жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңSparkMagicиғҪеҒҡд»Җд№ҲвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
йҖӮз”ЁдәҺJupyter NoteBookзҡ„SparkMagic
SparkmagicжҳҜдёҖдёӘйҖҡиҝҮLivy REST APIдёҺJupyter Notebookдёӯзҡ„иҝңзЁӢSparkзҫӨйӣҶиҝӣиЎҢдәӨдә’е·ҘдҪңзҡ„йЎ№зӣ®гҖӮе®ғжҸҗдҫӣдәҶдёҖз»„Jupyter NotebookеҚ•е…ғйӯ”жңҜе’ҢеҶ…ж ёпјҢеҸҜе°ҶJupyterеҸҳжҲҗз”ЁдәҺиҝңзЁӢйӣҶзҫӨзҡ„йӣҶжҲҗSparkзҺҜеўғгҖӮ
SparkMagicиғҪеӨҹпјҡ
д»ҘеӨҡз§ҚиҜӯиЁҖиҝҗиЎҢSparkд»Јз Ғ
жҸҗдҫӣеҸҜи§ҶеҢ–зҡ„SQLжҹҘиҜў
иҪ»жқҫи®ҝй—®Sparkеә”з”ЁзЁӢеәҸж—Ҙеҝ—е’ҢдҝЎжҒҜ
й’ҲеҜ№д»»дҪ•иҝңзЁӢSparkйӣҶзҫӨиҮӘеҠЁеҲӣе»әеёҰжңүSparkContextе’ҢHiveContextзҡ„SparkSession
е°ҶSparkжҹҘиҜўзҡ„иҫ“еҮәжҚ•иҺ·дёәжң¬ең°Pandasж•°жҚ®жЎҶжһ¶пјҢд»ҘиҪ»жқҫдёҺе…¶д»–Pythonеә“иҝӣиЎҢдәӨдә’(дҫӢеҰӮmatplotlib)
еҸ‘йҖҒжң¬ең°ж–Ү件жҲ–Pandasж•°жҚ®её§еҲ°иҝңзЁӢйӣҶзҫӨ(дҫӢеҰӮпјҢе°Ҷз»ҸиҝҮйў„и®ӯз»ғзҡ„жң¬ең°MLжЁЎеһӢзӣҙжҺҘеҸ‘йҖҒеҲ°SparkйӣҶзҫӨ)
еҸҜд»ҘдҪҝз”Ёд»ҘдёӢDockerfileжқҘжһ„е»әе…·жңүSparkMagicж”ҜжҢҒзҡ„Jupyter Notebookпјҡ
FROM jupyter/all-spark-notebook:7a0c7325e470USER$NB_USER RUN pip install --upgrade pip RUN pip install --upgrade --ignore-installed setuptools RUN pip install pandas --upgrade RUN pip install sparkmagic RUN mkdir /home/$NB_USER/.sparkmagic RUN wget https://raw.githubusercontent.com/jupyter-incubator/sparkmagic/master/sparkmagic/example_config.json RUN mv example_config.json /home/$NB_USER/.sparkmagic/config.json RUN sed -i 's/localhost:8998/host.docker.internal:9999/g'/home/$NB_USER/.sparkmagic/config.json RUN jupyter nbextension enable --py --sys-prefix widgetsnbextension RUN jupyter-kernelspec install --user --name SparkMagic $(pip show sparkmagic |grep Location | cut -d" " -f2)/sparkmagic/kernels/sparkkernel RUN jupyter-kernelspec install --user --name PySparkMagic $(pip show sparkmagic| grep Location | cut -d" " -f2)/sparkmagic/kernels/pysparkkernel RUN jupyter serverextension enable --py sparkmagic USER root RUN chown $NB_USER /home/$NB_USER/.sparkmagic/config.json CMD ["start-notebook.sh","--NotebookApp.iopub_data_rate_limit=1000000000"] USER $NB_USER
з”ҹжҲҗеӣҫеғҸ并用д»ҘдёӢд»Јз Ғж Үи®°пјҡ
docker build -t sparkmagic
并еңЁSpark Magicж”ҜжҢҒдёӢеҗҜеҠЁжң¬ең°Jupyterе®№еҷЁпјҢд»Ҙе®үиЈ…еҪ“еүҚе·ҘдҪңзӣ®еҪ•пјҡ
docker run -ti --name\"${PWD##*/}-pyspark\" -p 8888:8888 --rm -m 4GB --mounttype=bind,source=\"${PWD}\",target=/home/jovyan/work sparkmagicдёәдәҶиғҪеӨҹиҝһжҺҘеҲ°иҝңзЁӢSparkйӣҶзҫӨдёҠзҡ„Livy REST APIпјҢеҝ…йЎ»еңЁжң¬ең°и®Ўз®—жңәдёҠдҪҝз”Ёsshз«ҜеҸЈиҪ¬еҸ‘гҖӮиҺ·еҸ–дҪ зҡ„иҝңзЁӢйӣҶзҫӨзҡ„IPең°еқҖ并иҝҗиЎҢпјҡ
ssh -L 0.0.0.0:9999:localhost:8998REMOTE_CLUSTER_IP
йҰ–е…ҲпјҢдҪҝз”ЁеҗҜз”ЁдәҶSparkMagicзҡ„PySparkеҶ…ж ёеҲӣе»әдёҖдёӘж–°зҡ„NotebookпјҢеҰӮдёӢжүҖзӨәпјҡ

еңЁеҗҜз”ЁдәҶSparkMagicзҡ„NotebookдёӯпјҢдҪ еҸҜд»ҘдҪҝз”ЁдёҖзі»еҲ—еҚ•е…ғйӯ”жңҜжқҘеңЁжң¬ең°з¬”и®°жң¬з”өи„‘д»ҘеҸҠдҪңдёәйӣҶжҲҗзҺҜеўғзҡ„иҝңзЁӢSparkйӣҶзҫӨдёӯдҪҝз”ЁгҖӮ%% helpйӯ”жңҜиҫ“еҮәжүҖжңүеҸҜз”Ёзҡ„йӯ”жңҜе‘Ҫд»Өпјҡ

еҸҜд»ҘдҪҝз”Ё%%configuremagicй…ҚзҪ®иҝңзЁӢSparkеә”з”ЁзЁӢеәҸпјҡ

еҰӮеӣҫжүҖзӨәпјҢSparkMagicиҮӘеҠЁеҗҜеҠЁдәҶдёҖдёӘиҝңзЁӢPySparkдјҡиҜқпјҢ并жҸҗдҫӣдәҶдёҖдәӣжңүз”Ёзҡ„й“ҫжҺҘд»ҘиҝһжҺҘеҲ°Spark UIе’Ңж—Ҙеҝ—гҖӮ
NotebookйӣҶжҲҗдәҶ2з§ҚзҺҜеўғпјҡ
%%localпјҢеҸҜеңЁз¬”и®°жң¬з”өи„‘е’Ңjupyter dockerжҳ еғҸжҸҗдҫӣзҡ„anacondaзҺҜеўғдёӯжң¬ең°жү§иЎҢеҚ•е…ғ
%%sparkпјҢйҖҡиҝҮиҝңзЁӢSparkйӣҶзҫӨдёҠзҡ„PySpark REPLпјҢеҶҚйҖҡиҝҮLivy REST APIиҝңзЁӢжү§иЎҢеҚ•е…ғ
йҰ–е…Ҳе°Ҷд»ҘдёӢcode cellиҝңзЁӢеҜје…ҘSparkSqlж•°жҚ®зұ»еһӢ;е…¶ж¬ЎпјҢе®ғдҪҝз”ЁиҝңзЁӢSparkSessionе°ҶEnigma-JHU Covid-19ж•°жҚ®йӣҶеҠ иҪҪеҲ°жҲ‘们зҡ„иҝңзЁӢSparkйӣҶзҫӨдёӯгҖӮеҸҜд»ҘеңЁNotebookдёӯзңӢеҲ°remote .show()е‘Ҫд»Өзҡ„иҫ“еҮәпјҡ

дҪҶиҝҷе°ұжҳҜйӯ”жңҜејҖе§Ӣзҡ„ең°ж–№гҖӮеҸҜд»Ҙе°Ҷж•°жҚ®жЎҶжіЁеҶҢдёәHiveиЎЁпјҢ并дҪҝз”Ё%%sqlйӯ”жңҜеҜ№иҝңзЁӢзҫӨйӣҶдёҠзҡ„ж•°жҚ®жү§иЎҢHiveжҹҘиҜўпјҢ并еңЁжң¬ең°NotebookдёӯиҮӘеҠЁжҳҫзӨәз»“жһңгҖӮиҝҷдёҚжҳҜд»Җд№Ҳй«ҳйҡҫеәҰзҡ„дәӢпјҢдҪҶеҜ№дәҺж•°жҚ®еҲҶжһҗдәәе‘ҳе’Ңж•°жҚ®з§‘еӯҰйЎ№зӣ®ж—©жңҹзҡ„еҝ«йҖҹж•°жҚ®жҺўзҙўиҖҢиЁҖпјҢиҝҷйқһеёёж–№дҫҝгҖӮ

SparkMagicзңҹжӯЈжңүз”Ёд№ӢеӨ„еңЁдәҺе®һзҺ°жң¬ең°Notebookе’ҢиҝңзЁӢзҫӨйӣҶд№Ӣй—ҙж— зјқдј йҖ’ж•°жҚ®гҖӮж•°жҚ®з§‘еӯҰ家зҡ„ж—ҘеёёжҢ‘жҲҳжҳҜеңЁдёҺдёҙж—¶йӣҶзҫӨеҗҲдҪңд»ҘдёҺе…¶е…¬еҸёзҡ„ж•°жҚ®ж№–иҝӣиЎҢдәӨдә’зҡ„еҗҢж—¶пјҢеҲӣе»ә并дҝқжҢҒе…¶PythonзҺҜеўғгҖӮ
еңЁдёӢдҫӢдёӯпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°еҰӮдҪ•е°ҶseabornеҜје…Ҙдёәжң¬ең°еә“пјҢ并дҪҝз”Ёе®ғжқҘз»ҳеҲ¶covid_data pandasж•°жҚ®жЎҶгҖӮ
иҝҷдәӣж•°жҚ®д»ҺдҪ•иҖҢжқҘ?е®ғжҳҜз”ұиҝңзЁӢSparkйӣҶзҫӨеҲӣе»ә并еҸ‘йҖҒзҡ„гҖӮзҘһеҘҮзҡ„%%spark-oе…Ғи®ёжҲ‘们е®ҡд№үдёҖдёӘиҝңзЁӢеҸҳйҮҸпјҢд»ҘеңЁеҚ•е…ғжү§иЎҢж—¶иҪ¬з§»еҲ°жң¬ең°з¬”и®°жң¬дёҠдёӢж–ҮгҖӮжҲ‘们зҡ„еҸҳйҮҸcovid_dataжҳҜдёҖдёӘиҝңзЁӢйӣҶзҫӨдёҠзҡ„SparkSQL Data FrameпјҢе’ҢдёҖдёӘжң¬ең°JupyterNotebookдёӯзҡ„PandasDataFrameгҖӮ
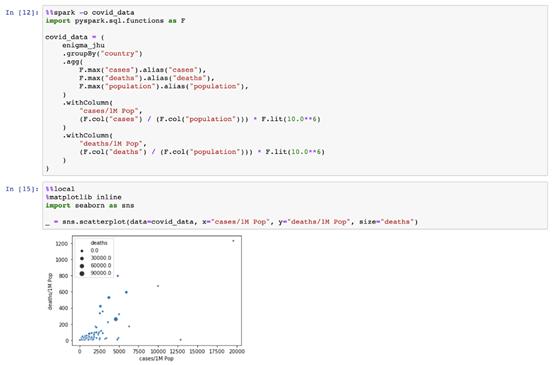
дҪҝз”ЁPandasеңЁJupyter NotebookдёӯиҒҡеҗҲиҝңзЁӢйӣҶзҫӨдёӯзҡ„еӨ§ж•°жҚ®д»ҘеңЁжң¬ең°е·ҘдҪңзҡ„иғҪеҠӣеҜ№дәҺж•°жҚ®жҺўзҙўйқһеёёжңүеё®еҠ©гҖӮдҫӢеҰӮпјҢдҪҝз”ЁSparkе°Ҷзӣҙж–№еӣҫзҡ„ж•°жҚ®йў„жұҮжҖ»дёәbinsпјҢд»ҘдҪҝз”Ёйў„жұҮжҖ»зҡ„и®Ўж•°е’Ңз®ҖеҚ•зҡ„жқЎеҪўеӣҫеңЁJupyterдёӯз»ҳеҲ¶зӣҙж–№еӣҫгҖӮ
еҸҰдёҖдёӘжңүз”Ёзҡ„еҠҹиғҪжҳҜиғҪеӨҹдҪҝз”Ёйӯ”жңҜ%%spark-o covid_data -m sample -r 0.5жқҘйҮҮж ·иҝңзЁӢSpark DataFrameгҖӮйӣҶжҲҗзҺҜеўғиҝҳе…Ғи®ёдҪ дҪҝз”ЁзҘһеҘҮзҡ„%%send_to_sparkе°Ҷжң¬ең°ж•°жҚ®еҸ‘йҖҒеҲ°иҝңзЁӢSparkйӣҶзҫӨгҖӮ
PandasDataFramesе’Ңеӯ—з¬ҰдёІж”ҜжҢҒзҡ„дёӨз§Қж•°жҚ®зұ»еһӢгҖӮиҰҒе°Ҷе…¶д»–жӣҙеӨҡжҲ–жӣҙеӨҚжқӮзҡ„дёңиҘҝ(дҫӢеҰӮпјҢз»ҸиҝҮи®ӯз»ғзҡ„scikitжЁЎеһӢз”ЁдәҺиҜ„еҲҶ)еҸ‘йҖҒеҲ°иҝңзЁӢSparkйӣҶзҫӨпјҢеҸҜд»ҘдҪҝз”ЁеәҸеҲ—еҢ–еҲӣе»әз”ЁдәҺдј иҫ“зҡ„еӯ—з¬ҰдёІиЎЁзӨәеҪўејҸпјҡ
import pickle import gzip import base64serialised_model = base64.b64encode( gzip.compress( pickle.dumps(trained_scikit_model) ) ).decode()
дҪҶжӯЈеҰӮдҪ жүҖи§ҒпјҢиҝҷз§ҚзҹӯжҡӮзҡ„PySparkйӣҶзҫӨжЁЎејҸжңүдёҖеӨ§иҜҹз—…пјҡдҪҝз”ЁPythonиҪҜ件еҢ…еј•еҜјEMRйӣҶзҫӨпјҢдё”иҝҷдёӘй—®йўҳдёҚдјҡйҡҸзқҖйғЁзҪІз”ҹдә§е·ҘдҪңиҙҹиҪҪиҖҢж¶ҲеӨұгҖӮ
вҖңSparkMagicиғҪеҒҡд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ