жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
1. еј•иЁҖ
зҺ°д»Ји®Ўз®—жңәпјҢеҚідҪҝеҫҲе°Ҹзҡ„жҷәиғҪжңәдәҰжҲ–иҖ…е№іжқҝз”өи„‘пјҢйғҪжҳҜдёҖдёӘеӨҡж ё(еӨҡCPU)еӨ„зҗҶи®ҫеӨҮпјҢеҰӮдҪ•е……еҲҶеҲ©з”ЁеӨҡж ёCPUиө„жәҗпјҢд»ҘиҫҫеҲ°еҚ•жңәжҖ§иғҪзҡ„жһҒеӨ§еҢ–жҲҗдёәжҲ‘们з ҒеҶңиҝӣиЎҢиҪҜ件ејҖеҸ‘зҡ„з—ӣзӮ№е’ҢйҡҫзӮ№гҖӮеңЁеӨҡж ёжңҚеҠЎеҷЁдёӯпјҢйҮҮз”ЁеӨҡиҝӣзЁӢжҲ–еӨҡзәҝзЁӢжқҘ并иЎҢеӨ„зҗҶд»»еҠЎпјҢдҝЁз„¶жҲҗдёәдәҶеӨ§е®¶жҖ§иғҪи°ғдјҳзҡ„ж ҮеҮҶи§ЈеҶіж–№жЎҲгҖӮеӨҡиҝӣзЁӢ(еӨҡзәҝзЁӢ)зҡ„并иЎҢзј–зЁӢж–№ејҸпјҢеҝ…然иҰҒйқўеҜ№е…ұдә«ж•°жҚ®зҡ„и®ҝй—®й—®йўҳпјҢеҰӮдҪ•е№¶еҸ‘гҖҒй«ҳж•ҲгҖҒе®үе…Ёең°и®ҝй—®е…ұдә«ж•°жҚ®иө„жәҗпјҢжҲҗдёә并иЎҢзј–зЁӢзҡ„дёҖдёӘйҮҚзӮ№е’ҢйҡҫзӮ№гҖӮ
дј з»ҹзҡ„е…ұдә«ж•°жҚ®и®ҝй—®ж–№ејҸжҳҜйҮҮз”ЁеҗҢжӯҘеҺҹиҜӯ(дёҙз•ҢеҢәгҖҒй”ҒгҖҒжқЎд»¶еҸҳйҮҸзӯү)жқҘиҫҫеҲ°е…ұдә«ж•°жҚ®зҡ„е®үе…Ёи®ҝй—®пјҢ然иҖҢпјҢеҗҢжӯҘжҒ°жҒ°е’Ң并иЎҢзј–зЁӢжҳҜеҜ№з«Ӣзҡ„пјҢеҫҲе®№жҳ“жҲҗдёә并иЎҢзЁӢеәҸдёӯзҡ„瓶йўҲгҖӮдёҖж–№йқўпјҢжңүдәӣеҗҢжӯҘеҺҹиҜӯжҳҜж“ҚдҪңзі»з»ҹзҡ„еҶ…ж ёеҜ№иұЎпјҢи°ғз”ЁиҜҘеҺҹиҜӯдјҡеёҰжқҘжҳӮиҙөзҡ„дёҠдёӢж–ҮеҲҮжҚў(з”ЁжҲ·жҖҒеҲҮжҚўеҲ°еҶ…ж ёжҖҒ)д»Јд»·пјҢеҗҢж—¶пјҢеҶ…ж ёеҜ№иұЎжҳҜдёҖдёӘжҜ”иҫғжңүйҷҗзҡ„иө„жәҗгҖӮеҸҰдёҖж–№йқўпјҢеҗҢжӯҘжқңз»қдәҶ并иЎҢж“ҚдҪңпјҢдёҖдёӘзәҝзЁӢеңЁи®ҝй—®е…ұдә«ж•°жҚ®зҡ„ж—¶еҖҷпјҢе…¶д»–зҡ„еӨҡдёӘзәҝзЁӢеҝ…йЎ»еңЁжҺ’йҳҹз©әй—Ізӯүеҫ…пјҢеҗҢж—¶пјҢеҗҢжӯҘеҸҜжү©еұ•жҖ§еҫҲејұпјҢйҡҸзқҖ并иЎҢзәҝзЁӢзҡ„еўһеҠ пјҢеҫҲе®№жҳ“жҲҗдёәзЁӢеәҸзҡ„дёҖдёӘ瓶йўҲпјҢз”ҡиҮіеҮәзҺ°пјҢжңҚеҠЎжҖ§иғҪеҗһеҗҗйҮҸ并没йҡҸCPUж ёж•°еўһеҠ жҲ–并еҸ‘зәҝзЁӢзҡ„еўһеҠ е‘ҲзҺ°зәҝжҖ§еўһй•ҝпјҢзӣёеҸҚеҮәзҺ°дёӢйҷҚзҡ„жғ…еҶөгҖӮ
дәҺжҳҜпјҢдәә们ејҖе§Ӣз ”з©¶еҜ№е…ұдә«ж•°жҚ®иҝӣиЎҢ并еҸ‘и®ҝй—®зҡ„ж•°жҚ®з»“жһ„е’Ңз®—жі•пјҢйҖҡеёёжңүд»ҘдёӢеҮ ж–№йқўпјҡ
```
1. Transactional memory --- дәӢеҠЎжҖ§еҶ…еӯҳ
2. Fine-grained algorithms --- з»ҶзІ’еәҰ(й”Ғ)з®—жі•
3. Lock-free data structures --- ж— й”Ғж•°жҚ®з»“жһ„
```
(1) дәӢеҠЎеҶ…еӯҳпјҲTransactional memoryпјүTMжҳҜдёҖдёӘиҪҜ件жҠҖжңҜпјҢз®ҖеҢ–дәҶ并еҸ‘зЁӢеәҸзҡ„зј–еҶҷгҖӮ TMеҖҹйүҙдәҶеңЁж•°жҚ®еә“зӨҫеҢәдёӯйҰ–е…Ҳе»әз«Ӣе’ҢеҸ‘еұ•иө·жқҘзҡ„жҰӮеҝөпјҢ еҹәжң¬зҡ„жғіжі•жҳҜиҰҒз”іжҳҺдёҖдёӘд»Јз ҒеҢәеҹҹдҪңдёәдёҖдёӘдәӢеҠЎгҖӮдёҖдёӘдәӢеҠЎпјҲtransaction пјү жү§иЎҢ并еҺҹеӯҗең°жҸҗдәӨжүҖжңүз»“жһңеҲ°еҶ…еӯҳпјҲеҰӮжһңдәӢеҠЎжҲҗеҠҹпјүпјҢжҲ–дёӯжӯўе№¶еҸ–ж¶ҲжүҖжңүзҡ„з»“жһңпјҲеҰӮжһңдәӢеҠЎеӨұиҙҘпјүгҖӮ TMзҡ„е…ій”®жҳҜжҸҗдҫӣеҺҹеӯҗжҖ§пјҲAtomicityпјүпјҢдёҖиҮҙжҖ§пјҲConsistency пјүе’Ңйҡ”зҰ»жҖ§пјҲIsolation пјүиҝҷдәӣиҰҒзҙ гҖӮ дәӢеҠЎеҸҜд»Ҙе®үе…Ёең°е№¶иЎҢжү§иЎҢпјҢд»ҘеҸ–д»ЈзҺ°жңүзҡ„з—ӣиӢҰе’Ңе®№жҳ“зҠҜй”ҷиҜҜ(дёӢйқўеҮ зӮ№)зҡ„жҠҖжңҜпјҢеҰӮй”Ғе’ҢдҝЎеҸ·йҮҸгҖӮ иҝҳжңүдёҖдёӘжҪңеңЁзҡ„жҖ§иғҪдјҳеҠҝгҖӮ жҲ‘们зҹҘйҒ“й”ҒжҳҜжӮІи§Ӯзҡ„пјҲpessimistic пјүпјҢ并еҒҮи®ҫдёҠй”Ғзҡ„зәҝзЁӢе°ҶеҶҷе…Ҙж•°жҚ®пјҢеӣ жӯӨпјҢе…¶д»–зәҝзЁӢзҡ„иҝӣеұ•иў«йҳ»еЎһгҖӮ 然иҖҢи®ҝй—®й”Ғе®ҡеҖјзҡ„дёӨдёӘдәӢеҠЎеҸҜд»Ҙ并иЎҢең°иҝӣиЎҢпјҢдё”еӣһж»ҡеҸӘеҸ‘з”ҹеңЁеҪ“дәӢеҠЎд№ӢдёҖеҶҷе…Ҙж•°жҚ®зҡ„ж—¶еҖҷгҖӮдҪҶжҳҜпјҢзӣ®еүҚиҝҳжІЎжңүеөҢе…ҘејҸзҡ„дәӢеҠЎеҶ…еӯҳпјҢжҜ”иҫғйҡҫе’Ңдј з»ҹд»Јз ҒйӣҶжҲҗпјҢйңҖиҰҒиҪҜ件еҒҡеҮәжҜ”иҫғеӨ§зҡ„еҸҳеҢ–пјҢеҗҢж—¶пјҢиҪҜ件TMжҖ§иғҪејҖй”ҖжһҒеӨ§пјҢ2-10еҖҚзҡ„йҖҹеәҰдёӢйҷҚжҳҜеёёи§Ғзҡ„пјҢиҝҷд№ҹйҷҗеҲ¶дәҶиҪҜ件TMзҡ„е№ҝжіӣдҪҝз”Ё
```
1. еӣ дёәеҝҳи®°дҪҝз”Ёй”ҒиҖҢеҜјиҮҙжқЎд»¶з«һдәү(race condition)
2. еӣ дёәдёҚжӯЈзЎ®зҡ„еҠ й”ҒйЎәеәҸиҖҢеҜјиҮҙжӯ»й”Ғ(deadlock)
3. еӣ дёәжңӘиў«жҚ•жҚүзҡ„ејӮеёёиҖҢйҖ жҲҗзЁӢеәҸеҙ©жәғ(corruption)
4. еӣ дёәй”ҷиҜҜең°еҝҪз•ҘдәҶйҖҡзҹҘпјҢйҖ жҲҗзәҝзЁӢж— жі•жӯЈеёёе”ӨйҶ’(lost wakeup)
```
(2) з»ҶзІ’еәҰ(й”Ғ)з®—жі•жҳҜдёҖз§ҚеҹәдәҺеҸҰзұ»зҡ„еҗҢжӯҘж–№жі•зҡ„з®—жі•пјҢе®ғйҖҡеёёеҹәдәҺвҖңиҪ»йҮҸзә§зҡ„вҖқеҺҹеӯҗжҖ§еҺҹиҜӯ(жҜ”еҰӮиҮӘж—Ӣй”Ғ)пјҢиҖҢдёҚжҳҜеҹәдәҺзі»з»ҹжҸҗдҫӣзҡ„жҳӮиҙөж¶ҲиҖ—зҡ„еҗҢжӯҘеҺҹиҜӯгҖӮз»ҶзІ’еәҰ(й”Ғ)з®—жі•йҖӮз”ЁдәҺд»»дҪ•й”ҒжҢҒжңүж—¶й—ҙе°‘дәҺе°ҶдёҖдёӘзәҝзЁӢйҳ»еЎһе’Ңе”ӨйҶ’жүҖйңҖиҰҒзҡ„ж—¶й—ҙзҡ„еңәеҗҲпјҢз”ұдәҺй”ҒзІ’еәҰжһҒе°ҸпјҢеңЁжӯӨзұ»еҺҹиҜӯд№ӢдёҠжһ„е»әзҡ„ж•°жҚ®з»“жһ„пјҢеҸҜд»Ҙ并иЎҢиҜ»еҸ–пјҢз”ҡиҮіе№¶еҸ‘еҶҷе…ҘгҖӮLinux 4.4д»ҘеүҚзҡ„еҶ…ж ёе°ұжҳҜйҮҮз”Ё_spin_lockиҮӘж—Ӣй”Ғиҝҷз§Қз»ҶзІ’еәҰй”Ғз®—жі•жқҘе®үе…Ёи®ҝй—®е…ұдә«зҡ„listen socketпјҢеңЁе№¶еҸ‘иҝһжҺҘзӣёеҜ№иҪ»йҮҸзҡ„жғ…еҶөдёӢпјҢе…¶жҖ§иғҪе’Ңж— й”ҒжҖ§иғҪзӣёеӘІзҫҺгҖӮ然иҖҢпјҢеңЁй«ҳ并еҸ‘иҝһжҺҘзҡ„еңәжҷҜдёӢпјҢз»ҶзІ’еәҰ(й”Ғ)з®—жі•е°ұдјҡжҲҗдёә并еҸ‘зЁӢеәҸзҡ„瓶йўҲжүҖеңЁгҖӮ
(3) ж— й”Ғж•°жҚ®з»“жһ„пјҢдёәи§ЈеҶіеңЁй«ҳ并еҸ‘еңәжҷҜдёӢпјҢз»ҶзІ’еәҰй”Ғж— жі•йҒҝе…Қзҡ„жҖ§иғҪ瓶йўҲпјҢе°Ҷе…ұдә«ж•°жҚ®ж”ҫе…Ҙж— й”Ғзҡ„ж•°жҚ®з»“жһ„дёӯпјҢйҮҮз”ЁеҺҹеӯҗдҝ®ж”№зҡ„ж–№ејҸжқҘи®ҝй—®е…ұдә«ж•°жҚ®гҖӮ
зӣ®еүҚпјҢеёёи§Ғзҡ„ж— й”Ғж•°жҚ®з»“жһ„дё»иҰҒжңүпјҡж— й”ҒйҳҹеҲ—(lock free queue)гҖҒж— й”Ғе®№еҷЁ(b+treeгҖҒlistгҖҒhashmapзӯү)гҖӮ
жң¬ж–Үд»ҘдёҖдёӘж— й”ҒйҳҹеҲ—е®һзҺ°зүҮж®өдёәи“қжң¬пјҢжқҘи°Ҳи°Ҳж— й”Ғзј–зЁӢдёӯзҡ„йӮЈдәӣдәӢгҖӮдёӢйқўжҳҜдёҖдёӘејҖжәҗC++并еҸ‘ж•°жҚ®з»“жһ„libдёӯзҡ„ж— й”ҒйҳҹеҲ—зҡ„е®һзҺ°зүҮж®ө
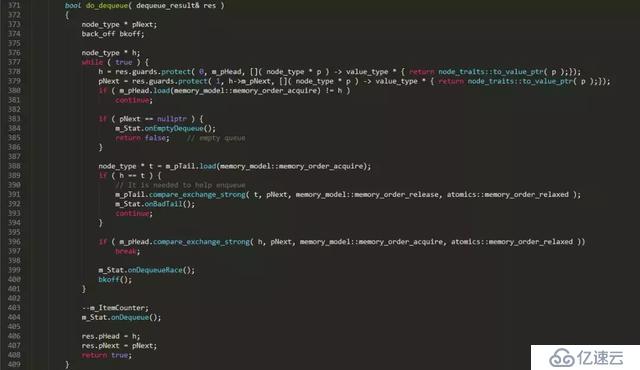
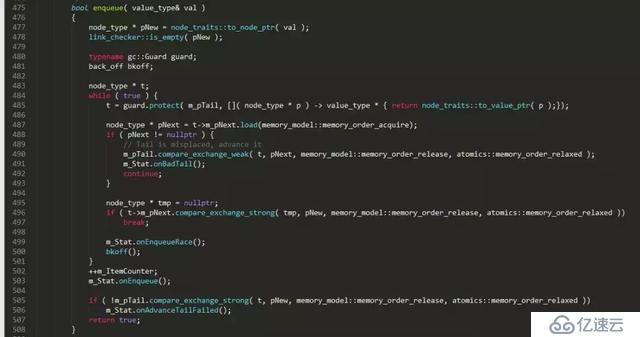
дёҠйқўжҳҜдёҖдёӘжҷ®йҖҡеҚ•еҗ‘й“ҫиЎЁйҳҹеҲ—зҡ„ж— й”Ғе®һзҺ°пјҢеҜ№жҜ”жҷ®йҖҡзҡ„й“ҫиЎЁйҳҹеҲ—е®һзҺ°пјҢж— й”Ғе®һзҺ°еӨҚжқӮдәҶеҫҲеӨҡпјҢеӨҡеҮәдәҶеҫҲеӨҡзӢ¬жңүзҡ„зү№еҫҒж“ҚдҪңпјҡ
```
1. C++11 ж ҮеҮҶзҡ„еҺҹеӯҗжҖ§ж“ҚдҪңпјҡ loadгҖҒstoreгҖҒcompare_exchange_weakгҖҒcompare_exchange_strong
2. дёҖдёӘж— йҷҗеҫӘзҺҜпјҡ while ( true ) { ... }
3. еұҖйғЁеҸҳйҮҸзҡ„е®үе…ЁжҖ§(guards)пјҡt = guard.protect( m_pTail, node_to_value() );
4. иЎҘеҒҝзӯ–з•Ҙ(functor bkoff)пјҡиҝҷдёҚжҳҜеҝ…йЎ»зҡ„пјҢдҪҶеҸҜд»ҘеңЁиҝһжҺҘеҫҲеӨҡзҡ„жғ…еҶөдёӢзј“и§ЈеӨ„зҗҶеҷЁзҡ„еҺӢеҠӣпјҢе°Өе…¶жҳҜеӨҡдёӘзәҝзЁӢйҖҗдёӘең°и°ғз”ЁйҳҹеҲ—ж—¶гҖӮ
5. helpingж–№жі•пјҡжң¬дҫӢдёӯпјҢdequeueдёӯеё®еҠ©enqueueе°Ҷm_pTailи®ҫзҪ®жӯЈзЎ®гҖӮ
// It is needed to help enqueue
m_pTail.compare_exchange_strong( t, pNext, memory_model::memory_order_release,
memory_model::memory_order_relaxed );
6. ж ҮеҮҶеҺҹеӯҗж“ҚдҪңдёӯдҪҝз”Ёзҡ„еҶ…еӯҳжЁЎеһӢ(memory model)пјҢд№ҹе°ұжҳҜеҶ…еӯҳж …ж Ҹ(еұҸйҡң)пјҡmemory_order_releaseгҖҒmemory_order_acquireзӯү
```
дёӢйқўеҲҶеҲ«и®ІдёҖдёӢдёҠйқўжҸҗеҲ°ж— й”ҒйҳҹеҲ—е®һзҺ°дёӯзҡ„6дёӘзү№еҫҒгҖӮ
2. еҺҹеӯҗжҖ§гҖҒеҺҹеӯҗжҖ§еҺҹиҜӯ
жҲ‘们зҹҘйҒ“ж— и®әжҳҜдҪ•з§Қжғ…еҶөпјҢеҸӘиҰҒжңүе…ұдә«зҡ„ең°ж–№пјҢе°ұзҰ»дёҚејҖеҗҢжӯҘпјҢд№ҹе°ұжҳҜconcurrencyгҖӮеҜ№е…ұдә«иө„жәҗзҡ„е®үе…Ёи®ҝй—®пјҢеңЁдёҚдҪҝз”Ёй”ҒгҖҒеҗҢжӯҘеҺҹиҜӯзҡ„жғ…еҶөдёӢпјҢеҸӘиғҪдҫқиө–дәҺ硬件ж”ҜжҢҒзҡ„еҺҹеӯҗжҖ§ж“ҚдҪңпјҢзҰ»ејҖеҺҹеӯҗж“ҚдҪңзҡ„дҝқиҜҒпјҢж— й”Ғзј–зЁӢ(lock-free programming)е°ҶеҸҳеҫ—дёҚеҸҜиғҪгҖӮ
з•ҷж„Ҹжң¬дҫӢзҡ„ж— й”ҒйҳҹеҲ—зҡ„е®һзҺ°дҫӢеӯҗпјҢжҲ‘们еҸ‘зҺ°еҺҹеӯҗжҖ§ж“ҚдҪңеҸҜд»Ҙз®ҖеҚ•еҲ’еҲҶдёәдёӨйғЁеҲҶпјҡ
```
1. еҺҹеӯҗжҖ§иҜ»еҶҷ(atomic read and write)пјҡжң¬дҫӢдёӯзҡ„еҺҹеӯҗload(иҜ»)гҖҒеҺҹеӯҗstore(еҶҷ)
2. еҺҹеӯҗГ—Г—Г—жҚў(Atomic Read-Modify-Write -- RMW)пјҡжң¬дҫӢдёӯзҡ„compare_exchange_weakгҖҒcompare_exchange_strong
```
еҺҹеӯҗж“ҚдҪңеҸҜи®ӨдёәжҳҜдёҖдёӘдёҚеҸҜеҲҶзҡ„ж“ҚдҪңпјӣиҰҒд№ҲеҸ‘з”ҹпјҢиҰҒд№ҲжІЎеҸ‘з”ҹпјҢжҲ‘们зңӢдёҚеҲ°д»»дҪ•жү§иЎҢзҡ„дёӯй—ҙиҝҮзЁӢпјҢдёҚеӯҳеңЁйғЁеҲҶз»“жһң(partial effects)гҖӮеҸҜд»ҘжғіиұЎзҡ„еҲ°пјҢеҺҹеӯҗж“ҚдҪңиҰҒдҝқиҜҒиҰҒд№Ҳе…ЁйғЁеҸ‘з”ҹпјҢиҰҒд№Ҳе…ЁйғЁжІЎеҸ‘з”ҹпјҢиҝҷж ·еҺҹеӯҗж“ҚдҪңз»қеҜ№дёҚжҳҜдёҖдёӘе»үд»·зҡ„ж¶ҲиҖ—дҪҺзҡ„жҢҮд»ӨпјҢзӣёеҸҚпјҢеҺҹеӯҗж“ҚдҪңжҳҜдёҖдёӘиҫғдёәжҳӮиҙөзҡ„жҢҮд»ӨгҖӮйӮЈд№ҲеңЁж— й”Ғзј–зЁӢдёӯпјҢжҲ‘们иҰҒйҒҝе…Қж»Ҙз”ЁеҺҹеӯҗж“ҚдҪңпјҢйӮЈд№Ҳд»Җд№Ҳжғ…еҶөдёӢпјҢжҲ‘们йңҖиҰҒеҜ№е…ұдә«еҸҳйҮҸзҡ„ж“ҚдҪңйҮҮз”ЁеҺҹеӯҗж“ҚдҪңе‘ўпјҹеҜ№еҸҳйҮҸзҡ„жҷ®йҖҡзҡ„иҜ»еҸ–иөӢеҖјж“ҚдҪңжҳҜеҺҹеӯҗзҡ„еҗ—пјҹ
йҖҡеёёжғ…еҶөдёӢпјҢжҲ‘们жңүдёҖдёӘеҜ№е…ұдә«еҸҳйҮҸеҝ…йЎ»дҪҝз”ЁеҺҹеӯҗж“ҚдҪңзҡ„规еҲҷпјҡ
```
д»»дҪ•ж—¶еҲ»пјҢеҸӘиҰҒеӯҳеңЁдёӨдёӘжҲ–еӨҡдёӘзәҝзЁӢ并еҸ‘ең°еҜ№еҗҢдёҖдёӘе…ұдә«еҸҳйҮҸиҝӣиЎҢж“ҚдҪңпјҢ并且иҝҷдәӣж“ҚдҪңдёӯзҡ„е…¶дёӯдёҖдёӘжҳҜжү§иЎҢдәҶеҶҷж“ҚдҪңпјҢйӮЈд№ҲжүҖжңүзҡ„зәҝзЁӢйғҪеҝ…йЎ»дҪҝз”ЁеҺҹеӯҗж“ҚдҪңгҖӮ
```
еҰӮжһңиҝқеҸҚдёҠйқўзҡ„规еҲҷпјҢеҚіеӯҳеңЁжҹҗдёӘзәҝзЁӢдҪҝз”ЁдәҶйқһеҺҹеӯҗж“ҚдҪңпјҢйӮЈд№ҲдҪ е°Ҷдјҡйҷ·е…ҘдёҖдёӘеңЁC++11ж ҮеҮҶдёӯз§°д№Ӣдёәж•°жҚ®з«һдәү(data race)пјҲиҝҷйҮҢзҡ„ж•°жҚ®з«һдәүе’ҢJavaдёӯзҡ„data raceжҰӮеҝөпјҢд»ҘеҸҠжӣҙйҖҡз”Ёзҡ„race conditionжҳҜдёҚдёҖж ·зҡ„пјүзҡ„жғ…еҪўгҖӮеҰӮжһңдҪ еј•еҸ‘дәҶж•°жҚ®з«һдәүпјҢйӮЈд№Ҳе°ұдјҡеҫ—еҲ°дёҖдёӘ"жңӘе®ҡд№үиЎҢдёәпјҲundefined behaviorпјү"зҡ„з»“жһңпјҢе®ғ们дјҡеҜјиҮҙtorn reads(ж’•иЈӮиҜ»)е’Ңtorn writes(ж’•иЈӮеҶҷ)пјҢд№ҹе°ұжҳҜдёҖдёӘйқһе®Ңж•ҙзҡ„иҜ»еҶҷгҖӮ
д»Җд№Ҳж ·зҡ„еҶ…еӯҳж“ҚдҪңжҳҜеҺҹеӯҗзҡ„е‘ўпјҹйҖҡеёёжғ…еҶөдёӢпјҢеҰӮжһңдёҖдёӘеҶ…еӯҳж“ҚдҪңдҪҝз”ЁдәҶеӨҡжқЎCPUжҢҮд»ӨпјҢйӮЈд№ҲиҝҷдёӘеҶ…еӯҳж“ҚдҪңжҳҜйқһеҺҹеӯҗзҡ„гҖӮйӮЈд№ҲеҸӘдҪҝз”ЁдёҖжқЎCPUжҢҮд»Өзҡ„еҶ…еӯҳж“ҚдҪңжҳҜдёҚжҳҜе°ұдёҖе®ҡжҳҜеҺҹеӯҗзҡ„е‘ўпјҹзӯ”жЎҲжҳҜдёҚдёҖе®ҡпјҢжҹҗдәӣд»…д»…дҪҝз”ЁдёҖжқЎCPUзҡ„еҶ…еӯҳж“ҚдҪңпјҢеңЁз»қеӨ§еӨҡж•°CPUжһ¶жһ„дёҠжҳҜеҺҹеӯҗпјҢдҪҶжҳҜпјҢеңЁдёӘеҲ«CPUжһ¶жһ„дёҠжҳҜйқһеҺҹеӯҗзҡ„гҖӮеҰӮжһңпјҢжҲ‘们жғіеҶҷеҮәеҸҜ移жӨҚзҡ„д»Јз ҒпјҢе°ұдёҚиғҪеҒҡеҮәдҪҝз”ЁдёҖжқЎCPUжҢҮд»Өзҡ„еҶ…еӯҳж“ҚдҪңдёҖе®ҡжҳҜеҺҹеӯҗзҡ„еҒҮи®ҫгҖӮ
еңЁC/C++дёӯпјҢжүҖжңүзҡ„еҶ…еӯҳж“ҚдҪңйғҪиў«еҒҮе®ҡдёәйқһеҺҹеӯҗжҖ§зҡ„пјҢеҚідҪҝжҳҜжҷ®йҖҡзҡ„32дҪҚГ—Г—Г—иөӢеҖјпјҢйҷӨйқһзј–иҜ‘еҷЁжҲ–硬件еҺӮе•Ҷжңүзү№ж®ҠиҜҙжҳҺиҝҷдёӘиөӢеҖјж“ҚдҪңжҳҜеҺҹеӯҗзҡ„гҖӮеңЁжүҖжңүзҡ„зҺ°д»Јx86пјҢx64пјҢItaniumпјҢSPARCпјҢARMе’ҢPowerPCеӨ„зҗҶеҷЁдёӯпјҢжҷ®йҖҡзҡ„32дҪҚГ—Г—Г—пјҢеҸӘиҰҒеҶ…еӯҳең°еқҖжҳҜеҜ№йҪҗзҡ„пјҢйӮЈд№ҲиөӢеҖјж“ҚдҪңе°ұжҳҜеҺҹеӯҗж“ҚдҪңпјҢиҝҷдёӘдҝқиҜҒжҳҜзү№е®ҡе№іеҸ°дёӢзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁеҒҡеҮәзҡ„дҝқиҜҒгҖӮз”ұдәҺC/C++иҜӯиЁҖж ҮеҮҶ并没еҜ№ж•ҙеһӢиөӢеҖјжҳҜеҺҹеӯҗж“ҚдҪңеҒҡеҮәдҝқиҜҒпјҢдәҺжҳҜпјҢиҰҒжғіеҶҷеҮәзңҹжӯЈеҸҜ移жӨҚзҡ„Cе’ҢC++д»Јз Ғж—¶пјҢжҲ‘们еҸӘиғҪдҪҝз”ЁC++11жҸҗдҫӣзҡ„еҺҹеӯҗеә“( C++11 atomic library)жқҘдҝқиҜҒеҜ№еҸҳйҮҸзҡ„load(иҜ»)е’Ңstore(еҶҷ)жҳҜеҺҹеӯҗзҡ„гҖӮ
2.1 дёҚиғҪдёҚиҜҙзҡ„е…ій”®еӯ—пјҡvolatile
йҖҡиҝҮдёҠйқўжҲ‘们зҹҘйҒ“пјҢеңЁзҺ°д»ЈеӨ„зҗҶеҷЁдёӯпјҢеҜ№дәҺдёҖдёӘеҜ№йҪҗзҡ„Г—Г—Г—зұ»еһӢ(Г—Г—Г—жҲ–жҢҮй’Ҳ)пјҢе…¶иҜ»еҶҷж“ҚдҪңжҳҜеҺҹеӯҗзҡ„пјҢиҖҢеҜ№дәҺзҺ°д»Јзј–иҜ‘еҷЁпјҢз”Ёvolatileдҝ®йҘ°зҡ„еҹәжң¬зұ»еһӢжӯЈзЎ®еҜ№йҪҗзҡ„дҝқйҡңпјҢ并且йҷҗеҲ¶дәҶзј–иҜ‘еҷЁеҜ№е…¶дјҳеҢ–гҖӮиҝҷж ·йҖҡиҝҮеҜ№intеҸҳйҮҸеҠ дёҠvolatileдҝ®йҘ°пјҢжҲ‘们е°ұиғҪеҜ№иҜҘеҸҳйҮҸиҝӣиЎҢеҺҹеӯҗжҖ§иҜ»еҶҷгҖӮ
```
volatile int i=10;//з”Ёvolatileдҝ®йҘ°еҸҳйҮҸi
......//something happened
int b = i;//atomic read
```
з”ұдәҺvolatile еңЁжҹҗз§ҚзЁӢеәҰдёҠйҷҗеҲ¶дәҶзј–иҜ‘еҷЁзҡ„дјҳеҢ–пјҢиҖҢеҫҲеӨҡж—¶еҖҷпјҢеҜ№дәҺеҗҢдёҖдёӘеҸҳйҮҸпјҢжҲ‘们еңЁжҹҗдәӣең°ж–№жңүеҺҹеӯҗжҖ§иҜ»еҶҷзҡ„йңҖжұӮпјҢеңЁжҹҗдәӣең°ж–№жҲ‘们еҸҲдёҚйңҖиҰҒеҺҹеӯҗжҖ§иҜ»еҶҷпјҢиҝҷдёӘж—¶еҖҷеёҢжңӣзј–иҜ‘еҷЁиҜҘдјҳеҢ–зҡ„ж—¶еҖҷе°ұдјҳеҢ–гҖӮ然иҖҢпјҢдёҚеҠ volatileдҝ®йҘ°пјҢйӮЈд№Ҳе°ұеҒҡдёҚеҲ°еүҚйқўдёҖзӮ№гҖӮеҠ дәҶvolatileпјҢеҗҺйқўиҝҷдёҖж–№йқўе°ұж— д»Һи°Ҳиө·пјҢжҖҺд№ҲеҠһпјҹе…¶е®һпјҢиҝҷйҮҢжңүдёӘе°ҸжҠҖе·§еҸҜд»ҘиҫҫеҲ°иҝҷдёӘзӣ®зҡ„пјҡ
```
int i = 2; //еҸҳйҮҸiиҝҳжҳҜдёҚз”ЁеҠ volatileдҝ®йҘ°
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
#define READ_ONCE(x) ACCESS_ONCE(x)
#define WRITE_ONCE(x, val) ({ ACCESS_ONCE(x) = (val); })
a = READ_ONCE(i);
WRITE_ONCE(i, 2);
```
йҖҡиҝҮдёҠйқўжҲ‘们зҹҘйҒ“пјҢз”Ёvolatileдҝ®йҘ°зҡ„intеңЁзҺ°д»ЈеӨ„зҗҶеҷЁдёӯпјҢиғҪеӨҹеҒҡеҲ°еҺҹеӯҗжҖ§зҡ„иҜ»еҶҷпјҢ并且йҷҗеҲ¶зј–иҜ‘еҷЁзҡ„дјҳеҢ–пјҢжҜҸж¬ЎйғҪжҳҜд»ҺеҶ…еӯҳдёӯиҜ»еҸ–жңҖж–°зҡ„еҖјпјҢеҫҲеӨҡеҗҢеӯҰе°ұиҜҜд»ҘдёәvolatileиғҪеӨҹдҝқиҜҒеҺҹеӯҗжҖ§е№¶дё”е…·жңүMemery Barrierзҡ„дҪңз”ЁгҖӮе…¶е®һvloatileж—ўдёҚиғҪдҝқиҜҒеҺҹеӯҗжҖ§пјҢд№ҹдёҚдјҡжңүд»»дҪ•зҡ„Memery Barrier(еҶ…еӯҳж …ж Ҹ)зҡ„дҝқиҜҒгҖӮдёҠйқўдҫӢеӯҗдёӯпјҢvolatileд»…д»…жҳҜдҝқиҜҒintзҡ„ең°еқҖеҜ№йҪҗпјҢиҖҢеҜ№йҪҗеҗҺзҡ„Г—Г—Г—еңЁзҺ°д»ЈеӨ„зҗҶеҷЁдёӯпјҢжҳҜиғҪеӨҹеҒҡеҲ°еҺҹеӯҗжҖ§иҜ»еҶҷзҡ„гҖӮеңЁC++дёӯvolatileе…·жңүд»ҘдёӢзү№жҖ§пјҡ
```
1. жҳ“еҸҳжҖ§пјҡжүҖи°“зҡ„жҳ“еҸҳжҖ§пјҢеңЁжұҮзј–еұӮйқўеҸҚжҳ еҮәжқҘпјҢе°ұжҳҜдёӨжқЎиҜӯеҸҘпјҢдёӢдёҖжқЎиҜӯеҸҘдёҚдјҡзӣҙжҺҘдҪҝз”ЁдёҠдёҖжқЎиҜӯеҸҘеҜ№еә”зҡ„volatileеҸҳйҮҸзҡ„еҜ„еӯҳеҷЁеҶ…е®№пјҢиҖҢжҳҜйҮҚж–°д»ҺеҶ…еӯҳдёӯиҜ»еҸ–гҖӮ
2. "дёҚеҸҜдјҳеҢ–"жҖ§пјҡvolatileе‘ҠиҜүзј–иҜ‘еҷЁпјҢдёҚиҰҒеҜ№жҲ‘иҝҷдёӘеҸҳйҮҸиҝӣиЎҢеҗ„з§ҚжҝҖиҝӣзҡ„дјҳеҢ–пјҢз”ҡиҮіе°ҶеҸҳйҮҸзӣҙжҺҘж¶ҲйҷӨпјҢдҝқиҜҒзЁӢеәҸе‘ҳеҶҷеңЁд»Јз Ғдёӯзҡ„жҢҮд»ӨпјҢдёҖе®ҡдјҡиў«жү§иЎҢгҖӮ
3. "йЎәеәҸжҖ§"пјҡиғҪеӨҹдҝқиҜҒVolatileеҸҳйҮҸй—ҙзҡ„йЎәеәҸжҖ§пјҢзј–иҜ‘еҷЁдёҚдјҡиҝӣиЎҢд№ұеәҸдјҳеҢ–гҖӮVolatileеҸҳйҮҸдёҺйқһVolatileеҸҳйҮҸзҡ„йЎәеәҸпјҢзј–иҜ‘еҷЁдёҚдҝқиҜҒйЎәеәҸпјҢеҸҜиғҪдјҡиҝӣиЎҢд№ұеәҸдјҳеҢ–гҖӮ
```
2.2 Compare-And-Swap(CAS)
еҜ№дәҺCASзӣёдҝЎеӨ§е®¶йғҪдёҚйҷҢз”ҹпјҢеңЁеӯҰжңҜеңҲпјҢcompare-and-swap (CASпјүиў«и®ӨдёәжҳҜжңҖеҹәзЎҖзҡ„дёҖз§ҚеҺҹеӯҗжҖ§RMWж“ҚдҪңпјҢе…¶дјӘд»Јз ҒеҰӮдёӢпјҡ
```
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
else
return false ;
}
```
дёҠйқўзҡ„CASиҝ”еӣһboolе‘ҠзҹҘеҺҹеӯҗГ—Г—Г—жҚўжҳҜеҗҰжҲҗеҠҹпјҢ然иҖҢеңЁжңүдәӣеә”з”ЁеңәжҷҜдёӯпјҢжҲ‘们еёҢжңӣCAS еӨұиҙҘеҗҺпјҢиғҪеӨҹиҝ”еӣһеҶ…еӯҳеҚ•е…ғдёӯзҡ„еҪ“еүҚеҖјпјҢдәҺжҳҜе°ұжңүдёҖдёӘз§°дёә valued CASзҡ„еҸҳз§ҚпјҢдјӘд»Јз ҒеҰӮдёӢпјҡ
```
int CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return nExpected ;
}
else
return *pAddr;
}
```
CASдҪңдёәжңҖеҹәзЎҖзҡ„RMWж“ҚдҪңпјҢе…¶д»–жүҖжңүRMWж“ҚдҪңйғҪеҸҜд»ҘйҖҡиҝҮCASжқҘе®һзҺ°пјҢдҫӢеҰӮ fetch-and-add(FAA)пјҢдјӘд»Јз ҒеҰӮдёӢпјҡ
```
int FAA( int * pAddr, int nIncr )
{
int ncur = *pAddr;
do {} while ( !compare_exchange( pAddr, ncur, ncur + nIncr ) ;//compare_exchangeеӨұиҙҘдјҡиҝ”еӣһеҪ“еүҚеҖјдәҺncur
return ncur ;
}
```
еңЁC++11зҡ„еҺҹеӯҗlibдёӯпјҢдё»иҰҒжңүд»ҘдёӢRMWж“ҚдҪңпјҡ
```
std::atomic<>::fetch_add()
std::atomic<>::fetch_sub()
std::atomic<>::fetch_and()
std::atomic<>::fetch_or()
std::atomic<>::fetch_xor()
std::atomic<>::exchange()
std::atomic<>::compare_exchange_strong()
std::atomic<>::compare_exchange_weak()
```
е…¶дёӯcompare_exchange_weak()е°ұжҳҜжңҖеҹәзЎҖзҡ„CASпјҢдҪҝз”Ёcompare_exchange_weak()жҲ‘们еҸҜд»Ҙе®һзҺ°е…¶д»–жүҖжңүзҡ„RMWж“ҚдҪңпјҢC++11 atomic libraryдёӯзҡ„еҺҹеӯҗRMWж“ҚдҪңжңүзӮ№е°‘пјҢдёҚиғҪж»Ўи¶іжҲ‘们е®һйҷ…йңҖжұӮпјҢжҲ‘们еҸҜд»ҘиҮӘе·ұеҠЁжүӢе®һзҺ°иҮӘе·ұйңҖиҰҒзҡ„еҺҹеӯҗRMWж“ҚдҪңгҖӮ
дҫӢеҰӮпјҡжҲ‘们йңҖиҰҒдёҖдёӘеҺҹеӯҗеҜ№еҶ…еӯҳдёӯеҖјжү§иЎҢд№ҳжі•пјҢд№ҹе°ұжҳҜ atomic fetch_multiplyпјҢе®һзҺ°дјӘд»Јз ҒеҰӮдёӢпјҡ
```
uint32_t fetch_multiply(std::atomic<uint32_t>& shared, uint32_t multiplier)
{
uint32_t oldValue = shared.load();
while (!shared.compare_exchange_weak(oldValue, oldValue * multiplier))
{
}
return oldValue;
}
```
д»ҘдёҠзҡ„еҺҹеӯҗRMWж“ҚдҪңйғҪжҳҜеҸӘиғҪеҜ№дёҖдёӘintegerеҸҳйҮҸиҝӣиЎҢеҺҹеӯҗдҝ®ж”№ж“ҚдҪңпјҢеҰӮжһңжҲ‘们жғіеҗҢж—¶еҜ№дёӨдёӘintegerеҸҳйҮҸиҝӣиЎҢеҺҹеӯҗж“ҚдҪңпјҢжҖҺд№Ҳе®һзҺ°е‘ўпјҹжҲ‘们зҹҘйҒ“C++11зҡ„еҺҹеӯҗеә“std::atomic<>жҳҜдёҖдёӘжЁЎзүҲпјҢиҝҷж ·жҲ‘们еҸҜд»Ҙз”ЁдёҖдёӘз»“жһ„дҪ“жқҘеҢ…еҗ«дёӨдёӘintegerеҸҳйҮҸпјҢжқҘеҜ№з»“жһ„дҪ“иҝӣиЎҢеҺҹеӯҗдҝ®ж”№пјҢе®һзҺ°еҰӮдёӢпјҡ
```
struct Terms
{
uint32_t x;
uint32_t y;
};
std::atomic<Terms> terms;
void atomicFibonacciStep()
{
Terms oldTerms = terms.load();
Terms newTerms;
do
{
newTerms.x = oldTerms.y;
newTerms.y = oldTerms.x + oldTerms.y;
}
while (!terms.compare_exchange_weak(oldTerms, newTerms));
}
```
еҲ°иҝҷйҮҢпјҢеҸҜиғҪеӨ§е®¶дјҡжңүз–‘й—®дәҶпјҢжҳҜдёҚжҳҜterms.compare_exchange_weak(oldTerms, newTerms)еңЁеҶ…йғЁеҠ дәҶй”ҒпјҢиҰҒдёҚжҖҺд№ҲиғҪеӨҹеҺҹеӯҗдҝ®ж”№е‘ўпјҹ
C++11зҡ„еҺҹеӯҗеә“std::atomic<> templateеҸҜд»ҘжҳҜд»»дҪ•зұ»еһӢ(intгҖҒboolзӯүbuil-in typeпјҢжҲ–user-defined type)пјҢдҪҶ并дёҚжҳҜжүҖжңүзҡ„зұ»еһӢзҡ„еҺҹеӯҗж“ҚдҪңжҳҜlock-freeзҡ„гҖӮC++11 ж ҮеҮҶеә“ std::atomic жҸҗдҫӣдәҶй’ҲеҜ№Г—Г—Г—(integral)е’ҢжҢҮй’Ҳзұ»еһӢзҡ„зү№еҢ–е®һзҺ°пјҢе…¶дёӯ integal д»ЈиЎЁдәҶеҰӮдёӢзұ»еһӢchar, signed char, unsigned char, short, unsigned short, int, unsigned int, long, unsigned long, long long, unsigned long long, char16_t, char32_t, wchar_tпјҢиҝҷдәӣзү№еҢ–е®һзҺ°пјҢйғҪеҢ…еҗ«дәҶдёҖдёӘis_lock_free()жҲҗе‘ҳжқҘз”ЁдәҺеҲӨж–ӯиҜҘеҺҹеӯҗзұ»еһӢжҳҜеҺҹеӯҗж“ҚдҪңжҳҜеҗҰжҳҜlock-freeзҡ„гҖӮ
дёҠйқўзҡ„дҫӢеӯҗдёӯпјҢеңЁX64е№іеҸ°дёӢпјҢз”ЁGCC4.9.2зј–иҜ‘еҮәжқҘзҡ„д»Јз Ғterms.compare_exchange_weak(oldTerms, newTerms)жҳҜlock-freeзҡ„пјҢеңЁе…¶д»–е№іеҸ°дёӢе°ұдёҚиғҪдҝқиҜҒдәҶгҖӮеңЁе®һйҷ…еә”з”ЁдёӯпјҢйҖҡеёёжғ…еҶөдёӢпјҢеҗҢж—¶ж»Ўи¶ід»ҘдёӢжқЎд»¶зҡ„еҺҹеӯҗзұ»зҡ„еҺҹеӯҗж“ҚдҪңжүҚиғҪеҒҡеҮәжҳҜlock-freeзҡ„дҝқиҜҒпјҡ
```
1. The compiler is a recent version MSVC, GCC or Clang.
2. The target processor is x86, x64 or ARMv7 (and possibly others).
3. The atomic type is std::atomic<uint32_t>, std::atomic<uint64_t> or std::atomic<T*> for some type T.
```
2.3 Weak and Strong CAS
зӣёдҝЎеӨ§е®¶зңӢеҲ°C++11зҡ„CASж“ҚдҪңжңүдёӨдёӘcompare_exchange_weakе’Ңcompare_exchange_strongпјҢCASжҖҺд№Ҳиҝҳжңүејәејұд№ӢеҲҶе‘ўпјҹзҺ°д»ЈеӨ„зҗҶеҷЁжһ¶жһ„еҜ№CASзҡ„е®һзҺ°еҲҶжҲҗдёӨеӨ§йҳөиҗҘпјҡ(1)е®һзҺ°дәҶеҺҹеӯҗжҖ§CASеҺҹиҜӯ -- X86гҖҒIntel ItaniumгҖҒSparcзӯүеӨ„зҗҶеҷЁжһ¶жһ„пјҢжңҖж—©е®һзҺ°дәҺIBM System 370гҖӮ(2)е®һзҺ°LL/SCеҜ№(load-linked/store-conditional) -- PowerPC, MIPS, Alpha, ARM зӯүеӨ„зҗҶеҷЁжһ¶жһ„пјҢжңҖж—©е®һзҺ°дәҺDECпјҢйҖҡиҝҮLL/SCеҜ№еҸҜд»Ҙе®һзҺ°еҺҹеӯҗжҖ§CASпјҢдҪҶеңЁдёҖдәӣжғ…еҶөдёӢе®ғ并дёҚе…·жңүеҺҹеӯҗжҖ§гҖӮдёәд»Җд№ҲдјҡеӯҳеңЁLL/SCеҜ№зҡ„дҪҝз”ЁпјҢиҖҢдёҚзӣҙжҺҘе®һзҺ°CASеҺҹиҜӯе‘ўпјҹиҰҒиҜҙжҳҺLL/SCеҜ№еӯҳеңЁзҡ„еҺҹеӣ пјҢдёҚеҫ—дёҚиҜҙдёҖдёӢж— й”Ғзј–зЁӢдёӯзҡ„дёҖдёӘжЈҳжүӢй—®йўҳпјҡABAй—®йўҳгҖӮ
2.3.1 ABAй—®йўҳ
дёӢйқўж— й”Ғе Ҷж Ҳзҡ„е®һзҺ°зүҮж®өпјҡ
```
// Shared variables
static NodeType * Top = NULL; // Initially null
Push(NodeType * node) {
do {
/*Push2*/ NodeType * t = Top;
/*Push3*/ node->Next = t;
/*Push4*/ } while ( !CAS(&Top,t,node) );
}
NodeType * Pop() {
Node * next ;
do {
/*Pop1*/ NodeType * t = Top;
/*Pop2*/ if ( t == null )
/*Pop3*/ return null;
/*Pop4*/ next = t->Next;
/*Pop5*/ } while ( !CAS(&Top,t,next) );
/*Pop6*/ return t;
}
```
еҒҮи®ҫеҪ“еүҚе Ҷж Ҳжңү4дёӘжҲҗе‘ҳжҳҜпјҡA-->B-->C-->DпјҢAдҪҚдәҺж ҲйЎ¶гҖӮдёӢйқўзҡ„дёҖдёӘжү§иЎҢж—¶еәҸдјҡеҜјиҮҙдёҖдёӘж Ҳиў«з ҙеқҸзҡ„ABAй—®йўҳпјҡ
```
1. Thread Xжү§иЎҢPop()ж“ҚдҪңпјҢ并еңЁжү§иЎҢе®Ң/*Pop4*/иҝҷиЎҢд»Јз ҒеҗҺThread Xиў«еҲҮеҮәеҺ»пјҢиҝҷдёӘж—¶еҖҷеҜ№дәҺThread XжқҘиҜҙпјҢ t == Aпјӣ next == A->next == BпјӣTop == AпјӣеҪ“еүҚж ҲпјҡA-->B-->C-->D
2. Thread Y жү§иЎҢNodeType * pTop=Pop()ж“ҚдҪңпјҢжҺҘзқҖеҸҲжү§иЎҢPop(),жңҖеҗҺжү§иЎҢPush(pTop)гҖӮиҝҷдёӘж—¶еҖҷеҪ“еүҚж ҲеҸҳжҲҗдәҶпјҡA-->C-->DгҖӮ
3. иҝҷдёӘж—¶еҖҷThread Xиў«и°ғеәҰжү§иЎҢ/*Pop5*/иҝҷиЎҢд»Јз ҒпјҢз”ұдәҺж ҲйЎ¶е…ғзҙ дҫқ然жҳҜAпјҢдәҺжҳҜCAS(&Top,t,next)жү§иЎҢжҲҗеҠҹпјҢTopеҸҳжҲҗжҢҮеҗ‘дәҶBпјҢж ҲйЎ¶жҢҮй’ҲжҢҮеҗ‘дәҶдёҖдёӘе·Із»ҸдёҚеҶҚж Ҳдёӯзҡ„е…ғзҙ BпјҢж•ҙдёӘж Ҳиў«з ҙеқҸдәҶгҖӮ
```
йҖҡиҝҮиҝҷдёӘдҫӢеӯҗпјҢжҲ‘们зҹҘйҒ“ABAй—®йўҳжҳҜжүҖжңүеҹәдәҺCASзҡ„ж— й”Ғе®№еҷЁзҡ„дёҖдёӘзҒҫйҡҫй—®йўҳпјҢиҰҒи§ЈеҶіABAй—®йўҳжңүдёӨдёӘжҖқи·Ҝпјҡ
```
1. дёҚиҰҒйҮҚз”Ёе®№еҷЁдёӯзҡ„е…ғзҙ пјҢжң¬дҫӢдёӯпјҢPopеҮәжқҘзҡ„AдёҚиҰҒзӣҙжҺҘPushиҝӣе®№еҷЁпјҢеә”иҜҘnewдёҖдёӘж–°зҡ„е…ғзҙ A_nеҮәжқҘ然еҗҺеңЁpushиҝӣе®№еҷЁдёӯгҖӮеҪ“然newдёҖдёӘж–°зҡ„е…ғзҙ д№ҹдёҚз»қеҜ№е®үе…ЁпјҢеҰӮжһңжҳҜAе…Ҳиў«deleteдәҶпјҢжҺҘзқҖи°ғз”ЁnewжқҘnewдёҖдёӘж–°зҡ„е…ғзҙ жңүеҸҜиғҪдјҡиҝ”еӣһAзҡ„ең°еқҖпјҢиҝҷж ·иҝҳжҳҜеӯҳеңЁABAзҡ„йЈҺйҷ©гҖӮдёҖиҲ¬еҜ№дәҺж— й”Ғзј–зЁӢдёӯзҡ„еҶ…еӯҳеӣһ收йҮҮ用延иҝҹеӣһ收зҡ„ж–№ејҸпјҢеңЁзЎ®дҝқиў«еӣһ收еҶ…еӯҳжІЎжңүиў«е…¶д»–зәҝзЁӢдҪҝз”Ёзҡ„жғ…еҶөдёӢе®үе…Ёеӣһ收еҶ…еӯҳгҖӮ
2. е…Ғи®ёеҶ…еӯҳйҮҚз”ЁпјҢеҜ№жҢҮеҗ‘зҡ„еҶ…еӯҳйҮҮз”Ёж ҮзӯҫжҢҮй’Ҳ(Tagged Pointers)зҡ„ж–№ејҸпјҢж ҮзӯҫдҪңдёәдёҖдёӘзүҲжң¬еҸ·пјҢйҡҸзқҖж ҮзӯҫжҢҮй’ҲдёҠзҡ„жҜҸдёҖж¬ЎCASиҝҗз®—иҖҢеўһеҠ пјҢ并且еҸӘеўһдёҚеҮҸгҖӮжң¬дҫӢдёӯпјҢеҰӮжһңйҮҮз”Ёж ҮзӯҫжҢҮй’Ҳж–№ејҸпјҢTread Xзҡ„tжҢҮеҗ‘Topзҡ„ж—¶еҖҷTopзҡ„ж ҮзӯҫдёәT1пјҢиҝҷдёӘж—¶еҖҷt == A并且ж ҮзӯҫжҳҜT1гҖӮйҡҸеҗҺTread Yжү§иЎҢPop()пјҢPop()пјҢPush(),TopиҮіе°‘иҝӣиҝҮдәҶ3ж¬ЎCASпјҢж ҮзӯҫеҸҳжҲҗдәҶT1+3пјҢдәҺжҳҜTop == A并且ж ҮзӯҫжҳҜT1+3пјҢиҝҷж ·еңЁThread Xиў«и°ғеәҰжү§иЎҢ/*Pop5*/иҝҷиЎҢд»Јз Ғзҡ„ж—¶еҖҷпјҢиҷҪ然t == Top == AпјҢдҪҶжҳҜж ҮзӯҫдёҚдёҖж ·пјҢдәҺжҳҜCASдјҡеӨұиҙҘпјҢиҝҷж ·ж Ҳе°ұдёҚдјҡиў«з ҙеқҸдәҶгҖӮ
```
2.3.2 Load-Linked / Store-Conditional -- LL/SCеҜ№
йҖҡиҝҮдёҠйқўжҲ‘们зҹҘйҒ“пјҢABAй—®йўҳзҡ„жң¬иҙЁеңЁдәҺпјҢCASиҝӣиЎҢжҜ”иҫғзҡ„жҳҜжҢҮй’ҲжҢҮеҗ‘зҡ„еҶ…еӯҳең°еқҖпјҢиҷҪ然еңЁ/*Pop1*/иЎҢиҜ»еҸ–TopжҢҮеҗ‘зҡ„еҶ…еӯҳең°еқҖпјҢеҲ°/*Pop5*/иЎҢзҡ„CASпјҢtе’ҢTopйғҪжҳҜжҢҮеҗ‘Aзҡ„еҶ…еӯҳең°еқҖпјҢдҪҶжҳҜAеҶ…еӯҳйҮҢйқўзҡ„еҶ…е®№е·Із»ҸеҸ‘з”ҹиҝҮеҸҳеҢ–дәҶ(Aзҡ„nextеҸҳжҲҗдәҶC)гҖӮеҰӮжһңеӨ„зҗҶеҷЁиғҪеӨҹж„ҹзҹҘеҫ—еҲ°еңЁиҝӣиЎҢCASзҡ„еҶ…еӯҳең°еқҖзҡ„еҶ…еҰӮеҸ‘з”ҹдәҶеҸҳеҢ–пјҢи®©CASеӨұиҙҘзҡ„иҜқпјҢйӮЈд№Ҳе°ұиғҪд»ҺжәҗеӨҙдёҠи§ЈеҶіABAй—®йўҳгҖӮдәҺжҳҜPowerPC, MIPS, Alpha, ARM зӯүеӨ„зҗҶеҷЁжһ¶жһ„зҡ„ејҖеҸ‘дәәе‘ҳжүҫеҲ°дәҶload-linkedгҖҒstore-conditional (LL/SC) иҝҷж ·зҡ„ж“ҚдҪңеҜ№жқҘеҪ»еә•и§ЈеҶіABAй—®йўҳпјҢдјӘд»Јз ҒеҰӮдёӢпјҡ
```
word LL( word * pAddr ) {
return *pAddr ;
}
bool SC( word * pAddr, word New ) {
if ( data in pAddr has not been changed since the LL call) {
*pAddr = New ;
return true ;
}
else
return false ;
}
```
LL/SCеҜ№д»ҘжӢ¬еҸ·иҝҗз®—з¬Ұзҡ„еҪўејҸиҝҗиЎҢпјҢLoad-linkedпјҲLLпјү иҝҗз®—д»…д»…иҝ”еӣһ pAddr ең°еқҖзҡ„еҪ“еүҚеҸҳйҮҸеҖјгҖӮеҰӮжһң pAddr дёӯзҡ„еҶ…еӯҳж•°жҚ®еңЁиҜ»еҸ–д№ӢеҗҺжІЎжңүеҸҳеҢ–пјҢйӮЈд№Ҳ Store-conditionalпјҲSCпјүж“ҚдҪңе°ҶдјҡжҲҗеҠҹпјҢе®ғе°ҶLLиҜ»еҸ– pAddr ең°еқҖзҡ„еӯҳеӮЁж–°зҡ„еҖјпјҢеҗҰеҲҷпјҢSCе°Ҷжү§иЎҢеӨұиҙҘгҖӮиҝҷйҮҢзҡ„pAddrдёӯзҡ„еҶ…еӯҳж•°жҚ®жҳҜеҗҰеҸҳеҢ–жҢҮзҡ„жҳҜpAddrең°еқҖжүҖеңЁзҡ„Cache LineжҳҜеҗҰеҸ‘з”ҹеҸҳеҢ–гҖӮеңЁе®һзҺ°дёҠпјҢеӨ„зҗҶеҷЁејҖеҸ‘иҖ…з»ҷжҜҸдёӘCahce Lineж·»еҠ йўқеӨ–зҡ„жҜ”зү№зҠ¶жҖҒеҖјпјҲstatus bitпјүгҖӮдёҖж—ҰLLжү§иЎҢиҜ»иҝҗз®—пјҢе°ұдјҡе…іиҒ”жӯӨжҜ”зү№еҖјгҖӮд»»дҪ•зҡ„зј“еӯҳиЎҢдёҖж—ҰжңүеҶҷе…ҘпјҢжӯӨжҜ”зү№еҖје°ұдјҡиў«йҮҚзҪ®пјӣеңЁеӯҳеӮЁд№ӢеүҚпјҢSCж“ҚдҪңдјҡжЈҖжҹҘжӯӨжҜ”зү№еҖјжҳҜеҗҰй’ҲеҜ№зү№е®ҡзҡ„зј“еӯҳиЎҢгҖӮеҰӮжһңжҜ”зү№еҖјдёә1пјҢж„Ҹе‘ізқҖзј“еӯҳиЎҢжІЎжңүд»»дҪ•ж”№еҸҳпјҢpAddr ең°еқҖдёӯзҡ„еҖјдјҡеҸҳжӣҙдёәж–°еҖјпјҢSCж“ҚдҪңжҲҗеҠҹгҖӮеҗҰеҲҷжң¬ж“ҚдҪңе°ұдјҡеӨұиҙҘпјҢpAddr ең°еқҖдёӯзҡ„еҖјдёҚдјҡеҸҳжӣҙдёәж–°еҖјгҖӮ
CASйҖҡиҝҮLL/SCеҜ№еҫ—д»Ҙе®һзҺ°пјҢдјӘд»Јз ҒеҰӮдёӢпјҡ
```
bool CAS( word * pAddr, word nExpected, word nNew ) {
if ( LL( pAddr ) == nExpected )
return SC( pAddr, nNew ) ;
return false ;
}
```
еҸҜд»ҘзңӢеҲ°йҖҡиҝҮLL/SCеҜ№е®һзҺ°зҡ„CAS并дёҚжҳҜдёҖдёӘеҺҹеӯҗжҖ§ж“ҚдҪңпјҢдҪҶжҳҜе®ғзЎ®е®һжү§иЎҢдәҶеҺҹеӯҗжҖ§зҡ„CASпјҢзӣ®ж ҮеҶ…еӯҳеҚ•е…ғеҶ…е®№иҰҒд№ҲдёҚеҸҳпјҢиҰҒд№ҲеҸ‘з”ҹеҺҹеӯҗжҖ§еҸҳеҢ–гҖӮз”ұдәҺйҖҡиҝҮLL/SCеҜ№е®һзҺ°зҡ„CAS并дёҚжҳҜдёҖдёӘеҺҹеӯҗжҖ§ж“ҚдҪңпјҢдәҺжҳҜпјҢиҜҘCASеңЁжү§иЎҢиҝҮзЁӢдёӯпјҢеҸҜиғҪдјҡиў«дёӯж–ӯпјҢдҫӢеҰӮпјҡзәҝзЁӢXеңЁжү§иЎҢLLиЎҢеҗҺпјҢOSеҶіе®ҡе°ҶXи°ғеәҰеҮәеҺ»пјҢзӯүOSйҮҚж–°и°ғеәҰжҒўеӨҚXд№ӢеҗҺпјҢSCе°ҶдёҚеҶҚе“Қеә”пјҢиҝҷж—¶CASе°Ҷиҝ”еӣһfalseпјҢCASеӨұиҙҘзҡ„еҺҹеӣ дёҚеңЁж•°жҚ®жң¬иә«(ж•°жҚ®жІЎеҸҳеҢ–)пјҢиҖҢжҳҜе…¶д»–еӨ–йғЁдәӢ件(зәҝзЁӢиў«дёӯж–ӯдәҶ)гҖӮ
жӯЈжҳҜеӣ дёәеҰӮжӯӨпјҢC++11ж ҮеҮҶдёӯж·»е…ҘдёӨдёӘcompare_exchangeеҺҹиҜӯ-ејұзҡ„е’Ңејәзҡ„гҖӮд№ҹеӣ жӯӨиҝҷдёӨеҺҹиҜӯеҲҶеҲ«иў«е‘ҪеҗҚдёәcompare_exchange_weakе’Ңcompare_exchange_strongгҖӮеҚідҪҝеҪ“еүҚзҡ„еҸҳйҮҸеҖјзӯүдәҺйў„жңҹеҖјпјҢиҝҷдёӘејұзҡ„зүҲжң¬д№ҹеҸҜиғҪеӨұиҙҘпјҢжҜ”еҰӮиҝ”еӣһfalseгҖӮеҸҜи§Ғд»»дҪ•weak CASйғҪиғҪз ҙеқҸCASиҜӯд№үпјҢ并иҝ”еӣһfalseпјҢиҖҢе®ғжң¬еә”иҝ”еӣһtrueгҖӮиҖҢStrong CASдјҡдёҘж јйҒөеҫӘCASиҜӯд№үгҖӮ
йӮЈд№ҲпјҢдҪ•з§Қжғ…еҪўдёӢдҪҝз”ЁWeak CASпјҢдҪ•з§Қжғ…еҪўдёӢдҪҝз”ЁStrong CASе‘ўпјҹйҖҡеёёжү§иЎҢд»ҘдёӢеҺҹеҲҷпјҡ
```
еҖҳиӢҘCASеңЁеҫӘзҺҜдёӯпјҲиҝҷжҳҜдёҖз§Қеҹәжң¬зҡ„CASеә”з”ЁжЁЎејҸпјүпјҢеҫӘзҺҜдёӯдёҚеӯҳеңЁжҲҗеҚғдёҠдёҮзҡ„иҝҗз®—пјҲеҫӘзҺҜдҪ“жҳҜиҪ»йҮҸзә§е’Ңз®ҖеҚ•зҡ„,жң¬дҫӢзҡ„ж— й”Ғе Ҷж ҲпјүпјҢдҪҝз”Ёcompare_exchange_weakгҖӮеҗҰеҲҷпјҢйҮҮз”Ёејәзұ»еһӢзҡ„compare_exchange_strongгҖӮ
```
2.3.3 False sharing(дјӘе…ұдә«)
зҺ°д»ЈеӨ„зҗҶеҷЁдёӯпјҢcacheжҳҜд»Ҙcache lineдёәеҚ•дҪҚзҡ„пјҢдёҖдёӘcache lineй•ҝеәҰLдёә64-128еӯ—иҠӮпјҢ并且cache lineе‘ҲзҺ°й•ҝеәҰиҝӣдёҖжӯҘеўһеҠ зҡ„и¶ӢеҠҝгҖӮдё»еӯҳеӮЁе’Ңcacheж•°жҚ®дәӨжҚўеңЁ L еӯ—иҠӮеӨ§е°Ҹзҡ„ L еқ—дёӯиҝӣиЎҢпјҢеҚідҪҝзј“еӯҳиЎҢдёӯзҡ„дёҖдёӘеӯ—иҠӮеҸ‘з”ҹеҸҳеҢ–пјҢжүҖжңүиЎҢйғҪиў«и§Ҷдёәж— ж•ҲпјҢеҝ…йңҖе’Ңдё»еӯҳиҝӣиЎҢеҗҢжӯҘгҖӮеӯҳеңЁиҝҷд№ҲдёҖдёӘеңәжҷҜпјҢжңүдёӨдёӘеҸҳйҮҸshare_1е’Ңshare_2пјҢдёӨдёӘеҸҳйҮҸеҶ…еӯҳең°еқҖжҜ”иҫғзӣёиҝ‘иў«еҠ иҪҪеҲ°еҗҢдёҖcahe lineдёӯпјҢcpu core1 еҜ№еҸҳйҮҸshare_1иҝӣиЎҢж“ҚдҪңпјҢcpu core2еҜ№еҸҳйҮҸshare_2иҝӣиЎҢж“ҚдҪңпјҢд»Һcpu core2зҡ„и§’еәҰзңӢпјҢcpu core1еҜ№share_1зҡ„дҝ®ж”№пјҢдјҡдҪҝеҫ—cpu core2зҡ„cahe lineдёӯзҡ„share_2ж— ж•ҲпјҢиҝҷз§ҚеңәжҷҜеҸ«еҒҡFalse sharing(дјӘе…ұдә«)гҖӮ
з”ұдәҺLL/SCеҜ№жҜ”иҫғдҫқиө–дәҺcache lineпјҢеҪ“еҮәзҺ°False sharingзҡ„ж—¶еҖҷеҸҜиғҪдјҡйҖ жҲҗжҜ”иҫғеӨ§зҡ„жҖ§иғҪжҚҹеӨұгҖӮеҠ иҪҪиҝһжҺҘпјҲLLпјүж“ҚдҪңиҝһжҺҘзј“еӯҳиЎҢпјҢиҖҢеӯҳеӮЁзҠ¶жҖҒпјҲSC)пјүж“ҚдҪңеңЁеҶҷд№ӢеүҚпјҢдјҡжЈҖжҹҘжң¬иЎҢдёӯзҡ„иҝһжҺҘж Үеҝ—жҳҜеҗҰиў«йҮҚзҪ®гҖӮеҰӮжһңж Үеҝ—иў«йҮҚзҪ®пјҢеҶҷе°ұж— жі•жү§иЎҢпјҢSCиҝ”еӣһ falseгҖӮиҖғиҷ‘еҲ°cache lineжҜ”иҫғй•ҝпјҢеңЁеӨҡж ёcpuдёӯпјҢcpu core1еңЁдёҖдёӘwhileеҫӘзҺҜдёӯеҸҳйҮҸshare_1жү§иЎҢCASдҝ®ж”№пјҢиҖҢе…¶д»–cpu coreiеңЁеҜ№еҗҢдёҖcache lineдёӯзҡ„еҸҳйҮҸshare_iиҝӣиЎҢдҝ®ж”№гҖӮеңЁжһҒз«Ҝжғ…еҶөдёӢдјҡеҮәзҺ°иҝҷж ·зҡ„дёҖдёӘlivelock(жҙ»й”Ғ)зҺ°иұЎпјҡжҜҸж¬Ўcpu core1еңЁLL(share_1)еҗҺпјҢеңЁеҮҶеӨҮиҝӣиЎҢSCзҡ„ж—¶еҖҷпјҢе…¶д»–cpu coreдҝ®ж”№дәҶеҗҢдёҖcache lineзҡ„е…¶д»–еҸҳйҮҸshare_iпјҢиҝҷж ·дҪҝеҫ—cache lineеҸ‘з”ҹдәҶж”№еҸҳпјҢSCиҝ”еӣһfalseпјҢдәҺжҳҜcpu core1еҸҲиҝӣе…ҘдёӢдёҖдёӘCASеҫӘзҺҜпјҢиҖғиҷ‘еҲ°cache lineжҜ”иҫғй•ҝпјҢcache lineзҡ„д»»дҪ•еҸҳжӣҙйғҪдјҡеҜјиҮҙSCиҝ”еӣһfalseпјҢиҝҷж ·дҪҝеҫ—cup core1еңЁдёҖж®өж—¶й—ҙеҶ…дёҖзӣҙеңЁиҝӣиЎҢдёҖдёӘCASеҫӘзҺҜпјҢcpu core1йғҪи·‘еҲ°100%дәҶпјҢдҪҶжҳҜе®һйҷ…дёҠжІЎеҒҡд»Җд№Ҳжңүз”ЁеҠҹгҖӮ
дёәдәҶжқңз»қиҝҷж ·зҡ„False sharingжғ…еҶөпјҢжҲ‘们еә”иҜҘдҪҝеҫ—дёҚеҗҢзҡ„е…ұдә«еҸҳйҮҸеӨ„дәҺдёҚеҗҢcache lineдёӯпјҢдёҖиҲ¬жғ…еҶөдёӢпјҢеҰӮжһңеҸҳйҮҸзҡ„еҶ…еӯҳең°еқҖзӣёе·®дҪҸеӨҹиҝңпјҢйӮЈд№Ҳе°ұдјҡеӨ„дәҺдёҚеҗҢзҡ„cache lineпјҢдәҺжҳҜжҲ‘们еҸҜд»ҘйҮҮз”ЁеЎ«е……пјҲpaddingпјүжқҘйҡ”зҰ»дёҚеҗҢе…ұдә«еҸҳйҮҸпјҢеҰӮдёӢпјҡ
```
struct Foo {
int volatile nShared1;
char _padding1[64]; // padding for cache line=64 byte
int volatile nShared2;
char _padding2[64]; // padding for cache line=64 byte
};
```
дёҠйқўпјҢnShared1е’ҢnShared2е°ұдјҡеӨ„дәҺдёҚеҗҢзҡ„cache lineпјҢcpu core1еҜ№nShared1зҡ„CASж“ҚдҪңе°ұдёҚдјҡиў«е…¶д»–coreеҜ№nShared2зҡ„дҝ®ж”№жүҖеҪұе“ҚдәҶгҖӮ
дёҠйқўжҸҗеҲ°зҡ„cpu core1еҜ№share_1зҡ„дҝ®ж”№дјҡдҪҝеҫ—cpu core2зҡ„share_2еҸҳйҮҸзҡ„cache lineеӨұж•ҲпјҢйҖ жҲҗcpu core2йңҖйҮҚж–°еҠ иҪҪеҗҢжӯҘshare_2пјӣеҗҢж ·пјҢcpu core2еҜ№share_2еҸҳйҮҸзҡ„дҝ®ж”№пјҢд№ҹдјҡдҪҝеҫ—cpu core1жүҖеңЁзҡ„cache lineе®һзҺ°пјҢйҖ жҲҗcpu core1йңҖиҰҒйҮҚж–°еҠ иҪҪеҗҢжӯҘshare_1гҖӮиҝҷж ·cpu core1зҡ„дёҖдёӘдҝ®ж”№йҖ жҲҗcpu core2зҡ„дёҖдёӘcache missпјҢcpu core2зҡ„дёҖдёӘдҝ®ж”№йҖ жҲҗcpu core1зҡ„дёҖдёӘcache missзҡ„еҸҚеӨҚзҺ°иұЎе°ұжҳҜжүҖи°“зҡ„Cache ping-pongй—®йўҳпјҢеҮәзҺ°еӨ§йҮҸCache ping-pongж„Ҹе‘ізқҖеӨ§йҮҸзҡ„cache missпјҢдјҡйҖ жҲҗе·ЁеӨ§зҡ„жҖ§иғҪжҚҹеӨұгҖӮжҲ‘们еҗҢж ·еҸҜд»ҘйҮҮз”ЁеЎ«е……пјҲpaddingпјүжқҘйҡ”зҰ»дёҚеҗҢе…ұдә«еҸҳйҮҸжқҘи§ЈеҶіcache ping-pongгҖӮ
3 еұҖйғЁеҸҳйҮҸзҡ„е®үе…ЁжҖ§
йҖҡиҝҮдёҠйқўпјҢжҲ‘们зҹҘйҒ“е®һзҺ°ж— й”Ғж•°жҚ®з»“жһ„еңЁеҶ…еӯҳдҪҝз”ЁдёҠеӯҳеңЁдёӨдёӘжЈҳжүӢзҡ„й—®йўҳпјҡдёҖжҳҜABAй—®йўҳпјҢдәҢжҳҜеҶ…еӯҳе®үе…Ёеӣһ收问йўҳгҖӮиҝҷдёӨдёӘй—®йўҳд№Ӣй—ҙиҒ”зі»жҜ”иҫғеҜҶеҲҮпјҢдҪҶжҳҜйІңжңүдёӨе…Ёе…¶зҫҺзҡ„еҠһжі•пјҢеҗҢж—¶и§ЈеҶіиҝҷдёӨеӨ§йҡҫйўҳпјҢйҖҡеёёйҮҮз”Ёеҗ„дёӘеҮ»з ҙпјҢеҲҶеҲ«дәҲд»Ҙи§ЈеҶігҖӮ
жңүз§Қд»Һж №жәҗдёҠи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„ж–№жі•пјҢйӮЈе°ұжҳҜдёҚдә§з”ҹиҝҷдёӨдёӘй—®йўҳпјҢеҜ№дәҺж— й”ҒйҳҹеҲ—жқҘиҜҙпјҢжҲ‘们еҸҜд»Ҙе®һзҺ°дёҖдёӘе®ҡй•ҝж— й”ҒйҳҹеҲ—пјҢйҳҹеҲ—еңЁеҲқе§ӢеҢ–зҡ„ж—¶еҖҷзЎ®е®ҡеҘҪйҳҹеҲ—зҡ„еӨ§е°ҸnпјҢиҝҷж ·дёҖж¬ЎжҖ§еҲҶй…ҚеҘҪжүҖйңҖзҡ„еҶ…еӯҳ(n * sizeof(node))гҖӮ
е®ҡй•ҝж— й”ҒйҳҹеҲ—е°ҶдёҖеқ—иҝһз»ӯзҡ„еҶ…еӯҳеҲҶеүІжҲҗnдёӘе°ҸеҶ…еӯҳеқ—blockпјҢжҜҸдёӘеҶ…еӯҳеқ—blockеҸҜд»ҘеӯҳеӮЁдёҖдёӘйҳҹеҲ—node(еҪ“然еңЁйҳҹеҲ—nodeиҝҮеӨ§зҡ„жғ…еҶөдёӢпјҢеҸҜд»Ҙз”Ёиҝһз»ӯзҡ„еҮ дёӘеҶ…еӯҳеқ—жқҘеӯҳеӮЁдёҖдёӘйҳҹеҲ—node)гҖӮйҖҡиҝҮheadе’ҢtailдёӨдёӘжҢҮй’ҲжқҘиҝӣиЎҢйҳҹеҲ—nodeзҡ„е…Ҙйҳҹе’ҢеҮәйҳҹпјҢд»ҺheadеҲ°tailжҳҜе·Із»Ҹиў«дҪҝз”Ёзҡ„еҶ…еӯҳblock(иў«е·Іе…Ҙйҳҹзҡ„йҳҹеҲ—nodeеҚ з”Ё)пјҢд»ҺtailеҲ°headд№Ӣй—ҙжҳҜз©әй—ІеҶ…еӯҳblockгҖӮе…Ҙйҳҹзҡ„ж—¶еҖҷпјҢйҰ–е…ҲеҺҹеӯҗдҝ®ж”№tailжҢҮй’Ҳ(tailжҢҮй’Ҳеҗ‘еҗҺ移еҠЁиӢҘе№Іblock)пјҢеҚ жҚ®йңҖиҰҒдҪҝз”Ёзҡ„blockпјҢ然еҗҺеҫҖblcokдёӯеҶҷе…ҘйҳҹеҲ—nodeгҖӮеҮәйҳҹзҡ„ж—¶еҖҷпјҢйҰ–е…ҲеҺҹеӯҗдҝ®ж”№headжҢҮй’Ҳ(headжҢҮй’Ҳеҗ‘еҗҺ移еҠЁиӢҘе№Іblock)пјҢеҚ жҚ®йңҖиҰҒиҜ»еҸ–зҡ„blockпјҢ然еҗҺд»ҺblockдёӯиҜ»еҸ–йҳҹеҲ—nodeгҖӮ
е®ҡй•ҝж— й”ҒйҳҹеҲ—дёҚеӯҳеңЁеҶ…еӯҳзҡ„еҲҶй…Қе’Ңеӣһ收问йўҳпјҢеҗҢж—¶еҶ…еӯҳblockзҡ„дҪҚзҪ®еӣәе®ҡпјҢеғҸдёҖдёӘзҺҜеҪўbufдёҖзӣҙеңЁеҫӘзҺҜиҜ»еҶҷдҪҝз”ЁпјҢдёҚеӯҳеңЁABAй—®йўҳгҖӮе®ҡй•ҝж— й”ҒйҳҹеҲ—еӯҳеңЁдёҖдёӘйҳҹеҲ—е…ғзҙ иҜ»еҶҷе®Ңж•ҙжҖ§й—®йўҳпјҢз”ұдәҺе…ҘйҳҹйҮҮз”Ёзҡ„жҳҜе…Ҳе…ҘйҳҹеңЁеҶҷе…ҘеҶ…е®№зҡ„ж–№ејҸпјҢдәҺжҳҜеӯҳеңЁйҳҹеҲ—nodeеҶ…е®№иҝҳжІЎеҶҷе…Ҙе®ҢжҜ•е°ұдјҡиў«еҮәйҳҹиҜ»еҸ–дәҶпјҢиҜ»еҸ–еҲ°дёҖдёӘдёҚе®Ңж•ҙзҡ„nodeгҖӮеҗҢж ·пјҢеҮәйҳҹйҮҮз”Ёе…ҲеҮәйҳҹпјҢеңЁиҜ»еҸ–йҳҹеҲ—nodeеҶ…е®№пјҢдәҺжҳҜд№ҹеӯҳеңЁеҶ…е®№иҝҳжІЎиҜ»еҸ–зҡ„ж—¶еҖҷпјҢиў«ж–°зҡ„йҳҹеҲ—nodeе…Ҙйҳҹзҡ„еҶ…е®№з»ҷиҰҶзӣ–дәҶгҖӮиҰҒи§ЈеҶіиҝҷдёӘй—®йўҳдёҚеӨҚжқӮпјҢеҸӘиҰҒз»ҷжҜҸдёӘйҳҹеҲ—nodeеҠ дёҠдёҖдёӘtagж Үи®°жҳҜеҗҰе·Із»ҸеҶҷе…Ҙе®ҢжҜ•гҖҒжҳҜеҗҰе·Із»ҸиҜ»еҸ–е®ҢжҜ•еҚіеҸҜгҖӮ
е®ҡй•ҝж— й”ҒйҳҹеҲ—иҷҪ然дёҚеӯҳеңЁABAй—®йўҳе’ҢеҶ…еӯҳе®үе…Ёеӣһ收问йўҳпјҢдҪҶжҳҜз”ұдәҺе…¶йҳҹеҲ—жҳҜе®ҡй•ҝзҡ„пјҢжү©еұ•жҖ§жҜ”иҫғе·®гҖӮеҜ№дәҺABAй—®йўҳзҡ„и§ЈеҶіж–№жЎҲпјҢеүҚйқўе·Із»Ҹд»Ӣз»ҚдәҶж ҮзӯҫжҢҮй’ҲпјҲTagged pointersпјүе’ҢLL/SCеҜ№дёӨз§Қи§ЈеҶіж–№жЎҲгҖӮдёӢйқўзқҖйҮҚд»Ӣз»Қд»ҘдёӢеҶ…еӯҳе®үе…Ёеӣһ收зҡ„и§ЈеҶіж–№жЎҲгҖӮ
еҶ…еӯҳе®үе…Ёеӣһ收问йўҳж №жәҗдёҠжҳҜеҫ…еӣһ收зҡ„еҶ…еӯҳиҝҳиў«е…¶д»–зәҝзЁӢеј•з”ЁдёӯпјҢжӯӨж—¶еҰӮжһңdeleteиҜҘеҶ…еӯҳпјҢйӮЈд№Ҳеј•з”ЁиҜҘеҶ…еӯҳзҡ„зәҝзЁӢе°ұдјҡеҮәзҺ°дҪҝз”Ёйқһжі•еҶ…еӯҳзҡ„й—®йўҳпјҢйӮЈд№ҲжҲ‘们еҸӘиғҪ延иҝҹеӣһ收иҜҘеҶ…еӯҳпјҢеҚіеңЁе®үе…Ёж—¶еҲ»еҶҚdeleteгҖӮзӣ®еүҚз”ЁдәҺlock freeд»Јз Ғзҡ„еҶ…еӯҳеӣһ收зҡ„з»Ҹе…ёж–№жі•жңүпјҡLock Free Reference CountingгҖҒHazard PointerгҖҒEpoch Based ReclamationгҖҒQuiescent State Based ReclamationзӯүгҖӮ
3.1 Epoch Based Reclamation(еҹәдәҺе‘Ёжңҹзҡ„еҶ…еӯҳеӣһ收)
Epoch Basedж–№жі•йҮҮз”ЁйҖ’еўһзҡ„ж–№ејҸжқҘз»ҙжҠӨи®°еҪ•еҪ“еүҚжӯЈеңЁиў«еј•з”Ёзҡ„еҶ…еӯҳзүҲжң¬ver_iпјҢеҰӮжһңиғҪзҹҘйҒ“еҪ“еүҚиў«еј•з”Ёзҡ„зҡ„еҶ…еӯҳзҡ„жңҖе°ҸзүҲжң¬ver_minпјҢйӮЈд№ҲжҲ‘们е°ұеҸҜд»Ҙе®үе…Ёеӣһ收жүҖжңүеҶ…еӯҳзүҲжң¬е°ҸдәҺver_minзҡ„еҶ…еӯҳдәҶгҖӮйҖҡеёёдёҚдјҡз»ҷдёҖдёӘеҶ…еӯҳеҜ№иұЎдёҖдёӘзүҲжң¬пјҢиҝҷж ·зүҲжң¬еӨӘеӨҡпјҢйҡҫд»Ҙз®ЎзҗҶпјҢдёҖдёӘжҠҳдёӯж–№жЎҲжҳҜдёҖдёӘе‘ЁжңҹеҶ…зҡ„еҶ…еӯҳеҜ№иұЎйғҪжҳҜеҲҶй…ҚеҗҢдёҖдёӘзүҲжң¬ver_pгҖӮйӮЈд№ҲпјҢжңҖе°‘йңҖиҰҒеҮ дёӘдёҚеҗҢзүҲжң¬е‘ўпјҹдёҖдёӘзүҲжң¬жҳҜиӮҜе®ҡдёҚеҸҜд»Ҙзҡ„пјҢиҝҷж ·е°ұж— жі•еҢәеҲҶе“ӘдәӣеҶ…еӯҳеҜ№иұЎжҳҜеҸҜд»Ҙе®үе…Ёеӣһ收зҡ„пјҢе“ӘдәӣжҳҜжҡӮж—¶дёҚиғҪеӣһ收зҡ„гҖӮдёӨдёӘзүҲжң¬ver_0гҖҒver_1жҳҜеҗҰOKе‘ўпјҹеҒҮи®ҫеҪ“еүҚзҡ„еҶ…еӯҳеҜ№иұЎйғҪиў«еҲҶй…ҚзүҲжң¬еҸ·ver_0пјҢеңЁжҹҗдёҖдёӘж—¶еҲ»t1пјҢжҲ‘们еҶіе®ҡеҸҳжӣҙзүҲжң¬еҸ·дёәver_1пјҢиҝҷж ·ж–°зҡ„еҶ…еӯҳеҜ№иұЎе°ұиў«еҲҶй…ҚзүҲжң¬ver_1гҖӮиҝҷж ·жүҚt1еҗҺпјҢеңЁжҲ‘们еҶҚж¬ЎеҸҳжӣҙзүҲжң¬еҸ·дёәver_0еүҚпјҢзүҲжң¬еҸ·дёәver_0зҡ„еҶ…еӯҳеҜ№иұЎе°ұдёҚеҶҚеўһеҠ дәҶгҖӮйӮЈд№ҲпјҢеңЁжүҖжңүдҪҝз”ЁзүҲжң¬еҸ·дёәver_0зҡ„еҶ…еӯҳеҜ№иұЎзҡ„зәҝзЁӢйғҪдёҚеҶҚдҪҝз”ЁиҝҷдәӣеҶ…еӯҳеҜ№иұЎеҗҺпјҢеҒҮи®ҫиҝҷдёӘж—¶еҖҷжҳҜt2пјҢиҝҷж—¶жҲ‘们е°ұеҸҜд»ҘејҖе§Ӣеӣһ收зүҲжң¬еҸ·ver_0зҡ„еҶ…еӯҳеҜ№иұЎпјҢеӣһ收иҖ—ж—¶k*n(nжҳҜеҫ…еӣһ收зҡ„еҶ…еӯҳеҜ№иұЎ)гҖӮеҫҲжҳҺжҳҫпјҢжҲ‘们еҶҚж¬ЎеҸҳжӣҙзүҲжң¬еҸ·дёәver_0зҡ„ж—¶еҲ»t3жҳҜдёҖе®ҡиҰҒеӨ§дәҺзӯүдәҺt2+k*nж—¶еҲ»зҡ„пјҢеӣ дёәпјҢеҰӮжһңt3<t2+k*nпјҢйӮЈд№ҲеңЁt2+k*nиҮіt3й—ҙдә§з”ҹзҡ„зүҲжң¬еҸ·дёәзҡ„еҜ№иұЎе°ұдјҡеӯҳеңЁйқһе®үе…Ёеӣһ收зҡ„йЈҺйҷ©гҖӮ
еҸҜд»ҘзңӢеҮәйҮҮз”ЁдёӨдёӘзүҲжң¬жҳҜokзҡ„пјҢдҪҶжҳҜз»Ҷеҝғзҡ„еҗҢеӯҰдјҡеҸ‘зҺ°пјҢиҝҷж ·зҡ„еӣһ收粒еәҰжңүзӮ№зІ—пјҢзүҲжң¬еҸ·дёәver_1зҡ„еҶ…еӯҳеҜ№иұЎеңЁt1иҮіt2+k*nиҝҷж®өж—¶й—ҙеҶ…дёҖзӣҙеңЁеўһй•ҝпјҢж•ҙдёӘж—¶й—ҙй•ҝеәҰдҫқиө–дәҺеҶ…еӯҳеҜ№иұЎиў«еј•з”Ёзҡ„ж—¶й—ҙе’Ңver_0зҡ„еҶ…еӯҳеҜ№иұЎиў«еӣһ收зҡ„ж—¶й—ҙпјҢиҝҷж ·еҸҜиғҪдјҡеј•иө·ж»ҡйӣӘзҗғж•Ҳеә”пјҢи¶ҠеҫҖеҗҺйқўеӣһ收时й—ҙдјҡи¶Ҡй•ҝгҖӮ
йҖҡиҝҮдёҠйқўзҡ„еҲҶжһҗпјҢжҲ‘们зҹҘйҒ“пјҢеҰӮжһңжғізүҲжң¬еҸ·еҸҳжӣҙзҡ„ж—¶й—ҙзӮ№дёҚдҫқиө–ver_0зҡ„еҶ…еӯҳеҜ№иұЎиў«еӣһ收зҡ„ж—¶й—ҙпјҢжҲ‘们йңҖиҰҒеўһеҠ дёҖдёӘзүҲжң¬еҸ·ver_2пјҢйӮЈд№ҲеңЁt2ж—¶еҲ»пјҢжҲ‘们е°ұеҸҜд»ҘеҲҮжҚўзүҲжң¬еҸ·дёәver_2пјҢеҗҢж—¶еҸҜд»ҘеҗҜеҠЁеӣһ收ver_0зҡ„еҶ…еӯҳеҜ№иұЎгҖӮ
йҖҡиҝҮдёҠйқўзҡ„еҲҶжһҗпјҢEpoch Basedз®—жі•з»ҙжҠӨдәҶдёҖдёӘе…ЁеұҖзҡ„epoch(еҸ–еҖјдёә0гҖҒ1гҖҒ2)е’ҢдёүдёӘе…ЁеұҖзҡ„retire_listпјҲжҜҸдёӘе…ЁеұҖзҡ„epochеҜ№еә”дёҖдёӘretire list, retire list еӯҳж”ҫйҖ»иҫ‘еҲ йҷӨеҗҺеҫ…еӣһ收зҡ„иҠӮзӮ№жҢҮй’ҲпјүгҖӮйҷӨжӯӨд№ӢеӨ–жҲ‘们дёәжҜҸдёӘзәҝзЁӢз»ҙжҠӨдёҖдёӘеұҖйғЁзҡ„thread_active flag(иҝҷдёӘз”ЁжқҘж ҮиҜҶthreadж—¶еҖҷе·Із»ҸдёҚеҶҚеј•з”ЁиҜҘepochеҖјзҡ„еҶ…еӯҳеҜ№иұЎ)е’Ңthread_epoch(еҸ–еҖјиҮӘ然д№ҹдёә0гҖҒ1гҖҒ2)гҖӮз®—жі•еҰӮдёӢпјҡ
```
#define N_THREADS 4 //еҒҮи®ҫдёҖе…ұ4дёӘзәҝзЁӢ
const EPOCH_COUNT = 3 ;
bool active[N_THREADS] = {false};
int epoches[N_THREADS] = {0};
int global_epoch = 0;
vector<int*> retire_list[3];
void read(int thread_id)
{
active[thread_id] = true;
epoches[thread_id] = global_epoch;
//иҝӣе…Ҙдёҙз•ҢеҢәдәҶгҖӮеҸҜд»Ҙе®үе…Ёзҡ„иҜ»еҸ–
//......
//иҜ»еҸ–е®ҢжҜ•пјҢзҰ»ејҖдёҙз•ҢеҢә
active[thread_id] = false;
}
void logical_deletion(int thread_id)
{
active[thread_id] = true;
epoches[thread_id] = global_epoch;
//иҝӣе…Ҙдёҙз•ҢеҢәдәҶпјҢиҝҷйҮҢпјҢжҲ‘们еҸҜд»Ҙе®үе…Ёзҡ„иҜ»еҸ–
//еҘҪдәҶпјҢеҒҮеҰӮиҜҙжҲ‘们зҺ°еңЁиҰҒеҲ йҷӨе®ғдәҶгҖӮе…ҲйҖ»иҫ‘еҲ йҷӨгҖӮ
//иҖҢиў«йҖ»иҫ‘еҲ йҷӨзҡ„tmpжҢҮеҗ‘зҡ„иҠӮзӮ№иҝҳдёҚиғҪ马дёҠиў«еӣһ收пјҢеӣ жӯӨжҠҠе®ғеҠ е…ҘеҲ°еҜ№еә”зҡ„retire list
retire_list[global_epoch].push_back(tmp);
//зҰ»ејҖдёҙз•ҢеҢә
active[thread_id] = false;
//зңӢзңӢиғҪдёҚиғҪзү©зҗҶеҲ йҷӨ
try_gc();
}
bool try_gc()
{
int &e = global_epoch;
for (int i = 0; i < N_THREADS; i++) {
if (active[i] && epoches[i] != e) {
//иҝҳжңүйғЁеҲҶзәҝзЁӢжІЎжңүжӣҙж–°еҲ°жңҖж–°зҡ„е…ЁеұҖзҡ„epochеҖј
//иҝҷж—¶еҖҷеҸҜд»Ҙеӣһ收(e + 1) % EPOCH_COUNTеҜ№еә”зҡ„retire listгҖӮ
free((e + 1) % EPOCH_COUNT);//дёҚжҳҜfree(e)пјҢд№ҹдёҚжҳҜfree(e-1)гҖӮ
return false;
}
}
//жӣҙж–°global epoch
e = (e + 1) % EPOCH_COUNT;
//жӣҙж–°д№ӢеҗҺпјҢйӮЈдәӣactiveзәҝзЁӢдёӯпјҢйғЁеҲҶзәҝзЁӢзҡ„epochеҖјеҸҜиғҪиҝҳжҳҜe - 1пјҲжЁЎEPOCH_COUNTпјү
//йӮЈдәӣinactiveзҡ„зәҝзЁӢпјҢд№ӢеҗҺе°ҶиҜ»еҲ°жңҖж–°зҡ„еҖјпјҢд№ҹе°ұжҳҜeгҖӮ
//дёҚз®ЎеҰӮдҪ•пјҢ(e + 1) % EPOCH_COUNTеҜ№еә”зҡ„retire listзҡ„йӮЈдәӣеҶ…еӯҳпјҢдёҚдјҡжңүдәәеҶҚи®ҝй—®еҲ°дәҶпјҢеҸҜд»Ҙеӣһ收е®ғ们дәҶ
//еӣ жӯӨepochзҡ„еҸ–еҖјйңҖиҰҒжңүдёүз§ҚпјҢд»…д»…дёӨз§ҚжҳҜдёҚеӨҹзҡ„гҖӮ
free((e + 1) % EPOCH_COUNT);//дёҚжҳҜfree(e)пјҢд№ҹдёҚжҳҜfree(e-1)гҖӮ
}
bool free(int epoch)
{
for each pointer in retire_list[epoch]
if (pointer is not NULL)
delete pointer;
}
```
Epoch Based Reclamation算法规еҲҷжҜ”иҫғз®ҖеҚ•жҳҺдәҶпјҢиҜҘ算法规еҲҷжңүдёӘйҮҚиҰҒзҡ„зјәйҷ·жҳҜпјҢе®ғдҫқиө–дәҺжүҖжңүдҪҝз”Ёver_0зҡ„еҶ…еӯҳеҜ№иұЎзҡ„зәҝзЁӢйғҪиҝӣе…ҘеҲ°дёӢдёӘе‘Ёжңҹver_1еҗҺпјҢver_0зҡ„еҶ…еӯҳеҜ№иұЎжүҚиғҪиў«еӣһ收гҖӮеҸӘиҰҒжңүдёҖдёӘзәҝзЁӢжңӘиғҪиҝӣе…ҘеҲ°дёӢдёӘе‘Ёжңҹver_1пјҢйӮЈд№ҲйӮЈдәӣеӨ§еӨҡж•°е·Із»ҸжІЎжңүеј•з”Ёзҡ„ver_0еҶ…еӯҳеҜ№иұЎе°ұдёҚиғҪиў«еҲ йҷӨеӣһ收гҖӮиҝҷдёӘеңЁзәҝзЁӢеӯҳеңЁдёҚеҗҢзҡ„дјҳе…Ҳзә§ж—¶еҖҷпјҢдјҳе…Ҳзә§дҪҺзҡ„зәҝзЁӢдјҡеҜјиҮҙдјҳе…Ҳзә§й«ҳзҡ„зәҝзЁӢ延иҝҹеҫ…еҲ йҷӨе…ғзҙ еўһй•ҝеҸҳеҫ—дёҚеҸҜжҺ§пјҢдёҖж—ҰжҹҗдёӘзәҝзЁӢдёҖзӣҙж— жі•иҝӣе…ҘдёӢдёҖдёӘе‘ЁжңҹпјҢдјҡеҜјиҮҙж— йҷҗзҡ„еҶ…еӯҳж¶ҲиҖ—гҖӮ
3.2 йҷ©иұЎжҢҮй’ҲпјҲHazard pointerпјү
Hazard Pointerз”ұMaged M. MichaelеңЁи®әж–Ү"Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects"дёӯжҸҗеҮәпјҢеҹәжң¬жҖқи·ҜжҳҜе°ҶеҸҜиғҪиҰҒиў«и®ҝй—®еҲ°зҡ„е…ұдә«еҜ№иұЎжҢҮй’ҲпјҲжҲҗдёәhazard pointerпјүе…ҲдҝқеӯҳеҲ°зәҝзЁӢеұҖйғЁпјҢ然еҗҺеҶҚи®ҝй—®пјҢи®ҝй—®е®ҢжҲҗеҗҺд»ҺзәҝзЁӢеұҖйғЁз§»йҷӨгҖӮиҖҢиҰҒйҮҠж”ҫдёҖдёӘе…ұдә«еҜ№иұЎж—¶пјҢеҲҷиҰҒе…ҲйҒҚеҺҶжҹҘиҜўжүҖжңүзәҝзЁӢзҡ„еұҖйғЁдҝЎжҒҜпјҢеҰӮжһңе°ҡжңүзәҝзЁӢеұҖйғЁдҝқеӯҳжңүиҝҷдёӘе…ұдә«еҜ№иұЎзҡ„жҢҮй’ҲпјҢиҜҙжҳҺиҝҷдёӘзәҝзЁӢжңүеҸҜиғҪе°ҶиҰҒи®ҝй—®иҝҷдёӘеҜ№иұЎпјҢеӣ жӯӨдёҚиғҪйҮҠж”ҫпјҢеҸӘжңүжүҖжңүзәҝзЁӢзҡ„еұҖйғЁдҝЎжҒҜдёӯйғҪжІЎжңүдҝқеӯҳиҝҷдёӘе…ұдә«еҜ№иұЎзҡ„жҢҮй’Ҳжғ…еҶөдёӢпјҢжүҚиғҪе°Ҷе…¶йҮҠж”ҫгҖӮ
жҲ‘们зҹҘйҒ“Hazard Pointerе°ҒиЈ…дәҶеҺҹе§ӢжҢҮй’ҲпјҢйӮЈд№ҲHazard Pointerзҡ„еҶ…еӯҳе’Ңз”ҹе‘Ҫе‘Ёжңҹжң¬иә«еҰӮдҪ•з®ЎзҗҶе‘ўпјҹд»ҘдёӢжҳҜеёёи§Ғзҡ„зӯ–з•Ҙпјҡ
```
1пјҢHazard Pointerжң¬иә«зҡ„еҶ…еӯҳеҸӘеҲҶй…ҚпјҢдёҚйҮҠж”ҫгҖӮеңЁstackгҖҒqueueзӯүж•°жҚ®з»“жһ„йҮҢпјҢйңҖиҰҒзҡ„Hazard Pointerж•°йҮҸдёҖиҲ¬дёә1жҲ–иҖ…2пјҢжүҖд»ҘдёҚйҮҠж”ҫй—®йўҳдёҚеӨ§гҖӮеҜ№дәҺskip listиҝҷз§Қж•°жҚ®з»“жһ„еҸҲжңүйҒҚеҺҶйңҖжұӮзҡ„пјҢйӮЈд№ҲHazard PointerеҸҜиғҪе°ұдёҚжҳҜйқһеёёйҖӮз”ЁдәҶпјҢеҸҜд»ҘиҖғиҷ‘дҪҝз”ЁEpoch Based ReclamationжҠҖжңҜгҖӮжҚ®жҲ‘жүҖзҹҘпјҢиҝҷд№ҹжҳҜmemsqlдҪҝз”Ёзҡ„еҶ…еӯҳеӣһ收зӯ–з•ҘгҖӮ
2пјҢжҜҸдёӘзәҝзЁӢжӢҘжңүгҖҒз®ЎзҗҶиҮӘе·ұзҡ„retire listе’Ңhazard pointer list пјҢиҖҢдёҚжҳҜжүҖжңүзәҝзЁӢе…ұдә«дёҖдёӘretire listпјҢиҝҷж ·еҸҜд»ҘйҒҝе…Қз»ҙжҠӨretire listе’Ңhazard pointer listзҡ„ејҖй”ҖпјҢеҗҰеҲҷжҲ‘们еҸҜиғҪеҸҲеҫ—жғіе°Ҫи„‘жұҒеҺ»и®ҫи®ЎеҸҰеӨ–дёҖеҘ—lock freeзҡ„зӯ–з•ҘжқҘз®ЎзҗҶиҝҷдәӣlistпјҢе…ҲжңүйёЎе…ҲжңүиӣӢпјҢж— з©·ж— е°ҪгҖӮжүҖи°“retire listе°ұжҳҜжҢҮйҖ»иҫ‘еҲ йҷӨеҗҺеҫ…зү©зҗҶеӣһ收зҡ„жҢҮй’ҲеҲ—иЎЁгҖӮ
3пјҢжҜҸдёӘзәҝзЁӢиҙҹиҙЈеӣһ收иҮӘе·ұзҡ„retire listдёӯи®°еҪ•з»ҙжҠӨзҡ„еҶ…еӯҳгҖӮиҝҷж ·пјҢretire listжҳҜдёҖдёӘзәҝзЁӢеұҖйғЁзҡ„ж•°жҚ®з»“жһ„пјҢиҮӘе·ұеҶҷпјҢиҮӘе·ұиҜ»пјҢеҗғиҮӘе·ұзҡ„зӢ—зІ®гҖӮ
4пјҢеҸӘжңүеҪ“retire listзҡ„еӨ§е°ҸпјҲж•°йҮҸпјүиҫҫеҲ°дёҖе®ҡзҡ„йҳҲеҖјж—¶пјҢжүҚиҝӣиЎҢGCгҖӮиҝҷж ·пјҢеҸҜд»ҘжҠҠGCзҡ„ејҖй”ҖиҝӣиЎҢеҲҶж‘ҠпјҢеҗҢж—¶пјҢеә”иҜҘе°ҪеҸҜиғҪдҪҝз”ЁJemallocжҲ–иҖ…TCmallocиҝҷдәӣй«ҳж•Ҳзҡ„гҖҒеёҰзәҝзЁӢеұҖйғЁзј“еӯҳзҡ„еҶ…еӯҳеҲҶй…ҚеҷЁгҖӮ
```
3.3 Hazard Version
HazardPointerзҡ„е®һзҺ°з®ҖеҚ•пјҢдҪҶжҳҜе…¶жңүдёӘдёҚи¶іпјҡйңҖиҰҒдёәжҜҸдёӘе…ұдә«еҸҳйҮҸз»ҙжҠӨдёҖдёӘзәҝзЁӢзҡ„hazard pointerпјҢиҝҷж ·дҪҝз”ЁиҖ…йңҖиҰҒд»”з»ҶеҲҶжһҗз®—жі•д»Ҙе°ҪйҮҸеҮҸе°‘еҗҢж—¶еӯҳеңЁзҡ„hazard pointerпјҢHazard PointerжңәеҲ¶д№ҹдёҺе…·дҪ“ж•°жҚ®з»“жһ„зҡ„е®һзҺ°жҜ”иҫғзҙ§зҡ„иҖҰеҗҲеңЁдёҖиө·пјҢеҜ№дәҺskip listиҝҷж ·зҡ„жңүйҒҚеҺҶйңҖжұӮзҡ„ж•°жҚ®з»“жһ„еҗҢж—¶еӯҳеңЁзҡ„hazard pointerеҫҲе®№жҳ“иҶЁиғҖжҜ”иҫғеӨҡпјҢеҶ…еӯҳдҪҝз”ЁжҳҜдёӘй—®йўҳгҖӮ
еӣ жӯӨеңЁHazard PointerеҹәзЎҖдёҠеҸ‘еұ•еҮәдәҶиў«з§°дёәHazard VersionжҠҖжңҜпјҢе®ғжҸҗдҫӣзұ»дјјlockдёҖж ·зҡ„acquire/releaseжҺҘеҸЈпјҢж”ҜжҢҒж— йҷҗеҲ¶дёӘж•°е…ұдә«еҜ№иұЎзҡ„з®ЎзҗҶгҖӮ
дёҺHazard Pointerзҡ„е®һзҺ°дёҚеҗҢпјҡйҰ–е…Ҳе…ЁеұҖиҰҒз»ҙжҠӨдёҖдёӘint64_tзұ»еһӢзҡ„GlobalVersionпјӣиҰҒи®ҝй—®е…ұдә«еҜ№иұЎеүҚпјҢе…Ҳе°ҶеҪ“ж—¶зҡ„GlobalVersionдҝқеӯҳеҲ°зәҝзЁӢеұҖйғЁпјҢз§°дёәhazard versionпјӣиҖҢжҜҸж¬ЎиҰҒйҮҠж”ҫе…ұдә«еҜ№иұЎзҡ„ж—¶еҖҷе…Ҳе°ҶеҪ“еүҚGlobalVersionдҝқеӯҳеңЁе…ұдә«еҜ№иұЎпјҢ然еҗҺе°ҶGlobalVersionеҺҹеӯҗзҡ„еҠ 1пјҢ然еҗҺйҒҚеҺҶжүҖжңүзәҝзЁӢзҡ„еұҖйғЁдҝЎжҒҜпјҢжүҫеҲ°жңҖе°Ҹзҡ„versionз§°дёәreclaim versionпјҢеҲӨж–ӯеҰӮжһңеҫ…йҮҠж”ҫзҡ„еҜ№иұЎдёӯдҝқеӯҳзҡ„versionе°ҸдәҺreclaim versionеҲҷеҸҜд»ҘйҮҠж”ҫгҖӮhazard versionе°ұзұ»дјјдәҺз»ҷжҜҸдёӘеҶ…еӯҳеҜ№иұЎеҲҶй…ҚдёҖдёӘеҚ•и°ғйҖ’еўһзҡ„versionзҡ„Epoch Basedж–№жі•пјҢжҳҜжӣҙз»ҶзІ’еәҰзҡ„еҶ…еӯҳеӣһ收гҖӮ
4 иЎҘеҒҝзӯ–з•Ҙ(functor bkoff)
иЎҘеҒҝзӯ–з•ҘйҖҡеёёдҪңдёәйҒҝе…ҚеӨ§йҮҸCASз«һдәүзҡ„дёҖз§ҚйҖҖйҒҝзӯ–з•ҘпјҢеңЁеӨ§е№¶еҸ‘дҝ®ж”№еҗҢдёҖеҸҳйҮҸзҡ„жғ…еҶөдёӢпјҢиғҪжңүж•Ҳзј“и§ЈCPUеҺӢеҠӣгҖӮиҖғиҷ‘иҝҷд№ҲдёҖдёӘеңәжҷҜпјҢNдёӘзәҝзЁӢеҗҢж—¶еҜ№дёҖдёӘж— й”ҒйҳҹеҲ—иҝӣиЎҢе…Ҙйҳҹж“ҚдҪңпјҢдәҺжҳҜеҗҢж—¶иҝӣиЎҢзҡ„NдёӘCASж“ҚдҪңпјҢжңҖз»ҲеҸӘжңүдёҖдёӘзәҝзЁӢиҝ”еӣһжҲҗеҠҹгҖӮдәҺжҳҜпјҢеӨұиҙҘзҡ„N-1дёӘзәҝзЁӢеңЁдёӢдёҖдёӘеҫӘзҺҜдёӯ继з»ӯйҮҚиҜ•еҗҢж—¶иҝӣиЎҢN-1дёӘCASж“ҚдҪңпјҢжңҖз»ҲиҝҳжҳҜеҸӘжңүдёҖдёӘзәҝзЁӢиҝ”еӣһжҲҗеҠҹгҖӮиҝҷж ·дёҖзӣҙдёӢеҺ»пјҢеӨ§йҮҸзҡ„CPUиў«ж¶ҲиҖ—еңЁж— з”Ёзҡ„CASж“ҚдҪңдёҠпјҢжҲ‘们зҹҘйҒ“CASж“ҚдҪңжҳҜдёҖдёӘеҫҲйҮҚзҡ„дёҖдёӘж“ҚдҪңпјҢжңҚеҠЎеҷЁжҖ§иғҪдјҡжҖҘеү§дёӢйҷҚгҖӮиҝҷеҘҪжҜ”жқҘиҮӘеӣӣйқўе…«ж–№зҡ„иҪҰиҫҶжұҮиҒҡеҲ°дёҖдёӘеҮәеҸЈпјҢеӨ§е®¶йғҪжҜ”иҫғиҮӘз§Ғзҡ„жғіиҰҒжңҖеҝ«йҖҡиҝҮзҡ„иҜқпјҢйӮЈд№ҲиҝҷдёӘи·ҜеҸЈдјҡиў«е өзҡ„ж°ҙжі„дёҚйҖҡпјҢзҗҶжғізҡ„жғ…еҶөжҳҜе°ҶиҪҰиҫҶжөҒж°ҙзәҝеҢ–пјҢиҝҷж ·еӨ§е®¶йғҪиғҪиҫғеҝ«йҖҡиҝҮеҮәеҸЈгҖӮ然иҖҢе®һйҷ…жғ…еҶөжҳҜжҜ”иҫғйҡҫжөҒж°ҙзәҝеҢ–зҡ„пјҢдәҺжҳҜпјҢжҲ‘们йҮҮз”ЁзӨји®©зҡ„ж–№ејҸпјҢеңЁе°қиҜ•йҖҡиҝҮи·ҜеҸЈеҸ‘зҺ°е өеЎһзҡ„ж—¶еҖҷпјҢе°ұdelayдёҖе°ҸдјҡеңЁе°қиҜ•йҖҡиҝҮгҖӮдёҖдёӘз®ҖеҚ•зҡ„е®һзҺ°еҰӮдёӢпјҡ
```
bkoof()
{
static const int64_t INIT_LOOP = 1000000;
static const int64_t MAX_LOOP = 8000000;
static __thread int64_t delay = 0;
if (delay <= 0) {
delay = INIT_LOOP;
}
for (int64_t i = 0; i < delay; i++) {
CPU_RELAX();
}
int64_t new_delay = delay << 1LL;
if (new_delay <= 0 || new_delay >= MAX_LOOP) {
new_delay = INIT_LOOP;
}
delay = new_delay;
}
}
```
5 helpingж–№жі•
Helpingж–№жі•жҳҜдёҖз§Қе№ҝжіӣеӯҳеңЁдәҺж— й”Ғз®—жі•дёӯзҡ„ж–№жі•пјҢзү№еҲ«жҳҜеңЁдёҖдёӘзәҝзЁӢеё®еҠ©е…¶е®ғзәҝзЁӢеҺ»жү§иЎҢд»»еҠЎеңәжҷҜдёӯгҖӮжң¬дҫӢдёӯзҡ„ж— й”ҒйҳҹеҲ—е®һзҺ°пјҢдјҡеҮәзҺ°m_pTailзҡ„жҡӮж—¶й”ҷдҪҚдёҚжӯЈзЎ®пјҢдё»иҰҒзҡ„еҺҹеӣ жҳҜm_pTailзҡ„дҝ®ж”№(еҰӮдёӢ)并дёҚиғҪдҝқиҜҒдёҖе®ҡжҲҗеҠҹгҖӮ
```
m_pTail.compare_exchange_strong( t, pNew, memory_model::memory_order_acq_rel,
memory_model::memory_order_relaxed );
```
иҝҷйҮҢдёәд»Җд№ҲдёҚйҮҚиҜ•и®©m_pTailжҢҮеҗ‘жӯЈзЎ®зҡ„дҪҚзҪ®е‘ўпјҹиҝҷйҮҢдё»иҰҒжҳҜе®һзҺ°зӯ–з•Ҙе’ҢжҲҗжң¬ејҖй”Җзҡ„й—®йўҳпјҢиҖғиҷ‘иҝҷд№ҲдёҖдёӘеңәжҷҜпјҡ
```
1. еҪ“еүҚж—¶еҲ»йҳҹеҲ—жңү3дёӘиҠӮзӮ№(A-->B-->C)пјҢйҳҹеҲ—зҠ¶жҖҒпјҡm_pHead->m_pNext == AпјҢm_pTail == C
2. иҝҷж—¶зәҝзЁӢ1жү§иЎҢе…Ҙйҳҹenqueue(D)пјҢзәҝзЁӢ2жү§иЎҢе…Ҙйҳҹenqueue(E)гҖӮ
3. зәҝзЁӢ1жү§иЎҢenqueue(D)иҝӣиЎҢеҲ°жңҖеҗҺдёҖжӯҘпјҢиҝҷж—¶йҳҹеҲ—зҠ¶жҖҒпјҡ(A-->B-->C-->D)пјҢm_pHead->m_pNext == AпјҢm_pTail == C
4. зәҝзЁӢ2жү§иЎҢenqueue(E)пјҢиҝҷж—¶е®ғеҸ‘зҺ°m_pTail->m_pNext != NULLпјҢm_pTailдҪҚзҪ®дёҚжӯЈзЎ®дәҶгҖӮ
```
иҝҷдёӘж—¶еҖҷпјҢзәҝзЁӢ2жңүдёӨдёӘйҖүжӢ©пјҡ(1) дёҚж–ӯйҮҚиҜ•зӯүеҫ…зәҝзЁӢ1е°Ҷm_pTailи®ҫзҪ®жӯЈзЎ®еҗҺпјҢиҮӘе·ұеңЁиҝӣиЎҢдёӢйқўзҡ„ж“ҚдҪңжӯҘйӘӨгҖӮ(2) йЎәи·Ҝеё®зәҝзЁӢ1дёҖжҠҠпјҢиҮӘе·ұе°Ҷm_pTailи°ғж•ҙеҲ°жӯЈзЎ®дҪҚзҪ®пјҢ然еҗҺеңЁиҝӣиЎҢдёӢйқўзҡ„ж“ҚдҪңжӯҘйӘӨгҖӮеҰӮжһңйҮҮз”Ё(1)пјҢзәҝзЁӢ2еҸҜиғҪдјҡиҝӣе…ҘдёҖдёӘиҫғжј«й•ҝзҡ„зӯүеҫ…жқҘзӯүзәҝзЁӢ1е®ҢжҲҗm_pTail зҡ„и®ҫзҪ®гҖӮйҮҮз”Ё(2)еҲҷжҳҜдёҖдёӘеҸҢиөўзҡ„еұҖйқўпјҢзәҝзЁӢ2дёҚеңЁйңҖиҰҒзӯүеҫ…е’Ңдҫқиө–зәҝзЁӢ1пјҢзәҝзЁӢ1д№ҹдёҚеҶҚйңҖиҰҒеңЁm_pTailи®ҫзҪ®еӨұиҙҘзҡ„ж—¶еҖҷиҝӣиЎҢйҮҚиҜ•дәҶгҖӮ
第6з« зҡ„еҶ…е®№е°ҶеңЁжң¬ж¬ЎжҺЁйҖҒзҡ„第дәҢжқЎеӣҫж–ҮгҖҠиҜҙиҜҙж— й”ҒпјҲLock-Freeпјүзј–зЁӢйӮЈдәӣдәӢпјҲдёӢпјүгҖӢдёӯйҳҗиҝ°гҖӮ
еҸӮиҖғиө„ж–ҷ
http://chonghw.github.io/
http://chonghw.github.io/blog/2016/08/11/memoryreorder/
http://chonghw.github.io/blog/2016/09/19/sourcecontrol/
http://chonghw.github.io/blog/2016/09/28/acquireandrelease/
http://www.wowotech.net/kernel_synchronization/Why-Memory-Barriers.html
http://www.wowotech.net/kernel_synchronization/why-memory-barrier-2.html
http://www.wowotech.net/kernel_synchronization/memory-barrier-1.html
http://www.wowotech.net/kernel_synchronization/perfbook-memory-barrier-2.html
https://kukuruku.co/post/lock-free-data-structures-introduction/
https://kukuruku.co/post/lock-free-data-structures-basics-atomicity-and-atomic-primitives/
https://kukuruku.co/post/lock-free-data-structures-the-inside-memory-management-schemes/
6 еҶ…еӯҳеұҸйҡңпјҲMemory Barriersпјү
6.1 What Memory Barriersпјҹ
еҶ…еӯҳеұҸйҡңпјҢд№ҹз§°еҶ…еӯҳж …ж ҸпјҢеҶ…еӯҳж …йҡңпјҢеұҸйҡңжҢҮд»ӨзӯүпјҢжҳҜдёҖзұ»еҗҢжӯҘеұҸйҡңжҢҮд»ӨпјҢжҳҜCPUжҲ–зј–иҜ‘еҷЁеңЁеҜ№еҶ…еӯҳйҡҸжңәи®ҝй—®зҡ„ж“ҚдҪңдёӯзҡ„дёҖдёӘеҗҢжӯҘзӮ№пјҢдҪҝеҫ—жӯӨзӮ№д№ӢеүҚзҡ„жүҖжңүиҜ»еҶҷж“ҚдҪңйғҪжү§иЎҢеҗҺжүҚеҸҜд»ҘејҖе§Ӣжү§иЎҢжӯӨзӮ№д№ӢеҗҺзҡ„ж“ҚдҪңгҖӮеӨ§еӨҡж•°зҺ°д»Ји®Ўз®—жңәдёәдәҶжҸҗй«ҳжҖ§иғҪиҖҢйҮҮеҸ–д№ұеәҸжү§иЎҢпјҢиҝҷдҪҝеҫ—еҶ…еӯҳеұҸйҡңжҲҗдёәеҝ…йЎ»гҖӮиҜӯд№үдёҠпјҢеҶ…еӯҳеұҸйҡңд№ӢеүҚзҡ„жүҖжңүеҶҷж“ҚдҪңйғҪиҰҒеҶҷе…ҘеҶ…еӯҳпјӣеҶ…еӯҳеұҸйҡңд№ӢеҗҺзҡ„иҜ»ж“ҚдҪңйғҪеҸҜд»ҘиҺ·еҫ—еҗҢжӯҘеұҸйҡңд№ӢеүҚзҡ„еҶҷж“ҚдҪңзҡ„з»“жһңгҖӮеӣ жӯӨпјҢеҜ№дәҺж•Ҹж„ҹзҡ„зЁӢеәҸеқ—пјҢеҶҷж“ҚдҪңд№ӢеҗҺгҖҒиҜ»ж“ҚдҪңд№ӢеүҚеҸҜд»ҘжҸ’е…ҘеҶ…еӯҳеұҸйҡңгҖӮ
йҖҡеёёжғ…еҶөдёӢпјҢжҲ‘们еёҢжңӣжҲ‘们жүҖзј–еҶҷзҡ„зЁӢеәҸд»Јз ҒиғҪ"жүҖи§ҒеҚіжүҖеҫ—"пјҢеҚізЁӢеәҸйҖ»иҫ‘ж»Ўи¶ізЁӢеәҸзҡ„йЎәеәҸжҖ§(ж»Ўи¶іprogram order)пјҢ然иҖҢпјҢеҫҲйҒ—жҶҫпјҢжҲ‘们зҡ„зЁӢеәҸйҖ»иҫ‘("жүҖи§Ғ")е’ҢжңҖеҗҺзҡ„жү§иЎҢз»“жһң("жүҖеҫ—")йҡ”зқҖпјҡ
```
1. зј–иҜ‘еҷЁ
2. CPUеҸ–жҢҮжү§иЎҢ
```
1. зј–иҜ‘еҷЁе°Ҷз¬ҰеҗҲдәәзұ»жҖқиҖғзҡ„йҖ»иҫ‘пјҲзЁӢеәҸд»Јз Ғпјүзҝ»иҜ‘жҲҗдәҶз¬ҰеҗҲCPUиҝҗ算规еҲҷзҡ„жұҮзј–жҢҮд»ӨпјҢзј–иҜ‘еҷЁдәҶи§Јеә•еұӮCPUзҡ„жҖқз»ҙжЁЎејҸпјҢеӣ жӯӨпјҢе®ғеҸҜд»ҘеңЁе°ҶзЁӢеәҸзҝ»иҜ‘жҲҗжұҮзј–зҡ„ж—¶еҖҷиҝӣиЎҢдјҳеҢ–пјҲдҫӢеҰӮеҶ…еӯҳи®ҝй—®жҢҮд»Өзҡ„йҮҚж–°жҺ’еәҸпјүпјҢи®©дә§еҮәзҡ„жұҮзј–жҢҮд»ӨеңЁCPUдёҠиҝҗиЎҢзҡ„ж—¶еҖҷжӣҙеҝ«гҖӮ然иҖҢпјҢиҝҷз§ҚдјҳеҢ–дә§еҮәзҡ„з»“жһңжңӘеҝ…з¬ҰеҗҲзЁӢеәҸе‘ҳеҺҹе§Ӣзҡ„йҖ»иҫ‘пјҢеӣ жӯӨпјҢдҪңдёәзЁӢеәҸе‘ҳпјҢеҝ…йЎ»жңүиғҪеҠӣдәҶи§Јзј–иҜ‘еҷЁзҡ„иЎҢдёәпјҢ并еңЁйҖҡиҝҮеҶ…еөҢеңЁзЁӢеәҸд»Јз Ғдёӯзҡ„memory barrierжқҘжҢҮеҜјзј–иҜ‘еҷЁзҡ„дјҳеҢ–иЎҢдёәпјҲиҝҷз§Қmemory barrierеҸҲеҸ«еҒҡдјҳеҢ–еұҸйҡңпјҢOptimization barrierпјүпјҢи®©зј–иҜ‘еҷЁдә§еҮәеҚій«ҳж•ҲпјҢеҸҲйҖ»иҫ‘жӯЈзЎ®зҡ„д»Јз ҒгҖӮ
2. CPUзҡ„ж ёеҝғжҖқжғіе°ұжҳҜеҸ–жҢҮжү§иЎҢпјҢеҜ№дәҺin-orderзҡ„еҚ•ж ёCPUпјҢ并且没жңүcacheпјҢжұҮзј–жҢҮд»Өзҡ„еҸ–жҢҮе’Ңжү§иЎҢжҳҜдёҘж јжҢүз…§йЎәеәҸиҝӣиЎҢзҡ„пјҢд№ҹе°ұжҳҜиҜҙпјҢжұҮзј–жҢҮд»Өе°ұжҳҜжүҖи§ҒеҚіжүҖеҫ—зҡ„пјҢжұҮзј–жҢҮд»Өзҡ„йҖ»иҫ‘дёҘж јзҡ„иў«CPUжү§иЎҢгҖӮ然иҖҢпјҢйҡҸзқҖи®Ўз®—жңәзі»з»ҹи¶ҠжқҘи¶ҠеӨҚжқӮпјҲеӨҡж ёгҖҒcacheгҖҒsuperscalarгҖҒout-of-orderпјүпјҢдҪҝз”ЁжұҮзј–жҢҮд»Өиҝҷж ·иҙҙиҝ‘еӨ„зҗҶеҷЁзҡ„иҜӯиЁҖд№ҹж— жі•дҝқиҜҒе…¶иў«CPUжү§иЎҢзҡ„з»“жһңзҡ„дёҖиҮҙжҖ§пјҢд»ҺиҖҢйңҖиҰҒзЁӢеәҸе‘ҳе‘ҠзҹҘCPUеҰӮдҪ•дҝқиҜҒйҖ»иҫ‘жӯЈзЎ®гҖӮ
з»јдёҠжүҖиҝ°пјҢmemory barrierжҳҜдёҖз§ҚдҝқиҜҒеҶ…еӯҳи®ҝй—®йЎәеәҸзҡ„дёҖз§Қж–№жі•пјҢи®©зі»з»ҹдёӯзҡ„HW blockпјҲеҗ„дёӘcpuгҖҒDMA controlerгҖҒdeviceзӯүпјүеҜ№еҶ…еӯҳжңүдёҖиҮҙжҖ§зҡ„и§Ҷи§’гҖӮ
йҖҡиҝҮдёҠйқўд»Ӣз»ҚпјҢжҲ‘们зҹҘйҒ“жҲ‘们жүҖзј–еҶҷзҡ„д»Јз Ғдјҡж №жҚ®дёҖе®ҡ规еҲҷеңЁдёҺеҶ…еӯҳзҡ„дәӨдә’иҝҮзЁӢдёӯеҸ‘з”ҹд№ұеәҸгҖӮеҶ…еӯҳжү§иЎҢйЎәеәҸзҡ„еҸҳеҢ–еңЁзј–иҜ‘еҷЁ(зј–иҜ‘жңҹй—ҙ)е’Ңcpu(иҝҗиЎҢжңҹй—ҙ)дёӯйғҪдјҡеҸ‘з”ҹпјҢе…¶зӣ®зҡ„йғҪжҳҜдёәдәҶи®©д»Јз ҒиҝҗиЎҢзҡ„жӣҙеҝ«гҖӮе°ұз®—жҳҜдёәдәҶжҖ§иғҪиҖҢд№ұеәҸпјҢдҪҶжҳҜд№ұеәҸжҖ»жңүдёӘеәҰеҗ§(жҖ»дёҚиғҪе°ҶжҢҮй’Ҳзҡ„еҲқе§ӢеҢ–зҡ„д»Јз Ғд№ұеәҸеңЁдҪҝз”ЁжҢҮй’Ҳзҡ„д»Јз Ғд№ӢеҗҺеҗ§пјҢиҝҷж ·и°Ғиҝҳж•ўеҶҷд»Јз Ғ)гҖӮзј–иҜ‘еҷЁејҖеҸ‘иҖ…е’ҢcpuеҺӮе•ҶйғҪйҒөе®ҲзқҖеҶ…еӯҳд№ұеәҸзҡ„еҹәжң¬еҺҹеҲҷпјҢз®ҖеҚ•еҪ’зәіеҰӮдёӢпјҡ
```
дёҚиғҪж”№еҸҳеҚ•зәҝзЁӢзЁӢеәҸзҡ„жү§иЎҢиЎҢдёә -- дҪҶзәҝзЁӢзЁӢеәҸжҖ»жҳҜж»Ўи¶іProgram Order(жүҖи§ҒеҚіжүҖеҫ—)
```
еңЁжӯӨеҺҹеҲҷжҢҮеҜјдёӢпјҢеҶҷеҚ•зәҝзЁӢд»Јз Ғзҡ„зЁӢеәҸе‘ҳдёҚйңҖиҰҒе…іеҝғеҶ…еӯҳд№ұеәҸзҡ„й—®йўҳгҖӮеңЁеӨҡзәҝзЁӢзј–зЁӢдёӯпјҢз”ұдәҺдҪҝз”Ёдә’ж–ҘйҮҸпјҢдҝЎеҸ·йҮҸе’ҢдәӢ件йғҪеңЁи®ҫи®Ўзҡ„ж—¶еҖҷйғҪйҳ»жӯўдәҶе®ғ们и°ғз”ЁзӮ№дёӯзҡ„еҶ…еӯҳд№ұеәҸ(е·Із»ҸйҡҗејҸеҢ…еҗ«еҗ„з§Қmemery barrier)пјҢеҶ…еӯҳд№ұеәҸзҡ„й—®йўҳеҗҢж ·дёҚйңҖиҰҒиҖғиҷ‘дәҶгҖӮеҸӘжңүеҪ“дҪҝз”Ёж— й”Ғ(lock-free)жҠҖжңҜж—¶вҖ“еҶ…еӯҳеңЁзәҝзЁӢй—ҙе…ұдә«иҖҢжІЎжңүд»»дҪ•зҡ„дә’ж–ҘйҮҸпјҢеҶ…еӯҳд№ұеәҸзҡ„ж•ҲжһңжүҚдјҡжҳҫйңІж— з–‘пјҢиҝҷж ·жҲ‘们жүҚйңҖиҰҒиҖғиҷ‘еңЁеҗҲйҖӮзҡ„ең°ж–№еҠ е…ҘеҗҲйҖӮзҡ„memery barrierгҖӮ
6.1.1 зј–иҜ‘жңҹд№ұеәҸ
иҖғиҷ‘дёӢйқўдёҖж®өд»Јз Ғпјҡ
```
int Value = 0;
int IsPublished = 0;
void sendValue(int x)
{
Value = x;
IsPublished = 1;
}
int tryRecvValue()
{
if (IsPublished)
{
return Value;
}
return -1; // or some other value to mean not yet received
}
```
еңЁеҮәзҺ°зј–иҜ‘жңҹд№ұеәҸзҡ„ж—¶еҖҷпјҢsendValueеҸҜиғҪеҸҳжҲҗеҰӮдёӢпјҡ
```
void sendValue(int x)
{
IsPublished = 1;
Value = x;
}
```
еҜ№дәҺдҪҶзәҝзЁӢиҖҢиЁҖпјҢиҝҷж ·зҡ„д№ұеәҸжҳҜдёҚдјҡжңүеҪұе“Қзҡ„пјҢеӣ дёәsendValue(10)и°ғз”ЁеҗҺпјҢIsPublished == 1; Value == 10пјӣиҝҷж—¶и°ғз”ЁtryRecvValue()е°ұдјҡеҫ—еҲ°10е’Ңд№ұеәҸеүҚжҳҜдёҖж ·зҡ„з»“жһңгҖӮдҪҶжҳҜеҜ№дәҺеӨҡзәҝзЁӢпјҢзәҝзЁӢ1и°ғз”ЁsendValue(10)пјҢ зәҝзЁӢ2и°ғз”ЁtryRecvValue()пјҢеҪ“зәҝзЁӢ1жү§иЎҢе®ҢIsPublished = 1;зҡ„ж—¶еҖҷпјҢзәҝзЁӢ2и°ғз”ЁtryRecvValue()е°ұдјҡеҫ—еҲ°Valueзҡ„еҲқе§Ӣй»ҳи®ӨеҖј0пјҢиҝҷе’ҢзЁӢеәҸеҺҹжң¬йҖ»иҫ‘иҝқиғҢпјҢдәҺжҳҜжҲ‘们еҝ…йЎ»еҠ дёҠзј–иҜ‘еҷЁзҡ„barrierжқҘйҳІжӯўзј–иҜ‘еҷЁзҡ„д№ұеәҸдјҳеҢ–пјҡ
```
#define COMPILER_BARRIER() asm volatile("" ::: "memory")
int Value;
int IsPublished = 0;
void sendValue(int x)
{
Value = x;
COMPILER_BARRIER(); // prevent reordering of stores
IsPublished = 1;
}
int tryRecvValue()
{
if (IsPublished)
{
COMPILER_BARRIER(); // prevent reordering of loads
return Value;
}
return -1; // or some other value to mean not yet received
}
```
дёӢйқўд№ҹжҳҜдёҖдёӘзј–иҜ‘еҷЁд№ұеәҸзҡ„дҫӢеӯҗ(еңЁGcc4.8.5дёӢ gcc -O2 -c -S compile_reordering.cpp)пјҡ
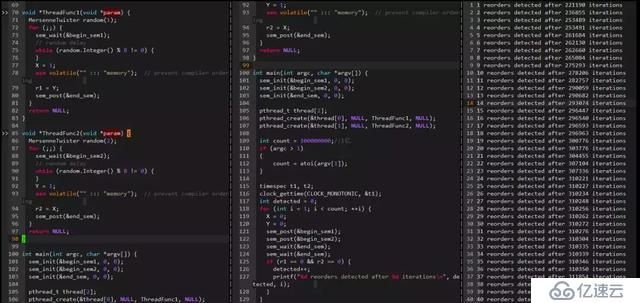
еҸҜд»ҘзңӢеҮәпјҢеңЁејҖеҗҜ-o2зј–иҜ‘еҷЁдјҳеҢ–йҖүйЎ№ж—¶пјҢеҶ…еӯҳдјҡеҸ‘з”ҹд№ұеәҸпјҢеңЁеҶҷеҸҳйҮҸAд№ӢеүҚдјҡе…ҲеҶҷеҸҳйҮҸBгҖӮ
6.1.2 иҝҗиЎҢжңҹд№ұеәҸ
дёӢйқўзңӢдёҖдёӘиҝҗиЎҢжңҹCPUд№ұеәҸзҡ„дҫӢеӯҗпјҡ
еҸҜд»ҘзңӢеҮәеңЁ22WеӨҡж¬Ўиҝӯд»ЈеҗҺжЈҖжөӢеҲ°дёҖж¬Ўд№ұеәҸпјҢд№ұеәҸй—ҙйҡ”еңЁж‘Үж‘ҶдёҚе®ҡгҖӮ
6.2 Why Memory Barriersпјҹ
6.2.1 зҺ°д»ЈеӨ„зҗҶеҷЁcacheжһ¶жһ„
йҖҡиҝҮдёҠйқўпјҢжҲ‘们зҹҘйҒ“еӯҳеңЁдёӨз§Қзұ»еһӢзҡ„Memory Barriersпјҡзј–иҜ‘еҷЁзҡ„Memory BarrierгҖҒеӨ„зҗҶеҷЁзҡ„Memory BarrierгҖӮеҜ№дәҺзј–иҜ‘еҷЁзҡ„Memory BarrierжҜ”иҫғеҘҪзҗҶи§ЈпјҢе°ұжҳҜйҳІжӯўзј–иҜ‘еҷЁдёәдәҶдјҳеҢ–иҖҢе°Ҷд»Јз Ғжү§иЎҢи°ғж•ҙд№ұеәҸгҖӮиҖҢеӨ„зҗҶеҷЁзҡ„Memory BarrierжҳҜйҳІжӯўCPUжҖҺж ·зҡ„д№ұеәҸе‘ўпјҹCPUзҡ„еҶ…еӯҳд№ұеәҸжҳҜжҖҺд№ҲжқҘзҡ„пјҹ
д№ұеәҸдјҡжңүй—®йўҳжң¬иҙЁдёҠжҳҜиҜ»еҲ°дәҶиҖҒзҡ„ж•°жҚ®пјҢжҲ–иҖ…жҳҜдёҖйғЁеҲҶиҜ»еҲ°ж–°зҡ„дёҖйғЁеҲҶиҜ»еҲ°иҖҒзҡ„ж•°жҚ®пјҢдҫӢеҰӮпјҡдёҠйқўзҡ„дҫӢеӯҗдёӯпјҢе·Із»ҸиҜ»еҲ°дәҶIsPublishedзҡ„ж–°еҖјпјҢеҚҙиҝҳжҳҜиҜ»еҲ°дәҶValueиҖҒзҡ„еҖјпјҢд»ҺиҖҢеј•иө·й—®йўҳгҖӮиҝҷз§Қж•°жҚ®дёҚдёҖиҮҙжҖҺд№ҲжқҘзҡ„е‘ўпјҹзӣёдҝЎиҝҷдёӘж—¶еҖҷеӨ§е®¶и„‘жө·йҮҢе·Із»Ҹжө®зҺ°еҮәдёҖдёӘиҜҚдәҶпјҡCacheгҖӮ
йҰ–е…ҲжҲ‘们жқҘзңӢзңӢзҺ°д»ЈеӨ„зҗҶеҷЁеҹәжң¬зҡ„cacheжһ¶жһ„

зҺ°д»ЈеӨ„зҗҶеҷЁдёәдәҶејҘиЎҘеҶ…еӯҳйҖҹеәҰдҪҺдёӢзҡ„зјәйҷ·пјҢеј•е…ҘCacheжқҘжҸҗй«ҳеӨ„зҗҶеҷЁи®ҝй—®зЁӢеәҸе’Ңж•°жҚ®зҡ„йҖҹеәҰпјҢCacheдҪңдёәиҝһжҺҘеҶ…ж ёе’ҢеҶ…еӯҳзҡ„жЎҘжўҒпјҢжһҒеӨ§жҸҗеҚҮдәҶзЁӢеәҸзҡ„иҝҗиЎҢйҖҹеәҰгҖӮдёәд»Җд№ҲеӨ„зҗҶеҷЁеҶ…йғЁеҠ дёҖдёӘйҖҹеәҰеҝ«пјҢе®№йҮҸе°Ҹзҡ„cacheе°ұиғҪжҸҗйҖҹе‘ўпјҹиҝҷйҮҢеҹәдәҺзЁӢеәҸзҡ„дёӨдёӘзү№жҖ§пјҡж—¶й—ҙзҡ„еұҖйғЁжҖ§(Temporal locality)е’Ңз©әй—ҙзҡ„еұҖйғЁжҖ§(Spatial)
```
[1] ж—¶й—ҙзҡ„еұҖйғЁжҖ§(Temporal locality)пјҡеҰӮжһңжҹҗдёӘж•°жҚ®иў«и®ҝй—®дәҶпјҢйӮЈд№ҲдёҚд№…зҡ„е°ҶжқҘе®ғеҫҲжңүеҸҜиғҪиў«еҶҚж¬Ўи®ҝй—®еҲ°гҖӮе…ёеһӢзҡ„дҫӢеӯҗе°ұжҳҜеҫӘзҺҜпјҢеҫӘзҺҜзҡ„д»Јз Ғиў«еӨ„зҗҶеҷЁйҮҚеӨҚжү§иЎҢпјҢе°ҶеҫӘзҺҜд»Јз Ғж”ҫеңЁCacheдёӯпјҢйӮЈд№ҲеҸӘжҳҜеңЁз¬¬дёҖж¬Ўзҡ„ж—¶еҖҷйңҖиҰҒиҖ—ж—¶иҫғй•ҝеҺ»еҶ…еӯҳеҸ–пјҢд»ҘеҗҺиҝҷдәӣд»Јз ҒйғҪиғҪиў«еҶ…ж ёд»Һcacheдёӯеҝ«йҖҹи®ҝй—®еҲ°гҖӮ
[2] з©әй—ҙзҡ„еұҖйғЁжҖ§(Spatial)пјҡеҰӮжһңжҹҗдёӘж•°жҚ®иў«и®ҝй—®дәҶпјҢйӮЈд№Ҳе®ғзӣёдёҙзҡ„ж•°жҚ®еҫҲеҸҜиғҪеҫҲеҝ«иў«и®ҝй—®еҲ°гҖӮе…ёеһӢзҡ„дҫӢеӯҗе°ұжҳҜж•°з»„пјҢж•°з»„дёӯзҡ„е…ғзҙ еёёеёёе®үиЈ…йЎәеәҸдҫқж¬Ўиў«зЁӢеәҸи®ҝй—®гҖӮ
```
зҺ°д»ЈеӨ„зҗҶеҷЁдёҖиҲ¬жҳҜеӨҡдёӘж ёеҝғCoreпјҢжҜҸдёӘCoreеңЁе№¶еҸ‘жү§иЎҢдёҚеҗҢзҡ„д»Јз Ғе’Ңи®ҝй—®дёҚеҗҢзҡ„ж•°жҚ®пјҢдёәдәҶйҡ”зҰ»еҪұе“ҚпјҢжҜҸдёӘcoreйғҪдјҡжңүиҮӘе·ұз§Ғжңүзҡ„cache(еҰӮеӣҫзҡ„L1е’ҢL2)пјҢеҗҢж—¶д№ҹеңЁе®№йҮҸе’ҢеӯҳеӮЁйҖҹеәҰдёҠиҝӣиЎҢдёҖдёӘе№іиЎЎ(е®№йҮҸд№ҹеӨ§еӯҳеӮЁйҖҹеәҰи¶Ҡж…ўпјҢйҖҹеәҰпјҡL1>L2>L3пјҢ е®№йҮҸпјҡL3>L2>L1)пјҢдәҺжҳҜе°ұеҮәзҺ°еӣҫдёӯзҡ„еұӮж¬ЎеҢ–з®ЎзҗҶгҖӮCacheзҡ„еұӮж¬ЎеҢ–еҝ…然еёҰжқҘдёҖдёӘcacheдёҖиҮҙжҖ§зҡ„й—®йўҳпјҡ

еҰӮеӣҫзҡ„дҫӢеӯҗпјҢеҸҳйҮҸX(еҲқе§ӢеҖјжҳҜ3)иў«cacheеңЁCore 0е’ҢCore 1зҡ„з§ҒжңүcacheдёӯпјҢиҝҷж—¶core 0е°ҶXдҝ®ж”№жҲҗ5пјҢеҰӮжһңcore 1дёҚзҹҘйҒ“Xе·Із»Ҹиў«дҝ®ж”№дәҶпјҢ继з»ӯдҪҝз”Ёcacheдёӯзҡ„ж—§еҖјпјҢйӮЈд№ҲеҸҜиғҪдјҡеҜјиҮҙдёҘйҮҚзҡ„й—®йўҳпјҢиҝҷе°ұжҳҜCacheзҡ„дёҚдёҖиҮҙеҜјиҮҙзҡ„гҖӮдёәдәҶдҝқиҜҒCacheзҡ„дёҖиҮҙжҖ§пјҢеӨ„зҗҶеҷЁжҸҗдҫӣдёӨдёӘдҝқиҜҒCacheдёҖиҮҙжҖ§зҡ„еә•еұӮж“ҚдҪңпјҡWrite Invalidateе’ҢWrite UpdateгҖӮ
```
Write Invalidate(зҪ®ж— ж•Ҳ)пјҡеҪ“дёҖдёӘCPU Coreдҝ®ж”№дәҶдёҖд»Ҫж•°жҚ®XпјҢйӮЈд№Ҳе®ғйңҖиҰҒйҖҡзҹҘе…¶д»–coreе°Ҷ他们зҡ„cacheдёӯзҡ„Xи®ҫзҪ®дёәж— ж•Ҳ(invalid)(еҰӮжһңcacheдёӯжңүзҡ„иҜқ)пјҢеҰӮдёӢеӣҫ
```
```
Write Update(еҶҷжӣҙж–°)пјҡеҪ“дёҖдёӘCPU Coreдҝ®ж”№дәҶдёҖд»Ҫж•°жҚ®XпјҢйӮЈд№Ҳе®ғйңҖиҰҒйҖҡзҹҘе…¶д»–coreе°Ҷ他们зҡ„cacheдёӯзҡ„Xжӣҙж–°еҲ°жңҖж–°еҖј(еҰӮжһңcacheдёӯжңүзҡ„иҜқ)пјҢеҰӮдёӢеӣҫ
```
Write Invalidateе’ҢWrite Updateзҡ„жҜ”иҫғпјҡWrite InvalidateжҳҜдёҖз§Қжӣҙдёәз®ҖеҚ•е’ҢиҪ»йҮҸзҡ„е®һзҺ°ж–№ејҸпјҢе®ғдёҚйңҖиҰҒз«ӢеҲ»е°Ҷж•°жҚ®жӣҙж–°еҲ°еӯҳеӮЁдёӯ(иҝҷж—¶дёҖдёӘиҖ—ж—¶иҝҮзЁӢ)пјҢеҰӮжһңеҗҺз»ӯCore 0继з»ӯйңҖиҰҒдҝ®ж”№XиҖҢCore 1е’ҢCore 2еҸҲдёҚеҶҚдҪҝз”Ёж•°жҚ®XдәҶпјҢйӮЈд№ҲиҝҷдёӘUpdateиҝҮзЁӢе°ұжңүзӮ№еҒҡдәҶж— з”ЁеҠҹпјҢиҖҢйҮҮз”Ёwrite invalidateе°ұжӣҙдёәиҪ»йҮҸе’Ңжңүж•ҲгҖӮдёҚиҝҮпјҢз”ұдәҺvalidж Үеҝ—жҳҜеҜ№еә”дёҖдёӘCache lineзҡ„пјҢе°Ҷvalidж Үеҝ—и®ҫзҪ®дёәinvalidеҗҺпјҢиҝҷдёӘcache lineзҡ„е…¶д»–жң¬жқҘжңүж•Ҳзҡ„ж•°жҚ®д№ҹдёҚиғҪиў«дҪҝз”ЁдәҶпјҢеҰӮжһңеӨ„зҗҶдёҚеҘҪе®№жҳ“еҮәзҺ°еүҚйқўжҸҗеҲ°зҡ„False sharing(дјӘе…ұдә«)е’ҢCache pingpongй—®йўҳгҖӮ
6.2.2 cacheдёҖиҮҙжҖ§еҚҸи®®MESI
з”ұдәҺWrite InvalidateжҜ”иҫғз®ҖеҚ•е’ҢиҪ»йҮҸпјҢеӨ§еӨҡж•°зҺ°д»ЈеӨ„зҗҶеҷЁйғҪйҮҮз”ЁWrite Invalidateзӯ–з•ҘпјҢеҹәдәҺWrite InvalidateеӨ„зҗҶеҷЁдјҡжңүдёҖеҘ—е®Ңж•ҙзҡ„еҚҸи®®жқҘдҝқиҜҒCacheзҡ„дёҖиҮҙжҖ§пјҢжҜ”иҫғз»Ҹе…ёзҡ„еҪ“еұһMESIеҚҸи®®пјҢеҘ”и…ҫеӨ„зҗҶеҷЁйҮҮз”Ёе®ғпјҢеҫҲеӨҡе…¶д»–еӨ„зҗҶеҷЁйғҪжҳҜйҮҮз”Ёе®ғзҡ„дёҖдёӘе°ҸеҸҳз§ҚгҖӮ
жҜҸдёӘж ёзҡ„Cacheдёӯзҡ„жҜҸдёӘCache LineйғҪжңү2дёӘж Үеҝ—дҪҚпјҡdirtyж Үеҝ—е’Ңvalidж Үеҝ—дҪҚпјҢдёӨдёӘж Үеҝ—дҪҚеҲҶеҲ«жҸҸиҝ°дәҶCacheе’ҢMemoryй—ҙзҡ„ж•°жҚ®е…ізі»(ж•°жҚ®жҳҜеҗҰжңүж•ҲпјҢж•°жҚ®жҳҜеҗҰиў«дҝ®ж”№)пјҢиҖҢеңЁеӨҡж ёеӨ„зҗҶеҷЁдёӯпјҢеӨҡдёӘж ёдјҡе…ұдә«дёҖдәӣж•°жҚ®пјҢMESIеҚҸи®®е°ұеҢ…еҗ«дәҶжҸҸиҝ°е…ұдә«зҡ„зҠ¶жҖҒгҖӮ
иҝҷж ·еңЁMESIеҚҸи®®дёӯпјҢжҜҸдёӘCache lineйғҪжңү4дёӘзҠ¶жҖҒпјҢеҸҜз”Ё2дёӘbitжқҘиЎЁзӨә(д№ҹе°ұжҳҜпјҢжҜҸдёӘcache lineйҷӨдәҶзү©зҗҶең°еқҖе’Ңе…·дҪ“зҡ„ж•°жҚ®д№ӢеӨ–пјҢиҝҳжңүдёҖдёӘ2-bitзҡ„tagжқҘж ҮиҜҶиҜҘcachelineзҡ„4з§ҚдёҚеҗҢзҡ„зҠ¶жҖҒ)пјҡ
```
[1] M(Modified): cache lineж•°жҚ®жңүж•ҲпјҢдҪҶжҳҜж•°жҚ®иў«дҝ®ж”№иҝҮдәҶпјҢжң¬Cacheдёӯзҡ„ж•°жҚ®жҳҜжңҖж–°зҡ„пјҢеҶ…еӯҳзҡ„ж•°жҚ®жҳҜиҖҒзҡ„пјҢйңҖиҰҒеңЁйҖӮеҪ“ж—¶еҖҷе°ҶCacheж•°жҚ®еҶҷеӣһеҶ…еӯҳгҖӮеӣ жӯӨпјҢеӨ„дәҺmodifiedзҠ¶жҖҒзҡ„cachelineд№ҹеҸҜд»ҘиҜҙжҳҜиў«иҜҘCPUзӢ¬еҚ гҖӮиҖҢеҸҲеӣ дёәеҸӘжңүиҜҘCPUзҡ„cacheдҝқеӯҳдәҶжңҖж–°зҡ„ж•°жҚ®пјҲжңҖз»Ҳзҡ„memoryдёӯйғҪжІЎжңүжӣҙж–°пјүпјҢжүҖд»ҘпјҢиҜҘcacheйңҖиҰҒеҜ№иҜҘж•°жҚ®иҙҹиҙЈеҲ°еә•гҖӮдҫӢеҰӮж №жҚ®иҜ·жұӮпјҢиҜҘcacheе°Ҷж•°жҚ®еҸҠе…¶жҺ§еҲ¶жқғдј йҖ’еҲ°е…¶д»–cacheдёӯпјҢжҲ–иҖ…cacheйңҖиҰҒиҙҹиҙЈе°Ҷж•°жҚ®еҶҷеӣһеҲ°memoryдёӯпјҢиҖҢиҝҷдәӣж“ҚдҪңйғҪйңҖиҰҒеңЁreuseиҜҘcache lineд№ӢеүҚе®ҢжҲҗгҖӮ
[2] E(Exclusive)пјҡcache lineж•°жҚ®жңүж•ҲпјҢ并且cacheе’Ңmemoryдёӯзҡ„ж•°жҚ®жҳҜдёҖиҮҙзҡ„пјҢеҗҢж—¶ж•°жҚ®еҸӘеңЁжң¬cacheдёӯжңүж•ҲгҖӮexclusiveзҠ¶жҖҒе’ҢmodifiedзҠ¶жҖҒйқһеёёзұ»дјјпјҢе”ҜдёҖзҡ„еҢәеҲ«жҳҜеҜ№еә”CPUиҝҳжІЎжңүдҝ®ж”№cachelineдёӯзҡ„ж•°жҚ®пјҢд№ҹжӯЈеӣ дёәиҝҳжІЎжңүдҝ®ж”№ж•°жҚ®пјҢеӣ жӯӨmemoryдёӯеҜ№еә”зҡ„dataд№ҹжҳҜжңҖж–°зҡ„гҖӮеңЁexclusiveзҠ¶жҖҒдёӢпјҢcpuд№ҹеҸҜд»ҘдёҚйҖҡзҹҘе…¶д»–CPU cacheиҖҢзӣҙжҺҘеҜ№cachelineиҝӣиЎҢж“ҚдҪңпјҢеӣ жӯӨпјҢexclusiveзҠ¶жҖҒд№ҹеҸҜд»Ҙиў«и®ӨдёәжҳҜиў«иҜҘCPUзӢ¬еҚ гҖӮз”ұдәҺmemoryдёӯзҡ„ж•°жҚ®е’Ңcachelineдёӯзҡ„ж•°жҚ®йғҪжҳҜжңҖж–°зҡ„пјҢеӣ жӯӨпјҢcpuдёҚйңҖеҜ№exclusiveзҠ¶жҖҒзҡ„cachelineжү§иЎҢеҶҷеӣһзҡ„ж“ҚдҪңжҲ–иҖ…е°Ҷж•°жҚ®д»ҘеҸҠеҪ’еұһжқғиҪ¬дәӨе…¶д»–cpu cacheпјҢиҖҢзӣҙжҺҘreuseиҜҘcachelineпјҲе°Ҷcacheineдёӯзҡ„ж•°жҚ®дёўејғпјҢз”ЁдҪңд»–з”ЁпјүгҖӮ
[3] S(Shared)пјҡcache lineзҡ„ж•°жҚ®жңүж•ҲпјҢ并且cacheе’Ңmemoryдёӯзҡ„ж•°жҚ®жҳҜдёҖиҮҙзҡ„пјҢеҗҢж—¶иҜҘж•°жҚ®еңЁеӨҡдёӘcpu cacheдёӯд№ҹжҳҜжңүж•Ҳзҡ„гҖӮе’ҢexclusiveзҠ¶жҖҒзұ»дјјпјҢеӨ„дәҺshareзҠ¶жҖҒзҡ„cachelineеҜ№еә”зҡ„memoryдёӯзҡ„ж•°жҚ®д№ҹжҳҜжңҖж–°зҡ„пјҢеӣ жӯӨпјҢcpuд№ҹеҸҜд»ҘзӣҙжҺҘдёўејғcachelineдёӯзҡ„ж•°жҚ®иҖҢдёҚеҝ…е°Ҷе…¶иҪ¬дәӨз»ҷе…¶д»–CPU cacheжҲ–иҖ…еҶҷеӣһеҲ°memoryдёӯгҖӮ
[4] I(Invalid)пјҡжң¬cache lineзҡ„ж•°жҚ®е·Із»ҸжҳҜж— ж•Ҳзҡ„гҖӮеӨ„дәҺinvalidзҠ¶жҖҒзҡ„cachelineжҳҜз©әзҡ„пјҢжІЎжңүж•°жҚ®гҖӮеҪ“ж–°зҡ„ж•°жҚ®иҰҒиҝӣе…Ҙcacheзҡ„ж—¶еҖҷпјҢдјҳйҖүзҠ¶жҖҒжҳҜinvalidзҡ„cachelineпјҢд№ӢжүҖд»ҘеҰӮжӯӨжҳҜеӣ дёәеҰӮжһңйҖүдёӯе…¶д»–зҠ¶жҖҒзҡ„cachelineпјҢеҲҷиҜҙжҳҺйңҖиҰҒжӣҝжҚўcachelineж•°жҚ®пјҢиҖҢжңӘжқҘеҰӮжһңеҶҚж¬Ўи®ҝй—®иҝҷдёӘиў«жӣҝжҚўжҺүзҡ„cachelineж•°жҚ®зҡ„ж—¶еҖҷе°ҶйҒҮеҲ°ејҖй”ҖйқһеёёеӨ§зҡ„cache missгҖӮ
```
еңЁMESIеҚҸи®®дёӯпјҢжҜҸдёӘCPUйғҪдјҡзӣ‘еҗ¬жҖ»зәҝ(bus)дёҠзҡ„е…¶д»–CPUеҜ№жҜҸдёӘCache lineзҡ„жүҖжңүж“ҚдҪңпјҢеӣ жӯӨиҜҘеҚҸи®®д№ҹз§°дёәзӣ‘еҗ¬(snoop)еҚҸи®®пјҢзӣ‘еҗ¬еҚҸи®®жҜ”иҫғз®ҖеҚ•пјҢиў«еӨҡе°‘еӨ„зҗҶеҷЁдҪҝз”ЁпјҢдёҚиҝҮзӣ‘еҗ¬еҚҸи®®зҡ„жІҹйҖҡжҲҗжң¬жҜ”иҫғй«ҳгҖӮжңүеҸҰеӨ–дёҖз§ҚеҚҸи®®еҸ«зӣ®еҪ•еҚҸи®®пјҢд»–йҮҮз”ЁйӣҶдёӯз®ЎзҗҶзҡ„ж–№ејҸпјҢе°Ҷcacheе…ұдә«зҡ„дҝЎжҒҜйӣҶдёӯеңЁдёҖиө·пјҢзұ»дјјдёҖдёӘзӣ®еҪ•пјҢеҸӘжңүе…ұдә«зҡ„Cache lineжүҚдјҡдәӨдә’ж•°жҚ®пјҢиҝҷз§ҚеҚҸи®®жІҹйҖҡжҲҗжң¬е°ұеӨ§еӨ§еҮҸе°‘дәҶгҖӮеңЁеҹәдәҺsnoopзҡ„еӨ„зҗҶеҷЁдёӯпјҢжүҖжңүзҡ„CPUйғҪжҳҜеңЁдёҖдёӘе…ұдә«зҡ„жҖ»зәҝдёҠпјҢеӨҡдёӘCPUд№Ӣй—ҙйңҖиҰҒзӣёдә’йҖҡдҝЎд»ҘдҝқиҜҒCache lineеңЁMгҖҒEгҖҒSгҖҒIеӣӣдёӘзҠ¶жҖҒй—ҙжӯЈзЎ®зҡ„иҪ¬жҚўпјҢд»ҺиҖҢдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§гҖӮйҖҡеёёжғ…еҶөдёӢпјҢCPUйңҖиҰҒд»ҘдёӢеҮ дёӘйҖҡдҝЎmessageеҚіеҸҜпјҡ
```
[1] Readж¶ҲжҒҜпјҡread messageз”ЁжқҘиҺ·еҸ–жҢҮе®ҡзү©зҗҶең°еқҖдёҠзҡ„cachelineж•°жҚ®гҖӮ
[2] Read Responseж¶ҲжҒҜпјҡиҜҘж¶ҲжҒҜжҗәеёҰдәҶread messageиҜ·жұӮзҡ„ж•°жҚ®гҖӮread responseеҸҜиғҪжқҘиҮӘmemoryпјҢд№ҹеҸҜиғҪжқҘиҮӘе…¶д»–зҡ„cacheгҖӮдҫӢеҰӮпјҡеҰӮжһңдёҖдёӘcacheжңүread messageиҜ·жұӮзҡ„ж•°жҚ®е№¶дё”иҜҘcachelineзҡ„зҠ¶жҖҒжҳҜmodifiedпјҢйӮЈд№ҲиҜҘcacheеҝ…йЎ»д»Ҙread responseеӣһеә”иҝҷдёӘread messageпјҢеӣ дёәиҜҘcacheдёӯдҝқеӯҳдәҶжңҖж–°зҡ„ж•°жҚ®гҖӮ
[3] Invalidateж¶ҲжҒҜпјҡиҜҘе‘Ҫд»Өз”ЁжқҘе°Ҷе…¶д»–cpu cacheдёӯзҡ„ж•°жҚ®и®ҫе®ҡдёәж— ж•ҲгҖӮиҜҘе‘Ҫд»ӨжҗәеёҰзү©зҗҶең°еқҖзҡ„еҸӮж•°пјҢе…¶д»–CPU cacheеңЁж”¶еҲ°иҜҘе‘Ҫд»ӨеҗҺпјҢеҝ…йЎ»иҝӣиЎҢеҢ№й…ҚпјҢеҸ‘зҺ°иҮӘе·ұзҡ„cachelineдёӯжңүиҜҘзү©зҗҶең°еқҖзҡ„ж•°жҚ®пјҢйӮЈд№Ҳе°ұе°Ҷ其移йҷӨ并用Invalidate Acknowledgeеӣһеә”гҖӮ
[4] Invalidate Acknowledgeж¶ҲжҒҜпјҡ 收еҲ°invalidate messageзҡ„cpu cacheпјҢеңЁз§»йҷӨдәҶе…¶cache lineдёӯзҡ„зү№е®ҡж•°жҚ®д№ӢеҗҺпјҢеҝ…йЎ»еҸ‘йҖҒinvalidate acknowledgeж¶ҲжҒҜгҖӮ
[5] Read Invalidateж¶ҲжҒҜпјҡ иҜҘmessageдёӯд№ҹеҢ…жӢ¬дәҶзү©зҗҶең°еқҖиҝҷдёӘеҸӮж•°пјҢд»ҘдҫҝиҜҙжҳҺе…¶жғіиҰҒиҜ»еҸ–е“ӘдёҖдёӘcachelineж•°жҚ®гҖӮжӯӨеӨ–пјҢиҜҘmessageиҝҳеҗҢж—¶жңүinvalidate messageзҡ„еҠҹж•ҲпјҢеҚіе…¶д»–зҡ„cacheеңЁж”¶еҲ°иҜҘе‘Ҫд»ӨеҗҺпјҢ移йҷӨиҮӘе·ұcachelineдёӯзҡ„ж•°жҚ®гҖӮеӣ жӯӨпјҢRead Invalidate messageе®һйҷ…дёҠе°ұжҳҜread пјӢ invalidateгҖӮеҸ‘йҖҒRead Invalidateд№ӢеҗҺпјҢcacheжңҹжңӣ收еҲ°дёҖдёӘread responseд»ҘеҸҠеӨҡдёӘinvalidate acknowledgeгҖӮ
[6] Writebackж¶ҲжҒҜпјҡ иҜҘmessageеҢ…жӢ¬дёӨдёӘеҸӮж•°пјҢдёҖдёӘжҳҜең°еқҖпјҢеҸҰеӨ–дёҖдёӘжҳҜеҶҷеӣһзҡ„ж•°жҚ®гҖӮиҜҘж¶ҲжҒҜз”ЁеңЁmodifiedзҠ¶жҖҒзҡ„cachelineиў«й©ұйҖҗеҮәеўғпјҲз»ҷе…¶д»–ж•°жҚ®и…ҫеҮәең°ж–№пјүзҡ„ж—¶еҖҷеҸ‘еҮәпјҢиҜҘе‘ҪеҗҚз”ЁжқҘе°ҶжңҖж–°зҡ„ж•°жҚ®еҶҷеӣһеҲ°memoryпјҲжҲ–иҖ…е…¶д»–зҡ„CPU cacheдёӯпјүгҖӮ
```
ж №жҚ®protocol messageзҡ„еҸ‘йҖҒе’ҢжҺҘ收жғ…еҶөпјҢcachelineдјҡеңЁвҖңmodifiedвҖқ, вҖңexclusiveвҖқ, вҖңsharedвҖқ, е’Ң вҖңinvalidвҖқиҝҷеӣӣдёӘзҠ¶жҖҒд№Ӣй—ҙиҝҒ移пјҢе…·дҪ“еҰӮдёӢеӣҫжүҖзӨәпјҡ
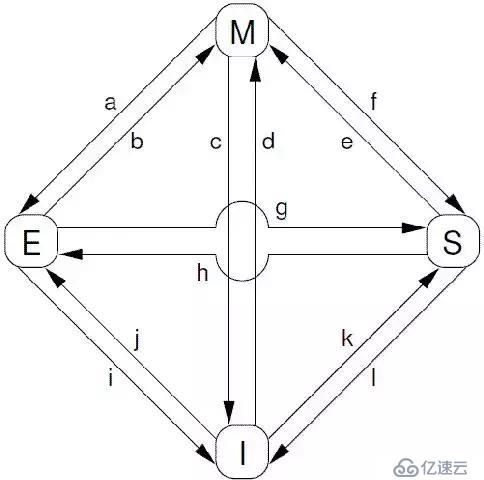
еҜ№дёҠеӣҫдёӯзҡ„зҠ¶жҖҒиҝҒ移解йҮҠеҰӮдёӢпјҡ
```
[a] Transition (a)пјҡcacheеҸҜд»ҘйҖҡиҝҮwriteback transactionе°ҶдёҖдёӘcachelineзҡ„ж•°жҚ®еҶҷеӣһеҲ°memoryдёӯпјҲжҲ–иҖ…дёӢдёҖзә§cacheдёӯпјүпјҢиҝҷж—¶еҖҷпјҢиҜҘcachelineзҡ„зҠ¶жҖҒд»ҺModifiedиҝҒ移еҲ°ExclusiveзҠ¶жҖҒгҖӮеҜ№дәҺcpuиҖҢиЁҖпјҢcachelineдёӯзҡ„ж•°жҚ®д»Қ然жҳҜжңҖж–°зҡ„пјҢиҖҢдё”жҳҜиҜҘcpuзӢ¬еҚ зҡ„пјҢеӣ жӯӨеҸҜд»ҘдёҚйҖҡзҹҘе…¶д»–cpu cacheиҖҢзӣҙжҺҘдҝ®ж”№д№ӢгҖӮ
[b] Transition (b)пјҡеңЁExclusiveзҠ¶жҖҒдёӢпјҢcpuеҸҜд»ҘзӣҙжҺҘе°Ҷж•°жҚ®еҶҷе…ҘcachelineпјҢдёҚйңҖиҰҒе…¶д»–ж“ҚдҪңгҖӮзӣёеә”зҡ„пјҢиҜҘcachelineзҠ¶жҖҒд»ҺExclusiveзҠ¶жҖҒиҝҒ移еҲ°ModifiedзҠ¶жҖҒгҖӮиҝҷдёӘзҠ¶жҖҒиҝҒ移иҝҮзЁӢдёҚж¶үеҸҠbusдёҠзҡ„TransactionпјҲеҚіж— йңҖMESI Protocol Messagesзҡ„дәӨдә’пјүгҖӮ
[c] Transition (c)пјҡCPU еңЁжҖ»зәҝдёҠ收еҲ°дёҖдёӘread invalidateзҡ„иҜ·жұӮпјҢеҗҢж—¶пјҢиҜҘиҜ·жұӮжҳҜй’ҲеҜ№дёҖдёӘеӨ„дәҺmodifiedзҠ¶жҖҒзҡ„cachelineпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢCPUеҝ…йЎ»иҜҘcachelineзҠ¶жҖҒи®ҫзҪ®дёәж— ж•ҲпјҢ并且用read responseвҖқе’ҢвҖңinvalidate acknowledgeжқҘеӣһеә”收еҲ°зҡ„read invalidateзҡ„иҜ·жұӮпјҢе®ҢжҲҗж•ҙдёӘbus transactionгҖӮдёҖж—Ұе®ҢжҲҗиҝҷдёӘtransactionпјҢж•°жҚ®иў«йҖҒеҫҖе…¶д»–cpu cacheдёӯпјҢжң¬ең°зҡ„copyе·Із»ҸдёҚеӯҳеңЁдәҶгҖӮ
[d] Transition (d)пјҡCPUйңҖиҰҒжү§иЎҢдёҖдёӘеҺҹеӯҗзҡ„readmodify-writeж“ҚдҪңпјҢ并且其cacheдёӯжІЎжңүзј“еӯҳж•°жҚ®пјҢиҝҷж—¶еҖҷпјҢCPUе°ұдјҡеңЁжҖ»зәҝдёҠеҸ‘йҖҒдёҖдёӘread invalidateз”ЁжқҘиҜ·жұӮж•°жҚ®пјҢеҗҢж—¶жғізӢ¬иҮӘйңёеҚ еҜ№иҜҘж•°жҚ®зҡ„жүҖжңүжқғгҖӮиҜҘCPUзҡ„cacheеҸҜд»ҘйҖҡиҝҮread responseиҺ·еҸ–ж•°жҚ®е№¶еҠ иҪҪcachelineпјҢеҗҢж—¶пјҢдёәдәҶзЎ®дҝқе…¶зӢ¬еҚ зҡ„жқғеҲ©пјҢеҝ…须收йӣҶжүҖжңүе…¶д»–cpuеҸ‘жқҘзҡ„invalidate acknowledgeд№ӢеҗҺпјҲе…¶д»–cpuжІЎжңүlocal copyпјүпјҢе®ҢжҲҗж•ҙдёӘbus transactionгҖӮ
[e] Transition (e)пјҡCPUйңҖиҰҒжү§иЎҢдёҖдёӘеҺҹеӯҗзҡ„readmodify-writeж“ҚдҪңпјҢ并且其local cacheдёӯжңүread onlyзҡ„зј“еӯҳж•°жҚ®пјҲcachelineеӨ„дәҺsharedзҠ¶жҖҒпјүпјҢиҝҷж—¶еҖҷпјҢCPUе°ұдјҡеңЁжҖ»зәҝдёҠеҸ‘йҖҒдёҖдёӘinvalidateиҜ·жұӮе…¶д»–cpuжё…з©әиҮӘе·ұзҡ„local copyпјҢд»Ҙдҫҝе®ҢжҲҗе…¶зӢ¬иҮӘйңёеҚ еҜ№иҜҘж•°жҚ®зҡ„жүҖжңүжқғзҡ„жўҰжғігҖӮеҗҢж ·зҡ„пјҢиҜҘcpuеҝ…须收йӣҶжүҖжңүе…¶д»–cpuеҸ‘жқҘзҡ„invalidate acknowledgeд№ӢеҗҺпјҢжүҚз®—е®ҢжҲҗж•ҙдёӘbus transactionгҖӮ
[f] Transition (f)пјҡеңЁжң¬cpuзӢ¬иҮӘдә«еҸ—зӢ¬еҚ ж•°жҚ®зҡ„ж—¶еҖҷпјҢе…¶д»–зҡ„cpuеҸ‘иө·readиҜ·жұӮпјҢеёҢжңӣиҺ·еҸ–ж•°жҚ®пјҢиҝҷж—¶еҖҷпјҢжң¬cpuеҝ…йЎ»д»Ҙе…¶local cachelineзҡ„ж•°жҚ®еӣһеә”пјҢ并д»Ҙread responseеӣһеә”д№ӢеүҚжҖ»зәҝдёҠзҡ„readиҜ·жұӮгҖӮиҝҷж—¶еҖҷпјҢжң¬cpuеӨұеҺ»дәҶзӢ¬еҚ жқғпјҢиҜҘcachelineзҠ¶жҖҒд»ҺModifiedзҠ¶жҖҒеҸҳжҲҗsharedзҠ¶жҖҒпјҲжңүеҸҜиғҪд№ҹдјҡиҝӣиЎҢеҶҷеӣһзҡ„еҠЁдҪңпјүгҖӮ
[g] Transition (g)пјҡиҝҷдёӘиҝҒ移е’Ңfзұ»дјјпјҢеҸӘдёҚиҝҮејҖе§Ӣcachelineзҡ„зҠ¶жҖҒжҳҜexclusiveпјҢcachelineе’Ңmemoryзҡ„ж•°жҚ®йғҪжҳҜжңҖж–°зҡ„пјҢдёҚеӯҳеңЁеҶҷеӣһзҡ„й—®йўҳгҖӮжҖ»зәҝдёҠзҡ„ж“ҚдҪңд№ҹжҳҜеңЁж”¶еҲ°readиҜ·жұӮд№ӢеҗҺпјҢд»Ҙread responseеӣһеә”гҖӮ
[h] Transition (h)пјҡеҰӮжһңcpuи®ӨдёәиҮӘе·ұеҫҲеҝ«е°ұдјҡеҗҜеҠЁеҜ№еӨ„дәҺsharedзҠ¶жҖҒзҡ„cachelineиҝӣиЎҢwriteж“ҚдҪңпјҢеӣ жӯӨжғіжҸҗеүҚе…ҲйңёеҚ дёҠиҜҘж•°жҚ®гҖӮеӣ жӯӨпјҢиҜҘcpuдјҡеҸ‘йҖҒinvalidateж•Ұдҝғе…¶д»–cpuжё…з©әиҮӘе·ұзҡ„local copyпјҢеҪ“收еҲ°е…ЁйғЁе…¶д»–cpuзҡ„invalidate acknowledgeд№ӢеҗҺпјҢtransactionе®ҢжҲҗпјҢжң¬cpuдёҠеҜ№еә”зҡ„cachelineд»ҺsharedзҠ¶жҖҒеҲҮжҚўexclusiveзҠ¶жҖҒгҖӮиҝҳжңүеҸҰеӨ–дёҖз§Қж–№жі•д№ҹеҸҜд»Ҙе®ҢжҲҗиҝҷдёӘзҠ¶жҖҒеҲҮжҚўпјҡеҪ“жүҖжңүе…¶д»–зҡ„cpuеҜ№е…¶local copyзҡ„cachelineиҝӣиЎҢеҶҷеӣһж“ҚдҪңпјҢеҗҢж—¶е°Ҷcachelineдёӯзҡ„ж•°жҚ®и®ҫдёәж— ж•ҲпјҲдё»иҰҒжҳҜдёәдәҶдёәж–°зҡ„ж•°жҚ®и…ҫдәӣең°ж–№пјүпјҢиҝҷж—¶еҖҷпјҢжң¬cpuеқҗдә«е…¶жҲҗпјҢзӣҙжҺҘиҺ·еҫ—дәҶеҜ№иҜҘж•°жҚ®зҡ„зӢ¬еҚ жқғгҖӮ
[i] Transition (i)пјҡе…¶д»–зҡ„CPUиҝӣиЎҢдёҖдёӘеҺҹеӯҗзҡ„read-modify-writeж“ҚдҪңпјҢдҪҶжҳҜпјҢж•°жҚ®еңЁжң¬cpuзҡ„cachelineдёӯпјҢеӣ жӯӨпјҢе…¶д»–зҡ„йӮЈдёӘCPUдјҡеҸ‘йҖҒread invalidateпјҢиҜ·жұӮеҜ№иҜҘж•°жҚ®д»ҘеҸҠзӢ¬еҚ жқғгҖӮжң¬cpuеӣһйҖҒread responseвҖқе’ҢвҖңinvalidate acknowledgeвҖқпјҢдёҖж–№йқўжҠҠж•°жҚ®иҪ¬з§»еҲ°е…¶д»–cpuзҡ„cacheдёӯпјҢеҸҰеӨ–дёҖж–№йқўпјҢжё…з©әиҮӘе·ұзҡ„cachelineгҖӮ
[j] Transition (j)пјҡcpuжғіиҰҒиҝӣиЎҢwriteзҡ„ж“ҚдҪңдҪҶжҳҜж•°жҚ®дёҚеңЁlocal cacheдёӯпјҢеӣ жӯӨпјҢиҜҘcpuйҰ–е…ҲеҸ‘йҖҒдәҶread invalidateеҗҜеҠЁдәҶдёҖж¬ЎжҖ»зәҝtransactionгҖӮеңЁж”¶еҲ°read responseеӣһеә”жӢҝеҲ°ж•°жҚ®пјҢ并且收йӣҶжүҖжңүе…¶д»–cpuеҸ‘жқҘзҡ„invalidate acknowledgeд№ӢеҗҺпјҲзЎ®дҝқе…¶д»–cpuжІЎжңүlocal copyпјүпјҢе®ҢжҲҗж•ҙдёӘbus transactionгҖӮеҪ“writeж“ҚдҪңе®ҢжҲҗд№ӢеҗҺпјҢиҜҘcachelineзҡ„зҠ¶жҖҒдјҡд»ҺExclusiveзҠ¶жҖҒиҝҒ移еҲ°ModifiedзҠ¶жҖҒгҖӮ
[k] Transition (k)пјҡжң¬CPUжү§иЎҢиҜ»ж“ҚдҪңпјҢеҸ‘зҺ°local cacheжІЎжңүж•°жҚ®пјҢеӣ жӯӨйҖҡиҝҮreadеҸ‘иө·дёҖж¬Ўbus transactionпјҢжқҘиҮӘе…¶д»–зҡ„cpu local cacheжҲ–иҖ…memoryдјҡйҖҡиҝҮread responseеӣһеә”пјҢд»ҺиҖҢе°ҶиҜҘcachelineд»ҺInvalidзҠ¶жҖҒиҝҒ移еҲ°sharedзҠ¶жҖҒгҖӮ
[l] Transition (l)пјҡеҪ“cachelineеӨ„дәҺsharedзҠ¶жҖҒзҡ„ж—¶еҖҷпјҢиҜҙжҳҺеңЁеӨҡдёӘcpuзҡ„local cacheдёӯеӯҳеңЁеүҜжң¬пјҢеӣ жӯӨпјҢиҝҷдәӣcachelineдёӯзҡ„ж•°жҚ®йғҪжҳҜread onlyзҡ„пјҢдёҖж—Ұе…¶дёӯдёҖдёӘcpuжғіиҰҒжү§иЎҢж•°жҚ®еҶҷе…Ҙзҡ„еҠЁдҪңпјҢеҝ…йЎ»е…ҲйҖҡиҝҮinvalidateиҺ·еҸ–иҜҘж•°жҚ®зҡ„зӢ¬еҚ жқғпјҢиҖҢе…¶д»–зҡ„CPUдјҡд»Ҙinvalidate acknowledgeеӣһеә”пјҢжё…з©әж•°жҚ®е№¶е°Ҷе…¶cachelineд»ҺsharedзҠ¶жҖҒдҝ®ж”№жҲҗinvalidзҠ¶жҖҒгҖӮ
```
дёӢйқўйҖҡиҝҮеҮ дёӘдҫӢеӯҗпјҢиҜҙжҳҺдёҖдёӢMESIеҚҸи®®жҳҜжҖҺд№Ҳе·ҘдҪңзҡ„гҖӮCPUжү§иЎҢеәҸеҲ—еҰӮдёӢпјҡ
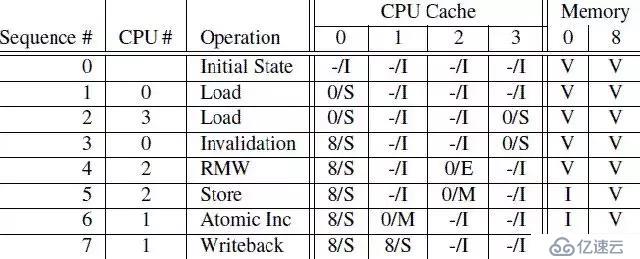
第дёҖеҲ—жҳҜж“ҚдҪңеәҸеҲ—еҸ·пјҢ第дәҢеҲ—жҳҜжү§иЎҢж“ҚдҪңзҡ„CPUпјҢ第дёүеҲ—жҳҜе…·дҪ“жү§иЎҢе“ӘдёҖз§Қж“ҚдҪңпјҢ第еӣӣеҲ—жҸҸиҝ°дәҶеҗ„дёӘcpu local cacheдёӯзҡ„cachelineзҡ„зҠ¶жҖҒпјҲз”Ёmeory address/зҠ¶жҖҒиЎЁзӨәпјүпјҢжңҖеҗҺдёҖеҲ—жҸҸиҝ°дәҶеҶ…еӯҳеңЁ0ең°еқҖе’Ң8ең°еқҖзҡ„ж•°жҚ®еҶ…е®№зҡ„зҠ¶жҖҒпјҡVиЎЁзӨәжҳҜжңҖж–°зҡ„пјҢе’Ңcpu cacheдёҖиҮҙпјҢIиЎЁзӨәдёҚжҳҜжңҖж–°зҡ„еҶ…е®№пјҢжңҖж–°зҡ„еҶ…е®№дҝқеӯҳеңЁcpu cacheдёӯгҖӮ
```
[1] sequence 0пјҡеҲқе§ӢзҠ¶жҖҒдёӢпјҢеҶ…еӯҳең°еқҖ0е’Ң8дҝқеӯҳдәҶжңҖж–°зҡ„ж•°жҚ®пјҢиҖҢ4дёӘCPUзҡ„cache lineйғҪжҳҜinvalid(жІЎcacheд»»дҪ•ж•°жҚ®жҲ–cacheзҡ„ж•°жҚ®йғҪжҳҜиҝҮжңҹж— ж•Ҳзҡ„)гҖӮ
[2] sequence 1пјҡCPU 0еҜ№еҶ…еӯҳең°еқҖ0жү§иЎҢloadж“ҚдҪңпјҢиҝҷж ·еҶ…еӯҳең°еқҖ0зҡ„ж•°жҚ®иў«еҠ иҪҪеҲ°CPU 0зҡ„cache lineдёӯпјҢCPU 0зҡ„cache lineд»ҺInvalidзҠ¶жҖҒеҲҮжҚўеҲ°ShareзҠ¶жҖҒ(иҝҷдёӘж—¶еҖҷпјҢCPU 0зҡ„cache lineе’ҢеҶ…еӯҳең°еқҖ0йғҪжҳҜзӣёеҗҢзҡ„жңҖж–°ж•°жҚ®)гҖӮ
[3] sequence 2пјҡCPU 3д№ҹеҜ№еҶ…еӯҳең°еқҖ0жү§иЎҢloadж“ҚдҪңпјҢиҝҷж ·еҶ…еӯҳең°еқҖ0зҡ„ж•°жҚ®иў«еҠ иҪҪеҲ°CPU 3зҡ„cache lineдёӯпјҢCPU 3зҡ„cache lineд»ҺInvalidзҠ¶жҖҒеҲҮжҚўеҲ°ShareзҠ¶жҖҒ(иҝҷдёӘж—¶еҖҷпјҢCPU 0гҖҒCPU 3зҡ„cache lineе’ҢеҶ…еӯҳең°еқҖ0йғҪжҳҜзӣёеҗҢзҡ„жңҖж–°ж•°жҚ®)гҖӮ
[4] sequence 3пјҡCPU 0жү§иЎҢеҜ№еҶ…еӯҳең°еқҖ8зҡ„loadж“ҚдҪңпјҢ(еҶ…еӯҳең°еқҖ0е’Ң8е…ұз”ЁдёҖдёӘcache line set)з”ұдәҺcache lineе·Із»Ҹеӯҳж”ҫдәҶеҶ…еӯҳең°еқҖ0зҡ„ж•°жҚ®пјҢиҝҷдёӘж—¶еҖҷпјҢCPU 0йңҖиҰҒе°Ҷcache lineзҡ„ж•°жҚ®жё…зҗҶжҺү(Invalidation)д»Ҙдҫҝи…ҫеҮәз©әй—ҙеӯҳж”ҫеҶ…еӯҳең°еқҖ8зҡ„ж•°жҚ®гҖӮз”ұдәҺпјҢеҪ“еүҚcache lineзҡ„зҠ¶жҖҒжҳҜShareпјҢCPU 0дёҚйңҖиҰҒйҖҡзҹҘе…¶д»–CPUпјҢCPU 0еңЁInvalidation cache lineзҡ„ж•°жҚ®еҗҺпјҢе°ұеҠ иҪҪеҶ…еӯҳең°еқҖ8зҡ„ж•°жҚ®еҲ°cache lineдёӯпјҢ并е°Ҷcache lineзҠ¶жҖҒж”№жҲҗShareгҖӮ
[5] sequence 4пјҡCPU 2еҜ№еҶ…еӯҳең°еқҖ0жү§иЎҢloadж“ҚдҪңпјҢз”ұдәҺCPU 2зҹҘйҒ“зЁӢеәҸйҡҸеҗҺдјҡдҝ®ж”№иҜҘеҖјпјҢе®ғйңҖиҰҒзӢ¬еҚ иҜҘж•°жҚ®пјҢеӣ жӯӨCPU 2еҗ‘жҖ»зәҝеҸ‘йҖҒдәҶread invalidateе‘Ҫд»ӨпјҢдёҖж–№йқўиҺ·еҸ–иҜҘж•°жҚ®(иҮӘе·ұзҡ„local cacheдёӯжІЎжңүең°еқҖ0зҡ„ж•°жҚ®)пјҢеҸҰеӨ–пјҢCPU 2жғізӢ¬еҚ иҜҘж•°жҚ®пјҲеӣ дёәйҡҸеҗҺиҰҒwriteпјүгҖӮиҝҷдёӘж“ҚдҪңеҜјиҮҙCPU 3зҡ„cachelineиҝҒ移еҲ°invalidзҠ¶жҖҒгҖӮеҪ“然пјҢиҝҷж—¶еҖҷпјҢmemoryд»Қ然жҳҜжңҖж–°зҡ„жңүж•Ҳж•°жҚ®гҖӮ
[6] sequence 5пјҡCPU 2еҜ№еҶ…еӯҳең°еқҖ0жү§иЎҢStoreж“ҚдҪңпјҢз”ұдәҺCPU 2зҡ„cache lineжҳҜExclusiveзҠ¶жҖҒ(еҜ№еҶ…еӯҳең°еқҖ0зҡ„ж•°жҚ®жҳҜзӢ¬еҚ зҠ¶жҖҒзҡ„)пјҢдәҺжҳҜCPU 2еҸҜд»ҘзӣҙжҺҘе°Ҷж–°зҡ„еҖјеҶҷе…Ҙcache lineиҰҶзӣ–иҖҒеҖјпјҢcache lineзҠ¶жҖҒиҪ¬жҚўжҲҗModifiedзҠ¶жҖҒгҖӮ(иҝҷдёӘж—¶еҖҷпјҢеҶ…еӯҳең°еқҖ0дёӯзҡ„ж•°жҚ®е·Із»ҸжҳҜInvalidзҡ„пјҢе…¶д»–CPUеҰӮжһңжғіloadеҶ…еӯҳең°еқҖ0зҡ„ж•°жҚ®пјҢдёҚиғҪзӣҙжҺҘд»ҺеҶ…еӯҳең°еқҖ0еҠ иҪҪж•°жҚ®дәҶпјҢйңҖиҰҒе—…жҺў(snoop)зҡ„ж–№ејҸд»ҺCPU 2зҡ„local cacheдёӯиҺ·еҸ–гҖӮ
[7] sequence 6пјҡCPU 1еҜ№еҶ…еӯҳең°еқҖ0жү§иЎҢдёҖдёӘеҺҹеӯҗеҠ ж“ҚдҪңгҖӮиҝҷж—¶еҖҷCPU 1дјҡеҸ‘еҮәread invalidateе‘Ҫд»ӨпјҢе°Ҷең°еқҖ0зҡ„ж•°жҚ®д»ҺCPU 2зҡ„cache lineдёӯе—…жҺўеҫ—еҲ°пјҢеҗҢж—¶йҖҡиҝҮinvalidateе…¶д»–CPU local cacheзҡ„еҶ…е®№иҖҢиҺ·еҫ—зӢ¬еҚ жҖ§зҡ„ж•°жҚ®и®ҝй—®жқғгҖӮиҝҷж—¶еҖҷпјҢCPU 2дёӯзҡ„cache lineзҠ¶жҖҒеҸҳжҲҗinvalidзҠ¶жҖҒпјҢиҖҢCPU 1зҡ„cache lineе°Ҷд»ҺinvalidзҠ¶жҖҒиҝҒ移еҲ°modifiedзҠ¶жҖҒгҖӮ
[8] sequence 7пјҡCPU 1еҜ№еҶ…еӯҳең°еқҖ8жү§иЎҢloadж“ҚдҪңгҖӮз”ұдәҺcache lineе·Із»Ҹеӯҳж”ҫдәҶеҶ…еӯҳең°еқҖ0зҡ„ж•°жҚ®пјҢ并且иҜҘзҠ¶жҖҒжҳҜmodifiedзҡ„пјҢCPU 1йңҖиҰҒе°Ҷcache lineзҡ„ж•°жҚ®еҶҷеӣһең°еқҖ0пјҢдәҺжҳҜжү§иЎҢwrite backж“ҚдҪңе°Ҷең°еқҖ0зҡ„ж•°жҚ®еҶҷеӣһеҲ°memory(иҝҷдёӘж—¶еҖҷпјҢеҶ…еӯҳең°еқҖ0дёӯзҡ„ж•°жҚ®д»ҺInvalidеҸҳжҲҗжңүж•Ҳзҡ„)гҖӮжҺҘзқҖпјҢCPU 1еҸ‘еҮәreadе‘Ҫд»ӨпјҢд»ҺCPU 0дёӯеҫ—еҲ°еҶ…еӯҳең°еқҖ8зҡ„ж•°жҚ®пјҢ并еҶҷе…ҘиҮӘе·ұзҡ„cache lineпјҢcache lineзҠ¶жҖҒиҪ¬жҚўжҲҗShareгҖӮ
```
йҖҡиҝҮдёҠйқўзҡ„дҫӢеӯҗпјҢжҲ‘们еҸ‘зҺ°пјҢеҜ№дәҺжҹҗдәӣзү№е®ҡең°еқҖзҡ„ж•°жҚ®пјҲеңЁдёҖдёӘcache lineдёӯпјүйҮҚеӨҚзҡ„иҝӣиЎҢиҜ»еҶҷпјҢиҝҷз§Қз»“жһ„еҸҜд»ҘиҺ·еҫ—еҫҲеҘҪзҡ„жҖ§иғҪ(дҫӢеҰӮпјҢеңЁsequence 5пјҢCPU 2еҸҚеӨҚеҜ№еҶ…еӯҳең°еқҖ0иҝӣиЎҢstoreж“ҚдҪңе°ҶиҺ·еҫ—еҫҲеҘҪзҡ„жҖ§иғҪпјҢеӣ дёәпјҢжҜҸж¬Ўstoreж“ҚдҪңпјҢCPU 2д»…д»…йңҖиҰҒе°Ҷж–°еҖјеҶҷе…ҘиҮӘе·ұзҡ„local cacheеҚіеҸҜ)пјҢдёҚиҝҮпјҢеҜ№дәҺ第дёҖж¬ЎеҶҷпјҢе…¶жҖ§иғҪйқһеёёе·®пјҢеҰӮеӣҫпјҡ
cpu 0еҸ‘иө·дёҖж¬ЎеҜ№жҹҗдёӘең°еқҖзҡ„еҶҷж“ҚдҪңпјҢдҪҶжҳҜlocal cacheжІЎжңүж•°жҚ®пјҢиҜҘж•°жҚ®еңЁCPU 1зҡ„local cacheдёӯпјҢеӣ жӯӨпјҢдёәдәҶе®ҢжҲҗеҶҷж“ҚдҪңпјҢCPU 0еҸ‘еҮәinvalidateзҡ„е‘Ҫд»ӨпјҢinvalidateе…¶д»–CPUзҡ„cacheж•°жҚ®гҖӮеҸӘжңүе®ҢжҲҗдәҶиҝҷдәӣжҖ»зәҝдёҠзҡ„transactionд№ӢеҗҺпјҢCPU 0жүҚиғҪжӯЈеңЁеҸ‘иө·еҶҷзҡ„ж“ҚдҪңпјҢиҝҷжҳҜдёҖдёӘжј«й•ҝзҡ„зӯүеҫ…иҝҮзЁӢгҖӮ
6.2.3 Store Buffer
еҜ№дәҺCPU 0жқҘиҜҙпјҢиҝҷж ·зҡ„жј«й•ҝзӯүеҫ…жҳҫеҫ—жңүзӮ№жІЎеҝ…иҰҒпјҢеӣ дёәпјҢCPU 1дёӯзҡ„cache lineдҝқеӯҳжңүд»Җд№Ҳж ·еӯҗзҡ„ж•°жҚ®пјҢе…¶е®һйғҪжІЎжңүж„Ҹд№үпјҢиҝҷдёӘеҖјйғҪдјҡиў«CPU 0ж–°еҶҷе…Ҙзҡ„еҖјиҰҶзӣ–зҡ„гҖӮдёәдәҶз»ҷCPU 0жҸҗйҖҹпјҢйңҖиҰҒе°Ҷиҝҷз§ҚеҗҢжӯҘйҳ»еЎһзӯүеҫ…пјҢеҸҳжҲҗејӮжӯҘеӨ„зҗҶгҖӮдәҺжҳҜпјҢ硬件е·ҘзЁӢеёҲпјҢдҝ®ж”№CPUжһ¶жһ„пјҢеңЁCPUе’Ңcacheд№Ӣй—ҙеўһеҠ store bufferиҝҷдёӘHW blockпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
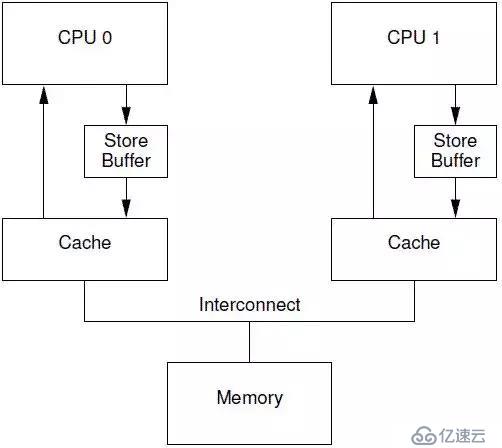
дёҖж—ҰеўһеҠ дәҶstore bufferпјҢйӮЈд№Ҳcpu 0ж— йңҖзӯүеҫ…е…¶д»–CPUзҡ„зӣёеә”пјҢеҸӘйңҖиҰҒе°ҶиҰҒдҝ®ж”№зҡ„еҶ…е®№ж”ҫе…Ҙstore bufferпјҢ然еҗҺ继з»ӯжү§иЎҢе°ұOKдәҶгҖӮеҪ“cache lineе®ҢжҲҗдәҶbus transactionпјҢ并жӣҙж–°дәҶcache lineзҡ„зҠ¶жҖҒеҗҺпјҢиҰҒдҝ®ж”№зҡ„ж•°жҚ®е°Ҷд»Һstore bufferиҝӣе…Ҙcache lineгҖӮеј•е…ҘдәҶstore buffпјҢеёҰжқҘдәҶдёҖдәӣеӨҚжқӮжҖ§пјҢдёҖдёҚе°ҸеҝғпјҢдјҡеёҰжқҘжң¬ең°ж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳгҖӮжҲ‘们е…ҲзңӢзңӢдёӢйқўзҡ„д»Јз Ғпјҡ
```
1 a = 1;
2 b = a + 1;
3 assert(b == 2);
aе’ҢbйғҪжҳҜеҲқе§ӢеҢ–дёә0пјҢ并且еҸҳйҮҸaеңЁCPU 1зҡ„cache lineдёӯпјҢеҸҳйҮҸbеңЁCPU 0зҡ„cachelineдёӯгҖӮ
```
еҰӮжһңcpuжү§иЎҢдёҠиҝ°д»Јз ҒпјҢйӮЈд№Ҳ第дёүиЎҢзҡ„assertдёҚеә”иҜҘеӨұиҙҘпјҢдёҚиҝҮпјҢеҰӮжһңCPUи®ҫи®ЎиҖ…дҪҝз”ЁдёҠеӣҫдёӯзҡ„йӮЈдёӘйқһеёёз®ҖеҚ•зҡ„store bufferз»“жһ„пјҢйӮЈд№ҲдҪ еә”иҜҘдјҡйҒҮеҲ°вҖңжғҠе–ңвҖқпјҲassertеӨұиҙҘдәҶпјүгҖӮе…·дҪ“зҡ„жү§иЎҢеәҸеҲ—иҝҮзЁӢеҰӮдёӢпјҡ
```
[1] CPU 0жү§иЎҢa=1зҡ„иөӢеҖјж“ҚдҪң, CPU 0йҒҮеҲ°cache miss
[2] CPU 0еҸ‘йҖҒread invalidateж¶ҲжҒҜд»Ҙдҫҝд»ҺCPU 1йӮЈйҮҢиҺ·еҫ—ж•°жҚ®пјҢ并invalidе…¶д»–cpuдҝқеӯҳaж•°жҚ®зҡ„local cache lineгҖӮ
[3] з”ұдәҺstore buffзҡ„еӯҳеңЁпјҢCPU 0жҠҠиҰҒеҶҷе…Ҙзҡ„ж•°жҚ®вҖң1вҖқж”ҫе…Ҙstore buffer
[4] CPU 1收еҲ°read invalidateеҗҺеӣһеә”пјҢжҠҠжң¬ең°cache lineзҡ„ж•°жҚ®еҸ‘йҖҒз»ҷCPU 0并清з©әжң¬ең°cacheдёӯaзҡ„ж•°жҚ®гҖӮ
[5] CPU 0жү§иЎҢb = a + 1
[6] CPU 0 收еҲ°жқҘиҮӘCPU 1зҡ„ж•°жҚ®пјҢиҜҘж•°жҚ®жҳҜвҖң0вҖқ
[7] CPU 0д»Һcache lineдёӯеҠ иҪҪaпјҢиҺ·еҫ—0еҖј
[8] CPU 0е°Ҷstore bufferдёӯзҡ„еҖјеҶҷе…Ҙcache lineпјҢиҝҷж—¶еҖҷcacheдёӯзҡ„aеҖјжҳҜвҖң1вҖқ
[9] CPU 0жү§иЎҢaпјӢ1пјҢеҫ—еҲ°1并е°ҶиҜҘеҖјеҶҷе…Ҙb
[10] CPU 0 executes assert(b == 2), which fails. OMGпјҢдҪ жңҹжңӣbзӯүдәҺ2пјҢдҪҶжҳҜе®һйҷ…дёҠbзӯүдәҺдәҶ1
```
еҜјиҮҙиҝҷдёӘй—®йўҳзҡ„ж №жң¬еҺҹеӣ жҳҜжҲ‘们жңүдёӨдёӘaеҖјпјҢдёҖдёӘеңЁcache lineдёӯпјҢдёҖдёӘеңЁstore bufferдёӯгҖӮstore bufferзҡ„еј•е…ҘпјҢиҝқеҸҚдәҶжҜҸдёӘCPUжҢүз…§е…¶и§Ҷи§’жқҘи§ӮеҜҹиҮӘе·ұзҡ„иЎҢдёәзҡ„ж—¶еҖҷеҝ…йЎ»жҳҜз¬ҰеҗҲprogram orderзҡ„еҺҹеҲҷгҖӮдёҖж—ҰиҝқиғҢиҝҷдёӘеҺҹеҲҷпјҢеҜ№иҪҜ件е·ҘзЁӢеёҲиҖҢиЁҖе°ұжҳҜзҒҫйҡҫгҖӮиҝҳеҘҪпјҢжңүвҖқеҘҪеҝғвҖңзҡ„硬件е·ҘзЁӢеёҲеё®еҠ©жҲ‘们пјҢдҝ®ж”№дәҶCPUзҡ„и®ҫи®ЎеҰӮдёӢпјҡ
иҝҷз§Қи®ҫи®ЎеҸ«еҒҡstore forwardingпјҢеҪ“CPUжү§иЎҢloadж“ҚдҪңзҡ„ж—¶еҖҷпјҢдёҚдҪҶиҰҒзңӢcacheпјҢиҝҳжңүзңӢstore bufferжҳҜеҗҰжңүеҶ…е®№пјҢеҰӮжһңstore bufferжңүиҜҘж•°жҚ®пјҢйӮЈд№Ҳе°ұйҮҮз”Ёstore bufferдёӯзҡ„еҖјгҖӮжңүдәҶstore forwardingзҡ„и®ҫи®ЎпјҢдёҠйқўзҡ„жӯҘйӘӨ[7]дёӯе°ұеҸҜд»ҘеңЁstore bufferиҺ·еҸ–жӯЈзЎ®зҡ„aеҖјжҳҜвҖқ1вҖңиҖҢдёҚжҳҜвҖқ0вҖңпјҢеӣ жӯӨи®Ўз®—еҫ—еҲ°зҡ„bзҡ„з»“жһңе°ұжҳҜ2пјҢе’ҢжҲ‘们预жңҹзҡ„дёҖиҮҙдәҶгҖӮ
store forwardingи§ЈеҶідәҶCPU 0зҡ„cache lineе’Ңstore bufferй—ҙзҡ„ж•°жҚ®дёҖиҮҙжҖ§й—®йўҳпјҢдҪҶжҳҜпјҢеңЁCPU 1зҡ„и§’еәҰжқҘзңӢпјҢжҳҜеҗҰд№ҹиғҪзңӢеҲ°дёҖиҮҙзҡ„ж•°жҚ®е‘ўпјҹжҲ‘们жқҘзңӢдёӢдёҖдёӘдҫӢеӯҗпјҡ
```
1 void foo(void)
2 {
3 a = 1;
4 b = 1;
5 }
6
7 void bar(void)
8 {
9 while (b == 0) continue;
10 assert(a == 1);
11 }
еҗҢж ·зҡ„пјҢaе’ҢbйғҪжҳҜеҲқе§ӢеҢ–жҲҗ0.
```
жҲ‘们еҒҮи®ҫCPU 0жү§иЎҢfooеҮҪж•°пјҢCPU 1жү§иЎҢbarеҮҪж•°пјҢaеҸҳйҮҸеңЁCPU 1зҡ„cacheдёӯпјҢbеңЁCPU 0 cacheдёӯпјҢжү§иЎҢзҡ„ж“ҚдҪңеәҸеҲ—еҰӮдёӢпјҡ
```
[1] CPU 0жү§иЎҢa=1зҡ„иөӢеҖјж“ҚдҪңпјҢз”ұдәҺaдёҚеңЁlocal cacheдёӯпјҢеӣ жӯӨпјҢCPU 0е°ҶaеҖјж”ҫеҲ°store bufferдёӯд№ӢеҗҺпјҢеҸ‘йҖҒдәҶread invalidateе‘Ҫд»ӨеҲ°жҖ»зәҝдёҠеҺ»гҖӮ
[2] CPU 1жү§иЎҢ while (b == 0) еҫӘзҺҜпјҢз”ұдәҺbдёҚеңЁCPU 1зҡ„cacheдёӯпјҢеӣ жӯӨпјҢCPUеҸ‘йҖҒдёҖдёӘread messageеҲ°жҖ»зәҝдёҠпјҢзңӢзңӢжҳҜеҗҰеҸҜд»Ҙд»Һе…¶д»–cpuзҡ„local cacheдёӯжҲ–иҖ…memoryдёӯиҺ·еҸ–ж•°жҚ®гҖӮ
[3] CPU 0继з»ӯжү§иЎҢb=1зҡ„иөӢеҖјиҜӯеҸҘпјҢз”ұдәҺbе°ұеңЁиҮӘе·ұзҡ„local cacheдёӯпјҲcachelineеӨ„дәҺmodifiedзҠ¶жҖҒжҲ–иҖ…exclusiveзҠ¶жҖҒпјүпјҢеӣ жӯӨCPU0еҸҜд»ҘзӣҙжҺҘж“ҚдҪңе°Ҷж–°зҡ„еҖј1еҶҷе…Ҙcache lineгҖӮ
[4] CPU 0收еҲ°дәҶread messageпјҢе°ҶжңҖж–°зҡ„bеҖјвҖқ1вҖңеӣһйҖҒз»ҷCPU 1пјҢеҗҢж—¶е°Ҷb cachelineзҡ„зҠ¶жҖҒи®ҫе®ҡдёәshared
[5] CPU 1收еҲ°дәҶжқҘиҮӘCPU 0зҡ„read responseж¶ҲжҒҜпјҢе°ҶbеҸҳйҮҸзҡ„жңҖж–°еҖјвҖқ1вҖңеҖјеҶҷе…ҘиҮӘе·ұзҡ„cachelineпјҢзҠ¶жҖҒдҝ®ж”№дёәsharedгҖӮ
[6] з”ұдәҺbеҖјзӯүдәҺ1дәҶпјҢеӣ жӯӨCPU 1и·іеҮәwhile (b == 0)зҡ„еҫӘзҺҜпјҢ继з»ӯеүҚиЎҢгҖӮ
[7] CPU 1жү§иЎҢassert(a == 1)пјҢиҝҷж—¶еҖҷCPU 1зҡ„local cacheдёӯиҝҳжҳҜж—§зҡ„aеҖјпјҢеӣ жӯӨassert(a == 1)еӨұиҙҘгҖӮ
[8] CPU 1收еҲ°дәҶжқҘиҮӘCPU 0зҡ„read invalidateж¶ҲжҒҜпјҢд»ҘaеҸҳйҮҸзҡ„еҖјиҝӣиЎҢеӣһеә”пјҢеҗҢж—¶жё…з©әиҮӘе·ұзҡ„cachelineпјҢдҪҶжҳҜиҝҷе·Із»ҸеӨӘжҷҡдәҶгҖӮ
[9] CPU 0收еҲ°дәҶread responseе’Ңinvalidate ackзҡ„ж¶ҲжҒҜд№ӢеҗҺпјҢе°Ҷstore bufferдёӯзҡ„aзҡ„жңҖж–°еҖјвҖқ1вҖңж•°жҚ®еҶҷе…ҘcachelineпјҢ然并еҚөпјҢCPU 1е·Із»Ҹassertion failдәҶгҖӮ
```
CPU 1еҮәзҺ°ејӮеёёзҡ„assertion failзҡ„ж №жң¬еҺҹеӣ жҳҜпјҢCPU 0еңЁеҸ‘еҮәread invalidate messageеҗҺпјҢ并没жңүзӯүеҫ…CPU 1收еҲ°пјҢе°ұ继з»ӯжү§иЎҢе°Ҷbж”№еҶҷдёә1пјҢд№ҹе°ұжҳҜstore bufferзҡ„еӯҳеңЁеҜјиҮҙдәҶCPU 1е…ҲзңӢеҲ°дәҶbдҝ®ж”№дёә1пјҢеҗҺзңӢеҲ°aиў«дҝ®ж”№дёә1гҖӮйҒҮеҲ°иҝҷж ·зҡ„й—®йўҳпјҢCPUи®ҫи®ЎиҖ…д№ҹдёҚиғҪзӣҙжҺҘеё®д»Җд№Ҳеҝҷ(йҷӨйқһеҺ»жҺүstore buffer)пјҢжҜ•з«ҹCPU并дёҚзҹҘйҒ“е“ӘдәӣеҸҳйҮҸжңүзӣёе…іжҖ§пјҢиҝҷдәӣеҸҳйҮҸжҳҜеҰӮдҪ•зӣёе…ізҡ„гҖӮдёҚиҝҮCPUи®ҫи®ЎиҖ…еҸҜд»Ҙй—ҙжҺҘжҸҗдҫӣдёҖдәӣе·Ҙе…·и®©иҪҜ件е·ҘзЁӢеёҲжқҘжҺ§еҲ¶иҝҷдәӣзӣёе…іжҖ§гҖӮиҝҷдәӣе·Ҙе…·е°ұжҳҜmemory-barrierжҢҮд»ӨгҖӮиҰҒжғізЁӢеәҸжӯЈеёёиҝҗиЎҢпјҢеҝ…йЎ»еўһеҠ дёҖдәӣmemory barrierзҡ„ж“ҚдҪңпјҢе…·дҪ“еҰӮдёӢпјҡ
```
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12}
```
smp_mb() иҝҷдёӘеҶ…еӯҳеұҸйҡңзҡ„ж“ҚдҪңдјҡеңЁжү§иЎҢеҗҺз»ӯзҡ„storeж“ҚдҪңд№ӢеүҚпјҢйҰ–е…Ҳflush store bufferпјҲд№ҹе°ұжҳҜе°Ҷд№ӢеүҚзҡ„еҖјеҶҷе…ҘеҲ°cachelineдёӯпјүгҖӮиҫҫеҲ°иҝҷдёӘзӣ®ж ҮжңүдёӨз§Қж–№жі•пјҡ
```
[1] CPUйҒҮеҲ°smp_mbеҶ…еӯҳеұҸйҡңеҗҺпјҢйңҖиҰҒзӯүеҫ…store bufferдёӯзҡ„ж•°жҚ®е®ҢжҲҗtransaction并е°Ҷstrore bufferдёӯзҡ„ж•°жҚ®еҶҷе…Ҙcache lineпјӣ
[2] CPUеңЁйҒҮеҲ°smp_mbеҶ…еӯҳеұҸйҡңеҗҺпјҢеҸҜд»Ҙ继з»ӯеүҚиЎҢпјҢдҪҶжҳҜйңҖиҰҒи®°еҪ•дёҖдёӢstore bufferдёӯзҡ„ж•°жҚ®йЎәеәҸпјҢеңЁstore bufferдёӯзҡ„ж•°жҚ®дёҘж јжҢүйЎәеәҸе…ЁйғЁеҶҷеӣһcache lineд№ӢеүҚпјҢе…¶д»–ж•°жҚ®дёҚиғҪе…Ҳжӣҙж–°cache lineпјҢйңҖиҰҒжҢүз…§йЎәеәҸе…ҲеҶҷеҲ°store bufferжүҚиғҪ继з»ӯеүҚиЎҢгҖӮ
```
йҖҡеёёйҮҮз”Ёзҡ„жҳҜж–№жі•[2]пјҢеўһеҠ дәҶsmp_mb()еҗҺпјҢжү§иЎҢеәҸеҲ—еҰӮдёӢпјҡ
```
[1] CPU 0жү§иЎҢa=1зҡ„иөӢеҖјж“ҚдҪңпјҢз”ұдәҺaдёҚеңЁlocal cacheдёӯпјҢеӣ жӯӨпјҢCPU 0е°ҶaеҖјж”ҫеҲ°store bufferдёӯд№ӢеҗҺпјҢеҸ‘йҖҒдәҶread invalidateе‘Ҫд»ӨеҲ°жҖ»зәҝдёҠеҺ»гҖӮ
[2] CPU 1жү§иЎҢ while (b == 0) еҫӘзҺҜпјҢз”ұдәҺbдёҚеңЁCPU 1зҡ„cacheдёӯпјҢеӣ жӯӨпјҢCPUеҸ‘йҖҒдёҖдёӘread messageеҲ°жҖ»зәҝдёҠпјҢзңӢзңӢжҳҜеҗҰеҸҜд»Ҙд»Һе…¶д»–cpuзҡ„local cacheдёӯжҲ–иҖ…memoryдёӯиҺ·еҸ–ж•°жҚ®гҖӮ
[3] CPU 0жү§иЎҢsmp_mb()еҮҪж•°пјҢз»ҷзӣ®еүҚstore bufferдёӯзҡ„жүҖжңүйЎ№еҒҡдёҖдёӘж Үи®°пјҲеҗҺйқўжҲ‘们称д№Ӣmarked entriesпјүгҖӮеҪ“然пјҢй’ҲеҜ№жҲ‘们иҝҷдёӘдҫӢеӯҗпјҢstore bufferдёӯеҸӘжңүдёҖдёӘmarked entryе°ұжҳҜвҖңa=1вҖқгҖӮ
[4] CPU 0继з»ӯжү§иЎҢb=1зҡ„иөӢеҖјиҜӯеҸҘпјҢиҷҪ然bе°ұеңЁиҮӘе·ұзҡ„local cacheдёӯпјҲcachelineеӨ„дәҺmodifiedзҠ¶жҖҒжҲ–иҖ…exclusiveзҠ¶жҖҒпјүпјҢдёҚиҝҮеңЁstore bufferдёӯжңүmarked entryпјҢеӣ жӯӨCPU 0дёҚиғҪзӣҙжҺҘж“ҚдҪңе°Ҷж–°зҡ„еҖј1еҶҷе…Ҙcache lineпјҢеҸ–иҖҢд»Јд№ӢжҳҜbзҡ„ж–°еҖј'1'иў«еҶҷе…Ҙstore buffer(CPU 0д№ҹеҸҜд»ҘдёҚжү§иЎҢb=1иҜӯеҸҘпјҢзӯүеҲ°aзҡ„transactionе®ҢжҲҗ并еҶҷеӣһcache lineпјҢеңЁжү§иЎҢb=1пјҢе°Ҷbзҡ„ж–°еҖј'1'еҶҷе…Ҙcache line)пјҢеҪ“然жҳҜunmarkedзҠ¶жҖҒгҖӮ
[5] CPU 0收еҲ°дәҶread messageпјҢе°ҶbеҖјвҖқ0вҖңпјҲж–°еҖјвҖқ1вҖңиҝҳеңЁstore bufferдёӯпјүеӣһйҖҒз»ҷCPU 1пјҢеҗҢж—¶е°Ҷb cachelineзҡ„зҠ¶жҖҒи®ҫе®ҡдёәsharedгҖӮ
[6] CPU 1收еҲ°дәҶжқҘиҮӘCPU 0зҡ„read responseж¶ҲжҒҜпјҢе°ҶbеҸҳйҮҸзҡ„еҖјпјҲ'0'пјүеҶҷе…ҘиҮӘе·ұзҡ„cachelineпјҢзҠ¶жҖҒдҝ®ж”№дёәsharedгҖӮ
[7] з”ұдәҺsmp_mbеҶ…еӯҳеұҸйҡңзҡ„еӯҳеңЁпјҢbзҡ„ж–°еҖј'1'йҡҗи—ҸеңЁCPU 0зҡ„store bufferдёӯпјҢCPU 1еҸӘиғҪзңӢеҲ°bзҡ„ж—§еҖј'0'пјҢиҝҷж—¶CPU 1еӨ„дәҺжӯ»еҫӘзҺҜдёӯгҖӮ
[8] CPU 1收еҲ°дәҶжқҘиҮӘCPU 0зҡ„read invalidateж¶ҲжҒҜпјҢд»ҘaеҸҳйҮҸзҡ„еҖјиҝӣиЎҢеӣһеә”пјҢеҗҢж—¶жё…з©әиҮӘе·ұзҡ„cachelineгҖӮ
[9] CPU 0收еҲ°CPU 1зҡ„е“Қеә”msgпјҢе®ҢжҲҗдәҶaзҡ„иөӢеҖјtransactionпјҢCPU 0е°Ҷstore bufferдёӯзҡ„aеҖјеҶҷе…ҘcachelineпјҢ并且е°ҶcachelineзҠ¶жҖҒдҝ®ж”№дёәmodifiedзҠ¶жҖҒгҖӮ
[10] з”ұдәҺstore bufferеҸӘжңүдёҖйЎ№marked entryпјҲеҜ№еә”a=1пјүпјҢеӣ жӯӨпјҢе®ҢжҲҗstep 9д№ӢеҗҺпјҢstore bufferзҡ„bд№ҹеҸҜд»Ҙиҝӣе…ҘcachelineдәҶгҖӮдёҚиҝҮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҪ“еүҚbеҜ№еә”зҡ„cache lineзҡ„зҠ¶жҖҒжҳҜsharedгҖӮ
[11] CPU 0жғіе°Ҷstore bufferдёӯзҡ„bзҡ„ж–°еҖј'1'еҶҷеӣһcache lineгҖӮз”ұдәҺbзҡ„cache lineжҳҜshareзҡ„гҖӮCPU 0йңҖиҰҒеҸ‘йҖҒinvalidateж¶ҲжҒҜпјҢиҜ·жұӮbж•°жҚ®зҡ„зӢ¬еҚ жқғгҖӮ
[12] CPU 1收еҲ°invalidateж¶ҲжҒҜпјҢжё…з©әиҮӘе·ұbзҡ„ cache lineпјҢ并еӣһйҖҒacknowledgementз»ҷCPU 0гҖӮ
[13] CPU 1зҡ„жҹҗж¬ЎеҫӘзҺҜжү§иЎҢеҲ°while (b == 0)пјҢиҝҷж—¶еҸ‘зҺ°bзҡ„cache lineжҳҜInvalidзҡ„дәҶпјҢдәҺжҳҜCPU 1еҸ‘йҖҒreadж¶ҲжҒҜпјҢиҜ·жұӮиҺ·еҸ–bзҡ„ж•°жҚ®гҖӮ
[14] CPU 0收еҲ°acknowledgementж¶ҲжҒҜпјҢе°ҶbеҜ№еә”зҡ„cache lineдҝ®ж”№жҲҗexclusiveзҠ¶жҖҒпјҢиҝҷж—¶еҖҷпјҢCPU 0з»ҲдәҺеҸҜд»Ҙе°Ҷbзҡ„ж–°еҖј1еҶҷе…Ҙcache lineдәҶгҖӮ
[15] CPU 0收еҲ°readж¶ҲжҒҜпјҢе°Ҷbзҡ„ж–°еҖј1еӣһйҖҒз»ҷCPU 1пјҢеҗҢж—¶е°Ҷе…¶local cacheдёӯbеҜ№еә”зҡ„cachelineзҠ¶жҖҒдҝ®ж”№дёәsharedгҖӮ
[16] CPU 1иҺ·еҸ–жқҘиҮӘCPU 0зҡ„bзҡ„ж–°еҖјпјҢе°Ҷе…¶ж”ҫе…Ҙcache lineдёӯгҖӮ
[17] з”ұдәҺbеҖјзӯүдәҺ1дәҶпјҢеӣ жӯӨCPU 1и·іеҮәwhile (b == 0)зҡ„еҫӘзҺҜпјҢ继з»ӯеүҚиЎҢгҖӮ
[18] CPU 1жү§иЎҢassert(a == 1)пјҢдёҚиҝҮиҝҷж—¶еҖҷaеҖјжІЎжңүеңЁиҮӘе·ұзҡ„cache lineдёӯпјҢеӣ жӯӨйңҖиҰҒйҖҡиҝҮcacheдёҖиҮҙжҖ§еҚҸи®®д»ҺCPU 0йӮЈйҮҢиҺ·еҫ—пјҢиҝҷж—¶еҖҷиҺ·еҸ–зҡ„жҳҜaзҡ„жңҖж–°еҖјпјҢд№ҹе°ұжҳҜ1еҖјпјҢеӣ жӯӨassertжҲҗеҠҹгҖӮ
```
д»ҺдёҠйқўзҡ„жү§иЎҢеәҸеҲ—еҸҜд»ҘзңӢеҮәпјҢеңЁи°ғз”Ёmemory barrierжҢҮд»Өд№ӢеҗҺпјҢдҪҝеҫ—CPU 0иҝҹиҝҹдёҚиғҪе°Ҷbзҡ„ж–°еҖј'1'еҶҷеӣһcache lineпјҢд»ҺиҖҢдҪҝеҫ—CPU 1дёҖзӣҙдёҚиғҪи§ӮеҜҹеҲ°bзҡ„ж–°еҖј'1'пјҢйҖ жҲҗCPU 1дёҖзӣҙдёҚиғҪ继з»ӯеүҚиЎҢгҖӮзӣҙи§ӮдёҠCPU 0дјјд№ҺдёҚеҸ—д»Җд№ҲеҪұе“ҚпјҢеӣ дёәCPU 0еҸҜд»Ҙ继з»ӯеүҚиЎҢпјҢеҸӘжҳҜе°Ҷbзҡ„ж–°еҖј'1'еҶҷеҲ°store bufferиҖҢдёҚиғҪеҶҷеӣһcache lineгҖӮдёҚе№ёзҡ„жҳҜпјҡжҜҸдёӘcpuзҡ„store bufferдёҚиғҪе®һзҺ°зҡ„еӨӘеӨ§пјҢе…¶entryзҡ„ж•°зӣ®дёҚдјҡеӨӘеӨҡгҖӮеҪ“cpu 0д»Ҙдёӯзӯүзҡ„йў‘зҺҮжү§иЎҢstoreж“ҚдҪңзҡ„ж—¶еҖҷпјҲеҒҮи®ҫжүҖжңүзҡ„storeж“ҚдҪңеҜјиҮҙдәҶcache missпјүпјҢstore bufferдјҡеҫҲеҝ«зҡ„иў«еЎ«ж»ЎгҖӮеңЁиҝҷз§ҚзҠ¶еҶөдёӢпјҢCPU 0еҸӘиғҪеҸҲиҝӣе…Ҙзӯүеҫ…зҠ¶жҖҒпјҢзӣҙеҲ°cache lineе®ҢжҲҗinvalidationе’Ңackзҡ„дәӨдә’д№ӢеҗҺпјҢеҸҜд»Ҙе°Ҷstore bufferзҡ„entryеҶҷе…ҘcachelineпјҢд»ҺиҖҢдёәж–°зҡ„storeи®©еҮәз©әй—ҙд№ӢеҗҺпјҢCPU 0жүҚеҸҜд»Ҙ继з»ӯжү§иЎҢгҖӮиҝҷз§ҚзҠ¶еҶөжҒ°жҒ°еңЁи°ғз”ЁдәҶmemory barrierжҢҮд»Өд№ӢеҗҺпјҢжӣҙе®№жҳ“еҸ‘з”ҹпјҢеӣ дёәдёҖж—Ұstore bufferдёӯзҡ„жҹҗдёӘentryиў«ж Үи®°дәҶпјҢйӮЈд№ҲйҡҸеҗҺзҡ„storeйғҪеҝ…йЎ»зӯүеҫ…invalidationе®ҢжҲҗпјҢеӣ жӯӨдёҚз®ЎжҳҜеҗҰcache missпјҢиҝҷдәӣstoreйғҪеҝ…йЎ»иҝӣе…Ҙstore bufferпјҢиҝҷж ·е°ұеҫҲе®№жҳ“еЎһж»Ўstore bufferгҖӮ
6.2.4 Invalidate Queue
store bufferд№ӢжүҖд»ҘеҫҲе®№жҳ“иў«еЎ«е……ж»ЎпјҢдё»иҰҒжҳҜе…¶д»–CPUеӣһеә”invalidate acknowledgeжҜ”иҫғж…ўпјҢеҰӮжһңиғҪеӨҹеҠ еҝ«иҝҷдёӘиҝҮзЁӢпјҢи®©store bufferе°Ҫеҝ«иҝӣе…Ҙcache lineпјҢйӮЈд№Ҳд№ҹе°ұдёҚдјҡйӮЈд№Ҳе®№жҳ“еЎ«ж»ЎдәҶгҖӮ
invalidate acknowledgeдёҚиғҪе°Ҫеҝ«еӣһеӨҚзҡ„дё»иҰҒеҺҹеӣ жҳҜinvalidate cachelineзҡ„ж“ҚдҪңжІЎжңүйӮЈд№Ҳеҝ«е®ҢжҲҗпјҢзү№еҲ«жҳҜcacheжҜ”иҫғз№Ғеҝҷзҡ„ж—¶еҖҷпјҢиҝҷж—¶пјҢCPUеҫҖеҫҖиҝӣиЎҢеҜҶйӣҶзҡ„loadingе’Ңstoringзҡ„ж“ҚдҪңпјҢиҖҢжқҘиҮӘе…¶д»–CPUзҡ„пјҢеҜ№жң¬CPU local cachelineзҡ„ж“ҚдҪңйңҖиҰҒе’Ңжң¬CPUзҡ„еҜҶйӣҶзҡ„cacheж“ҚдҪңиҝӣиЎҢз«һдәүпјҢеҸӘиҰҒе®ҢжҲҗдәҶinvalidateж“ҚдҪңд№ӢеҗҺпјҢжң¬CPUжүҚдјҡеҸ‘з”ҹinvalidate acknowledgeгҖӮжӯӨеӨ–пјҢеҰӮжһңзҹӯж—¶й—ҙеҶ…收еҲ°еӨ§йҮҸзҡ„invalidateж¶ҲжҒҜпјҢCPUжңүеҸҜиғҪи·ҹдёҚдёҠеӨ„зҗҶпјҢд»ҺиҖҢеҜјиҮҙе…¶д»–CPUдёҚж–ӯзҡ„зӯүеҫ…гҖӮ
иҰҒжғіиҫҫеҲ°еҝ«йҖҹеӣһеӨҚacknowledgementпјҢдёҖдёӘи§ЈеҶіж–№жі•жҳҜпјҢеј•е…ҘдёҖдёӘзј“еҶІйҳҹеҲ—пјҢжҺҘ收еҲ°invalidateиҜ·жұӮпјҢеҸҜд»Ҙе…Ҳе°ҶиҜ·жұӮе…Ҙйҳҹзј“еҶІйҳҹеҲ—пјҢе°ұеҸҜд»ҘеӣһеӨҚacknowledgementж¶ҲжҒҜдәҶпјҢеҗҺйқўеңЁејӮжӯҘе®ҢжҲҗinvalidateж“ҚдҪңгҖӮдәҺжҳҜ硬件е·ҘзЁӢеёҲпјҢеј•е…ҘдёҖдёӘinvalidate queueпјҢжңүinvalidate queueзҡ„зі»з»ҹз»“жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡ
ејӮжӯҘ延еҗҺеӨ„зҗҶпјҢд№ҹйңҖиҰҒжңүдёӘеәҰжүҚиЎҢгҖӮдёҖж—Ұе°ҶдёҖдёӘinvalidateпјҲдҫӢеҰӮй’ҲеҜ№еҸҳйҮҸaзҡ„cachelineпјүж¶ҲжҒҜж”ҫе…ҘCPUзҡ„Invalidate QueueпјҢе®һйҷ…дёҠиҜҘCPUе°ұзӯүдәҺдҪңеҮәиҝҷж ·зҡ„жүҝиҜәпјҡеңЁеӨ„зҗҶе®ҢиҜҘinvalidateж¶ҲжҒҜд№ӢеүҚпјҢдёҚдјҡеҸ‘йҖҒд»»дҪ•зӣёе…іпјҲеҚій’ҲеҜ№еҸҳйҮҸaзҡ„cachelineпјүзҡ„MESIеҚҸи®®ж¶ҲжҒҜгҖӮдёәд»Җд№ҲжҳҜеңЁеҸ‘еҮәжҹҗдёӘеҸҳйҮҸaзҡ„MESIеҚҸи®®ж¶ҲжҒҜзҡ„ж—¶еҖҷпјҢйңҖжұӮеҺ»жЈҖжҹҘinvalidate queueзңӢжҳҜеҗҰжңүеҸҳйҮҸaзҡ„invalidateж¶ҲжҒҜе‘ўпјҹиҖҢдёҚжҳҜеңЁеҜ№иҜҘеҸҳйҮҸзҡ„д»»дҪ•ж“ҚдҪңйғҪйңҖиҰҒжЈҖжҹҘд»ҘдёӢinvalidate queueе‘ўпјҹе…¶е®һиҝҷж ·еңЁдҝқиҜҒMESIеҚҸи®®жӯЈзЎ®жҖ§зҡ„жғ…еҶөдёӢпјҢиҝӣдёҖжӯҘдҝқиҜҒжҖ§иғҪзҡ„жҠҳдёӯж–№жЎҲгҖӮ
еӣ дёәпјҢеңЁеҚ•зәҜиҖғиҷ‘жҖ§иғҪзҡ„жғ…еҶөдёӢпјҢе°‘еҺ»жЈҖжҹҘinvalidate queueпјҢе‘ЁжңҹжҖ§(дёҖе®ҡж—¶й—ҙпјҢcpuжІЎйӮЈд№Ҳз№ҒеҝҷгҖҒinvalidate queueе®№йҮҸиҫҫеҲ°дёҖе®ҡ)жү№йҮҸеӨ„зҗҶinvalidate queueдёӯзҡ„ж¶ҲжҒҜпјҢиҝҷж ·жҖ§иғҪиғҪеӨҹиҫҫеҲ°жңҖдҪігҖӮдҪҶжҳҜпјҢиҝҷж ·еңЁжҹҗдәӣжғ…еҶөдёӢпјҢдҪҝеҫ—MESIеҚҸи®®еӨұж•ҲгҖӮдҫӢеҰӮпјҡеңЁдёҖдёӘ4ж ёзҡ„жңәеҷЁдёҠпјҢеҸҳйҮҸaеҲқе§ӢеҖјжҳҜ'0'пјҢе®ғcacheеңЁCPU 0е’ҢCPU 1зҡ„cache lineдёӯпјҢзҠ¶жҖҒйғҪжҳҜShareгҖӮ
```
[1] CPU 0йңҖиҰҒдҝ®ж”№еҸҳйҮҸaзҡ„еҖјдёә'1'пјҢCPU 0еҸ‘йҖҒinvalidateж¶ҲжҒҜз»ҷе…¶д»–CPU(1~3).
[2] е…¶д»–CPU(1~3)е°Ҷinvalidateж¶ҲжҒҜж”ҫе…Ҙinvalidate queueпјҢ然еҗҺйғҪеӣһеӨҚз»ҷCPU 0.
[3] CPU 0收еҲ°е“Қеә”еҗҺпјҢе°Ҷaзҡ„ж–°еҖј'1'еҶҷе…Ҙcache line并дҝ®ж”№зҠ¶жҖҒдёәModifiedгҖӮ
[4] CPU 2йңҖиҰҒиҜ»еҸ–aзҡ„ж—¶еҖҷйҒҮеҲ°cache missпјҢдәҺжҳҜCPU 2еҸ‘йҖҒreadж¶ҲжҒҜз»ҷе…¶д»–CPUпјҢиҜ·жұӮиҺ·еҸ–aзҡ„ж•°жҚ®гҖӮ
[5] CPU 1收еҲ°readиҜ·жұӮпјҢз”ұдәҺaеңЁиҮӘе·ұзҡ„cache line并且жҳҜshareзҠ¶жҖҒзҡ„пјҢдәҺжҳҜCPU 1е°Ҷaзҡ„invalidеҖј'0'е“Қеә”з»ҷCPU 2гҖӮ
[6] CPU 2йҖҡиҝҮдёҖдёӘreadж¶ҲжҒҜиҺ·еҸ–еҲ°дёҖдёӘиҝҮжңҹзҡ„йқһжі•зҡ„еҖјпјҢиҝҷж ·MESIеҚҸи®®ж— жі•дҝқиҜҒж•°жҚ®дёҖиҮҙжҖ§дәҶгҖӮ
```
дәҺжҳҜпјҢдёәдәҶдҝқиҜҒMESIеҚҸи®®зҡ„жӯЈзЎ®жҖ§пјҢCPUеңЁйңҖиҰҒеҸ‘еҮәжҹҗдёӘеҸҳйҮҸзҡ„aзҡ„MESIеҚҸи®®ж¶ҲжҒҜзҡ„ж—¶еҖҷпјҢйңҖиҰҒжЈҖжҹҘinvalidate queueдёӯжҳҜеҗҰжңүиҜҘеҸҳйҮҸaзҡ„invalidateж¶ҲжҒҜпјҢеҰӮжһңжңүйңҖиҰҒе…ҲеҮәжқҘе®ҢжҲҗиҝҷдёӘinvliadteж¶ҲжҒҜеҗҺпјҢжүҚиғҪеҸ‘еҮәжӯЈзЎ®зҡ„MESIеҚҸи®®ж¶ҲжҒҜгҖӮеңЁеҗҲйҖӮзҡ„ж—¶еҖҷпјҢеҸ‘еҮәжӯЈзЎ®зҡ„MESIеҚҸи®®жҳҜдҝқиҜҒдәҶдёҚеҗ‘е…¶д»–CPUдј йҖ’й”ҷиҜҜзҡ„дҝЎжҒҜпјҢд»ҺиҖҢдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§гҖӮдҪҶжҳҜпјҢеҜ№дәҺжң¬CPUжҳҜеҗҰд№ҹеҸҜд»Ҙй«ҳжһ•ж— еҝ§е‘ўпјҹжҲ‘们жқҘзңӢеҗҢдёҠйқўдёҖж ·зҡ„дёҖдёӘдҫӢеӯҗпјҡ
```
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
```
еңЁдёҠйқўзҡ„д»Јз ҒзүҮж®өдёӯпјҢжҲ‘们еҒҮи®ҫaе’ҢbеҲқеҖјжҳҜ0пјҢ并且aеңЁCPU 0е’ҢCPU 1йғҪжңүзј“еӯҳзҡ„еүҜжң¬пјҢеҚіaеҸҳйҮҸеҜ№еә”зҡ„CPU0е’ҢCPU 1зҡ„cachelineйғҪжҳҜsharedзҠ¶жҖҒгҖӮbеӨ„дәҺexclusiveжҲ–иҖ…modifiedзҠ¶жҖҒпјҢиў«CPU 0зӢ¬еҚ гҖӮжҲ‘们еҒҮи®ҫCPU 0жү§иЎҢfooеҮҪж•°пјҢCPU 1жү§иЎҢbarеҮҪж•°пјҢжү§иЎҢеәҸеҲ—еҰӮдёӢпјҡ
```
[1] CPU 0жү§иЎҢa=1зҡ„иөӢеҖјж“ҚдҪңпјҢз”ұдәҺaеңЁCPU 0 local cacheдёӯзҡ„cachelineеӨ„дәҺsharedзҠ¶жҖҒпјҢеӣ жӯӨпјҢCPU 0е°Ҷaзҡ„ж–°еҖјвҖң1вҖқж”ҫе…Ҙstore bufferпјҢ并且еҸ‘йҖҒдәҶinvalidateж¶ҲжҒҜеҺ»жё…з©әCPU 1еҜ№еә”зҡ„cachelineгҖӮ
[2] CPU 1жү§иЎҢwhile (b == 0)зҡ„еҫӘзҺҜж“ҚдҪңпјҢдҪҶжҳҜbжІЎжңүеңЁlocal cacheпјҢеӣ жӯӨеҸ‘йҖҒreadж¶ҲжҒҜиҜ•еӣҫиҺ·еҸ–иҜҘеҖјгҖӮ
[3] CPU 1收еҲ°дәҶCPU 0зҡ„invalidateж¶ҲжҒҜпјҢж”ҫе…ҘInvalidate QueueпјҢ并з«ӢеҲ»еӣһйҖҒAckгҖӮ
[4] CPU 0收еҲ°дәҶCPU 1зҡ„invalidate ACKд№ӢеҗҺпјҢеҚіеҸҜд»Ҙи¶ҠиҝҮзЁӢеәҸи®ҫе®ҡеҶ…еӯҳеұҸйҡңпјҲ第еӣӣиЎҢд»Јз Ғзҡ„smp_mb() пјүпјҢиҝҷж ·aзҡ„ж–°еҖјд»Һstore bufferиҝӣе…ҘcachelineпјҢзҠ¶жҖҒеҸҳжҲҗModifiedгҖӮ
[5] CPU 0 и¶ҠиҝҮmemory barrierеҗҺ继з»ӯжү§иЎҢb=1зҡ„иөӢеҖјж“ҚдҪңпјҢз”ұдәҺbеҖјеңЁCPU 0зҡ„local cacheдёӯпјҢеӣ жӯӨstoreж“ҚдҪңе®ҢжҲҗ并иҝӣе…Ҙcache lineгҖӮ
[6] CPU 0收еҲ°дәҶreadж¶ҲжҒҜеҗҺе°Ҷbзҡ„жңҖж–°еҖјвҖң1вҖқеӣһйҖҒз»ҷCPU 1пјҢ并дҝ®жӯЈиҜҘcache lineдёәsharedзҠ¶жҖҒгҖӮ
[7] CPU 1收еҲ°read responseпјҢе°Ҷbзҡ„жңҖж–°еҖјвҖң1вҖқеҠ иҪҪеҲ°local cachelineгҖӮ
[8] еҜ№дәҺCPU 1иҖҢиЁҖпјҢbе·Із»ҸзӯүдәҺ1дәҶпјҢеӣ жӯӨи·іеҮәwhile (b == 0)зҡ„еҫӘзҺҜпјҢ继з»ӯжү§иЎҢеҗҺз»ӯд»Јз Ғ
[9] CPU 1жү§иЎҢassert(a == 1)пјҢдҪҶжҳҜз”ұдәҺиҝҷж—¶еҖҷCPU 1 cacheзҡ„aеҖјд»Қ然жҳҜж—§еҖј0пјҢеӣ жӯӨassertion еӨұиҙҘ
[10] иҜҘжқҘжҖ»дјҡжқҘпјҢInvalidate Queueдёӯй’ҲеҜ№a cachelineзҡ„invalidateж¶ҲжҒҜжңҖз»Ҳдјҡиў«CPU 1жү§иЎҢпјҢе°Ҷaи®ҫе®ҡдёәж— ж•ҲпјҢдҪҶпјҢеӨ§й”ҷе·Із»Ҹй…ҝжҲҗгҖӮ
```
CPU 1еҮәзҺ°assertеӨұиҙҘпјҢжҳҜеӣ дёәжІЎжңүеҸҠж—¶еӨ„зҗҶinvalidate queueдёӯзҡ„aзҡ„invalidateж¶ҲжҒҜпјҢеҜјиҮҙдҪҝз”ЁдәҶжң¬cache lineдёӯзҡ„дёҖдёӘе·Із»ҸжҳҜinvalidзҡ„дёҖдёӘж—§зҡ„еҖјпјҢиҝҷжҳҜе…ёеһӢзҡ„cacheеёҰжқҘзҡ„дёҖиҮҙжҖ§й—®йўҳгҖӮиҝҷдёӘж—¶еҖҷпјҢжҲ‘们д№ҹйңҖиҰҒдёҖдёӘmemory barrierжҢҮд»ӨжқҘе‘ҠиҜүCPUпјҢиҝҷдёӘж—¶еҖҷеә”иҜҘйңҖиҰҒеӨ„зҗҶinvalidate queueдёӯзҡ„ж¶ҲжҒҜдәҶпјҢеҗҰеҲҷеҸҜиғҪдјҡиҜ»еҲ°дёҖдёӘinvalidзҡ„ж—§еҖјгҖӮ
```
еҪ“CPUжү§иЎҢmemory barrierжҢҮд»Өзҡ„ж—¶еҖҷпјҢеҜ№еҪ“еүҚInvalidate Queueдёӯзҡ„жүҖжңүзҡ„entryиҝӣиЎҢж ҮжіЁпјҢиҝҷдәӣиў«ж ҮжіЁзҡ„йЎ№иў«з§°дёәmarked entriesпјҢиҖҢйҡҸеҗҺCPUжү§иЎҢзҡ„д»»дҪ•зҡ„loadж“ҚдҪңйғҪйңҖиҰҒзӯүеҲ°Invalidate QueueдёӯжүҖжңүmarked entriesе®ҢжҲҗеҜ№cachelineзҡ„ж“ҚдҪңд№ӢеҗҺжүҚиғҪиҝӣиЎҢ
```
еӣ жӯӨпјҢиҰҒжғідҝқиҜҒзЁӢеәҸйҖ»иҫ‘жӯЈзЎ®пјҢжҲ‘们йңҖиҰҒз»ҷbarеҮҪж•°еўһеҠ еҶ…еӯҳеұҸйҡңзҡ„ж“ҚдҪңпјҢе…·дҪ“еҰӮдёӢпјҡ
```
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_mb();
12 assert(a == 1);
13 }
```
bar()еҮҪж•°ж·»еҠ smp_mbеҶ…еӯҳеұҸйҡңеҗҺпјҢжү§иЎҢеәҸеҲ—еҰӮдёӢпјҡ
```
[1] ~ [8] еҗҢдёҠ
[9] CPU 1йҒҮеҲ°smp_mbеҶ…еӯҳеұҸйҡңпјҢеҸ‘зҺ°дёӢдёҖжқЎиҜӯеҸҘжҳҜload aпјҢиҝҷдёӘж—¶еҖҷCPU 1дёҚиғҪ继з»ӯжү§иЎҢд»Јз ҒпјҢеҸӘиғҪзӯүеҫ…пјҢзӣҙеҲ°Invalidate Queueдёӯзҡ„messageиў«еӨ„зҗҶе®ҢжҲҗ
[10] CPU 1еӨ„зҗҶInvalidate Queueдёӯзј“еӯҳзҡ„Invalidateж¶ҲжҒҜпјҢе°ҶaеҜ№еә”зҡ„cachelineи®ҫзҪ®дёәж— ж•ҲгҖӮ
[11] з”ұдәҺaеҸҳйҮҸеңЁlocal cacheдёӯж— ж•ҲпјҢеӣ жӯӨCPU 1еңЁжү§иЎҢassert(a == 1)зҡ„ж—¶еҖҷйңҖиҰҒеҸ‘йҖҒдёҖдёӘreadж¶ҲжҒҜеҺ»иҺ·еҸ–aеҖјгҖӮ
[12] CPU 0з”Ёaзҡ„ж–°еҖј1еӣһеә”жқҘиҮӘCPU 1зҡ„иҜ·жұӮгҖӮ
[13] CPU 1иҺ·еҫ—дәҶaзҡ„ж–°еҖјпјҢ并ж”ҫе…ҘcachelineпјҢиҝҷж—¶еҖҷassert(a == 1)дёҚдјҡеӨұиҙҘдәҶгҖӮ
```
еңЁжҲ‘们дёҠйқўзҡ„дҫӢеӯҗдёӯпјҢmemory barrierжҢҮд»ӨеҜ№store bufferе’Ңinvalidate queueйғҪиҝӣиЎҢдәҶж ҮжіЁпјҢдёҚиҝҮпјҢеңЁе®һйҷ…зҡ„д»Јз ҒзүҮж®өдёӯпјҢfooеҮҪж•°дёҚйңҖиҰҒmark invalidate queueпјҢbarеҮҪж•°дёҚйңҖиҰҒmark store bufferгҖӮеӣ жӯӨпјҢи®ёеӨҡCPU architectureжҸҗдҫӣдәҶејұдёҖзӮ№зҡ„memory barrierжҢҮд»ӨеҸӘmarkе…¶дёӯд№ӢдёҖгҖӮеҰӮжһңеҸӘmark invalidate queueпјҢйӮЈд№Ҳиҝҷз§Қmemory barrierиў«з§°дёәread memory barrierгҖӮзӣёеә”зҡ„пјҢwrite memory barrierеҸӘmark store bufferгҖӮдёҖдёӘе…ЁеҠҹиғҪзҡ„memory barrierдјҡеҗҢж—¶mark store bufferе’Ңinvalidate queueгҖӮ
жҲ‘们дёҖиө·жқҘзңӢзңӢиҜ»еҶҷеҶ…еӯҳеұҸйҡңзҡ„жү§иЎҢж•ҲжһңпјҡеҜ№дәҺread memory barrierжҢҮд»ӨпјҢе®ғеҸӘжҳҜзәҰжқҹжү§иЎҢCPUдёҠзҡ„loadж“ҚдҪңзҡ„йЎәеәҸпјҢе…·дҪ“зҡ„ж•Ҳжһңе°ұжҳҜCPUдёҖе®ҡжҳҜе®ҢжҲҗread memory barrierд№ӢеүҚзҡ„loadж“ҚдҪңд№ӢеҗҺпјҢжүҚејҖе§Ӣжү§иЎҢread memory barrierд№ӢеҗҺзҡ„loadж“ҚдҪңгҖӮread memory barrierжҢҮд»ӨиұЎдёҖйҒ“ж …ж ҸпјҢдёҘж јеҢәеҲҶдәҶд№ӢеүҚе’Ңд№ӢеҗҺзҡ„loadж“ҚдҪңгҖӮеҗҢж ·зҡ„пјҢwrite memory barrierжҢҮд»ӨпјҢе®ғеҸӘжҳҜзәҰжқҹжү§иЎҢCPUдёҠзҡ„storeж“ҚдҪңзҡ„йЎәеәҸпјҢе…·дҪ“зҡ„ж•Ҳжһңе°ұжҳҜCPUдёҖе®ҡжҳҜе®ҢжҲҗwrite memory barrierд№ӢеүҚзҡ„storeж“ҚдҪңд№ӢеҗҺпјҢжүҚејҖе§Ӣжү§иЎҢwrite memory barrierд№ӢеҗҺзҡ„storeж“ҚдҪңгҖӮе…ЁеҠҹиғҪзҡ„memory barrierдјҡеҗҢж—¶зәҰжқҹloadе’Ңstoreж“ҚдҪңпјҢеҪ“然еҸӘжҳҜеҜ№жү§иЎҢmemory barrierзҡ„CPUжңүж•ҲгҖӮ
зҺ°еңЁпјҢжҲ‘们еҸҜд»Ҙж”№дёҖдёӘз”ЁиҜ»еҶҷеҶ…еӯҳеұҸйҡңзҡ„зүҲжң¬дәҶпјҢе…·дҪ“еҰӮдёӢпјҡ
```
1 void foo(void)
2 {
3 a = 1;
4 smp_wmb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_rmb();
12 assert(a == 1);
13 }
```
еҸҜи§ҒпјҢmemory barrierйңҖиҰҒжҲҗеҜ№дҪҝз”ЁжүҚиғҪдҝқиҜҒзЁӢеәҸзҡ„жӯЈзЎ®жҖ§гҖӮд»Җд№Ҳжғ…еҶөдёӢдҪҝз”Ёmemory barrierпјҢдҪҝз”ЁжҖҺж ·зҡ„memory barrierпјҢе’ҢCPUжһ¶жһ„жңүйӮЈдәӣзӣёе…іжҖ§е‘ўпјҹ
6.3 How Memory Barriersпјҹ
memory barrierзҡ„иҜӯд№үеңЁдёҚеҗҢCPUдёҠжҳҜдёҚеҗҢзҡ„пјҢеӣ жӯӨпјҢжғіиҰҒе®һзҺ°дёҖдёӘеҸҜ移жӨҚзҡ„memory barrierзҡ„д»Јз ҒйңҖиҰҒеҜ№еҪўеҪўГ—Г—Г—зҡ„CPUдёҠзҡ„memory barrierиҝӣиЎҢжҖ»з»“гҖӮе№ёиҝҗзҡ„жҳҜпјҢж— и®әе“ӘдёҖз§ҚcpuйғҪйҒөе®ҲдёӢйқўзҡ„规еҲҷпјҡ
```
[1]гҖҒд»ҺCPUиҮӘе·ұзҡ„и§Ҷи§’зңӢпјҢе®ғиҮӘе·ұзҡ„memory orderжҳҜжңҚд»Һprogram orderзҡ„
[2]гҖҒд»ҺеҢ…еҗ«жүҖжңүcpuзҡ„sharebility domainзҡ„и§’еәҰзңӢпјҢжүҖжңүcpuеҜ№дёҖдёӘе…ұдә«еҸҳйҮҸзҡ„и®ҝй—®еә”иҜҘжңҚд»ҺиӢҘе№ІдёӘе…ЁеұҖеӯҳеӮЁйЎәеәҸ
[3]гҖҒmemory barrierйңҖиҰҒжҲҗеҜ№дҪҝз”Ё
[4]гҖҒmemory barrierзҡ„ж“ҚдҪңжҳҜжһ„е»әдә’ж–Ҙй”ҒеҺҹиҜӯзҡ„еҹәзҹі
```
6.3.1 жңүжқЎд»¶зҡ„йЎәеәҸдҝқиҜҒ
иҰҒдҝқиҜҒзЁӢеәҸеңЁеӨҡж ёCPUдёӯжү§иЎҢжңҚд»Һprogram orderпјҢйӮЈд№ҲжҲ‘们йңҖиҰҒжҲҗеҜ№дҪҝз”Ёзҡ„memory barrierпјҢ然иҖҢжҲҗеҜ№зҡ„memory barrier并дёҚиғҪжҸҗдҫӣз»қеҜ№зҡ„йЎәеәҸдҝқиҜҒпјҢеҸӘиғҪжҸҗдҫӣжңүжқЎд»¶зҡ„йЎәеәҸдҝқиҜҒгҖӮйӮЈд№Ҳд»Җд№ҲжҳҜжңүжқЎд»¶зҡ„йЎәеәҸдҝқиҜҒпјҹиҖғиҷ‘дёӢйқўдёҖдёӘи®ҝй—®дҫӢеӯҗ(иҝҷйҮҢзҡ„accessеҸҜд»ҘжҳҜиҜ»жҲ–еҶҷ)пјҡ
д»ҺCPU1и§’еәҰжқҘзңӢпјҢеҜ№Aзҡ„и®ҝй—®жҖ»жҳҜе…ҲдәҺеҜ№Bзҡ„и®ҝй—®гҖӮдҪҶжҳҜпјҢе…ій”®зҡ„жҳҜд»ҺCPU2зҡ„и§’еәҰжқҘзңӢпјҢCPU1еҜ№AгҖҒBзҡ„и®ҝй—®йЎәеәҸжҳҜеҗҰе°ұдёҖе®ҡжҳҜAдјҳе…ҲдәҺBе‘ўпјҹеҒҮеҰӮеңЁCPU2ж„ҹзҹҘCPU1еҜ№Aзҡ„и®ҝй—®з»“жһңзҡ„жғ…еҶөдёӢпјҢжҳҜеҗҰеҸҜд»ҘдҝқиҜҒCPU2д№ҹиғҪж„ҹзҹҘCPU1еҜ№Bзҡ„и®ҝй—®з»“жһңе‘ўпјҹиҝҷжҳҜдёҚдёҖе®ҡзҡ„пјҢдҫӢеҰӮжү§иЎҢж—¶еәҸеҰӮдёӢпјҢйӮЈд№Ҳжҳҫ然пјҢеңЁCPU2ж„ҹзҹҘCPU1еҜ№Aзҡ„и®ҝй—®з»“жһңзҡ„жғ…еҶөдёӢпјҢжҳҜ并дёҚиғҪж„ҹзҹҘCPU1еҜ№Bзҡ„и®ҝй—®з»“жһң(CPU2еҜ№Aзҡ„и®ҝй—®иҰҒж—©дәҺCPU1еҜ№Bзҡ„и®ҝй—®)гҖӮ
еҸҰеӨ–пјҢеҰӮжһңCPU1еҜ№Bзҡ„и®ҝй—®з»“жһңе·Із»Ҹиў«CPU2ж„ҹзҹҘеҲ°дәҶпјҢйӮЈд№ҲпјҢеңЁиҝҷдёӘжқЎд»¶дёӢпјҢCPU1еҜ№Aзҡ„и®ҝй—®з»“жһңе°ұдёҖе®ҡиғҪеӨҹиў«CPU2ж„ҹзҹҘеҲ°гҖӮиҝҷе°ұжҳҜи§ӮеҜҹиҖ…(CPU2)еңЁж»Ўи¶ідёҖе®ҡжқЎд»¶дёӢжүҚиғҪдҝқиҜҒиҝҷдёӘmemoryзҡ„и®ҝй—®йЎәеәҸгҖӮ
еҜ№дәҺдёҠйқўдҫӢеӯҗдёӯзҡ„accessж“ҚдҪңпјҢеңЁеҶ…еӯҳдёҠеҢ…жӢ¬loadе’ҢstoreдёӨз§ҚдёҚеҗҢж“ҚдҪңпјҢдёӢйқўеҲ—еҮәдәҶCPU1е’ҢCPU2дёҚеҗҢзҡ„ж“ҚдҪңз»„еҗҲе…ұ16дёӘпјҢдёӢйқўжқҘиҜҰз»ҶжҸҸиҝ°дёҖдёӢпјҢеңЁдёҚеҗҢзҡ„ж“ҚдҪңз»„еҗҲдёӢmemory barrierеҸҜд»ҘеҒҡеҮәжҖҺж ·зҡ„дҝқиҜҒгҖӮ

з”ұдәҺCPUжһ¶жһ„еҚғе·®дёҮеҲ«пјҢдёҠйқўзҡ„16з§Қз»„еҗҲеҸҜд»ҘеҲҶжҲҗ3зұ»
```
[1] Portable Combinations -- йҖҡжқҖжүҖжңүCPU
[2] Semi-Portable Combinations -- зҺ°д»ЈCPUеҸҜд»ҘworkпјҢдҪҶжҳҜдёҚйҖӮеә”еңЁжҜ”иҫғж—§зҡ„йӮЈдәӣCPU
[3] Dubious Combinations -- еҹәжң¬жҳҜдёҚеҸҜ移жӨҚзҡ„
```
6.3.1.1 йҖҡжқҖжүҖжңүCPU
(1) Pairing 1
жғ…еҶө3пјҢCPUжү§иЎҢд»Јз ҒеҰӮдёӢпјҡпјҲAе’ҢBзҡ„еҲқеҖјйғҪжҳҜ0пјү
| CPU1 | CPU2 |
| ------ | ------ |
| X = A; | B = 1; |
| smp_mb(); | smp_mb(); |
| Y = B; | A = 1; |
еҜ№дәҺиҝҷз§Қжғ…еҶөпјҢдёӨдёӘCPUйғҪжү§иЎҢе®ҢдёҠйқўзҡ„д»Јз ҒеҗҺпјҢеҰӮжһңXзҡ„еҖјжҳҜ1пјҢйӮЈд№ҲжҲ‘们еҸҜд»Ҙж–ӯе®ҡYд№ҹжҳҜзӯүдәҺ1зҡ„гҖӮд№ҹе°ұжҳҜеҰӮжһңCPU1ж„ҹзҹҘеҲ°дәҶCPU2еҜ№Aзҡ„и®ҝй—®з»“жһңпјҢйӮЈд№ҲеҸҜд»Ҙж–ӯе®ҡCPU1д№ҹеҝ…иғҪж„ҹзҹҘCPU2еҜ№Bзҡ„и®ҝй—®з»“жһңгҖӮдҪҶжҳҜпјҢеҰӮжһңXзҡ„еҖјжҳҜ0пјҢйӮЈд№Ҳmemory barrierзҡ„жқЎд»¶дёҚеӯҳеңЁпјҢдәҺжҳҜYзҡ„еҖјеҸҜиғҪжҳҜ0д№ҹеҸҜиғҪжҳҜ1гҖӮ
еҜ№дәҺжғ…еҶөCпјҢе®ғжҳҜе’Ңжғ…еҶө1жҳҜеҜ№з§°пјҢдәҺжҳҜз»“и®әд№ҹжҳҜзұ»дјјзҡ„пјҡпјҲAе’ҢBзҡ„еҲқеҖјйғҪжҳҜ0пјү
еҗҢж ·пјҢдёӨдёӘCPUйғҪжү§иЎҢе®ҢдёҠйқўзҡ„д»Јз ҒеҗҺпјҢеҰӮжһңYзҡ„еҖјжҳҜ1пјҢйӮЈд№ҲеҸҜд»Ҙж–ӯе®ҡXзҡ„еҖјд№ҹжҳҜ1гҖӮ
(2) Pairing 2
жғ…еҶө5пјҢCPUжү§иЎҢд»Јз ҒеҰӮдёӢпјҡпјҲAе’ҢBзҡ„еҲқеҖјйғҪжҳҜ0пјү
дёӨдёӘCPUйғҪжү§иЎҢе®ҢдёҠйқўзҡ„д»Јз ҒеҗҺпјҢеңЁдёҚеҪұе“ҚйҖ»иҫ‘зҡ„жғ…еҶөдёӢпјҢеңЁCPU2зҡ„A=1;еүҚйқўжҸ’е…Ҙд»Јз ҒZ=XпјҢж №жҚ®жғ…еҶөCпјҢеҰӮжһңYзҡ„еҖјжҳҜ1пјҢйӮЈд№ҲZзҡ„еҖје°ұдёҖе®ҡжҳҜAпјҢз”ұдәҺZ=Xжү§иЎҢеңЁA=1еүҚйқўпјҢйӮЈд№ҲZзҡ„еҖјжҳҜAзҡ„еҲқе§ӢеҖј0пјҢдәҺжҳҜXзҡ„еҖјдёҖе®ҡжҳҜ0гҖӮеҗҢж ·пјҢеҰӮжһңXзӯүдәҺ1пјҢйӮЈд№ҲжҲ‘们дёҖе®ҡеҸҜд»Ҙеҫ—еҲ°YзӯүдәҺ0;
(3) Pairing 3
жғ…еҶө7пјҢCPUжү§иЎҢд»Јз ҒеҰӮдёӢпјҡпјҲAе’ҢBзҡ„еҲқеҖјйғҪжҳҜ0пјү
дёӨдёӘCPUйғҪжү§иЎҢе®ҢдёҠйқўзҡ„д»Јз ҒеҗҺпјҢеңЁдёҚеҪұе“ҚйҖ»иҫ‘зҡ„жғ…еҶөдёӢпјҢеңЁCPU1зҡ„B=1;еүҚйқўжҸ’е…Ҙд»Јз ҒZ=BпјҢж №жҚ®жғ…еҶө3пјҢеҰӮжһңXзӯүдәҺ1пјҢйӮЈд№ҲеҸҜд»Ҙж–ӯе®ҡZзӯүдәҺ2пјҢд№ҹе°ұжҳҜеңЁCPU1жү§иЎҢе®ҢжҜ•Z=Bд»Јз ҒеүҚпјҢBзҡ„еҖјжҳҜ2пјҢз”ұдәҺCPU1еңЁжү§иЎҢе®ҢZ=BеҗҺдјҡжү§иЎҢB=1пјҢдәҺжҳҜеҜ№CPU1иҖҢе·ІпјҢжңҖеҗҺBзҡ„еҖјжҳҜ1гҖӮ
йҖҡиҝҮдёҠйқў(1) пјҢеҰӮжһңCPU1жү§иЎҢзҡ„е…ЁжҳҜstoreж“ҚдҪңпјҢиҖҢCPU2жү§иЎҢзҡ„е…ЁжҳҜloadж“ҚдҪң(еҜ№з§°дёӢпјҢCPU2жү§иЎҢзҡ„е…ЁжҳҜstoreж“ҚдҪңпјҢиҖҢCPU1жү§иЎҢзҡ„е…ЁжҳҜloadж“ҚдҪң)пјҢйӮЈд№ҲдјҡжңүдёҖдёӘmemory barrierжқЎд»¶дҪҝеҫ—жү§иЎҢеҫ—еҲ°дёҖдёӘзЎ®е®ҡзҡ„йЎәеәҸпјҢ并且жҳҜйҖҡеҗғжүҖжңүCPUзҡ„гҖӮиҖҢпјҢ(2)е’Ң(3)з»ҸиҝҮжҸ’е…Ҙд»Јз Ғд№ҹеҸҜд»ҘиҪ¬жҚўжҲҗ(1)зҡ„жғ…еҶөгҖӮ
жғ…еҶөDпјҢCPUжү§иЎҢд»Јз ҒеҰӮдёӢпјҡпјҲAе’ҢBзҡ„еҲқеҖјйғҪжҳҜ0пјү
иҜҘжғ…еҶөжҳҜжғ…еҶө7жҳҜзұ»дјјзҡ„гҖӮеңЁYзӯү1зҡ„ж—¶еҖҷпјҢжңҖз»ҲAзӯүдәҺ2.
6.3.1.2 зҺ°д»ЈCPUеҸҜд»ҘworkпјҢдҪҶжҳҜдёҚйҖӮеә”еңЁжҜ”иҫғж—§зҡ„йӮЈдәӣCPU
(1) Ears to Mouths
жғ…еҶөAпјҢCPUжү§иЎҢд»Јз ҒеҰӮдёӢпјҡпјҲAе’ҢBеҲқеҖјйғҪжҳҜ0пјҢе…¶д»–еҸҳйҮҸеҲқе§ӢеҖјжҳҜ-1пјү
иҝҷз§Қжғ…еҶөдёӢпјҢжҜ”иҫғе®№жҳ“жҺЁз®—еҮәXзӯү1зҡ„ж—¶еҖҷпјҢYеҸҜиғҪдёә0д№ҹеҸҜиғҪдёә1пјҢеҪ“XзӯүдәҺ0зҡ„ж—¶еҖҷпјҢд№ҹжҜ”иҫғе®№жҳ“жҺЁз®—еҮәYеҖјеҸҜд»Ҙдёә1гҖӮдҪҶжҳҜпјҢXзӯү0зҡ„ж—¶еҖҷпјҢYжңүжІЎеҸҜиғҪд№ҹжҳҜ0е‘ўпјҹ
жҲ‘们йҖҡиҝҮжҸ’е…Ҙд»Јз Ғ(Z=X)пјҢиҝҷж ·е°ұиҪ¬жҚўжҲҗжғ…еҶөCпјҢеңЁXзӯүдәҺ0пјҢZзӯүдәҺ0зҡ„ж—¶еҖҷпјҢйӮЈд№Ҳmemory barrierжқЎд»¶жҲҗз«ӢпјҢдәҺжҳҜYеҝ…然зӯү1гҖӮ然иҖҢпјҢеҰӮжһңXзӯүдәҺ0зҡ„ж—¶еҖҷпјҢZдёҚзӯүдәҺ0пјҢиҝҷдёӘж—¶еҖҷmemory barrierжқЎд»¶е°ұдёҚиғҪжҲҗз«ӢдәҶпјҢиҝҷдёӘж—¶еҖҷYе°ұеҸҜиғҪдёә0гҖӮ
дёӢйқўжҲ‘们жқҘи®ІдёӢпјҢдёҠйқўжғ…еҶөдёӢдјҡеҮәзҺ°Xе’ҢYеҗҢж—¶дёә0гҖӮеңЁдёҖдёӘжңүInvalidate queueе’Ңstore bufferзҡ„зі»з»ҹдёӯпјҢBе’ҢXеңЁCPU1зҡ„local cacheдёӯ并且жҳҜзӢ¬еҚ зҡ„пјҢAе’ҢYеңЁCPU2зҡ„local cacheдёӯ并且д№ҹжҳҜзӢ¬еҚ зҡ„гҖӮCPUsзҡ„жү§иЎҢеәҸеҲ—еҰӮдёӢпјҡ
```
[1] CPU1еҜ№AеҸ‘иө·storeж“ҚдҪңпјҢз”ұдәҺAдёҚеңЁCPU1зҡ„cacheдёӯпјҢCPU1еҸ‘иө·invalidate messageпјҢеҪ“然пјҢCPU1дёҚдјҡеҒңдёӢе®ғзҡ„и„ҡжӯҘпјҢе°ҶAзҡ„ж–°еҖј'1'ж”ҫе…Ҙstore bufferпјҢе®ғе°ұ继з»ӯеҫҖдёӢжү§иЎҢ
[2] smp_mbдҪҝеҫ—CPU1еҜ№store bufferдёӯзҡ„entryиҝӣиЎҢж ҮжіЁпјҲеҪ“然д№ҹеҜ№Invalidate QueueиҝӣиЎҢж ҮжіЁпјҢдёҚиҝҮе’Ңжң¬еңәжҷҜж— е…іпјүпјҢstore Aзҡ„ж“ҚдҪңеҸҳжҲҗmarkedзҠ¶жҖҒ
[3] CPU2еҜ№BеҸ‘иө·storeж“ҚдҪңпјҢз”ұдәҺBдёҚеңЁCPU2зҡ„cacheдёӯпјҢCPU2еҸ‘иө·invalidate messageпјҢеҪ“然пјҢCPU2дёҚдјҡеҒңдёӢе®ғзҡ„и„ҡжӯҘпјҢе°ҶBзҡ„ж–°еҖј'1'ж”ҫе…Ҙstore bufferпјҢе®ғе°ұ继з»ӯеҫҖдёӢжү§иЎҢ
[4] CPU2收еҲ°CPU1зҡ„invalidate messageе°ҶиҜҘmessageж”ҫе…ҘInvalidate QueueеҗҺ继з»ӯеүҚиЎҢгҖӮ
[5] smp_mbдҪҝеҫ—CPU2еҜ№store bufferдёӯзҡ„entryиҝӣиЎҢж ҮжіЁпјҲеҪ“然д№ҹеҜ№Invalidate QueueиҝӣиЎҢж ҮжіЁпјүпјҢstore Bзҡ„ж“ҚдҪңеҸҳжҲҗmarkedзҠ¶жҖҒ
[6] CPU1收еҲ°CPU2зҡ„invalidate messageе°ҶиҜҘmessageж”ҫе…ҘInvalidate QueueеҗҺ继з»ӯеүҚиЎҢгҖӮ
[7] CPU1еүҚиЎҢжү§иЎҢload BпјҢз”ұдәҺBеңЁCPU1зҡ„local cacheзӢ¬еҚ зҡ„(CPU1并дёҚйңҖиҰҒеҸ‘йҖҒд»»дҪ•MESIеҚҸи®®ж¶ҲжҒҜпјҢе®ғ并дёҚйңҖиҰҒз«ӢеҚіеӨ„зҗҶInvalidate QueueйҮҢйқўзҡ„ж¶ҲжҒҜ)пјҢдәҺжҳҜCPU1д»Һlocal cacheдёӯеҫ—еҲ°Bзҡ„еҖј'0'пјҢжҺҘзқҖCPU1继з»ӯжү§иЎҢstore XпјҢз”ұдәҺXд№ҹеңЁCPU1зҡ„local cacheзӢ¬еҚ зҡ„пјҢдәҺжҳҜпјҢCPU1е°ҶXзҡ„ж–°еҖјдҝ®ж”№дёәBзҡ„еҖј'0'并е°Ҷе…¶ж”ҫе…Ҙstore bufferдёӯгҖӮ
[8] CPU2еүҚиЎҢжү§иЎҢload AпјҢз”ұдәҺAеңЁCPU2зҡ„local cacheзӢ¬еҚ зҡ„(CPU2并дёҚйңҖиҰҒеҸ‘йҖҒд»»дҪ•MESIеҚҸи®®ж¶ҲжҒҜпјҢе®ғ并дёҚйңҖиҰҒз«ӢеҚіеӨ„зҗҶInvalidate QueueйҮҢйқўзҡ„ж¶ҲжҒҜ)пјҢдәҺжҳҜCPU2д»Һlocal cacheдёӯеҫ—еҲ°Aзҡ„еҖј'0'пјҢжҺҘзқҖCPU2继з»ӯжү§иЎҢstore YпјҢз”ұдәҺYд№ҹеңЁCPU2зҡ„local cacheзӢ¬еҚ зҡ„пјҢдәҺжҳҜпјҢCPU2е°ҶYзҡ„ж–°еҖјдҝ®ж”№дёәBзҡ„еҖј'0'并е°Ҷе…¶ж”ҫе…Ҙstore bufferдёӯгҖӮ
[9] CPU1ејҖе§ӢеӨ„зҗҶInvalidate QueueйҮҢйқўзҡ„ж¶ҲжҒҜпјҢе°Ҷжң¬local cacheдёӯзҡ„BзҪ®дёәInvalideпјҢеҗҢж—¶е“Қеә”Invalidate response messageз»ҷCPU2
[10] CPU2收еҲ°Invalidate response messageеҗҺпјҢиҝҷдёӘж—¶еҖҷеҸҜд»Ҙе°Ҷstore bufferйҮҢйқўзҡ„Bе’ҢYеҶҷеӣһcache lineпјҢжңҖеҗҺBдёә1пјҢYдёә0гҖӮ
[11] CPU1е’ҢCPU2зұ»дјјпјҢжңҖз»ҲAдёә1пјҢXдёә0.
```
(2) Pass in the Night
жғ…еҶөFпјҢCPUжү§иЎҢд»Јз ҒеҰӮдёӢпјҡпјҲAе’ҢBеҲқеҖјйғҪжҳҜ0пјҢе…¶д»–еҸҳйҮҸеҲқе§ӢеҖјжҳҜ-1пјү
| CPU1 | CPU2 |
| ------ | ------ |
| A = 1; | B = 2;|
| smp_mb(); | smp_mb(); |
| B = 1; | A = 2; |
жғ…еҶөFпјҢжӯЈеёёжғ…еҶөдёӢпјҢж— и®әеҰӮдҪ•пјҢдҪҶжҳҜж— и®әеҰӮдҪ•пјҢеңЁдёӨдёӘCPUйғҪжү§иЎҢе®ҢдёҠйқўзҡ„д»Јз Ғд№ӢеҗҺ{A==1,B==2} иҝҷз§Қжғ…еҶөдёҚеҸҜиғҪеҸ‘з”ҹгҖӮдёҚе№ёзҡ„жҳҜпјҢеңЁдёҖдәӣиҖҒзҡ„CPUжһ¶жһ„дёҠпјҢжҳҜеҸҜиғҪеҮәзҺ°{A==1,B==2} зҡ„пјҢеҮәзҺ°иҝҷз§Қжғ…еҶөе’ҢдёҠйқўзҡ„еҺҹеӣ жңүзӮ№зұ»дјјпјҢдёӢйқўд№ҹз®ҖеҚ•жҸҸиҝ°дёҖдёӢпјҢеңЁдёҖдёӘжңүInvalidate queueе’Ңstore bufferзҡ„зі»з»ҹдёӯпјҢBеңЁCPU1зҡ„local cacheдёӯ并且жҳҜзӢ¬еҚ зҡ„пјҢAеңЁCPU2зҡ„local cacheдёӯ并且д№ҹжҳҜзӢ¬еҚ зҡ„гҖӮCPUsзҡ„жү§иЎҢеәҸеҲ—еҰӮдёӢпјҡ
```
[1]~[6]е’Ң (1) Ears to Mouthsдёӯзҡ„еҹәжң¬дёҖж ·
[7] CPU1继з»ӯеүҚиЎҢпјҢз”ұдәҺBеңЁCPU1зҡ„local cacheзӢ¬еҚ зҡ„(CPU1并дёҚйңҖиҰҒеҸ‘йҖҒд»»дҪ•MESIеҚҸи®®ж¶ҲжҒҜпјҢе®ғ并дёҚйңҖиҰҒз«ӢеҚіеӨ„зҗҶInvalidate QueueйҮҢйқўзҡ„ж¶ҲжҒҜ)пјҢдәҺжҳҜпјҢCPU1е°ҶBзҡ„ж–°еҖј'1'ж”ҫе…Ҙstore bufferдёӯгҖӮ
[8] CPU2继з»ӯеүҚиЎҢпјҢз”ұдәҺAеңЁCPU2зҡ„local cacheзӢ¬еҚ зҡ„(CPU1并дёҚйңҖиҰҒеҸ‘йҖҒд»»дҪ•MESIеҚҸи®®ж¶ҲжҒҜпјҢе®ғ并дёҚйңҖиҰҒз«ӢеҚіеӨ„зҗҶInvalidate QueueйҮҢйқўзҡ„ж¶ҲжҒҜ)пјҢдәҺжҳҜпјҢCPU2е°ҶAзҡ„ж–°еҖј'2'ж”ҫе…Ҙstore bufferдёӯгҖӮ
[9] CPU1ејҖе§ӢеӨ„зҗҶInvalidate QueueйҮҢйқўзҡ„ж¶ҲжҒҜпјҢе°Ҷжң¬local cacheдёӯзҡ„BзҪ®дёәInvalide(иҝҷдёӘж—¶еҖҷstore bufferйҮҢйқўBзҡ„ж–°еҖј'1'д№ҹиў«invalidateдәҶ)пјҢеҗҢж—¶е“Қеә”Invalidate response messageз»ҷCPU2
[9] CPU2ејҖе§ӢеӨ„зҗҶInvalidate QueueйҮҢйқўзҡ„ж¶ҲжҒҜпјҢе°Ҷжң¬local cacheдёӯзҡ„зҪ®дёәInvalide(иҝҷдёӘж—¶еҖҷstore bufferйҮҢйқўAзҡ„ж–°еҖј'2'д№ҹиў«invalidateдәҶ)пјҢеҗҢж—¶е“Қеә”Invalidate response messageз»ҷCPU1
[10] CPU1收еҲ°Invalidate response messageпјҢиҝҷдёӘж—¶еҖҷеҸҜд»Ҙе°Ҷstore bufferдёӯзҡ„A=1еҲ·еҲ°cache lineпјҢжңҖз»ҲAзҡ„еҖјдёә1
[11] CPU2收еҲ°Invalidate response messageпјҢиҝҷдёӘж—¶еҖҷеҸҜд»Ҙе°Ҷstore bufferдёӯзҡ„B=2еҲ·еҲ°cache lineпјҢжңҖз»ҲBзҡ„еҖјдёә2
```
еҲ°иҝҷжқҘпјҢеӨ§е®¶еә”иҜҘдјҡеҸ‘зҺ°пјҢ第дёҖдёӘиөӢеҖјпјҲеҜ№дәҺCPU1иҖҢиЁҖжҳҜA = 1пјҢеҜ№дәҺCPU2иҖҢиЁҖжҳҜB = 2пјүе…¶е®һжҳҜpass in the nightпјҢйқҷжӮ„жӮ„зҡ„иө°иҝҮпјҢиҖҢ第дәҢдёӘиөӢеҖјпјҲеҜ№дәҺCPU1иҖҢиЁҖжҳҜB = 1пјҢеҜ№дәҺCPU2иҖҢиЁҖжҳҜA = 2пјүеҲҷдјҡеҗҺеҸ‘е…ҲиҮіпјҢжңҖз»ҲеҜјиҮҙ第дёҖдёӘиөӢеҖје…ҲеҸ‘иҖҢеҗҺиҮіиҰҶзӣ–第дәҢдёӘиөӢеҖјгҖӮ
е…¶е®һпјҢеҸӘиҰҒз¬ҰеҗҲдёӢйқўзҡ„дҪҝз”ЁжЁЎејҸпјҢдёҠйқўжҸҸиҝ°зҡ„ж“ҚдҪңйЎәеәҸпјҲ第дәҢдёӘstoreзҡ„з»“жһң被第дёҖдёӘstoreиҰҶзӣ–пјүйғҪжҳҜжңүеҸҜиғҪеҸ‘з”ҹзҡ„пјҡ
| CPU1 | CPU2 |
| ------ | ------ |
| A = 1; | B = 2;|
| smp_mb(); | smp_mb(); |
|xxxx; | xxxx; |
еүҚйқўиҜҙзҡ„'ears to mouths'д№ҹжҳҜиҝҷз§ҚжЁЎејҸпјҢдёҚиҝҮпјҢеҜ№дәҺ21дё–зәӘзҡ„硬件系з»ҹиҖҢиЁҖпјҢ硬件е·ҘзЁӢеёҲе·Із»Ҹеё®еҝҷи§ЈеҶідәҶдёҠйқўзҡ„й—®йўҳпјҢеӣ жӯӨпјҢиҪҜ件е·ҘзЁӢеёҲеҸҜд»Ҙе®үе…Ёзҡ„дҪҝз”ЁStores вҖңPass in the NightвҖқгҖӮ
6.3.1.3 еҹәжң¬дёҚеҸҜ移жӨҚ
еү©дёӢзҡ„жғ…еҶө0гҖҒ1гҖҒ2гҖҒ4гҖҒ6гҖҒ8гҖҒ9иҝҷ7з§Қжғ…еҶөзҡ„з»„еҗҲпјҢеҚідҪҝжҳҜеңЁ21дё–зәӘзҡ„йӮЈдәӣж–°зҡ„CPU硬件平еҸ°дёҠпјҢд№ҹжҳҜдёҚиғҪеӨҹдҝқиҜҒжҳҜеҸҜ移жӨҚзҡ„гҖӮеҪ“然пјҢеңЁдёҖдәӣ硬件平еҸ°дёҠпјҢжҲ‘们иҝҳжҳҜеҸҜд»Ҙеҫ—еҲ°дёҖдәӣзЎ®е®ҡзҡ„жү§иЎҢйЎәеәҸзҡ„гҖӮ
(1) Ears to Ears
жғ…еҶө0пјҢCPUsдёҠе…ЁжҳҜloadж“ҚдҪң
| CPU1 | CPU2 |
| ------ | ------ |
| load A; | load B;|
| smp_mb(); | smp_mb(); |
| load B; | load A; |
з”ұдәҺloadж“ҚдҪңдёҚиғҪж”№еҸҳmemoryзҡ„зҠ¶жҖҒпјҢеӣ жӯӨпјҢдёҖдёӘCPUдёҠзҡ„loadжҳҜж— жі•ж„ҹзҹҘеҲ°еҸҰеӨ–дёҖдҫ§CPUзҡ„loadж“ҚдҪңзҡ„гҖӮдёҚиҝҮпјҢеҰӮжһңCPU2дёҠзҡ„load Bж“ҚдҪңиҝ”еӣһзҡ„еҖјжҜ”CPU 1дёҠзҡ„load Bиҝ”еӣһзҡ„еҖјж–°зҡ„иҜқпјҲеҚіCPU2дёҠload BжҷҡдәҺCPU1зҡ„load Bжү§иЎҢпјүпјҢйӮЈд№ҲеҸҜд»ҘжҺЁж–ӯCPU2зҡ„load Aиҝ”еӣһзҡ„еҖјиҰҒд№Ҳе’ҢCPU1дёҠзҡ„load Aиҝ”еӣһеҖјдёҖж ·ж–°пјҢиҰҒд№ҲеҠ иҪҪжӣҙж–°зҡ„еҖјгҖӮ
(2) Mouth to Mouth, Ear to Ear
иҝҷдёӘз»„еҗҲзҡ„зү№зӮ№жҳҜдёҖдёӘеҸҳйҮҸеҸӘжҳҜжү§иЎҢstoreж“ҚдҪңпјҢиҖҢеҸҰеӨ–дёҖдёӘеҸҳйҮҸеҸӘжҳҜиҝӣиЎҢloadж“ҚдҪңгҖӮжү§иЎҢеәҸеҲ—еҰӮдёӢпјҡ
| CPU1 | CPU2 |
| ------ | ------ |
| load A; | store B;|
| smp_mb(); | smp_mb(); |
| store B; | load A; |
иҝҷз§Қжғ…еҶөдёӢпјҢеҰӮжһңCPU2дёҠзҡ„store BжңҖеҗҺеҸ‘з”ҹ(д№ҹе°ұжҳҜпјҢдёҠйқўд»Јз Ғжү§иЎҢе®ҢжҜ•еҗҺпјҢеңЁжү§иЎҢдёҖж¬Ўload Bеҫ—еҲ°зҡ„еҖјжҳҜCPU2 store Bзҡ„еҖј)пјҢйӮЈд№ҲеҸҜд»ҘжҺЁж–ӯCPU2зҡ„load Aиҝ”еӣһзҡ„еҖјиҰҒд№Ҳе’ҢCPU1дёҠзҡ„load Aиҝ”еӣһеҖјдёҖж ·ж–°пјҢиҰҒд№ҲеҠ иҪҪжӣҙж–°зҡ„еҖјгҖӮ
(3) Only One Store
| CPU1 | CPU2 |
| ------ | ------ |
| load A; | load B;|
| smp_mb(); | smp_mb(); |
| load B; | store A; |
иҝҷз§Қжғ…еҶөдёӢпјҢеҸӘжңүдёҖдёӘеҸҳйҮҸзҡ„storeж“ҚдҪңеҸҜд»Ҙиў«еҸҰеӨ–зҡ„CPUдёҠзҡ„loadж“ҚдҪңи§ӮеҜҹеҲ°пјҢеҰӮжһңеңЁCPU1дёҠиҝҗиЎҢзҡ„load Aж„ҹзҹҘеҲ°дәҶеңЁCPU2дёҠеҜ№Aзҡ„иөӢеҖјпјҢйӮЈд№ҲпјҢCPU1дёҠзҡ„load Bеҝ…然иғҪи§ӮеҜҹеҲ°е’ҢCPU2дёҠload BдёҖж ·зҡ„еҖјжҲ–иҖ…жӣҙж–°зҡ„еҖјгҖӮ
6.3.2 memory barrierеҶ…еӯҳеұҸйҡңзұ»еһӢ
6.3.2.1 жҳҫејҸеҶ…еӯҳеұҸйҡң
6.3.1з« иҠӮеҲ—дёҫзҡ„16з§Қжғ…еҶөзҡ„дҫӢеӯҗдёӯеҶ…еӯҳеұҸйҡңsmp_mb()жҢҮзҡ„жҳҜдёҖз§Қе…ЁеҠҹиғҪеҶ…еӯҳеұҸйҡң(General memory barrier)пјҢ然иҖҢе…ЁеҠҹиғҪзҡ„еҶ…еӯҳеұҸйҡңеҜ№жҖ§иғҪзҡ„жқҖдјӨиҫғеӨ§пјҢжҹҗдәӣжғ…еҶөдёӢжҲ‘们еҸҜд»ҘдҪҝз”ЁдёҖдәӣејұдёҖзӮ№зҡ„еҶ…еӯҳеұҸйҡңгҖӮеңЁжңүInvalidate queueе’Ңstore bufferзҡ„зі»з»ҹдёӯпјҢе…ЁеҠҹиғҪзҡ„еҶ…еӯҳеұҸйҡңж—ўдјҡmark store bufferд№ҹдјҡmark invalidate queueпјҢеҜ№дәҺжғ…еҶө3пјҢCPU1е…ЁжҳҜloadе®ғеҸӘйңҖиҰҒmark invalidate queueеҚіеҸҜпјҢзӣёеҸҚCPU2е…ЁжҳҜstoreпјҢе®ғеҸӘйңҖmark store bufferеҚіеҸҜпјҢдәҺжҳҜCPU1еҸӘйңҖиҰҒдҪҝз”ЁиҜ»еҶ…еӯҳеұҸйҡң(Read memory barrier)пјҢCPU2еҸӘйңҖдҪҝз”ЁеҶҷеҶ…еӯҳеұҸйҡң(Write memory barrier)гҖӮ
жғ…еҶө3пјҢдҝ®ж”№еҰӮдёӢ
| CPU1 | CPU2 |
| ------ | ------ |
| X = A; | B = 1; |
| read_mb(); | write_mb(); |
| Y = B; | A = 1; |
еҲ°иҝҷжқҘпјҢжҲ‘们зҹҘйҒ“жңү3з§ҚдёҚеҗҢзҡ„еҶ…еӯҳеұҸйҡңпјҢиҝҳжІЎжңүе…¶д»–зҡ„е‘ўпјҹжҲ‘们жқҘзңӢдёҖдёӘдҫӢеӯҗпјҡ
еҲқе§ӢеҢ–
int A = 1;
int B = 2;
int C = 3;
int *P = &A;
int *Q = &B;
йҖҡеёёжғ…еҶөдёӢпјҢQжңҖеҗҺиҰҒд№ҲзӯүдәҺ&AпјҢиҰҒд№ҲзӯүдәҺ&BгҖӮд№ҹе°ұжҳҜиҜҙпјҡQ == &AпјҢ D == 1 жҲ–иҖ… Q == &BпјҢ D == 4пјҢз»қеҜ№дёҚдјҡеҮәзҺ°Q == &BпјҢ D == 2зҡ„жғ…еҪўгҖӮ然иҖҢпјҢи®©дәәеҗғжғҠзҡ„жҳҜпјҢDEC AlphaдёӢпјҢе°ұеҸҜиғҪеҮәзҺ°Q == &BпјҢ D == 2зҡ„жғ…еҪўгҖӮ
дәҺжҳҜпјҢеңЁDEC AlphaдёӢпјҢCPU2дёҠзҡ„Q=PдёӢйқўйңҖиҰҒжҸ’е…ҘдёҖдёӘmemory barrierжқҘдҝқиҜҒзЁӢеәҸйЎәеәҸпјҢиҝҷжқҘз”ЁдёҖдёӘиҜ»еҶ…еӯҳеұҸйҡң(read_mb)еҚіеҸҜпјҢдҪҶжҳҜжҲ‘们еҸ‘зҺ°CPU2дёҠзҡ„Q = Pе’ҢD = *QжҳҜдёҖдёӘж•°жҚ®дҫқиө–е…ізі»пјҢжҳҜеҗҰеҸҜд»Ҙеј•е…ҘдёҖдёӘжӣҙдёәиҪ»йҮҸзҡ„еҶ…еӯҳеұҸйҡңжқҘи§ЈеҶіе‘ўпјҹ
дәҺжҳҜиҝҷйҮҢеј•е…ҘдёҖз§ҚеҶ…еӯҳеұҸйҡң-ж•°жҚ®дҫқиө–еҶ…еӯҳеұҸйҡңdd_mb(data dependency memory barrier)пјҢdd_mbжҳҜдёҖз§ҚжҜ”read_mbиҰҒејұдёҖдәӣзҡ„еҶ…еӯҳеұҸйҡңпјҲиҝҷйҮҢзҡ„ејұжҳҜжҢҮеҜ№жҖ§иғҪзҡ„жқҖдјӨеҠӣиҰҒејұдёҖдәӣпјүгҖӮread_mbйҖӮз”ЁжүҖжңүзҡ„loadж“ҚдҪңпјҢиҖҢddmbиҰҒжұӮloadд№Ӣй—ҙжңүдҫқиө–е…ізі»пјҢеҚіз¬¬дәҢдёӘloadж“ҚдҪңдҫқиө–第дёҖдёӘloadж“ҚдҪңзҡ„жү§иЎҢз»“жһңпјҲдҫӢеҰӮпјҡе…Ҳloadең°еқҖпјҢ然еҗҺloadиҜҘең°еқҖзҡ„еҶ…е®№пјүгҖӮddmbиў«з”ЁжқҘдҝқиҜҒиҝҷж ·зҡ„ж“ҚдҪңйЎәеәҸпјҡеңЁжү§иЎҢ第дёҖдёӘload Aж“ҚдҪңзҡ„ж—¶еҖҷпјҲAжҳҜдёҖдёӘең°еқҖеҸҳйҮҸпјүпјҢеҠЎеҝ…дҝқиҜҒAжҢҮеҗ‘зҡ„ж•°жҚ®е·Із»Ҹжӣҙж–°гҖӮеҸӘжңүдҝқиҜҒдәҶиҝҷж ·зҡ„ж“ҚдҪңйЎәеәҸпјҢеңЁз¬¬дәҢloadж“ҚдҪңзҡ„ж—¶еҖҷжүҚиғҪиҺ·еҸ–Aең°еқҖдёҠдҝқеӯҳзҡ„ж–°еҖјгҖӮ
еңЁзәҜзІ№зҡ„ж•°жҚ®дҫқиө–е…ізі»дёӢдҪҝз”Ёж•°жҚ®дҫқиө–еҶ…еӯҳеұҸйҡңdd_mbжқҘдҝқиҜҒйЎәеәҸпјҢдҪҶжҳҜеҰӮжһңеҠ е…ҘдәҶжҺ§еҲ¶дҫқиө–пјҢйӮЈд№Ҳд»…д»…дҪҝз”Ёdd_mbжҳҜдёҚеӨҹзҡ„пјҢйңҖиҰҒдҪҝз”Ёread_mbпјҢзңӢдёӢйқўдҫӢеӯҗпјҡ
з”ұдәҺеҠ е…ҘдәҶжқЎд»¶if (t)дҫқиө–пјҢиҝҷе°ұдёҚжҳҜзңҹжӯЈзҡ„ж•°жҚ®дҫқиө–дәҶпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢCPUдјҡиҝӣиЎҢеҲҶж”Ҝйў„жөӢпјҢеҸҜиғҪдјҡ"жҠ„иҝ‘и·Ҝ"е…ҲеҺ»жү§иЎҢ*Qзҡ„loadж“ҚдҪңпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢйңҖиҰҒе°Ҷdata_dependency_mbж”№жҲҗread_mbгҖӮ
еҲ°иҝҷжқҘпјҢжҲ‘们зҹҘйҒ“жңү4дёӯдёҚеҗҢзҡ„еҶ…еӯҳеұҸйҡңз§Қзұ»пјҡ
```
[1] Write (or store) memory barriers -- еҶҷеҶ…еӯҳеұҸйҡң
[2] Data dependency barriers -- ж•°жҚ®дҫқиө–еҶ…еӯҳеұҸйҡң
[3] Read (or load) memory barriers -- иҜ»еҶ…еӯҳеұҸйҡң
[4] General memory barriers -- е…ЁеҠҹиғҪеҶ…еӯҳеұҸйҡң
```
6.3.2.2 йҡҗејҸеҶ…еӯҳеұҸйҡң
жңүдәӣж“ҚдҪңеҸҜд»Ҙйҡҗеҗ«memory barrierзҡ„еҠҹиғҪпјҢдё»иҰҒжңүдёӨз§Қзұ»еһӢзҡ„ж“ҚдҪңпјҡдёҖжҳҜеҠ й”Ғж“ҚдҪңпјҢеҸҰеӨ–дёҖдёӘжҳҜйҮҠж”ҫй”Ғзҡ„ж“ҚдҪңгҖӮ
```
[1] LOCK operations -- еҠ й”Ғж“ҚдҪң
[2] UNLOCK operations -- йҮҠж”ҫй”Ғж“ҚдҪң
```
(1) еҠ й”Ғж“ҚдҪңиў«и®ӨдёәжҳҜдёҖз§Қhalf memory barrierпјҢеҠ й”Ғж“ҚдҪңд№ӢеүҚзҡ„еҶ…еӯҳи®ҝй—®еҸҜд»Ҙд»»ж„Ҹ***иҝҮеҠ й”Ғж“ҚдҪңпјҢеңЁе…¶д»–жү§иЎҢпјҢдҪҶжҳҜпјҢеҸҰеӨ–дёҖдёӘж–№еҗ‘з»қеҜ№жҳҜдёҚе…Ғи®ёзҡ„пјҡеҚіеҠ й”Ғж“ҚдҪңд№ӢеҗҺзҡ„еҶ…еӯҳи®ҝй—®ж“ҚдҪңпјҢеҝ…йЎ»еңЁеҠ й”Ғж“ҚдҪңд№ӢеҗҺе®ҢжҲҗгҖӮ
(2) е’Ңlockж“ҚдҪңдёҖж ·пјҢunlockд№ҹжҳҜhalf memory barrierгҖӮе®ғзЎ®дҝқеңЁunlockж“ҚдҪңд№ӢеүҚзҡ„еҶ…еӯҳж“ҚдҪңе…ҲдәҺunlockж“ҚдҪңе®ҢжҲҗпјҢд№ҹе°ұжҳҜиҜҙunlockд№ӢеүҚзҡ„ж“ҚдҪңз»қеҜ№дёҚиғҪи¶ҠиҝҮunlockиҝҷдёӘзҜұз¬ҶпјҢеңЁе…¶еҗҺжү§иЎҢгҖӮеҪ“然пјҢеҸҰеӨ–дёҖдёӘж–№еҗ‘жҳҜOKзҡ„пјҢд№ҹе°ұжҳҜиҜҙпјҢunlockд№ӢеҗҺзҡ„еҶ…еӯҳж“ҚдҪңеҸҜд»ҘеңЁunlockж“ҚдҪңд№ӢеүҚе®ҢжҲҗгҖӮ
жҲ‘们зңӢдёӢйқўдёҖдёӘдҫӢеӯҗпјҡ
```
1 *A = a;
2 LOCK
3 C = 1;
4 UNLOCK
5 *B = b;
```
дёҠйқўзҡ„зЁӢеәҸжңүеҸҜиғҪжҢүз…§дёӢйқўзҡ„йЎәеәҸжү§иЎҢпјҡ
```
2 LOCK
3 C = 1;
5 *B = b;
1 *A = a;
4 UNLOCK
```
йҖҡиҝҮдёҠйқўпјҢжҲ‘们еҫ—зҹҘпјҢз»ҸLOCK-UNLOCKеҜ№дёҚиғҪе®һзҺ°е®Ңе…Ёзҡ„еҶ…еӯҳеұҸйҡңзҡ„еҠҹиғҪпјҢдҪҶжҳҜпјҢе®ғ们д№ҹзҡ„зЎ®дјҡеҪұе“ҚеҶ…еӯҳи®ҝй—®йЎәеәҸпјҢеҸӮиҖғдёӢйқўзҡ„дҫӢеӯҗпјҡ
еӨҡдёӘCPUеҜ№дёҖжҠҠй”Ғж“ҚдҪңзҡ„еңәжҷҜпјҡ
иҝҷз§Қжғ…еҶөдёӢпјҢCPU1жҲ–иҖ…CPU2пјҢеҸӘиғҪжңүдёҖдёӘиҝӣе…Ҙдёҙз•ҢеҢәпјҢеҰӮжһңжҳҜCPU1иҝӣе…Ҙдёҙз•ҢеҢәзҡ„иҜқпјҢеҜ№A B Cзҡ„иөӢеҖјж“ҚдҪңпјҢеҝ…然еңЁеҜ№F G HеҸҳйҮҸиөӢеҖјд№ӢеүҚе®ҢжҲҗгҖӮеҰӮжһңCPU2иҝӣе…Ҙдёҙз•ҢеҢәзҡ„иҜқпјҢеҜ№E F Gзҡ„иөӢеҖјж“ҚдҪңпјҢеҝ…然еңЁеҜ№B C DеҸҳйҮҸиөӢеҖјд№ӢеүҚе®ҢжҲҗгҖӮ
6.3.3 C++11 memory order
иҰҒзј–еҶҷеҮәжӯЈзЎ®зҡ„lock freeеӨҡзәҝзЁӢзЁӢеәҸпјҢжҲ‘们йңҖиҰҒеңЁжӯЈзЎ®зҡ„дҪҚзҪ®дёҠжҸ’е…ҘеҗҲйҖӮзҡ„memory barrierд»Јз ҒпјҢ然иҖҢдёҚеҗҢCPUжһ¶жһ„еҜ№дәҺзҡ„memory barrierжҢҮд»ӨеҚғе·®дёҮеҲ«пјҢиҰҒеҶҷеҮәеҸҜ移жӨҚзҡ„C++зЁӢеәҸпјҢжҲ‘们йңҖиҰҒдёҖдёӘиҜӯиЁҖеұӮйқўзҡ„Memory Order规иҢғпјҢд»Ҙдҫҝзј–иҜ‘еҷЁеҸҜд»Ҙж №жҚ®дёҚеҗҢCPUжһ¶жһ„жҸ’е…ҘдёҚеҗҢзҡ„memory barrierжҢҮд»ӨпјҢжҲ–иҖ…并дёҚйңҖиҰҒжҸ’е…ҘйўқеӨ–зҡ„memory barrierжҢҮд»ӨгҖӮ
жңүдәҶиҝҷдёӘMemory Order规иҢғпјҢжҲ‘们еҸҜд»ҘеңЁhigh level languageеұӮйқўе®һзҺ°еҜ№еңЁеӨҡеӨ„зҗҶеҷЁдёӯеӨҡзәҝзЁӢе…ұдә«еҶ…еӯҳдәӨдә’зҡ„ж¬ЎеәҸжҺ§еҲ¶пјҢиҖҢдёҚз”ЁиҖғиҷ‘compilerпјҢCPU archзҡ„дёҚеҗҢеҜ№еӨҡзәҝзЁӢзј–зЁӢзҡ„еҪұе“ҚдәҶгҖӮ
C++11жҸҗдҫӣ6з§ҚеҸҜд»Ҙеә”з”ЁдәҺеҺҹеӯҗеҸҳйҮҸзҡ„еҶ…еӯҳйЎәеәҸпјҡ
```
[1] memory_order_relaxed
[2] memory_order_consume
[3] memory_order_acquire
[4] memory_order_release
[5] memory_order_acq_rel
[6] memory_order_seq_cst
```
дёҠйқў6з§ҚеҶ…еӯҳйЎәеәҸжҸҸиҝ°дәҶдёүз§ҚеҶ…еӯҳжЁЎеһӢ(memory model)пјҡ
```
[1] sequential consistent(memory_order_seq_cst)
[2] relaxed(momory_order_relaxed)
[3] acquire release(memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel)
```
6.3.3.1 C++11дёӯзҡ„еҗ„з§Қе…ізі»
C++11еј•е…ҘдёҠйқў6з§ҚеҶ…еӯҳйЎәеәҸжң¬иҙЁдёҠжҳҜдёәдәҶи§ЈеҶі"visible side-effects"зҡ„й—®йўҳпјҢд№ҹе°ұжҳҜиҜ»ж“ҚдҪңзҡ„иҝ”еӣһеҖјй—®йўҳпјҢйҖҡдҝ—жқҘи®Іпјҡ
```
зәҝзЁӢ1жү§иЎҢеҶҷж“ҚдҪңAд№ӢеҗҺпјҢеҰӮдҪ•еҸҜйқ 并й«ҳж•Ҳең°дҝқиҜҒзәҝзЁӢ2жү§иЎҢзҡ„иҜ»ж“ҚдҪңBпјҢload Aзҡ„з»“жһңжҳҜе®Ңж•ҙеҸҜи§Ғзҡ„пјҹ
```
дёәдәҶи§ЈеҶі"visible side-effects"иҝҷдёӘй—®йўҳпјҢC++11еј•е…Ҙ"happens-before"е…ізі»пјҢе…¶е®ҡд№үеҰӮдёӢпјҡ
```
Let A and B represent operations performed by a multithreaded process. If A happens-before B, then the memory effects of A effectively become visible to the thread performing B before B is performed.
```
OKпјҢзҺ°еңЁй—®йўҳе°ұиҪ¬еҢ–дёәпјҡеҰӮдҪ•еңЁAгҖҒBдёӨдёӘж“ҚдҪңд№Ӣй—ҙе»әз«Ӣиө·happens-beforeе…ізі»гҖӮеңЁжҺЁеҜјhappens-beforeе…ізі»еүҚпјҢжҲ‘们е…ҲжҸҸиҝ°дёӢйқўеҮ дёӘе…ізі»пјҡ
6.3.3.1.1 Sequenced-before е…ізі»
е®ҡд№үеҰӮдёӢпјҡ
```
Sequenced before is an asymmetric, transitive, pair-wise relation between evaluations executed by a single thread, which induces a partial order among those evaluations.
```
Sequenced-beforeжҳҜеңЁеҗҢдёҖдёӘзәҝзЁӢеҶ…пјҢеҜ№жұӮеҖјйЎәеәҸе…ізі»зҡ„жҸҸиҝ°пјҢе®ғжҳҜйқһеҜ№з§°зҡ„пјҢеҸҜдј йҖ’зҡ„е…ізі»гҖӮ
```
[1] еҰӮжһңA is sequenced-before BпјҢд»ЈиЎЁAзҡ„жұӮеҖјдјҡе…Ҳе®ҢжҲҗпјҢжүҚиҝӣиЎҢеҜ№Bзҡ„жұӮеҖј
[2] еҰӮжһңA is not sequenced before B иҖҢдё” B is sequenced before AпјҢд»ЈиЎЁBзҡ„жұӮеҖјдјҡе…Ҳе®ҢжҲҗпјҢжүҚејҖе§ӢеҜ№Aзҡ„жұӮеҖјгҖӮ
[3] еҰӮжһңA is not sequenced before B иҖҢдё” B is not sequenced before AпјҢиҝҷж ·жұӮеҖјйЎәеәҸжҳҜдёҚзЎ®е®ҡзҡ„пјҢеҸҜиғҪAе…ҲдәҺBпјҢд№ҹеҸҜиғҪBе…ҲдәҺAпјҢд№ҹеҸҜиғҪдёӨз§ҚжұӮеҖјйҮҚеҸ гҖӮ
```
6.3.3.1.2 Carries a dependency е…ізі»
е®ҡд№үеҰӮдёӢпјҡ
```
Within the same thread, evaluation A that is sequenced-before evaluation B may also carry a dependency into B (that is, B depends on A), if any of the following is true
1) The value of A is used as an operand of B, except
a) if B is a call to std::kill_dependency
b) if A is the left operand of the built-in &&, ||, ?:, or , operators.
2) A writes to a scalar object M, B reads from M
3) A carries dependency into another evaluation X, and X carries dependency into B
```
з®ҖеҚ•жқҘи®ІпјҢcarries-a-dependency-to дёҘж јеә”з”ЁдәҺеҚ•дёӘзәҝзЁӢпјҢе»әз«ӢдәҶ ж“ҚдҪңй—ҙзҡ„ж•°жҚ®дҫқиө–жЁЎеһӢпјҡеҰӮжһңж“ҚдҪң A зҡ„з»“жһңиў«ж“ҚдҪң B дҪңдёәж“ҚдҪңж•°,йӮЈд№Ҳ A carries-a-dependency-to B(дёҖдёӘзӣҙи§Ӯзҡ„дҫӢеӯҗпјҡB=M[A] )пјҢ carries a dependencyе…·жңүдј йҖ’жҖ§гҖӮ
######6.3.3.1.3 Dependency-ordered before е…ізі»
иҜҘе…ізі»жҸҸиҝ°зҡ„жҳҜзәҝзЁӢй—ҙзҡ„дёӨдёӘж“ҚдҪңй—ҙзҡ„е…ізі»пјҢе®ҡд№үеҰӮдёӢпјҡ
```
Between threads, evaluation A is dependency-ordered before evaluation B if any of the following is true
1) A performs a release operation on some atomic M, and, in a different thread, B performs a consume operation on the same atomic M, and B reads a value written by any part of the release sequence headed by A.
2) A is dependency-ordered before X and X carries a dependency into B.
```
case 1жҢҮзҡ„жҳҜпјҡзәҝзЁӢ1зҡ„ж“ҚдҪңAеҜ№еҸҳйҮҸMжү§иЎҢвҖңreleaseвҖқеҶҷпјҢзәҝзЁӢ2зҡ„ж“ҚдҪңBеҜ№еҸҳйҮҸMжү§иЎҢвҖңconsumeвҖқиҜ»пјҢ并且ж“ҚдҪңBиҜ»еҸ–еҲ°зҡ„еҖјжәҗдәҺж“ҚдҪңAд№ӢеҗҺзҡ„вҖңreleaseвҖқеҶҷеәҸеҲ—дёӯзҡ„д»»дҪ•дёҖдёӘпјҲеҢ…жӢ¬ж“ҚдҪңAжң¬иә«пјүгҖӮ
case 2жҸҸиҝ°зҡ„жҳҜдёҖз§Қдј йҖ’жҖ§гҖӮ
6.3.3.1.4 Synchronized-with е…ізі»
е®ҡд№үеҰӮдёӢпјҡ
```
An atomic operation A that performs a release operation on an atomic object M synchronizes withan atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release sequence headed by A.
```
иҜҘе…ізі»жҸҸиҝ°зҡ„жҳҜпјҢеҜ№дәҺеңЁеҸҳйҮҸ x дёҠзҡ„еҶҷж“ҚдҪң W(x) synchronized-with еңЁиҜҘеҸҳйҮҸдёҠзҡ„иҜ»ж“ҚдҪң R(x), иҝҷдёӘиҜ»ж“ҚдҪңж¬ІиҜ»еҸ–зҡ„еҖјжҳҜ W(x) жҲ–еҗҢдёҖзәҝзЁӢйҡҸеҗҺзҡ„еңЁ x дёҠзҡ„еҶҷж“ҚдҪң WвҖҷ,жҲ–д»»ж„ҸзәҝзЁӢдёҖзі»еҲ—зҡ„еңЁ x дёҠзҡ„ read-modify-write ж“ҚдҪңпјҲеҰӮ fetch_add()жҲ–
compare_exchange_weak()пјүиҖҢиҝҷдёҖзі»еҲ—ж“ҚдҪңжңҖеҲқиҜ»еҲ° x зҡ„еҖјжҳҜ W(x) еҶҷе…Ҙзҡ„еҖјгҖӮ
дҫӢеҰӮпјҡA Write-Release Can Synchronize-With a Read-AcquireпјҢз®ҖеҚ•жқҘиҜҙпјҢ зәҝзЁӢ1зҡ„Aж“ҚдҪңеҶҷдәҶеҸҳйҮҸxпјҢзәҝзЁӢ2зҡ„Bж“ҚдҪңиҜ»дәҶеҸҳйҮҸxпјҢBиҜ»еҲ°зҡ„жҳҜAеҶҷе…Ҙзҡ„еҖјжҲ–иҖ…жӣҙж–°зҡ„еҖјпјҢйӮЈд№ҲA, B й—ҙеӯҳеңЁ synchronized-with е…ізі»гҖӮ
6.3.3.1.5 Inter-thread happens-before е…ізі»
е®ҡд№үеҰӮдёӢпјҡ
```
Between threads, evaluation A inter-thread happens before evaluation B if any of the following is true
1) A synchronizes-with B
2) A is dependency-ordered before B
3) A synchronizes-with some evaluation X, and X is sequenced-before B
4) A is sequenced-before some evaluation X, and X inter-thread happens-before B
5) A inter-thread happens-before some evaluation X, and X inter-thread happens-before B
```
Inter-thread happens-before е…ізі»е…·жңүдј йҖ’жҖ§гҖӮиҜҘе…ізі»жҸҸиҝ°зҡ„жҳҜпјҢеҰӮжһңA inter-thread happens-before BпјҢеҲҷзәҝзЁӢ1зҡ„Aж“ҚдҪңеҜ№memoryзҡ„и®ҝй—®з»“жһңпјҢдјҡеңЁзәҝзЁӢ2зҡ„Bж“ҚдҪңжү§иЎҢеүҚеҜ№зәҝзЁӢ2жҳҜеҸҜи§Ғзҡ„гҖӮ
######6.3.3.1.6 Happens-before е…ізі»
е®ҡд№үеҰӮдёӢпјҡ
```
Regardless of threads, evaluation A happens-before evaluation B if any of the following is true:
1) A is sequenced-before B
2) A inter-thread happens before B
```
Happens-before жҢҮжҳҺдәҶе“ӘдәӣжҢҮд»Өе°ҶзңӢеҲ°е“ӘдәӣжҢҮд»Өзҡ„з»“жһңгҖӮ
еҜ№дәҺеҚ•зәҝзЁӢпјҢsequenced-beforeе…ізі»еҚіжҳҜHappens-before е…ізі»пјҢиЎЁжҳҺдәҶж“ҚдҪң A жҺ’еҲ—еңЁеҸҰдёҖдёӘж“ҚдҪң B д№ӢеүҚгҖӮ
еҜ№дәҺеӨҡзәҝзЁӢпјҢеҲҷinter-thread happens beforeе…ізі»еҚіжҳҜHappens-before е…ізі»гҖӮ
Happens-before е…ізі»жҺЁеҜјеӣҫжҖ»з»“еҰӮдёӢпјҡ
6.3.3.2 6з§Қmemory orderжҸҸиҝ°
дёӢйқўжҲ‘们еҲҶеҲ«жқҘи§ЈжһҗдёҖдёӢдёҠйқўиҜҙзҡ„6з§Қmemory orderзҡ„дҪңз”Ёд»ҘеҸҠз”Ёжі•гҖӮ
6.3.3.2.1 йЎәеәҸдёҖиҮҙж¬ЎеәҸ - memory_order_seq_cst
SCжҳҜC++11дёӯеҺҹеӯҗеҸҳйҮҸзҡ„й»ҳи®ӨеҶ…еӯҳеәҸпјҢе®ғж„Ҹе‘ізқҖе°ҶзЁӢеәҸзңӢеҒҡжҳҜдёҖдёӘз®ҖеҚ•зҡ„еәҸеҲ—гҖӮеҰӮжһңеҜ№дәҺдёҖдёӘеҺҹеӯҗеҸҳйҮҸзҡ„ж“ҚдҪңйғҪжҳҜйЎәеәҸдёҖиҮҙзҡ„пјҢйӮЈд№ҲеӨҡзәҝзЁӢзЁӢеәҸзҡ„иЎҢдёәе°ұеғҸжҳҜиҝҷдәӣж“ҚдҪңйғҪд»ҘдёҖз§Қзү№е®ҡйЎәеәҸиў«еҚ•зәҝзЁӢзЁӢеәҸжү§иЎҢгҖӮ
д»ҺеҗҢжӯҘзҡ„и§’еәҰжқҘзңӢпјҢдёҖдёӘйЎәеәҸдёҖиҮҙзҡ„ store ж“ҚдҪң synchroniezd-with дёҖдёӘйЎәеәҸдёҖиҮҙзҡ„йңҖиҰҒиҜ»еҸ–зӣёеҗҢзҡ„еҸҳйҮҸзҡ„ load ж“ҚдҪңгҖӮйҷӨжӯӨд»ҘеӨ–пјҢйЎәеәҸжЁЎеһӢиҝҳдҝқиҜҒдәҶеңЁ load д№ӢеҗҺжү§иЎҢзҡ„йЎәеәҸдёҖиҮҙеҺҹеӯҗж“ҚдҪңйғҪеҫ—иЎЁзҺ°еҫ—еңЁ store д№ӢеҗҺе®ҢжҲҗгҖӮ
йЎәеәҸдёҖиҮҙж¬ЎеәҸеҜ№еҶ…еӯҳеәҸиҰҒжұӮжҜ”иҫғдёҘж јпјҢеҜ№жҖ§иғҪзҡ„жҚҹдјӨжҜ”иҫғеӨ§гҖӮ
6.3.3.2.2 жқҫејӣж¬ЎеәҸ - memory_order_relaxed
еңЁеҺҹеӯҗеҸҳйҮҸдёҠйҮҮз”Ё relaxed ordering зҡ„ж“ҚдҪңдёҚеҸӮдёҺ synchronized-with е…ізі»гҖӮеңЁеҗҢдёҖзәҝзЁӢеҶ…еҜ№еҗҢдёҖеҸҳйҮҸзҡ„ж“ҚдҪңд»ҚдҝқжҢҒhappens-beforeе…ізі»пјҢдҪҶиҝҷдёҺеҲ«зҡ„зәҝзЁӢж— е…ігҖӮеңЁ relaxed ordering дёӯе”ҜдёҖзҡ„иҰҒжұӮжҳҜеңЁеҗҢдёҖзәҝзЁӢдёӯпјҢеҜ№еҗҢдёҖеҺҹеӯҗеҸҳйҮҸзҡ„и®ҝй—®дёҚеҸҜд»Ҙиў«йҮҚжҺ’гҖӮ
жҲ‘们зңӢдёӢйқўзҡ„д»Јз ҒзүҮж®өпјҢxе’ҢyеҲқе§ӢеҖјйғҪжҳҜ0
```
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
```
з”ұдәҺж Үи®°дёәmemory_order_relaxedзҡ„atomicж“ҚдҪңеҜ№дәҺmemory orderеҮ д№ҺдёҚдҪңдҝқиҜҒпјҢйӮЈд№ҲжңҖз»ҲеҸҜиғҪиҫ“еҮәr1 == r2 == 42пјҢйҖ жҲҗиҝҷз§Қжғ…еҶөеҸҜиғҪжҳҜзј–иҜ‘еҷЁеҜ№жҢҮд»Өзҡ„йҮҚжҺ’пјҢеҜјиҮҙеңЁзәҝзЁӢ2дёӯDж“ҚдҪңе…ҲдәҺCж“ҚдҪңе®ҢжҲҗгҖӮ
Relaxed orderingжҜ”иҫғйҖӮз”ЁдәҺвҖңи®Ўж•°еҷЁвҖқдёҖзұ»зҡ„еҺҹеӯҗеҸҳйҮҸпјҢдёҚеңЁж„Ҹmemory orderзҡ„еңәжҷҜгҖӮ
6.3.3.2.3 иҺ·еҸ–-йҮҠж”ҫж¬ЎеәҸ --memory_order_release, memory_order_acquire, memory_order_acq_rel
Acquire-release дёӯжІЎжңүе…ЁеәҸе…ізі»пјҢдҪҶе®ғдҫӣдәҶдёҖдәӣеҗҢжӯҘж–№жі•гҖӮеңЁиҝҷз§ҚеәҸеҲ—жЁЎеһӢдёӢпјҢеҺҹеӯҗ load ж“ҚдҪңжҳҜ acquire ж“ҚдҪң(memory_order_acquire)пјҢеҺҹеӯҗ store ж“ҚдҪңжҳҜreleaseж“ҚдҪң(memory_order_release), еҺҹеӯҗread_modify_writeж“ҚдҪң(еҰӮfetch_add()пјҢexchange())еҸҜд»ҘжҳҜ acquire, release жҲ–дёӨиҖ…зҡҶжҳҜ(memory_order_acq_rel)гҖӮеҗҢжӯҘжҳҜжҲҗеҜ№еҮәзҺ°зҡ„пјҢе®ғеҮәзҺ°еңЁдёҖдёӘиҝӣиЎҢ release ж“ҚдҪңе’ҢдёҖдёӘиҝӣиЎҢ acquire ж“ҚдҪңзҡ„зәҝзЁӢй—ҙгҖӮдёҖдёӘ release ж“ҚдҪң syncrhonized-with дёҖдёӘжғіиҰҒиҜ»еҸ–еҲҡжүҚиў«еҶҷзҡ„еҖјзҡ„ acquire ж“ҚдҪңгҖӮ
д№ҹе°ұжҳҜпјҢеҰӮжһңеңЁзәҝзЁӢ1дёӯпјҢж“ҚдҪңAеҜ№еҺҹеӯҗMдҪҝз”Ёmemory_order_releaseжқҘиҝӣиЎҢatomic storeпјҢиҖҢеңЁеҸҰеӨ–дёҖдёӘзәҝзЁӢ2дёӯпјҢж“ҚдҪңBеҜ№еҗҢдёҖдёӘеҺҹеӯҗеҸҳйҮҸMдҪҝз”Ёmemory_order_acquireжқҘиҝӣиЎҢatomic loadпјҢйӮЈд№ҲзәҝзЁӢ1еңЁж“ҚдҪңAд№ӢеүҚзҡ„жүҖжңүеҶҷж“ҚдҪң(еҢ…жӢ¬ж“ҚдҪңA)пјҢйғҪдјҡеңЁзәҝзЁӢ2е®ҢжҲҗж“ҚдҪңBеҗҺжҳҜеҸҜи§Ғзҡ„гҖӮ
жҲ‘们зңӢдёӢйқўдёҖдёӘдҫӢеӯҗпјҡ
```
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello");//A
data = 42;//B
ptr.store(p, std::memory_order_release);//C
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))//D
;
assert(*p2 == "Hello"); //E
assert(data == 42); //F
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
```
йҰ–е…ҲпјҢжҲ‘们еҸҜд»Ҙзӣҙи§Ӯең°еҫ—еҮәеҰӮдёӢе…ізі»пјҡA sequenced-before B sequenced-before CгҖҒC synchronizes-with DгҖҒD sequenced-before E sequenced-before FгҖӮеҲ©з”ЁеүҚиҝ°happens-beforeжҺЁеҜјеӣҫпјҢдёҚйҡҫеҫ—еҮәA happens-before EгҖҒB happens-before FпјҢеӣ жӯӨпјҢиҝҷйҮҢзҡ„EгҖҒFдёӨеӨ„зҡ„assertж°ёиҝңдёҚдјҡfailгҖӮ
6.3.3.2.4 ж•°жҚ®дҫқиө–ж¬ЎеәҸ memory_order_consume
memory_order_consumeжҳҜиҪ»йҮҸзә§зҡ„memory_order_acquireпјҢжҳҜ memory_order_acquire еҶ…еӯҳеәҸзҡ„зү№дҫӢ:е®ғе°ҶеҗҢжӯҘж•°жҚ®йҷҗе®ҡдёәе…·жңүзӣҙжҺҘдҫқиө–зҡ„ж•°жҚ®гҖӮиғҪеӨҹз”Ёmemory_order_consumeзҡ„еңәжҷҜдёӢе°ұдёҖе®ҡиғҪеӨҹдҪҝз”Ёmemory_order_acquireпјҢеј•е…Ҙmemory_order_consumeзҡ„зӣ®зҡ„жҳҜдёәдәҶеңЁдёҖдәӣе·ІзҹҘзҡ„PowerPCе’ҢARMзӯүweakly-ordered CPUsдёҠпјҢеҜ№дәҺеңЁеҜ№жңүж•°жҚ®дҫқиө–зҡ„ж•°жҚ®иҝӣиЎҢеҗҢжӯҘзҡ„ж—¶еҖҷдёҚиҰҒжҸ’е…ҘйўқеӨ–memory barrierпјҢеӣ дёәе®ғ们жң¬иә«е°ұиғҪдҝқиҜҒеңЁжңүж•°жҚ®дҫқиө–зҡ„жғ…еҶөдёӢжңәеҷЁжҢҮд»Өзҡ„еҶ…еӯҳйЎәеәҸпјҢе°‘дәҶйўқеӨ–зҡ„memory barrierеҜ№жҖ§иғҪжҸҗеҚҮиҝҳжҳҜжҜ”иҫғеӨ§зҡ„гҖӮ
memory_order_consumeжҸҸиҝ°зҡ„жҳҜdependency-ordered-beforeе…ізі»гҖӮжҲ‘们зңӢдёҠйқўзҡ„дҫӢеӯҗпјҢжҠҠDдёӯmemory_order_acquireж”№жҲҗmemory_order_consumeдјҡжҖҺж ·е‘ўпјҹ
иҝҷдёӘж—¶еҖҷпјҢз”ұдәҺp2е’Ңptrжңүж•°жҚ®дҫқиө–пјҢдёҠйқўдҫӢеӯҗеҹәжң¬зҡ„е…ізі»еҜ№жҳҜпјҡA sequenced-before B sequenced-before CгҖҒC dependency-ordered before DгҖҒD carries a dependency into EпјҢ E sequenced-before FгҖӮ
ж №жҚ®е…ізі»жҺЁеҜјпјҢз”ұC dependency-ordered before D && D carries a dependency into Eеҫ—еҲ°C dependency-ordered before EпјҢиҝӣдёҖжӯҘеҫ—еҲ°C Inter-thread happens-before EпјҢ继иҖҢA sequenced-before C && C Inter-thread happens-before Eеҫ—еҲ°A Inter-thread happens-before EпјҢдәҺжҳҜеҫ—еҲ°A Happens-before EпјҢEж°ёиҝңдёҚдјҡassert failгҖӮеҜ№дәҺFпјҢз”ұдәҺDгҖҒFй—ҙдёҚеӯҳеңЁ carries a dependencyе…ізі»пјҢйӮЈд№ҲFзҡ„assertжҳҜеҸҜиғҪfailзҡ„гҖӮ
йҖҡеёёжғ…еҶөдёӢпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮжәҗз Ғзҡ„е°Ҹи°ғж•ҙе®һзҺ°д»ҺRelease-Acquire orderingеҲ°Release-Consume orderingзҡ„иҪ¬жҚўпјҢдёӢйқўжҳҜдёҖдёӘ
дҫӢеӯҗпјҡ

7. жҖ»з»“
жң¬ж–ҮйҖҡиҝҮдёҖдёӘж— й”ҒйҳҹеҲ—дёәеј•еӯҗпјҢд»Ӣз»ҚдәҶж— й”Ғзј–зЁӢж¶үеҸҠзҡ„6дёӘжҠҖжңҜиҰҒзӮ№пјҢе…¶дёӯеҶ…еӯҳеұҸйҡңжҳҜжңҖдёәе…ій”®пјҢдҪҝз”Ёд»Җд№Ҳж ·зҡ„memory barrierпјҢд»Җд№Ҳж—¶еҖҷдҪҝз”Ёmemory barrierеҸҲжҳҜе…¶дёӯзҡ„йҮҚдёӯд№ӢйҮҚгҖӮmemory barrierдёҚе®№жҳ“зҗҶи§ЈпјҢиҰҒжғіжӯЈзЎ®й«ҳж•Ҳең°дҪҝз”Ёmemory barrierе°ұжӣҙйҡҫдәҶпјҢйҖҡеёёжғ…еҶөдёӢпјҢиғҪдёҚзӣҙжҺҘз”Ёmemory barrierеҺҹиҜӯе°ұдёҚз”ЁпјҢжңҖеҘҪдҪҝз”Ёй”Ғ(дә’ж–ҘйҮҸ)зӯүдә’ж–ҘеҺҹиҜӯиҝҷж ·зҡ„йҡҗеҗ«дәҶmemory barrierеҠҹиғҪзҡ„еҺҹиҜӯгҖӮй”ҒеңЁеңЁеҫҲй•ҝдёҖж®өж—¶й—ҙйғҪиў«иҜҜи§ЈдәҶпјҢи®Өдёәй”ҒжҳҜж…ўзҡ„пјҢз”ұдәҺй”Ғзҡ„еј•е…ҘпјҢз»ҷжҖ§иғҪеёҰжқҘе·ЁеӨ§зҡ„瓶йўҲжҳҜеҫҲеёёи§Ғзҡ„гҖӮдҪҶиҝҷ并дёҚж„Ҹе‘ізқҖжүҖжңүзҡ„й”ҒйғҪжҳҜзј“ж…ўзҡ„пјҢеҪ“жҲ‘们дҪҝз”ЁиҪ»йҮҸзә§й”Ғ并жҺ§еҲ¶еҘҪй”Ғз«һдәүзҡ„ж—¶еҖҷпјҢй”Ғдҫқ然жңүйқһеёёеҮәиүІзҡ„жҖ§иғҪиЎЁзҺ°пјҢй”ҒдёҚж…ўпјҢй”Ғз«һдәүж…ўгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ