您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“ActiveMQ架构设计与实践案例分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1、架构设计概要
ActiveMQ提供两种可供实施的架构模型:“M-S”和“network bridge”;其中“M-S”是HA方案,“网络转发桥”用于实现“分布式队列”。
1.1、M-S
Master-Slave模型下,通常需要2+个ActiveMQ实例,任何时候只有一个实例为Master,向Client提供”生产”、“消费”服务,Slaves用于做backup或者等待Failover时角色接管。
M-S模型是最通用的架构模型,它提供了“高可用”特性,当Master失效后,Slaves之一提升为master继续提供服务,且Failover之后消息仍然可以恢复。(根据底层存储不同,有可能会有消息的丢失)。
有以下两方面要点:
第一,M-S架构中,涉及到选举问题,选举的首要条件就是需要有“排它锁”的支持。排它锁,可以有共享文件锁、JDBC数据库排它锁、JDBC锁租约、zookeeper分布式锁等方式实现。这取决你的底层存储的机制。
第二,M-S架构中,消息存储的机制有多种,“共享文件存储”、“JDBC”存储、“非共享存储”等。不同存储机制,各有优缺点。在使用的时候一定要权衡。
1.2、网络转发桥(network bridge)
无论如何,一组M-S所能承载的消息量、Client并发级别总是有限的,当我们的消息规模达到单机的上限时,就应该使用基于集群的方式,将消息、Client进行分布式和负载均衡。
ActiveMQ提供了“网络转发桥”模式,核心思想是:
1、集群中多个broker之间,通过“连接”互相通信,并将消息在多个Broker之间转发和存储,提供存储层面的“负载均衡”。
2、根据Client的并发情况,对Client进行动态平衡,最终实现支持大规模生产者、消费者。
这和Kafka的核心思想是相似的。
2、M-S架构设计详解
2.1、非共享存储模式
集群中有2+个ActiveMQ实例,每个实例单独存储数据,Master将消息保存在本地后,并将消息以异步的方式转发给Slaves。
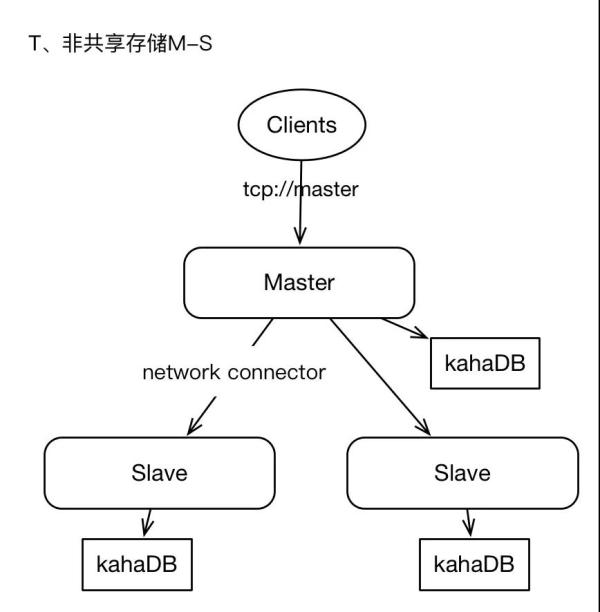
Master和slaves独立部署,各自负责自己的存储,Master与slaves之间通过“network connector”连接,通常是Master单向与slaves建立连接。master上接收到的消息将会全量转发给slaves。
有下面几个要点:
1)任何时候只有Master向Clients提供服务,slaves仅作backup。古老的影子节点方式。
2)slaves上存储的消息,有短暂的延迟。
3)master永远是master,当master失效时,我们不能随意进行角色切换,最佳实施方式就是重启master,只有当master物理失效时才会考虑将slave提升为master。(这个真是弱爆了)
4)当slaves需要提升为master时,应该确保此slaves的消息是最新的。
5)如果slaves离线,那么在重启slaves之前,还应该将master的数据手动同步给slaves。否则slave离线期间的数据,将不会在slaves上复现。
6)Client端不支持failover协议;即Client只会与master建立连接。
这种架构,是最原始的架构,易于实时,但是问题比较严重,缺乏Failover机制,消息的可靠性我们无法完全保障,因为master与slaves角色切换没有仲裁者、或者说缺少分布式排它锁机制。在Production环境中,不建议采用,如果你能容忍failover期间SLA水平降级的话,也可以作为备选。
2.2、共享文件存储
即采用SAN(GFS)技术,基于网络的全局共享文件系统模式(真是一个名次制造机器),这种架构简单易用,但是可架构、可设计的能力较弱,在Production环境下酌情采用。
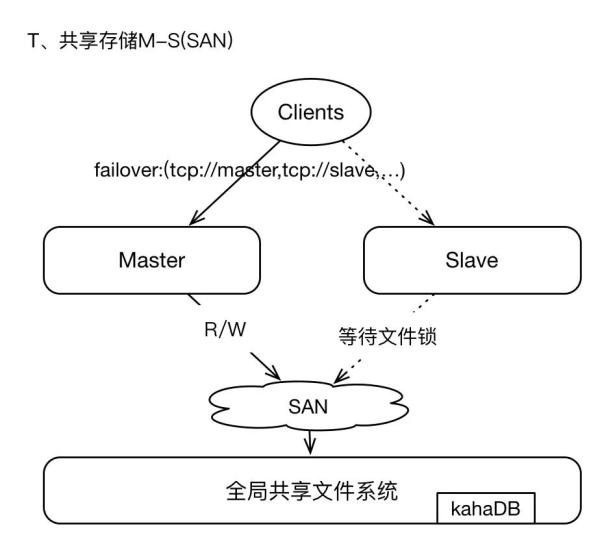
SAN存储,可以参考GFS。其中master和slaves配置保持一致,每个broker都需要有唯一的brokerName;broker实例在启动时首先通过SAN获取文件系统的排它锁,获取lock的实例将成为master,其他brokers将等待lock、并间歇性的尝试获取锁,slaves不提供Clients服务;因为brokers将数据写入GFS,所以在failover之后,新的master获取的数据视图仍然与原master保持一致,毕竟GFS是全局的共享文件系统。
我们通常使用kahaDB作为存储引擎,即使用日志文件方式;kahaDB的存储效率非常的高,TPS可以高达2W左右,是一种高效的、数据恢复能力强的存储机制。
这种架构模式下,支持failover,当master失效后,Clients能够通过failover协议与新的master重连,服务中断时间很短。因为基于GFS存储,所以数据总是保存在远端共享存储区域,所以不存在数据丢失的问题。
唯一的问题,就是GFS(SAN)的稳定性问题。这一点需要确定,SAN区域中的节点之间网络通信必须稳定且高效。(自己搭建比如NFS服务,或者基于AWS EFS)。
这不过是把一个问题转移到另外一个组件上而已。
2.3、基于JDBC共享存储
我们可以将支持JDBC的数据库作为共享存储层,即master将数据写入数据库,本地不保存任何数据,在failover期间,slave提升为master之后,新master即可从数据库中读取数据,这也意味着在整个周期中,master与slaves的数据视图是一致的(同SAN架构),所以数据的恢复能力和一致性是可以保障的,也不存在数据丢失的情况(在存储层)。
但是JDBC存储机制,性能实在是太低,与kahaDB这种基于日志存储层相比,性能相差近10倍左右。
Oh my god。不过在一些低并发,纯粹解耦的场景是可以的。用在高并发互联网就是找死(互联网不一定意味着就是高并发的)。
如果你的业务需求,表明数据丢失是难以容忍的、且SLA水平很高很高,那么JDBC或许是你最好的选择。
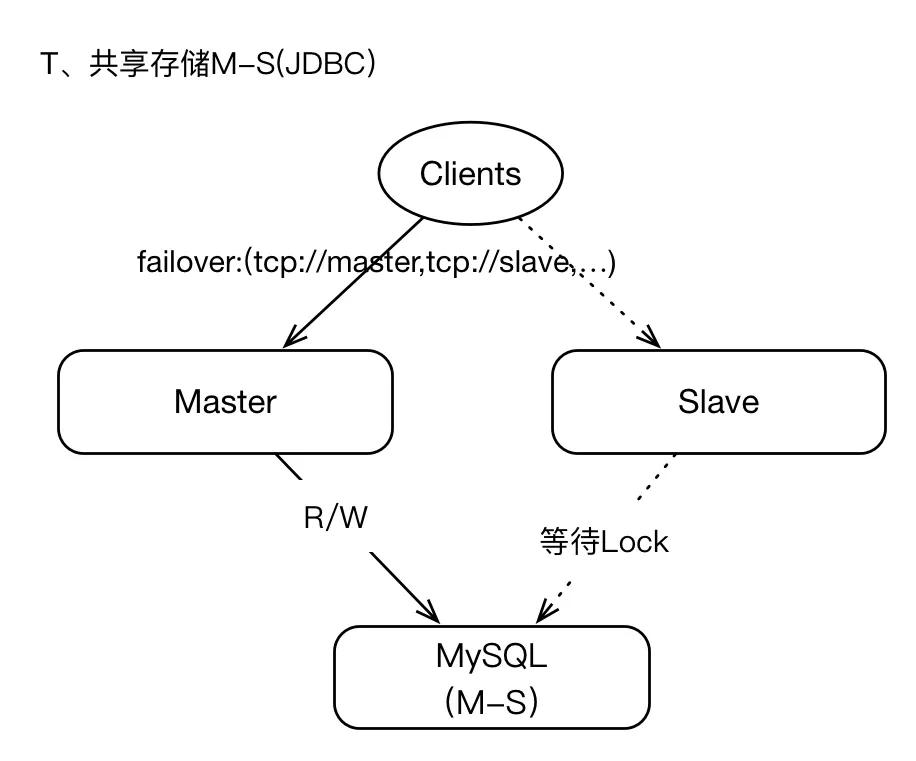
既然JDBC数据库为最终存储层,那么我们很多时候需要关注数据库的可用性问题,比如数据库基于M-S模式等;如果数据库失效,将导致ActiveMQ集群不可用。
JDBC存储面临最大的问题就是“TPS”(吞吐能力),确实比kahaDB低数倍,如果你的业务存在高峰,“削峰”的策略可以首先将消息写入本地文件(然后异步同步给AcitveMQ Broker)。
这个时候我总是有个疑问。直接使用数据库就好了,您废这么大劲上个ActiveMQ又是何苦呢。可能是为了设计而设计吧。
3、network bridges模式架构
这种架构模式,主要是应对大规模Clients、高密度的消息增量的场景;它将以集群的模式,承载较大数据量的应用。
它有下面的要求和特点。
1)有大量Producers、Consumers客户端接入。只所以如此,或许是因为消息通道(Topic,Queue)在水平扩张的方向上,已经没有太大的拆分可能性。所以一股脑挤在一块。
2)或许消息的增量,是很庞大的,特别是一些“非持久化消息”。我们寄希望于构建“分布式队列”架构。也就是其他系统解决不了的问题,希望消息队列能够缓冲一下。
3)因为集群规模较大,我们可能允许集群某些节点短暂的离线,但数据恢复机制仍然需要提供,总体而言,集群仍然提供较高的可用性。
4)集群支持Clients的负载均衡,比如有多个producers时,这些producers会被动态的在多个brokers之间平衡。否则分配不均就会造成风险。
5)支持failover,即当某个broker失效时,Clients可以与其他brokers重连;当集群中有的新的brokers加入时,集群的拓扑也可以动态的通知给Clients。这个是运维人员最喜欢的,谁也不想大半夜起床捣鼓机器。
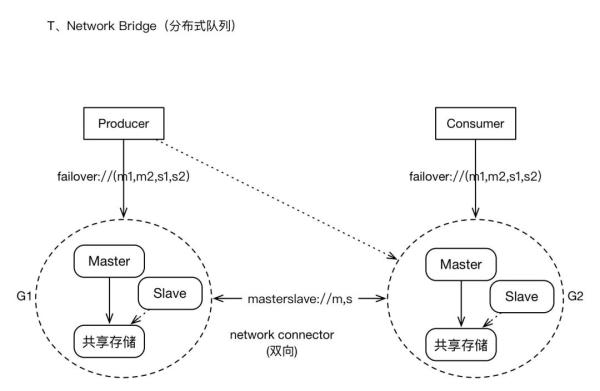
集群有多个子Groups构成,每个Group为M-S模式、共享存储;多个Groups之间基于“network Connector”建立连接(masterslave协议),通常为双向连接,所有的Groups之间彼此相连,Groups之间形成“订阅”关系,比如G2在逻辑上为G1的订阅者(订阅的策略是根据各个Broker上消费者的Destination列表进行分类),消息的转发原理也是基于此。
对于Client而言,仍然支持failover,failover协议中可以包含集群中“多数派”的节点地址。
对于Topic订阅者的消息,将会在所有Group中复制存储;对于Queue的消息,将会在brokers之间转发,并最终到达Consumer所在的节点。
Producers和Consumers可以与任何Group中的Master建立连接并进行消息通信,当Brokers集群拓扑变化时、Producers或Consumers的个数变化时,将会动态平衡Clients的连接位置。Brokers之间通过“advisory”机制来同步Clients的连接信息,比如新的Consumers加入,Broker将会发送advisory消息(内部的通道)通知其他brokers。
集群模式提供了较好的可用性担保能力,在某些特性上或许需要权衡,比如Queue消息的有序性将会打破,因为同一个Queue的多个Consumer可能位于不同的Group上,如果某个Group实现,那么保存在其上的消息只有当其恢复后才能对Clients可见。
4、性能评估
综上所述,在Production环境中,我们能够真正意义上采用的架构,只有三种:
1)基于JDBC的共享数据库模式:HA架构,单一Group,Group中包含一个master和任意多个slaves;所有Brokers之间通过远端共享数据库存取数据。对客户端而言支持Failover协议。
2)基于Network Bridge构建分布式消息集群:Cluster架构,集群中有多个Group,每个Group均为M-S架构、基于共享存储;对于Clients而言,支持负载均衡和Failover;消息从Producer出发,到达Broker节点,Broker根据“集群中Consumers分布”,将消息转发给Consumers所在的Broker上,实现消息的按需流动。
3)基于Network Bridge的简化改造:与2)类似,但是每个“Group”只有一个Broker节点,此Broker基于kahaDB本地文件存储,即相对于2)Group缺少了HA特性;当Broker节点失效时,其上的消息将不可见、直到Broker恢复正常。这种简化版的架构模式,通过增加机器的数量、细分消息的分布,来降低数据影响故障影响的规模,因为其基于kahaDB本地日志存储,所以性能很高。
4.1、共享JDBC测试结果
生产端配置。
Producer端(压力输出机器):数量:4台 硬件配置:16Core、32G,云主机 软件配置:JDK 1.8,JVM 24G 并发与线程:32并发线程,连接池为128,发送文本消息,每个消息128个字符实体。消息:持久化,Queue,非事务
Broker端配置。
Broker端(压力承载) 数量:2台 硬件配置:16Core、32G,云主机 软件配置:JDK 1.8,JVM 24G 架构模式:M-S模式,开启异步转发、关闭FlowControl,数据库连接池为1024
存储层配置。
数据库(存储层) 数量:2台 硬件配置:16Core、32G,SSD(IOPS 3000),云主机 架构模式:M-S 数据库:MySQL
测试结果:
1、消息生产效率:1500 TPS
2、Broker负载情况:CPU 30%,内存使用率11%
3、MySQL负载情况:CPU 46%,IO_WAIT 25%
结论:
1、基于共享JDBC存储架构,性能确实较低。
2、影响性能的关键点,就是数据库的并发IO能力,当TPS在1800左右时,数据库的磁盘(包括slave同步IO)已经出现较高的IO_WAIT。
3、通过升级磁盘、增加IOPS,可以有效提升TPS指标,建议同时提高CPU的个数。
打算采用数据库来实现HA的同学们,你们看到这操蛋的TPS了么?
4.2、基于非共享文件存储的测试结果
测试单个ActiveMQ,基于kahaDB存储,kahaDB分为两种数据刷盘模式:
1)逐条消息刷盘
2)每隔一秒刷盘
<persistenceAdapter> <kahaDB directory="${activemq.data}/kahadb" journalDiskSyncStrategy="periodic" journalDiskSyncInterval="2000"/> </persistenceAdapter>压力测试环境与1)保持一致,只是ActiveMQ的机器的磁盘更换为:SSD (600 IOPS)。
测试结果:
1)逐条刷新磁盘
TPS:660
Broker IO_WAIT:19%
2)每隔一秒刷新磁盘
TPS:9800
Broker IO_WAIT:1.6% (原则上优化磁盘和IOPS等,应该还能提升)
由此可见,基于日志文件的存储性能比JDBC高了接近5倍,其中逐条刷盘策略,消息的可靠性是最高的,但是性能却低于JDBC。如果基于“每隔一秒刷盘”策略,在极端情况下,可能导致最近一秒的数据丢失。
还不错,但离着kafka这样的MQ还远着呢。
4.3、基于转发桥的测试结果
基于转发桥的架构,实施成本较高,维护成本较高,架构复杂度也相对较大。本人根据实践经验,不推荐使用此模式。如果你希望尝试,也无妨,毕竟它是ActiveMQ官方推荐的“分布式队列实现机制”,从原理上它可以支持较大规模的消息存储。
但是,我有更轻量级的,干么用你呢?
4.4、优秀实践
所以本优秀实践是在以上测试的基础上得来的。
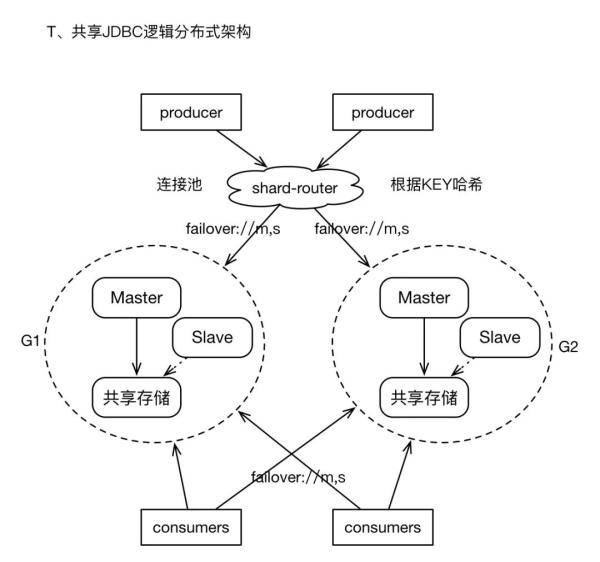
如果我们最终不得不面对“海量消息”的存储,在按照业务进行队列拆分之后,仍然需要面临某个单纯业务的消息量是“单个M-S架构”无法满足的。而我们又不愿意承担Cluster模式复杂度所带来的潜在问题,此时,可以采用比较通用的“逻辑分布式”机制。
1)构建多个M-S组,但是每个Group之间在物理上没有关联,即它们之间互不通信,且不共享存储。
2)在Producer的客户端,增加“router”层, 即开发一个Client Wrapper,此wrapper提供了Producer常用的接口,且持有多个M-S组的ConnectionFactory,在通过底层通道发送消息之前,根据message中的某个property、或者指定的KEY,进行hash计算,进而选择相应的连接(或者Spring的包装类),然后发送消息。这有点类似于基于客户端的数据库读写分离的策略。
3)对于Consumers,则只需要配置多个ConnectionFactory即可。
4)经过上述实践,将消息sharding到多个M-S组,解决了消息发送效率的问题,且逻辑集群可以进行较大规模的扩展。而且对Client是透明的。
5)如果你不想开发shard-router层面,我们仍然可以基于failover协议来实现“逻辑分布式”的消息散列存储,此时需要在failover协议中指明所有Groups的brokers节点列表,且randomize=true。这种用法,可以实现消息在多个Group上存储,唯一遗憾的地方时,因为缺乏“自动负载均衡策略”,可能导致消息分布不均。
配置如下:
failover:(tcp://G1.master,tcp://G1.slave,tcp://G2.master,tcp://G2.slave)?randomize=true //randomize必须为true
“ActiveMQ架构设计与实践案例分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。