жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңSparkж ёеҝғжҰӮеҝөжҳҜд»Җд№ҲвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁSparkж ёеҝғжҰӮеҝөжҳҜд»Җд№Ҳй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқSparkж ёеҝғжҰӮеҝөжҳҜд»Җд№ҲвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
жҰӮиҝ°
д»Җд№ҲжҳҜSpark
в—Ҷ SparkжҳҜUC Berkeley AMP labжүҖејҖжәҗзҡ„зұ»Hadoop MapReduceзҡ„йҖҡз”Ёзҡ„并иЎҢи®Ўз®—жЎҶжһ¶пјҢSparkеҹәдәҺmap reduceз®—жі•е®һзҺ°зҡ„еҲҶеёғејҸи®Ўз®—пјҢжӢҘжңүHadoop MapReduceжүҖе…·жңүзҡ„дјҳзӮ№пјӣдҪҶдёҚеҗҢдәҺMapReduceзҡ„жҳҜJobдёӯй—ҙиҫ“еҮәе’Ңз»“жһңеҸҜд»ҘдҝқеӯҳеңЁеҶ…еӯҳдёӯпјҢд»ҺиҖҢдёҚеҶҚйңҖиҰҒиҜ»еҶҷHDFSпјҢеӣ жӯӨSparkиғҪжӣҙеҘҪең°йҖӮз”ЁдәҺж•°жҚ®жҢ–жҺҳдёҺжңәеҷЁеӯҰд№ зӯүйңҖиҰҒиҝӯд»Јзҡ„map reduceзҡ„з®—жі•гҖӮе…¶жһ¶жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡ
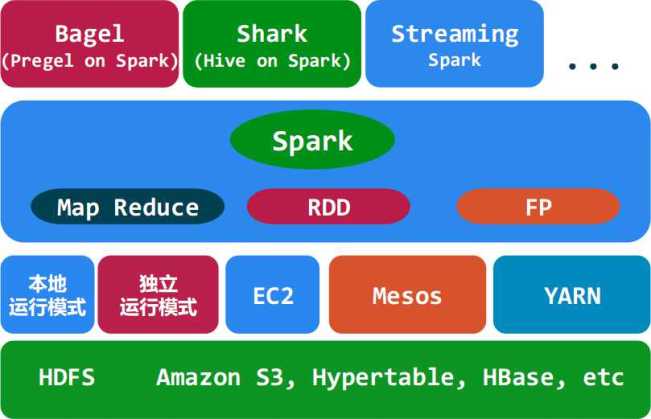
SparkдёҺHadoopзҡ„еҜ№жҜ”
в—Ҷ Sparkзҡ„дёӯй—ҙж•°жҚ®ж”ҫеҲ°еҶ…еӯҳдёӯпјҢеҜ№дәҺиҝӯд»Јиҝҗз®—ж•ҲзҺҮжӣҙй«ҳгҖӮ
SparkжӣҙйҖӮеҗҲдәҺиҝӯд»Јиҝҗз®—жҜ”иҫғеӨҡзҡ„MLе’ҢDMиҝҗз®—гҖӮеӣ дёәеңЁSparkйҮҢйқўпјҢжңүRDDзҡ„жҠҪиұЎжҰӮеҝөгҖӮ
в—Ҷ SparkжҜ”HadoopжӣҙйҖҡз”ЁгҖӮ
SparkжҸҗдҫӣзҡ„ж•°жҚ®йӣҶж“ҚдҪңзұ»еһӢжңүеҫҲеӨҡз§ҚпјҢдёҚеғҸHadoopеҸӘжҸҗдҫӣдәҶMapе’ҢReduceдёӨз§Қж“ҚдҪңгҖӮжҜ”еҰӮmap, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionByзӯүеӨҡз§Қж“ҚдҪңзұ»еһӢпјҢSparkжҠҠиҝҷдәӣж“ҚдҪңз§°дёәTransformationsгҖӮеҗҢж—¶иҝҳжҸҗдҫӣCount, collect, reduce, lookup, saveзӯүеӨҡз§Қactionsж“ҚдҪңгҖӮ
иҝҷдәӣеӨҡз§ҚеӨҡж ·зҡ„ж•°жҚ®йӣҶж“ҚдҪңзұ»еһӢпјҢз»ҷз»ҷејҖеҸ‘дёҠеұӮеә”з”Ёзҡ„з”ЁжҲ·жҸҗдҫӣдәҶж–№дҫҝгҖӮеҗ„дёӘеӨ„зҗҶиҠӮзӮ№д№Ӣй—ҙзҡ„йҖҡдҝЎжЁЎеһӢдёҚеҶҚеғҸHadoopйӮЈж ·е°ұжҳҜе”ҜдёҖзҡ„Data ShuffleдёҖз§ҚжЁЎејҸгҖӮз”ЁжҲ·еҸҜд»Ҙе‘ҪеҗҚпјҢзү©еҢ–пјҢжҺ§еҲ¶дёӯй—ҙз»“жһңзҡ„еӯҳеӮЁгҖҒеҲҶеҢәзӯүгҖӮеҸҜд»ҘиҜҙзј–зЁӢжЁЎеһӢжҜ”HadoopжӣҙзҒөжҙ»гҖӮ
дёҚиҝҮз”ұдәҺRDDзҡ„зү№жҖ§пјҢSparkдёҚйҖӮз”ЁйӮЈз§ҚејӮжӯҘз»ҶзІ’еәҰжӣҙж–°зҠ¶жҖҒзҡ„еә”з”ЁпјҢдҫӢеҰӮwebжңҚеҠЎзҡ„еӯҳеӮЁжҲ–иҖ…жҳҜеўһйҮҸзҡ„webзҲ¬иҷ«е’Ңзҙўеј•гҖӮе°ұжҳҜеҜ№дәҺйӮЈз§ҚеўһйҮҸдҝ®ж”№зҡ„еә”з”ЁжЁЎеһӢдёҚйҖӮеҗҲгҖӮ
в—Ҷ е®№й”ҷжҖ§гҖӮ
еңЁеҲҶеёғејҸж•°жҚ®йӣҶи®Ўз®—ж—¶йҖҡиҝҮcheckpointжқҘе®һзҺ°е®№й”ҷпјҢиҖҢcheckpointжңүдёӨз§Қж–№ејҸпјҢдёҖдёӘжҳҜcheckpoint dataпјҢдёҖдёӘжҳҜlogging the updatesгҖӮз”ЁжҲ·еҸҜд»ҘжҺ§еҲ¶йҮҮз”Ёе“Әз§Қж–№ејҸжқҘе®һзҺ°е®№й”ҷгҖӮ
в—Ҷ еҸҜз”ЁжҖ§гҖӮ
SparkйҖҡиҝҮжҸҗдҫӣдё°еҜҢзҡ„Scala, JavaпјҢPython APIеҸҠдәӨдә’ејҸShellжқҘжҸҗй«ҳеҸҜз”ЁжҖ§гҖӮ
SparkдёҺHadoopзҡ„з»“еҗҲ
в—Ҷ SparkеҸҜд»ҘзӣҙжҺҘеҜ№HDFSиҝӣиЎҢж•°жҚ®зҡ„иҜ»еҶҷпјҢеҗҢж ·ж”ҜжҢҒSpark on YARNгҖӮSparkеҸҜд»ҘдёҺMapReduceиҝҗиЎҢдәҺеҗҢйӣҶзҫӨдёӯпјҢе…ұдә«еӯҳеӮЁиө„жәҗдёҺи®Ўз®—пјҢж•°жҚ®д»“еә“Sharkе®һзҺ°дёҠеҖҹз”ЁHiveпјҢеҮ д№ҺдёҺHiveе®Ңе…Ёе…је®№гҖӮ
Sparkзҡ„йҖӮз”ЁеңәжҷҜ
в—Ҷ SparkжҳҜеҹәдәҺеҶ…еӯҳзҡ„иҝӯд»Ји®Ўз®—жЎҶжһ¶пјҢйҖӮз”ЁдәҺйңҖиҰҒеӨҡж¬Ўж“ҚдҪңзү№е®ҡж•°жҚ®йӣҶзҡ„еә”з”ЁеңәеҗҲгҖӮйңҖиҰҒеҸҚеӨҚж“ҚдҪңзҡ„ж¬Ўж•°и¶ҠеӨҡпјҢжүҖйңҖиҜ»еҸ–зҡ„ж•°жҚ®йҮҸи¶ҠеӨ§пјҢеҸ—зӣҠи¶ҠеӨ§пјҢж•°жҚ®йҮҸе°ҸдҪҶжҳҜи®Ўз®—еҜҶйӣҶеәҰиҫғеӨ§зҡ„еңәеҗҲпјҢеҸ—зӣҠе°ұзӣёеҜ№иҫғе°Ҹ
в—Ҷ з”ұдәҺRDDзҡ„зү№жҖ§пјҢSparkдёҚйҖӮз”ЁйӮЈз§ҚејӮжӯҘз»ҶзІ’еәҰжӣҙж–°зҠ¶жҖҒзҡ„еә”з”ЁпјҢдҫӢеҰӮwebжңҚеҠЎзҡ„еӯҳеӮЁжҲ–иҖ…жҳҜеўһйҮҸзҡ„webзҲ¬иҷ«е’Ңзҙўеј•гҖӮе°ұжҳҜеҜ№дәҺйӮЈз§ҚеўһйҮҸдҝ®ж”№зҡ„еә”з”ЁжЁЎеһӢдёҚйҖӮеҗҲгҖӮ
в—Ҷ жҖ»зҡ„жқҘиҜҙSparkзҡ„йҖӮз”ЁйқўжҜ”иҫғе№ҝжіӣдё”жҜ”иҫғйҖҡз”ЁгҖӮ
иҝҗиЎҢжЁЎејҸ
в—Ҷ жң¬ең°жЁЎејҸ
в—Ҷ StandaloneжЁЎејҸ
в—Ҷ MesoesжЁЎејҸ
в—Ҷ yarnжЁЎејҸ
Sparkз”ҹжҖҒзі»з»ҹ
в—Ҷ Shark ( Hive on Spark): Sharkеҹәжң¬дёҠе°ұжҳҜеңЁSparkзҡ„жЎҶжһ¶еҹәзЎҖдёҠжҸҗдҫӣе’ҢHiveдёҖж ·зҡ„H iveQLе‘Ҫд»ӨжҺҘеҸЈпјҢдёәдәҶжңҖеӨ§зЁӢеәҰзҡ„дҝқжҢҒе’ҢHiveзҡ„е…је®№жҖ§пјҢSharkдҪҝз”ЁдәҶHiveзҡ„APIжқҘе®һзҺ°query Parsingе’Ң Logic Plan generationпјҢжңҖеҗҺзҡ„PhysicalPlan executionйҳ¶ж®өз”ЁSparkд»ЈжӣҝHadoop MapReduceгҖӮйҖҡиҝҮй…ҚзҪ®SharkеҸӮж•°пјҢSharkеҸҜд»ҘиҮӘеҠЁеңЁеҶ…еӯҳдёӯзј“еӯҳзү№е®ҡзҡ„RDDпјҢе®һзҺ°ж•°жҚ®йҮҚз”ЁпјҢиҝӣиҖҢеҠ еҝ«зү№е®ҡж•°жҚ®йӣҶзҡ„жЈҖзҙўгҖӮеҗҢж—¶пјҢSharkйҖҡиҝҮUDFз”ЁжҲ·иҮӘе®ҡд№үеҮҪж•°е®һзҺ°зү№е®ҡзҡ„ж•°жҚ®еҲҶжһҗеӯҰд№ з®—жі•пјҢдҪҝеҫ—SQLж•°жҚ®жҹҘиҜўе’Ңиҝҗз®—еҲҶжһҗиғҪз»“еҗҲеңЁдёҖиө·пјҢжңҖеӨ§еҢ–RDDзҡ„йҮҚеӨҚдҪҝз”ЁгҖӮ
в—Ҷ Spark streaming: жһ„е»әеңЁSparkдёҠеӨ„зҗҶStreamж•°жҚ®зҡ„жЎҶжһ¶пјҢеҹәжң¬зҡ„еҺҹзҗҶжҳҜе°ҶStreamж•°жҚ®еҲҶжҲҗе°Ҹзҡ„ж—¶й—ҙзүҮж–ӯпјҲеҮ з§’пјүпјҢд»Ҙзұ»дјјbatchжү№йҮҸеӨ„зҗҶзҡ„ж–№ејҸжқҘеӨ„зҗҶиҝҷе°ҸйғЁеҲҶж•°жҚ®гҖӮSpark Streamingжһ„е»әеңЁSparkдёҠпјҢдёҖж–№йқўжҳҜеӣ дёәSparkзҡ„дҪҺ延иҝҹжү§иЎҢеј•ж“ҺпјҲ100ms+пјүеҸҜд»Ҙз”ЁдәҺе®һж—¶и®Ўз®—пјҢеҸҰдёҖж–№йқўзӣёжҜ”еҹәдәҺRecordзҡ„е…¶е®ғеӨ„зҗҶжЎҶжһ¶пјҲеҰӮStormпјүпјҢRDDж•°жҚ®йӣҶжӣҙе®№жҳ“еҒҡй«ҳж•Ҳзҡ„е®№й”ҷеӨ„зҗҶгҖӮжӯӨеӨ–е°Ҹжү№йҮҸеӨ„зҗҶзҡ„ж–№ејҸдҪҝеҫ—е®ғеҸҜд»ҘеҗҢж—¶е…је®№жү№йҮҸе’Ңе®һж—¶ж•°жҚ®еӨ„зҗҶзҡ„йҖ»иҫ‘е’Ңз®—жі•гҖӮж–№дҫҝдәҶдёҖдәӣйңҖиҰҒеҺҶеҸІж•°жҚ®е’Ңе®һж—¶ж•°жҚ®иҒ”еҗҲеҲҶжһҗзҡ„зү№е®ҡеә”з”ЁеңәеҗҲгҖӮ
в—Ҷ Bagel: Pregel on SparkпјҢеҸҜд»Ҙз”ЁSparkиҝӣиЎҢеӣҫи®Ўз®—пјҢиҝҷжҳҜдёӘйқһеёёжңүз”Ёзҡ„е°ҸйЎ№зӣ®гҖӮBagelиҮӘеёҰдәҶдёҖдёӘдҫӢеӯҗпјҢе®һзҺ°дәҶGoogleзҡ„PageRankз®—жі•гҖӮ
еңЁдёҡз•Ңзҡ„дҪҝз”Ё
в—Ҷ SparkйЎ№зӣ®еңЁ2009е№ҙеҗҜеҠЁпјҢ2010е№ҙејҖжәҗ, зҺ°еңЁдҪҝз”Ёзҡ„жңүпјҡBerkeley, Princeton, Klout, Foursquare, Conviva, Quantifind, Yahoo! Research & others, ж·ҳе®қзӯүпјҢиұҶз“Јд№ҹеңЁдҪҝз”ЁSparkзҡ„pythonе…ӢйҡҶзүҲDparkгҖӮ
Sparkж ёеҝғжҰӮеҝө
Resilient Distributed Dataset (RDD)еј№жҖ§еҲҶеёғж•°жҚ®йӣҶ
в—Ҷ RDDжҳҜSparkзҡ„жңҖеҹәжң¬жҠҪиұЎ,жҳҜеҜ№еҲҶеёғејҸеҶ…еӯҳзҡ„жҠҪиұЎдҪҝз”ЁпјҢе®һзҺ°дәҶд»Ҙж“ҚдҪңжң¬ең°йӣҶеҗҲзҡ„ж–№ејҸжқҘж“ҚдҪңеҲҶеёғејҸж•°жҚ®йӣҶзҡ„жҠҪиұЎе®һзҺ°гҖӮRDDжҳҜSparkжңҖж ёеҝғзҡ„дёңиҘҝпјҢе®ғиЎЁзӨәе·Іиў«еҲҶеҢәпјҢдёҚеҸҜеҸҳзҡ„并иғҪеӨҹ被并иЎҢж“ҚдҪңзҡ„ж•°жҚ®йӣҶеҗҲпјҢдёҚеҗҢзҡ„ж•°жҚ®йӣҶж јејҸеҜ№еә”дёҚеҗҢзҡ„RDDе®һзҺ°гҖӮRDDеҝ…йЎ»жҳҜеҸҜеәҸеҲ—еҢ–зҡ„гҖӮRDDеҸҜд»ҘcacheеҲ°еҶ…еӯҳдёӯпјҢжҜҸж¬ЎеҜ№RDDж•°жҚ®йӣҶзҡ„ж“ҚдҪңд№ӢеҗҺзҡ„з»“жһңпјҢйғҪеҸҜд»Ҙеӯҳж”ҫеҲ°еҶ…еӯҳдёӯпјҢдёӢдёҖдёӘж“ҚдҪңеҸҜд»ҘзӣҙжҺҘд»ҺеҶ…еӯҳдёӯиҫ“е…ҘпјҢзңҒеҺ»дәҶMapReduceеӨ§йҮҸзҡ„зЈҒзӣҳIOж“ҚдҪңгҖӮиҝҷеҜ№дәҺиҝӯд»Јиҝҗз®—жҜ”иҫғеёёи§Ғзҡ„жңәеҷЁеӯҰд№ з®—жі•, дәӨдә’ејҸж•°жҚ®жҢ–жҺҳжқҘиҜҙпјҢж•ҲзҺҮжҸҗеҚҮжҜ”иҫғеӨ§гҖӮ
в—Ҷ RDDзҡ„зү№зӮ№пјҡ
е®ғжҳҜеңЁйӣҶзҫӨиҠӮзӮ№дёҠзҡ„дёҚеҸҜеҸҳзҡ„гҖҒе·ІеҲҶеҢәзҡ„йӣҶеҗҲеҜ№иұЎгҖӮ
йҖҡиҝҮ并иЎҢиҪ¬жҚўзҡ„ж–№ејҸжқҘеҲӣе»әеҰӮпјҲmap, filter, join, etcпјүгҖӮ
еӨұиҙҘиҮӘеҠЁйҮҚе»әгҖӮ
еҸҜд»ҘжҺ§еҲ¶еӯҳеӮЁзә§еҲ«пјҲеҶ…еӯҳгҖҒзЈҒзӣҳзӯүпјүжқҘиҝӣиЎҢйҮҚз”ЁгҖӮ
еҝ…йЎ»жҳҜеҸҜеәҸеҲ—еҢ–зҡ„гҖӮ
жҳҜйқҷжҖҒзұ»еһӢзҡ„гҖӮ
в—Ҷ RDDзҡ„еҘҪеӨ„
RDDеҸӘиғҪд»ҺжҢҒд№…еӯҳеӮЁжҲ–йҖҡиҝҮTransformationsж“ҚдҪңдә§з”ҹпјҢзӣёжҜ”дәҺеҲҶеёғејҸе…ұдә«еҶ…еӯҳпјҲDSMпјүеҸҜд»Ҙжӣҙй«ҳж•Ҳе®һзҺ°е®№й”ҷпјҢеҜ№дәҺдёўеӨұйғЁеҲҶж•°жҚ®еҲҶеҢәеҸӘйңҖж №жҚ®е®ғзҡ„lineageе°ұеҸҜйҮҚж–°и®Ўз®—еҮәжқҘпјҢиҖҢдёҚйңҖиҰҒеҒҡзү№е®ҡзҡ„CheckpointгҖӮ
RDDзҡ„дёҚеҸҳжҖ§пјҢеҸҜд»Ҙе®һзҺ°зұ»Hadoop MapReduceзҡ„жҺЁжөӢејҸжү§иЎҢгҖӮ
RDDзҡ„ж•°жҚ®еҲҶеҢәзү№жҖ§пјҢеҸҜд»ҘйҖҡиҝҮж•°жҚ®зҡ„жң¬ең°жҖ§жқҘжҸҗй«ҳжҖ§иғҪпјҢиҝҷдёҺHadoop MapReduceжҳҜдёҖж ·зҡ„гҖӮ
RDDйғҪжҳҜеҸҜеәҸеҲ—еҢ–зҡ„пјҢеңЁеҶ…еӯҳдёҚи¶іж—¶еҸҜиҮӘеҠЁйҷҚзә§дёәзЈҒзӣҳеӯҳеӮЁпјҢжҠҠRDDеӯҳеӮЁдәҺзЈҒзӣҳдёҠпјҢиҝҷж—¶жҖ§иғҪдјҡжңүеӨ§зҡ„дёӢйҷҚдҪҶдёҚдјҡе·®дәҺзҺ°еңЁзҡ„MapReduceгҖӮ
в—Ҷ RDDзҡ„еӯҳеӮЁдёҺеҲҶеҢә
з”ЁжҲ·еҸҜд»ҘйҖүжӢ©дёҚеҗҢзҡ„еӯҳеӮЁзә§еҲ«еӯҳеӮЁRDDд»ҘдҫҝйҮҚз”ЁгҖӮ
еҪ“еүҚRDDй»ҳи®ӨжҳҜеӯҳеӮЁдәҺеҶ…еӯҳпјҢдҪҶеҪ“еҶ…еӯҳдёҚи¶іж—¶пјҢRDDдјҡspillеҲ°diskгҖӮ
RDDеңЁйңҖиҰҒиҝӣиЎҢеҲҶеҢәжҠҠж•°жҚ®еҲҶеёғдәҺйӣҶзҫӨдёӯж—¶дјҡж №жҚ®жҜҸжқЎи®°еҪ•KeyиҝӣиЎҢеҲҶеҢәпјҲеҰӮHash еҲҶеҢәпјүпјҢд»ҘжӯӨдҝқиҜҒдёӨдёӘж•°жҚ®йӣҶеңЁJoinж—¶иғҪй«ҳж•ҲгҖӮ
в—Ҷ RDDзҡ„еҶ…йғЁиЎЁзӨә
еңЁRDDзҡ„еҶ…йғЁе®һзҺ°дёӯжҜҸдёӘRDDйғҪеҸҜд»ҘдҪҝз”Ё5дёӘж–№йқўзҡ„зү№жҖ§жқҘиЎЁзӨәпјҡ
еҲҶеҢәеҲ—иЎЁпјҲж•°жҚ®еқ—еҲ—иЎЁпјү
и®Ўз®—жҜҸдёӘеҲҶзүҮзҡ„еҮҪж•°пјҲж №жҚ®зҲ¶RDDи®Ўз®—еҮәжӯӨRDDпјү
еҜ№зҲ¶RDDзҡ„дҫқиө–еҲ—иЎЁ
еҜ№key-value RDDзҡ„PartitionerгҖҗеҸҜйҖүгҖ‘
жҜҸдёӘж•°жҚ®еҲҶзүҮзҡ„йў„е®ҡд№үең°еқҖеҲ—иЎЁ(еҰӮHDFSдёҠзҡ„ж•°жҚ®еқ—зҡ„ең°еқҖ)гҖҗеҸҜйҖүгҖ‘
в—Ҷ RDDзҡ„еӯҳеӮЁзә§еҲ«
RDDж №жҚ®useDiskгҖҒuseMemoryгҖҒdeserializedгҖҒreplicationеӣӣдёӘеҸӮж•°зҡ„з»„еҗҲжҸҗдҫӣдәҶ11з§ҚеӯҳеӮЁзә§еҲ«пјҡ
val NONE = new StorageLevel(false, false, false) val DISK_ONLY = new StorageLevel(true, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, 2) val MEMORY_ONLY = new StorageLevel(false, true, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, 2) val MEMORY_AND_DISK = new StorageLevel(true, true, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, 2)
в—Ҷ RDDе®ҡд№үдәҶеҗ„з§Қж“ҚдҪңпјҢдёҚеҗҢзұ»еһӢзҡ„ж•°жҚ®з”ұдёҚеҗҢзҡ„RDDзұ»жҠҪиұЎиЎЁзӨәпјҢдёҚеҗҢзҡ„ж“ҚдҪңд№ҹз”ұRDDиҝӣиЎҢжҠҪе®һзҺ°гҖӮ
RDDзҡ„з”ҹжҲҗ
в—Ҷ RDDжңүдёӨз§ҚеҲӣе»әж–№ејҸпјҡ
1гҖҒд»ҺHadoopж–Ү件系з»ҹпјҲжҲ–дёҺHadoopе…је®№зҡ„е…¶е®ғеӯҳеӮЁзі»з»ҹпјүиҫ“е…ҘпјҲдҫӢеҰӮHDFSпјүеҲӣе»әгҖӮ
2гҖҒд»ҺзҲ¶RDDиҪ¬жҚўеҫ—еҲ°ж–°RDDгҖӮ
в—Ҷ дёӢйқўжқҘзңӢдёҖд»ҺHadoopж–Ү件系з»ҹз”ҹжҲҗRDDзҡ„ж–№ејҸпјҢеҰӮпјҡval file = spark.textFile("hdfs://...")пјҢfileеҸҳйҮҸе°ұжҳҜRDDпјҲе®һйҷ…жҳҜHadoopRDDе®һдҫӢпјүпјҢз”ҹжҲҗзҡ„е®ғзҡ„ж ёеҝғд»Јз ҒеҰӮдёӢпјҡ
// SparkContextж №жҚ®ж–Ү件/зӣ®еҪ•еҸҠеҸҜйҖүзҡ„еҲҶзүҮж•°еҲӣе»әRDD, иҝҷйҮҢжҲ‘们еҸҜд»ҘзңӢеҲ°SparkдёҺHadoop MapReduceеҫҲеғҸ // йңҖиҰҒInputFormat, KeyгҖҒValueзҡ„зұ»еһӢпјҢе…¶е®һSparkдҪҝз”Ёзҡ„Hadoopзҡ„InputFormat, Writableзұ»еһӢгҖӮ def textFile(path: String, minSplits: Int = defaultMinSplits): RDD[String] = { hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], minSplits) .map(pair => pair._2.toString) } // ж №жҚ®Hadoopй…ҚзҪ®пјҢеҸҠInputFormatзӯүеҲӣе»әHadoopRDD new HadoopRDD(this, conf, inputFormatClass, keyClass, valueClass, minSplits)в—Ҷ еҜ№RDDиҝӣиЎҢи®Ўз®—ж—¶пјҢRDDд»ҺHDFSиҜ»еҸ–ж•°жҚ®ж—¶дёҺHadoop MapReduceеҮ д№ҺдёҖж ·зҡ„пјҡ
RDDзҡ„иҪ¬жҚўдёҺж“ҚдҪң
в—Ҷ еҜ№дәҺRDDеҸҜд»ҘжңүдёӨз§Қи®Ўз®—ж–№ејҸпјҡиҪ¬жҚўпјҲиҝ”еӣһеҖјиҝҳжҳҜдёҖдёӘRDDпјүдёҺж“ҚдҪңпјҲиҝ”еӣһеҖјдёҚжҳҜдёҖдёӘRDDпјүгҖӮ
в—Ҷ иҪ¬жҚў(Transformations) (еҰӮпјҡmap, filter, groupBy, joinзӯү)пјҢTransformationsж“ҚдҪңжҳҜLazyзҡ„пјҢд№ҹе°ұжҳҜиҜҙд»ҺдёҖдёӘRDDиҪ¬жҚўз”ҹжҲҗеҸҰдёҖдёӘRDDзҡ„ж“ҚдҪңдёҚжҳҜ马дёҠжү§иЎҢпјҢSparkеңЁйҒҮеҲ°Transformationsж“ҚдҪңж—¶еҸӘдјҡи®°еҪ•йңҖиҰҒиҝҷж ·зҡ„ж“ҚдҪңпјҢ并дёҚдјҡеҺ»жү§иЎҢпјҢйңҖиҰҒзӯүеҲ°жңүActionsж“ҚдҪңзҡ„ж—¶еҖҷжүҚдјҡзңҹжӯЈеҗҜеҠЁи®Ўз®—иҝҮзЁӢиҝӣиЎҢи®Ўз®—гҖӮ
в—Ҷ ж“ҚдҪң(Actions) (еҰӮпјҡcount, collect, saveзӯү)пјҢActionsж“ҚдҪңдјҡиҝ”еӣһз»“жһңжҲ–жҠҠRDDж•°жҚ®еҶҷеҲ°еӯҳеӮЁзі»з»ҹдёӯгҖӮActionsжҳҜи§ҰеҸ‘SparkеҗҜеҠЁи®Ўз®—зҡ„еҠЁеӣ гҖӮ
в—Ҷ дёӢйқўдҪҝз”ЁдёҖдёӘдҫӢеӯҗжқҘзӨәдҫӢиҜҙжҳҺTransformationsдёҺActionsеңЁSparkзҡ„дҪҝз”ЁгҖӮ
val sc = new SparkContext(master, "Example", System.getenv("SPARK_HOME"), Seq(System.getenv("SPARK_TEST_JAR"))) val rdd_A = sc.textFile(hdfs://.....) val rdd_B = rdd_A.flatMap((line => line.split("\\s+"))).map(word => (word, 1)) val rdd_C = sc.textFile(hdfs://.....) val rdd_D = rdd_C.map(line => (line.substring(10), 1)) val rdd_E = rdd_D.reduceByKey((a, b) => a + b) val rdd_F = rdd_B.jion(rdd_E) rdd_F.saveAsSequenceFile(hdfs://....)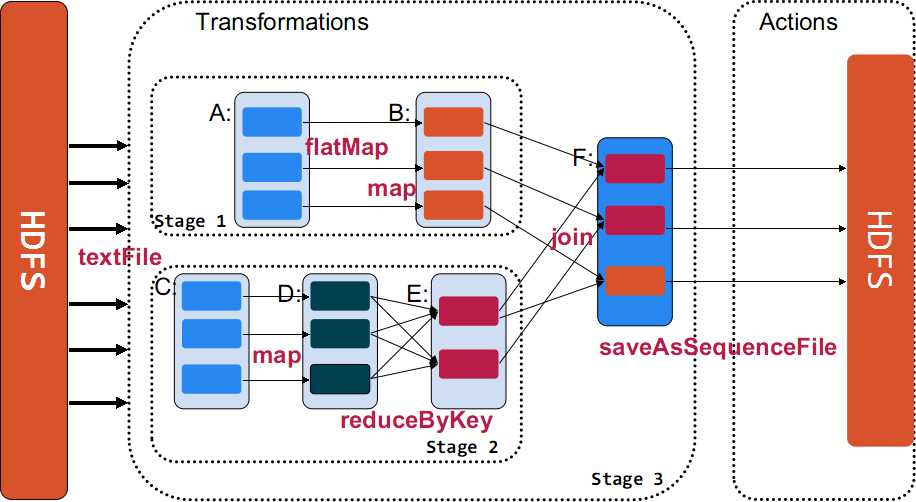
LineageпјҲиЎҖз»ҹпјү
в—Ҷ еҲ©з”ЁеҶ…еӯҳеҠ еҝ«ж•°жҚ®еҠ иҪҪ,еңЁдј—еӨҡзҡ„е…¶е®ғзҡ„In-Memoryзұ»ж•°жҚ®еә“жҲ–Cacheзұ»зі»з»ҹдёӯд№ҹжңүе®һзҺ°пјҢSparkзҡ„дё»иҰҒеҢәеҲ«еңЁдәҺе®ғеӨ„зҗҶеҲҶеёғејҸиҝҗз®—зҺҜеўғдёӢзҡ„ж•°жҚ®е®№й”ҷжҖ§пјҲиҠӮзӮ№е®һж•Ҳ/ж•°жҚ®дёўеӨұпјүй—®йўҳж—¶йҮҮз”Ёзҡ„ж–№жЎҲгҖӮдёәдәҶдҝқиҜҒRDDдёӯж•°жҚ®зҡ„йІҒжЈ’жҖ§пјҢRDDж•°жҚ®йӣҶйҖҡиҝҮжүҖи°“зҡ„иЎҖз»ҹе…ізі»(Lineage)и®°дҪҸдәҶе®ғжҳҜеҰӮдҪ•д»Һе…¶е®ғRDDдёӯжј”еҸҳиҝҮжқҘзҡ„гҖӮзӣёжҜ”е…¶е®ғзі»з»ҹзҡ„з»Ҷйў—зІ’еәҰзҡ„еҶ…еӯҳж•°жҚ®жӣҙж–°зә§еҲ«зҡ„еӨҮд»ҪжҲ–иҖ…LOGжңәеҲ¶пјҢRDDзҡ„Lineageи®°еҪ•зҡ„жҳҜзІ—йў—зІ’еәҰзҡ„зү№е®ҡж•°жҚ®иҪ¬жҚўпјҲTransformationпјүж“ҚдҪңпјҲfilter, map, join etc.)иЎҢдёәгҖӮеҪ“иҝҷдёӘRDDзҡ„йғЁеҲҶеҲҶеҢәж•°жҚ®дёўеӨұж—¶пјҢе®ғеҸҜд»ҘйҖҡиҝҮLineageиҺ·еҸ–и¶іеӨҹзҡ„дҝЎжҒҜжқҘйҮҚж–°иҝҗз®—е’ҢжҒўеӨҚдёўеӨұзҡ„ж•°жҚ®еҲҶеҢәгҖӮиҝҷз§ҚзІ—йў—зІ’зҡ„ж•°жҚ®жЁЎеһӢпјҢйҷҗеҲ¶дәҶSparkзҡ„иҝҗз”ЁеңәеҗҲпјҢдҪҶеҗҢж—¶зӣёжҜ”з»Ҷйў—зІ’еәҰзҡ„ж•°жҚ®жЁЎеһӢпјҢд№ҹеёҰжқҘдәҶжҖ§иғҪзҡ„жҸҗеҚҮгҖӮ
в—Ҷ RDDеңЁLineageдҫқиө–ж–№йқўеҲҶдёәдёӨз§ҚNarrow DependenciesдёҺWide Dependenciesз”ЁжқҘи§ЈеҶіж•°жҚ®е®№й”ҷзҡ„й«ҳж•ҲжҖ§гҖӮNarrow DependenciesжҳҜжҢҮзҲ¶RDDзҡ„жҜҸдёҖдёӘеҲҶеҢәжңҖеӨҡиў«дёҖдёӘеӯҗRDDзҡ„еҲҶеҢәжүҖз”ЁпјҢиЎЁзҺ°дёәдёҖдёӘзҲ¶RDDзҡ„еҲҶеҢәеҜ№еә”дәҺдёҖдёӘеӯҗRDDзҡ„еҲҶеҢәжҲ–еӨҡдёӘзҲ¶RDDзҡ„еҲҶеҢәеҜ№еә”дәҺдёҖдёӘеӯҗRDDзҡ„еҲҶеҢәпјҢд№ҹе°ұжҳҜиҜҙдёҖдёӘзҲ¶RDDзҡ„дёҖдёӘеҲҶеҢәдёҚеҸҜиғҪеҜ№еә”дёҖдёӘеӯҗRDDзҡ„еӨҡдёӘеҲҶеҢәгҖӮWide DependenciesжҳҜжҢҮеӯҗRDDзҡ„еҲҶеҢәдҫқиө–дәҺзҲ¶RDDзҡ„еӨҡдёӘеҲҶеҢәжҲ–жүҖжңүеҲҶеҢәпјҢд№ҹе°ұжҳҜиҜҙеӯҳеңЁдёҖдёӘзҲ¶RDDзҡ„дёҖдёӘеҲҶеҢәеҜ№еә”дёҖдёӘеӯҗRDDзҡ„еӨҡдёӘеҲҶеҢәгҖӮеҜ№дёҺWide DependenciesпјҢиҝҷз§Қи®Ўз®—зҡ„иҫ“е…Ҙе’Ңиҫ“еҮәеңЁдёҚеҗҢзҡ„иҠӮзӮ№дёҠпјҢlineageж–№жі•еҜ№дёҺиҫ“е…ҘиҠӮзӮ№е®ҢеҘҪпјҢиҖҢиҫ“еҮәиҠӮзӮ№е®•жңәж—¶пјҢйҖҡиҝҮйҮҚж–°и®Ўз®—пјҢиҝҷз§Қжғ…еҶөдёӢпјҢиҝҷз§Қж–№жі•е®№й”ҷжҳҜжңүж•Ҳзҡ„пјҢеҗҰеҲҷж— ж•ҲпјҢеӣ дёәж— жі•йҮҚиҜ•пјҢйңҖиҰҒеҗ‘дёҠе…¶зҘ–е…ҲиҝҪжәҜзңӢжҳҜеҗҰеҸҜд»ҘйҮҚиҜ•пјҲиҝҷе°ұжҳҜlineageпјҢиЎҖз»ҹзҡ„ж„ҸжҖқпјүпјҢNarrow DependenciesеҜ№дәҺж•°жҚ®зҡ„йҮҚз®—ејҖй”ҖиҰҒиҝңе°ҸдәҺWide Dependenciesзҡ„ж•°жҚ®йҮҚз®—ејҖй”ҖгҖӮ
е®№й”ҷ
в—Ҷ еңЁRDDи®Ўз®—пјҢйҖҡиҝҮcheckpintиҝӣиЎҢе®№й”ҷпјҢеҒҡcheckpointжңүдёӨз§Қж–№ејҸпјҢдёҖдёӘжҳҜcheckpoint dataпјҢдёҖдёӘжҳҜlogging the updatesгҖӮз”ЁжҲ·еҸҜд»ҘжҺ§еҲ¶йҮҮз”Ёе“Әз§Қж–№ејҸжқҘе®һзҺ°е®№й”ҷпјҢй»ҳи®ӨжҳҜlogging the updatesж–№ејҸпјҢйҖҡиҝҮи®°еҪ•и·ҹиёӘжүҖжңүз”ҹжҲҗRDDзҡ„иҪ¬жҚўпјҲtransformationsпјүд№ҹе°ұжҳҜи®°еҪ•жҜҸдёӘRDDзҡ„lineageпјҲиЎҖз»ҹпјүжқҘйҮҚж–°и®Ўз®—з”ҹжҲҗдёўеӨұзҡ„еҲҶеҢәж•°жҚ®гҖӮ
иө„жәҗз®ЎзҗҶдёҺдҪңдёҡи°ғеәҰ
в—Ҷ SparkеҜ№дәҺиө„жәҗз®ЎзҗҶдёҺдҪңдёҡи°ғеәҰеҸҜд»ҘдҪҝз”ЁStandalone(зӢ¬з«ӢжЁЎејҸ)пјҢApache MesosеҸҠHadoop YARNжқҘе®һзҺ°гҖӮ Spark on YarnеңЁSpark0.6ж—¶еј•з”ЁпјҢдҪҶзңҹжӯЈеҸҜз”ЁжҳҜеңЁзҺ°еңЁзҡ„branch-0.8зүҲжң¬гҖӮSpark on YarnйҒөеҫӘYARNзҡ„е®ҳ方规иҢғе®һзҺ°пјҢеҫ—зӣҠдәҺSparkеӨ©з”ҹж”ҜжҢҒеӨҡз§ҚSchedulerе’ҢExecutorзҡ„иүҜеҘҪи®ҫи®ЎпјҢеҜ№YARNзҡ„ж”ҜжҢҒд№ҹе°ұйқһеёёе®№жҳ“пјҢSpark on Yarnзҡ„еӨ§иҮҙжЎҶжһ¶еӣҫгҖӮ
в—Ҷ и®©SparkиҝҗиЎҢдәҺYARNдёҠдёҺHadoopе…ұз”ЁйӣҶзҫӨиө„жәҗеҸҜд»ҘжҸҗй«ҳиө„жәҗеҲ©з”ЁзҺҮгҖӮ
зј–зЁӢжҺҘеҸЈ
в—Ҷ SparkйҖҡиҝҮдёҺзј–зЁӢиҜӯиЁҖйӣҶжҲҗзҡ„ж–№ејҸжҡҙйңІRDDзҡ„ж“ҚдҪңпјҢзұ»дјјдәҺDryadLINQе’ҢFlumeJavaпјҢжҜҸдёӘж•°жҚ®йӣҶйғҪиЎЁзӨәдёәRDDеҜ№иұЎпјҢеҜ№ж•°жҚ®йӣҶзҡ„ж“ҚдҪңе°ұиЎЁзӨәжҲҗеҜ№RDDеҜ№иұЎзҡ„ж“ҚдҪңгҖӮSparkдё»иҰҒзҡ„зј–зЁӢиҜӯиЁҖжҳҜScalaпјҢйҖүжӢ©ScalaжҳҜеӣ дёәе®ғзҡ„з®ҖжҙҒжҖ§пјҲScalaеҸҜд»ҘеҫҲж–№дҫҝеңЁдәӨдә’ејҸдёӢдҪҝз”Ёпјүе’ҢжҖ§иғҪпјҲJVMдёҠзҡ„йқҷжҖҒејәзұ»еһӢиҜӯиЁҖпјүгҖӮ
в—Ҷ Sparkе’ҢHadoop MapReduceзұ»дјјпјҢз”ұMaster(зұ»дјјдәҺMapReduceзҡ„Jobtracker)е’ҢWorkers(Sparkзҡ„Slaveе·ҘдҪңиҠӮзӮ№)з»„жҲҗгҖӮз”ЁжҲ·зј–еҶҷзҡ„SparkзЁӢеәҸиў«з§°дёәDriverзЁӢеәҸпјҢDirverзЁӢеәҸдјҡиҝһжҺҘmaster并е®ҡд№үдәҶеҜ№еҗ„RDDзҡ„иҪ¬жҚўдёҺж“ҚдҪңпјҢиҖҢеҜ№RDDзҡ„иҪ¬жҚўдёҺж“ҚдҪңйҖҡиҝҮScalaй—ӯеҢ…(еӯ—йқўйҮҸеҮҪж•°)жқҘиЎЁзӨәпјҢScalaдҪҝз”ЁJavaеҜ№иұЎжқҘиЎЁзӨәй—ӯеҢ…дё”йғҪжҳҜеҸҜеәҸеҲ—еҢ–зҡ„пјҢд»ҘжӯӨжҠҠеҜ№RDDзҡ„й—ӯеҢ…ж“ҚдҪңеҸ‘йҖҒеҲ°еҗ„WorkersиҠӮзӮ№гҖӮ WorkersеӯҳеӮЁзқҖж•°жҚ®еҲҶеқ—е’Ңдә«жңүйӣҶзҫӨеҶ…еӯҳпјҢжҳҜиҝҗиЎҢеңЁе·ҘдҪңиҠӮзӮ№дёҠзҡ„е®ҲжҠӨиҝӣзЁӢпјҢеҪ“е®ғ收еҲ°еҜ№RDDзҡ„ж“ҚдҪңж—¶пјҢж №жҚ®ж•°жҚ®еҲҶзүҮдҝЎжҒҜиҝӣиЎҢжң¬ең°еҢ–ж•°жҚ®ж“ҚдҪңпјҢз”ҹжҲҗж–°зҡ„ж•°жҚ®еҲҶзүҮгҖҒиҝ”еӣһз»“жһңжҲ–жҠҠRDDеҶҷе…ҘеӯҳеӮЁзі»з»ҹгҖӮ
Scala
в—Ҷ SparkдҪҝз”ЁScalaејҖеҸ‘пјҢй»ҳи®ӨдҪҝз”ЁScalaдҪңдёәзј–зЁӢиҜӯиЁҖгҖӮзј–еҶҷSparkзЁӢеәҸжҜ”зј–еҶҷHadoop MapReduceзЁӢеәҸиҰҒз®ҖеҚ•зҡ„еӨҡпјҢSparKжҸҗдҫӣдәҶSpark-ShellпјҢеҸҜд»ҘеңЁSpark-ShellжөӢиҜ•зЁӢеәҸгҖӮеҶҷSparKзЁӢеәҸзҡ„дёҖиҲ¬жӯҘйӘӨе°ұжҳҜеҲӣе»әжҲ–дҪҝз”Ё(SparkContext)е®һдҫӢпјҢдҪҝз”ЁSparkContextеҲӣе»әRDDпјҢ然еҗҺе°ұжҳҜеҜ№RDDиҝӣиЎҢж“ҚдҪңгҖӮеҰӮпјҡ
val sc = new SparkContext(master, appName, [sparkHome], [jars]) val textFile = sc.textFile("hdfs://.....") textFile.map(....).filter(.....).....Java
в—Ҷ Sparkж”ҜжҢҒJavaзј–зЁӢпјҢдҪҶеҜ№дәҺдҪҝз”ЁJavaе°ұжІЎжңүдәҶSpark-Shellиҝҷж ·ж–№дҫҝзҡ„е·Ҙе…·пјҢе…¶е®ғдёҺScalaзј–зЁӢжҳҜдёҖж ·зҡ„пјҢеӣ дёәйғҪжҳҜJVMдёҠзҡ„иҜӯиЁҖпјҢScalaдёҺJavaеҸҜд»Ҙдә’ж“ҚдҪңпјҢJavaзј–зЁӢжҺҘеҸЈе…¶е®һе°ұжҳҜеҜ№Scalaзҡ„е°ҒиЈ…гҖӮеҰӮпјҡ
JavaSparkContext sc = new JavaSparkContext(...); JavaRDD lines = ctx.textFile("hdfs://..."); JavaRDD words = lines.flatMap( new FlatMapFunction<String, String>() { public Iterable call(String s) { return Arrays.asList(s.split(" ")); } } );Python
в—Ҷ зҺ°еңЁSparkд№ҹжҸҗдҫӣдәҶPythonзј–зЁӢжҺҘеҸЈпјҢSparkдҪҝз”Ёpy4jжқҘе®һзҺ°pythonдёҺjavaзҡ„дә’ж“ҚдҪңпјҢд»ҺиҖҢе®һзҺ°дҪҝз”Ёpythonзј–еҶҷSparkзЁӢеәҸгҖӮSparkд№ҹеҗҢж ·жҸҗдҫӣдәҶpysparkпјҢдёҖдёӘSparkзҡ„python shellпјҢеҸҜд»Ҙд»ҘдәӨдә’ејҸзҡ„ж–№ејҸдҪҝз”ЁPythonзј–еҶҷSparkзЁӢеәҸгҖӮ еҰӮпјҡ
from pyspark import SparkContext sc = SparkContext("local", "Job Name", pyFiles=['MyFile.py', 'lib.zip', 'app.egg']) words = sc.textFile("/usr/share/dict/words") words.filter(lambda w: w.startswith("spar")).take(5)дҪҝз”ЁзӨәдҫӢ
StandaloneжЁЎејҸ
в—Ҷ дёәж–№дҫҝSparkзҡ„жҺЁе№ҝдҪҝз”ЁпјҢSparkжҸҗдҫӣдәҶStandaloneжЁЎејҸпјҢSparkдёҖејҖе§Ӣе°ұи®ҫи®ЎиҝҗиЎҢдәҺApache Mesosиө„жәҗз®ЎзҗҶжЎҶжһ¶дёҠпјҢиҝҷжҳҜйқһеёёеҘҪзҡ„и®ҫи®ЎпјҢдҪҶжҳҜеҚҙеёҰдәҶйғЁзҪІжөӢиҜ•зҡ„еӨҚжқӮжҖ§гҖӮдёәдәҶи®©SparkиғҪжӣҙж–№дҫҝзҡ„йғЁзҪІе’Ңе°қиҜ•пјҢSparkеӣ жӯӨжҸҗдҫӣдәҶStandaloneиҝҗиЎҢжЁЎејҸпјҢе®ғз”ұдёҖдёӘSpark Masterе’ҢеӨҡдёӘSpark workerз»„жҲҗпјҢдёҺHadoop MapReduce1еҫҲзӣёдјјпјҢе°ұиҝһйӣҶзҫӨеҗҜеҠЁж–№ејҸйғҪеҮ д№ҺжҳҜдёҖж ·гҖӮ
в—Ҷ д»ҘStandaloneжЁЎејҸиҝҗиЎҢSparkйӣҶзҫӨ
дёӢиҪҪScala2.9.3пјҢ并й…ҚзҪ®SCALA_HOME
дёӢиҪҪSparkд»Јз ҒпјҲеҸҜд»ҘдҪҝз”Ёжәҗз Ғзј–иҜ‘д№ҹеҸҜд»ҘдёӢиҪҪзј–иҜ‘еҘҪзҡ„зүҲжң¬пјүиҝҷйҮҢдёӢиҪҪ зј–иҜ‘еҘҪзҡ„зүҲжң¬пјҲhttp://spark-project.org/download/spark-0.7.3-prebuilt-cdh5.tgzпјү
и§ЈеҺӢspark-0.7.3-prebuilt-cdh5.tgzе®үиЈ…еҢ…
дҝ®ж”№й…ҚзҪ®пјҲconf/*пјү slaves: й…ҚзҪ®е·ҘдҪңиҠӮзӮ№зҡ„дё»жңәеҗҚ spark-env.shпјҡй…ҚзҪ®зҺҜеўғеҸҳйҮҸгҖӮ
SCALA_HOME=/home/spark/scala-2.9.3 JAVA_HOME=/home/spark/jdk1.6.0_45 SPARK_MASTER_IP=spark1 SPARK_MASTER_PORT=30111 SPARK_MASTER_WEBUI_PORT=30118 SPARK_WORKER_CORES=2 SPARK_WORKER_MEMORY=4g SPARK_WORKER_PORT=30333 SPARK_WORKER_WEBUI_PORT=30119 SPARK_WORKER_INSTANCES=1
в—Ҷ жҠҠHadoopй…ҚзҪ®copyеҲ°confзӣ®еҪ•дёӢ
в—Ҷ еңЁmasterдё»жңәдёҠеҜ№е…¶е®ғжңәеҷЁеҒҡsshж— еҜҶз Ғзҷ»еҪ•
в—Ҷ жҠҠй…ҚзҪ®еҘҪзҡ„SparkзЁӢеәҸдҪҝз”Ёscp copyеҲ°е…¶е®ғжңәеҷЁ
в—Ҷ еңЁmasterеҗҜеҠЁйӣҶзҫӨ
$SPARK_HOME/start-all.sh
yarnжЁЎејҸ
в—Ҷ Spark-shellзҺ°еңЁиҝҳдёҚж”ҜжҢҒYarnжЁЎејҸпјҢдҪҝз”ЁYarnжЁЎејҸиҝҗиЎҢпјҢйңҖиҰҒжҠҠSparkзЁӢеәҸе…ЁйғЁжү“еҢ…жҲҗдёҖдёӘjarеҢ…жҸҗдәӨеҲ°YarnдёҠиҝҗиЎҢгҖӮзӣ®еҪ•еҸӘжңүbranch-0.8зүҲжң¬жүҚзңҹжӯЈж”ҜжҢҒYarnгҖӮ
в—Ҷ д»ҘYarnжЁЎејҸиҝҗиЎҢSpark
дёӢиҪҪSparkд»Јз Ғ.
git clone git://github.com/mesos/spark
в—Ҷ еҲҮжҚўеҲ°branch-0.8
cd spark git checkout -b yarn --track origin/yarn
в—Ҷ дҪҝз”Ёsbtзј–иҜ‘Spark并
$SPARK_HOME/sbt/sbt > package > assembly
в—Ҷ жҠҠHadoop yarnй…ҚзҪ®copyеҲ°confзӣ®еҪ•дёӢ
в—Ҷ иҝҗиЎҢжөӢиҜ•
SPARK_JAR=./core/target/scala-2.9.3/spark-core-assembly-0.8.0-SNAPSHOT.jar \ ./run spark.deploy.yarn.Client --jar examples/target/scala-2.9.3/ \ --class spark.examples.SparkPi --args yarn-standalone
дҪҝз”ЁSpark-shell
в—Ҷ Spark-shellдҪҝз”ЁеҫҲз®ҖеҚ•пјҢеҪ“Sparkд»ҘStandalonжЁЎејҸиҝҗиЎҢеҗҺпјҢдҪҝз”Ё$SPARK_HOME/spark-shellиҝӣе…ҘshellеҚіеҸҜпјҢеңЁSpark-shellдёӯSparkContextе·Із»ҸеҲӣе»әеҘҪдәҶпјҢе®һдҫӢеҗҚдёәscеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁпјҢиҝҳжңүдёҖдёӘйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеңЁStandaloneжЁЎејҸдёӢпјҢSparkй»ҳи®ӨдҪҝз”Ёзҡ„и°ғеәҰеҷЁзҡ„FIFOи°ғеәҰеҷЁиҖҢдёҚжҳҜе…¬е№іи°ғеәҰпјҢиҖҢSpark-shellдҪңдёәдёҖдёӘSparkзЁӢеәҸдёҖзӣҙиҝҗиЎҢеңЁSparkдёҠпјҢе…¶е®ғзҡ„SparkзЁӢеәҸе°ұеҸӘиғҪжҺ’йҳҹзӯүеҫ…пјҢд№ҹе°ұжҳҜиҜҙеҗҢдёҖж—¶й—ҙеҸӘиғҪжңүдёҖдёӘSpark-shellеңЁиҝҗиЎҢгҖӮ
в—Ҷ еңЁSpark-shellдёҠеҶҷзЁӢеәҸйқһеёёз®ҖеҚ•пјҢе°ұеғҸеңЁScala ShellдёҠеҶҷзЁӢеәҸдёҖж ·гҖӮ
scala> val textFile = sc.textFile("hdfs://hadoop1:2323/user/data") textFile: spark.RDD[String] = spark.MappedRDD@2ee9b6e3 scala> textFile.count() // Number of items in this RDD res0: Long = 21374 scala> textFile.first() // First item in this RDD res1: String = # Sparkзј–еҶҷDriverзЁӢеәҸ
в—Ҷ еңЁSparkдёӯSparkзЁӢеәҸз§°дёәDriverзЁӢеәҸпјҢзј–еҶҷDriverзЁӢеәҸеҫҲз®ҖеҚ•еҮ д№ҺдёҺеңЁSpark-shellдёҠеҶҷзЁӢеәҸжҳҜдёҖж ·зҡ„пјҢдёҚеҗҢзҡ„ең°ж–№е°ұжҳҜSparkContextйңҖиҰҒиҮӘе·ұеҲӣе»әгҖӮеҰӮWorkCountзЁӢеәҸеҰӮдёӢпјҡ
import spark.SparkContext import SparkContext._ object WordCount { def main(args: Array[String]) { if (args.length ==0 ){ println("usage is org.test.WordCount ") } println("the args: ") args.foreach(println) val hdfsPath = "hdfs://hadoop1:8020" // create the SparkContextпјҢ args(0)з”ұyarnдј е…ҘappMasterең°еқҖ val sc = new SparkContext(args(0), "WrodCount", System.getenv("SPARK_HOME"), Seq(System.getenv("SPARK_TEST_JAR"))) val textFile = sc.textFile(hdfsPath + args(1)) val result = textFile.flatMap(line => line.split("\\s+")) .map(word => (word, 1)).reduceByKey(_ + _) result.saveAsTextFile(hdfsPath + args(2)) } }еҲ°жӯӨпјҢе…ідәҺвҖңSparkж ёеҝғжҰӮеҝөжҳҜд»Җд№ҲвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ