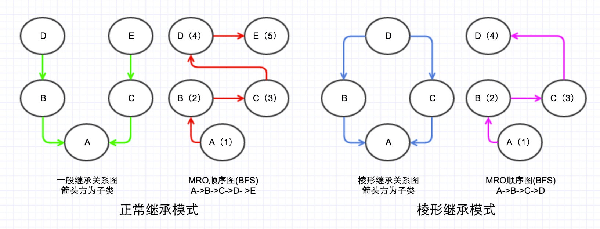
新式类两种继承模式在BFS下的优缺点:
***种,正常继承模式。比如B明明继承了D的某个属性(假设为foo),C中也实现了这个属性foo,那么BFS明明先访问B然后再去访问C,但是A的foo属性是c,这个问题称为单调性问题。
第二种,棱形继承模式,BFS的查找顺序解决了DFS顺序中的只能继承无法重写的问题。
因为DFS 和 BFS 都存在较大的问题,所以从Python2.3开始新式类的 MRO采用了C3算法,解决了单调性问题,和只能继承无法重写的问题。MRO的C3算法顺序如下图:
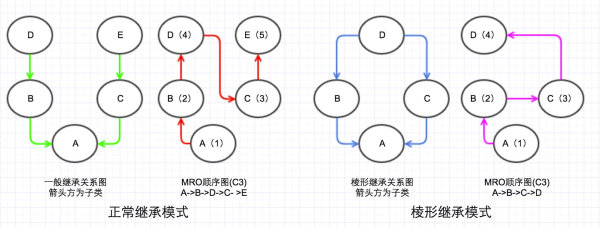
C3 采用图的拓扑排序算法,具体实现可以参考官网文档。
多态
多态即多种形态,在运行时确定其状态,在编译阶段无法确定其类型,这就是多态。Python中的多态和Java以及C++中的多态有点不同,Python中的变量是动态类型的,在定义时不用指明其类型,它会根据需要在运行时确定变量的类型。
Python本身是一种解释性语言,不进行预编译,因此它就只在运行时确定其状态,故也有人说Python是一种多态语言。在Python中很多地方都可以体现多态的特性,比如内置函数len(object),len函数不仅可以计算字符串的长度,还可以计算列表、元组等对象中的数据个数,这里在运行时通过参数类型确定其具体的计算过程,正是多态的一种体现。
特殊的类方法
类中经常有一些方法用两个下划线包围来命名,下图给出一些例子。合理地使用它们可以对类添加一些“魔法”的行为。

构造与析构
当我们调用 x = SomeClass() 的时候,***个被调用的函数是 __new__ ,这个方法创建实例。接下来可以用 __init__ 来指明一个对象的初始化行为。当这个对象的生命周期结束的时候, __del__ 会被调用。
__new__(cls,[...]) 是对象实例化时***个调用的方法,它只取下 cls 参数,并把其他参数传给init。
__init__(self,[...]) 为类的初始化方法。它获取任何传给构造器的参数(比如我们调用 x = SomeClass(10, ‘foo’) ,init 函数就会接到参数 10 和 ‘foo’) 。
__del__(self):new和init是对象的构造器, del则是对象的销毁器。它并非实现了语句 del x (因此该语句不等同于x.__del__()),而是定义当对象被回收时的行为。
当我们创建一个类的实例时,首先会调用new创建实例,接着才会调用init来进行初始化。不过注意在旧式类中,实例的创建并没有调用new方法,如下例子:
class A: def __new__(cls): print "A.__new__ is called" # -> this is never called A()
对于新式类来说,我们可以覆盖new方法,注意该方法的***个参数cls(其实就是当前类类型)用来指明要创建的类型,后续参数用来传递给init进行初始化。如果new返回了cls类型的对象,那么接下来调用init,否则的话不会调用init(调用该方法必须传递一个实例对象)。
class A(object): # -> don't forget the object specified as base def __new__(cls): print "A.__new__ called" return super(A, cls).__new__(cls) def __init__(self): print "A.__init__ called" A() # A.__new__ called # A.__init__ called
这里我们调用super()来获取 MRO 中A的下一个类(在这里其实就是基类 object)的new方法来创建一个cls的实例对象,接着用这个对象来调用了init。下面的例子中,并没有返回一个合适的对象,所以并没有调用init:
class Sample(object): def __str__(self): return "SAMPLE" class A(object): def __new__(cls): print "A.__new__ called" return super(A, cls).__new__(Sample) # return Sample() def __init__(self): print "A.__init__ called" # -> is actually never called a = A() # A.__new__ called
关于 super,这里是一个非常不错的解释,简单来说super做了下面的事情:
def super(cls, inst): mro = inst.__class__.mro() return mro[mro.index(cls) + 1]
关于 MRO,这篇文章非常棒:你真的理解Python中MRO算法吗?,简单来说,在新式类MRO的 C3 算法中,保证:基类永远出现在派生类后面,如果有多个基类,基类的相对顺序保持不变。
操作符
利用特殊方法可以构建一个拥有Python内置类型行为的对象,这意味着可以避免使用非标准的、丑陋的方式来表达简单的操作。在一些语言中,这样做很常见:
if instance.equals(other_instance): # do something
Python中当然也可以这么做,但是这样做让代码变得冗长而混乱。不同的类库可能对同一种比较操作采用不同的方法名称,这让使用者需要做很多没有必要的工作。因此我们可以定义方法__eq__,然后就可以像下面这样使用:
if instance == other_instance: # do something
Python 有许多特殊的函数对应到常用的操作符上,比如:
__cmp__(self, other):定义了所有比较操作符的行为。应该在 self < other 时返回一个负整数,在 self == other 时返回0,在 self > other 时返回正整数。
__eq__(self, other):定义等于操作符(==)的行为。
__ne__(self, other):定义不等于操作符(!=)的行为(定义了 eq 的情况下也必须再定义 ne!)
__le__(self, other):定义小于等于操作符(<)的行为。
__ge__(self, other):定义大于等于操作符(>)的行为。
数值操作符
就像可以使用比较操作符来比较类的实例,也可以定义数值操作符的行为。可以分成五类:一元操作符,常见算数操作符,反射算数操作符,增强赋值操作符,和类型转换操作符,下面为一些例子:
__pos__(self) 实现取正操作,例如 +some_object
__invert__(self) 实现取反操作符 ~
__add__(self, other) 实现加法操作
__sub__(self, other) 实现减法操作
__radd__(self, other) 实现反射加法操作
__rsub__(self, other) 实现反射减法操作
__floordiv__(self, other) 实现使用 // 操作符的整数除法
__iadd__(self, other) 实现加法赋值操作。
__isub__(self, other) 实现减法赋值操作。
__int__(self) 实现到int的类型转换。
__long__(self) 实现到long的类型转换。
反射运算符方法和它们的常见版本做的工作相同,只不过是处理交换两个操作数之后的情况。类型转换操作符,主要用于实现类似 float() 这样的内建类型转换函数的操作。
类的表示
使用字符串来表示类是一个相当有用的特性。在Python中有一些内建方法可以返回类的表示,相对应的,也有一系列特殊方法可以用来自定义在使用这些内建函数时类的行为。
__str__(self) 定义对类的实例调用 str() 时的行为。
__repr__(self) 定义对类的实例调用 repr() 时的行为。 str() 和 repr() 最主要的差别在于“目标用户”,repr() 的作用是产生机器可读的输出(大部分情况下,其输出可以作为有效的Python代码),而 str() 则产生人类可读的输出。
__dir__(self) 定义对类的实例调用 dir() 时的行为,这个方法应该向调用者返回一个属性列表。如果重定义了__getattr__ 或者使用动态生成的属性,以实现类的交互式使用,那么这个方法是必不可少的。
属性控制
在Python中,重载__getattr__、__setattr__、__delattr__和__getattribute__方法可以用来管理一个自定义类中的属性访问。其中:
getattr方法将拦截所有未定义的属性获取(当要访问的属性已经定义时,该方法不会被调用,至于定义不定义,是由Python能否查找到该属性来决定的);
getattribute方法将拦截所有属性的获取(不管该属性是否已经定义,只要获取它的值,该方法都会调用),由于此情况,所以,当一个类中同时重载了getattr和getattribute方法,那么getattr永远不会被调用,另外getattribute方法仅仅存在于Python2.6的新式类和Python3的所有类中;
setattr方法将拦截所有的属性赋值;
delattr方法将拦截所有的属性删除。
在Python中,一个类或类实例中的属性是动态的(因为Python是动态的),也就是说,可以往一个类或类实例中添加或删除一个属性。
由于getattribute、setattr、delattr方法对所有的属性进行拦截,所以,在重载它们时,不能再像往常的编码,要注意避免递归调用(如果出现递归,则会引起死循环);然而对getattr方法,则没有这么多的限制。
在重载setattr方法时,不能使用“self.name = value”格式,否则,它将会导致递归调用而陷入死循环。正确的应该是:
def __setattr__(self, name, value): # do-something object.__setattr__(self, name, value) # do-something
其中的object.__setattr__(self, name, value)一句可以换成self.__dict__[name] = value;但前提是,必须保证getattribute方法重载正确(如果重载了getattribute方法的话),否则,将在赋值时导致错误,因为self.dict将要触发对self所有属性中的dict属性的获取,这样从而就会引发getattribute方法的调用,如果getattribute方法重载错误,setattr方法自然而然也就会失败。
自定义序列
有许多办法可以让 Python 类表现得像是内建序列类型(字典,元组,列表,字符串等)。
在Python中实现自定义容器类型需要用到一些协议。首先,不可变容器类型有如下协议:想实现一个不可变容器,你需要定义__len__ 和 __getitem__。
可变容器的协议除了上面提到的两个方法之外,还需要定义 __setitem__ 和 __delitem__ 。如果你想让你的对象可以迭代,你需要定义 __iter__ ,这个方法返回一个迭代器。迭代器必须遵守迭代器协议,需要定义 __iter__ (返回它自己)和 next 方法。
上下文管理
上下文管理协议(Context Management Protocol)包含方法 __enter__() 和 __exit__(),支持 该协议的对象要实现这两个方法。
enter: 进入上下文管理器的运行时上下文。如果指定了 as 子句的话,返回值赋值给 as 子句中的 target。
exit: 退出与上下文管理器相关的运行时上下文。返回一个布尔值表示是否对发生的异常进行处理。
在执行with语句包裹起来的代码块之前会调用上下文管理器的 enter 方法,执行完语句体之后会执行 exit 方法。
with 语句的语法格式如下:
with context_expression [as target(s)]: with-body
Python 对一些内建对象进行改进,加入了对上下文管理器的支持,可以用于 with 语句中,比如可以自动关闭文件、线程锁的自动获取和释放等。如下面例子:
>>> with open("etc/CS.json") as d: ...: print d <open file 'etc/CS.json', mode 'r' at 0x109344540> >>> print d <closed file 'etc/CS.json', mode 'r' at 0x109344540> >>> print dir(d) ['__class__', '__delattr__', '__doc__', '__enter__', '__exit__', ...]通过使用 with 语句,不管在处理文件过程中是否发生异常,都能保证 with 语句执行完毕后已经关闭了打开的文件句柄。
上述内容就是如何进行python中类的全面分析,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。