жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–ҮжқҘиҮӘзӨҫеҢәз”ЁжҲ·жҠ•зЁҝпјҢж„ҹи°ўиҝҷдҪҚе°Ҹдјҷдјҙзҡ„жҠҖжңҜеҲҶдә«
е·Ёжқүж•°жҚ®еә“жһ¶жһ„з®Җд»Ӣ
е·Ёжқүж•°жҚ®еә“дҪңдёәеҲҶеёғејҸж•°жҚ®еә“жҳҜи®Ўз®—е’ҢеӯҳеӮЁеҲҶзҰ»жһ¶жһ„пјҢз”ұж•°жҚ®еә“е®һдҫӢеұӮе’ҢеӯҳеӮЁеј•ж“ҺеұӮз»„жҲҗзҡ„гҖӮеӯҳеӮЁеј•ж“ҺеұӮиҙҹиҙЈж•°жҚ®еә“ж ёеҝғеҠҹиғҪжҜ”еҰӮж•°жҚ®иҜ»еҶҷеӯҳеӮЁд»ҘеҸҠеҲҶеёғејҸдәӢеҠЎз®ЎзҗҶгҖӮж•°жҚ®еә“е®һдҫӢеұӮд№ҹе°ұжҳҜиҝҷйҮҢзҡ„зҡ„SQLеұӮиҙҹиҙЈжҠҠеә”з”ЁSQLиҜ·жұӮеӨ„зҗҶеҗҺеҸ‘еӯҳеӮЁеј•ж“ҺеұӮеӨ„зҗҶпјҢ并且жҠҠеӯҳеӮЁеј•ж“ҺеұӮе“Қеә”з»“жһңеҸҚйҰҲз»ҷеә”з”ЁеұӮгҖӮж”ҜжҢҒз»“жһ„еҢ–е®һдҫӢжҜ”еҰӮMySQLе®һдҫӢ/PGе®һдҫӢ/sparkе®һдҫӢпјҢд№ҹж”ҜжҢҒйқһз»“жһ„еҢ–е®һдҫӢжҜ”еҰӮ Jsonе®һдҫӢ/S3еҜ№иұЎеӯҳеӮЁе®һдҫӢ/PosixFsе®һдҫӢзӯүзӯүгҖӮиҝҷз§Қжһ¶жһ„ж”ҜжҢҒзҡ„е®һдҫӢзұ»еһӢжҜ”иҫғеӨҡпјҢж–№дҫҝд»Һдј з»ҹж•°жҚ®еә“ж— зјқиҝҒ移еҲ°е·Ёжқүж•°жҚ®еә“пјҢеҮҸе°ҸдәҶејҖеҸ‘еӯҰд№ жҲҗжң¬пјҢд№ӢеүҚд№ҹи·ҹж•°жҚ®еә“еңҲеҗҢиЎҢдәӨжөҒпјҢ他们еҜ№жһ¶жһ„д№ҹжҳҜеҚҒеҲҶи®ӨеҸҜгҖӮ
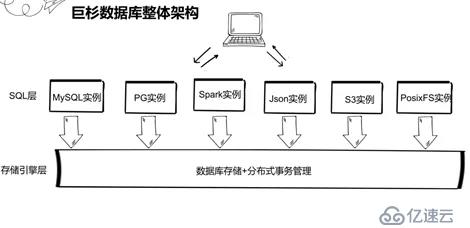
иҝҷйҮҢзҡ„SQLеұӮйҮҮз”Ёзҡ„жҳҜMySQLе®һдҫӢпјҢеӯҳеӮЁеј•ж“ҺеұӮжҳҜжңүдёүдёӘж•°жҚ®иҠӮзӮ№е’ҢеҚҸи°ғиҠӮзӮ№зј–зӣ®иҠӮзӮ№з»„жҲҗгҖӮе…¶дёӯж•°жҚ®иҠӮзӮ№е°ұжҳҜз”ЁжқҘеӯҳеӮЁж•°жҚ®зҡ„пјҢеҚҸи°ғиҠӮзӮ№дёҚеӯҳеӮЁж•°жҚ®пјҢжҳҜз”ЁжқҘжҠҠMySQLзҡ„иҜ·жұӮиҝӣиЎҢи·Ҝз”ұеҲҶеҸ‘еҲ°ж•°жҚ®еә“иҠӮзӮ№гҖӮзј–зӣ®иҠӮзӮ№з”ЁжқҘеӯҳеӮЁйӣҶзҫӨзҡ„зі»з»ҹдҝЎжҒҜжҜ”еҰӮз”ЁжҲ·дҝЎжҒҜ/еҲҶеҢәдҝЎжҒҜзӯүзӯүгҖӮиҝҷйҮҢз”ЁдёҖдёӘе®№еҷЁжқҘжЁЎжӢҹдёҖдёӘзү©зҗҶжңәжҲ–дә‘иҷҡжӢҹжңәпјҢиҝҷйҮҢи®ҫзҪ®зҡ„жҳҜMySQLе®һдҫӢеңЁдёҖдёӘе®№еҷЁйҮҢпјҢзј–зӣ®е’ҢиҠӮзӮ№е’ҢеҚҸи°ғиҠӮзӮ№ж”ҫеңЁдәҶдёҖдёӘе®№еҷЁпјҢдёүдёӘж•°жҚ®иҠӮзӮ№еҲҶеҲ«ж”ҫеңЁдёҖдёӘе®№еҷЁпјҢдёүдёӘж•°жҚ®иҠӮзӮ№жһ„жҲҗдәҶдёүдёӘж•°жҚ®з»„пјҢжҜҸдёӘж•°жҚ®з»„дёүдёӘеүҜжң¬гҖӮWebеә”з”Ёзҡ„жө·йҮҸж•°жҚ®жҳҜйҖҡиҝҮеҲҶзүҮеҲҮеҲҶзҡ„ж–№ејҸеҲҶж•Јз»ҷдёҚеҗҢзҡ„ж•°жҚ®иҠӮзӮ№пјҢеғҸиҝҷйҮҢзҡ„ж•°жҚ®ABCйҖҡиҝҮеҲҶзүҮжү“ж•ЈеҲ°дёүеҸ°жңәеҷЁгҖӮ
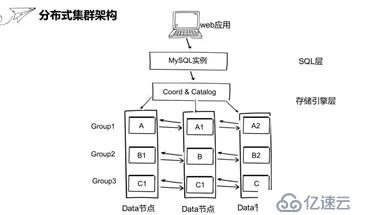
иҝҷйҮҢзҡ„ж•°жҚ®еҲҶзүҮжҳҜйҖҡиҝҮеҲҶеёғејҸHashз®—жі•DHTжңәеҲ¶е®һзҺ°пјҢDHTжҳҜdistribute Hashing table зј©еҶҷгҖӮеҪ“еҶҷе…Ҙж•°жҚ®ж—¶пјҢйҰ–е…ҲйҖҡиҝҮMySQLе®һдҫӢжҠҠи®°еҪ•дёӢеҸ‘еҲ°еҚҸи°ғиҠӮзӮ№пјҢеҚҸи°ғиҠӮзӮ№дјҡйҖҡиҝҮеҲҶеёғејҸHashз®—жі•ж №жҚ®жҜҸжқЎи®°еҪ•зҡ„еҲҶеҢәй”®иҝӣиЎҢж•ЈеҲ—пјҢж•ЈеҲ—е®Ңд№ӢеҗҺеҚҸи°ғиҠӮзӮ№ж №жҚ®еҲҶеҢәй”®еҲӨж–ӯеҲ°еә•еҸ‘йҖҒеҲ°е“ӘдёҖдёӘеҲҶеҢәпјҢжүҖд»ҘжҜҸдёӘеҲҶеҢәд№Ӣй—ҙзҡ„ж•°жҚ®жҳҜе®Ңе…Ёйҡ”зҰ»дә’зӣёзӢ¬з«Ӣзҡ„гҖӮйҮҮз”Ёиҝҷз§Қж–№жі•пјҢжҲ‘们е°ұеҸҜд»ҘжҠҠдёҖдёӘеҫҲеӨ§зҡ„иЎЁжӢҶж•ЈеҲ°дёӢйқўдёҚеҗҢзҡ„еӯҗеҲҶеҢәйҮҢйқўе°ҸиЎЁпјҢе®һзҺ°ж•°жҚ®жӢҶеҲҶгҖӮ
mysqldumpе’Ң mydumper/myloader
еҜје…ҘеҜјеҮәе·Ҙе…·е®һжҲҳ
SequoiaDBе®һзҺ°дәҶеҜ№MySQLзҡ„е®Ңж•ҙе…је®№пјҢйӮЈд№Ҳжңүзҡ„з”ЁжҲ·дјҡй—®дәҶпјҡ
вҖң既然жҳҜе®Ңж•ҙе…је®№пјҢMySQLзӣёе…ізҡ„е·Ҙе…·жҳҜеҗҰиғҪдҪҝз”ЁпјҹвҖқ
вҖңж•°жҚ®д»ҺMySQLиҝҒ移еҲ°SequoiaDBеҰӮдҪ•ж“ҚдҪңпјҹвҖқ
дёӢйқўжҲ‘们е°ұд»Ӣз»ҚSequoiaDBеҰӮдҪ•дҪҝз”Ё mysqldumpе’Ң mydumper/myloader иҝӣиЎҢж•°жҚ®зҡ„еҜје…ҘеҜјеҮәгҖӮ
1пјүйҖҡиҝҮеӯҳеӮЁиҝҮзЁӢеҲ¶йҖ жөӢиҜ•ж•°жҚ®
#mysql -h 127.0.0.1 -P 3306 -u root
mysql>create database news;
mysql>use news;
mysql>create table user_info(id int(11),unickname varchar(100));
delimiter //
create procedure `news`.`user_info_PROC`()
begin
declare iloop smallint default 0;
declare iNum mediumint default 0;
declare uid int default 0;
declare unickname varchar(100) default 'test';
while iNum <=10 do
start transaction;
while iloop<=10 do
set uid=uid+1;
set unickname=CONCAT('test',uid);
insert into `news`.`user_info`(id,unickname)
values(uid,unickname);
set iloop=iloop+1;
end while;
set iloop=0;
set iNum=iNum+1;
commit;
end while;
end//
delimiter ;
call news.user_info_PROC();2пјүжҹҘзңӢеҲ¶йҖ жөӢиҜ•ж•°жҚ®зҠ¶еҶө
mysql> use news;
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
1 row in set (0.00 sec)
mysql> select count(*) from user_info;
+----------+
| count(*) |
+----------+
| 121 |
+----------+
1 row in set (0.01 sec)3пјүжү§иЎҢдёӢйқўmysqldumpеӨҮд»ҪжҢҮд»Ө
#/opt/sequoiasql/mysql/bin/mysqldump -h 127.0.0.1 -P 3306 -u
root -B news > news.sqlжҹҘзңӢеҲ°еҜ№еә”зҡ„ж–Ү件дёәnews.sql
然еҗҺзҷ»йҷҶеҲ°ж•°жҚ®еә“еҲ йҷӨеҺҹжқҘзҡ„ж•°жҚ®еә“ж•°жҚ®
mysql> drop database news;
Query OK, 1 row affected (0.10 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)4пјүз”ЁsourceеҜје…Ҙж–°зҡ„ж•°жҚ®
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
дҪҝз”ЁmysqldumpеҜјеҮәзҡ„е®Ңж•ҙsqlиҜӯеҸҘпјҢзӣҙжҺҘзҷ»йҷҶж•°жҚ®еә“жү§иЎҢеҜје…ҘеҚіеҸҜ:
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
mysql>source news.sql
mysql> use news;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with-A
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
1 row in set (0.00 sec)еҸҜд»ҘзңӢеҲ°иҝ”еӣһз»“жһңпјҢзҡ„зЎ®ж”ҜжҢҒmysqldumpж•°жҚ®еҜјеҮәе·Ҙе…·е’ҢsourceеҜје…Ҙе·Ҙе…·гҖӮ
иҝҷдёҖз« иҠӮе°Ҷд»Ӣз»Қжңүе…іmydumperе’Ңmyloaderе·Ҙе…·зҡ„дҪҝз”ЁгҖӮ
жңүзҡ„еҗҢеӯҰеҜ№дәҺmysqldumpдёҺmydumperжңүзӮ№ж··ж·ҶпјҡmysqldumpжҳҜMySQLеҺҹеҺӮиҮӘеёҰзҡ„гҖӮmydumper/myloaderжҳҜз”ұMySQL /Facebookзӯүе…¬еҸёејҖеҸ‘з»ҙжҠӨзҡ„дёҖеҘ—йҖ»иҫ‘еӨҮд»ҪжҒўеӨҚе·Ҙе…·пјҢDBAиҫғеёёдҪҝз”ЁпјҢйңҖиҰҒеҚ•зӢ¬е®үиЈ…пјҢе…·дҪ“е®үиЈ…ж–№ејҸеҸҜд»ҘеңЁзҪ‘з»ңдёҠиҝӣиЎҢжҹҘиҜўгҖӮ
й’ҲеҜ№SequoiaDBдҪҝз”Ёmydumper/myloaderзҡ„жғ…еҶөпјҢ
жҲ‘们йҰ–е…ҲжҹҘзңӢmydumperзүҲжң¬еҸ·
# mydumper --version
mydumper 0.9.1, built against MySQL 5.7.171пјүmydumperеҜјеҮәж•°жҚ®
# mydumper -h 127.0.0.1 -P 3306 -u root -B news -o /home/sequoiadb
еҲ йҷӨеҺҹжқҘзҡ„ж•°жҚ®еә“
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| news |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> drop database news;
Query OK, 1 row affected (0.13 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)2пјүmyloader еҜје…Ҙж•°жҚ®
еҸҜд»ҘзңӢеҲ°ж•°жҚ®е·Із»Ҹиў«еҲ йҷӨпјҢеҲ©з”ЁmyloaderеҜје…Ҙж•°жҚ®
#myloader -h 127.0.0.1 -P 3306 -u root -B news -d /home/sequoiadb
зҷ»йҷҶеҲ°ж•°жҚ®еә“дёӯжҹҘзңӢ
# /opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| news |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> use news;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
1 row in set (0.00 sec)
mysql> select count(*) from user_info;
+----------+
| count(*) |
+----------+
| 121 |
+----------+
1 row in set (0.00 sec)mydumper еҸҠ myloader еҜје…Ҙж•°жҚ®жІЎй—®йўҳпјҢзңӢжқҘе·Ёжқүж•°жҚ®еә“ Sequoiadb зҡ„зЎ®ж”ҜжҢҒ MySQL зҡ„е…је®№е·Ҙе…· mydumper еҸҠ myloaderгҖӮ
иҝҒ移 MySQL ж•°жҚ®еә“ж•°жҚ®еҸӘйңҖиҰҒжҠҠ MySQL ж•°жҚ®еҲ©з”Ё mydumper еҜјеҮәд№ӢеҗҺпјҢеңЁе·Ёжқүж•°жҚ®еә“еҲ©з”Ё myloader еҜје…ҘеҲ°е·Ёжқүж•°жҚ®еә“еҚіеҸҜгҖӮ
жҖ»з»“
е·Ёжқүж•°жҚ®еә“йҮҮз”Ёи®Ўз®—-еӯҳеӮЁеҲҶзҰ»зҡ„жһ¶жһ„пјҢе®һзҺ°дәҶMySQLзҡ„100%е®Ңж•ҙе…је®№гҖӮйҖҡиҝҮжң¬ж–ҮпјҢжҲ‘们д№ҹеҸҜд»ҘзңӢеҲ°пјҢе·Ёжқүж•°жҚ®еә“еҸҜд»Ҙж”ҜжҢҒжүҖжңүж ҮеҮҶMySQLзҡ„е‘Ёиҫ№е·Ҙе…·пјҢеҗҢж—¶еҲҶеёғејҸеҸҜжү©еұ•жҖ§е°ҶеӨ§еӨ§жҸҗеҚҮе·Іжңүеә”з”Ёзҡ„жү©еұ•жҖ§д»ҘеҸҠж•ҙдҪ“ж•°жҚ®з®ЎзҗҶиғҪеҠӣгҖӮеӣ жӯӨпјҢе·Ёжқүж•°жҚ®еә“SequoiaDBеҸҜд»ҘиҜҙжҳҜдј з»ҹеҚ•зӮ№MySQLж–№жЎҲзҡ„дёҖз§ҚжңүеҠӣжӣҝжҚўгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ