жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңдёәд»Җд№ҲиҜҙе…ұдә«ж•°жҚ®еә“е·ІжҲҗиҝҮеҺ»ејҸдәҶвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңдёәд»Җд№ҲиҜҙе…ұдә«ж•°жҚ®еә“е·ІжҲҗиҝҮеҺ»ејҸдәҶвҖқеҗ§пјҒ
е…ұдә«ж•°жҚ®еә“иҢғејҸжҳҜдёҖз§Қеёёи§Ғзҡ„ејҖеҸ‘е·ҘдҪңжөҒзЁӢпјҢеҚіеӣўйҳҹдёӯзҡ„жүҖжңүејҖеҸ‘дәәе‘ҳйғҪе…ұдә«жҹҗдёҖдёӘж•°жҚ®еә“зҡ„и®ҝй—®жқғйҷҗпјҢйғҪдҪҝз”ЁиҜҘж•°жҚ®еә“жқҘж”ҜжҢҒеә”з”ЁзЁӢеәҸејҖеҸ‘гҖӮ
иҝҷдёҖе·ҘдҪңжөҒзЁӢеҫҲз®ҖеҚ•пјҢж— йңҖдёәжҜҸдёӘе·ҘзЁӢеёҲй…ҚзҪ®еҹәзЎҖжһ¶жһ„пјҢдҪҝе®үиЈ…жҲҗжң¬йҷҚиҮіжңҖдҪҺпјҢеӣ иҖҢдәә们ж„ҝж„ҸйҖүжӢ©е®ғгҖӮдҪҶз”ұдәҺе·ҘзЁӢеёҲеҒҡеҮәж”№еҸҳзҡ„еҗҢж—¶дёҚеҫ—дёҚжүҝжӢ…зқҖеҪұе“Қе…¶д»–дәәе·ҘдҪңзҡ„йЈҺйҷ©пјҢе®ғд№ҹдјҡз»ҷе·ҘзЁӢеёҲйҖ жҲҗз—ӣиӢҰе’Ң瓶йўҲгҖӮ
SpawnдҪҝжҲ‘们иғҪеӨҹиҪ»жқҫиҝӣиЎҢж•°жҚ®еә“й…ҚзҪ®пјҢ并дҪҝжҜҸдёӘе·ҘзЁӢеёҲйғҪжӢҘжңүиҮӘе·ұдё“з”Ёзҡ„ж•°жҚ®еә“зҺҜеўғпјҢиҖҢж— йңҖй…ҚзҪ®д»»дҪ•йўқеӨ–зҡ„еҹәзЎҖжһ¶жһ„гҖӮ
е…ұдә«ж•°жҚ®еә“
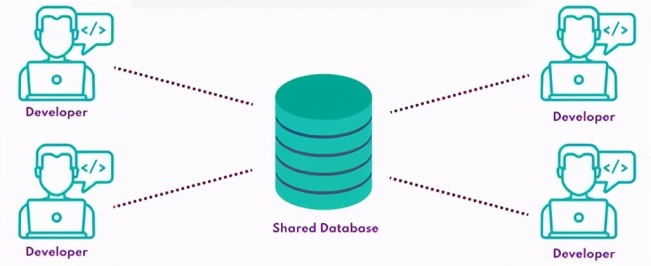
е…ұдә«ж•°жҚ®еә“йҖҡеёёеҢ…еҗ«дёҖдёӘз”ҹдә§ж•°жҚ®еә“зҡ„еүҜжң¬(йҖӮеҪ“ең°иў«еұҸи”Ҫд»ҘеҲ йҷӨж•Ҹж„ҹж•°жҚ®пјҢ并且еҸҜиғҪиў«еӯҗйӣҶеҢ–д»Ҙзј©е°Ҹ其规模)пјҢиҜҘеүҜжң¬з”ұеӣўйҳҹдёӯзҡ„жүҖжңүејҖеҸ‘дәәе‘ҳе…ұдә«гҖӮе…ұдә«ж•°жҚ®еә“зҡ„еҘҪеӨ„жҳҜз®ЎзҗҶзҡ„еҹәзЎҖжһ¶жһ„жӣҙе°‘пјҢејҖеҸ‘дәәе‘ҳеҸӘйңҖе°ҶиҝһжҺҘеӯ—з¬ҰдёІжҸ’е…Ҙе…ұдә«ж•°жҚ®еә“еҚіеҸҜеҝ«йҖҹеҗҜеҠЁе№¶иҝҗиЎҢгҖӮ
е°Ҫз®Ўиҝҷз§Қи®ҫзҪ®еҜ№дёҖдёӘеҫҲе°Ҹзҡ„еӣўйҳҹжҲ–еҫҲе°‘иҝӣиЎҢж•°жҚ®еә“жӣҙж”№зҡ„еӣўйҳҹйўҮжңүдҪңз”ЁпјҢдҪҶе®ғеҫҲеҝ«дјҡйҒҮеҲ°дёҖдәӣй—®йўҳпјҡ
дә’иё©пјҡејҖеҸ‘дәәе‘ҳеҸҜиғҪдјҡе°қиҜ•еҜ№е…ұдә«ж•°жҚ®еә“иҝӣиЎҢзҹӣзӣҫдә’ж–Ҙзҡ„жӣҙж”№пјҢеӯҳеңЁжҠ№еҺ»еҪјжӯӨе·ҘдҪңзҡ„йЈҺйҷ©гҖӮ
дёҚиғҪе®үе…Ёең°иҝҒ移еә”з”Ёпјҡжӣҙж”№дёҖйЎ№еҠҹиғҪзҡ„ж•°жҚ®еә“жһ¶жһ„еҸҜиғҪдјҡз ҙеқҸе…¶д»–д»Јз ҒгҖӮ
жңӘзҹҘзҠ¶жҖҒпјҡеҰӮжһңж•°жҚ®еә“зҡ„зҠ¶жҖҒдёҚеҸ—еҚ•дёӘејҖеҸ‘дәәе‘ҳзҡ„жҺ§еҲ¶пјҢд»ҺдёҖзһ¬й—ҙжӣҙж”№еҲ°дёӢдёҖзһ¬й—ҙпјҢй”ҷиҜҜеҶҚзҺ°е’Ңеә”з”ЁзЁӢеәҸжөӢиҜ•е°ҶеҸҳеҫ—жӣҙеҠ еӣ°йҡҫгҖӮ
е…ұдә«ж•°жҚ®еә“жЁЎејҸж—ҘзӣҠиҗҪеҗҺпјҢеӣ дёәе®№еҷЁеҢ–дҪҝеҫ—ж•°жҚ®еә“дҫӣеә”жҜ”д»ҘеҫҖд»»дҪ•ж—¶еҖҷйғҪжӣҙе®№жҳ“пјҢж¶ҲйҷӨдәҶеҹәзЎҖи®ҫж–Ҫдҫӣеә”зҡ„ејҖй”ҖгҖӮ
жҜҸдёӘејҖеҸ‘дәәе‘ҳдёҖдёӘж•°жҚ®еә“
еңЁиҝҷз§ҚжЁЎеһӢдёӢпјҢеӣўйҳҹдёӯзҡ„жҜҸдёӘејҖеҸ‘дәәе‘ҳйғҪжңүиҮӘе·ұзҡ„(йҡҗи—Ҹзҡ„)з”ҹдә§ж•°жҚ®еә“еүҜжң¬пјҢеҸҜд»Ҙж №жҚ®иҜҘеүҜжң¬иҝӣиЎҢе·ҘдҪңгҖӮиҝҷдҪҝејҖеҸ‘дәәе‘ҳеҸҜд»ҘеҚ•зӢ¬жӣҙж”№е…¶ж•°жҚ®еә“еүҜжң¬пјҢд»ҺиҖҢи§ЈеҶідәҶз”ұдәҺдәүз”Ёе…ұдә«ж•°жҚ®еә“иҖҢеј•иө·зҡ„й—®йўҳгҖӮ
иҝҷеңЁиҝҮеҺ»жҜ”иҫғеӣ°йҡҫпјҢеӣ дёәжҲ‘们еҝ…йЎ»дёәжҜҸдёӘејҖеҸ‘дәәе‘ҳжҸҗдҫӣзұ»дјјдәҺз”ҹдә§зҡ„еә”з”ЁзЁӢеәҸж•°жҚ®еә“зҡ„еүҜжң¬гҖӮдҪҶжҳҜпјҢйҖҡиҝҮдҪҝз”ЁSpawnпјҢжҲ‘们еҸҜд»Ҙд»Һе‘Ҫд»ӨиЎҢй…ҚзҪ®дёҙж—¶ж•°жҚ®еә“е®һдҫӢпјҢиҖҢж— йңҖи®ҫзҪ®жҲ–жүҳз®Ўд»»дҪ•е…¶д»–еҹәзЎҖжһ¶жһ„пјҡ
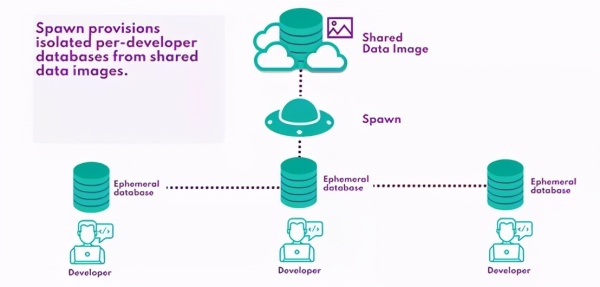
дҪҝз”ЁSpawnпјҢжҲ‘们еҸҜд»ҘжҜҸеӨ©д»Һз”ҹдә§зҺҜеўғдёӯеҲӣе»әдёҖдёӘж•°жҚ®жҳ еғҸ(дҪңдёәи®ЎеҲ’жһ„е»әз®ЎйҒ“зҡ„дёҖйғЁеҲҶ)пјҢ并дҪҝжӯӨжҳ еғҸеҜ№ејҖеҸ‘дәәе‘ҳе’ҢCIзі»з»ҹйғҪеҸҜз”Ё——жүҖжңүиҝҷдәӣйғҪдҪҝз”ЁSpawn CLIгҖӮеҸҜд»Ҙд»ҺеӨҮд»Ҫж–Ү件жҲ–и„ҡжң¬еҲӣе»әжҳ еғҸгҖӮ
然еҗҺпјҢжҜҸдёӘејҖеҸ‘дәәе‘ҳйғҪеҸҜд»ҘеҹәдәҺжӯӨжҳ еғҸй…ҚзҪ®иҮӘе·ұзҡ„ж•°жҚ®еә“пјҢиҖҢдёҚеҝ…еғҸиҝҗиЎҢspawnctl create data-container
SpawnеңЁе№•еҗҺKubernetesйӣҶзҫӨдёӯеҲӣе»ә并жүҳз®ЎдёҖдёӘе®№еҷЁеҢ–зҡ„ж•°жҚ®еә“е®һдҫӢпјҢе°ҶејҖеҸ‘еӣўйҳҹд»Һз®ЎзҗҶиҮӘе·ұзҡ„ж•°жҚ®еә“еҹәзЎҖи®ҫж–Ҫзҡ„иҙҹжӢ…дёӯи§Ји„ұеҮәжқҘпјҢ并иҺ·еҫ—дё“з”Ёж•°жҚ®еә“иҝӣиЎҢејҖеҸ‘зҡ„жүҖжңүеҘҪеӨ„пјҡ
еҝ«йҖҹжҸҗдҫӣд»»ж„Ҹ规模зҡ„ж•°жҚ®еә“пјҡSpawnдҪҝз”Ёеқ—зә§ж–Ү件系з»ҹеҝ«з…§жқҘжҒўеӨҚе’ҢеҶҷе…Ҙж•°жҚ®еә“гҖӮиҝҷж„Ҹе‘ізқҖеҚідҪҝжҳҜжңҖеӨ§зҡ„жҳ еғҸд№ҹеҸҜд»ҘеңЁеҮ з§’й’ҹеҶ…й…ҚзҪ®е®ҢжҜ•пјҢ并且дҝқжҢҒй«ҳйҖҹеҶҷе…ҘгҖӮ
еҝ«з…§е’ҢиҝҳеҺҹпјҡеҸҜд»ҘдҪҝз”ЁSpawn CLI spawnctl saveе‘Ҫд»ӨйҡҸж—¶еҜ№ж•°жҚ®еә“иҝӣиЎҢеҝ«з…§гҖӮдҪҝз”ЁspawnctlresetеҸҜжҒўеӨҚеҲ°д»ҘеүҚзҡ„д»»дҪ•зҠ¶жҖҒгҖӮж— йңҖжӢ…еҝғж•°жҚ®еә“жӣҙж”№пјҢеӣ дёәе®ғжҖ»жҳҜеҫҲе®№жҳ“иҝҳеҺҹгҖӮ
ж— йңҖеҹәзЎҖи®ҫж–ҪпјҡSpawnиҙҹиҙЈж•°жҚ®еә“зҡ„дҫӣеә”е’Ңжүҳз®ЎпјҢе…Ғи®ёејҖеҸ‘дәәе‘ҳдё“жіЁдәҺд»Јз ҒгҖӮ
еҗҢдёҖжҳ еғҸзҡ„еӨҡдёӘеүҜжң¬пјҡдёҖдёӘжҳ еғҸеҸҜз”ЁдәҺж №жҚ®йңҖиҰҒжҸҗдҫӣе°ҪеҸҜиғҪеӨҡзҡ„ж•°жҚ®еә“——жүҖжңүиҝҷдәӣж•°жҚ®еә“йғҪжңүиҮӘе·ұзҡ„иҝһжҺҘеӯ—з¬ҰдёІпјҢзӣёдә’зӢ¬з«Ӣе’ҢеҲҶзҰ»гҖӮ
еӨҡж•°жҚ®еә“ж”ҜжҢҒпјҡSpawnж”ҜжҢҒSQL ServerгҖҒPostgresгҖҒMySQLгҖҒRedisе’ҢMongoгҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңдёәд»Җд№ҲиҜҙе…ұдә«ж•°жҚ®еә“е·ІжҲҗиҝҮеҺ»ејҸдәҶвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№дёәд»Җд№ҲиҜҙе…ұдә«ж•°жҚ®еә“е·ІжҲҗиҝҮеҺ»ејҸдәҶиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ