жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚжҖҺд№Ҳжһ„е»әOpenStackзҡ„й«ҳеҸҜз”ЁжҖ§пјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
1гҖҒCAPзҗҶи®ә
1пјү CAP зҗҶи®әз»ҷеҮәдәҶ3дёӘеҹәжң¬иҰҒзҙ пјҡ
дёҖиҮҙжҖ§ ( Consistency) пјҡд»»дҪ•дёҖдёӘиҜ»ж“ҚдҪңжҖ»жҳҜиғҪиҜ»еҸ–еҲ°д№ӢеүҚе®ҢжҲҗзҡ„еҶҷж“ҚдҪңз»“жһңпјӣ
еҸҜз”ЁжҖ§ ( Availability) пјҡжҜҸдёҖдёӘж“ҚдҪңжҖ»жҳҜиғҪеӨҹеңЁзЎ®е®ҡзҡ„ж—¶й—ҙеҶ…иҝ”еӣһпјӣ
еҲҶеҢәеҸҜе®№еҝҚжҖ§ (Tolerance of network Partition) пјҡеңЁеҮәзҺ°зҪ‘з»ңеҲҶеҢәзҡ„жғ…еҶөдёӢпјҢд»Қ然иғҪеӨҹж»Ўи¶ідёҖиҮҙжҖ§е’ҢеҸҜз”ЁжҖ§пјӣ
CAP зҗҶи®әжҢҮеҮәпјҢдёүиҖ…дёҚиғҪеҗҢж—¶ж»Ўи¶ігҖӮеҜ№иҝҷдёӘзҗҶи®әжңүдёҚе°‘ејӮи®®пјҢдҪҶжҳҜе®ғзҡ„еҸӮиҖғд»·еҖјдҫқ然巨еӨ§гҖӮ
иҝҷдёӘзҗҶи®ә并дёҚиғҪдёәдёҚж»Ўи¶іиҝҷ3дёӘеҹәжң¬иҰҒжұӮзҡ„и®ҫи®ЎжҸҗдҫӣеҖҹеҸЈпјҢеҸӘжҳҜиҜҙжҳҺзҗҶи®әдёҠ3иҖ…дёҚеҸҜз»қеҜ№зҡ„ж»Ўи¶іпјҢиҖҢдё”е·ҘзЁӢдёҠд»ҺжқҘдёҚиҰҒжұӮз»қеҜ№зҡ„дёҖиҮҙжҖ§жҲ–иҖ…еҸҜз”ЁжҖ§пјҢдҪҶжҳҜеҝ…йЎ»еҜ»жұӮдёҖз§Қе№іиЎЎе’Ң***гҖӮ
еҜ№дәҺеҲҶеёғејҸж•°жҚ®зі»з»ҹпјҢеҲҶеҢәе®№еҝҚжҖ§жҳҜеҹәжң¬иҰҒжұӮгҖӮеӣ жӯӨи®ҫи®ЎеҲҶеёғејҸж•°жҚ®зі»з»ҹпјҢеҫҲеӨҡж—¶еҖҷжҳҜеңЁдёҖиҮҙжҖ§е’ҢеҸҜз”ЁжҖ§пјҲеҸҜйқ жҖ§пјүд№Ӣй—ҙеҜ»жұӮдёҖдёӘе№іиЎЎгҖӮжӣҙеӨҡзҡ„зі»з»ҹжҖ§иғҪе’Ңжһ¶жһ„зҡ„и®Ёи®әд№ҹжҳҜеӣҙз»•дёҖиҮҙжҖ§е’ҢеҸҜз”ЁжҖ§еұ•ејҖгҖӮ
2пјү OpenStackгҖҒSwiftдёҺCAPзҡ„е·ҘзЁӢе®һи·ө
еҜ№з…§CAPзҗҶи®әпјҢOpenStackзҡ„еҲҶеёғејҸеҜ№иұЎеӯҳеӮЁзі»з»ҹSwiftж»Ўи¶ідәҶеҸҜз”ЁжҖ§е’ҢеҲҶеҢәе®№еҝҚжҖ§пјҢжІЎжңүдҝқиҜҒдёҖиҮҙжҖ§пјҲеҸҜйҖүзҡ„пјүпјҢеҸӘжҳҜе®һзҺ°дәҶжңҖз»ҲдёҖиҮҙжҖ§гҖӮSwiftеҰӮжһңGETж“ҚдҪңжІЎжңүеңЁиҜ·жұӮеӨҙдёӯеҢ…еҗ«’X-Newest’еӨҙпјҢйӮЈд№Ҳиҝҷж¬ЎиҜ»еҸ–жңүеҸҜиғҪиҜ»еҲ°зҡ„дёҚжҳҜ***зҡ„objectпјҢеңЁдёҖиҮҙжҖ§зӘ—еҸЈж—¶й—ҙеҶ…objectжІЎжңүиў«жӣҙж–°пјҢйӮЈд№ҲеҗҺз»ӯGETж“ҚдҪңиҜ»еҸ–зҡ„objectе°ҶжҳҜ***зҡ„пјҢдҝқиҜҒдәҶжңҖз»ҲдёҖиҮҙжҖ§пјӣеҸҚд№ӢеҢ…еҗ«дәҶ’X-Newest’еӨҙпјҢGETж“ҚдҪңе§Ӣз»ҲиғҪиҜ»еҸ–еҲ°***зҡ„obejctпјҢе°ұжҳҜдёҖиҮҙзҡ„гҖӮ
еңЁOpenStackжһ¶жһ„дёӯпјҢеҜ№дәҺй«ҳеҸҜз”ЁжҖ§йңҖиҰҒиҝӣиЎҢеҫҲеӨҡе·ҘдҪңжқҘдҝқиҜҒгҖӮеӣ жӯӨпјҢдёӢйқўе°ҶеҜ№OpenStackз»“жһ„дёӯзҡ„еҸҜз”ЁжҖ§иҝӣиЎҢи®Ёи®әпјҡ
2гҖҒOpenStackзҡ„й«ҳеҸҜз”ЁжҖ§пјҲOpenStack HAпјү
иҰҒеј„жё…жҘҡжҖҺд№Ҳе®һзҺ°й«ҳеҸҜз”ЁжҖ§пјҢе°ұйңҖиҰҒзҹҘйҒ“е“ӘдәӣжңҚеҠЎе®№жҳ“еҮәзҺ°дёҚеҸҜйқ гҖӮйҰ–е…ҲдәҶи§ЈдёҖдәӣOpenStackзҡ„еӨ§иҮҙз»“жһ„гҖӮ
OpenStackз”ұ5еӨ§з»„件组жҲҗпјҲи®Ўз®—novaпјҢиә«д»Ҫз®ЎзҗҶkeystoneпјҢй•ңеғҸз®ЎзҗҶglanceпјҢеүҚз«Ҝз®ЎзҗҶdashboardе’ҢеҜ№иұЎеӯҳеӮЁswiftпјүгҖӮ
novaжҳҜи®Ўз®—гҖҒжҺ§еҲ¶зҡ„ж ёеҝғ组件пјҢе®ғеҸҲеҢ…жӢ¬nova-computeгҖҒnova-schedulerгҖҒnova-volumeгҖҒnova-networkе’Ңnova-apiзӯүжңҚеҠЎгҖӮеҖҹз”Ёhttp://ken.people.infoзҡ„д»ҘдёӢиҝҷе№…еӣҫдәҶи§ЈOpenStackзҡ„5еӨ§з»„件е’ҢеҠҹиғҪпјҡ
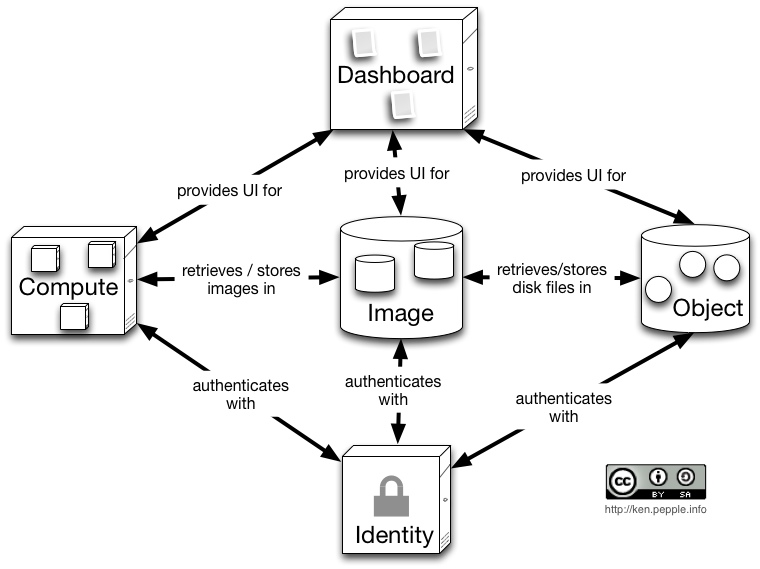
дёӢйқўиҝҷе№…еӣҫжҸҸиҝ°дәҶеҗ„дёӘ组件зҡ„еҠҹиғҪе’ҢжңҚеҠЎз»“жһ„пјҡ
еҗҢе…¶е®ғеӨ§йғЁеҲҶеҲҶеёғејҸзі»з»ҹдёҖж ·пјҢOpenStackд№ҹеҲҶдёәжҺ§еҲ¶иҠӮзӮ№е’Ңи®Ўз®—иҠӮзӮ№дёӨз§ҚдёҚеҗҢеҠҹиғҪзҡ„иҠӮзӮ№гҖӮжҺ§еҲ¶иҠӮзӮ№жҸҗдҫӣйҷӨnova-computeд»ҘеӨ–зҡ„жңҚеҠЎгҖӮиҝҷдәӣ组件е’ҢжңҚеҠЎйғҪжҳҜеҸҜд»ҘзӢ¬з«Ӣе®үиЈ…зҡ„пјҢеҸҜд»ҘйҖүжӢ©з»„еҗҲгҖӮ
nova-computeеңЁжҜҸдёӘи®Ўз®—иҠӮзӮ№иҝҗиЎҢпјҢжҡӮдё”еҒҮи®ҫе®ғжҳҜеҸҜдҝЎд»»зҡ„пјӣжҲ–иҖ…дҪҝз”ЁеӨҮд»ҪжңәжқҘе®һзҺ°ж•…йҡңиҪ¬з§»пјҲдёҚиҝҮжҜҸдёӘи®Ўз®—иҠӮзӮ№й…ҚзҪ®еӨҮд»Ҫзҡ„д»Јд»·зӣёжҜ”收зӣҠдјјд№ҺеӨӘеӨ§пјүгҖӮ
жҺ§еҲ¶иҠӮзӮ№зҡ„й«ҳеҸҜйқ жҖ§жҳҜдё»иҰҒй—®йўҳпјҢиҖҢдё”еҜ№дәҺдёҚеҗҢзҡ„组件йғҪжңүиҮӘе·ұзҡ„й«ҳеҸҜйқ жҖ§йңҖжұӮе’Ңж–№жЎҲгҖӮ
пјҲ1пјүз”ұдәҺCotrolNodeеҸӘжңүпј‘дёӘпјҢдё”иҙҹиҙЈж•ҙдёӘзі»з»ҹзҡ„з®ЎзҗҶе’ҢжҺ§еҲ¶пјҢеӣ жӯӨеҪ“Cotrol NodeдёҚиғҪжҸҗдҫӣжӯЈеёёжңҚеҠЎж—¶пјҢжҖҺд№ҲеҠһпјҹиҝҷе°ұжҳҜеёёи§Ғзҡ„еҚ•иҠӮзӮ№ж•…йҡңпјҲSPoFпјҢsingle point of failureпјүй—®йўҳгҖӮ
й«ҳеҸҜз”ЁжҖ§еҹәжң¬дёҠжҳҜжІЎеҠһжі•йҖҡиҝҮдёҖеҸ°жқҘиҫҫеҲ°зӣ®ж Үзҡ„пјҢжӣҙеӨҡзҡ„ж—¶еҖҷжҳҜи®ҫи®Ўж–№жЎҲзЎ®дҝқеңЁеҮәй—®йўҳзҡ„ж—¶еҖҷе°Ҫеҝ«жҺҘз®Ўж•…йҡңжңәеҷЁпјҢеҪ“然иҝҷиҰҒд»ҳеҮәжӣҙеӨ§зҡ„жҲҗжң¬гҖӮ
еҜ№дәҺеҚ•зӮ№й—®йўҳпјҢи§ЈеҶізҡ„ж–№жЎҲдёҖиҲ¬жҳҜйҮҮз”ЁеҶ—дҪҷи®ҫеӨҮжҲ–иҖ…зғӯеӨҮпјҢеӣ дёә硬件зҡ„й”ҷиҜҜжҲ–иҖ…дәәдёәзҡ„еҺҹеӣ пјҢжҖ»жҳҜжңүеҸҜиғҪйҖ жҲҗеҚ•дёӘжҲ–еӨҡдёӘиҠӮзӮ№зҡ„еӨұж•ҲпјҢжңүж—¶еҒҡиҠӮзӮ№зҡ„з»ҙжҠӨжҲ–иҖ…еҚҮзә§пјҢд№ҹйңҖиҰҒжҡӮж—¶еҒңжӯўжҹҗдәӣиҠӮзӮ№пјҢжүҖд»ҘдёҖдёӘеҸҜйқ зҡ„зі»з»ҹеҝ…йЎ»иғҪжүҝеҸ—еҚ•дёӘжҲ–еӨҡдёӘиҠӮзӮ№зҡ„еҒңжӯўгҖӮ
еёёи§Ғзҡ„йғЁзҪІжЁЎејҸжңүпјҡActive-passiveдё»еӨҮжЁЎејҸпјҢActive-activeеҸҢдё»еҠЁжЁЎејҸпјҢйӣҶзҫӨжЁЎејҸгҖӮ
пјҲ2пјүйӮЈд№ҲеҰӮдҪ•жһ„е»әеҶ—дҪҷзҡ„жҺ§еҲ¶иҠӮзӮ№пјҹжҲ–иҖ…д»Җд№Ҳе…¶е®ғж–№жі•е®һзҺ°й«ҳеҸҜйқ зҡ„жҺ§еҲ¶пјҹ
еҫҲеӨҡдәәеҸҜиғҪжғіеҲ°е®һзҺ°active-passiveжЁЎејҸпјҢдҪҝз”Ёеҝғи·іжңәеҲ¶жҲ–иҖ…зұ»дјјзҡ„ж–№жі•иҝӣиЎҢеӨҮд»ҪпјҢйҖҡиҝҮж•…йҡңиҪ¬з§»жқҘе®һзҺ°й«ҳеҸҜйқ жҖ§гҖӮOpenstackжҳҜжІЎжңүеӨҡдёӘжҺ§еҲ¶иҠӮзӮ№зҡ„пјҢPacemakerйңҖиҰҒеӨҡз§ҚжңҚеҠЎеҗ„иҮӘе®һзҺ°иҝҷз§ҚеӨҮд»ҪгҖҒзӣ‘еҗ¬е’ҢеҲҮжҚўгҖӮ
д»”з»ҶеҲҶжһҗжҺ§еҲ¶иҠӮзӮ№жҸҗдҫӣзҡ„жңҚеҠЎпјҢдё»иҰҒе°ұжҳҜnova-apiгҖҒnova-networkгҖҒnova-scheduleгҖҒnova-volumeпјҢд»ҘеҸҠglanceгҖҒkeysonteе’Ңж•°жҚ®еә“mysqlзӯүпјҢиҝҷдәӣжңҚеҠЎжҳҜеҲҶејҖжҸҗдҫӣзҡ„гҖӮnova-apiгҖҒnova-networkгҖҒglanceзӯүеҸҜд»ҘеҲҶеҲ«еңЁжҜҸдёӘи®Ўз®—иҠӮзӮ№дёҠе·ҘдҪңпјҢRabbitMQеҸҜд»Ҙе·ҘдҪңеңЁдё»еӨҮжЁЎејҸпјҢmysqlеҸҜд»ҘдҪҝз”ЁеҶ—дҪҷзҡ„й«ҳеҸҜз”ЁйӣҶзҫӨгҖӮ
дёӢйқўеҲҶеҲ«д»Ӣз»Қпјҡ
1пјүnova-apiе’Ңnova-schedulerзҡ„й«ҳеҸҜйқ жҖ§
жҜҸдёӘи®Ўз®—иҠӮзӮ№еҸҜд»ҘиҝҗиЎҢиҮӘе·ұзҡ„nova-apiе’Ңnova-schedulerпјҢжҸҗдҫӣиҙҹиҪҪеқҮиЎЎжқҘдҝқиҜҒиҝҷж ·жӯЈзЎ®е·ҘдҪңгҖӮ
иҝҷж ·еҪ“жҺ§еҲ¶иҠӮзӮ№еҮәзҺ°ж•…йҡңпјҢи®Ўз®—иҠӮзӮ№зҡ„nova-apiзӯүжңҚеҠЎйғҪз…§еёёиҝӣиЎҢгҖӮ
2пјүnova-volumeзҡ„й«ҳеҸҜйқ жҖ§
еҜ№дәҺnova-volumeзӣ®еүҚжІЎжңүе®Ңе–„зҡ„HAпјҲhigh availabilityпјүж–№жі•пјҢиҝҳйңҖиҰҒеҒҡеҫҲеӨҡе·ҘдҪңгҖӮ
дёҚиҝҮпјҢnova-volumeз”ұiSCSIй©ұеҠЁпјҢиҝҷдёӘеҚҸи®®дёҺDRBDз»“еҗҲпјҢжҲ–иҖ…еҹәдәҺiSCSIзҡ„й«ҳеҸҜйқ зҡ„硬件解еҶіж–№жЎҲпјҢеҸҜд»Ҙе®һзҺ°й«ҳеҸҜйқ гҖӮ
3пјү зҪ‘з»ңжңҚеҠЎnova-networkзҡ„й«ҳеҸҜйқ жҖ§
OpenStackзҡ„зҪ‘з»ңе·Із»ҸеӯҳеңЁеӨҡз§Қй«ҳеҸҜйқ зҡ„ж–№жЎҲпјҢеёёз”Ёзҡ„дҪ еҸӘйңҖиҰҒдҪҝз”Ё --multi_host йҖүйЎ№е°ұеҸҜд»Ҙи®©зҪ‘з»ңжңҚеҠЎеӨ„дәҺй«ҳеҸҜз”ЁжЁЎејҸпјҲhigh availability modeпјүпјҢе…·дҪ“д»Ӣз»Қи§ҒExisting High Availability Options for NetworkingгҖӮ
ж–№жЎҲ1: Multi-host
еӨҡдё»жңәгҖӮжҜҸдёӘи®Ўз®—иҠӮзӮ№дёҠй…ҚзҪ®nova-networkгҖӮиҝҷж ·пјҢжҜҸдёӘи®Ўз®—иҠӮзӮ№йғҪдјҡе®һзҺ°NAT, DHCPе’ҢзҪ‘е…ізҡ„еҠҹиғҪпјҢеҝ…然йңҖиҰҒдёҖе®ҡзҡ„ејҖй”ҖпјҢеҸҜд»ҘдёҺhardware gatewayж–№ејҸз»“еҗҲпјҢйҒҝе…ҚжҜҸдёӘи®Ўз®—иҠӮзӮ№зҡ„зҪ‘е…іеҠҹиғҪгҖӮиҝҷж ·пјҢжҜҸдёӘи®Ўз®—иҠӮзӮ№йғҪйңҖиҰҒе®үиЈ…nova-computeеӨ–иҝҳиҰҒnova-networkе’Ңnova-apiпјҢ并且йңҖиҰҒиғҪиҝһжҺҘеӨ–зҪ‘гҖӮе…·дҪ“д»Ӣз»Қи§ҒNova Multi-host Mode against SPoFгҖӮ
ж–№жЎҲ2: Failover
ж•…йҡңиҪ¬з§»гҖӮиғҪеӨҹ4з§’иҪ¬з§»еҲ°зғӯеӨҮд»ҪдёҠпјҢиҜҰз»Ҷд»Ӣз»Қи§Ғhttps://lists.launchpad.net/openstack/msg02099.htmlгҖӮдёҚи¶ід№ӢеӨ„жҳҜпјҢйңҖиҰҒеӨҮд»ҪжңәпјҢиҖҢдё”жңү4秒延иҝҹгҖӮ
ж–№жЎҲ3: Multi-nic
еӨҡзҪ‘еҚЎжҠҖжңҜгҖӮжҠҠVMжЎҘжҺҘеҲ°еӨҡдёӘзҪ‘з»ңпјҢVMе°ұжӢҘжңү2з§Қдј еҮәи·Ҝз”ұпјҢе®һзҺ°ж•…йҡңж—¶еҲҮжҚўгҖӮдҪҶжҳҜиҝҷйңҖиҰҒзӣ‘еҗ¬еӨҡдёӘзҪ‘з»ңпјҢд№ҹйңҖиҰҒи®ҫи®ЎеҲҮжҚўзӯ–з•ҘгҖӮ
ж–№жЎҲ4: Hardware gateway
硬件зҪ‘е…ігҖӮйңҖиҰҒй…ҚзҪ®еӨ–йғЁзҪ‘е…ігҖӮз”ұдәҺVLANжЁЎејҸйңҖиҰҒеҜ№жҜҸдёӘзҪ‘з»ңжңүдёҖдёӘзҪ‘е…іпјҢиҖҢhardware gatewayж–№ејҸеҸӘиғҪеҜ№жүҖжңүе®һдҫӢдҪҝз”ЁдёҖдёӘзҪ‘е…іпјҢеӣ жӯӨдёҚиғҪеңЁVLANжЁЎејҸдёӢдҪҝз”ЁгҖӮ
ж–№жЎҲ5пјҡ QuantumпјҲOpenStackдёӢдёҖдёӘзүҲжң¬Folsomдёӯпјү
Quantumзҡ„зӣ®ж ҮжҳҜйҖҗжӯҘе®һзҺ°еҠҹиғҪе®ҢеӨҮзҡ„иҷҡжӢҹзҪ‘з»ңжңҚеҠЎгҖӮе®ғжҡӮж—¶дјҡ继з»ӯе…је®№ж—§зҡ„nova-networkзҡ„еҠҹиғҪеҰӮFlatгҖҒFlatdhcpзӯүгҖӮдҪҶжҳҜе®һзҺ°дәҶзұ»дјјmulti_hostзҡ„еҠҹиғҪпјҢж”ҜжҢҒOpenStackе·ҘдҪңеңЁдё»еӨҮжЁЎејҸпјҲactive-backupиҝҷз§Қй«ҳеҸҜз”ЁжҖ§жЁЎејҸпјүгҖӮ
QuantumеҸӘйңҖиҰҒдёҖдёӘnova-networkзҡ„е®һдҫӢиҝҗиЎҢпјҢеӣ жӯӨдёҚиғҪдёҺmulti_hostжЁЎејҸе…ұеҗҢе·ҘдҪңгҖӮ
Quantumе…Ғи®ёеҚ•дёӘз§ҹжҲ·жӢҘжңүеӨҡдёӘз§Ғдәәдё“з”ЁL2зҪ‘з»ңпјҢйҖҡиҝҮеҠ ејәQoSпјҢд»ҘеҗҺеә”иҜҘиғҪдҪҝhadoopйӣҶзҫӨеҫҲеҘҪзҡ„еңЁnovaиҠӮзӮ№дёҠе·ҘдҪңгҖӮ
еҜ№дәҺQuantumзҡ„е®үиЈ…дҪҝз”ЁпјҢиҝҷзҜҮж–Үз« Quantum Setup жңүд»Ӣз»ҚгҖӮ
4пјү glanceгҖҒkeystoneзҡ„й«ҳеҸҜйқ жҖ§
OpenStackзҡ„й•ңеғҸеҸҜд»ҘдҪҝз”ЁswiftеӯҳеӮЁпјҢglanceеҸҜд»ҘиҝҗиЎҢеңЁеӨҡдёӘдё»жңәгҖӮIntegrating OpenStack ImageService (Glance) with Swift д»Ӣз»ҚдәҶglanceдҪҝз”ЁswiftеӯҳеӮЁгҖӮ
йӣҶзҫӨз®ЎзҗҶе·Ҙе…· Pacemaker жҳҜејәеӨ§зҡ„й«ҳеҸҜз”ЁжҖ§и§ЈеҶіж–№жЎҲпјҢиғҪеӨҹз®ЎзҗҶеӨҡиҠӮзӮ№йӣҶзҫӨпјҢе®һзҺ°жңҚеҠЎеҲҮжҚўе’ҢиҪ¬з§»пјҢеҸҜдёҺCorosync е’Ң Heartbeatзӯүй…ҚеҘ—дҪҝз”ЁгҖӮPacemaker иғҪеӨҹиҫғдёәзҒөжҙ»зҡ„е®һзҺ°дё»еӨҮгҖҒN+1 гҖҒN-N зӯүеӨҡз§ҚжЁЎејҸгҖӮ
bringing-high-availability-openstack-keystone-and-glanceд»Ӣз»ҚдәҶеҰӮдҪ•йҖҡиҝҮPacemakerе®һзҺ°keystoneе’Ңglanceзҡ„й«ҳеҸҜйқ гҖӮеңЁжҜҸдёӘиҠӮзӮ№е®үиЈ…OCFд»ЈзҗҶеҗҺпјҢе®ғиғҪеӨҹе‘ҠиҜүдёҖдёӘиҠӮзӮ№еҸҰдёҖдёӘиҠӮзӮ№жҳҜеҗҰжӯЈеёёиҝҗиЎҢglanceе’ҢkeysoneжңҚеҠЎпјҢд»ҺиҖҢеё®еҠ©PacemakerејҖеҗҜгҖҒеҒңжӯўе’Ңзӣ‘жөӢиҝҷдәӣжңҚеҠЎгҖӮ
5пјү SwiftеҜ№иұЎеӯҳеӮЁзҡ„й«ҳеҸҜйқ жҖ§
дёҖиҲ¬жғ…еҶөдёӢпјҢOpenStackзҡ„еҲҶеёғејҸеҜ№иұЎеӯҳеӮЁзі»з»ҹSwiftзҡ„HAжҳҜдёҚйңҖиҰҒиҮӘе·ұж·»еҠ зҡ„гҖӮеӣ дёәпјҢSwiftи®ҫи®Ўж—¶е°ұжҳҜеҲҶеёғејҸпјҲжІЎжңүдё»жҺ§иҠӮзӮ№пјүгҖҒе®№й”ҷгҖҒеҶ—дҪҷжңәеҲ¶гҖҒж•°жҚ®жҒўеӨҚжңәеҲ¶гҖҒеҸҜжү©еұ•е’Ңй«ҳеҸҜйқ зҡ„гҖӮд»ҘдёӢжҳҜSwiftзҡ„йғЁеҲҶдјҳзӮ№пјҢиҝҷд№ҹиҜҙжҳҺдәҶиҝҷзӮ№гҖӮ
Built-in Replication(N copies of accounts, container, objects) 3x+ data redundancy compared to 2x on RAID еҶ…е»әеҶ—дҪҷжңәеҲ¶ RAIDжҠҖжңҜеҸӘеҒҡдёӨдёӘеӨҮд»ҪпјҢиҖҢSwiftжңҖе°‘жңү3дёӘеӨҮд»Ҫ | High Availability й«ҳеҸҜйқ жҖ§ |
Easily add capacity unlike RAID resize еҸҜд»Ҙж–№дҫҝең°иҝӣиЎҢеӯҳеӮЁжү©е®№ | Elastic data scaling with ease ж–№дҫҝзҡ„жү©е®№иғҪеҠӣ |
No central database жІЎжңүдёӯеҝғиҠӮзӮ№ | Higher performance, No bottlenecks й«ҳжҖ§иғҪпјҢж— з“¶йўҲйҷҗеҲ¶ |
6пјү ж¶ҲжҒҜйҳҹеҲ—жңҚеҠЎRabbitMQзҡ„й«ҳеҸҜйқ жҖ§
RabbitMQеӨұж•Ҳе°ұдјҡеҜјиҮҙдёўеӨұж¶ҲжҒҜпјҢеҸҜд»ҘжңүеӨҡз§ҚHAжңәеҲ¶пјҡ
publisher confirms ж–№жі•еҸҜд»ҘеңЁж•…йҡңж—¶йҖҡзҹҘд»Җд№ҲеҶҷе…ҘдәҶзЈҒзӣҳгҖӮ
еӨҡжңәйӣҶзҫӨжңәеҲ¶пјҢдҪҶжҳҜиҠӮзӮ№еӨұж•Ҳе®№жҳ“еҜјиҮҙйҳҹеҲ—еӨұж•ҲгҖӮ
дё»еӨҮжЁЎејҸпјҲactive-passiveпјүпјҢиғҪеӨҹе®һзҺ°ж•…йҡңж—¶иҪ¬з§»пјҢдҪҶжҳҜеҗҜеҠЁеӨҮд»ҪжңәеҸҜиғҪйңҖиҰҒ延иҝҹз”ҡиҮіеӨұж•ҲгҖӮ
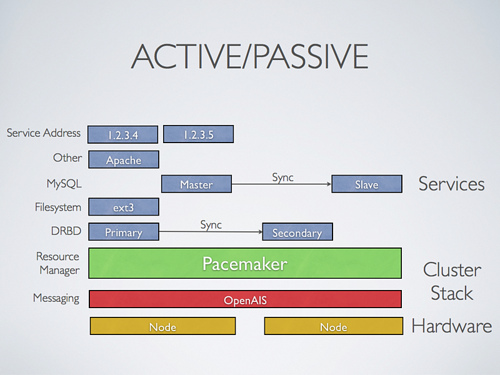
еңЁе®№зҒҫдёҺеҸҜз”ЁжҖ§ж–№йқўпјҢRabbitMQжҸҗдҫӣдәҶеҸҜжҢҒд№…еҢ–зҡ„йҳҹеҲ—гҖӮиғҪеӨҹеңЁйҳҹеҲ—жңҚеҠЎеҙ©жәғзҡ„ж—¶еҖҷпјҢе°ҶжңӘеӨ„зҗҶзҡ„ж¶ҲжҒҜжҢҒд№…еҢ–еҲ°зЈҒзӣҳдёҠгҖӮдёәдәҶйҒҝе…Қеӣ дёәеҸ‘йҖҒж¶ҲжҒҜеҲ°еҶҷе…Ҙж¶ҲжҒҜд№Ӣй—ҙзҡ„延иҝҹеҜјиҮҙдҝЎжҒҜдёўеӨұпјҢRabbitMQеј•е…ҘдәҶPublisher ConfirmжңәеҲ¶д»ҘзЎ®дҝқж¶ҲжҒҜиў«зңҹжӯЈең°еҶҷе…ҘеҲ°зЈҒзӣҳдёӯгҖӮе®ғеҜ№Clusterзҡ„ж”ҜжҢҒжҸҗдҫӣдәҶActive/PassiveдёҺActive/ActiveдёӨз§ҚжЁЎејҸгҖӮдҫӢеҰӮпјҢеңЁActive/PassiveжЁЎејҸдёӢпјҢдёҖж—ҰдёҖдёӘиҠӮзӮ№еӨұиҙҘпјҢPassiveиҠӮзӮ№е°ұдјҡ马дёҠиў«жҝҖжҙ»пјҢ并иҝ…йҖҹжӣҝд»ЈеӨұиҙҘзҡ„ActiveиҠӮзӮ№пјҢжүҝжӢ…иө·ж¶ҲжҒҜдј йҖ’зҡ„иҒҢиҙЈгҖӮеҰӮеӣҫжүҖзӨәпјҡ

еӣҫ Active/Passive ClusterпјҲеӣҫзүҮжқҘиҮӘRabbitMQе®ҳж–№зҪ‘з«ҷпјү
active-passiveжЁЎејҸеӯҳеңЁжүҖиҜҙзҡ„й—®йўҳпјҢеӣ жӯӨпјҢеҹәдәҺRabbitMQйӣҶзҫӨеј•е…ҘдәҶдёҖз§ҚеҸҢдё»еҠЁйӣҶзҫӨжңәеҲ¶пјҲactive-activeпјүи§ЈеҶідәҶиҝҷдәӣй—®йўҳгҖӮhttp://www.rabbitmq.com/ha.htmlиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶRabbitMQзҡ„й«ҳеҸҜйқ йғЁзҪІе’ҢеҺҹзҗҶгҖӮ
7пјү ж•°жҚ®еә“mysqlзҡ„й«ҳеҸҜйқ жҖ§
йӣҶзҫӨ并дёҚе°ұжҳҜй«ҳеҸҜйқ пјҢеёёз”Ёзҡ„жһ„е»әй«ҳеҸҜйқ зҡ„mysqlзҡ„ж–№жі•жңүActive-passiveдё»еӨҮжЁЎејҸпјҡдҪҝз”ЁDRBDе®һзҺ°дё»еӨҮжңәзҡ„зҒҫе®№пјҢHeartbeatжҲ–иҖ…CorosyncеҒҡеҝғи·ізӣ‘жөӢгҖҒжңҚеҠЎеҲҮжҚўз”ҡиҮіfailoverпјҢPacemakerе®һзҺ°жңҚеҠЎпјҲиө„жәҗпјүзҡ„еҲҮжҚўеҸҠжҺ§еҲ¶зӯүпјӣжҲ–иҖ…зұ»дјјзҡ„жңәеҲ¶гҖӮе…¶дёӯдё»иҰҒдҪҝз”ЁPacemakerе®һзҺ°дәҶmysqlзҡ„active-passiveй«ҳеҸҜз”ЁйӣҶзҫӨгҖӮ
дёҖдёӘйҮҚиҰҒзҡ„жҠҖжңҜжҳҜDRBDпјҡ(distributed replication block device)еҚіеҲҶеёғејҸеӨҚеҲ¶еқ—и®ҫеӨҮпјҢз»Ҹеёёиў«з”ЁжқҘд»Јжӣҝе…ұдә«зЈҒзӣҳгҖӮ
е®ғзҡ„е·ҘдҪңеҺҹзҗҶжҳҜпјҡеңЁAдё»жңәдёҠжңүеҜ№жҢҮе®ҡзЈҒзӣҳи®ҫеӨҮеҶҷиҜ·жұӮж—¶пјҢж•°жҚ®еҸ‘йҖҒз»ҷAдё»жңәзҡ„kernelпјҢ然еҗҺйҖҡиҝҮkernelдёӯзҡ„дёҖдёӘжЁЎеқ—пјҢжҠҠзӣёеҗҢзҡ„ж•°жҚ®дј йҖҒз»ҷBдё»жңәзҡ„kernelдёӯдёҖд»ҪпјҢ然еҗҺBдё»жңәеҶҚеҶҷе…ҘиҮӘе·ұжҢҮе®ҡзҡ„зЈҒзӣҳи®ҫеӨҮпјҢд»ҺиҖҢе®һзҺ°дёӨдё»жңәж•°жҚ®зҡ„еҗҢжӯҘ,д№ҹе°ұе®һзҺ°дәҶеҶҷж“ҚдҪңй«ҳеҸҜз”ЁгҖӮDRBDдёҖиҲ¬жҳҜдёҖдё»дёҖд»ҺпјҢ并且жүҖжңүзҡ„иҜ»еҶҷж“ҚдҪңпјҢжҢӮиҪҪеҸӘиғҪеңЁдё»иҠӮзӮ№жңҚеҠЎеҷЁдёҠиҝӣиЎҢпјҢпјҢдҪҶжҳҜдё»д»ҺDRBDжңҚеҠЎеҷЁд№Ӣй—ҙжҳҜеҸҜд»ҘиҝӣиЎҢи°ғжҚўзҡ„гҖӮиҝҷйҮҢжңүеҜ№ DRBD зҡ„д»Ӣз»ҚгҖӮ
HAforNovaDB - OpenStackд»Ӣз»ҚдәҶеҸӘдҪҝз”Ёе…ұдә«зЈҒзӣҳиҖҢжІЎжңүдҪҝз”ЁDRBDпјҢйҖҡиҝҮPacemakerе®һзҺ°OpenStackзҡ„й«ҳеҸҜйқ гҖӮ
NovaZooKeeperHeartbeatд»Ӣз»ҚдәҶдҪҝз”ЁZooKeeperдҪңеҝғи·іжЈҖжөӢгҖӮ
MySQL HA with Pacemaker д»Ӣз»ҚдәҶдҪҝз”ЁPacemakerжҸҗдҫӣй«ҳеҸҜйқ жңҚеҠЎпјҢиҝҷд№ҹжҳҜеҫҲеёёи§Ғзҡ„и§ЈеҶіж–№жЎҲгҖӮ
Galera жҳҜй’ҲеҜ№Mysql/InnoDBзҡ„еҗҢжӯҘзҡ„еӨҡmasterйӣҶзҫӨзҡ„ејҖжәҗйЎ№зӣ®пјҢжҸҗдҫӣдәҶеҫҲеӨҡзҡ„дјҳзӮ№пјҲеҰӮеҗҢжӯҘеӨҚеҲ¶гҖҒиҜ»еҶҷеҲ°д»»ж„ҸиҠӮзӮ№гҖҒиҮӘеҠЁжҲҗе‘ҳжҺ§еҲ¶гҖҒиҮӘеҠЁиҠӮзӮ№еҠ е…ҘгҖҒиҫғе°Ҹ延иҝҹзӯүпјүпјҢеҸҜд»ҘеҸӮиҖғгҖӮ
PacemakerдёҺDRBDгҖҒMysqlзҡ„е·ҘдҪңжЁЎејҸеҸҜд»ҘеҸӮиҖғдёӢеӣҫпјҡ
е…¶е®ғзҡ„ж–№жЎҲпјҢж №жҚ® MySQLPerformance Blog зҡ„иҜҙжі•пјҢMySQLеҮ з§Қй«ҳеҸҜз”Ёи§ЈеҶіж–№жЎҲиғҪиҫҫеҲ°зҡ„еҸҜз”ЁжҖ§еҰӮдёӢпјҡ

3гҖҒжһ„е»әй«ҳеҸҜз”ЁжҖ§зҡ„OpenStackпјҲHigh-availability OpenStackпјү
дёҖиҲ¬жқҘиҜҙпјҢй«ҳеҸҜз”ЁжҖ§д№ҹе°ұжҳҜе»әз«ӢеҶ—дҪҷеӨҮд»ҪпјҢеёёз”Ёзӯ–з•Ҙжңүпјҡ
йӣҶзҫӨе·ҘдҪңжЁЎејҸгҖӮеӨҡжңәдә’еӨҮпјҢиҝҷж ·жЁЎејҸжҳҜжҠҠжҜҸдёӘе®һдҫӢеӨҮд»ҪеӨҡд»ҪпјҢжІЎжңүдёӯеҝғиҠӮзӮ№пјҢжҜ”еҰӮеҲҶеёғејҸеҜ№иұЎеӯҳеӮЁзі»з»ҹSwiftгҖҒnova-networkеӨҡдё»жңәжЁЎејҸгҖӮ
иҮӘдё»жЁЎејҸгҖӮжңүж—¶еҖҷпјҢи§ЈеҶіеҚ•зӮ№ж•…йҡңпјҲSPoFпјүеҸҜд»Ҙз®ҖеҚ•зҡ„дҪҝз”ЁжҜҸдёӘиҠӮзӮ№иҮӘдё»е·ҘдҪңпјҢйҖҡиҝҮеҺ»дё»д»Һе…ізі»жқҘеҮҸе°‘дё»жҺ§иҠӮзӮ№еӨұж•ҲеёҰжқҘзҡ„й—®йўҳпјҢжҜ”еҰӮnova-apiеҸӘиҙҹиҙЈиҮӘе·ұжүҖеңЁиҠӮзӮ№гҖӮ
дё»еӨҮжЁЎејҸгҖӮеёёи§Ғзҡ„жЁЎејҸactive-passiveпјҢиў«еҠЁиҠӮзӮ№еӨ„дәҺзӣ‘еҗ¬е’ҢеӨҮд»ҪжЁЎејҸпјҢж•…йҡңж—¶еҸҠж—¶еҲҮжҚўпјҢжҜ”еҰӮmysqlй«ҳеҸҜз”ЁйӣҶзҫӨгҖҒglanceгҖҒkeystoneдҪҝз”ЁPacemakerе’ҢHeartbeatзӯүжқҘе®һзҺ°гҖӮ
еҸҢдё»жЁЎејҸгҖӮиҝҷз§ҚжЁЎејҸдә’еӨҮдә’жҸҙпјҢRabbitMQе°ұжҳҜactive-activeйӣҶзҫӨй«ҳеҸҜз”ЁжҖ§пјҢйӣҶзҫӨдёӯзҡ„иҠӮзӮ№еҸҜиҝӣиЎҢйҳҹеҲ—зҡ„еӨҚеҲ¶гҖӮд»Һжһ¶жһ„дёҠжқҘиҜҙпјҢиҝҷж ·е°ұдёҚз”ЁжӢ…еҝғpassiveиҠӮзӮ№дёҚиғҪеҗҜеҠЁжҲ–иҖ…延иҝҹеӨӘеӨ§дәҶпјҹ
д»ҘдёҠжҳҜвҖңжҖҺд№Ҳжһ„е»әOpenStackзҡ„й«ҳеҸҜз”ЁжҖ§вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ