您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关如何实现K8s集群架构与高可用解析,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
基本工作过程
Kubernetes 的核心工作过程:
资源对象:Node、Pod、Service、Replication Controller 等都可以看作一种资源对象
操作:通过使用 kubectl 工具,执行增删改查
存储:对象的目标状态(预设状态),保存在 etcd 中持久化储存;
自动控制:跟踪、对比 etcd 中存储的目标状态与资源的当前状态,对差异资源纠偏,自动控制集群状态。
Kubernetes 实际是:高度自动化的资源控制系统,将其管理的一切抽象为资源对象,大到服务器 Node 节点,小到服务实例 Pod。
Kubernetes 的资源控制是一种声明+引擎的理念:
声明:对某种资源,声明他的目标状态
自动:Kubernetes 自动化资源控制系统,会一直努力将该资源对象维持在目标状态。
架构(物理+逻辑)
Kubernetes 集群,是主从架构:
Master:管理节点,集群的控制和调度
Node:工作节点,执行具体的业务容器
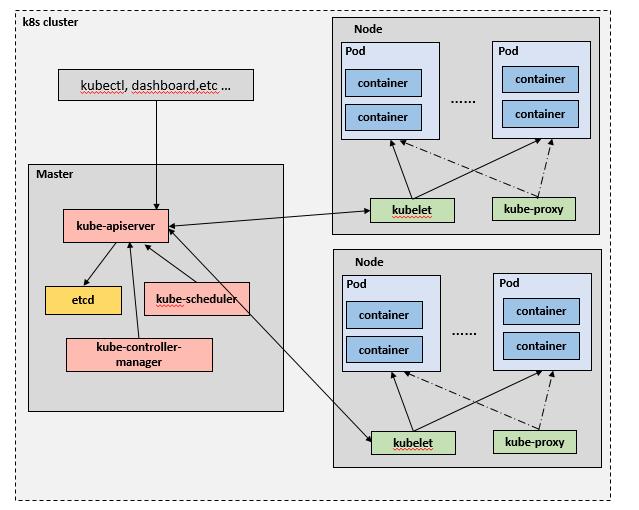
下述几个组件,都是独立的进程,每个进程都是 Go 语言编写,实际部署 Kubernetes 集群,就是部署这些程序。
Master节点:
kube-apiserver
kube-controller-manager
kube-scheduler
Node节点:
kubelet
kube-proxy
具体,2 种角色的节点,需要运行的进程和职责不同,详细描述如下。
Master 管理节点:管理整个 Kubernetes 集群,接收外部命令,维护集群状态。
apiserver: Kubernetes API Server
集群控制的入口
资源的增删改查,持久化存储到 etcd
kubectl 直接与 API Server 交互,默认端口 6443。
etcd: 一个高可用的 key-value 存储系统
作用:存储资源的状态
支持 Restful 的API。
默认监听 2379 和 2380 端口(2379提供服务,2380用于集群节点通信)(疑问:集群节点,是说 etcd 的集群? Master 集群?)
scheduler: 负责将 pod 资源调度到合适的 node 上。
调度算法:根据 node 节点的性能、负载、数据位置等,进行调度。
默认监听 10251 端口。
controller-manager: 所有资源的自动化控制中心
每个资源,都对应有一个控制器(疑问:作用是什么?)
controller manager 管理这些控制器
controller manager 是自动化的循环控制器
Kubernetes 的核心控制守护进程,默认监听10252端口。(疑问:为什么有监听段口感?)
补充说明:
scheduler和controller-manager都是通过apiserver从etcd中获取各种资源的状态,进行相应的调度和控制操作。
Node 节点:Master 节点,将任务调度到 Node 节点,以 docker 方式运行;当 Node 节点宕机时,Master 会自动将 Node 上的任务调度到其他 Node 上。
kubelet: 本节点Pod的生命周期管理,定期向Master上报本节点及Pod的基本信息
Kubelet是在每个Node节点上运行agent
负责维护和管理所有容器:从 apiserver 接收 Pod 的创建请求,启动和停止Pod
Kubelet不会管理不是由Kubernetes创建的容器
定期向Master上报信息,如操作系统、Docker版本、CPU、内存、pod 运行状态等信息
kube-proxy:集群中 Service 的通信以及负载均衡
功能:服务发现、反向代理。
反向代理:支持TCP和UDP连接转发,默认基于Round Robin算法将客户端流量转发到与service对应的一组后端pod。
服务发现:使用 etcd 的 watch 机制,监控集群中service和endpoint对象数据的动态变化,并且维护一个service到endpoint的映射关系。(本质是:路由关系)
实现方式:存在两种实现方式,userspace 和 iptables。
userspace:在用户空间,通过kuber-proxy实现负载均衡的代理服务,是最初的实现方案,较稳定、效率不高;
iptables:在内核空间,是纯采用iptables来实现LB,是Kubernetes目前默认的方式;
runtime:一般使用 docker 容器,也支持其他的容器。
集群的高可用
Kubernetes 集群,在生产环境,必须实现高可用:
鸿蒙官方战略合作共建——HarmonyOS技术社区
实现Master节点及其核心组件的高可用;
如果Master节点出现问题的话,那整个集群就失去了控制;
具体的 HA 示意图:
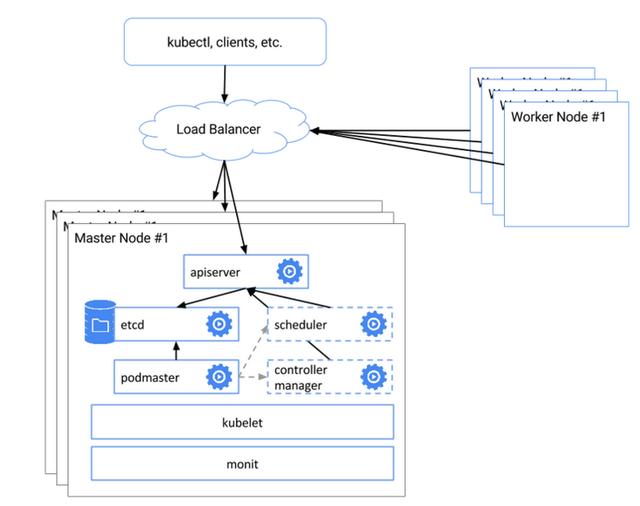
上述方式可以用作 HA,但仍未成熟,据了解,未来会更新升级 HA 的功能.
具体工作原理:
etcd 集群:部署了3个Master节点,每个Master节点的etcd组成集群
入口集群:3个Master节点上的APIServer的前面放一个负载均衡器,工作节点和客户端通过这个负载均衡和APIServer进行通信
pod-master保证仅是主master可用,scheduler、controller-manager 在集群中多个实例只有一个工作,其他为备用
关于如何实现K8s集群架构与高可用解析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。