您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“消息队列应用场景和注意事项有哪些”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“消息队列应用场景和注意事项有哪些”吧!

我们可以把消息队列看作是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。
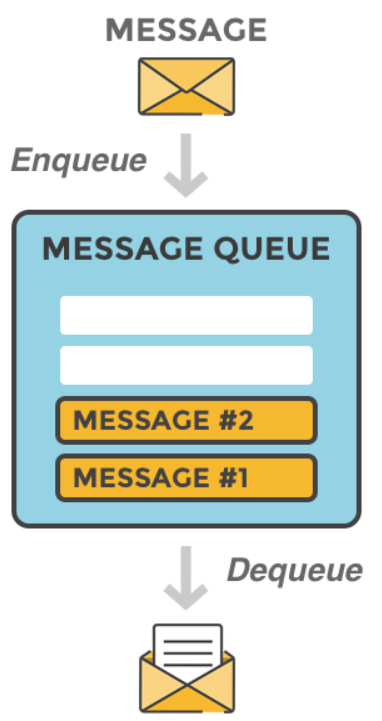
队列Queue是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。
通常来说,使用消息队列能为我们的系统带来下面三点好处:
鸿蒙官方战略合作共建——HarmonyOS技术社区
异步处理,通过异步处理提高系统性能,减少响应所需时间
流量削峰,避免高并发访问直接把数据库搞挂
应用解耦,降低系统耦合性
同步处理过程

异步处理过程

将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,使用消息队列进行异步处理之后,需要适当修改业务流程进行配合,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们用手机订火车票和电影票。
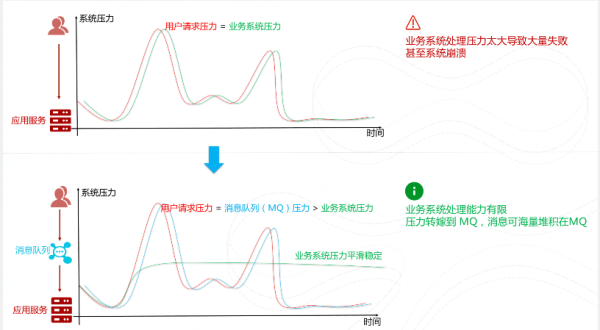
先将短时间高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。
例如:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
假设有这样的一个场景:A系统发送数据到B、C、D三个系统,通过接口调用发送。如果E系统也要这个数据呢?那如果C系统现在不需要了呢?A系统负责人几乎要改到崩溃......
在这个场景中,A 系统跟其它各种乱七八糟的系统严重耦合,A系统产生一条比较关键的数据,很多系统都需要A系统将这个数据发送过来。A系统要时时刻刻考虑B、C、D、E四个系统如果挂了该怎么办?要不要重发,要不要把消息存起来?头发都白了啊!
如果使用MQ,A系统产生一条数据,发送到MQ里面去,哪个系统需要数据自己去MQ里面消费。如果新系统需要数据,直接从MQ里消费即可;如果某个系统不需要这条数据了,就取消对MQ消息的消费即可。这样下来,A系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。如下图所示:
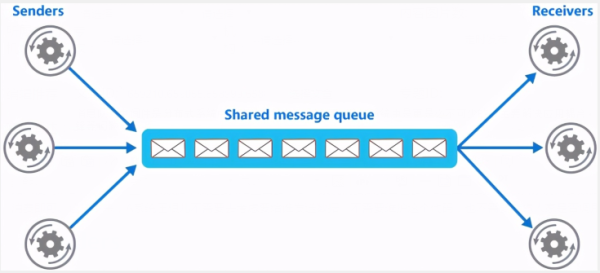
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
消息队列是用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。 从上图可以看到消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现系统业务的可扩展性设计。
系统可用性降低: 系统可用性在某种程度上降低,系统引入的外部依赖越多,越容易挂掉。在加入MQ之前,我们不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后需要去考虑如何保证消息队列的高可用,否则MQ一挂就有可能导致整套系统崩溃!
系统复杂性提高: 加入MQ之后,我们需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
数据一致性问题: 上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况!
市面上有很多MQ产品,主流的就是Kafka、ActiveMQ、RabbitMQ、RocketMQ这四种,但是我们在做技术选型的时候该用哪一个呢?每一个MQ没有绝对的好坏,就是看用在哪个场景可以扬长避短,利用其优势,规避其劣势。

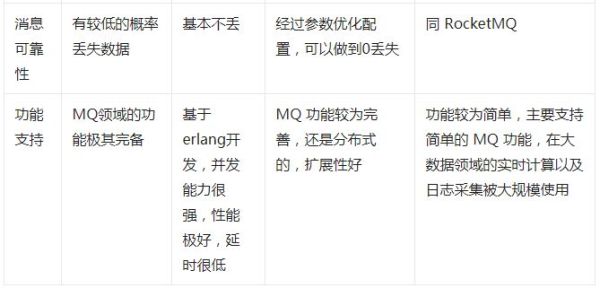
ActiveMQ:的社区算是比较成熟,但是较目前来说,ActiveMQ的性能比较差,而且版本迭代很慢,不推荐使用。
RabbitMQ:在吞吐量方面虽然稍逊于Kafka和RocketMQ ,但是由于它基于erlang开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为RabbitMQ基于erlang开发,所以国内很少有公司有实力做erlang源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这四种消息队列中,RabbitMQ一定是你的首选。如果是大数据领域的实时计算、日志采集等场景,用Kafka是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
RocketMQ:阿里出品,Java系开源项目,源代码我们可以直接阅读,然后可以定制自己公司的MQ,并且 RocketMQ有阿里巴巴的实际业务场景的实战考验。RocketMQ 社区活跃度相对较为一般,目前RocketMQ已捐给 Apache,但 GitHub 上的活跃度其实不算高,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用RabbitMQ吧,人家有活跃的开源社区,绝对不会黄。
Kafka:特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量。kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。
到此,相信大家对“消息队列应用场景和注意事项有哪些”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。