您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1、Pandas模块
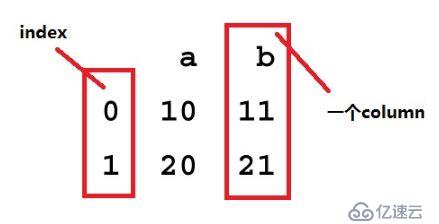
DataFrame提供的是一个类似表的结构,由多个Series组成,而Series在DataFrame中columns。
附: pandas模块文档
2、安装IPython解释器:
其实,一键安装Anaconda可以帮助使用者,一次性配置好我所有需要的工具包以及IPython解释器环境。但是,出于我想学习更加透彻,所以自己安装工具包和IPython解释器环境。
(1)因为,python在windows下通过pip安装带有c扩展的包时,如果是python2.7,需要vs2008,如果是 python 3.x,需要vs2010,版本错了都不行(建议直接装编译好的安装包:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml)。
但链接里没有IPython,所以我用的方法是官网下载并安装VCForPython27.msi。
然后在控制台里输入:
pip install ipython
pip install “ipython[notebook]”
进入ipynb文件所在目录,输入ipython notebook,会在浏览器中打开ipynb文件。
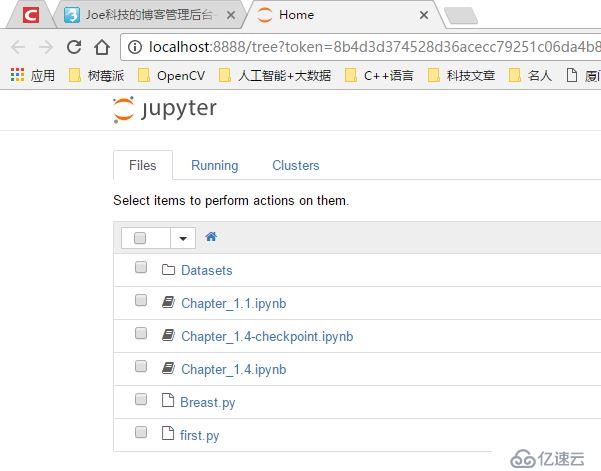
ipython notebook在下一个版本被命名为Jupyter Notebook。
通过pip install jupyter安装
jupyter notebook运行
3、
使用plot()绘图时,如果指定样式参数为仅绘制数据点,那么所绘制的就是一幅散列图。但是这种方法所绘制的点无法单独指定颜色和大小。
scatter()所绘制的散列图却可以指定每个点的颜色和大小。
scatter()的前两个参数是数组,分别指定每个点的X轴和Y轴的坐标。
s参数指定点的大 小,值和点的面积成正比。它可以是一个数,指定所有点的大小;也可以是数组,分别对每个点指定大小。
c参数指定每个点的颜色,可以是数值或数组。这里使用一维数组为每个点指定了一个数值。通过颜色映射表,每个数值都会与一个颜色相对应。默认的颜色映射表中蓝色与最小值对应,红色与最大值对应。当c参数是形状为(N,3)或(N,4)的二维数组时,则直接表示每个点的RGB颜色。
marker参数设置点的形状,可以是个表示形状的字符串,也可以是表示多边形的两个元素的元组,第一个元素表示多边形的边数,第二个元素表示多边形的样式,取值范围为0、1、2、3。0表示多边形,1表示星形,2表示放射形,3表示忽略边数而显示为圆形。
alpha参数设置点的透明度。
lw参数设置线宽,lw是line width的缩写。
facecolors参数为“none”时,表示散列点没有填充色。
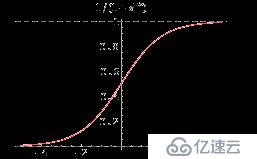
4、Sigmoid函数是一个在生物学中常见的S型的函数,也称为S型生长曲线。
sigmoid函数是一个良好的阈值函数,连续,光滑,严格单调,关于(0,0.5)中心对称。
 http://blog.csdn.net/chl033/article/details/4851541
http://blog.csdn.net/chl033/article/details/4851541
5、读取 .csv 文件
#读取 .csv 文件练习
import csv
csvfile = file('csv_test.csv', 'wb')
writer = csv.writer(csvfile)
writer.writerow(['姓名', '年龄', '电话'])
data = [
('小河', '25', '1234567'),
('小芳', '18', '789456')
]
writer.writerows(data)
#csvfile.close()
csvfile = file('csv_test.csv', 'rb')
reader = csv.reader(csvfile)
for line in reader:
print line
csvfile.close()
['\xe5\xa7\x93\xe5\x90\x8d', '\xe5\xb9\xb4\xe9\xbe\x84', '\xe7\x94\xb5\xe8\xaf\x9d']
['\xe5\xb0\x8f\xe6\xb2\xb3', '25', '1234567']
['\xe5\xb0\x8f\xe8\x8a\xb3', '18', '789456']6、train_test_split(分割train与test数据)函数练习
>>> import numpy as np >>> from sklearn.model_selection import train_test_split >>> X, y = np.arange(10).reshape((5, 2)), range(5) >>> Xarray([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]]) >>> list(y) [0, 1, 2, 3, 4] >>> >>> X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.33, random_state=42) >>> X_train array([[4, 5], [0, 1], [6, 7]]) >>> y_train [2, 0, 3] >>> X_test array([[2, 3], [8, 9]]) >>> y_test [1, 4]
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。