您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“怎么利用python3爬取漫画岛”,在日常操作中,相信很多人在怎么利用python3爬取漫画岛问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么利用python3爬取漫画岛”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
首先是我们想要爬取的漫画网页:http://www.manhuadao.cn/
网页截图:
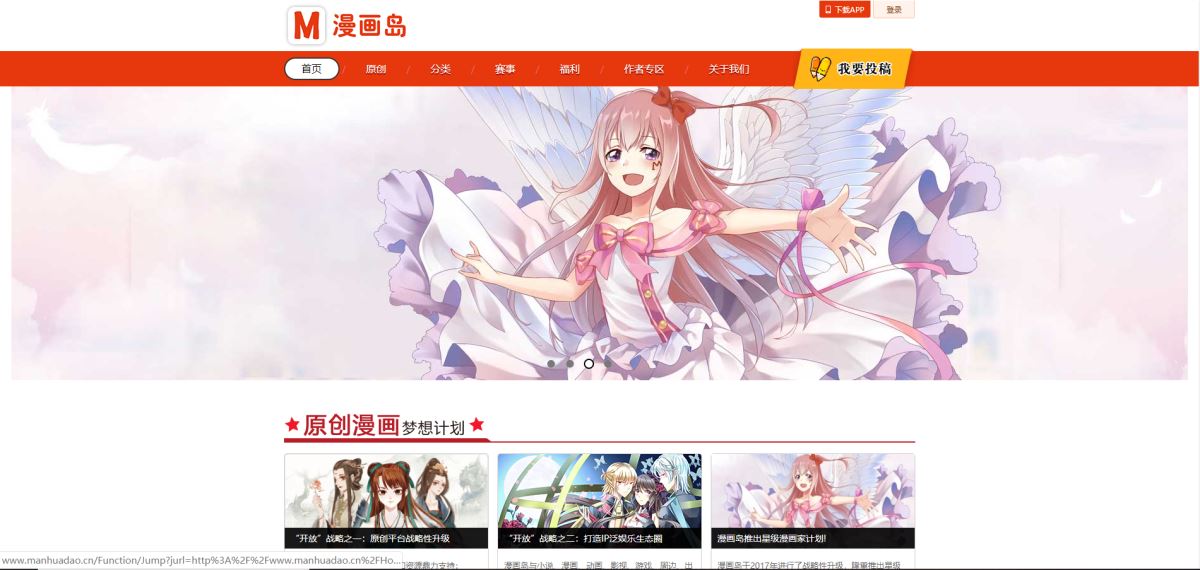
其次是爬取下来的效果:
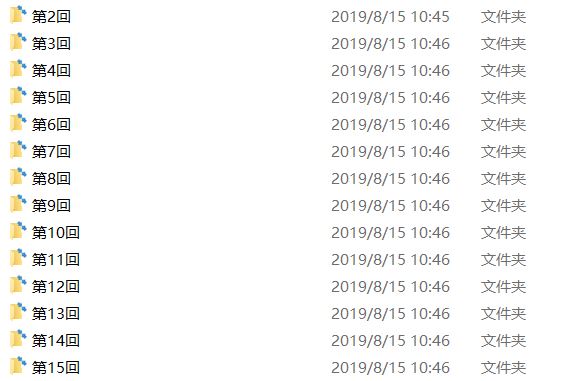
每一回的文件夹里面是这样的: (因为网站图片的问题...所以就成了这个鬼样子)

1、准备:需要vscode或者其他能够编译运行python的软件,推荐python版本3.X ,否则有可能出现编译问题。
下载所需模块:win+R进入命令行,输入pipinstall <模块名>即可下载。例如:
pip install beautifulsoup4
2、原理: 模拟浏览器点击->打开漫画网页链接->获取网页源码->定位每一章漫画的链接->模拟点击->获取图片页面源码->定位图片链接->下载图片
1、引入模块 (这里不再详述)
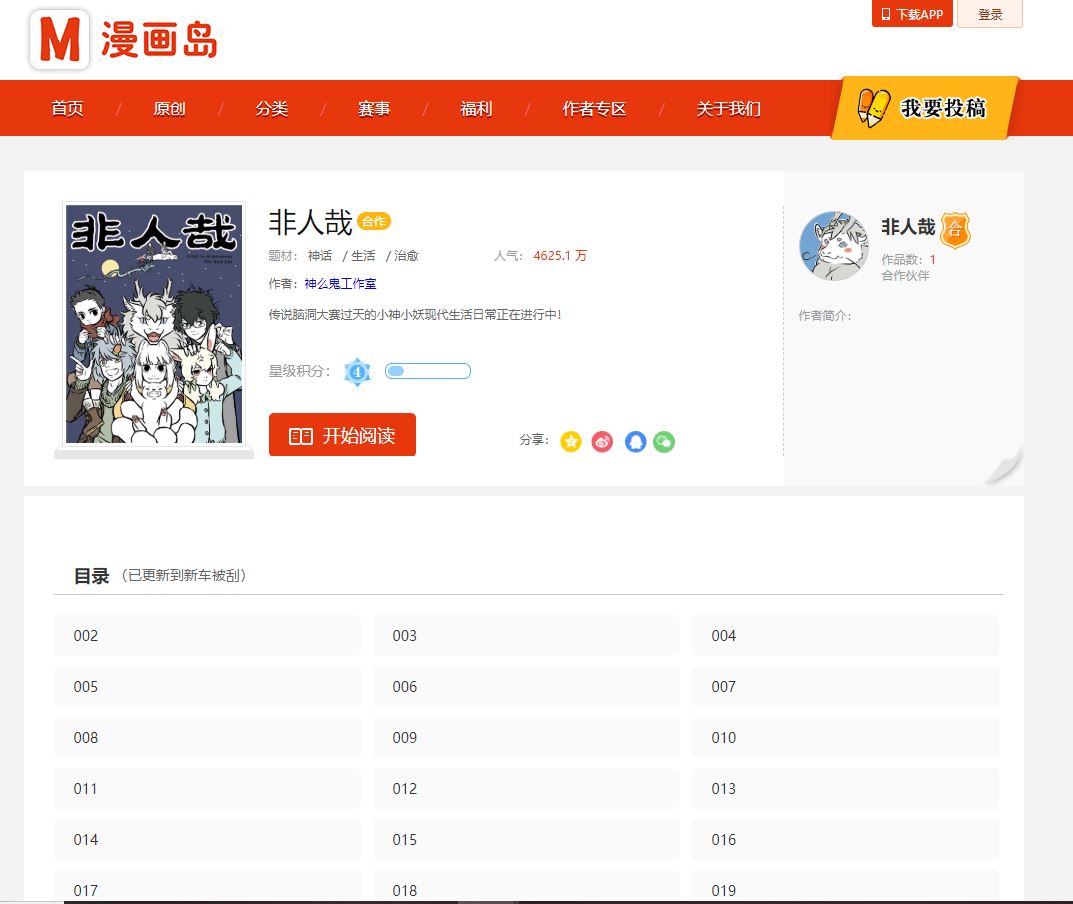
2、模拟浏览器访问网页

(1)、这里我们打开漫画的目录页,如下: url = ”http://www.manhuadao.cn/Home/ComicDetail?id=58ddb07827a7c1392c234628“ ,此链接就是目录页链接。
(2)、按F12打开此网页的源码(谷歌浏览器),选中上方NetWork,Ctrl+R刷新。
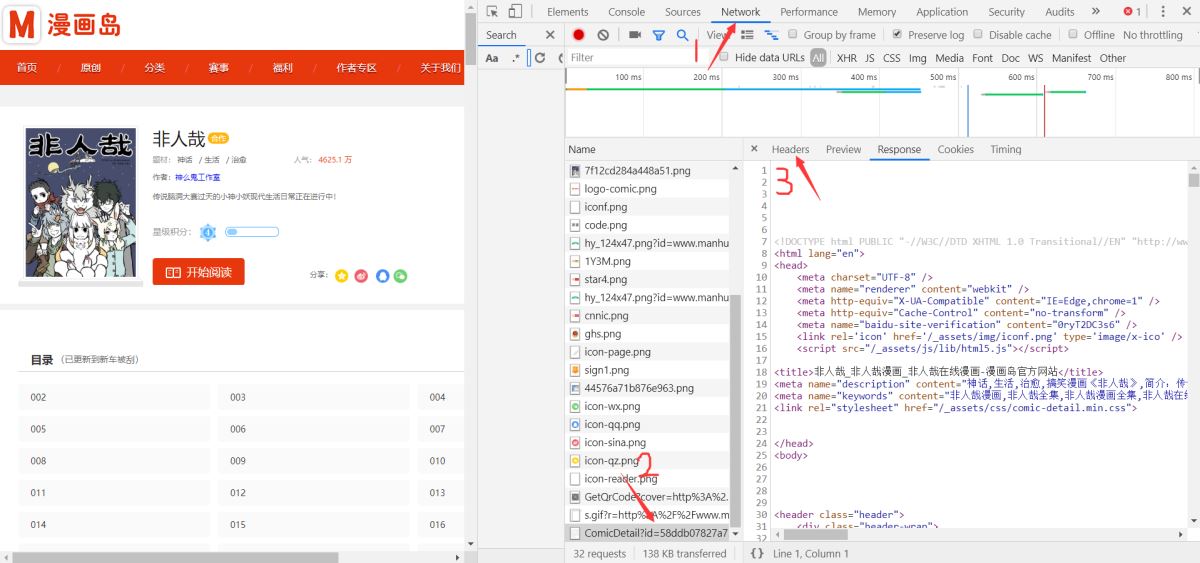
(3)、找到加载网页的源码文件,点击Headers,如下图: StatusCode表示网页返回的代码,值为200时表示访问成功。
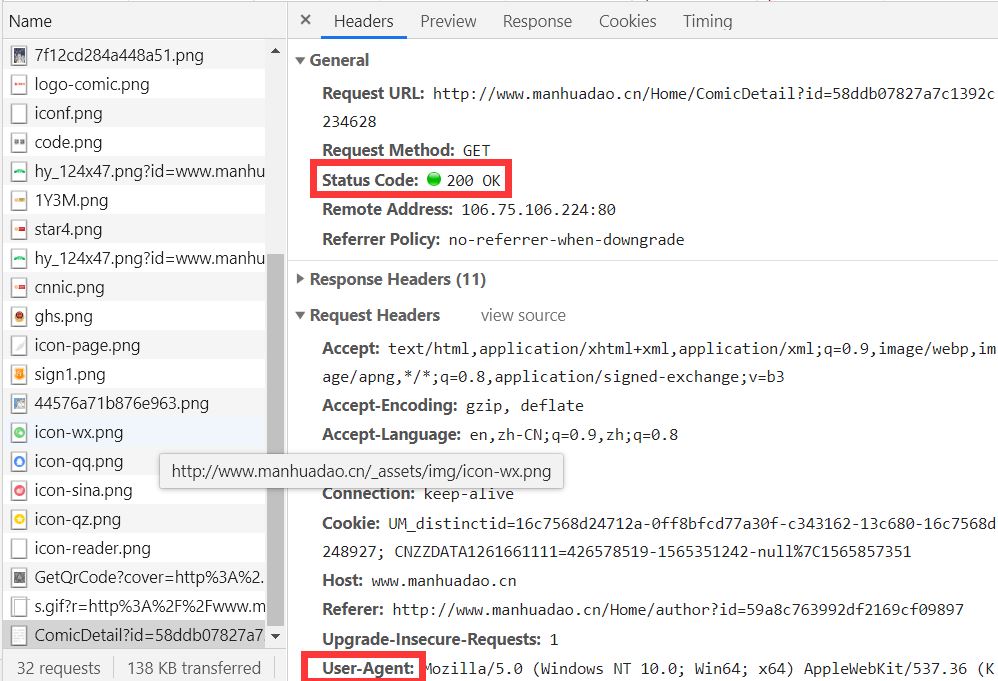
(4)、headers中的参数为下面红框User-Agent。
response = requests.get(url=url, headers=headers) # 模拟访问网页 print(response) # 此处应输出 <Response [200]> print(response.text) # 输出网页源码
两个输出分别输出:
 输出返回200表示访问成功。
输出返回200表示访问成功。
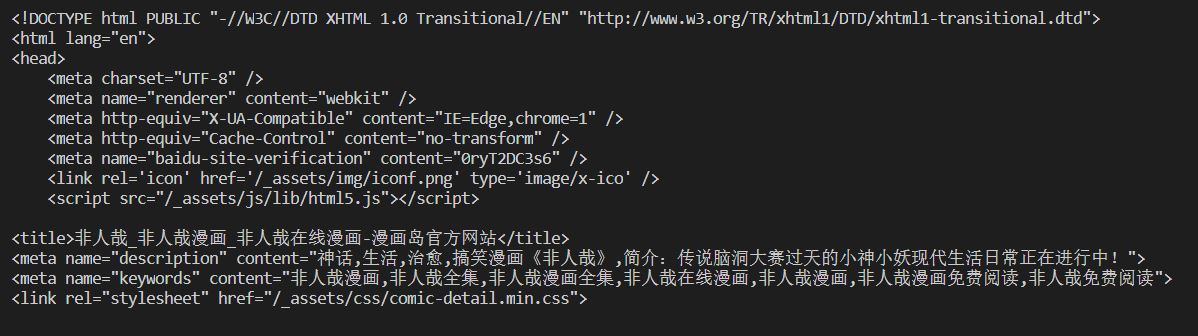 (节选)
(节选)
(5)、将html代码存入 data 中,xpath定位每一章链接。点击上方Element,点击:
将鼠标移至目录处:
右边代码区域出现每一章链接:

data = etree.HTML(response.text)
# tp = data.xpath("//ul[@class="read-chapter"]/li/a[@class="active"]/@href")
tp = data.xpath("//*[@class="yesReader"]/@href")
zhang_list = tp # tp为链接列表输出zhang_list,结果如下:

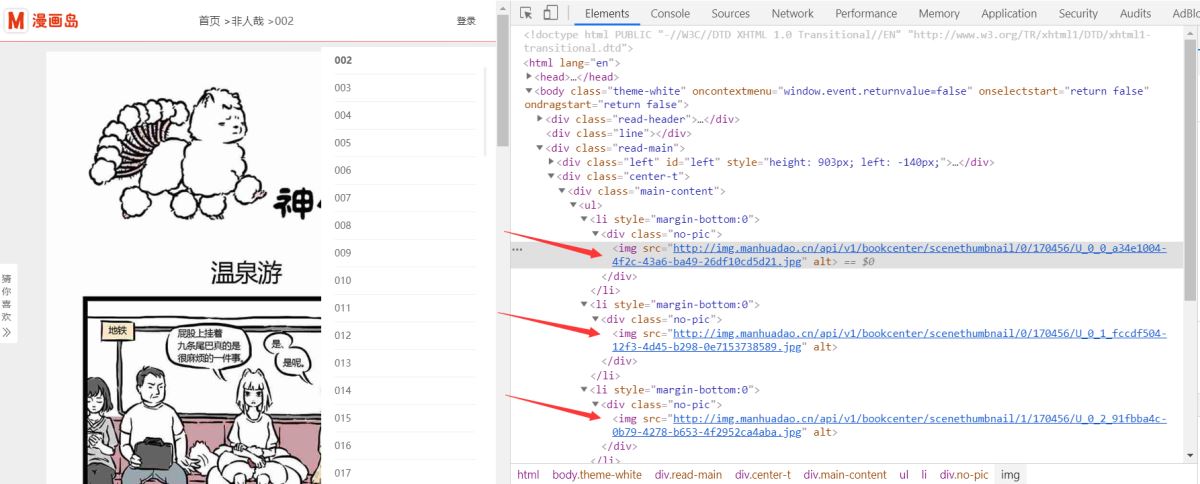
(6)、获取图片链接(获取方式同上一步)
点进第一章,同上一步,寻找到图片链接:
i=1
for next_zhang in zhang_list: # 在章节列表中循环
i=i+1
j=0
hui_url = r_url+next_zhang
name1 = "第"+str(i)+"回"
file = "C:/Users/wangyueke/Desktop/"+keyword+"/{}/".format(name1) # 创建文件夹
if not os.path.exists(file):
os.makedirs(file)
print("创建文件夹:", file)
response = requests.get(url=hui_url, headers=headers) # 模拟访问每一章链接
data = etree.HTML(response.text)
# tp = data.xpath("//div[@class="no-pic"]//img/@src")
tp = data.xpath("//div[@class="main-content"]//ul//li//div[@class="no-pic"]//img/@src") # 定位
ye_list = tp(7)、下载图片
for k in ye_list: # 在每一章的图片链接列表中循环 download_url = tp[j] print(download_url) j=j+1 file_name="第"+str(j)+"页" response = requests.get(url=download_url) # 模拟访问图片链接 with open(file+file_name+".jpg","wb") as f: f.write(response.content)
"""
用于爬取非人哉漫画
目标网址:http://www.manhuadao.cn/
开始时间:2019/8/14 20:01:26
完成时间:2019/8/15 11:04:56
作者:kong_gu
"""
import requests
import json
import time
import os
from lxml import etree
from bs4 import BeautifulSoup
def main():
keyword="非人哉"
file = "E:/{}".format(keyword)
if not os.path.exists(file):
os.mkdir(file)
print("创建文件夹:",file)
r_url="http://www.manhuadao.cn/"
url = "http://www.manhuadao.cn/Home/ComicDetail?id=58ddb07827a7c1392c234628"
headers = { # 模拟浏览器访问网页
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
response = requests.get(url=url, headers=headers)
# print(response.text) # 输出网页源码
data = etree.HTML(response.text)
# tp = data.xpath("//ul[@class="read-chapter"]/li/a[@class="active"]/@href")
tp = data.xpath("//*[@class="yesReader"]/@href")
zhang_list = tp
i=1
for next_zhang in zhang_list:
i=i+1
j=0
hui_url = r_url+next_zhang
name1 = "第"+str(i)+"回"
file = "C:/Users/wangyueke/Desktop/"+keyword+"/{}/".format(name1) # 这里需要自己设置路径
if not os.path.exists(file):
os.makedirs(file)
print("创建文件夹:", file)
response = requests.get(url=hui_url, headers=headers)
data = etree.HTML(response.text)
# tp = data.xpath("//div[@class="no-pic"]//img/@src")
tp = data.xpath("//div[@class="main-content"]//ul//li//div[@class="no-pic"]//img/@src")
ye_list = tp
for k in ye_list:
download_url = tp[j]
print(download_url)
j=j+1
file_name="第"+str(j)+"页"
response = requests.get(url=download_url)
with open(file+file_name+".jpg","wb") as f:
f.write(response.content)
if __name__ == "__main__":
main()到此,关于“怎么利用python3爬取漫画岛”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。