жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңElasticSearchе№іеҸ°жһ¶жһ„еҚҮзә§еҲҶжһҗвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁElasticSearchе№іеҸ°жһ¶жһ„еҚҮзә§еҲҶжһҗй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқElasticSearchе№іеҸ°жһ¶жһ„еҚҮзә§еҲҶжһҗвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
иғҢжҷҜпјҡжҺЁзҹіеӨҙзҡ„иҘҝиҘҝеј—ж–Ҝ
ж»ҙж»ҙ ElasticSearch еӣўйҳҹд»Һ 2016 е№ҙејҖе§Ӣе»әи®ҫ ElasticSearch е№іеҸ°пјҢеңЁ 2016 е№ҙ 6 жңҲд»Ҫзҡ„ж—¶еҖҷејҖе§ӢеҜ№еӨ–жҸҗдҫӣжңҚеҠЎпјҢеҪ“ж—¶йҖүжӢ©дәҶ ElasticSearch жңҖж–°зҡ„ 2.3 зүҲжң¬гҖӮ
еҰӮд»Ҡдёүе№ҙиҝҮеҺ»дәҶпјҢElasticSearch з”ҹжҖҒз»ҸеҺҶдәҶйЈһйҖҹзҡ„еўһй•ҝпјҢElastic е…¬еҸёе®ҢжҲҗдәҶдёҠеёӮпјҢElasticSearch еңЁ db-engines зҡ„еҲҶж•°д»Һ 88 дёҠж¶ЁеҲ° 148пјҢжҺ’еҗҚд»Һ 11 еҗҚдёҠеҚҮеҲ°з¬¬ 7 еҗҚгҖӮ
иҝҷжңҹй—ҙ ES еҸ‘еёғдәҶ 3 дёӘеӨ§зүҲжң¬пјҢеҮ еҚҒдёӘдёӯзүҲжң¬пјҢиҖҢжңҖиҝ‘ ElasticSearch е·Із»ҸеҸ‘еёғдәҶ 7.x зүҲжң¬гҖӮ
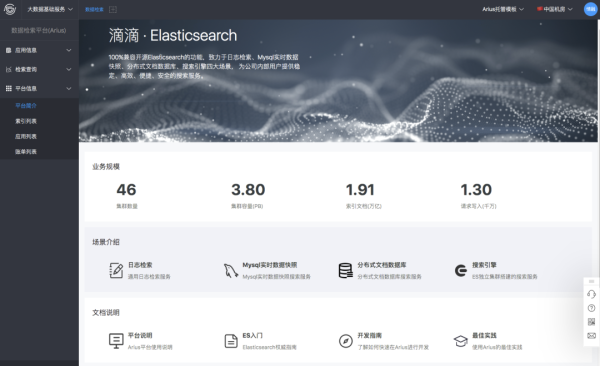
еңЁиҝҷдёүе№ҙдёӯж»ҙж»ҙ Elasticsearch е№іеҸ°еҹәдәҺ ElasticSearch жҺЁеҮәдәҶж—Ҙеҝ—жЈҖзҙўгҖҒMySQL е®һж—¶ж•°жҚ®еә“еҝ«з…§гҖҒеҲҶеёғејҸж–ҮжЎЈж•°жҚ®еә“гҖҒжҗңзҙўеј•ж“ҺзӯүеӣӣеӨ§жңҚеҠЎпјҢеӣӣеӨ§дёҡеҠЎеқҮеҝ«йҖҹеҸ‘еұ•гҖӮ
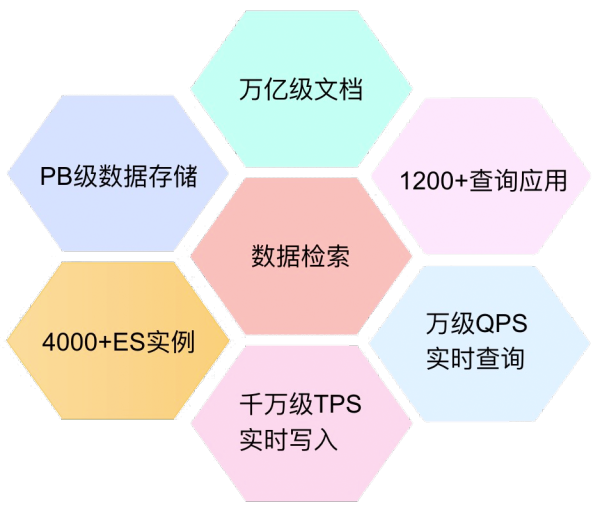
зӣ®еүҚж»ҙж»ҙ ElasticSearch е№іеҸ°жңҚеҠЎдәҶйӣҶеӣўйҮҢйқў 1200 дёӘеә”з”ЁпјҢе…¶дёӯпјҡи®ўеҚ•гҖҒе®ўжңҚгҖҒйҮ‘иһҚгҖҒжҠҠи„үгҖҒж–°ж”ҝзӯүдёҡеҠЎж ёеҝғе®һж—¶еңәжҷҜд№ҹиҝҗиЎҢеңЁ Elasticsearch д№ӢдёҠпјҢиҝҗз»ҙ ES йӣҶзҫӨ 30+пјҢеҶҷе…Ҙ TPS еі°еҖјеҲ°иҫҫ 1500WпјҢжҹҘиҜў QPS иҫҫеҲ° 2WгҖӮ
дёҡеҠЎзҡ„еҝ«йҖҹеҸ‘еұ•ж—ўжҳҜж»ҙж»ҙ ElasticSearch еӣўйҳҹе·ҘдҪңзҡ„иӮҜе®ҡпјҢдҪҶйҡҸд№ӢиҖҢжқҘд№ҹжңүе·ЁеӨ§зҡ„жҢ‘жҲҳе’ҢеҺӢеҠӣпјҢе…¶дёӯзүҲжң¬иҝҮдҪҺжҳҜжңӘжқҘ ElasticSearch е№іеҸ°еҸ‘еұ•жңҖеӨ§еҲ¶зәҰеӣ зҙ пјҢе…¶дёӯдё»иҰҒжңүд»ҘдёӢеҮ зӮ№гҖӮ
в‘ зӨҫеҢәдёҚеҶҚз»ҙжҠӨиҖҒзүҲжң¬пјҡElasticSearch 2.3.3 зүҲжң¬иҝҮдәҺйҷҲж—§пјҢES зӨҫеҢәж—©е·ІдёҚеҶҚиҝӣиЎҢз»ҙжҠӨпјҢеңЁ 2.x дёҠйҒҮеҲ°зҡ„й—®йўҳзӨҫеҢәдёҚи§ЈеҶіпјҢжҸҗдәӨзҡ„ issue д№ҹдёҚеӨ„зҗҶпјҢжҸҗдәӨд»Јз Ғд№ҹдёҚиў«жҺҘ收гҖӮ
еҹәдәҺ 2.3.3 жҲ‘们д№ҹи§ЈеҶідәҶеҫҲеӨҡ ES иҮӘиә«зҡ„й—®йўҳпјҢеҰӮпјҡMaster жӣҙж–°е…ғж•°жҚ®и¶…ж—¶еҜјиҮҙеҶ…еӯҳжі„йңІгҖҒTCP еҚҸи®®еӯ—ж®өжәўеҮәзӯүгҖӮ
з”ұдәҺж— жі•е’ҢзӨҫеҢәдә’еҠЁпјҢеӣўйҳҹеҗҢеӯҰзҡ„д»·еҖјд№ҹеҫ—дёҚеҲ°зӨҫеҢәзҡ„и®ӨеҸҜпјҢй•ҝжӯӨд»ҘеҫҖеҸӘдјҡе’Ң ES з”ҹжҖҒи¶ҠжқҘи¶ҠиҝңпјҢжҲ‘们еңЁ ES жҠҖжңҜеңҲдёӯзҡ„еЈ°йҹід№ҹдјҡи¶ҠжқҘи¶ҠејұгҖӮ
в‘Ўж–°зүҲжң¬зү№жҖ§еҫҲйҡҫиў«дҪҝз”ЁпјҡжңҖиҝ‘ 3 е№ҙжҳҜ ES з”ҹжҖҒеӨ§еҸ‘еұ•зҡ„ 3 е№ҙпјҢES иҮӘиә«еңЁеҠҹиғҪгҖҒжҖ§иғҪдёҠйғҪжңүйқһеёёеӨ§жҸҗеҚҮгҖӮ
еҰӮпјҡй»ҳи®ӨдҪҝз”Ё BM25 иҜ„еҲҶз®—жі•пјҢж•ҲжһңжӣҙдҪі;lucene docvalues зЁҖз–ҸеҢәеҹҹж”№иҝӣпјҢжӣҙиҠӮзәҰзЈҒзӣҳз©әй—ҙ;ж–°еўһ Frozen indices иғҪеҠӣпјҢеҸҜд»Ҙжҳҫи‘—йҷҚдҪҺ ES еҶ…еӯҳејҖй”ҖгҖӮ
еҫҲеӨҡзү№жҖ§д№ҹйқһеёёйҖӮеҗҲ ElasticSearch е№іеҸ°зҡ„еңәжҷҜпјҢдҪҶжҳҜзүҲжң¬е·®и·қиҝҮеӨ§дёҖзӣҙеҲ¶зәҰзқҖжҲ‘们пјҢж— жі•дә«еҸ—жҠҖжңҜиҝӣжӯҘзҡ„зәўеҲ©гҖӮ
дёҖиҫ№жҳҜдёҡеҠЎеҝ«йҖҹеҸ‘еұ•иҰҒжұӮжӣҙдё°еҜҢзҡ„еҠҹиғҪгҖҒжӣҙејәеӨ§зҡ„жҖ§иғҪгҖҒжӣҙдҪҺзҡ„жҲҗжң¬гҖҒжӣҙзЁіе®ҡзҡ„жңҚеҠЎ;дёҖиҫ№зҰ»жңҖж–°зҡ„дёҡеҶ…жҠҖжңҜи¶ҠжқҘи¶ҠиҝңпјҢеӣўйҳҹд»·еҖји¶ҠжқҘи¶ҠејұпјҢйҖҗжёҗжІҰдёәдёҖж”ҜеҸӘиғҪеҒҡдёҡеҠЎзҡ„дјӘеј•ж“ҺеӣўйҳҹпјҢж•ҙдёӘеӣўйҳҹзҡ„зҺ°зҠ¶е°ұеҰӮеҗҢжҺЁзҹіеӨҙзҡ„иҘҝиҘҝеј—ж–ҜгҖӮ
иҰҒд№ҲжҲ‘们иҝҺйҡҫиҖҢдёҠпјҢе…ӢжңҚеӣ°йҡҫпјҢдёҖеҸЈж°”жҠҠж•ҙдёӘйӣҶзҫӨеҚҮзә§еҲ°жңҖж–°зҡ„зүҲжң¬пјҢжҠҠзҹіеӨҙжҺЁиҝҮеұұйЎ¶пјҢеҶҚиҪ»иЈ…еүҚиЎҢ;иҰҒд№Ҳе°ұжҳҜ继з»ӯзӢ¬иҮӘеӢүеҠӣж”Ҝж’‘пјҢеңЁдёҡеҠЎе’Ңеј•ж“Һзҡ„еҸҢйҮҚеҺӢеҠӣдёӢи№’и·ҡиҖҢиЎҢгҖӮ
ж»ҙж»ҙ ElasticSearch еӣўйҳҹжңҖз»ҲйҖүжӢ©еҜ№ж»ҙж»ҙ ElasticSearch е№іеҸ°иҝӣиЎҢйҮҚжһ„并е°Ҷз»ҙжҠӨзҡ„жүҖжңү ES йӣҶзҫӨеҚҮзә§еҲ°жңҖж–°зүҲжң¬гҖӮ
еӣ°йҡҫпјҡжӢ”еү‘еӣӣйЎҫеҝғиҢ«з„¶
зҗҶжғіеҫҲдё°ж»ЎпјҢзҺ°е®һеҫҲйӘЁж„ҹпјҢдёӢеҶіеҝғеҫҲе®№жҳ“пјҢ然иҖҢе®һйҷ…жү§иЎҢеҫҲеӣ°йҡҫпјҡ
2.3.3 е’Ң 6.6.1 еҚҸи®®дёҚе…је®№е•ҠпјҢ6.6.1 йғҪдёҚж”ҜжҢҒ TCP еҚҸи®®дәҶпјҢйӮЈдәӣйҖҡиҝҮ TCP жҹҘзҡ„з”ЁжҲ·жҖҺд№ҲеҠһпјҢ让他们дёҖдёӘдёҖдёӘж”№д»Јз ҒпјҢйӮЈиҰҒж”№еҲ°д»Җд№Ҳж—¶еҖҷ?
2.3.3 е’Ң 6.6.1 жңүдәӣиҝ”еӣһзҡ„еӯ—ж®өйғҪдёҚдёҖж ·дәҶпјҢжңүдәӣжҹҘиҜўиҜӯжі•д№ҹдёҚе…је®№пјҢжҖҺд№ҲеҒҡеҲ°еҜ№з”ЁжҲ·зҡ„йҖҸжҳҺпјҢиҝҳжҳҜзӣҙжҺҘејәиҝ«з”ЁжҲ·жҺҘеҸ—ж”№еҸҳ?
2.3.3 е’Ң 6.6.1 lucene ж–Үд»¶ж јејҸйғҪдёҚдёҖж ·пјҢжІЎеҠһжі•еҺҹең°зӣҙжҺҘеҚҮзә§пјҢиҰҒеҶҚжҗһдёӘйӣҶзҫӨе…ЁйғЁеҸҢеҶҷдёҖйҒҚгҖӮ
2.3.3 е’Ң 6.6.1 зҡ„ Mapping ж јејҸдёҚз»ҹдёҖпјҢ6.6.1 дёҚж”ҜжҢҒеӨҡ typeпјҢзҺ°жңүзҡ„йӮЈдәӣж•°жҚ®жҗ¬иҝҒйғҪжІЎеҠһжі•жҗ¬гҖӮ
ж»ҙж»ҙ ElasticSearch е№іеҸ°зҺ°еңЁдёҚж”ҜжҢҒзҙўеј•еӨҡзүҲжң¬еҗҢж—¶жҹҘиҜўпјҢз”ЁжҲ·жҹҘиҜўд№ жғҜд№ҹеҚғеҘҮзҷҫжҖӘпјҢеҫҲеӨҡеёҰ*жҹҘиҜўдҪ ж №жң¬жҺ§еҲ¶дёҚдәҶгҖӮ
з”ЁжҲ·йӮЈд№ҲеӨҡпјҢдҪҝз”Ёе·®ејӮеҫҲеӨ§пјҢжҖҺд№Ҳе’Ңз”ЁжҲ·иҝӣиЎҢжІҹйҖҡе’Ңе®ЈеҜјпјҢжҖҺд№ҲеұҸи”Ҫз”ЁжҲ·еҪұе“Қе’Ңз®ЎзҗҶз”ЁдәҺйў„жңҹ?
е°ұз®—жҳҜиҰҒжҗ¬иҝҒеҚҮзә§пјҢе“ӘйҮҢеҺ»жүҫйӮЈд№ҲеӨҡжңәеҷЁпјҢзҺ°еңЁиҝҳиҰҒжңәжҲҝиЈҒж’ӨпјҢиҝҳиҰҒеҫҖеӨ–жӢҝжңәеҷЁгҖӮ
еҮ еҚҒдёӘйӣҶзҫӨпјҢеҮ еҚғдёӘиҠӮзӮ№йғҪиҰҒйғЁзҪІгҖҒжҗӯе»әгҖҒйҮҚеҗҜпјҢиҝҳиҰҒи…ҫжҢӘдёҠеҚғеҸ°жңәеҷЁгҖӮж…ўзӮ№жҗһпјҢиҝҷеҫ—жҗһеҲ°д»Җд№Ҳж—¶еҖҷпјҢеҝ«зӮ№жҗһпјҢдёҮдёҖеҮәй—®йўҳжҖҺд№ҲеҠһ?
е°ұз®—жҳҜеҸҢеҶҷеҚҮзә§дәҶпјҢжҖҺд№ҲзҹҘйҒ“дёӯй—ҙжңүжІЎжңүй—®йўҳпјҢж•°жҚ®жңүжІЎжңүдёўеӨұпјҢз”ЁжҲ·зҡ„жҹҘиҜўжҳҜдёҚжҳҜдёҖиҮҙзҡ„пјҢеҠҹиғҪе’ҢжҖ§иғҪжңүжІЎжңүиҫҫеҲ°йў„жңҹпјҢиҝҷдёӘжҖҺд№ҲйӘҢиҜҒ?
иҝҷд№ҲеӨҡж•°жҚ®пјҢиҝҷд№ҲеӨҡдәәеңЁз”ЁпјҢиҝҷд№ҲзӮ№иө„жәҗпјҢдёҡеҠЎзЁіе®ҡеҺӢеҠӣеҸҲеӨ§пјҢдј°и®Ўд»Ҡе№ҙдёҖе№ҙйғҪжҗһдёҚе®ҢгҖӮ
…………
еңЁеҲҡејҖе§ӢеҶіе®ҡиҝӣиЎҢи·ЁзүҲжң¬еҚҮзә§д№ӢеҗҺпјҢжҲ‘们йқўдёҙзҡ„й—®йўҳе°ұжү‘йқўиҖҢжқҘпјҢе…¶дёӯд»»дҪ•дёҖжқЎдёҚи§ЈеҶіпјҢйғҪдјҡжһҒеӨ§зҡ„йҳ»зўҚеҚҮзә§зҡ„иҝӣзЁӢгҖӮ
жҖқиҖғпјҡеӨ©з”ҹжҲ‘жқҗеҝ…жңүз”Ё
еңЁиө·жӯҘйҳ¶ж®өжңүеҫҲеӨҡй—®йўҳжқӮзі…еңЁдёҖиө·пјҢйңҖиҰҒзҗҶжё…жҘҡжҜҸдёӘй—®йўҳзҡ„йҮҚиҰҒжҖ§гҖҒзҙ§жҖҘзЁӢеәҰгҖҒеҪұе“ҚеұӮйқўгҖҒзӣёдә’дҫқиө–е…ізі»пјҢйҖҡиҝҮеҲҶжһҗеҪ’зәіжҲ‘们е°Ҷе…¶жҖ»з»“дёәеӣӣеӨ§й—®йўҳеҹҹпјҡ
еңЁеҜ№й—®йўҳеҹҹиҝӣиЎҢеҪ’жҖ»д№ӢеҗҺпјҢжҲ‘们讨и®әдәҶе…·дҪ“зҡ„е®һж–Ҫж–№жЎҲе’ҢжӯҘйӘӨпјҢе°Ҷе…¶еҪ’зәід»ҘдёӢеӣӣдёӘеҸҜд»Ҙе®һйҷ…жҺЁиҝӣзҡ„зҺҜиҠӮпјҡ

йҰ–е…ҲиҝӣиЎҢжһ¶жһ„еҚҮзә§пјҡи§ЈеҶіеј•ж“Һдҫ§ 2.x/6.x зҡ„дёҚе…је®№й—®йўҳпјҢжүҖжңүзҡ„еҚҸи®®гҖҒжҹҘиҜўиҜӯжі•гҖҒMapping зӯүдёҚе…је®№еӨ„зҗҶеңЁе№іеҸ°дҫ§иҝӣиЎҢеӨ„зҗҶгҖӮ
еҗҢж—¶жҲ‘们ејҖеҸ‘дәҶдёҖдёӘ ES java SDK з”ЁжқҘи§ЈеҶі 6.x дёҚж”ҜжҢҒ TCP жҺҘеҸЈзҡ„й—®йўҳпјҢдҪҝз”Ёж–№ејҸе’ҢеҺҹжңүзҡ„ es java client е®Ңе…ЁдёҖиҮҙпјҢз”ЁжҲ·еҸӘиҰҒдҝ®ж”№ pom еҚіеҸҜгҖӮ
е…·дҪ“еҢ…жӢ¬пјҡArius е№іеҸ°еӨҡзүҲжң¬ж”ҜжҢҒгҖҒGateway зҡ„еӨҡзүҲжң¬е…је®№гҖҒз”ЁжҲ· SDK ејҖеҸ‘гҖҒAMS ж•°жҚ®йҮҮйӣҶзӯүпјҢе…·дҪ“и§ҒеҗҺз»ӯиҜҰз»ҶиҜҙжҳҺгҖӮ
е…¶ж¬Ўи§ЈеҶіиҝҗз»ҙй—®йўҳпјҡи§ЈеҶіиҝҗз»ҙж“ҚдҪңиҝҮзЁӢдёӯеӨҡйӣҶзҫӨжҗӯе»әгҖҒйғЁзҪІгҖҒйҮҚеҗҜзҡ„з®ЎжҺ§й—®йўҳпјҢжҸҗеҚҮж“ҚдҪңзҡ„дҫҝеҲ©жҖ§пјҢжҸҗеҚҮеҚҮзә§зҡ„ж“ҚдҪңж•ҲзҺҮпјҢе…·дҪ“и§ҒеҗҺз»ӯиҜҰз»ҶиҜҙжҳҺгҖӮ
еҶҚж¬Ўи§ЈеҶіиө„жәҗй—®йўҳпјҡи§ЈеҶіжҗ¬иҝҒеҚҮзә§жүҖйңҖиҰҒзҡ„еӨ§йҮҸжңәеҷЁиө„жәҗй—®йўҳпјҢдёәеӨ§йҮҸйӣҶзҫӨеҚҮзә§еҒҡе……и¶іеҮҶеӨҮпјҢеҗҢж—¶иҝҳиҰҒж»Ўи¶іжңәжҲҝиЈҒж’ӨеҪ’иҝҳжңәеҷЁзҡ„иҰҒжұӮгҖӮ
е…·дҪ“еҢ…жӢ¬пјҡзҙўеј•еӯҳеӮЁе‘ЁжңҹдјҳеҢ–гҖҒеҶ·зғӯж•°жҚ®еҲҶзҰ»гҖҒMapping дјҳеҢ–гҖҒfastIndex зӯүпјҢе…·дҪ“и§ҒеҗҺз»ӯиҜҰз»ҶиҜҙжҳҺгҖӮ
жңҖеҗҺејҖе§Ӣе®һйҷ…жҺЁиҝӣпјҡеңЁеҒҡеҘҪеүҚжңҹзҡ„жүҖжңүеҮҶеӨҮе·ҘдҪңд№ӢеҗҺпјҢејҖе§Ӣе®һйҷ…жҺЁиҝӣеҚҮзә§иҝҮзЁӢгҖӮе…·дҪ“еҢ…жӢ¬пјҡжҖ§иғҪеҺӢжөӢгҖҒиө„жәҗиҜ„дј°гҖҒжү№йҮҸеҸҢеҶҷгҖҒжҹҘиҜўеӣһж”ҫпјҢе…¶дёӯиҝҳжңүдёҖдәӣж„ҸжғідёҚеҲ°зҡ„йҮҮеқ‘е’ҢеЎ«еқ‘зҡ„иҝҮзЁӢпјҢе…·дҪ“и§ҒеҗҺз»ӯиҜҰз»ҶиҜҙжҳҺгҖӮ
е®һжҲҳпјҡзҷҪжІҷжҲҳеңәзўҺй“ҒиЎЈ
еңЁзҗҶжё…дәҶж•ҙдёӘеҚҮзә§иҝҮзЁӢдёӯзҡ„еҗ„дёӘзҺҜиҠӮзҡ„дҫқиө–е…ізі»гҖҒиө„жәҗж¶ҲиҖ—гҖҒ瓶йўҲзӮ№д№ӢеҗҺпјҢй’ҲеҜ№жһ¶жһ„гҖҒиө„жәҗгҖҒе®һж“ҚзӯүдёүдёӘж–№йқўзҡ„й—®йўҳпјҢжҲ‘们йғҪи®ҫи®ЎдәҶеҜ№еә”зҡ„и§ЈеҶіж–№жЎҲпјҢдё»иҰҒеҰӮдёӢпјҡ

жһ¶жһ„
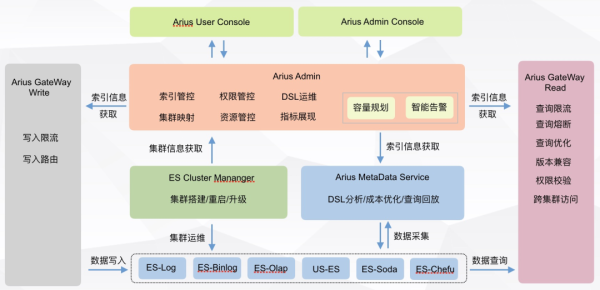
в‘ ж»ҙж»ҙ ElasticSearch е№іеҸ° ES еӨҡзүҲжң¬ж”ҜжҢҒзҡ„жһ¶жһ„ж”№йҖ
йҰ–е…ҲжҲ‘们еңЁж»ҙж»ҙ ElasticSearch е№іеҸ°дёҠе®ҢжҲҗдәҶ ES еӨҡзүҲжң¬ж”ҜжҢҒзҡ„жһ¶жһ„еҚҮзә§пјҢе…¶дёӯйҮҚзӮ№жңүпјҡ
Arius Gateway еҜ№и·ЁзүҲжң¬жҹҘиҜўе·®ејӮзҡ„е…је®№пјҢд»ҘеҸҠеӨҡйӣҶзҫӨдёӢзҙўеј•и·Ёй«ҳдҪҺзүҲжң¬йӣҶзҫӨи®ҝй—®пјҢдҪҝеҫ—еңЁеҚҮзә§иҝҮзЁӢдёӯеҜ№з”ЁжҲ·жҹҘиҜўз»“жһңйҖҸжҳҺгҖӮ
Elasticsearch-didi-interanl-client SDK ејҖеҸ‘пјҢеҜ№з”ЁжҲ·еұҸи”Ҫ ES TCP/HTTP жҹҘиҜўе·®ејӮпјҢи§ЈеҶі ES 6.x зүҲжң¬дёҚж”ҜжҢҒ TCP жҺҘеҸЈзҡ„й—®йўҳпјҢеҺҹжңү 2.x зҡ„з”ЁжҲ·еҸӘиҰҒдҝ®ж”№дёҖиЎҢ pom е°ұеҸҜд»ҘеҲҮжҚўеҲ°й«ҳзүҲжң¬и®ҝй—®гҖӮ
ж»ҙж»ҙ ElasticSearch е№іеҸ°жһ¶жһ„жўізҗҶд»ҘеҸҠ Arius admin еӨҡзүҲжң¬ж”ҜжҢҒгҖӮ
в‘ЎеҹәдәҺеј№жҖ§дә‘зҡ„ ES еӨҡйӣҶзҫӨз®ЎжҺ§ж–№жЎҲ
зӣ®еүҚж»ҙж»ҙ ElasticSearch еӣўйҳҹиҝҗз»ҙ 30 еӨҡдёӘ ES йӣҶзҫӨпјҢ5000+ зҡ„ ES иҠӮзӮ№пјҢйӣҶзҫӨ规模еӨ§пјҢеңәжҷҜеӨҚжқӮпјҢиҝҗз»ҙз®ЎжҺ§жҲҗжң¬жҜ”иҫғй«ҳгҖӮ
дёәжӯӨжҲ‘们и®ҫи®ЎејҖеҸ‘дәҶ ECM(ElasticSearch Cluster Manager)зі»з»ҹз”ЁдәҺ ES йӣҶзҫӨзҡ„йғЁзҪІгҖҒйҮҚеҗҜгҖҒжү©е®№гҖҒй…ҚзҪ®з®ЎжҺ§зӯүдёҖзі»еҲ—ж“ҚдҪңгҖӮ
并且жҲ‘们 80% зҡ„ ES иҠӮзӮ№иҝҗиЎҢеңЁеј№жҖ§дә‘дёҠпјҢз»“еҗҲеј№жҖ§дә‘зҒөжҙ»й«ҳж•Ҳзҡ„зү№зӮ№пјҢдҪҝеҫ—жҲ‘们еңЁиҝӣиЎҢжҗ¬иҝҒеҚҮзә§зҡ„иҝҮзЁӢжӣҙеҠ й«ҳж•ҲгҖӮ
в‘ўES жңҚеҠЎе…ғж•°жҚ®дҪ“зі»е»әи®ҫ
жҲ‘们жһ„е»әдәҶдёҖеҘ— AMS(Arius MetaData Service)жңҚеҠЎпјҢз”ЁдәҺйҮҮйӣҶе’ҢеҲҶжһҗ ES жүҖжңүйӣҶзҫӨгҖҒиҠӮзӮ№гҖҒзҙўеј•зҡ„еҗ„з§Қж•°жҚ®гҖӮ
еҢ…жӢ¬пјҡе®№йҮҸдҝЎжҒҜ(йӣҶзҫӨгҖҒиҠӮзӮ№гҖҒжЁЎжқҝгҖҒзҙўеј•гҖҒз§ҹжҲ·)гҖҒTPS/QPS дҝЎжҒҜ(йӣҶзҫӨгҖҒиҠӮзӮ№гҖҒжЁЎжқҝгҖҒзҙўеј•гҖҒз§ҹжҲ·)гҖҒиҝҗиЎҢдҝЎжҒҜгҖҒжҹҘиҜўиҜӯеҸҘгҖҒжҹҘиҜўжЁЎжқҝдҝЎжҒҜгҖҒжҹҘиҜўз»“жһңе’Ңе‘ҪдёӯзҺҮзҡ„еҲҶжһҗдҝЎжҒҜзӯүзӯүгҖӮ
еңЁиҝҷдәӣеҹәзЎҖзҡ„жҢҮж Үж•°жҚ®еҹәзЎҖдёҠпјҢжҲ‘们жһ„е»әдәҶе…Ёйқўзҡ„ ES иҝҗиЎҢжҢҮж Үзі»з»ҹпјҢеҸҜд»Ҙе…Ёйқўзҡ„дәҶи§Је’Ңзӣ‘жҺ§йӣҶзҫӨгҖҒиҠӮзӮ№гҖҒзҙўеј•гҖҒз§ҹжҲ·зә§еҲ«зҡ„иҝҗиЎҢдҝЎжҒҜгҖӮ
иҜҰе°Ҫзҡ„ж•°жҚ®дёәеҗҺз»ӯзҡ„ ES зҡ„жҲҗжң¬дјҳеҢ–жҸҗдҫӣдәҶеҹәзЎҖпјҢе…·дҪ“и§Ғ —— еҹәдәҺж•°жҚ®й©ұеҠЁзҡ„ ES еҲҶзә§еӯҳеӮЁдҪ“зі»пјҢеҲҶзә§еӯҳеӮЁдҪ“зі»зҡ„жһ„е»әдҪҝеҫ—жҲ‘们жһ„е»әдәҶдёҖеҘ—дҪ“зі»еҢ–зҡ„ESжҲҗжң¬иҠӮзәҰзҡ„зі»з»ҹгҖӮ
иҜҰе°Ҫзҡ„ж•°жҚ®дёәеҗҺз»ӯеҚҮзә§ж—¶еҒҡжҹҘиҜўзҡ„жөҒйҮҸеӣһж”ҫеҜ№жҜ”жҸҗдҫӣдәҶеҹәзЎҖпјҢе…·дҪ“и§Ғ——еҹәдәҺ ES жңҚеҠЎе…ғж•°жҚ®зҡ„жҹҘиҜўжөҒйҮҸеӣһж”ҫеҜ№жҜ”зі»з»ҹпјҢдҪҝеҫ—жҲ‘们еңЁеҚҮзә§иҝҮзЁӢдёӯеҸҜд»Ҙеҝ«йҖҹйӘҢиҜҒеҚҮзә§з»“жһңпјҢжҸҗеҚҮеҚҮзә§ж•ҲзҺҮе’ҢзЁіе®ҡжҖ§гҖӮ
еҗҢж—¶ AMS иҝҳеҜ№ж•°жҚ®зҡ„еҸҜйқ жҖ§иҙҹиҙЈпјҢдҝқиҜҒдә§з”ҹзҡ„ж•°жҚ®жҳҜеҸҠ时并且еҮҶзЎ®зҡ„пјҢиҝҷж ·дҫқиө– AMS зҡ„ж•°жҚ®еҲҶжһҗжңҚеҠЎгҖӮ
еҰӮпјҡеҲҶзә§еӯҳеӮЁгҖҒе®№йҮҸ规еҲ’гҖҒеӣһж”ҫзі»з»ҹгҖҒжҲҗжң¬иҙҰеҚ•гҖҒйӣҶзҫӨеҒҘеә·жЈҖжҹҘгҖҒзҙўеј•еҒҘеә·еҲҶзӯүпјҢеҸӘз”Ёдё“жіЁиҮӘиә«зҡ„йҖ»иҫ‘зҡ„е®һзҺ°еҚіеҸҜгҖӮ
иө„жәҗ
еңЁи§ЈеҶіжһ¶жһ„е’Ңе…је®№жҖ§й—®йўҳд№ӢеҗҺпјҢжҲ‘们已з»ҸжңүдҝЎеҝғе°ҶдёҖдёӘйӣҶзҫӨеңЁзәҝеҚҮзә§еҲ°ж–°зүҲжң¬гҖӮ
然иҖҢз”ұдәҺзүҲжң¬и·ЁеәҰеӨӘеӨ§ж— жі•еңЁеҺҹйӣҶзҫӨдёҠзӣҙжҺҘиҝӣиЎҢж»ҡеҠЁеҚҮзә§пјҢеҝ…йЎ»иҰҒиҝӣиЎҢж•°жҚ®еҸҢеҶҷзҡ„жҗ¬иҝҒеҚҮзә§пјҢиҝҷж ·еҚҮзә§жүҖйңҖиҰҒзҡ„ buff иө„жәҗе°ұжҲҗдёәеҲ¶зәҰж•ҙдёӘеҚҮзә§иҝӣеәҰжңҖйҮҚиҰҒзҡ„еӣ зҙ пјҢеӣ жӯӨжҺҘдёӢжқҘжҲ‘们жҠҠзІҫеҠӣж”ҫеңЁиҠӮзңҒиө„жәҗжҸҗй«ҳиө„жәҗеҲ©з”ЁзҺҮдёҠгҖӮ
йҖҡиҝҮеҶ…еӨ–жҢ–жҪңе’ҢжҠҖжңҜж”№йҖ пјҢдёҚд»…ж”ҜжҢҒдәҶзүҲжң¬еҚҮзә§жүҖйңҖиҰҒзҡ„жңәеҷЁиө„жәҗ(й«ҳеі°ж—¶ 3 дёӘйӣҶзҫӨеҗҢж—¶еҚҮзә§)пјҢжңҖз»ҲиҝҳеҪ’иҝҳдәҶиҝ‘ 400 еҸ°жңәеҷЁпјҢиҠӮзәҰжҲҗжң¬ 80W+ /жңҲгҖӮ
в‘ еҹәдәҺж•°жҚ®й©ұеҠЁзҡ„ ES еҲҶзә§еӯҳеӮЁдҪ“зі»
еҹәдәҺ AMS еҜ№еә”зҙўеј•зҡ„еӨ§е°ҸгҖҒж•°жҚ®йҮҸгҖҒжҹҘиҜўйҮҸгҖҒжҹҘиҜўжқЎд»¶гҖҒжҹҘиҜўж—¶й—ҙгҖҒиҝ”еӣһз»“жһңзҡ„з»ҹи®Ўе’ҢеҲҶжһҗпјҢжҲ‘们иғҪзІҫзЎ®зҡ„еҲҶжһҗеҮәжқҘжҜҸдёӘзҙўеј•иў«дҪҝз”Ёзҡ„еңәжҷҜд»ҘеҸҠиў«жҹҘиҜўзҡ„ж–№ејҸгҖӮ
еҰӮпјҡзҙўеј•зҡ„й«ҳйў‘жҹҘиҜўж—¶й—ҙеҢәй—ҙгҖҒзҙўеј•иў«жЈҖзҙўзҡ„еӯ—ж®өзӯүпјҢеңЁж•°жҚ®еҲҶжһҗеҹәзЎҖдёҠжҲ‘们й’ҲеҜ№жҜҸдёӘзҙўеј•иҝӣиЎҢдәҶ Mapping дјҳеҢ–гҖҒеӯҳеӮЁе‘ЁжңҹдјҳеҢ–гҖҒеҶ·зғӯж•°жҚ®еӯҳеӮЁдјҳеҢ–гҖӮ
еңЁдёҚеҪұе“Қз”ЁжҲ·дҪҝз”ЁйңҖжұӮзҡ„еүҚжҸҗдёӢпјҢзҙҜи®ЎиҠӮзңҒж•°жҚ® 1PBпјҢжҗ¬иҝҒеҶ·ж•°жҚ® 700TBпјҢдёҚд»…дҝқйҡңдәҶеҚҮзә§иҝҮзЁӢдёӯжңүе……и¶ізҡ„ buff жңәеҷЁпјҢиҝҳеҪ’иҝҳдәҶиҝ‘ 400 еҸ°зү©зҗҶжңәпјҢиҠӮзңҒжҲҗжң¬ 70W+ /жңҲгҖӮ
в‘ЎES FastIndex зҰ»зәҝж•°жҚ®еҜје…ҘдҪ“зі»
ES FastIndex зҡ„еҲқиЎ·жҳҜдёәдәҶи§ЈеҶійӣҶеӣўж Үзӯҫзі»з»ҹзҡ„зҰ»зәҝеҜје…Ҙзҡ„ж•ҲзҺҮе’Ңиө„жәҗй—®йўҳпјҢйӣҶеӣўж Үзӯҫзі»з»ҹжҜҸеӨ©жңү 30 еӨҡ TB зҡ„ж•°жҚ®йңҖиҰҒеңЁзҹӯж—¶й—ҙеҶ…еҗҢжӯҘеҲ° ES дёӯпјҢеҗҰеҲҷе°ҶдјҡеҪұе“ҚеҪ“еӨ©зҡ„дёҡеҠЎз»“жһңпјҢд№ӢеүҚж–№жЎҲдёәдәҶж»Ўи¶іж•ҲзҺҮйҮҮз”ЁдәҶеӨ§йҮҸзҡ„жңәеҷЁиө„жәҗгҖӮ
йҮҮз”ЁеҹәдәҺ Hadoop зҡ„ ES fastIndex зҰ»зәҝж•°жҚ®еҜје…Ҙзі»з»ҹд№ӢеҗҺпјҢеҗҢж ·зҡ„ж•°жҚ®еҜје…Ҙж—¶й—ҙз”ұеҺҹжқҘзҡ„ 8 дёӘе°Ҹж—¶дёӢйҷҚеҲ° 2 дёӘе°Ҹж—¶гҖӮ
жңәеҷЁжҲҗжң¬з”ұеҺҹжқҘзҡ„ 40 еҸ°зү©зҗҶжңә (ES 27 еҸ°гҖҒKafka 3 еҸ°гҖҒDsink 10 еҸ°) дёӢйҷҚеҲ° 30 еҸ°еј№жҖ§дә‘иҠӮзӮ№(10 еҸ°зү©зҗҶжңә)пјҢеҚ•еҚ•еңЁж ҮзӯҫеңәжҷҜе°ұиҠӮзәҰжҲҗжң¬ 7W+ жҜҸжңҲгҖӮ
в‘ўеҹәдәҺиө„жәҗ Quota з®ЎжҺ§зҡ„ ES йӣҶзҫӨе®№йҮҸ规еҲ’ж–№жЎҲ
жҸҗеҚҮ ES йӣҶзҫӨиө„жәҗдҪҝз”ЁзҺҮд№ҹжҳҜж»ҙж»ҙ ElasticSearch еӣўйҳҹдёҖзӣҙйқўдёҙе’ҢиҮҙеҠӣдәҺи§ЈеҶізҡ„й—®йўҳгҖӮ
ж»ҙж»ҙ ElasticSearch еӣўйҳҹз»ҙжҠӨзҡ„ ES жңәеҷЁжҖ»е®№йҮҸе°Ҷиҝ‘ 5PBпјҢжҸҗеҚҮ 10% зҡ„иө„жәҗдҪҝз”ЁзҺҮеҚіеҸҜиҠӮзәҰ 500TB зҡ„з©әй—ҙпјҢжҲ–иҖ…з”ЁдәҺеҪ’иҝҳжңәеҷЁпјҢжҲ–иҖ…з”ЁдәҺжңҚеҠЎж–°зҡ„йңҖжұӮгҖӮ
еҪ“еүҚ ES йӣҶзҫӨж•ҙдҪ“зЈҒзӣҳдҪҝз”ЁзҺҮеңЁ 50% е·ҰеҸіпјҢй«ҳеі°жңҹжӣҫз»ҸиҫҫеҲ° 60%пјҢж—Ҙеҝ—йӣҶзҫӨзЈҒзӣҳдҪҝз”ЁзҺҮиҫҫеҲ° 69.5% (2019.05.01)пјҢдҪҶжҳҜиҝҷдёӘж—¶еҖҷйӣҶзҫӨиө„жәҗйқһеёёдёҚеқҮпјҢзЈҒзӣҳе‘ҠиӯҰд№ҹеҫҲдёҘйҮҚпјҢиҝҗз»ҙеҺӢеҠӣйқһеёёеӨ§пјҢеҒ¶е°”иҝҳдјҡеҮәзҺ°дёўж•°жҚ®зҡ„й—®йўҳгҖӮ
дёәжӯӨжҲ‘们еңЁеҺҹжңүзҡ„ ES жңәеҷЁе®№йҮҸ规еҲ’з®—жі•дёҠпјҢеҠ е…ҘдәҶиө„жәҗ Qutoa з®ЎжҺ§пјҢ并ж·ұе…Ҙеј•ж“ҺпјҢеңЁеј•ж“ҺеұӮйқўе®Ңе–„ ES иҠӮзӮ№зҡ„е®№йҮҸ规еҲ’е’Ңиө„жәҗеқҮеҢҖпјҢжңҹжңӣе°Ҷ ES йӣҶзҫӨзҡ„зЈҒзӣҳж•ҙдҪ“дҪҝз”ЁзҺҮеҶҚжҸҗеҚҮ 10%пјҢж—ҘеқҮиҫҫеҲ° 60%пјҢй«ҳеі°иҫҫеҲ° 70%пјҢ并且没жңүзЈҒзӣҳе‘ҠиӯҰе’ҢзЁіе®ҡжҖ§й—®йўҳгҖӮ
е®һж“Қ
еңЁеүҚжңҹеҮҶеӨҮе·ҘдҪңйғҪе®ҢжҲҗд№ӢеҗҺпјҢйӣҶзҫӨеҚҮзә§е°ұжҲҗдёәдёҖдёӘжҢүйғЁе°ұзҸӯзҡ„иҝҮзЁӢпјҢиҷҪ然жңҹй—ҙд№ҹйҒҮеҲ°дәҶдёҖдәӣж„ҸжғідёҚеҲ°зҡ„жғ…еҶөпјҢиё©дәҶдёҖдәӣеқ‘пјҢдҪҶж•ҙдҪ“зҡ„иҝҮзЁӢиҝҳжҳҜиҝӣиЎҢзҡ„жҜ”иҫғйЎәеҲ©гҖӮ
в‘ еҹәдәҺ ES жңҚеҠЎе…ғж•°жҚ®зҡ„жҹҘиҜўжөҒйҮҸеӣһж”ҫеҜ№жҜ”зі»з»ҹ
еңЁеүҚжңҹжһ„е»әзҡ„ AMS(Arius Meta Service)зі»з»ҹдёҠпјҢжҲ‘们еҜ№з”ЁжҲ·жҹҘиҜўжқЎд»¶гҖҒжҹҘиҜўз»“жһңиҝӣиЎҢи®°еҪ•е’ҢеҲҶжһҗгҖӮ
еңЁеҸҢеҶҷжҗ¬иҝҒеҚҮзә§иҝҮзЁӢдёӯпјҢжҲ‘们е°Ҷз”ЁжҲ·зҡ„жҹҘиҜўжқЎд»¶еҲҶеҲ«еңЁй«ҳдҪҺзүҲжң¬зҡ„йӣҶзҫӨдёҠиҝӣиЎҢеӣһж”ҫпјҢе°ҶжҹҘиҜўиҝ”еӣһзҡ„з»“жһңгҖҒжҖ§иғҪеҸӮж•°иҝӣиЎҢеҜ№жҜ”еҲҶжһҗгҖӮ
еҸӘжңүеҜ№жҜ”дёҖиҮҙпјҢ并且жҖ§иғҪж— еӨӘеӨ§е·®ејӮзҡ„жғ…еҶөдёӢпјҢжҲ‘们жүҚи®ӨдёәеҚҮзә§жңүж•ҲпјҢиҝҷж ·еҒҡеҲ°еҝғдёӯжңүеә•гҖӮ
в‘ЎеҹәдәҺ ECM зҡ„ ES еӨҡйӣҶзҫӨеҚҮзә§иҝҮзЁӢ
з”ұдәҺйңҖиҰҒиҝӣиЎҢеҸҢеҶҷжҗ¬иҝҒеҚҮзә§пјҢеңЁе®һйҷ…зҡ„еҚҮзә§иҝҮзЁӢдёӯпјҢйңҖиҰҒеҜҶйӣҶзҡ„иҝӣиЎҢйӣҶзҫӨжҗӯе»әгҖҒжҗ¬иҝҒгҖҒйҮҚеҗҜзӯүж“ҚдҪңпјҢеҫ—зӣҠдәҺ ECM зҡ„йӣҶзҫӨз®ЎжҺ§иғҪеҠӣпјҢеј№жҖ§дә‘зҒөжҙ»зҡ„зү№жҖ§пјҢжҲ‘们е’Ңиҝҗз»ҙеҗҢеӯҰеҜҶеҲҮй…ҚеҗҲжүҚиғҪеңЁзҹӯж—¶й—ҙеҶ…е®ҢжҲҗеӨҡдёӘйӣҶзҫӨзҡ„еҚҮзә§е·ҘдҪңгҖӮ
в‘ўES ж–°зүҲжң¬зү№жҖ§д»ҘеҸҠеҚҮзә§жҖ§иғҪеҲҶжһҗ
ES 6.6.1 жҸҗдҫӣдәҶеҫҲеӨҡж–°зҡ„зү№жҖ§пјҢеңЁжҹҘиҜўеҶҷе…ҘжҖ§иғҪдёҠд№ҹжңүеҫҲеӨ§зҡ„жҸҗеҚҮпјҢжҲ‘们еҚҮзә§е®ҢжҲҗзҡ„дёҖдәӣжЎҲеҲ—д№ҹеҫ—еҲ°дәҶйӘҢиҜҒпјҢжҲ‘们дјҡиҝҷдәӣзү№жҖ§е’ҢжҖ§иғҪжҸҗеҚҮиҝӣиЎҢдёҖдёӘиҜҰз»Ҷзҡ„еҲҶжһҗ并еҲҶдә«з»ҷеӨ§е®¶гҖӮ
в‘ЈES зүҲжң¬еҚҮзә§йҮҮеқ‘еҲҶжһҗ
еңЁеҚҮзә§зҡ„иҝҮзЁӢдёӯжҲ‘们д№ҹиё©дәҶдёҖдәӣеқ‘пјҢеҰӮпјҡй«ҳзүҲжң¬ SDK е ҶеӨ–еҶ…еӯҳж— йҷҗеҲ¶дҪҝз”ЁеҜјиҮҙ OOM зҡ„й—®йўҳпјҢжҲ‘们жҠҠйҒҮеҲ°зҡ„й—®йўҳйғҪиҜҰз»Ҷи®°еҪ•дёӢжқҘиҝӣиЎҢ并еҲҶдә«з»ҷеӨ§е®¶гҖӮ
收иҺ·пјҡй•ҝйЈҺз ҙжөӘдјҡжңүж—¶
з»ҸиҝҮиҝ‘еҚҠе№ҙзҡ„ејҖеҸ‘е’ҢйҮҚжһ„пјҢеңЁе°ҶеӣҪеҶ…йӣҶзҫӨеҚҮзә§еҲ°й«ҳзүҲжң¬зҡ„иҝҮзЁӢдёӯпјҢжҲ‘们д№ҹеңЁжһ¶жһ„гҖҒдә§е“ҒгҖҒжҲҗжң¬гҖҒжҖ§иғҪгҖҒзү№жҖ§гҖҒиҮӘиә«иғҪеҠӣдёҠйғҪжңүдәҶеҫҲеӨ§зҡ„жҸҗеҚҮгҖӮ
жһ¶жһ„жӣҙжё…жҷ°
йҮҚжһ„д№ӢеҗҺж•ҙдёӘж»ҙж»ҙ ElasticSearch е№іеҸ°зҡ„жңҚеҠЎдҪ“зі»еҸҳеҫ—жӣҙжё…жҷ°пјҢдё»иҰҒ收ж•ӣдёәеӣӣеӨ§еқ—еә”з”Ёпјҡ
Gateway иҙҹиҙЈжҹҘиҜўеҶҷе…ҘиҜ·жұӮзҡ„жҺҘе…ҘпјҢз”ЁжҲ·зҡ„йҷҗжөҒгҖҒжқғйҷҗж ЎйӘҢгҖҒзүҲжң¬е…је®№еңЁжӯӨе®ҢжҲҗгҖӮ
ECM иҙҹиҙЈжүҖжңүйӣҶзҫӨзҡ„з®ЎжҺ§пјҢйӣҶзҫӨжҗӯе»әгҖҒеҚҮзә§гҖҒйҮҚеҗҜгҖҒйӣҶзҫӨзә§еҲ«зӣ‘жҺ§е’Ңиҝҗз»ҙеҲҶжһҗеңЁжӯӨе®ҢжҲҗгҖӮ
AMS иҙҹиҙЈжүҖжңүйӣҶзҫӨгҖҒиҠӮзӮ№гҖҒзҙўеј•зҡ„иҝҗиЎҢж—¶дҝЎжҒҜйҮҮйӣҶдёҺеҲҶжһҗпјҢдҝқйҡңж•°жҚ®иҙЁйҮҸпјҢ并ж”ҜжҢҒе…¶д»–ж•°жҚ®еҲҶжһҗеә”з”ЁпјҢеҲҶзә§еӯҳеӮЁгҖҒзҙўеј•еҒҘеә·еҲҶгҖҒйӣҶзҫӨеҒҘеә·жЈҖжҹҘгҖҒжҹҘиҜўеӣһж”ҫзӯүеңЁжӯӨе®ҢжҲҗгҖӮ
Arius Admin иҙҹиҙЈзҙўеј•гҖҒжқғйҷҗгҖҒиө„жәҗз®ЎжҺ§зӯүж ёеҝғиғҪеҠӣгҖӮдҫқиө– Admin зҡ„ж ёеҝғиғҪеҠӣд»ҘеҸҠ AMS зҡ„ж•°жҚ®йҮҮйӣҶиғҪеҠӣпјҢиҝҳжҸҗдҫӣдәҶе®№йҮҸ规еҲ’е’ҢжҷәиғҪе‘ҠиӯҰдёӨдёӘи®ҫи®ЎиүҜеҘҪ并且еҸҜжҸ’жӢ”зҡ„жү©еұ•жңҚеҠЎгҖӮ
еӣӣдёӘеә”з”Ёе®ҢжҲҗеҠҹиғҪжҠҪиұЎгҖҒдҫқиө–и§ЈиҖҰе’ҢжңҚеҠЎеҢ–ж”№йҖ пјҢзӣёжҜ”д№ӢеүҚдёӢзәҝдәҶ arius-watchгҖҒarius-dslгҖҒarius-toolsгҖҒarius-monitorгҖҒarius-mark зӯүдә”дёӘе°Ҹеә”з”ЁпјҢйҮҚжһ„д№ӢеҗҺж•ҙдҪ“ејҖеҸ‘ж•ҲзҺҮе’ҢеҸҜиҝҗз»ҙжҖ§еҫ—еҲ°дәҶеҫҲеӨ§зҡ„жҸҗй«ҳгҖӮ
дә§е“Ғжӣҙжҳ“з”Ё
жҲ‘们еҹәдәҺ ES 6.5.1 зүҲжң¬пјҢе®Ңе…ЁйҮҚжһ„дәҶж»ҙж»ҙ ElasticSearch з”ЁжҲ·жҺ§еҲ¶еҸ°пјҢе…¶дёӯе°Ҷз”ЁжҲ·зҡ„дёҖдәӣй«ҳйў‘ж“ҚдҪңпјҢеҰӮпјҡMapping и®ҫзҪ®/еҸҳжӣҙгҖҒж•°жҚ®жё…зҗҶгҖҒзҙўеј•жү©е®№зј©е®№гҖҒзҙўеј•иҪ¬и®©гҖҒжҲҗжң¬иҙҰеҚ•зӯүејҖж”ҫз»ҷз”ЁжҲ·пјҢжҸҗеҚҮз”ЁжҲ·зҡ„иҮӘеҠ©ж“ҚдҪңжҖ§гҖӮ
жңӘжқҘжҲ‘们иҝҳдјҡеҜ№ж»ҙж»ҙ ElasticSearch з”ЁжҲ·жҺ§еҲ¶еҸ°дёӯзҡ„ Kibana еҚҮзә§еҲ°жңҖж–°зүҲжң¬е№¶иҝӣиЎҢе®ҡеҲ¶еҢ–ејҖеҸ‘пјҢжҸҗдҫӣжӣҙдё°еҜҢе’ҢжӣҙејәеӨ§зҡ„еҠҹиғҪз»ҷз”ЁжҲ·дҪҝз”ЁгҖӮ
жҲҗжң¬жӣҙдҪҺе»ү
д№ӢеүҚж»ҙж»ҙ ElasticSearch е№іеҸ°жңүдёҖеҘ—еҹәдәҺзҙўеј•еҲӣе»ә规еҲҷзҡ„е®№йҮҸ规еҲ’з®—жі•пјҢзӣёжҜ”е®Ңе…ЁжІЎжңү规еҲ’пјҢиҖҒзүҲе®№йҮҸ规еҲ’з®—жі•еҸҜд»Ҙе°Ҷж•ҙдҪ“зҡ„йӣҶзҫӨиө„жәҗдҪҝз”ЁзҺҮз”ұ 30% жҸҗеҚҮеҲ° 50% е·ҰеҸігҖӮ
дҪҶжҳҜд№ҹеӯҳеңЁзқҖдёҖдәӣй—®йўҳпјҢеҰӮпјҡиө„жәҗеҲҶеёғдёҚеқҮгҖҒзғӯзӮ№ж— жі•еҝ«йҖҹеҸ‘зҺ°гҖҒеҠЁжҖҒиҮӘйҖӮеә”иғҪеҠӣдҪҺгҖҒ规еҲ’з®—жі•жҠҪиұЎдёҚеӨҹж— жі•еңЁзҙўеј•йӣҶзҫӨз”ҹж•ҲгҖҒиҝҗз»ҙдҫҝеҲ©жҖ§е·®гҖӮ
дёӢеӣҫеұ•зҺ°дәҶдёҖдёӘж—Ҙеҝ—йӣҶзҫӨж–°иҖҒе®№йҮҸ规еҲ’зҡ„зЈҒзӣҳдҪҝз”ЁзҺҮеҜ№жҜ”пјҢдёҠзәҝж–°зҡ„е®№йҮҸ规еҲ’д№ӢеҗҺпјҢйӣҶзҫӨиө„жәҗдјҡеҗ‘зқҖдёӨдёӘж–№еҗ‘еҸ‘еұ•пјҡ
жӯЈеңЁдҪҝз”Ёзҡ„иө„жәҗжӣҙеҠ иҒҡжӢўпјҢиҠӮзӮ№д№Ӣй—ҙиө„жәҗдҪҝз”ЁзҺҮжӣҙе№іеқҮпјҢж•ҙдҪ“зҡ„иө„жәҗдҪҝз”ЁзҺҮд№ҹжӣҙй«ҳгҖӮ
з©әй—Іиө„жәҗе®Ңе…ЁйҮҠж”ҫпјҢеҹәдәҺеј№жҖ§дә‘йғЁзҪІпјҢеҸҜд»ҘеҒҡеҲ°еҝ«йҖҹд»ҺйӣҶзҫӨж‘ҳйҷӨпјҢеҠ е…ҘеҗҺеӨҮиө„жәҗжұ жҲ–иҖ…еҠ е…Ҙе…¶е®ғиө„жәҗзҙ§еј зҡ„йӣҶзҫӨдёӯгҖӮ
з»ҸиҝҮдёҖзі»еҲ—зҡ„еӯҳеӮЁдјҳеҢ–е’Ңиө„жәҗдҪҝз”ЁзҺҮж”№йҖ зҡ„е®ҢжҲҗпјҢеңЁж»Ўи¶ійӣҶзҫӨеҚҮзә§е’ҢдёҡеҠЎйңҖиҰҒеўһй•ҝзҡ„еҹәзЎҖдёҠпјҢеӣҪеҶ… ES зҡ„иө„жәҗжҲҗжң¬д»Һ 2019 е№ҙ 2 жңҲзҡ„ 339w дёӢйҷҚеҲ° 2019 е№ҙ 6 жңҲзҡ„ 259wпјҢжңәеҷЁж•°д№ҹд»Һ 1658 еҸ°дёӢйҷҚеҲ° 1321 еҸ°гҖӮ
йҡҸзқҖеӣҪеҶ…йӣҶзҫӨеҚҮзә§йҖҗжёҗе…ЁйғЁе®ҢжҲҗпјҢCeph еҶ·еӯҳзҡ„е®Ңе–„пјҢиҝҳдјҡйҖҗжӯҘеҪ’иҝҳжӣҙеӨҡзҡ„жңәеҷЁпјҢж»ҙж»ҙ ElasticSearch е№іеҸ°зҡ„дҪҝз”ЁжҲҗжң¬д№ҹдјҡдёҖжӯҘдёҖжӯҘдёӢйҷҚпјҢеңЁе®ҡд»·дёҠжҲ‘们д№ҹдјҡиҖғиҷ‘иҝӣдёҖжӯҘзҡ„иҝӣиЎҢйҷҚд»·гҖӮ
жҖ§иғҪжӣҙејәеӨ§
ж–°зүҲжң¬еҚҮзә§д№ӢеҗҺеёҰжқҘзҡ„жҖ§иғҪдё»иҰҒдҪ“зҺ°еңЁд»ҘдёӢдёӨзӮ№пјҡ
в‘ жҹҘиҜўжҖ§иғҪжҸҗеҚҮ
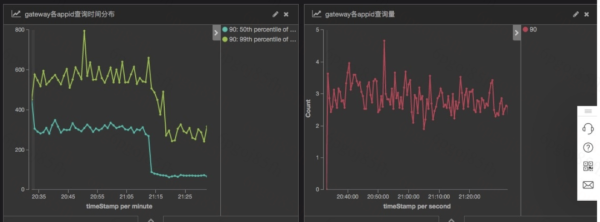
дёӢеӣҫжҳҜе®ўжңҚи®ўеҚ•еҲ—иЎЁжҹҘиҜўиҜӯеҸҘеҚҮзә§еүҚеҗҺзҡ„еҜ№жҜ”пјҢ50 еҲҶдҪҚиҖ—ж—¶д»Һ 300ms дёӢйҷҚеҲ° 50msгҖӮ99 еҲҶдҪҚд»Һ 600ms дёӢйҷҚеҲ° 300msгҖӮ
жҖ§иғҪжҸҗеҚҮзҡ„иҜҰз»ҶеҲҶжһҗи§ҒпјҡES ж–°зүҲжң¬зү№жҖ§д»ҘеҸҠеҚҮзә§жҖ§иғҪеҲҶжһҗгҖӮ
в‘ЎйӣҶзҫӨеҶҷе…ҘжҖ§иғҪжҸҗеҚҮ
еҚҮзә§еҲ°й«ҳзүҲжң¬еҸӘдјҡпјҢES 6.6.1 йӣҶзҫӨзӣёеҜ№дәҺ ES 2.3.3 йӣҶзҫӨеҗҢзӯүиө„жәҗж¶ҲиҖ—дёӢпјҢж•ҙдёӘйӣҶзҫӨзҡ„еҶҷе…ҘиғҪеҠӣжҸҗеҚҮдәҶ 30%гҖӮ
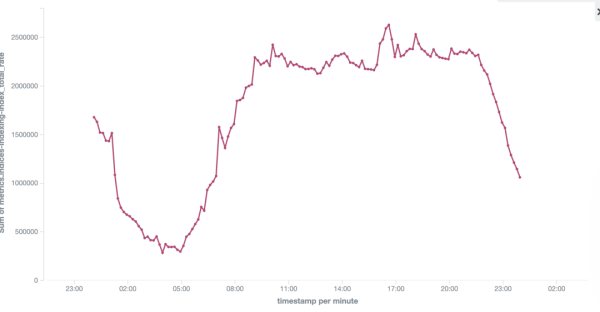
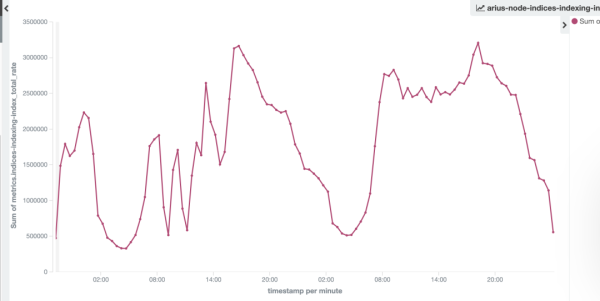
еҰӮдёӢеӣҫж—Ҙеҝ—йӣҶзҫӨзҡ„еҶҷе…Ҙ TPS еүҚеҗҺеҜ№жҜ”пјҢйӣҶзҫӨеҶҷе…ҘиғҪеҠӣд»Һ 240w/s жҸҗеҚҮеҲ°320w/sгҖӮ
еұ•жңӣпјҡзӣҙжҢӮдә‘еёҶжөҺжІ§жө·
иҮіжӯӨпјҢж»ҙж»ҙ ElasticSearch еӣўйҳҹе·Із»Ҹе®ҢжҲҗдәҶеӣҪеҶ…е…ЁйғЁж—Ҙеҝ—йӣҶзҫӨгҖҒ90% зҡ„ vip йӣҶзҫӨзҡ„еҚҮзә§пјҢж•ҙдёӘж»ҙж»ҙ ElasticSearch е№іеҸ°зҡ„жһ¶жһ„д№ҹеҫ—д»ҘйҮҚжһ„е’ҢеҚҮзә§пјҢд»ҺиҖҢеңЁ ES еј•ж“ҺеұӮйқўд№ҹжңүдәҶжӣҙеӨ§зҡ„еҸ‘еұ•з©әй—ҙгҖӮ
жңӘжқҘжҲ‘们е°ҶжӣҙеҠ дё“жіЁдәҺеј•ж“Һе»әи®ҫпјҢжӣҙеӨҡзҡ„д»Һж №жң¬дёҠи§ЈеҶізӣ®еүҚйҒҮеҲ°зҡ„й—®йўҳгҖӮжңӘжқҘжҲ‘们е°ҶеңЁд»ҘдёӢеҮ дёӘж–№еҗ‘жҢҒз»ӯеҠӘеҠӣпјҡ
в‘ жӣҙеӨ§зҡ„йӣҶзҫӨ
еңЁж—Ҙеҝ—еңәжҷҜдёӢе°қиҜ•зӘҒз ҙ ES еҚ•йӣҶзҫӨж”ҜжҢҒзҡ„жңҖеӨ§иҠӮзӮ№ж•°йҷҗеҲ¶пјҢжҸҗеҚҮеҚ•дёӘйӣҶзҫӨиғҪж”ҜжҢҒзҡ„иҠӮзӮ№ж•°йҮҸпјҢд»Һзӣ®еүҚзҡ„еҚ•йӣҶзҫӨж”ҜжҢҒзҡ„ 200 дёӘиҠӮзӮ№жҸҗеҚҮеҲ° 1000 дёӘиҠӮзӮ№гҖӮ
жңҹеҫ…еңЁеӨ§йӣҶзҫӨдёӢиғҪйҷҚдҪҺжҲ‘们зҡ„йӣҶзҫӨж•°йҮҸжҸҗеҚҮиҝҗз»ҙж•ҲзҺҮпјҢеҗҢж—¶жӣҙеӨ§зҡ„йӣҶзҫӨиғҪжӣҙж–№дҫҝе’ҢжӣҙзҒөжҙ»зҡ„жҸҗеҚҮиө„жәҗдҪҝз”ЁзҺҮпјҢи§ЈеҶіжөҒйҮҸзӘҒеўһе’Ңиө„жәҗзғӯзӮ№й—®йўҳгҖӮ
в‘ЎжӣҙдҪҺзҡ„жҲҗжң¬
йҷҚдҪҺ ES зҡ„дҪҝз”ЁжҲҗжң¬пјҢжҸҗеҚҮиө„жәҗдҪҝз”ЁзҺҮдёҖзӣҙжҳҜжҲ‘们иҝҪжұӮзҡ„зӣ®ж ҮпјҢдёҠеҚҠе№ҙжҲ‘们еңЁе®ҢжҲҗйӣҶзҫӨеҚҮзә§д»ҘеҸҠжңҚеҠЎеҘҪдёҡеҠЎзҡ„еҗҢж—¶д№ҹе®ҢжҲҗиҠӮзәҰжҲҗжң¬ 80w жҜҸжңҲпјҢES ж•ҙдҪ“жҲҗжң¬дёӢйҷҚзәҰ 25%пјҢдёӢеҚҠе№ҙдәүеҸ–еҶҚдёӢйҷҚжҲҗжң¬ 10%гҖӮ
ES 6.6.1 жҸҗдҫӣзҡ„дёҖдәӣж–°зү№жҖ§еҰӮпјҡFrozen жңәеҲ¶гҖҒIndexing sort йғҪе°ҶдјҡиҝӣдёҖжӯҘйҷҚдҪҺиө„жәҗж¶ҲиҖ—гҖӮ
в‘ўжӣҙеҝ«зҡ„иҝӯд»Ј
ES йӣҶзҫӨеҶ…еӨҡз§ҹжҲ·жҹҘиҜўд№Ӣй—ҙзҡ„зӣёдә’еҪұе“ҚдёҖзӣҙд№ҹжҳҜж»ҙж»ҙ ElasticSearch еӣўйҳҹйқўдёҙзҡ„дёҖдёӘжҜ”иҫғйҡҫи§ЈеҶізҡ„й—®йўҳпјҢд№ӢеүҚжӣҙеӨҡзҡ„жҳҜеңЁе№іеҸ°еұӮйқўйҖҡиҝҮзү©зҗҶиө„жәҗйҡ”зҰ»пјҢжҹҘиҜўе®Ўж ёе’ҢйҷҗжөҒжқҘи§ЈеҶіпјҢиө„жәҗеҲ©з”ЁзҺҮдёҚй«ҳе’Ңдәәдёәиҝҗз»ҙжҲҗжң¬еӨӘеӨ§гҖӮ
еҗҺз»ӯжҲ‘们е°Ҷжһ„е»әдёҖеҘ— ES иҮӘиә«зҡ„жҹҘиҜўдјҳеҢ–еҷЁпјҢзұ»дјј MySQL зҡ„ ExplainпјҢеҸҜд»ҘеңЁжҹҘиҜўиҜӯеҸҘзә§еҲ«иҝӣиЎҢжҖ§иғҪеҲҶжһҗе’ҢжҹҘиҜўдјҳеҢ–пјҢ并еңЁеј•ж“ҺеұӮйқўйҖҡиҝҮзҙўеј•жЁЎжқҝзә§еҲ«зҡ„жҹҘиҜўиө„жәҗйҡ”зҰ»гҖҒдёҖиҲ¬ query е’Ң heavy query зҡ„еҲҶзҰ»жқҘдҝқйҡңжҹҘиҜўзҡ„зЁіе®ҡгҖӮ
в‘Јжӣҙзҙ§еҜҶзҡ„иҒ”зі»
еңЁ ES ж–°зүҲзҡ„еҹәзЎҖдёҠпјҢжҲ‘们е°Ҷе’ҢзӨҫеҢәдҝқжҢҒжӣҙзҙ§еҜҶзҡ„иҒ”зі»пјҢз§ҜжһҒзҡ„и·ҹиҝӣзӨҫеҢәжҸҗдҫӣзҡ„ж–°зү№жҖ§е’ҢеҸ‘еұ•ж–№еҗ‘пјҢ并引е…Ҙж»ҙж»ҙдҫӣеӨ§е®¶дҪҝз”ЁгҖӮ
д№ҹдјҡжӣҙз§ҜжһҒзҡ„еҸӮдёҺзӨҫеҢәе»әи®ҫпјҢе°ҶжҲ‘们еңЁж»ҙж»ҙеҶ…йғЁйҒҮеҲ°е’Ңи§ЈеҶізҡ„й—®йўҳеҸҚйҰҲз»ҷзӨҫеҢәпјҢиҙЎзҢ®жӣҙеӨҡзҡ„ PR е’Ңдә§з”ҹжӣҙеӨҡзҡ„ ES ContributorгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңElasticSearchе№іеҸ°жһ¶жһ„еҚҮзә§еҲҶжһҗвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ