您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“如何掌握Table与DataStream之间的互转”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
一、将kafka作为输入流
kafka 的连接器 flink-kafka-connector 中,1.10 版本的已经提供了 Table API 的支持。我们可以在 connect方法中直接传入一个叫做 Kafka 的类,这就是 kafka 连接器的描述器ConnectorDescriptor。
准备数据:
1,语数 2,英物 3,化生 4,文学 5,语理 6,学物
创建kafka主题
./kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --replication-factor 2 --partitions 3 --topic FlinkSqlTest
通过命令行的方式启动一个生产者
[root@node01 bin]# ./kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic FlinkSqlTest >1,语数 >2,英物 >3,化生 >4,文学 >5,语理\ >6,学物
编写Flink代码连接到kafka
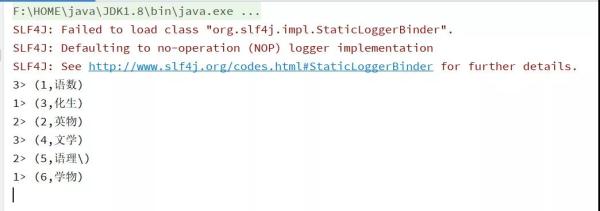
import org.apache.flink.streaming.api.scala._ import org.apache.flink.table.api.DataTypes import org.apache.flink.table.api.scala._ import org.apache.flink.table.descriptors.{Csv, Kafka, Schema} /** * @Package * @author 大数据老哥 * @date 2020/12/17 0:35 * @version V1.0 */ object FlinkSQLSourceKafka { def main(args: Array[String]): Unit = { // 获取流处理的运行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 获取table的运行环境 val tableEnv = StreamTableEnvironment.create(env) tableEnv.connect( new Kafka() .version("0.11") // 设置kafka的版本 .topic("FlinkSqlTest") // 设置要连接的主题 .property("zookeeper.connect","node01:2181,node02:2181,node03:2181") //设置zookeeper的连接地址跟端口号 .property("bootstrap.servers","node01:9092,node02:9092,node03:9092") //设置kafka的连接地址跟端口号 ).withFormat(new Csv()) // 设置格式 .withSchema(new Schema() // 设置元数据信息 .field("id",DataTypes.STRING()) .field("name",DataTypes.STRING()) ).createTemporaryTable("kafkaInputTable") // 创建临时表 //定义要查询的sql语句 val result = tableEnv.sqlQuery("select * from kafkaInputTable ") //打印数据 result.toAppendStream[(String,String)].print() // 开启执行 env.execute("source kafkaInputTable") } }运行结果图
当然也可以连接到 ElasticSearch、MySql、HBase、Hive 等外部系统,实现方式基本上是类似的。
二、表的查询
利用外部系统的连接器 connector,我们可以读写数据,并在环境的 Catalog 中注册表。接下来就可以对表做查询转换了。Flink 给我们提供了两种查询方式:Table API 和 SQL。
三、Table API 的调用
Table API 是集成在 Scala 和 Java 语言内的查询 API。与 SQL 不同,Table API 的查询不会用字符串表示,而是在宿主语言中一步一步调用完成的。 Table API 基于代表一张表的 Table 类,并提供一整套操作处理的方法 API。这些方法会返回一个新的 Table 对象,这个对象就表示对输入表应用转换操作的结果。有些关系型转换操作,可以由多个方法调用组成,构成链式调用结构。例如 table.select(…).filter(…) ,其中 select(…) 表示选择表中指定的字段,filter(…)表示筛选条件。代码中的实现如下:
val kafkaInputTable = tableEnv.from("kafkaInputTable") kafkaInputTable.select("*") .filter('id !=="1")四、SQL查询
Flink 的 SQL 集成,基于的是 ApacheCalcite,它实现了 SQL 标准。在 Flink 中,用常规字符串来定义 SQL 查询语句。SQL 查询的结果,是一个新的 Table。
代码实现如下:
val result = tableEnv.sqlQuery("select * from kafkaInputTable ")当然,也可以加上聚合操作,比如我们统计每个用户的个数
调用 table API
val result: Table = tableEnv.from("kafkaInputTable") result.groupBy("user") .select('name,'name.count as 'count)调用SQL
val result = tableEnv.sqlQuery("select name ,count(1) as count from kafkaInputTable group by name ")这里 Table API 里指定的字段,前面加了一个单引号’,这是 Table API 中定义的 Expression类型的写法,可以很方便地表示一个表中的字段。 字段可以直接全部用双引号引起来,也可以用半边单引号+字段名的方式。以后的代码中,一般都用后一种形式。
五、将DataStream 转成Table
Flink 允许我们把 Table 和DataStream 做转换:我们可以基于一个 DataStream,先流式地读取数据源,然后 map 成样例类,再把它转成 Table。Table 的列字段(column fields),就是样例类里的字段,这样就不用再麻烦地定义 schema 了。
5.1、代码实现
代码中实现非常简单,直接用 tableEnv.fromDataStream() 就可以了。默认转换后的 Table schema 和 DataStream 中的字段定义一一对应,也可以单独指定出来。
这就允许我们更换字段的顺序、重命名,或者只选取某些字段出来,相当于做了一次 map 操作(或者 Table API 的 select 操作)。
代码具体如下:
import org.apache.flink.streaming.api.scala._ import org.apache.flink.table.api.scala._ /** * @Package * @author 大数据老哥 * @date 2020/12/17 21:21 * @version V1.0 */ object FlinkSqlReadFileTable { def main(args: Array[String]): Unit = { // 构建流处理运行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 构建table运行环境 val tableEnv = StreamTableEnvironment.create(env) // 使用流处理来读取数据 val readData = env.readTextFile("./data/word.txt") // 使用flatMap进行切分 val word: DataStream[String] = readData.flatMap(_.split(" ")) // 将word 转为 table val table = tableEnv.fromDataStream(word) // 计算wordcount val wordCount = table.groupBy("f0").select('f0, 'f0.count as 'count) wordCount.printSchema() //转换成流处理打印输出 tableEnv.toRetractStream[(String,Long)](wordCount).print() env.execute("FlinkSqlReadFileTable") } }5.2 数据类型与 Table schema 的对应
DataStream 中的数据类型,与表的 Schema之间的对应关系,是按照样例类中的字段名来对应的(name-based mapping),所以还可以用 as 做重命名。
另外一种对应方式是,直接按照字段的位置来对应(position-based mapping),对应的过程中,就可以直接指定新的字段名了。
基于名称的对应:
val userTable = tableEnv.fromDataStream(dataStream,'username as 'name,'id as 'myid)
基于位置的对应:
val userTable = tableEnv.fromDataStream(dataStream, 'name, 'id)
Flink 的 DataStream 和 DataSet API 支持多种类型。组合类型,比如元组(内置 Scala 和 Java 元组)、POJO、Scala case 类和 Flink 的 Row 类型等,允许具有多个字段的嵌套数据结构,这些字段可以在 Table 的表达式中访问。其他类型,则被视为原子类型。
元组类型和原子类型,一般用位置对应会好一些;如果非要用名称对应,也是可以的:元组类型,默认的名称是_1, _2;而原子类型,默认名称是 f0。
六、创建临时视图(Temporary View)
创建临时视图的第一种方式,就是直接从 DataStream 转换而来。同样,可以直接对应字段转换;也可以在转换的时候,指定相应的字段。代码如下:
tableEnv.createTemporaryView("sensorView", dataStream) tableEnv.createTemporaryView("sensorView", dataStream, 'id, 'temperature,'timestamp as 'ts)另外,当然还可以基于 Table 创建视图:
tableEnv.createTemporaryView("sensorView", sensorTable)View 和 Table 的 Schema 完全相同。事实上,在 Table API 中,可以认为 View 和 Table是等价的。
“如何掌握Table与DataStream之间的互转”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。