жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№ҲеңЁKaggleдёҠжү“жҜ”иөӣвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№ҲеңЁKaggleдёҠжү“жҜ”иөӣвҖқеҗ§пјҒ
KaggleжҳҜжңҖи‘—еҗҚзҡ„жңәеҷЁеӯҰд№ з«һиөӣзҪ‘з«ҷгҖӮKaggleз«һиөӣз”ұдёҖдёӘж•°жҚ®йӣҶз»„жҲҗпјҢиҜҘж•°жҚ®йӣҶеҸҜд»Ҙд»ҺзҪ‘з«ҷдёҠиҺ·еҫ—пјҢйңҖиҰҒдҪҝз”ЁжңәеҷЁгҖҒж·ұеәҰеӯҰд№ жҲ–е…¶д»–ж•°жҚ®з§‘еӯҰжҠҖжңҜжқҘи§ЈеҶій—®йўҳгҖӮдёҖж—ҰдҪ еҸ‘зҺ°дәҶдёҖдёӘи§ЈеҶіж–№жЎҲпјҢдҪ е°ұеҸҜд»ҘжҠҠдҪ зҡ„жЁЎеһӢз»“жһңдёҠдј еҲ°зҪ‘з«ҷдёҠпјҢ然еҗҺзҪ‘з«ҷж №жҚ®дҪ зҡ„з»“жһңеҜ№дҪ иҝӣиЎҢжҺ’еҗҚгҖӮеҰӮжһңдҪ зҡ„з»“жһңеҸҜд»ҘеҮ»иҙҘе…¶д»–еҸӮиөӣйҖүжүӢпјҢйӮЈд№ҲдҪ еҸҜиғҪиҺ·еҫ—зҺ°йҮ‘еҘ–еҠұгҖӮ

KaggleжҳҜдёҖдёӘзЈЁз»ғжӮЁзҡ„жңәеҷЁеӯҰд№ е’Ңж•°жҚ®з§‘еӯҰжҠҖиғҪзҡ„еҘҪең°ж–№пјҢжӮЁеҸҜд»Ҙе°ҶиҮӘе·ұдёҺд»–дәәиҝӣиЎҢжҜ”иҫғпјҢ并еӯҰд№ ж–°зҡ„жҠҖжңҜгҖӮ
KaggleжңҖж–°зҡ„дёҖйЎ№з«һиөӣжҸҗдҫӣдәҶдёҖдёӘж•°жҚ®йӣҶпјҢеҢ…еҗ«жҺЁж–Үд»ҘеҸҠдёҖдёӘе‘ҠиҜүжҲ‘们иҝҷдәӣжҺЁж–ҮжҳҜеҗҰзңҹзҡ„жҳҜе…ідәҺзҒҫйҡҫзҡ„ж ҮзӯҫгҖӮиҜҘжҜ”иөӣзҡ„жҺ’иЎҢжҰңдёҠжңүиҝ‘3000еҗҚеҸӮиөӣиҖ…пјҢжңҖй«ҳеҘ–йҮ‘дёә1дёҮзҫҺе…ғгҖӮ
еҰӮжһңдҪ иҝҳжІЎжңүKaggleиҙҰжҲ·пјҢдҪ еҸҜд»Ҙе…Ҳе…Қиҙ№еҲӣе»әдёҖдёӘгҖӮ
еҰӮжһңдҪ д»ҺжҜ”иөӣйЎөйқўйҖүжӢ©вҖңдёӢиҪҪе…ЁйғЁвҖқпјҢдҪ дјҡеҫ—еҲ°дёҖдёӘеҢ…еҗ«дёүдёӘCSVж–Ү件зҡ„zipж–Ү件пјҡ
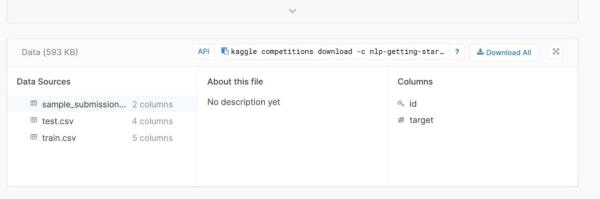
第дёҖдёӘж•°жҚ®ж–Ү件train.csvеҢ…еҗ«дёҖз»„зү№жҖ§еҸҠе…¶еҜ№еә”зҡ„з”ЁдәҺеҹ№и®ӯзӣ®зҡ„зҡ„зӣ®ж Үж ҮзӯҫгҖӮиҜҘж•°жҚ®йӣҶз”ұд»ҘдёӢеұһжҖ§з»„жҲҗ:
Id: tweetзҡ„ж•°еӯ—ж ҮиҜҶз¬ҰгҖӮеҪ“жҲ‘们е°ҶжҲ‘们зҡ„йў„жөӢдёҠдј еҲ°жҺ’иЎҢжҰңж—¶пјҢиҝҷе°ҶжҳҜйқһеёёйҮҚиҰҒзҡ„гҖӮ
е…ій”®еӯ—:жҺЁж–Үдёӯзҡ„дёҖдёӘе…ій”®еӯ—пјҢеҸҜиғҪеңЁжҹҗдәӣжғ…еҶөдёӢжІЎжңүгҖӮ
дҪҚзҪ®:еҸ‘йҖҒжҺЁж–Үзҡ„дҪҚзҪ®пјҢиҝҷд№ҹеҸҜиғҪдёҚеӯҳеңЁгҖӮ
ж–Үжң¬:жҺЁж–Үзҡ„е…Ёж–ҮгҖӮ
зӣ®ж Ү:иҝҷжҳҜжҲ‘们иҜ•еӣҫйў„жөӢзҡ„ж ҮзӯҫгҖӮеҰӮжһңиҝҷжқЎжҺЁж–Үзңҹзҡ„жҳҜе…ідәҺдёҖеңәзҒҫйҡҫпјҢе®ғе°ҶжҳҜ1пјҢеҰӮжһңдёҚжҳҜпјҢе®ғе°ҶжҳҜ0гҖӮ
и®©жҲ‘们并иҝӣдёҖжӯҘдәҶи§ЈиҝҷдёӘгҖӮеңЁдёӢйқўзҡ„д»Јз ҒдёӯпјҢжӮЁе°ҶжіЁж„ҸеҲ°жҲ‘дҪҝз”ЁдәҶдёҖдёӘset_option е‘Ҫд»ӨгҖӮиҝҷдёӘжқҘиҮӘPandasеә“зҡ„е‘Ҫд»Өе…Ғи®ёжӮЁжҺ§еҲ¶dataframeз»“жһңжҳҫзӨәзҡ„ж јејҸгҖӮжҲ‘еңЁиҝҷйҮҢдҪҝз”ЁиҝҷдёӘе‘Ҫд»ӨпјҢд»ҘзЎ®дҝқжҳҫзӨәж–Үжң¬еҲ—зҡ„е…ЁйғЁеҶ…е®№пјҢиҝҷдҪҝжҲ‘зҡ„з»“жһңе’ҢеҲҶжһҗжӣҙе®№жҳ“жҹҘзңӢ:
import pandas as pdpd.set_option('display.max_colwidth', -1)train_data = pd.read_csv('train.csv')train_data.head()
第дәҢдёӘж•°жҚ®ж–Ү件test.csvжҳҜжөӢиҜ•йӣҶпјҢеҸӘеҢ…еҗ«зү№еҫҒпјҢиҖҢжІЎжңүж ҮзӯҫгҖӮеҜ№дәҺиҝҷдёӘж•°жҚ®йӣҶпјҢжҲ‘们е°Ҷйў„жөӢзӣ®ж Үж Үзӯҫ并дҪҝз”Ёз»“жһңеңЁжҺ’иЎҢжҰңдёҠиҺ·еҫ—дёҖдёӘдҪҚзҪ®гҖӮ
test_data = pd.read_csv('test.csv')test_data.head()
第дёүдёӘж–Ү件sample_submissionжҳҜзӨәдҫӢпјҢеұ•зӨәдәҶжҸҗдәӨж–Ү件зҡ„еӨ–и§ӮгҖӮиҝҷдёӘж–Ү件е°ҶеҢ…еҗ«test.csvж–Ү件дёӯзҡ„idеҲ—е’ҢжҲ‘们用模еһӢйў„жөӢзҡ„зӣ®ж ҮгҖӮдёҖж—ҰжҲ‘们еҲӣе»әдәҶиҝҷдёӘж–Ү件пјҢжҲ‘们е°ҶжҸҗдәӨз»ҷзҪ‘з«ҷпјҢ并иҺ·еҫ—дёҖдёӘдҪҚзҪ®зҡ„жҺ’иЎҢжҰңгҖӮ
sample_submission = pd.read_csv('sample_submission.csv')sample_submission.head()
еҜ№дәҺд»»дҪ•жңәеҷЁеӯҰд№ д»»еҠЎпјҢеңЁжҲ‘们еҸҜд»Ҙи®ӯз»ғдёҖдёӘжЁЎеһӢд№ӢеүҚпјҢжҲ‘们еҝ…йЎ»жү§иЎҢдёҖдәӣж•°жҚ®жё…зҗҶе’Ңйў„еӨ„зҗҶгҖӮиҝҷеңЁеӨ„зҗҶж–Үжң¬ж•°жҚ®ж—¶е°ӨдёәйҮҚиҰҒгҖӮ
дёәдәҶз®ҖеҢ–жҲ‘们зҡ„第дёҖдёӘжЁЎеһӢпјҢ并且з”ұдәҺиҝҷдәӣеҲ—дёӯжңүи®ёеӨҡзјәеӨұзҡ„ж•°жҚ®пјҢжҲ‘们е°ҶеҲ йҷӨдҪҚзҪ®е’Ңе…ій”®еӯ—зү№жҖ§пјҢеҸӘдҪҝз”ЁжқҘиҮӘtweetзҡ„е®һйҷ…ж–Үжң¬иҝӣиЎҢи®ӯз»ғгҖӮжҲ‘们иҝҳе°ҶеҲ йҷӨidеҲ—пјҢеӣ дёәиҝҷеҜ№и®ӯз»ғжЁЎеһӢжІЎжңүз”ЁеӨ„гҖӮ
train_data = train_data.drop(['keyword', 'location', 'id'], axis=1)train_data.head()
жҲ‘们зҡ„ж•°жҚ®йӣҶеҸҳжҲҗиҝҷж ·пјҡ

ж–Үжң¬еёёеёёеҢ…еҗ«и®ёеӨҡзү№ж®Ҡеӯ—з¬ҰпјҢиҝҷдәӣеӯ—з¬ҰеҜ№дәҺжңәеҷЁеӯҰд№ з®—жі•жқҘиҜҙдёҚдёҖе®ҡжңүж„Ҹд№үгҖӮеӣ жӯӨпјҢжҲ‘иҰҒйҮҮеҸ–зҡ„第дёҖжӯҘжҳҜеҲ йҷӨиҝҷдәӣгҖӮжҲ‘д№ҹжҠҠжүҖжңүзҡ„еҚ•иҜҚйғҪе°ҸеҶҷдәҶгҖӮ
import redef clean_text(df, text_field): df[text_field] = df[text_field].str.lower() df[text_field] = df[text_field].apply(lambda elem: re.sub(r"(@[A-Za-z0-9]+)|([^0-9A- Za-z \t])|(\w+:\/\/\S+)|^rt|http.+?", "", elem)) return dfdata_clean = clean_text(train_data, "text")data_clean.head()

еҸҰдёҖдёӘжңүз”Ёзҡ„ж–Үжң¬жё…зҗҶиҝҮзЁӢжҳҜеҲ йҷӨеҒңжӯўеӯ—гҖӮеҒңжӯўиҜҚжҳҜйқһеёёеёёз”Ёзҡ„иҜҚпјҢйҖҡеёёдј иҫҫеҫҲе°‘зҡ„ж„ҸжҖқгҖӮеңЁиӢұиҜӯдёӯпјҢиҝҷдәӣиҜҚеҢ…жӢ¬вҖңtheвҖқгҖҒвҖңitвҖқе’ҢвҖңasвҖқгҖӮеҰӮжһңжҲ‘们жҠҠиҝҷдәӣеҚ•иҜҚз•ҷеңЁж–Үжң¬дёӯпјҢе®ғ们дјҡдә§з”ҹеҫҲеӨҡеҷӘйҹіпјҢиҝҷе°ҶдҪҝз®—жі•жӣҙйҡҫеӯҰд№ гҖӮ
NLTKжҳҜз”ЁдәҺеӨ„зҗҶж–Үжң¬ж•°жҚ®зҡ„pythonеә“е’Ңе·Ҙе…·зҡ„йӣҶеҗҲгҖӮйҷӨдәҶеӨ„зҗҶе·Ҙе…·д№ӢеӨ–пјҢNLTKиҝҳжӢҘжңүеӨ§йҮҸзҡ„ж–Үжң¬иҜӯж–ҷеә“е’ҢиҜҚжұҮиө„жәҗпјҢе…¶дёӯеҢ…жӢ¬еҗ„з§ҚиҜӯиЁҖдёӯзҡ„жүҖжңүеҒңжӯўиҜҚгҖӮжҲ‘们е°ҶдҪҝз”ЁиҝҷдёӘеә“д»Һж•°жҚ®йӣҶдёӯеҲ йҷӨеҒңжӯўеӯ—гҖӮ
еҸҜд»ҘйҖҡиҝҮpipе®үиЈ…NLTKеә“гҖӮе®үиЈ…д№ӢеҗҺпјҢйңҖиҰҒеҜје…Ҙеә“ж–ҮйӣҶпјҢ然еҗҺдёӢиҪҪstopwordsж–Ү件пјҡ
import nltk.corpusnltk.download('stopwords')дёҖж—ҰиҝҷдёҖжӯҘе®ҢжҲҗпјҢдҪ еҸҜд»Ҙйҳ…иҜ»еҒңжӯўиҜҚпјҢ并дҪҝз”Ёе®ғжқҘеҲ йҷӨ他们зҡ„жҺЁж–ҮгҖӮ
from nltk.corpus import stopwordsstop = stopwords.words('english')data_clean['text'] = data_clean['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))data_clean.head()
дёҖж—Ұжё…зҗҶеҘҪж•°жҚ®пјҢе°ұйңҖиҰҒиҝӣдёҖжӯҘзҡ„йў„еӨ„зҗҶпјҢдёәжңәеҷЁеӯҰд№ з®—жі•зҡ„дҪҝз”ЁеҒҡеҘҪеҮҶеӨҮгҖӮ
жүҖжңүзҡ„жңәеҷЁеӯҰд№ з®—жі•йғҪдҪҝз”Ёж•°еӯҰи®Ўз®—жқҘжҳ е°„зү№еҫҒ(еңЁжҲ‘们зҡ„дҫӢеӯҗдёӯжҳҜж–Үжң¬жҲ–еҚ•иҜҚ)е’Ңзӣ®ж ҮеҸҳйҮҸдёӯзҡ„жЁЎејҸгҖӮеӣ жӯӨпјҢеңЁеҜ№жңәеҷЁеӯҰд№ жЁЎеһӢиҝӣиЎҢи®ӯз»ғд№ӢеүҚпјҢеҝ…йЎ»е°Ҷж–Үжң¬иҪ¬жҚўдёәж•°еӯ—иЎЁзӨәпјҢд»ҘдҫҝиҝӣиЎҢиҝҷдәӣи®Ўз®—гҖӮ
иҝҷз§Қзұ»еһӢзҡ„йў„еӨ„зҗҶжңүеҫҲеӨҡж–№жі•пјҢдҪҶжҳҜеңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢжҲ‘е°ҶдҪҝз”ЁдёӨдёӘжқҘиҮӘscikit-learnеә“зҡ„ж–№жі•гҖӮ
иҝҷдёӘиҝҮзЁӢзҡ„第дёҖжӯҘжҳҜе°Ҷж•°жҚ®еҲҶеүІжҲҗж Үи®°жҲ–еҚ•дёӘеҚ•иҜҚпјҢи®Ўз®—жҜҸдёӘеҚ•иҜҚеңЁж–Үжң¬дёӯеҮәзҺ°зҡ„йў‘зҺҮпјҢ然еҗҺе°Ҷиҝҷдәӣи®Ўж•°иЎЁзӨәдёәдёҖдёӘзЁҖз–Ҹзҹ©йҳөгҖӮCountVectoriserеҮҪж•°еҸҜд»Ҙе®һзҺ°иҝҷдёҖзӮ№гҖӮ
дёӢдёҖжӯҘжҳҜеҜ№CountVectoriserз”ҹжҲҗзҡ„еӯ—ж•°иҝӣиЎҢеҠ жқғгҖӮеә”з”Ёиҝҷз§ҚеҠ жқғзҡ„зӣ®зҡ„жҳҜзј©е°Ҹж–Үжң¬дёӯеҮәзҺ°йў‘зҺҮйқһеёёй«ҳзҡ„еҚ•иҜҚзҡ„еҪұе“ҚпјҢд»ҘдҫҝеңЁжЁЎеһӢи®ӯз»ғдёӯи®ӨдёәеҮәзҺ°йў‘зҺҮиҫғдҪҺгҖҒеҸҜиғҪдҝЎжҒҜйҮҸиҫғеӨ§зҡ„еҚ•иҜҚеҫҲйҮҚиҰҒгҖӮTfidTransformerеҸҜд»Ҙжү§иЎҢиҝҷдёӘеҠҹиғҪгҖӮ
и®©жҲ‘们жҠҠжүҖжңүиҝҷдәӣйў„еӨ„зҗҶе’ҢжЁЎеһӢжӢҹеҗҲдёҖиө·ж”ҫеҲ°scikit-learnжөҒзЁӢдёӯпјҢзңӢзңӢжЁЎеһӢжҳҜеҰӮдҪ•жү§иЎҢзҡ„гҖӮеҜ№дәҺ第дёҖж¬Ўе°қиҜ•пјҢжҲ‘дҪҝз”ЁзәҝжҖ§ж”ҜжҢҒеҗ‘йҮҸжңәеҲҶзұ»еҷЁ(SGDClassifier)пјҢеӣ дёәиҝҷйҖҡеёёиў«и®ӨдёәжҳҜжңҖеҘҪзҡ„ж–Үжң¬еҲҶзұ»з®—жі•д№ӢдёҖгҖӮ
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(data_clean['text'],data_clean['target'],random_state = 0)from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.pipeline import Pipelinefrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfTransformerfrom sklearn.linear_model import SGDClassifierpipeline_sgd = Pipeline([ ('vect', CountVectorizer()), ('tfidf', TfidfTransformer()), ('nb', SGDClassifier()),])model = pipeline_sgd.fit(X_train, y_train)и®©жҲ‘们дҪҝз”ЁиҝҷдёӘи®ӯз»ғеҘҪзҡ„жЁЎеһӢжқҘйў„жөӢжҲ‘们зҡ„жөӢиҜ•ж•°жҚ®пјҢ并зңӢзңӢиҝҷдёӘжЁЎеһӢжҳҜеҰӮдҪ•жү§иЎҢзҡ„гҖӮ
from sklearn.metrics import classification_reporty_predict = model.predict(X_test)print(classification_report(y_test, y_predict))
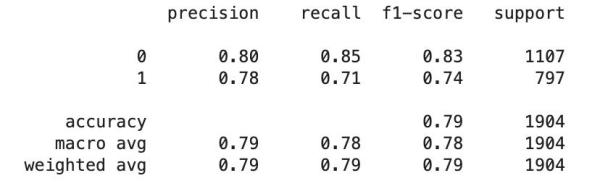
еҜ№дәҺ第дёҖж¬Ўе°қиҜ•пјҢжЁЎеһӢжү§иЎҢеҫ—зӣёеҪ“еҘҪгҖӮ
зҺ°еңЁи®©жҲ‘们зңӢзңӢиҝҷдёӘжЁЎеһӢеңЁз«һдәүжөӢиҜ•ж•°жҚ®йӣҶдёҠзҡ„иЎЁзҺ°пјҢд»ҘеҸҠжҲ‘们еңЁжҺ’иЎҢжҰңдёҠзҡ„жҺ’еҗҚгҖӮ
йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒжё…йҷӨжөӢиҜ•ж–Ү件дёӯзҡ„ж–Үжң¬пјҢ并дҪҝз”ЁжЁЎеһӢиҝӣиЎҢйў„жөӢгҖӮдёӢйқўзҡ„д»Јз ҒиҺ·еҸ–жөӢиҜ•ж•°жҚ®зҡ„еүҜжң¬пјҢ并жү§иЎҢжҲ‘们еә”з”ЁдәҺеҹ№и®ӯж•°жҚ®зҡ„зӣёеҗҢжё…зҗҶгҖӮиҫ“еҮәеҰӮдёӢйқўзҡ„д»Јз ҒжүҖзӨәгҖӮ
submission_test_clean = test_data.copy()submission_test_clean = clean_text(submission_test_clean, "text")submission_test_clean['text'] = submission_test_clean['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))submission_test_clean = submission_test_clean['text']submission_test_clean.head()

жҺҘдёӢжқҘпјҢжҲ‘们дҪҝз”ЁжЁЎеһӢеҲӣе»әйў„жөӢгҖӮ
submission_test_pred = model.predict(submission_test_clean)
дёәдәҶеҲӣе»әдёҖдёӘжҸҗдәӨпјҢжҲ‘们йңҖиҰҒжһ„йҖ дёҖдёӘdataframeпјҢе®ғеҸӘеҢ…еҗ«жқҘиҮӘжөӢиҜ•йӣҶзҡ„idе’ҢжҲ‘们зҡ„йў„жөӢгҖӮ
id_col = test_data['id']submission_df_1 = pd.DataFrame({ "id": id_col, "target": submission_test_pred})submission_df_1.head()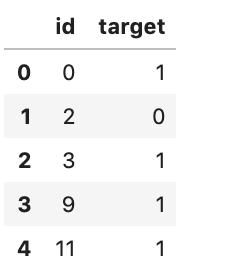
жңҖеҗҺпјҢжҲ‘们е°Ҷе…¶дҝқеӯҳдёәCSVж–Ү件гҖӮеҝ…йЎ»еҢ…еҗ«index=FalseпјҢеҗҰеҲҷзҙўеј•е°Ҷиў«дҝқеӯҳдёәж–Ү件дёӯзҡ„дёҖеҲ—пјҢжӮЁзҡ„жҸҗдәӨе°Ҷиў«жӢ’з»қгҖӮ
submission_df_1.to_csv('submission_1.csv', index=False)дёҖж—ҰжҲ‘们жңүдәҶCSVж–Ү件пјҢжҲ‘们е°ұеҸҜд»Ҙиҝ”еӣһжҜ”иөӣйЎөйқўе№¶йҖүжӢ©жҸҗдәӨйў„жөӢжҢүй’®гҖӮиҝҷе°Ҷжү“ејҖдёҖдёӘиЎЁеҚ•пјҢжӮЁеҸҜд»ҘдёҠдј CSVж–Ү件гҖӮж·»еҠ дёҖдәӣе…ідәҺиҜҘж–№жі•зҡ„жіЁйҮҠжҳҜдёҖдёӘеҘҪдё»ж„ҸпјҢиҝҷж ·жӮЁе°ұжңүдәҶд»ҘеүҚжҸҗдәӨе°қиҜ•зҡ„и®°еҪ•гҖӮ
жҸҗдәӨж–Ү件еҗҺпјҢжӮЁе°ҶзңӢеҲ°еҰӮдёӢз»“жһңпјҡ
зҺ°еңЁжҲ‘们жңүдёҖдёӘжҲҗеҠҹзҡ„жҸҗдәӨ!
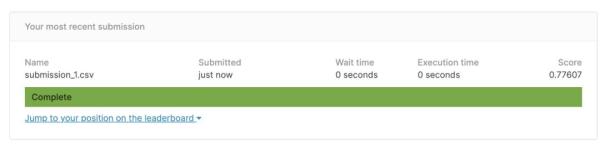
иҝҷдёӘжЁЎеһӢеңЁжҺ’иЎҢжҰңдёҠз»ҷдәҶжҲ‘0.78еҲҶпјҢжҺ’еҗҚ2371гҖӮжҳҫ然иҝҳжңүдёҖдәӣж”№иҝӣзҡ„з©әй—ҙпјҢдҪҶзҺ°еңЁжҲ‘е·Із»ҸжңүдәҶдёҖдёӘжңӘжқҘжҸҗдәӨзҡ„еҹәеҮҶгҖӮ

ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№ҲеңЁKaggleдёҠжү“жҜ”иөӣвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№ҲеңЁKaggleдёҠжү“жҜ”иөӣиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ