жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңMySQLдјҳеҢ–еҺҹзҗҶжҳҜд»Җд№ҲвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁMySQLдјҳеҢ–еҺҹзҗҶжҳҜд»Җд№Ҳй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқMySQLдјҳеҢ–еҺҹзҗҶжҳҜд»Җд№ҲвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
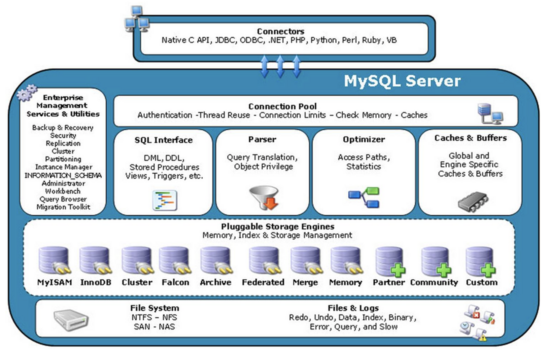
ServerеұӮдё»иҰҒ еҢ…еҗ«иҝһжҺҘеҷЁгҖҒжЈҖзҙўеҶ…еӯҳгҖҒеҲҶжһҗеҷЁгҖҒдјҳеҢ–еҷЁгҖҒжү§иЎҢеҷЁзӯүпјҢжүҖжңүи·ЁеӯҳеӮЁеј•ж“Һзҡ„еҠҹиғҪеқҮдәҺиҝҷдёҖеұӮжһ„е»әпјҢдҫӢеҰӮеӯҳеӮЁиҝҮзЁӢгҖҒи§ҰеҸ‘еҷЁгҖҒи§ҶеӣҫпјҢеҮҪж•°зӯүпјҢжңүдёҖдёӘж ҮеҮҶеҢ–зҡ„binglogж—Ҙеҝ—жЁЎеқ—гҖӮ
еӯҳеӮЁеј•ж“ҺиҙҹиҙЈж•°жҚ®зҡ„еӯҳеӮЁдёҺеӯҳеҸ–пјҢдҪҝз”ЁеҸҜжӣҙжҚўзҡ„жҸ’件ејҸжһ¶жһ„пјҢжӢҘжңүInnoDBгҖҒMyISAMгҖҒMemoryзӯүеӨҡдёӘеӯҳеӮЁеј•ж“ҺпјҢе…¶дёӯInnoDBеј•ж“Һжңүredo logж—Ҙеҝ—жЁЎеқ—гҖӮеҰӮдёӢеӣҫжүҖзӨә
е®һйӘҢзҺҜеўғ
ж“ҚдҪңзі»з»ҹеҶ…ж ёзүҲжң¬пјҡTencent tlinux release 2.2
MySQLж•°жҚ®еә“зүҲжң¬пјҡ5.7.10
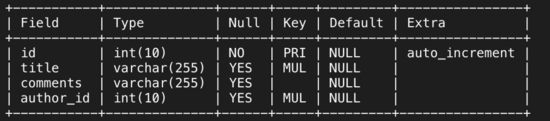
еҲӣе»әж–°иЎЁtb_articleпјҢеҲӣе»әдәҶдёӨдёӘзҙўеј•пјҡindex_titleгҖҒindex_author_idпјҢиЎЁз»“жһ„еҰӮдёӢпјҡ
жҲ‘们е°қиҜ•жҸ’е…ҘдёҖдәӣж•°жҚ®пјҡ
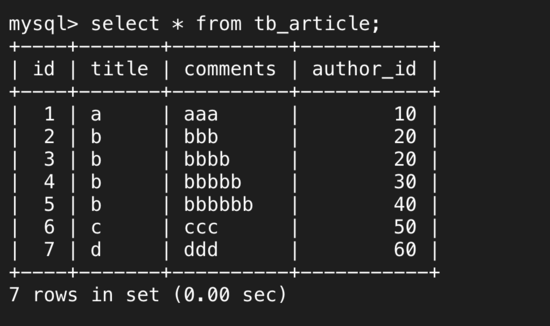
зҺ°жү§иЎҢSQLиҜӯеҸҘпјҢselect * from tb_article where author_id=20 and title='b'; еҲҶжһҗиҜҘSQLиҜӯеҸҘзҡ„жү§иЎҢиҝҮзЁӢе’ҢдјҳеҢ–зӯ–з•ҘгҖӮ
MySQLжү§иЎҢSQLиҜӯеҸҘиҝҮзЁӢ
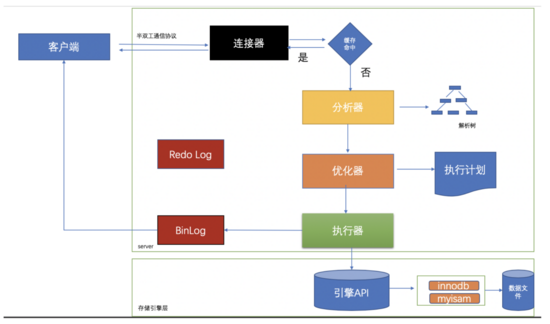
дёҖгҖҒMySQLе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁйҖҡи®Ҝ
е®ўжҲ·з«ҜжҢүз…§MySQLйҖҡдҝЎеҚҸи®®е°ҶSQLеҸ‘йҖҒеҲ°жңҚеҠЎз«ҜпјҢSQLеҲ°иҫҫжңҚеҠЎз«ҜеҗҺпјҢжңҚеҠЎз«ҜдјҡеҚ•иө·дёҖдёӘзәҝзЁӢжү§иЎҢSQLгҖӮMySQLе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁд№Ӣй—ҙзҡ„йҖҡи®ҜеҚҸи®®жҳҜвҖңеҚҠеҸҢе·ҘвҖқзҡ„гҖӮ
дәҢгҖҒжҹҘиҜўзҠ¶жҖҒ
еҜ№дәҺMySQLиҝһжҺҘпјҢд»»дҪ•ж—¶еҲ»йғҪжңүдёҖдёӘзҠ¶жҖҒпјҢиҜҘзҠ¶жҖҒиЎЁзӨәдәҶMySQLеҪ“еүҚжӯЈеңЁеҒҡд»Җд№ҲгҖӮдҪҝз”Ёshow full processlistе‘Ҫд»ӨжҹҘзңӢеҪ“еүҚзҠ¶жҖҒгҖӮеңЁдёҖдёӘжҹҘиҜўз”ҹе‘Ҫе‘ЁжңҹдёӯпјҢзҠ¶жҖҒдјҡеҸҳеҢ–еҫҲеӨҡж¬ЎпјҢдёӢйқўжҳҜиҝҷдәӣзҠ¶жҖҒзҡ„и§ЈйҮҠпјҡ
1. sleepпјҡ зәҝзЁӢжӯЈеңЁзӯүеҫ…е®ўжҲ·з«ҜеҸ‘йҖҒж–°зҡ„иҜ·жұӮпјӣ
2. queryпјҡ зәҝзЁӢжӯЈеңЁжү§иЎҢжҹҘиҜўжҲ–иҖ…жӯЈеңЁе°Ҷз»“жһңеҸ‘йҖҒз»ҷе®ўжҲ·з«Ҝпјӣ
3. lockedпјҡ еңЁMySQLжңҚеҠЎеҷЁеұӮпјҢиҜҘзәҝзЁӢжӯЈеңЁзӯүеҫ…иЎЁй”ҒгҖӮ еңЁеӯҳеӮЁеј•ж“Һзә§еҲ«е®һзҺ°зҡ„й”ҒпјҢдҫӢеҰӮInnoDBзҡ„иЎҢй”ҒпјҢ并дёҚдјҡдҪ“зҺ°еңЁзәҝзЁӢзҠ¶жҖҒдёӯгҖӮ еҜ№дәҺMyISAMжқҘиҜҙиҝҷжҳҜдёҖдёӘжҜ”иҫғе…ёеһӢзҡ„зҠ¶жҖҒпјӣ
4. analyzing and statisticsпјҡ зәҝзЁӢжӯЈеңЁж”¶йӣҶеӯҳеӮЁеј•ж“Һзҡ„з»ҹи®ЎдҝЎжҒҜпјҢ并з”ҹжҲҗжҹҘиҜўзҡ„жү§иЎҢи®ЎеҲ’пјӣ
5. copying to tmp tableпјҡ зәҝзЁӢеңЁжү§иЎҢжҹҘиҜўпјҢ并且е°Ҷе…¶з»“жһңйӣҶеӨҚеҲ¶еҲ°дёҖдёӘдёҙж—¶иЎЁдёӯпјҢиҝҷз§ҚзҠ¶жҖҒдёҖиҲ¬иҰҒд№ҲжҳҜеҒҡgroup byж“ҚдҪңпјҢиҰҒд№ҲжҳҜж–Ү件жҺ’еәҸж“ҚдҪңпјҢжҲ–иҖ…unionж“ҚдҪңгҖӮ еҰӮжһңиҝҷдёӘзҠ¶жҖҒеҗҺйқўиҝҳжңүon diskж Үи®°пјҢйӮЈиЎЁзӨәMySQLжӯЈеңЁе°ҶдёҖдёӘеҶ…еӯҳдёҙж—¶иЎЁж”ҫеҲ°зЈҒзӣҳдёҠпјӣ
6. sorting resultпјҡ зәҝзЁӢжӯЈеңЁеҜ№з»“жһңйӣҶиҝӣиЎҢжҺ’еәҸпјӣ
7. sending dataпјҡ зәҝзЁӢеҸҜиғҪеңЁеӨҡдёӘзҠ¶жҖҒй—ҙдј йҖҒж•°жҚ®пјҢжҲ–иҖ…еңЁз”ҹжҲҗз»“жһңйӣҶпјҢжҲ–иҖ…еңЁжғіе®ўжҲ·з«Ҝиҝ”еӣһж•°жҚ®гҖӮ
дёүгҖҒжҹҘиҜўзј“еӯҳ
MySQLзҡ„зј“еӯҳдё»иҰҒзҡ„дҪңз”ЁжҳҜдёәдәҶжҸҗеҚҮжҹҘиҜўзҡ„ж•ҲзҺҮпјҢзј“еӯҳд»Ҙkeyе’Ңvalueзҡ„е“ҲеёҢиЎЁеҪўејҸеӯҳеӮЁпјҢkeyжҳҜе…·дҪ“зҡ„sqlиҜӯеҸҘпјҢvalueжҳҜз»“жһңзҡ„йӣҶеҗҲгҖӮеҰӮжһңж— жі•е‘Ҫдёӯзј“еӯҳ,е°ұ继з»ӯиө°еҲ°еҲҶжһҗеҷЁзҡ„зҡ„дёҖжӯҘ,еҰӮжһңе‘Ҫдёӯзј“еӯҳе°ұзӣҙжҺҘиҝ”еӣһз»ҷе®ўжҲ·з«Ҝ гҖӮ
еҰӮжһңдҪҝз”ЁжҹҘиҜўзј“еӯҳпјҢеңЁиҝӣиЎҢиҜ»еҶҷж“ҚдҪңж—¶дјҡеёҰжқҘйўқеӨ–зҡ„иө„жәҗж¶ҲиҖ—пјҢеҰӮжһңеңЁдёҖдёӘеҶҷеӨҡиҜ»е°‘зҡ„зҺҜеўғдёӯпјҢзј“еӯҳдјҡйў‘з№Ғзҡ„ж–°еўһе’ҢеӨұж•ҲгҖӮMySQL8.0зүҲжң¬ејҖе§ӢеҸ–ж¶ҲжҹҘиҜўзј“еӯҳгҖӮ
еӣӣгҖҒжҹҘиҜўдјҳеҢ–еӨ„зҗҶ
жҹҘиҜўзҡ„з”ҹе‘Ҫе‘Ёжңҹзҡ„дёӢдёҖжӯҘжҳҜе°ҶдёҖдёӘSQLиҪ¬жҚўжҲҗдёҖдёӘжү§иЎҢи®ЎеҲ’пјҢMySQLеңЁдҫқз…§иҝҷдёӘжү§иЎҢи®ЎеҲ’е’ҢеӯҳеӮЁеј•ж“ҺиҝӣиЎҢдәӨдә’гҖӮиҝҷеҢ…еҗ«еӨҡдёӘеӯҗйҳ¶ж®өпјҡи§ЈжһҗSQLгҖҒйў„еӨ„зҗҶгҖҒдјҳеҢ–SQLжү§иЎҢи®ЎеҲ’гҖӮиҝҷдёӘиҝҮзЁӢдёӯд»»дҪ•й”ҷиҜҜйғҪеҸҜиғҪз»ҲжӯўжҹҘиҜўгҖӮ
1. иҜӯ жі•и§ЈжһҗеҷЁе’Ңйў„еӨ„зҗҶпјҡ йҰ–е…ҲMySQLйҖҡиҝҮе…ій”®еӯ—е°ҶSQLиҜӯеҸҘиҝӣиЎҢи§ЈжһҗпјҢ并з”ҹжҲҗдёҖйў—еҜ№еә”зҡ„вҖңи§Јжһҗж ‘вҖқгҖӮ MySQLи§ЈжһҗеҷЁе°ҶдҪҝз”ЁmysqlиҜӯ法规еҲҷйӘҢиҜҒе’Ңи§ЈжһҗжҹҘиҜўпјӣ йў„еӨ„зҗҶеҷЁеҲҷж №жҚ®дёҖдәӣMySQL规еҲҷиҝӣдёҖжӯҘжЈҖжҹҘи§Јжһҗж•°жҳҜеҗҰеҗҲжі•гҖӮ
2. жҹҘиҜўдјҳеҢ–еҷЁпјҡ еҪ“иҜӯжі•ж ‘иў«и®ӨдёәжҳҜеҗҲжі•зҡ„дәҶпјҢ并且з”ұдјҳеҢ–еҷЁе°Ҷе…¶иҪ¬еҢ–жҲҗжү§иЎҢи®ЎеҲ’гҖӮ дёҖжқЎжҹҘиҜўеҸҜд»ҘжңүеҫҲеӨҡз§Қжү§иЎҢж–№ејҸпјҢжңҖеҗҺйғҪиҝ”еӣһзӣёеҗҢзҡ„з»“жһңгҖӮ дјҳеҢ–еҷЁзҡ„дҪңз”Ёе°ұжҳҜжүҫеҲ°иҝҷе…¶дёӯжңҖеҘҪзҡ„жү§иЎҢи®ЎеҲ’гҖӮ
3. жү§иЎҢи®ЎеҲ’пјҡ MySQLдёҚдјҡз”ҹжҲҗжҹҘиҜўеӯ—иҠӮз ҒжқҘжү§иЎҢжҹҘиҜўпјҢMySQLз”ҹжҲҗжҹҘиҜўзҡ„дёҖжЈөжҢҮд»Өж ‘пјҢ然еҗҺйҖҡиҝҮеӯҳеӮЁеј•ж“Һжү§иЎҢе®ҢжҲҗиҝҷжЈөжҢҮд»Өж ‘е№¶иҝ”еӣһз»“жһңгҖӮ жңҖз»Ҳзҡ„жү§иЎҢи®ЎеҲ’еҢ…еҗ«дәҶйҮҚжһ„жҹҘиҜўзҡ„е…ЁйғЁдҝЎжҒҜгҖӮ
дә”гҖҒжҹҘиҜўжү§иЎҢеј•ж“Һ
еңЁи§Јжһҗе’ҢдјҳеҢ–йҳ¶ж®өпјҢMySQLе°Ҷз”ҹжҲҗжҹҘиҜўеҜ№еә”зҡ„жү§иЎҢи®ЎеҲ’пјҢMySQLж №жҚ®дјҳеҢ–еҷЁз”ҹжҲҗзҡ„жү§иЎҢи®ЎеҲ’пјҢи°ғз”ЁеӯҳеӮЁеј•ж“Һзҡ„APIжқҘжү§иЎҢжҹҘиҜўгҖӮ
е…ӯгҖҒиҝ”еӣһз»“жһңз»ҷе®ўжҲ·з«Ҝ
дәҶи§Јselect * from tb_article where author_id=20 and title='b';жҖ§иғҪе’ҢдјҳеҢ–зӯ–з•ҘпјҢдёҖиҲ¬йҮҮз”Ёexplainе‘Ҫд»ӨиҝӣиЎҢеҲҶжһҗгҖӮ
MySQL explain
MySQL Query OptimizerйҖҡиҝҮжү§иЎҢexplainе‘Ҫд»ӨжқҘиҺ·еҸ–дёҖдёӘQueryеңЁеҪ“еүҚзҠ¶жҖҒзҡ„ж•°жҚ®еә“дёӯзҡ„жү§иЎҢи®ЎеҲ’гҖӮexpainеҮәжқҘзҡ„дҝЎжҒҜжңү10еҲ—пјҢеҲҶеҲ«жҳҜidгҖҒselect_typeгҖҒtableгҖҒtypeгҖҒpossible_keysгҖҒkeyгҖҒkey_lenгҖҒrefгҖҒrowsгҖҒExtra
дёӢйқўеҜ№иҝҷдәӣеӯ—ж®өеҮәзҺ°зҡ„еҸҜиғҪиҝӣиЎҢи§ЈйҮҠпјҡ
1. id
idеҲ—зҡ„зј–еҸ·жҳҜ select зҡ„еәҸеҲ—еҸ·пјҢжңүеҮ дёӘ select е°ұжңүеҮ дёӘidпјҢ并且idзҡ„йЎәеәҸжҳҜжҢү select еҮәзҺ°зҡ„йЎәеәҸеўһй•ҝзҡ„гҖӮMySQLе°Ҷ select жҹҘиҜўеҲҶдёәз®ҖеҚ•жҹҘиҜўе’ҢеӨҚжқӮжҹҘиҜўгҖӮеӨҚжқӮжҹҘиҜўеҲҶдёәдёүзұ»пјҡз®ҖеҚ•еӯҗжҹҘиҜўгҖҒжҙҫз”ҹиЎЁпјҲfromиҜӯеҸҘдёӯзҡ„еӯҗжҹҘиҜўпјүгҖҒunion жҹҘиҜўгҖӮ
2.select_type
(1) SIMPLE(з®ҖеҚ•SELECT,дёҚдҪҝз”ЁUNIONжҲ–еӯҗжҹҘиҜўзӯү)пјӣ
(2) PRIMARY(жҹҘиҜўдёӯиӢҘеҢ…еҗ«д»»дҪ•еӨҚжқӮзҡ„еӯҗйғЁеҲҶ,жңҖеӨ–еұӮзҡ„selectиў«ж Үи®°дёәPRIMARY)пјӣ
(3) UNION(UNIONдёӯзҡ„第дәҢдёӘжҲ–еҗҺйқўзҡ„SELECTиҜӯеҸҘ)пјӣ
(4) DEPENDENT UNION(UNIONдёӯзҡ„第дәҢдёӘжҲ–еҗҺйқўзҡ„SELECTиҜӯеҸҘпјҢеҸ–еҶідәҺеӨ–йқўзҡ„жҹҘиҜў)пјӣ
(5) UNION RESULT(UNIONзҡ„з»“жһң)пјӣ
(6) SUBQUERY(еӯҗжҹҘиҜўдёӯзҡ„第дёҖдёӘSELECT)пјӣ
(7) DEPENDENT SUBQUERY(еӯҗжҹҘиҜўдёӯзҡ„第дёҖдёӘSELECTпјҢеҸ–еҶідәҺеӨ–йқўзҡ„жҹҘиҜў)пјӣ
(8) DERIVED(жҙҫз”ҹиЎЁзҡ„SELECT, FROMеӯҗеҸҘзҡ„еӯҗжҹҘиҜў)пјӣ
(9) UNCACHEABLE SUBQUERY(дёҖдёӘеӯҗжҹҘиҜўзҡ„з»“жһңдёҚиғҪиў«зј“еӯҳпјҢеҝ…йЎ»йҮҚж–°иҜ„дј°еӨ–й“ҫжҺҘзҡ„第дёҖиЎҢ)гҖӮ
3. table
иҝҷдёҖеҲ—иЎЁзӨә explain зҡ„дёҖиЎҢжӯЈеңЁи®ҝй—®е“ӘдёӘиЎЁгҖӮеҪ“ from еӯҗеҸҘдёӯжңүеӯҗжҹҘиҜўж—¶пјҢtableеҲ—жҳҜ <derivenN> ж јејҸпјҢиЎЁзӨәеҪ“еүҚжҹҘиҜўдҫқиө– id=N зҡ„жҹҘиҜўпјҢдәҺжҳҜе…Ҳжү§иЎҢ id=N зҡ„жҹҘиҜўгҖӮеҪ“жңүunionж—¶пјҢUNION RESULTзҡ„tableеҲ—зҡ„еҖјдёә <union1,2>пјҢ1е’Ң2иЎЁзӨәеҸӮдёҺ union зҡ„selectиЎҢidгҖӮ
4. type
иЎЁзӨәMySQLеңЁиЎЁдёӯжүҫеҲ°жүҖйңҖиЎҢзҡ„ж–№ејҸпјҢеҸҲз§°вҖңи®ҝй—®зұ»еһӢвҖқгҖӮ
еёёз”Ёзҡ„зұ»еһӢжңүпјҡALL, index, range, ref, eq_ref, const, system, NULLпјҲд»Һе·ҰеҲ°еҸіпјҢжҖ§иғҪд»Һе·®еҲ°еҘҪпјү
ALLпјҡFull Table ScanпјҢ MySQLе°ҶйҒҚеҺҶе…ЁиЎЁд»ҘжүҫеҲ°еҢ№й…Қзҡ„иЎҢ
index: Full Index ScanпјҢindexдёҺALLеҢәеҲ«дёәindexзұ»еһӢеҸӘйҒҚеҺҶзҙўеј•ж ‘
range:еҸӘжЈҖзҙўз»ҷе®ҡиҢғеӣҙзҡ„иЎҢпјҢдҪҝз”ЁдёҖдёӘзҙўеј•жқҘйҖүжӢ©иЎҢ
ref: иЎЁзӨәдёҠиҝ°иЎЁзҡ„иҝһжҺҘеҢ№й…ҚжқЎд»¶пјҢеҚіе“ӘдәӣеҲ—жҲ–еёёйҮҸиў«з”ЁдәҺжҹҘжүҫзҙўеј•еҲ—дёҠзҡ„еҖјгҖӮзӣёжҜ” eq_refпјҢдёҚдҪҝз”Ёе”ҜдёҖзҙўеј•пјҢиҖҢжҳҜдҪҝз”Ёжҷ®йҖҡзҙўеј•жҲ–иҖ…е”ҜдёҖжҖ§зҙўеј•зҡ„йғЁеҲҶеүҚзјҖпјҢзҙўеј•иҰҒе’ҢжҹҗдёӘеҖјзӣёжҜ”иҫғпјҢеҸҜиғҪдјҡжүҫеҲ°еӨҡдёӘз¬ҰеҗҲжқЎд»¶зҡ„иЎҢгҖӮ
eq_ref: зұ»дјјrefпјҢеҢәеҲ«е°ұеңЁдҪҝз”Ёзҡ„зҙўеј•жҳҜе”ҜдёҖзҙўеј•пјҢеҜ№дәҺжҜҸдёӘзҙўеј•й”®еҖјпјҢиЎЁдёӯеҸӘжңүдёҖжқЎи®°еҪ•еҢ№й…ҚпјҢз®ҖеҚ•жқҘиҜҙпјҢе°ұжҳҜеӨҡиЎЁиҝһжҺҘдёӯдҪҝз”Ёprimary keyжҲ–иҖ… unique keyдҪңдёәе…іиҒ”жқЎд»¶
constгҖҒsystem: еҪ“MySQLеҜ№жҹҘиҜўжҹҗйғЁеҲҶиҝӣиЎҢдјҳеҢ–пјҢ并иҪ¬жҚўдёәдёҖдёӘеёёйҮҸж—¶пјҢдҪҝз”Ёиҝҷдәӣзұ»еһӢи®ҝй—®гҖӮеҰӮе°Ҷдё»й”®зҪ®дәҺwhereеҲ—иЎЁдёӯпјҢMySQLе°ұиғҪе°ҶиҜҘжҹҘиҜўиҪ¬жҚўдёәдёҖдёӘеёёйҮҸ,systemжҳҜconstзұ»еһӢзҡ„зү№дҫӢпјҢеҪ“жҹҘиҜўзҡ„иЎЁеҸӘжңүдёҖиЎҢзҡ„жғ…еҶөдёӢпјҢдҪҝз”Ёsystem
NULL: MySQLеңЁдјҳеҢ–иҝҮзЁӢдёӯеҲҶи§ЈиҜӯеҸҘпјҢжү§иЎҢж—¶з”ҡиҮідёҚз”Ёи®ҝй—®иЎЁжҲ–зҙўеј•пјҢдҫӢеҰӮд»ҺдёҖдёӘзҙўеј•еҲ—йҮҢйҖүеҸ–жңҖе°ҸеҖјеҸҜд»ҘйҖҡиҝҮеҚ•зӢ¬зҙўеј•жҹҘжүҫе®ҢжҲҗгҖӮ
5. possible_keys
иҝҷдёҖеҲ—жҳҫзӨәжҹҘиҜўеҸҜиғҪдҪҝз”Ёе“Әдәӣзҙўеј•жқҘжҹҘжүҫгҖӮ
explain ж—¶еҸҜиғҪеҮәзҺ° possible_keys жңүеҲ—пјҢиҖҢ key жҳҫзӨә NULL зҡ„жғ…еҶөпјҢиҝҷз§Қжғ…еҶөжҳҜеӣ дёәиЎЁдёӯж•°жҚ®дёҚеӨҡпјҢMySQLи®Өдёәзҙўеј•еҜ№жӯӨжҹҘиҜўеё®еҠ©дёҚеӨ§пјҢйҖүжӢ©дәҶе…ЁиЎЁжҹҘиҜўгҖӮ
еҰӮжһңиҜҘеҲ—жҳҜNULLпјҢеҲҷжІЎжңүзӣёе…ізҡ„зҙўеј•гҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢеҸҜд»ҘйҖҡиҝҮжЈҖжҹҘ where еӯҗеҸҘзңӢжҳҜеҗҰеҸҜд»ҘеҲӣйҖ дёҖдёӘйҖӮеҪ“зҡ„зҙўеј•жқҘжҸҗй«ҳжҹҘиҜўжҖ§иғҪпјҢ然еҗҺз”Ё explain жҹҘзңӢж•ҲжһңгҖӮ
6. key
keyеҲ—жҳҫзӨәMySQLе®һйҷ…еҶіе®ҡдҪҝз”Ёзҡ„й”®пјҲзҙўеј•пјү
еҰӮжһңжІЎжңүйҖүжӢ©зҙўеј•пјҢй”®жҳҜNULLгҖӮиҰҒжғіејәеҲ¶MySQLдҪҝз”ЁжҲ–еҝҪи§Ҷpossible_keysеҲ—дёӯзҡ„зҙўеј•пјҢеңЁжҹҘиҜўдёӯдҪҝз”ЁFORCE INDEXгҖҒUSE INDEXжҲ–иҖ…IGNORE INDEXгҖӮ
7. key_len
иЎЁзӨәзҙўеј•дёӯдҪҝз”Ёзҡ„еӯ—иҠӮж•°пјҢеҸҜйҖҡиҝҮиҜҘеҲ—и®Ўз®—жҹҘиҜўдёӯдҪҝз”Ёзҡ„зҙўеј•зҡ„й•ҝеәҰпјҲkey_lenжҳҫзӨәзҡ„еҖјдёәзҙўеј•еӯ—ж®өзҡ„жңҖеӨ§еҸҜиғҪй•ҝеәҰпјҢ并йқһе®һйҷ…дҪҝз”Ёй•ҝеәҰпјҢеҚіkey_lenжҳҜж №жҚ®иЎЁе®ҡд№үи®Ўз®—иҖҢеҫ—пјҢдёҚжҳҜйҖҡиҝҮиЎЁеҶ…жЈҖзҙўеҮәзҡ„пјүгҖӮ
дёҚжҚҹеӨұзІҫзЎ®жҖ§зҡ„жғ…еҶөдёӢпјҢй•ҝеәҰи¶Ҡзҹӯи¶ҠеҘҪгҖӮ
8. ref
иЎЁзӨәдёҠиҝ°иЎЁзҡ„иҝһжҺҘеҢ№й…ҚжқЎд»¶пјҢеҚіе“ӘдәӣеҲ—жҲ–еёёйҮҸиў«з”ЁдәҺжҹҘжүҫзҙўеј•еҲ—дёҠзҡ„еҖјгҖӮ
9. rows
иЎЁзӨәMySQLж №жҚ®иЎЁз»ҹи®ЎдҝЎжҒҜеҸҠзҙўеј•йҖүз”Ёжғ…еҶөпјҢдј°з®—зҡ„жүҫеҲ°жүҖйңҖзҡ„и®°еҪ•жүҖйңҖиҰҒиҜ»еҸ–зҡ„иЎҢж•°пјҢиҝҷдёӘдёҚжҳҜз»“жһңйӣҶйҮҢзҡ„иЎҢж•°гҖӮ
10. Extra
иҜҘеҲ—еҢ…еҗ«MySQLи§ЈеҶіжҹҘиҜўзҡ„иҜҰз»ҶдҝЎжҒҜ,жңүд»ҘдёӢеҮ з§Қжғ…еҶөпјҡ
Using indexпјҡиҝҷеҸ‘з”ҹеңЁеҜ№иЎЁзҡ„иҜ·жұӮеҲ—йғҪжҳҜеҗҢдёҖзҙўеј•зҡ„йғЁеҲҶзҡ„ж—¶еҖҷпјҢиҝ”еӣһзҡ„еҲ—ж•°жҚ®еҸӘдҪҝз”ЁдәҶзҙўеј•дёӯзҡ„дҝЎжҒҜпјҢиҖҢжІЎжңүеҶҚеҺ»и®ҝй—®иЎЁдёӯзҡ„иЎҢи®°еҪ•пјҢжҳҜжҖ§иғҪй«ҳзҡ„иЎЁзҺ°гҖӮ
Using whereпјҡеҲ—ж•°жҚ®жҳҜд»Һд»…д»…дҪҝз”ЁдәҶзҙўеј•дёӯзҡ„дҝЎжҒҜиҖҢжІЎжңүиҜ»еҸ–е®һйҷ…зҡ„иЎҢеҠЁзҡ„иЎЁиҝ”еӣһзҡ„пјҢиҝҷеҸ‘з”ҹеңЁеҜ№иЎЁзҡ„е…ЁйғЁзҡ„иҜ·жұӮеҲ—йғҪжҳҜеҗҢдёҖдёӘзҙўеј•зҡ„йғЁеҲҶзҡ„ж—¶еҖҷпјҢиЎЁзӨәmysqlжңҚеҠЎеҷЁе°ҶеңЁеӯҳеӮЁеј•ж“ҺжЈҖзҙўиЎҢеҗҺеҶҚиҝӣиЎҢиҝҮж»ӨгҖӮ
Using temporaryпјҡиЎЁзӨәMySQLйңҖиҰҒдҪҝз”Ёдёҙж—¶иЎЁжқҘеӯҳеӮЁз»“жһңйӣҶпјҢеёёи§ҒдәҺжҺ’еәҸе’ҢеҲҶз»„жҹҘиҜўгҖӮ
Using filesortпјҡMySQLдёӯж— жі•еҲ©з”Ёзҙўеј•е®ҢжҲҗзҡ„жҺ’еәҸж“ҚдҪңз§°дёәвҖңж–Ү件жҺ’еәҸвҖқпјҢеҜ№з»“жһңдҪҝз”ЁдёҖдёӘеӨ–йғЁзҙўеј•жҺ’еәҸпјҢиҖҢдёҚжҳҜжҢүзҙўеј•ж¬ЎеәҸд»ҺиЎЁйҮҢиҜ»еҸ–иЎҢгҖӮжӯӨж—¶mysqlдјҡж №жҚ®иҒ”жҺҘзұ»еһӢжөҸи§ҲжүҖжңүз¬ҰеҗҲжқЎд»¶зҡ„и®°еҪ•пјҢ并дҝқеӯҳжҺ’еәҸе…ій”®еӯ—е’ҢиЎҢжҢҮй’ҲпјҢ然еҗҺжҺ’еәҸе…ій”®еӯ—并жҢүйЎәеәҸжЈҖзҙўиЎҢдҝЎжҒҜгҖӮиҝҷз§Қжғ…еҶөдёӢдёҖиҲ¬д№ҹжҳҜиҰҒиҖғиҷ‘дҪҝз”Ёзҙўеј•жқҘдјҳеҢ–зҡ„гҖӮ
Using join bufferпјҡж”№еҖјејәи°ғдәҶеңЁиҺ·еҸ–иҝһжҺҘжқЎд»¶ж—¶жІЎжңүдҪҝз”Ёзҙўеј•пјҢ并且йңҖиҰҒиҝһжҺҘзј“еҶІеҢәжқҘеӯҳеӮЁдёӯй—ҙз»“жһңгҖӮеҰӮжһңеҮәзҺ°дәҶиҝҷдёӘеҖјпјҢйӮЈеә”иҜҘжіЁж„ҸпјҢж №жҚ®жҹҘиҜўзҡ„е…·дҪ“жғ…еҶөеҸҜиғҪйңҖиҰҒж·»еҠ зҙўеј•жқҘж”№иҝӣиғҪгҖӮ
Impossible whereпјҡиҝҷдёӘеҖјејәи°ғдәҶwhereиҜӯеҸҘдјҡеҜјиҮҙжІЎжңүз¬ҰеҗҲжқЎд»¶зҡ„иЎҢгҖӮ
жү§иЎҢexplainиҜӯеҸҘ
explain select * from tb_article where author_id=20 and title='b';

еҸҜд»ҘеҸ‘зҺ°пјҢжү§иЎҢиҝҷжқЎSQLиҜӯеҸҘе®һйҷ…дёҠжІЎжңүиө°index_titleзҙўеј•пјҢиҖҢжҳҜйҖүжӢ©иө°index_author_idзҙўеј•гҖӮ
жү“ејҖoptimizer traceеҠҹиғҪпјҡ
SET optimizer_trace="enabled=on"; select * from information_schema.optimizer_trace\G;
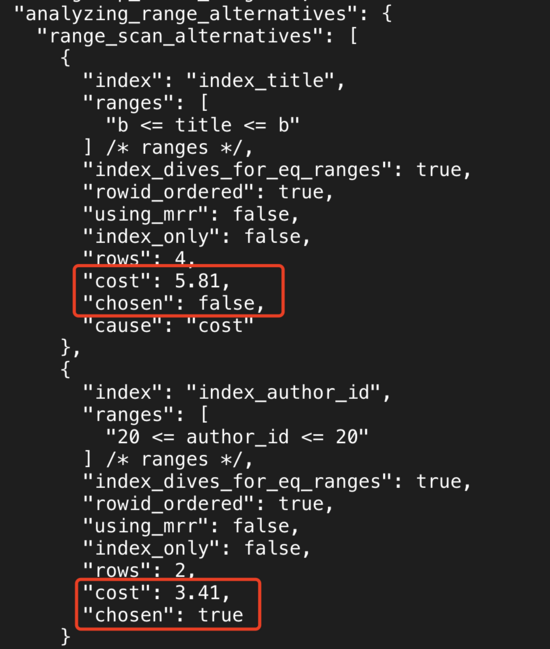
жү§иЎҢи®ЎеҲ’жңҖз»ҲйҖүжӢ©дәҶindex_author_idзҙўеј•пјҢеҺҹеӣ жҳҜindex_author_idзҡ„costе°ҸдәҺindex_titleгҖӮиҝҷйҮҢйңҖиҰҒд»Ӣз»ҚMySQLзҡ„д»Јд»·и®Ўз®—жЁЎеһӢгҖӮ
MySQLд»Јд»·жЁЎеһӢ
жҖ»д»Јд»·жЁЎеһӢпјҡCOST = CPU Cost + IO Cost
MySQLеңЁcostзұ»еһӢдёҠеҲҶдёәIOгҖҒCPUе’ҢMemoryпјҢMySQL5.7зҡ„д»Јд»·жЁЎеһӢиҝҳеңЁе®Ңе–„дёӯпјҢMemoryзҡ„д»Јд»·иҷҪ然已з»Ҹ收йӣҶдәҶпјҢдҪҶиҝҳжІЎжңүи®Ўз®—еңЁжңҖз»Ҳзҡ„д»Јд»·дёӯгҖӮ
MySQL5.7еңЁжәҗз ҒдёҠеҜ№costжЁЎеһӢиҝӣиЎҢдәҶеӨ§йҮҸйҮҚжһ„пјҢд»Јд»·еҲҶдёәserverеұӮе’ҢengineеұӮгҖӮserverеұӮдё»иҰҒжҳҜCPUд»Јд»·пјҢиҖҢengineеұӮдё»иҰҒжҳҜIOд»Јд»·гҖӮMySQL5.7 еј•е…ҘдәҶдёӨдёӘзі»з»ҹиЎЁmysql.server_costе’Ңmysql.engine_costжқҘеҲҶеҲ«й…ҚзҪ®иҝҷдёӨдёӘеұӮзҡ„д»Јд»·гҖӮ
д»ҘдёӢеҲҶжһҗеқҮеҹәдәҺMySQL5.7.10
server_cost
1. row_evaluate_cost (default 0.2) и®Ўз®—з¬ҰеҗҲжқЎд»¶зҡ„иЎҢзҡ„д»Јд»·пјҢиЎҢж•°и¶ҠеӨҡпјҢжӯӨйЎ№д»Јд»·и¶ҠеӨ§пјӣ
2. memory_temptable_create_cost (default 2.0) еҶ…еӯҳдёҙж—¶иЎЁзҡ„еҲӣе»әд»Јд»·пјӣ
3. memory_temptable_row_cost (default 0.2) еҶ…еӯҳдёҙж—¶иЎЁзҡ„иЎҢд»Јд»·пјӣ
4. key_compare_cost (default 0.1) й”®жҜ”иҫғзҡ„д»Јд»·пјҢдҫӢеҰӮжҺ’еәҸпјӣ
5. disk_temptable_create_cost (default 40.0) еҶ…йғЁmyisamжҲ–innodbдёҙж—¶иЎЁзҡ„еҲӣе»әд»Јд»·пјӣ
6. disk_temptable_row_cost (default 1.0) еҶ…йғЁmyisamжҲ–innodbдёҙж—¶иЎЁзҡ„иЎҢд»Јд»·пјӣ
еҸҜд»ҘзңӢеҮәеҲӣе»әдёҙж—¶иЎЁзҡ„д»Јд»·жҳҜеҫҲй«ҳзҡ„пјҢе°Өе…¶жҳҜеҶ…йғЁзҡ„myisamжҲ–innodbдёҙж—¶иЎЁгҖӮ
engine_cost
1. io_block_read_cost (default 1.0) д»ҺзЈҒзӣҳиҜ»ж•°жҚ®зҡ„costпјҢеҜ№innodbжқҘиҜҙпјҢиЎЁзӨәд»ҺзЈҒзӣҳиҜ»дёҖдёӘpageзҡ„costпјӣ
2. memory_block_read_cost (default 1.0пјүпјӣ
д»ҺеҶ…еӯҳиҜ»ж•°жҚ®зҡ„costпјҢеҜ№innodbжқҘиҜҙпјҢиЎЁзӨәд»Һbuffer poolиҜ»дёҖдёӘpageзҡ„costгҖӮ
зӣ®еүҚio_block_read_costе’Ңmemory_block_read_costй»ҳи®ӨеҖјеқҮдёә1пјҢе®һйҷ…з”ҹдә§дёӯе»әи®®й…Ңжғ…и°ғеӨ§memory_block_read_costпјҢзү№еҲ«жҳҜеҜ№жҷ®йҖҡзЎ¬зӣҳзҡ„еңәжҷҜгҖӮ
еҜ№иЎЁtb_articleеҲӣе»әеӨҚеҗҲзҙўеј•index_title_author
ALTER TABLE tb_article ADD KEY index_title_author(`title`,`author_id`); select * from tb_article where author_id=20 and title='b';
index_author_idе’Ңindex_title_authorзҡ„costзӣёзӯүпјҢMySQLдјҡдјҳе…ҲйҖүжӢ©еҸ¶еӯҗеқ—ж•°йҮҸиҫғе°‘зҡ„зҙўеј•гҖӮ
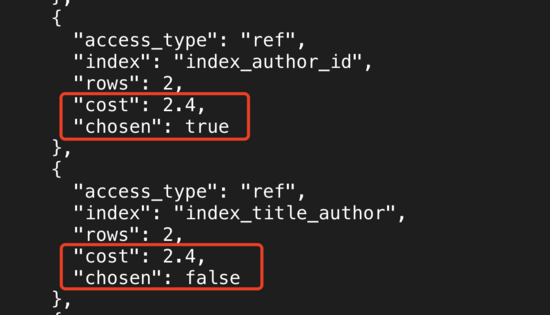
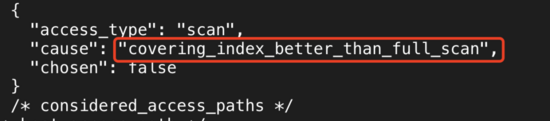
еҜ№дәҺSQLиҜӯеҸҘпјҡselect title, author_id from tb_article where author_id=20 and title='b';
MySQLдјҡдјҳе…ҲйҖүжӢ©иө°еӨҚеҗҲзҙўеј•index_title_authorпјҢеҺҹеӣ жҳҜindex_title_authorжҳҜзҙўеј•иҰҶзӣ–жү«жҸҸпјҢдёҚйңҖиҰҒеӣһиЎЁпјҢжҖ§иғҪиҫғй«ҳгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңMySQLдјҳеҢ–еҺҹзҗҶжҳҜд»Җд№ҲвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ