жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷйҮҢе…Ҳеј•з”ЁдёҖдёӢзҷҫеәҰзҷҫ科зҡ„е®ҡд№ү.
并еҸ‘пјҢеңЁж“ҚдҪңзі»з»ҹдёӯпјҢжҳҜжҢҮдёҖдёӘж—¶й—ҙж®өдёӯжңүеҮ дёӘзЁӢеәҸйғҪеӨ„дәҺе·ІеҗҜеҠЁиҝҗиЎҢеҲ°иҝҗиЎҢе®ҢжҜ•д№Ӣй—ҙпјҢдё”иҝҷеҮ дёӘзЁӢеәҸйғҪжҳҜеңЁеҗҢдёҖдёӘеӨ„зҗҶжңәдёҠиҝҗиЎҢпјҢдҪҶд»»дёҖдёӘж—¶еҲ»зӮ№дёҠеҸӘжңүдёҖдёӘзЁӢеәҸеңЁеӨ„зҗҶжңәдёҠиҝҗиЎҢ
йҮҢйқўзҡ„дёҖдёӘж—¶й—ҙж®өеҶ…иҜҙжҳҺйқһеёёйҮҚиҰҒ,иҝҷйҮҢеҒҮи®ҫиҝҷдёӘж—¶й—ҙж®өжҳҜдёҖз§’,жүҖд»Ҙжң¬ж–ҮжҢҮзҡ„并еҸ‘жҳҜжҢҮжңҚеҠЎеҷЁеңЁдёҖз§’дёӯеӨ„зҗҶзҡ„иҜ·жұӮж•°йҮҸ,еҚіrps,йӮЈд№Ҳrpsй«ҳ,жң¬ж–Үе°ұи®Өдёәй«ҳ并еҸ‘.
е•Ҙ?иҝҷдёҚжҳҜдҪ и®Өдёәзҡ„й«ҳ并еҸ‘, еҮәй—Ёе·ҰиҪ¬гҖӮ
еҰӮжһңз”ұ笔иҖ…жқҘжҰӮжӢ¬пјҢж“ҚдҪңзі»з»ҹеӨ§жҰӮеҒҡдәҶдёӨ件дәӢжғ…пјҢи®Ўз®—дёҺIOпјҢд»»дҪ•е…·дҪ“ж•°еӯҰи®Ўз®—жҲ–иҖ…йҖ»иҫ‘еҲӨж–ӯпјҢжҲ–иҖ…дёҡеҠЎйҖ»иҫ‘йғҪжҳҜи®Ўз®—пјҢиҖҢзҪ‘з»ңдәӨдә’пјҢзЈҒзӣҳдәӨдә’пјҢдәәжңәд№Ӣй—ҙзҡ„дәӨдә’йғҪжҳҜIOгҖӮ
ж №жҚ®з¬”иҖ…з»ҸйӘҢпјҢеӨ§еӨҡж•°ж—¶еҖҷеңЁIOдёҠйқўгҖӮжіЁж„ҸпјҢиҝҷйҮҢиҜҙеҫ—жҳҜеӨ§еӨҡж•°пјҢдёҚжҳҜиҜҙз»қеҜ№гҖӮ
еӣ дёәеӨ§еӨҡж•°ж—¶еҖҷдёҡеҠЎжң¬иҙЁдёҠйғҪжҳҜд»Һж•°жҚ®еә“жҲ–иҖ…е…¶д»–еӯҳеӮЁдёҠиҜ»еҸ–еҶ…е®№пјҢ然еҗҺж №жҚ®дёҖе®ҡзҡ„йҖ»иҫ‘пјҢе°Ҷж•°жҚ®иҝ”еӣһз»ҷз”ЁжҲ·пјҢжҜ”еҰӮеӨ§еӨҡж•°webеҶ…е®№гҖӮиҖҢеӨ§еӨҡж•°йҖ»иҫ‘зҡ„дәӨдә’йғҪз®—дёҚдёҠи®Ўз®—йҮҸеӨҡеӨ§зҡ„йҖ»иҫ‘пјҢCPUзҡ„йҖҹеәҰиҰҒиҝңиҝңй«ҳдәҺеҶ…еӯҳIO,зЈҒзӣҳIO,зҪ‘з»ңIO, иҖҢиҝҷдәӣIOдёӯзҪ‘з»ңIOжңҖж…ўгҖӮ
еңЁж №жҚ®дёҠйқўзҡ„笔иҖ…еҜ№ж“ҚдҪңзі»з»ҹзҡ„жҰӮиҝ°пјҢеҪ“并еҸ‘й«ҳеҲ°дёҖе®ҡзҡ„зЁӢеәҰпјҢж №жҚ®дёҡеҠЎзҡ„дёҚеҗҢпјҢжҜ”еҰӮи®Ўз®—еҜҶйӣҶпјҢIOеҜҶйӣҶпјҢжҲ–дёӨиҖ…зҡҶжңүпјҢеӣ жӯӨ瓶йўҲеҸҜиғҪеҮәеңЁи®Ўз®—дёҠйқўжҲ–иҖ…IOдёҠйқўпјҢеҸҲжҲ–дёӨиҖ…е…јжңүгҖӮ
иҖҢжң¬ж–Үи§ЈеҶізҡ„й«ҳ并еҸ‘пјҢжҳҜжҢҮIOеҜҶйӣҶзҡ„й«ҳ并еҸ‘瓶йўҲпјҢеӣ жӯӨпјҢи®Ўз®—еҜҶйӣҶзҡ„й«ҳ并еҸ‘并дёҚеңЁжң¬ж–Үзҡ„и®Ёи®әиҢғеӣҙеҶ…гҖӮ
дёәдәҶдҪҝжң¬ж–Үжӯ§д№үжӣҙе°‘пјҢиҝҷйҮҢзҡ„IOдё»иҰҒжҢҮзҪ‘з»ңIO.
дҪҝз”ЁеҚҸзЁӢ, дәӢ件еҫӘзҺҜ, й«ҳж•ҲIOжЁЎеһӢ(жҜ”еҰӮеӨҡи·ҜеӨҚз”ЁпјҢжҜ”еҰӮepoll), дёүиҖ…зјәдёҖдёҚеҸҜгҖӮ
еҫҲеӨҡж—¶еҖҷпјҢ笔иҖ…зңӢиҝҮзҡ„ж–Үз« йғҪжҳҜиҜҙеҚҸзЁӢеҰӮдҪ•еҰӮдҪ•пјҢжңҖеҗҺе‘ҠиҜүжҲ‘дёҖдәӣеҚҸзЁӢеә“жҲ–иҖ…asyncioз”ЁжқҘиҜҙжҳҺеҚҸзЁӢзҡ„еЁҒеҠӣпјҢжңҖз»ҲжҲ‘зңӢжҮӮдәҶеҚҸзЁӢпјҢеҚҙиҝҳжҳҜдёҚзҹҘйҒ“е®ғдёәе•ҘиғҪй«ҳ并еҸ‘пјҢиҝҷд№ҹжҳҜ笔иҖ…еҶҷжң¬ж–Үзҡ„зӣ®зҡ„гҖӮ
дҪҶжҳҜдёҖеҲҮиҝҳжҳҜеҫ—д»Һз”ҹжҲҗеҷЁиҜҙиө·пјҢеӣ дёәasyncioжҲ–иҖ…еӨ§еӨҡж•°еҚҸзЁӢеә“еҶ…йғЁд№ҹжҳҜйҖҡиҝҮз”ҹжҲҗеҷЁе®һзҺ°зҡ„гҖӮ
жіЁж„ҸдёҠйқўзҡ„дёүиҖ…зјәдёҖдёҚеҸҜгҖӮ
еҰӮжһңеҸӘжҮӮе…¶дёӯдёҖдёӘпјҢйӮЈд№ҲдҪ жҮӮдәҶдёүеҲҶд№ӢдёҖпјҢд»ҘжӯӨзұ»жҺЁпјҢеҸӘжңүйғҪдјҡдәҶпјҢдҪ жүҚзҹҘйҒ“дёәе•ҘеҚҸзЁӢиғҪй«ҳ并еҸ‘гҖӮ
з”ҹжҲҗеҷЁзҡ„е®ҡд№үеҫҲжҠҪиұЎпјҢзҺ°еңЁдёҚжҮӮжІЎе…ізі»пјҢдҪҶжҳҜеҪ“дҪ жҮӮдәҶд№ӢеҗҺеӣһиҝҮеӨҙеҶҚзңӢпјҢдјҡи§үеҫ—е®ҡд№үзҡ„жІЎй”ҷпјҢ并且еҮҶзЎ®гҖӮдёӢйқўжҳҜе®ҡд№ү
ж‘ҳиҮӘзҷҫеәҰзҷҫ科: з”ҹжҲҗеҷЁжҳҜдёҖж¬Ўз”ҹжҲҗдёҖдёӘеҖјзҡ„зү№ж®Ҡзұ»еһӢеҮҪж•°гҖӮеҸҜд»Ҙе°Ҷе…¶и§ҶдёәеҸҜжҒўеӨҚеҮҪж•°гҖӮ
е…ідәҺз”ҹжҲҗеҷЁзҡ„еҶ…е®№пјҢжң¬ж–ҮзқҖйҮҚдәҺз”ҹжҲҗеҷЁе®һзҺ°дәҶе“ӘдәӣеҠҹиғҪпјҢиҖҢдёҚжҳҜз”ҹжҲҗеҷЁзҡ„еҺҹзҗҶеҸҠеҶ…йғЁе®һзҺ°гҖӮ
з®ҖеҚ•дҫӢеӯҗеҰӮдёӢ
def gen_func():
yield 1
yield 2
yield 3
if __name__ == '__main__':
gen = gen_func()
for i in gen:
print(i)
output:
1
2
3дёҠйқўзҡ„дҫӢеӯҗжІЎжңүд»Җд№ҲзЁҖеҘҮзҡ„дёҚжҳҜеҗ—пјҹyieldеғҸдёҖдёӘзү№ж®Ҡзҡ„е…ій”®еӯ—пјҢе°ҶеҮҪж•°еҸҳжҲҗдәҶдёҖдёӘзұ»дјјдәҺиҝӯд»ЈеҷЁзҡ„еҜ№иұЎпјҢеҸҜд»ҘдҪҝз”ЁforеҫӘзҺҜеҸ–еҖјгҖӮ
еҚҸзЁӢиҮӘ然дёҚдјҡиҝҷд№Ҳз®ҖеҚ•пјҢpythonеҚҸзЁӢзҡ„зӣ®ж ҮжҳҜжҳҹиҫ°еӨ§жө·пјҢд»ҺдёҠйқўзҡ„дҫӢд№ӢжүҖд»ҘgetдёҚеҲ°е®ғзҡ„йҮҺеҝғпјҢжҳҜеӣ дёәдҪ жІЎжңүиҜ•иҝҮsend, nextдёӨдёӘеҮҪж•°гҖӮ
йҰ–е…ҲиҜҙnext
def gen_func():
yield 1
yield 2
yield 3
if __name__ == '__main__':
gen = gen_func()
print(next(gen))
print(next(gen))
print(next(gen))
output:
1
2
3
nextзҡ„ж“ҚдҪңжңүзӮ№еғҸforеҫӘзҺҜпјҢжҜҸи°ғз”ЁдёҖж¬ЎnextпјҢе°ұдјҡд»ҺдёӯеҸ–еҮәдёҖдёӘyieldеҮәжқҘзҡ„еҖјпјҢе…¶е®һиҝҳжҳҜжІЎе•Ҙзү№еҲ«зҡ„пјҢж„ҹи§үиҝҳжІЎжңүforеҫӘзҺҜеҘҪз”ЁгҖӮ
дёҚиҝҮпјҢдёҚзҹҘйҒ“дҪ жңүжІЎжңүжғіиҝҮпјҢеҰӮжһңдҪ еҸӘйңҖиҰҒдёҖдёӘеҖјпјҢдҪ nextдёҖж¬Ўе°ұеҸҜд»ҘдәҶпјҢ然еҗҺдҪ еҸҜд»ҘеҺ»еҒҡе…¶д»–дәӢжғ…пјҢзӯүеҲ°йңҖиҰҒзҡ„ж—¶еҖҷжүҚеӣһжқҘеҶҚж¬ЎnextеҸ–еҖјгҖӮ
е°ұиҝҷдёҖйғЁеҲҶиҖҢиЁҖпјҢдҪ д№ҹи®ёзҹҘйҒ“дёәе•ҘиҜҙз”ҹжҲҗеҷЁжҳҜеҸҜд»ҘжҡӮеҒңзҡ„дәҶпјҢдёҚиҝҮпјҢиҝҷдјјд№Һд№ҹжІЎд»Җд№Ҳз”ЁпјҢйӮЈжҳҜеӣ дёәдҪ дёҚзҹҘеҲ°ж—¶пјҢз”ҹжҲҗеҷЁйҷӨдәҶеҸҜд»ҘжҠӣеҮәеҖјпјҢиҝҳиғҪе°ҶеҖјдј йҖ’иҝӣеҺ»гҖӮ
жҺҘдёӢжқҘжҲ‘们зңӢsendзҡ„дҫӢеӯҗгҖӮ
def gen_func():
a = yield 1
print("a: ", a)
b = yield 2
print("b: ", b)
c = yield 3
print("c: ", c)
return "finish"
if __name__ == '__main__':
gen = gen_func()
for i in range(4):
if i == 0:
print(gen.send(None))
else:
# еӣ дёәgenз”ҹжҲҗеҷЁйҮҢйқўеҸӘжңүдёүдёӘyieldпјҢйӮЈд№ҲеҸӘиғҪеҫӘзҺҜдёүж¬ЎгҖӮ
# 第еӣӣж¬ЎеҫӘзҺҜзҡ„ж—¶еҖҷ,з”ҹжҲҗеҷЁдјҡжҠӣеҮәStopIterationејӮеёё,并且returnиҜӯеҸҘйҮҢйқўеҶ…е®№ж”ҫеңЁStopIterationејӮеёёйҮҢйқў
try:
print(gen.send(i))
except StopIteration as e:
print("e: ", e)
output:
1
a: 1
2
b: 2
3
c: 3
e: finishsendжңүзқҖnextе·®дёҚеӨҡзҡ„еҠҹиғҪпјҢдёҚиҝҮsendеңЁдј йҖ’дёҖдёӘеҖјз»ҷз”ҹжҲҗеҷЁзҡ„еҗҢж—¶пјҢиҝҳиғҪиҺ·еҸ–еҲ°з”ҹжҲҗеҷЁyieldжҠӣеҮәзҡ„еҖјпјҢеңЁдёҠйқўзҡ„д»Јз ҒдёӯпјҢsendеҲҶеҲ«е°ҶNone,1,2,3еӣӣдёӘеҖјдј йҖ’з»ҷдәҶз”ҹжҲҗеҷЁпјҢд№ӢжүҖд»Ҙ第дёҖйңҖиҰҒдј йҖ’Noneз»ҷз”ҹжҲҗеҷЁпјҢжҳҜеӣ дёә规е®ҡпјҢд№ӢжүҖд»Ҙ规е®ҡпјҢеӣ дёә第дёҖж¬Ўдј йҖ’иҝҮеҺ»зҡ„еҖјжІЎжңүзү№е®ҡзҡ„еҸҳйҮҸжҲ–иҖ…иҜҙеҜ№иұЎиғҪжҺҘ收пјҢжүҖд»Ҙ规е®ҡеҸӘиғҪдј йҖ’None, еҰӮжһңдҪ дј йҖ’дёҖдёӘйқһNoneзҡ„еҖјиҝӣеҺ»пјҢдјҡжҠӣеҮәдёҖдёӢй”ҷиҜҜ
TypeError: can't send non-None value to a just-started generatorд»ҺдёҠйқўзҡ„дҫӢеӯҗжҲ‘们д№ҹеҸ‘зҺ°пјҢз”ҹжҲҗеҷЁйҮҢйқўзҡ„еҸҳйҮҸa,b,cиҺ·еҫ—дәҶпјҢsendеҮҪж•°еҸ‘йҖҒе°ҶжқҘзҡ„1, 2, 3.
еҰӮжһңдҪ жңүдәӢ件еҫӘзҺҜжҲ–иҖ…иҜҙеӨҡи·ҜеӨҚз”Ёзҡ„з»ҸйӘҢпјҢдҪ д№ҹи®ёиғҪеӨҹйҡҗйҡҗеҜҹи§үеҲ°еҫ®еҰҷзҡ„ж„ҹи§үгҖӮ
иҝҷдёӘеҫ®еҰҷзҡ„ж„ҹи§үжҳҜпјҢжҳҜеҗҰеҸҜд»Ҙе°ҶIOж“ҚдҪңyieldеҮәжқҘпјҹз”ұдәӢ件еҫӘзҺҜи°ғеәҰ, еҰӮжһңдҪ иғҪgetеҲ°иҝҷдёӘеҫ®еҰҷзҡ„ж„ҹи§ү,йӮЈд№ҲдҪ е·Із»ҸзҹҘйҒ“еҚҸзЁӢй«ҳ并еҸ‘зҡ„з§ҳеҜҶдәҶ.
дҪҶжҳҜиҝҳе·®дёҖзӮ№зӮ№.е—Ҝ, иҝҳе·®дёҖзӮ№зӮ№дәҶ.
дёӢйқўжҳҜyield fromзҡ„дҫӢеӯҗ
def gen_func():
a = yield 1
print("a: ", a)
b = yield 2
print("b: ", b)
c = yield 3
print("c: ", c)
return 4
def middle():
gen = gen_func()
ret = yield from gen
print("ret: ", ret)
return "middle Exception"
def main():
mid = middle()
for i in range(4):
if i == 0:
print(mid.send(None))
else:
try:
print(mid.send(i))
except StopIteration as e:
print("e: ", e)
if __name__ == '__main__':
main()
output:
1
a: 1
2
b: 2
3
c: 3
ret: 4
e: middle Exceptionд»ҺдёҠйқўзҡ„д»Јз ҒжҲ‘们еҸ‘зҺ°,mainеҮҪж•°и°ғз”Ёзҡ„middleеҮҪж•°зҡ„send,дҪҶжҳҜgen_funcеҮҪж•°еҚҙиғҪжҺҘ收еҲ°mainеҮҪж•°дј йҖ’зҡ„еҖј.жңүдёҖз§ҚйҖҸдј зҡ„ж„ҹи§ү,иҝҷе°ұжҳҜyield fromзҡ„дҪңз”Ё, иҝҷеҫҲе…ій”®гҖӮ
иҖҢyield fromжңҖз»Ҳдј йҖ’еҮәжқҘзҡ„еҖјжҳҜStopIterationејӮеёёпјҢејӮеёёйҮҢйқўзҡ„еҶ…е®№жҳҜжңҖз»ҲжҺҘ收з”ҹжҲҗеҷЁ(жң¬зӨәдҫӢжҳҜgen_func)returnеҮәжқҘзҡ„еҖјпјҢжүҖд»ҘretиҺ·еҫ—дәҶgen_funcеҮҪж•°returnзҡ„4.дҪҶжҳҜretе°ҶејӮеёёйҮҢйқўзҡ„еҖјеҸ–еҮәд№ӢеҗҺдјҡ继з»ӯе°ҶжҺҘ收еҲ°зҡ„ејӮеёёеҫҖдёҠжҠӣпјҢжүҖд»ҘmainеҮҪж•°йҮҢйқўйңҖиҰҒдҪҝз”ЁtryиҜӯеҸҘжҚ•иҺ·ејӮеёёгҖӮиҖҢgen_funcжҠӣеҮәзҡ„ејӮеёёйҮҢйқўзҡ„еҖје·Із»Ҹиў«middleеҮҪж•°жҺҘ收пјҢжүҖд»ҘmiddleеҮҪж•°дјҡе°ҶжҠӣеҮәзҡ„ејӮеёёйҮҢйқўзҡ„еҖји®ҫдёәиҮӘиә«returnзҡ„еҖјпјҢ
иҮіжӯӨз”ҹжҲҗеҷЁзҡ„е…ЁйғЁеҶ…е®№и®Іи§Је®ҢжҜ•пјҢеҰӮжһңпјҢдҪ getеҲ°дәҶиҝҷдәӣеҠҹиғҪпјҢйӮЈд№ҲдҪ е·Із»ҸдјҡдҪҝз”Ёз”ҹжҲҗеҷЁдәҶгҖӮ
еҶҚж¬Ўејәи°ғ,жң¬е°Ҹз»“еҸӘжҳҜиҜҙжҳҺз”ҹжҲҗеҷЁзҡ„еҠҹиғҪ,иҮідәҺе…·дҪ“з”ҹжҲҗеҷЁеҶ…йғЁжҖҺд№Ҳе®һзҺ°зҡ„,дҪ еҸҜд»ҘеҺ»зңӢе…¶д»–ж–Үз« ,жҲ–иҖ…йҳ…иҜ»жәҗд»Јз Ғ.
Linuxе№іеҸ°дёҖе…ұжңүдә”еӨ§IOжЁЎеһӢпјҢжҜҸдёӘжЁЎеһӢжңүиҮӘе·ұзҡ„дјҳзӮ№дёҺзЎ®е®ҡгҖӮж №жҚ®еә”з”ЁеңәжҷҜзҡ„дёҚеҗҢеҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„IOжЁЎеһӢгҖӮ
дёҚиҝҮжң¬ж–Үдё»иҰҒзҡ„иҖғиҷ‘еңәжҷҜжҳҜй«ҳ并еҸ‘пјҢжүҖд»Ҙдјҡй’ҲеҜ№й«ҳ并еҸ‘зҡ„еңәжҷҜеҒҡеҮәиҜ„д»·гҖӮ
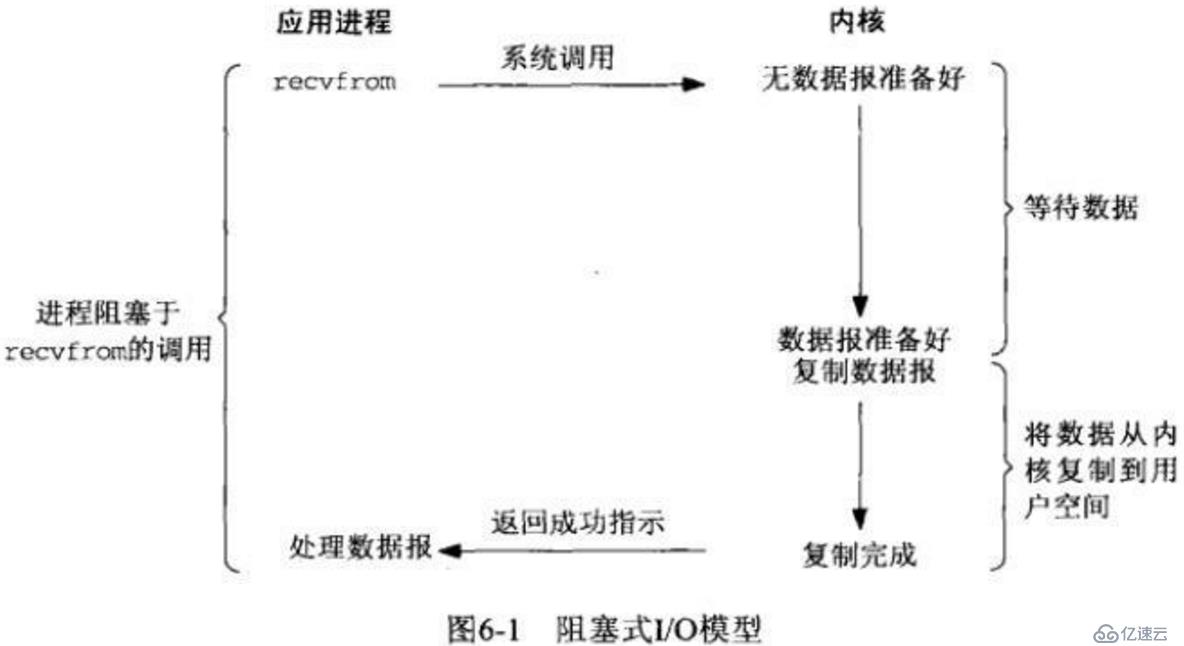
еҗҢжӯҘжЁЎеһӢиҮӘ然жҳҜж•ҲзҺҮжңҖдҪҺзҡ„жЁЎеһӢдәҶпјҢжҜҸж¬ЎеҸӘиғҪеӨ„зҗҶе®ҢдёҖдёӘиҝһжҺҘжүҚиғҪеӨ„зҗҶдёӢдёҖдёӘ,еҰӮжһңеҸӘжңүдёҖдёӘзәҝзЁӢзҡ„иҜқ, еҰӮжһңжңүдёҖдёӘиҝһжҺҘдёҖзӣҙеҚ з”ЁпјҢйӮЈд№ҲеҗҺжқҘиҖ…еҸӘиғҪеӮ»еӮ»зҡ„зӯүдәҶгҖӮжүҖд»ҘдёҚйҖӮеҗҲй«ҳ并еҸ‘пјҢдёҚиҝҮжңҖз®ҖеҚ•пјҢз¬ҰеҗҲжғҜжҖ§жҖқз»ҙгҖӮ

дёҚдјҡйҳ»еЎһеҗҺйқўзҡ„д»Јз ҒпјҢдҪҶжҳҜйңҖиҰҒдёҚеҒңзҡ„жҳҫејҸиҜўй—®еҶ…ж ёж•°жҚ®жҳҜеҗҰеҮҶеӨҮеҘҪпјҢдёҖиҲ¬йҖҡиҝҮwhileеҫӘзҺҜпјҢиҖҢwhileеҫӘзҺҜдјҡиҖ—иҙ№еӨ§йҮҸзҡ„CPUгҖӮжүҖд»Ҙд№ҹдёҚйҖӮеҗҲй«ҳ并еҸ‘гҖӮ
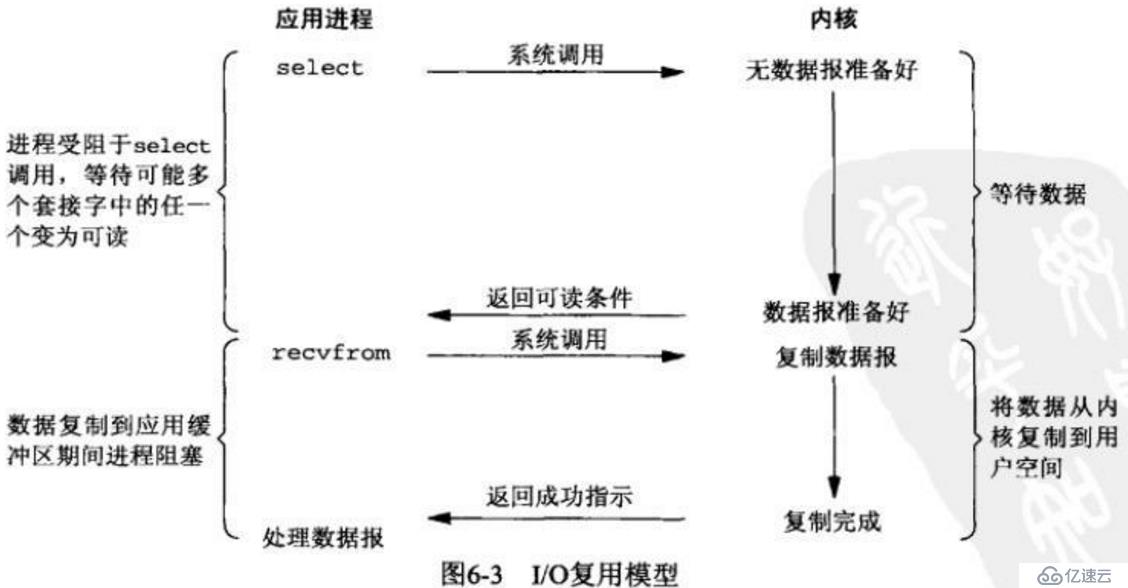
еҪ“еүҚжңҖжөҒиЎҢпјҢдҪҝз”ЁжңҖе№ҝжіӣзҡ„й«ҳ并еҸ‘ж–№жЎҲгҖӮ
иҖҢеӨҡи·ҜеӨҚз”ЁеҸҲжңүдёүз§Қе®һзҺ°ж–№ејҸ, еҲҶеҲ«жҳҜselect, poll, epollгҖӮ
select,pollз”ұдәҺи®ҫи®Ўзҡ„й—®йўҳпјҢеҪ“еӨ„зҗҶиҝһжҺҘиҝҮеӨҡдјҡйҖ жҲҗжҖ§иғҪзәҝжҖ§дёӢйҷҚпјҢиҖҢepollжҳҜеңЁеүҚдәәзҡ„з»ҸйӘҢдёҠеҒҡиҝҮж”№иҝӣзҡ„и§ЈеҶіж–№жЎҲгҖӮдёҚдјҡжңүжӯӨй—®йўҳгҖӮ
дёҚиҝҮselect, poll并дёҚжҳҜдёҖж— жҳҜеӨ„пјҢеҒҮи®ҫеңәжҷҜжҳҜиҝһжҺҘж•°дёҚеӨҡпјҢ并且жҜҸдёӘиҝһжҺҘйқһеёёжҙ»и·ғпјҢselectпјҢpollжҳҜиҰҒжҖ§иғҪй«ҳдәҺepollзҡ„гҖӮ
иҮідәҺдёәе•ҘпјҢжҹҘзңӢе°Ҹз»“еҸӮиҖғй“ҫжҺҘ, жҲ–иҖ…иҮӘиЎҢжҹҘиҜўиө„ж–ҷгҖӮ
дҪҶжҳҜжң¬ж–Үи®Іи§Јзҡ„й«ҳ并еҸ‘еҸҜжҳҜжҢҮзҡ„иҝһжҺҘж•°йқһеёёеӨҡзҡ„гҖӮ
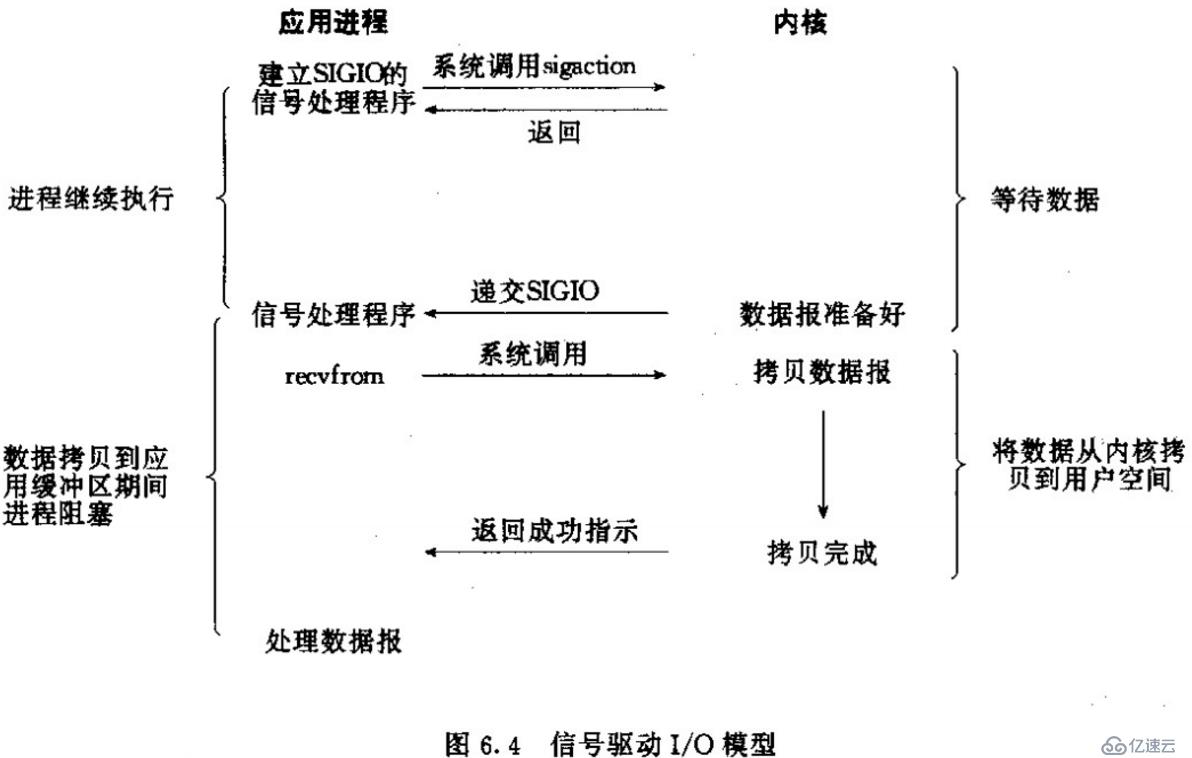
еҫҲеҒҸй—Ёзҡ„дёҖдёӘIOжЁЎеһӢпјҢдёҚжӣҫйҒҮи§ҒиҝҮдҪҝз”ЁжЎҲдҫӢгҖӮзңӢжЁЎеһӢд№ҹдёҚи§Ғеҫ—жҜ”еӨҡи·ҜеӨҚз”ЁеҘҪз”ЁгҖӮ
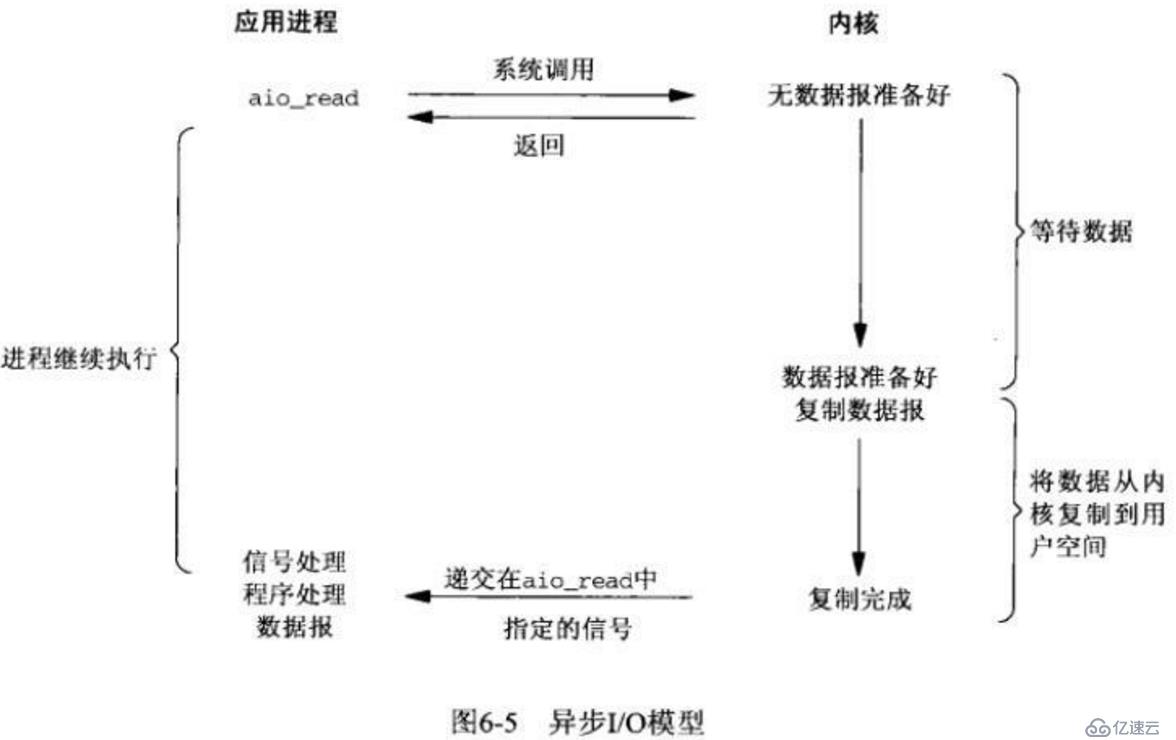
з”Ёеҫ—дёҚжҳҜеҫҲеӨҡпјҢзҗҶи®әдёҠжҜ”еӨҡи·ҜеӨҚз”Ёжӣҙеҝ«пјҢеӣ дёәе°‘дәҶдёҖж¬Ўи°ғз”ЁпјҢдҪҶжҳҜе®һйҷ…дҪҝ用并没жңүжҜ”еӨҡи·ҜеӨҚз”Ёеҝ«йқһеёёеӨҡпјҢжүҖд»Ҙдёәе•ҘдёҚдҪҝз”Ёе№ҝжіӣдҪҝз”Ёзҡ„еӨҡи·ҜеӨҚз”ЁгҖӮ
дҪҝз”ЁжңҖе№ҝжіӣеӨҡи·ҜеӨҚз”Ёepoll, еҸҜд»ҘдҪҝеҫ—IOж“ҚдҪңжӣҙжңүж•ҲзҺҮгҖӮдҪҶжҳҜдҪҝз”ЁдёҠжңүдёҖе®ҡзҡ„йҡҫеәҰгҖӮ
иҮіжӯӨпјҢеҰӮжһңдҪ зҗҶи§ЈдәҶеӨҡи·ҜеӨҚз”Ёзҡ„IOжЁЎеһӢпјҢйӮЈд№ҲдҪ дәҶи§Јpythonдёәд»Җд№ҲиғҪеӨҹйҖҡиҝҮеҚҸзЁӢе®һзҺ°й«ҳ并еҸ‘зҡ„дёүеҲҶд№ӢдәҢдәҶгҖӮ
IOжЁЎеһӢеҸӮиҖғ: https://www.jianshu.com/p/486b0965c296
select,poll,epollеҢәеҲ«еҸӮиҖғ: https://www.cnblogs.com/Anker/p/3265058.html
дёҠйқўзҡ„IOжЁЎеһӢиғҪеӨҹи§ЈеҶіIOзҡ„ж•ҲзҺҮй—®йўҳпјҢдҪҶжҳҜе®һйҷ…дҪҝз”Ёиө·жқҘйңҖиҰҒдёҖдёӘдәӢ件еҫӘзҺҜй©ұеҠЁеҚҸзЁӢеҺ»еӨ„зҗҶIOгҖӮ
дёӢйқўеј•з”Ёе®ҳж–№зҡ„дёҖдёӘз®ҖеҚ•дҫӢеӯҗгҖӮ
import selectors
import socket
# еҲӣе»әдёҖдёӘselctorеҜ№иұЎ
# еңЁдёҚеҗҢзҡ„е№іеҸ°дјҡдҪҝз”ЁдёҚеҗҢзҡ„IOжЁЎеһӢ,жҜ”еҰӮLinuxдҪҝз”Ёepoll, windowsдҪҝз”Ёselect(дёҚзЎ®е®ҡ)
# дҪҝз”Ёselectи°ғеәҰIO
sel = selectors.DefaultSelector()
# еӣһи°ғеҮҪж•°,з”ЁдәҺжҺҘ收新иҝһжҺҘ
def accept(sock, mask):
conn, addr = sock.accept() # Should be ready
print('accepted', conn, 'from', addr)
conn.setblocking(False)
sel.register(conn, selectors.EVENT_READ, read)
# еӣһи°ғеҮҪж•°,з”ЁжҲ·иҜ»еҸ–clientз”ЁжҲ·ж•°жҚ®
def read(conn, mask):
data = conn.recv(1000) # Should be ready
if data:
print('echoing', repr(data), 'to', conn)
conn.send(data) # Hope it won't block
else:
print('closing', conn)
sel.unregister(conn)
conn.close()
# еҲӣе»әдёҖдёӘйқһе өеЎһзҡ„socket
sock = socket.socket()
sock.bind(('localhost', 1234))
sock.listen(100)
sock.setblocking(False)
sel.register(sock, selectors.EVENT_READ, accept)
# дёҖдёӘдәӢ件еҫӘзҺҜ,з”ЁдәҺIOи°ғеәҰ
# еҪ“IOеҸҜиҜ»жҲ–иҖ…еҸҜеҶҷзҡ„ж—¶еҖҷ, жү§иЎҢдәӢ件жүҖеҜ№еә”зҡ„еӣһи°ғеҮҪж•°
def loop():
while True:
events = sel.select()
for key, mask in events:
callback = key.data
callback(key.fileobj, mask)
if __name__ == '__main__':
loop()
дёҠйқўд»Јз ҒдёӯloopеҮҪж•°еҜ№еә”дәӢ件еҫӘзҺҜ,е®ғиҰҒеҒҡзҡ„е°ұжҳҜдёҖйҒҚдёҖйҒҚзҡ„зӯүеҫ…IO,然еҗҺи°ғз”ЁдәӢ件зҡ„еӣһи°ғеҮҪж•°.
дҪҶжҳҜдҪңдёәдәӢ件еҫӘзҺҜиҝңиҝңдёҚеӨҹ,жҜ”еҰӮжҖҺд№ҲеҒңжӯў,жҖҺд№ҲеңЁдәӢ件еҫӘзҺҜдёӯеҠ е…Ҙе…¶д»–йҖ»иҫ‘.
еҰӮжһңе°ұеҠҹиғҪиҖҢиЁҖ,дёҠйқўзҡ„д»Јз Ғдјјд№Һе·Із»Ҹе®ҢжҲҗдәҶй«ҳ并еҸ‘зҡ„еҪұеӯҗ,дҪҶжҳҜеҰӮдҪ жүҖи§Ғ,зӣҙжҺҘдҪҝз”Ёselectзҡ„зј–з ҒйҡҫеәҰжҜ”иҫғеӨ§, еҶҚиҖ…еӣһи°ғеҮҪж•°зҙ жқҘжңү"еӣһи°ғең°зӢұ"зҡ„жҒ¶еҗҚ.
е®һйҷ…з”ҹжҙ»дёӯзҡ„й—®йўҳиҰҒеӨҚжқӮзҡ„еӨҡпјҢдҪңдёәдёҖдёӘи°ғеә“зӢӮйӯ”пјҢжҖҺд№ҲеҸҜиғҪдјҡиҮӘе·ұеҺ»е®һзҺ°иҝҷдәӣпјҢжүҖд»Ҙpythonе®ҳж–№е®һзҺ°дәҶдёҖдёӘи·Ёе№іеҸ°зҡ„дәӢ件еҫӘзҺҜпјҢиҮідәҺIOжЁЎеһӢе…·дҪ“йҖүжӢ©пјҢе®ҳж–№дјҡеҒҡйҖӮй…ҚеӨ„зҗҶгҖӮ
дёҚиҝҮе®ҳж–№е®һзҺ°жҳҜеңЁPython3.5еҸҠд»ҘеҗҺдәҶпјҢ3.5д№ӢеүҚзҡ„зүҲжң¬еҸӘиғҪдҪҝ用第дёүж–№е®һзҺ°зҡ„й«ҳ并еҸ‘ејӮжӯҘIOи§ЈеҶіж–№жЎҲ, жҜ”еҰӮtornado,gevent,twistedгҖӮ
иҮіжӯӨдҪ йңҖиҰҒgetеҲ°pythonй«ҳ并еҸ‘зҡ„еҝ…иҰҒжқЎд»¶дәҶ.
еңЁжң¬ж–ҮејҖеӨҙ,笔иҖ…е°ұиҜҙиҝҮ,pythonиҰҒе®ҢжҲҗй«ҳ并еҸ‘йңҖиҰҒеҚҸзЁӢ,дәӢ件еҫӘзҺҜ,й«ҳж•ҲIOжЁЎеһӢ.иҖҢPythonиҮӘеёҰзҡ„asyncioжЁЎеқ—е·Із»Ҹе…ЁйғЁе®ҢжҲҗдәҶ.е°Ҫжғ…дҪҝз”Ёеҗ§.
дёӢйқўжҳҜжңүеј•з”Ёе®ҳж–№зҡ„дёҖдёӘдҫӢеӯҗ
import asyncio
# йҖҡиҝҮasyncеЈ°жҳҺдёҖдёӘеҚҸзЁӢ
async def handle_echo(reader, writer):
# е°ҶйңҖиҰҒioзҡ„еҮҪж•°дҪҝз”Ёawaitзӯүеҫ…, йӮЈд№ҲжӯӨеҮҪж•°е°ұдјҡеҒңжӯў
# еҪ“IOж“ҚдҪңе®ҢжҲҗдјҡе”ӨйҶ’иҝҷдёӘеҚҸзЁӢ
# еҸҜд»Ҙе°ҶawaitзҗҶи§Јдёәyield from
data = await reader.read(100)
message = data.decode()
addr = writer.get_extra_info('peername')
print("Received %r from %r" % (message, addr))
print("Send: %r" % message)
writer.write(data)
await writer.drain()
print("Close the client socket")
writer.close()
# еҲӣе»әдәӢ件еҫӘзҺҜ
loop = asyncio.get_event_loop()
# йҖҡиҝҮasyncio.start_serverж–№жі•еҲӣе»әдёҖдёӘеҚҸзЁӢ
coro = asyncio.start_server(handle_echo, '127.0.0.1', 8888, loop=loop)
server = loop.run_until_complete(coro)
# Serve requests until Ctrl+C is pressed
print('Serving on {}'.format(server.sockets[0].getsockname()))
try:
loop.run_forever()
except KeyboardInterrupt:
pass
# Close the server
server.close()
loop.run_until_complete(server.wait_closed())
loop.close()жҖ»зҡ„жқҘиҜҙpython3.5жҳҺзЎ®дәҶд»Җд№ҲжҳҜеҚҸзЁӢпјҢд»Җд№ҲжҳҜз”ҹжҲҗеҷЁпјҢиҷҪ然еҺҹзҗҶе·®дёҚеӨҡпјҢдҪҶжҳҜиҝҷж ·дјҡдҪҝеҫ—дёҚдјҡи®©з”ҹжҲҗеҷЁеҚіеҸҜд»ҘдҪңдёәз”ҹжҲҗеҷЁдҪҝз”Ё(жҜ”еҰӮиҝӯд»Јж•°жҚ®)еҸҲеҸҜд»ҘдҪңдёәеҚҸзЁӢгҖӮ
жүҖд»Ҙеј•е…ҘдәҶasync,awaitдҪҝеҫ—еҚҸзЁӢзҡ„иҜӯд№үжӣҙеҠ жҳҺзЎ®гҖӮ
asyncioе®ҳж–№еҸӘе®һзҺ°дәҶжҜ”иҫғеә•еұӮзҡ„еҚҸи®®пјҢжҜ”еҰӮTCPпјҢUDPгҖӮжүҖд»ҘиҜёеҰӮHTTPеҚҸи®®д№Ӣзұ»йғҪйңҖиҰҒеҖҹеҠ©з¬¬дёүж–№еә“пјҢжҜ”еҰӮaiohttpгҖӮ
иҷҪ然ејӮжӯҘзј–зЁӢзҡ„з”ҹжҖҒдёҚеӨҹеҗҢжӯҘзј–зЁӢзҡ„з”ҹжҖҒйӮЈд№ҲејәеӨ§пјҢдҪҶжҳҜеҰӮжһңеҸҲй«ҳ并еҸ‘зҡ„йңҖжұӮдёҚеҰЁиҜ•иҜ•пјҢдёӢйқўиҜҙдёҖдёӢжҜ”иҫғжҲҗзҶҹзҡ„ејӮжӯҘеә“
ејӮжӯҘhttp client/serverжЎҶжһ¶
githubең°еқҖ: https://github.com/aio-libs/aiohttp
йҖҹеәҰжӣҙеҝ«зҡ„зұ»flask webжЎҶжһ¶гҖӮ
githubең°еқҖ:
https://github.com/channelcat/sanic
еҝ«йҖҹпјҢеҶ…еөҢдәҺasyncioдәӢ件еҫӘзҺҜзҡ„еә“пјҢдҪҝз”ЁcythonеҹәдәҺlibuvе®һзҺ°гҖӮ
е®ҳж–№жҖ§иғҪжөӢиҜ•:
nodejsзҡ„дёӨеҖҚпјҢиҝҪе№іgolang
githubең°еқҖ: https://github.com/MagicStack/uvloop
дёәдәҶеҮҸе°‘жӯ§д№үпјҢиҝҷйҮҢзҡ„жҖ§иғҪжөӢиҜ•еә”иҜҘеҸӘжҳҜзҪ‘з»ңIOй«ҳ并еҸ‘ж–№йқўдёҚжҳҜиҜҙд»»дҪ•ж–№йқўиҝҪе№іgolangгҖӮ
Pythonд№ӢжүҖд»ҘиғҪеӨҹеӨ„зҗҶзҪ‘з»ңIOй«ҳ并еҸ‘пјҢжҳҜеӣ дёәеҖҹеҠ©дәҶй«ҳж•Ҳзҡ„IOжЁЎеһӢпјҢиғҪеӨҹжңҖеӨ§йҷҗеәҰзҡ„и°ғеәҰIOпјҢ然еҗҺдәӢ件еҫӘзҺҜдҪҝз”ЁеҚҸзЁӢеӨ„зҗҶIOпјҢеҚҸзЁӢйҒҮеҲ°IOж“ҚдҪңе°ұе°ҶжҺ§еҲ¶жқғжҠӣеҮәпјҢйӮЈд№ҲеңЁIOеҮҶеӨҮеҘҪд№ӢеүҚзҡ„иҝҷж®өдәӢ件пјҢдәӢ件еҫӘзҺҜе°ұеҸҜд»ҘдҪҝз”Ёе…¶д»–зҡ„еҚҸзЁӢеӨ„зҗҶе…¶д»–дәӢжғ…пјҢ然еҗҺеҚҸзЁӢеңЁз”ЁжҲ·з©әй—ҙпјҢ并且жҳҜеҚ•зәҝзЁӢзҡ„пјҢжүҖд»ҘдёҚдјҡеғҸеӨҡзәҝзЁӢпјҢеӨҡиҝӣзЁӢйӮЈж ·йў‘з№Ғзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢеӣ иҖҢиғҪеӨҹиҠӮзңҒеӨ§йҮҸзҡ„дёҚеҝ…иҰҒжҖ§иғҪжҚҹеӨұгҖӮ
жіЁ: дёҚиҰҒеҶҚеҚҸзЁӢйҮҢйқўдҪҝз”Ёtime.sleepд№Ӣзұ»зҡ„еҗҢжӯҘж“ҚдҪңпјҢеӣ дёәеҚҸзЁӢеҶҚеҚ•зәҝзЁӢйҮҢйқўпјҢжүҖд»ҘдјҡдҪҝеҫ—ж•ҙдёӘзәҝзЁӢеҒңдёӢжқҘзӯүеҫ…пјҢд№ҹе°ұжІЎжңүеҚҸзЁӢзҡ„дјҳеҠҝдәҶ
жң¬ж–Үдё»иҰҒи®Іи§ЈPythonдёәд»Җд№ҲиғҪеӨҹеӨ„зҗҶй«ҳ并еҸ‘,дёҚжҳҜдёәдәҶи®Іи§ЈжҹҗдёӘеә“жҖҺд№ҲдҪҝз”Ё,жүҖд»ҘдҪҝз”Ёз»ҶиҠӮиҜ·жҹҘйҳ…е®ҳж–№ж–ҮжЎЈжҲ–иҖ…жү§иЎҢгҖӮ
ж— и®әд»Җд№Ҳзј–зЁӢиҜӯиЁҖпјҢй«ҳжҖ§иғҪжЎҶжһ¶пјҢдёҖиҲ¬з”ұдәӢ件еҫӘзҺҜ + й«ҳжҖ§иғҪIOжЁЎеһӢ(д№ҹи®ёжҳҜepoll)з»„жҲҗгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ