
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іgoиҜӯиЁҖдёӯеһғеңҫеӣһ收жңәеҲ¶зҡ„еҺҹзҗҶжҳҜд»Җд№ҲпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
еҶ…еӯҳз®ЎзҗҶпјҡеҶ…еӯҳз®ЎзҗҶеҜ№дәҺзј–зЁӢиҜӯиЁҖиҮіе…ійҮҚиҰҒгҖӮжұҮзј–е…Ғи®ёдҪ ж“ҚдҪңжүҖжңүдёңиҘҝпјҢжҲ–иҖ…иҜҙиҰҒжұӮдҪ еҝ…йЎ»е…ЁжқғеӨ„зҗҶжүҖжңүз»ҶиҠӮжӣҙеҗҲйҖӮгҖӮC иҜӯиЁҖдёӯиҷҪ然ж ҮеҮҶеә“еҮҪж•°жҸҗдҫӣдёҖдәӣеҶ…еӯҳз®ЎзҗҶж”ҜжҢҒпјҢдҪҶжҳҜеҜ№дәҺд№ӢеүҚи°ғз”Ё malloc з”іиҜ·зҡ„еҶ…еӯҳпјҢиҝҳжҳҜдҫқиө–дәҺдҪ дәІиҮӘ free жҺүгҖӮд»ҺC++гҖҒPythonгҖҒSwift е’Ң Java ејҖе§ӢпјҢжүҚеңЁдёҚеҗҢзЁӢеәҰдёҠж”ҜжҢҒеҶ…еӯҳз®ЎзҗҶгҖӮ
еҶ…еӯҳеҺӢзј©пјҡеҜ№еҶ…еӯҳзўҺзүҮиҝӣиЎҢеҺӢзј©гҖӮпјҲе’Ңwin10зҡ„йӮЈдёӘвҖңеҶ…еӯҳеҺӢзј©вҖқдёҚеӨӘдёҖж ·е•Ұпјү
win10еҶ…еӯҳеҺӢзј©пјҡзү©зҗҶеҶ…еӯҳе·Із»Ҹи§Ғеә•пјҢе°ҶдёҖйғЁеҲҶдёҚеёёдҪҝз”Ёзҡ„еҶ…еӯҳж•°жҚ®жү“еҢ…еҺӢзј©иө·жқҘпјҢзӯүеҲ°жңүзЁӢеәҸйңҖиҰҒи®ҝй—®йӮЈдәӣж•°жҚ®зҡ„ж—¶еҖҷпјҢеҶҚи§ЈеҺӢзј©еҮәжқҘгҖӮ
еј•з”ЁдёҺжҢҮй’Ҳпјҡ
иҝҷжҳҜйқһеёёжңүе®ізҡ„пјҢжҜ«ж— з–‘й—®гҖӮз»“жһңе°ҶжҳҜдёҚзЎ®е®ҡзҡ„пјҲзј–иҜ‘еҷЁиғҪдә§з”ҹдёҖдәӣиҫ“еҮәпјҢеҜјиҮҙд»»дҪ•дәӢжғ…йғҪжңүеҸҜиғҪеҸ‘з”ҹпјүпјҢеә”иҜҘиәІејҖеҶҷеҮәиҝҷж ·д»Јз Ғзҡ„дәәйҷӨйқһ他们еҗҢж„Ҹж”№жӯЈй”ҷиҜҜгҖӮеҰӮжһңдҪ жӢ…еҝғиҝҷж ·зҡ„д»Јз ҒдјҡеҮәзҺ°еңЁдҪ зҡ„иҪҜ件йҮҢпјҢйӮЈд№ҲдҪ жңҖеҘҪе®Ңе…ЁйҒҝе…ҚдҪҝз”Ёеј•з”ЁпјҢиҰҒдёҚ然е°ұеҺ»и®©жӣҙдјҳз§Җзҡ„зЁӢеәҸе‘ҳеҺ»еҒҡгҖӮ
жңҖеҗҺдёҠйҷ„еӣҫпјҢеё®еҠ©зҗҶи§Ј
еј•з”Ёиў«еҲӣе»әзҡ„еҗҢж—¶еҝ…йЎ»иў«еҲқе§ӢеҢ–пјҲжҢҮй’ҲеҲҷеҸҜд»ҘеңЁд»»дҪ•ж—¶еҖҷиў«еҲқе§ӢеҢ–пјүгҖӮ
дёҚиғҪжңүNULL еј•з”ЁпјҢеј•з”Ёеҝ…йЎ»дёҺеҗҲжі•зҡ„еӯҳеӮЁеҚ•е…ғе…іиҒ”пјҲжҢҮй’ҲеҲҷеҸҜд»ҘжҳҜNULLпјүгҖӮ
дёҖж—Ұеј•з”Ёиў«еҲқе§ӢеҢ–пјҢе°ұдёҚиғҪж”№еҸҳеј•з”Ёзҡ„е…ізі»пјҲжҢҮй’ҲеҲҷеҸҜд»ҘйҡҸж—¶ж”№еҸҳжүҖжҢҮзҡ„еҜ№иұЎпјүгҖӮ
еј•з”ЁеҸӘжҳҜжҹҗеқ—еҶ…еӯҳзҡ„еҲ«еҗҚгҖӮ
е®һйҷ…дёҠвҖңеј•з”ЁвҖқеҸҜд»ҘеҒҡзҡ„д»»дҪ•дәӢжғ…вҖңжҢҮй’ҲвҖқд№ҹйғҪиғҪеӨҹеҒҡпјҢдёәд»Җд№ҲиҝҳиҰҒвҖңеј•з”ЁвҖқ иҝҷдёңиҘҝпјҹ зӯ”жЎҲжҳҜвҖңз”ЁйҖӮеҪ“зҡ„е·Ҙе…·еҒҡжҒ°еҰӮе…¶еҲҶзҡ„е·ҘдҪңвҖқгҖӮжҜ”еҰӮиҜҙпјҢжҹҗдәәйңҖиҰҒдёҖд»ҪиҜҒжҳҺпјҢжң¬жқҘеңЁж–Ү件дёҠзӣ– дёҠе…¬з« зҡ„еҚ°еӯҗе°ұиЎҢдәҶпјҢеҰӮжһңжҠҠеҸ–е…¬з« зҡ„й’ҘеҢҷдәӨз»ҷд»–пјҢйӮЈд№Ҳд»–е°ұиҺ·еҫ—дәҶдёҚиҜҘжңүзҡ„жқғеҲ©гҖӮпјҲд»Җд№Ҳжғ…еҶөдёӢпјҢе°ұз”Ёд»Җд№ҲеҜ№зӯ–пјү
дёәд»Җд№ҲиҝҳиҰҒиҜҙвҖңеҸӘжңүжҢҮй’ҲпјҢжІЎжңүеј•з”ЁжҳҜдёҖдёӘйҮҚиҰҒж”№еҸҳпјҹвҖқпјҹзӯ”жЎҲжҳҜиҷҪ然引用еңЁжҹҗдәӣжғ…еҶөдёӢеҘҪз”ЁпјҢдҪҶд»–д№ҹдјҡеҜјиҮҙиҮҙе‘Ҫй”ҷиҜҜгҖӮеҰӮдёӢпјҡ
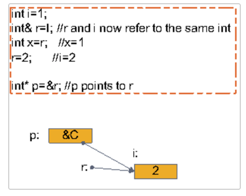
char *pc = 0; // и®ҫзҪ®жҢҮй’Ҳдёәз©әеҖј char& rc = *pc; // и®©еј•з”ЁжҢҮеҗ‘з©әеҖј
е ҶпјҲheapпјүе’Ңж ҲпјҲstackпјү
е№іеёёиҜҙзҡ„вҖңе Ҷж ҲвҖқе…¶е®һжҳҜж ҲгҖӮ
ж ҲпјҢе°ұжҳҜйӮЈдәӣз”ұзј–иҜ‘еҷЁеңЁйңҖиҰҒзҡ„ж—¶еҖҷеҲҶй…ҚпјҢеңЁдёҚйңҖиҰҒзҡ„ж—¶еҖҷиҮӘеҠЁжё…йҷӨзҡ„еҸҳйҮҸзҡ„еӯҳеӮЁеҢәгҖӮйҮҢйқўзҡ„еҸҳйҮҸйҖҡеёёжҳҜеұҖйғЁеҸҳйҮҸгҖҒеҮҪж•°еҸӮж•°зӯүгҖӮ
е ҶпјҢе°ұжҳҜйӮЈдәӣз”ұnewеҲҶй…Қзҡ„еҶ…еӯҳеқ—пјҢ他们зҡ„йҮҠж”ҫзј–иҜ‘еҷЁдёҚеҺ»з®ЎпјҢз”ұжҲ‘们зҡ„еә”з”ЁзЁӢеәҸеҺ»жҺ§ еҲ¶пјҢдёҖиҲ¬дёҖдёӘnewе°ұиҰҒеҜ№еә”дёҖдёӘdeleteгҖӮеҰӮжһңзЁӢеәҸе‘ҳжІЎжңүйҮҠж”ҫжҺүпјҢйӮЈд№ҲеңЁзЁӢеәҸз»“жқҹеҗҺпјҢж“ҚдҪңзі»з»ҹдјҡиҮӘеҠЁеӣһ收гҖӮ
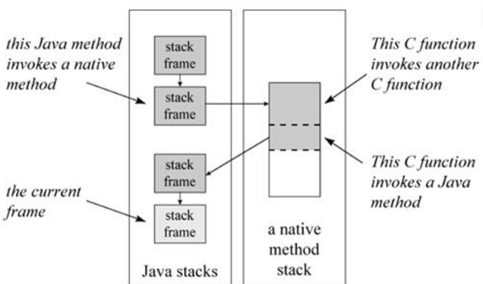
зЁӢеәҸзҡ„ж Ҳз»“жһ„2.дёҙж—¶еҸҳйҮҸпјҡеҢ…жӢ¬еҮҪж•°зҡ„йқһйқҷжҖҒеұҖйғЁеҸҳйҮҸд»ҘеҸҠзј–иҜ‘еҷЁиҮӘеҠЁз”ҹжҲҗзҡ„е…¶е®ғдёҙж—¶еҸҳйҮҸ 3.дҝқеӯҳзҡ„дёҠдёӢж–ҮпјҡеҢ…жӢ¬еңЁеҮҪж•°и°ғз”ЁеүҚеҗҺйңҖиҰҒдҝқеӯҳдёҚеҸҳзҡ„еҜ„еӯҳеҷЁеҖј1.иҝ”еӣһең°еқҖ:дёҖдёӘmainеҮҪж•°дёӯж–ӯжү§иЎҢзҡ„жү§иЎҢзӮ№. 2.ebp:жҢҮеҗ‘еҮҪж•°жҙ»еҠЁи®°еҪ•зҡ„дёҖдёӘеӣәе®ҡдҪҚзҪ®пјҢebpеҸҲиў«з§°дёәеё§жҢҮй’Ҳ.еӣәе®ҡдҪҚзҪ®жҳҜпјҢиҝҷж ·еңЁеҮҪж•°иҝ”еӣһзҡ„ж—¶еҖҷпјҢebpе°ұеҸҜд»ҘйҖҡиҝҮиҝҷдёӘжҒўеӨҚеҲ°и°ғз”ЁеүҚзҡ„еҖјгҖӮ 3.espе§Ӣз»ҲжҢҮеҗ‘ж ҲйЎ¶пјҢеӣ жӯӨйҡҸзқҖеҮҪж•°зҡ„жү§иЎҢпјҢе®ғжҖ»жҳҜеҸҳеҢ–зҡ„гҖӮ 4.е…Ҙж ҲйЎәеәҸпјҡе…ҲеҺӢжӯӨж¬Ўи°ғз”ЁеҮҪж•°еҸӮж•°е…Ҙж ҲпјҢжҺҘзқҖжҳҜmainеҮҪж•°иҝ”еӣһең°еқҖпјҢ然еҗҺжҳҜebpзӯүеҜ„еӯҳеҷЁгҖӮ
LinkпјҡCзЁӢеәҸзҡ„еҮҪж•°ж ҲдҪңз”ЁжңәзҗҶпјҲиҝҷдёӘи®Іеҫ—еҘҪпјҢжңүе®һдҫӢпјҢжүҖд»ҘдёҚеҶҚзҶ¬иҝ°пјү
е°ұжҳҜе®ғпјҢе…ҲдёҠеӣҫ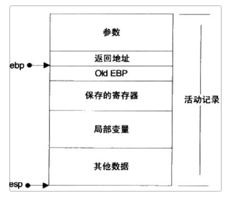
зЁӢеәҸзҡ„ең°еқҖз©әй—ҙеёғеұҖпјҡ зЁӢеәҸиҝҗиЎҢйқ еӣӣдёӘдёңиҘҝпјҡд»Јз ҒгҖҒж ҲгҖҒе ҶгҖҒж•°жҚ®ж®өгҖӮд»Јз Ғж®өдё»иҰҒеӯҳж”ҫзҡ„е°ұжҳҜеҸҜжү§иЎҢж–Ү件(йҖҡеёёеҸҜжү§иЎҢж–Ү件еҶ…пјҢеҗ«жңүд»ҘдәҢиҝӣеҲ¶зј–з Ғзҡ„еҫ®еӨ„зҗҶеҷЁжҢҮд»ӨпјҢд№ҹеӣ жӯӨеҸҜжү§иЎҢж–Ү件жңүж—¶з§°дёәдәҢиҝӣеҲ¶ж–Ү件)дёӯзҡ„д»Јз Ғпјӣж•°жҚ®ж®өеӯҳж”ҫзҡ„е°ұжҳҜзЁӢеәҸдёӯе…ЁеұҖеҸҳйҮҸе’ҢйқҷжҖҒеҸҳйҮҸпјӣе ҶдёӯжҳҜзЁӢеәҸзҡ„еҠЁжҖҒеҶ…еӯҳеҢәеҹҹпјҢеҪ“зЁӢеәҸдҪҝз”ЁmallocжҲ–newеҫ—еҲ°зҡ„еҶ…еӯҳжҳҜжқҘиҮӘе Ҷзҡ„пјӣж Ҳдёӯз»ҙжҠӨзҡ„жҳҜеҮҪж•°и°ғз”Ёзҡ„дёҠдёӢж–ҮпјҢзҰ»ејҖдәҶж Ҳе°ұдёҚеҸҜиғҪе®һзҺ°еҮҪж•°зҡ„и°ғз”ЁгҖӮ
ж Ҳеё§пјҡ д№ҹеҸ«жҙ»еҠЁи®°еҪ•пјҢдҝқеӯҳзҡ„жҳҜдёҖдёӘеҮҪж•°и°ғз”ЁжүҖйңҖиҰҒз»ҙжҠӨзҡ„жүҖжңүдҝЎжҒҜгҖӮеҰӮдёӢпјҡ 1.еҮҪж•°зҡ„иҝ”еӣһең°еқҖе’ҢеҸӮж•°
иҝҷйҮҢжҲ‘们еҜ№жҜ”дәҶи§ЈдёҚеҗҢзҡ„ вҖңжүҫеҲ°йңҖиҰҒж Үи®°зҡ„еҜ№иұЎвҖқзҡ„ж–№жі•
еј•з”Ёи®Ўж•°жі•
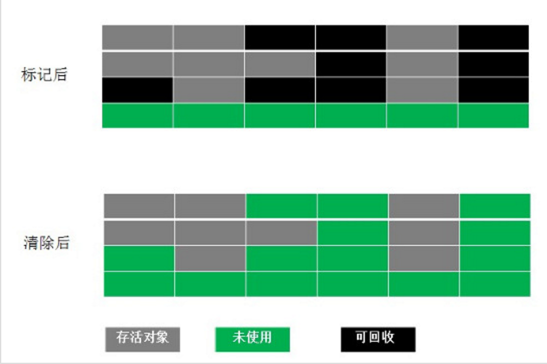
з»ҷеҜ№иұЎдёӯж·»еҠ дёҖдёӘеј•з”Ёи®Ўж•°еҷЁпјҢжҜҸеҪ“жңүдёҖдёӘең°ж–№еј•з”Ёе®ғж—¶пјҢи®Ўж•°еҷЁеҖје°ұеҠ 1пјӣеҪ“еј•з”ЁеӨұж•Ҳж—¶пјҢ и®Ўж•°еҷЁеҖје°ұеҮҸ1пјӣд»»дҪ•ж—¶еҲ»и®Ўж•°еҷЁдёә0зҡ„еҜ№иұЎе°ұжҳҜдёҚеҸҜиғҪеҶҚиў«дҪҝз”Ёзҡ„гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
дјҳзӮ№пјҡ引用计数收йӣҶеҷЁеҸҜд»ҘеҫҲеҝ«ең°жү§иЎҢпјҢдәӨз»ҮеңЁзЁӢеәҸзҡ„иҝҗиЎҢд№ӢдёӯгҖӮиҝҷдёӘзү№жҖ§еҜ№дәҺзЁӢеәҸдёҚиғҪиў«й•ҝж—¶й—ҙжү“ж–ӯзҡ„е®һж—¶зҺҜеўғеҫҲжңүеҲ©гҖӮ зјәзӮ№пјҡеҫҲйҡҫеӨ„зҗҶеҫӘзҺҜеј•з”ЁпјҢжҜ”еҰӮеӣҫдёӯзӣёдә’еј•з”Ёзҡ„дёӨдёӘеҜ№иұЎеҲҷж— жі•йҮҠж”ҫгҖӮ еә”з”ЁпјҡPython е’Ң Swift йҮҮз”Ёеј•з”Ёи®Ўж•°ж–№жЎҲгҖӮ
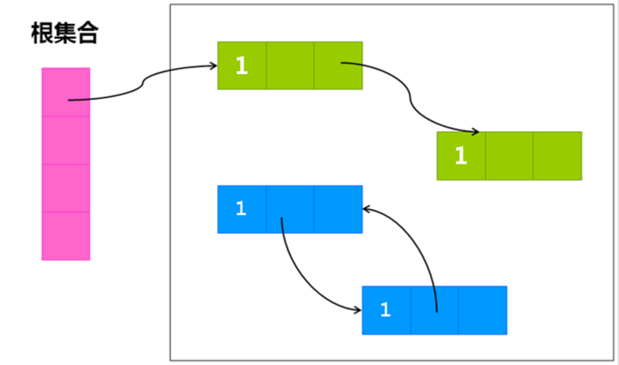
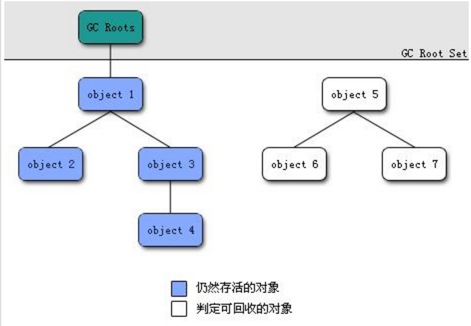
еҸҜиҫҫжҖ§еҲҶжһҗз®—жі•пјҲж №жҗңзҙўз®—жі•пјү
д»ҺGC RootsпјҲжҜҸз§Қе…·дҪ“е®һзҺ°еҜ№GC RootsжңүдёҚеҗҢзҡ„е®ҡд№үпјүдҪңдёәиө·зӮ№пјҢеҗ‘дёӢжҗңзҙўе®ғ们引用зҡ„еҜ№иұЎпјҢеҸҜд»Ҙз”ҹжҲҗдёҖжЈөеј•з”Ёж ‘пјҢж ‘зҡ„иҠӮзӮ№и§ҶдёәеҸҜиҫҫеҜ№иұЎпјҢеҸҚд№Ӣи§ҶдёәдёҚеҸҜиҫҫгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
жҺҘдёӢжқҘиЎҘе……еҮ дёӘжҰӮеҝөеё®еҠ©зҗҶи§ЈпјҲд»ҘjavaдёәдҫӢпјүпјҡ
GC RootsеҜ№иұЎпјҡ
иҷҡжӢҹжңәж ҲпјҲеё§ж Ҳдёӯзҡ„жң¬ең°еҸҳйҮҸиЎЁпјүдёӯеј•з”Ёзҡ„еҜ№иұЎгҖӮ ж–№жі•еҢәдёӯйқҷжҖҒеұһжҖ§еј•з”Ёзҡ„еҜ№иұЎгҖӮ ж–№жі•еҢәдёӯеёёйҮҸеј•з”Ёзҡ„еҜ№иұЎгҖӮ жң¬ең°ж–№жі•ж ҲдёӯJNIеј•з”Ёзҡ„еҜ№иұЎгҖӮ жң¬ең°ж–№жі•ж ҲеҲҷдёәиҷҡжӢҹжңәжүҖдҪҝз”Ёзҡ„Nativeж–№жі•жңҚеҠЎгҖӮ Nativeж–№жі•жҳҜжҢҮжң¬ең°ж–№жі•пјҢеҪ“еңЁж–№жі•дёӯи°ғз”ЁдёҖдәӣдёҚжҳҜз”ұjavaиҜӯиЁҖеҶҷзҡ„д»Јз ҒжҲ–иҖ…еңЁж–№жі•дёӯз”ЁjavaиҜӯиЁҖзӣҙжҺҘж“Қзәөи®Ўз®—жңә硬件гҖӮ JNIпјҡJava Native Interfaceзј©еҶҷпјҢе…Ғи®ёJavaд»Јз Ғе’Ңе…¶д»–иҜӯиЁҖеҶҷзҡ„д»Јз ҒиҝӣиЎҢдәӨдә’гҖӮ
дёҠиҝ°еҰӮеӣҫпјҢе…ідәҺrootеҢәеҹҹзҡ„иҜҰз»Ҷи§ЈйҮҠеҸӮиҖғиҝҷйҮҢ
иҝҷйҮҢжҲ‘们д»Ӣз»ҚеҮ з§ҚдёҚеҗҢзҡ„ вҖңж Үи®°еҜ№иұЎвҖқзҡ„ж–№жі•
дҝқе®Ҳжі•е°ҶжүҖжңүе ҶдёҠеҜ№йҪҗзҡ„еӯ—йғҪи®ӨдёәжҳҜжҢҮй’ҲпјҢйӮЈд№Ҳжңүдәӣж•°жҚ®е°ұдјҡиў«иҜҜи®ӨдёәжҳҜжҢҮй’ҲгҖӮдәҺжҳҜжҹҗдәӣе®һйҷ…жҳҜж•°еӯ—зҡ„еҒҮжҢҮй’ҲпјҢдјҡиғҢиҜҜи®ӨдёәжҢҮеҗ‘жҙ»и·ғеҜ№иұЎпјҢеҜјиҮҙеҶ…еӯҳжі„йңІпјҲеҒҮжҢҮй’ҲжҢҮеҗ‘зҡ„еҜ№иұЎеҸҜиғҪжҳҜжӯ»еҜ№иұЎпјҢдҪҶдҫқж—§жңүжҢҮй’ҲжҢҮеҗ‘вҖ”вҖ”иҝҷдёӘеҒҮжҢҮй’ҲжҢҮеҗ‘е®ғпјүеҗҢж—¶жҲ‘们дёҚиғҪ移еҠЁд»»дҪ•еҶ…еӯҳеҢәеҹҹгҖӮ
зј–иҜ‘еҷЁжҸҗзӨәжі•еҰӮжһңжҳҜйқҷжҖҒиҜӯиЁҖпјҢзј–иҜ‘еҷЁиғҪеӨҹе‘ҠиҜүжҲ‘们жҜҸдёӘзұ»еҪ“дёӯжҢҮй’Ҳзҡ„е…·дҪ“дҪҚзҪ®пјҢиҖҢдёҖж—ҰжҲ‘们зҹҘйҒ“еҜ№иұЎж—¶е“ӘдёӘзұ»е®һдҫӢеҢ–еҫ—еҲ°зҡ„пјҢе°ұиғҪзҹҘйҒ“еҜ№иұЎдёӯжүҖжңүжҢҮй’ҲгҖӮиҝҷжҳҜJVMе®һзҺ°еһғеңҫеӣһ收зҡ„ж–№ејҸпјҢдҪҶиҝҷз§Қж–№ејҸ并дёҚйҖӮеҗҲJSиҝҷж ·зҡ„еҠЁжҖҒиҜӯиЁҖ
ж Үи®°жҢҮй’Ҳжі•ж Үи®°жҢҮй’Ҳжі•пјҡиҝҷз§Қж–№жі•йңҖиҰҒеңЁжҜҸдёӘеӯ—жң«дҪҚйў„з•ҷдёҖдҪҚжқҘж Үи®°иҝҷдёӘеӯ—ж®өжҳҜжҢҮй’ҲиҝҳжҳҜж•°жҚ®гҖӮиҝҷз§Қж–№жі•йңҖиҰҒзј–иҜ‘еҷЁж”ҜжҢҒпјҢдҪҶе®һзҺ°з®ҖеҚ•пјҢиҖҢдё”жҖ§иғҪдёҚй”ҷгҖӮV8йҮҮз”Ёзҡ„жҳҜиҝҷз§Қж–№ејҸгҖӮ
дҪҚеӣҫж Үи®°(GoиҜӯиЁҖдёәдҫӢ)
йқһдҫөе…ҘејҸж Үи®°дҪҚе®ҡд№ү
既然еһғеңҫеӣһ收算法иҰҒжұӮз»ҷеҜ№иұЎеҠ дёҠеһғеңҫеӣһ收зҡ„ж Үи®°пјҢжҳҫ然жҳҜйңҖиҰҒжңүж Үи®°дҪҚзҡ„гҖӮдёҖиҲ¬зҡ„еҒҡжі•
дјҡе°ҶеҜ№иұЎз»“жһ„дҪ“дёӯеҠ дёҠдёҖдёӘж Үи®°еҹҹпјҢдёҖдәӣдјҳеҢ–зҡ„еҒҡжі•дјҡеҲ©з”ЁеҜ№иұЎжҢҮй’Ҳзҡ„дҪҺдҪҚиҝӣиЎҢж Үи®°пјҢиҝҷ
йғҪеҸӘжҳҜдәӣеҘҮжҠҖж·«е·§зҪўдәҶгҖӮGoжІЎжңүиҝҷд№ҲеҒҡпјҢе®ғзҡ„еҜ№иұЎе’ҢCзҡ„з»“жһ„дҪ“еҜ№иұЎе®Ңе…ЁдёҖиҮҙпјҢдҪҝз”Ёзҡ„жҳҜ
йқһдҫөе…ҘејҸзҡ„ж Үи®°дҪҚгҖӮ
е…·дҪ“е®һзҺ°
е ҶеҢәеҹҹеҜ№еә”дәҶдёҖдёӘж Үи®°дҪҚеӣҫеҢәеҹҹпјҢе ҶдёӯжҜҸдёӘеӯ—(дёҚжҳҜbyteпјҢиҖҢжҳҜword)йғҪдјҡеңЁж Үи®°дҪҚеҢәеҹҹ
дёӯжңүеҜ№еә”зҡ„ж Үи®°дҪҚгҖӮжҜҸдёӘжңәеҷЁеӯ—(32дҪҚжҲ–64дҪҚ)дјҡеҜ№еә”4дҪҚзҡ„ж Үи®°дҪҚгҖӮеӣ жӯӨпјҢ64дҪҚзі»з»ҹдёӯ
зӣёеҪ“дәҺжҜҸдёӘж Үи®°дҪҚеӣҫзҡ„еӯ—иҠӮеҜ№еә”16дёӘе Ҷдёӯзҡ„еӯ—иҠӮгҖӮ
иҷҪ然жҳҜдёҖдёӘе Ҷеӯ—иҠӮеҜ№еә”4дҪҚж Үи®°дҪҚпјҢдҪҶж Үи®°дҪҚеӣҫеҢәеҹҹзҡ„еҶ…еӯҳеёғеұҖ并дёҚжҳҜжҢү4дҪҚдёҖз»„пјҢиҖҢжҳҜ
16дёӘе Ҷеӯ—иҠӮдёәдёҖз»„пјҢе°Ҷе®ғ们зҡ„ж Үи®°дҪҚдҝЎжҒҜжү“еҢ…еӯҳеӮЁзҡ„гҖӮжҜҸз»„64дҪҚзҡ„ж Үи®°дҪҚеӣҫд»ҺдёҠеҲ°дёӢдҫқ
ж¬ЎеҢ…жӢ¬пјҡ
16дҪҚзҡ„ зү№ж®ҠдҪҚ ж Үи®°дҪҚ 16дҪҚзҡ„ еһғеңҫеӣһ收 ж Үи®°дҪҚ 16дҪҚзҡ„ ж— жҢҮй’Ҳ/еқ—иҫ№з•Ң зҡ„ж Үи®°дҪҚ 16дҪҚзҡ„ е·ІеҲҶй…Қ ж Үи®°дҪҚ
иҝҷж ·и®ҫи®ЎдҪҝеҫ—еҜ№дёҖдёӘзұ»еһӢзҡ„зӣёеә”зҡ„дҪҚиҝӣиЎҢйҒҚеҺҶеҫҲе®№жҳ“гҖӮ
еүҚйқўжҸҗеҲ°е ҶеҢәеҹҹе’Ңе Ҷең°еқҖзҡ„ж Үи®°дҪҚеӣҫеҢәеҹҹжҳҜеҲҶејҖеӯҳеӮЁзҡ„пјҢе…¶е®һе®ғ们жҳҜд»Ҙ
mheap.arena_startең°еқҖдёәиҫ№з•ҢпјҢеҗ‘дёҠжҳҜе®һйҷ…дҪҝз”Ёзҡ„е Ҷең°еқҖз©әй—ҙпјҢеҗ‘дёӢеҲҷжҳҜж Үи®°дҪҚеӣҫеҢә
еҹҹгҖӮд»Ҙ64дҪҚзі»з»ҹдёәдҫӢпјҢи®Ўз®—е ҶдёӯжҹҗдёӘең°еқҖзҡ„ж Үи®°дҪҚзҡ„е…¬ејҸеҰӮдёӢпјҡ
еҒҸ移 = ең°еқҖ - mheap.arena_start ж Үи®°дҪҚең°еқҖ = mheap.arena_start - еҒҸ移/16 - 1移дҪҚ = еҒҸ移 % 16ж Үи®°дҪҚ = *ж Үи®°дҪҚең°еқҖ >> 移дҪҚ
然еҗҺе°ұеҸҜд»ҘйҖҡиҝҮ (ж Үи®°дҪҚ & еһғеңҫеӣһ收ж Үи®°дҪҚ),(ж Үи®°дҪҚ & еҲҶй…ҚдҪҚ),зӯүжқҘжөӢиҜ•зӣёеә”зҡ„дҪҚгҖӮ
(д№ҹе°ұжҳҜиҜҙпјҢжң¬жқҘ64дҪҚжҳҜдёҖдёӘеӯ—пјҢйңҖиҰҒ4дҪҚж Үи®°дҪҚгҖӮдҪҶжҳҜпјҢдёәдәҶдёҺеӯ—й•ҝзӣёеҜ№пјҢ16дёӘж Үи®°дҪҚ
ж”ҫдёҖиө·пјҲеҲҡеҘҪдёҖдёӘеӯ—й•ҝпјүдёҖиө·иЎЁзӨә16дёӘеӯ—гҖӮ并且жҜҸзұ»ж Үи®°дҪҚйғҪж”ҫеңЁдёҖиө·
AA..AABB...BB)
жҺҘдёӢжқҘиЎҘе……еҮ дёӘжҰӮеҝөеё®еҠ©зҗҶи§Јпјҡ
дёәд»Җд№ҲиҰҒеҲӨж–ӯе“ӘдәӣжҳҜж•°жҚ®пјҢе“ӘдәӣжҳҜжҢҮй’Ҳпјҹ
еҒҮи®ҫе ҶдёӯжңүдёҖдёӘlongзҡ„еҸҳйҮҸпјҢе®ғзҡ„еҖјжҳҜ8860225560гҖӮдҪҶжҳҜжҲ‘们дёҚзҹҘйҒ“е®ғзҡ„зұ»еһӢжҳҜ
longпјҢжүҖд»ҘеңЁиҝӣиЎҢеһғеңҫеӣһ收时дјҡжҠҠдёӘеҪ“дҪңжҢҮй’ҲеӨ„зҗҶпјҢиҝҷдёӘжҢҮй’Ҳеј•з”ЁеҲ°дәҶ0x2101c5018дҪҚ
зҪ®гҖӮеҒҮи®ҫ0x2101c5018зў°е·§жңүжҹҗдёӘеҜ№иұЎпјҢйӮЈд№ҲиҝҷдёӘеҜ№иұЎе°ұж— жі•иў«йҮҠж”ҫдәҶпјҢеҚідҪҝе®һйҷ…дёҠе·І
з»ҸжІЎд»»дҪ•ең°ж–№дҪҝз”Ёе®ғгҖӮ
з”ұдәҺжІЎжңүзұ»еһӢдҝЎжҒҜпјҢжҲ‘们并дёҚзҹҘйҒ“иҝҷдёӘз»“жһ„дҪ“жҲҗе‘ҳдёҚеҢ…еҗ«жҢҮй’ҲпјҢеӣ жӯӨжҲ‘们еҸӘиғҪеҜ№з»“жһ„дҪ“
зҡ„жҜҸдёӘеӯ—иҠӮйҖ’еҪ’ең°ж Үи®°дёӢеҺ»пјҢиҝҷжҳҫ然дјҡжөӘиҙ№еҫҲеӨҡж—¶й—ҙгҖӮ
пјҲиғҪдёҚиғҪжё…йҷӨ еҸҳжҲҗдәҶжҰӮзҺҮдәӢ件пјүгҖӮ
еһғеңҫ收йӣҶеҷЁпјҲCMS收йӣҶеҷЁдёәдҫӢпјү еҮ дёӘйҳ¶ж®өпјҡ
еҲқе§Ӣж Үи®°
并еҸ‘ж Үи®°
жңҖз»Ҳж Үи®°
зӯӣйҖүеӣһ收
еҲқе§Ӣж Үи®°д»…д»…жҳҜж Үи®°дёҖдёӢGC RootsиғҪзӣҙжҺҘе…іиҒ”еҲ°зҡ„еҜ№иұЎпјҢйҖҹеәҰеҫҲеҝ«пјҢ并еҸ‘ж Үи®°е°ұжҳҜиҝӣиЎҢ
GC Roots Trancingзҡ„иҝҮзЁӢпјҢиҖҢйҮҚж–°ж Үи®°йҳ¶ж®өеҲҷжҳҜдёәдәҶдҝ®жӯЈе№¶еҸ‘ж Үи®°жңҹй—ҙеӣ з”ЁжҲ·зЁӢеәҸ继
з»ӯиҝҗиЎҢиҖҢеҜјиҮҙж Үи®°дә§з”ҹеҸҳеҠЁйӮЈдёҖйғЁеҲҶеҜ№иұЎзҡ„ж Үи®°и®°еҪ•пјҢиҝҷдёӘйҳ¶ж®өзҡ„еҒңйЎҝж—¶й—ҙжҜ”еҲқе§Ӣж Үи®°зЁҚ
й•ҝдёҖдәӣпјҢдҪҶиҝңжҜ”并еҸ‘ж Үи®°ж—¶й—ҙзҹӯгҖӮ
stop the world
еӣ дёәеһғеңҫеӣһ收зҡ„ж—¶еҖҷпјҢйңҖиҰҒж•ҙдёӘзҡ„еј•з”ЁзҠ¶жҖҒдҝқжҢҒдёҚеҸҳпјҢеҗҰеҲҷеҲӨе®ҡжҳҜеһғеңҫпјҢзӯүжҲ‘зЁҚеҗҺеӣһ
收зҡ„ж—¶еҖҷе®ғеҸҲиў«еј•з”ЁдәҶпјҢиҝҷе°ұе…Ёд№ұеҘ—дәҶгҖӮжүҖд»ҘпјҢGCзҡ„ж—¶еҖҷпјҢе…¶д»–жүҖжңүзҡ„зЁӢеәҸжү§иЎҢеӨ„дәҺжҡӮеҒң
зҠ¶жҖҒпјҢеҚЎдҪҸдәҶгҖӮ
иҝҷдёӘжҰӮеҝөжҸҗеүҚеј•е…ҘпјҢеңЁиҝҷйҮҢиҝӣиЎҢеҜ№жҜ”пјҢж•ҲжһңдјҡжӣҙеҘҪдәӣгҖӮдёҺж Үи®°йҳ¶ж®өеҜ№жҜ”пјҢstop the worldеҸ‘з”ҹеңЁеӣһ收йҳ¶ж®өгҖӮ
иҝҷйҮҢжҲ‘们д»Ӣз»ҚеҮ з§ҚдёҚеҗҢзҡ„еһғеңҫеӣһ收算法
ж Үи®°жё…йҷӨз®—жі• (Mark-Sweep)
ж Үи®°-жё…йҷӨз®—жі•еҲҶдёәдёӨдёӘйҳ¶ж®өпјҡж Үи®°йҳ¶ж®өе’Ңжё…йҷӨйҳ¶ж®өгҖӮж Үи®°йҳ¶ж®өзҡ„д»»еҠЎжҳҜж Үи®°еҮәжүҖжңүйңҖиҰҒиў«еӣһ收зҡ„еҜ№иұЎпјҢжё…йҷӨйҳ¶ж®өе°ұжҳҜеӣһ收被ж Үи®°зҡ„еҜ№иұЎжүҖеҚ з”Ёзҡ„з©әй—ҙгҖӮ
дјҳзӮ№жҳҜз®ҖеҚ•пјҢе®№жҳ“е®һзҺ°гҖӮзјәзӮ№жҳҜе®№жҳ“дә§з”ҹеҶ…еӯҳзўҺзүҮпјҢзўҺзүҮеӨӘеӨҡеҸҜиғҪдјҡеҜјиҮҙеҗҺз»ӯиҝҮзЁӢдёӯйңҖиҰҒдёәеӨ§еҜ№иұЎеҲҶй…Қз©әй—ҙж—¶ж— жі•жүҫеҲ°и¶іеӨҹзҡ„з©әй—ҙиҖҢжҸҗеүҚи§ҰеҸ‘ж–°зҡ„дёҖж¬Ўеһғеңҫ收йӣҶеҠЁдҪңгҖӮпјҲеӣ дёәжІЎжңүеҜ№дёҚеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎйҮҮз”ЁдёҚеҗҢз®—жі•пјҢжүҖд»ҘзўҺзүҮеӨҡпјҢеҶ…еӯҳе®№жҳ“ж»ЎпјҢgcйў‘зҺҮй«ҳпјҢиҖ—ж—¶пјҢзңӢдәҶеҗҺйқўзҡ„ж–№жі•е°ұжҳҺзҷҪдәҶпјү
еҲҶд»Јеӣһ收算法
ж №жҚ®еҜ№иұЎеӯҳжҙ»зҡ„з”ҹе‘Ҫе‘Ёжңҹе°ҶеҶ…еӯҳеҲ’еҲҶдёәиӢҘе№ІдёӘдёҚеҗҢзҡ„еҢәеҹҹгҖӮдёҚеҗҢеҢәеҹҹйҮҮз”ЁдёҚеҗҢз®—жі•пјҲеӨҚеҲ¶з®—жі•пјҢж Үи®°ж•ҙзҗҶз®—жі•пјүпјҢиҝҷе°ұжҳҜеҲҶд»Јеӣһ收算法гҖӮ
дёҖиҲ¬жғ…еҶөдёӢе°Ҷе ҶеҢәеҲ’еҲҶдёәиҖҒе№ҙд»ЈпјҲOld Generationпјүе’Ңж–°з”ҹд»ЈпјҲYoung GenerationпјүпјҢиҖҒе№ҙд»Јзҡ„зү№зӮ№жҳҜжҜҸж¬Ўеһғеңҫ收йӣҶж—¶еҸӘжңүе°‘йҮҸеҜ№иұЎйңҖиҰҒиў«еӣһ收пјҢиҖҢж–°з”ҹд»Јзҡ„зү№зӮ№жҳҜжҜҸж¬Ўеһғеңҫеӣһ收时йғҪжңүеӨ§йҮҸзҡ„еҜ№иұЎйңҖиҰҒиў«еӣһ收пјҢйӮЈд№Ҳе°ұеҸҜд»Ҙж №жҚ®дёҚеҗҢд»Јзҡ„зү№зӮ№йҮҮеҸ–жңҖйҖӮеҗҲзҡ„收йӣҶз®—жі•гҖӮ
1.ж–°з”ҹд»Јеӣһ收
ж–°з”ҹд»ЈдҪҝз”ЁScavengeз®—жі•иҝӣиЎҢеӣһ收гҖӮеңЁScavengeз®—жі•зҡ„е®һзҺ°дёӯпјҢдё»иҰҒйҮҮз”ЁдәҶCheneyз®—жі•гҖӮ
Cheneyз®—жі•жҳҜдёҖз§ҚйҮҮз”ЁеӨҚеҲ¶зҡ„ж–№ејҸе®һзҺ°зҡ„еһғеңҫеӣһ收算法гҖӮ е®ғе°ҶеҶ…еӯҳдёҖеҲҶдёәдәҢпјҢжҜҸдёҖйғЁеҲҶз©әй—ҙз§°дёәsemispaceгҖӮеңЁиҝҷдёӨдёӘsemispaceдёӯпјҢдёҖдёӘеӨ„дәҺдҪҝз”ЁзҠ¶жҖҒпјҢеҸҰдёҖдёӘеӨ„дәҺй—ІзҪ®зҠ¶жҖҒгҖӮ з®ҖиҖҢиЁҖд№ӢпјҢе°ұжҳҜйҖҡиҝҮе°Ҷеӯҳжҙ»еҜ№иұЎеңЁдёӨдёӘsemispaceз©әй—ҙд№Ӣй—ҙиҝӣиЎҢеӨҚеҲ¶гҖӮ еӨҚеҲ¶иҝҮзЁӢйҮҮз”Ёзҡ„жҳҜBFSпјҲе№ҝеәҰдјҳе…ҲйҒҚеҺҶпјүзҡ„жҖқжғіпјҢд»Һж №еҜ№иұЎеҮәеҸ‘пјҢе№ҝеәҰдјҳе…ҲйҒҚеҺҶжүҖжңүиғҪеҲ°иҫҫзҡ„еҜ№иұЎ дјҳзӮ№пјҡж—¶й—ҙж•ҲзҺҮдёҠиЎЁзҺ°дјҳејӮпјҲзүәзүІз©әй—ҙжҚўеҸ–ж—¶й—ҙпјү зјәзӮ№пјҡеҸӘиғҪдҪҝз”Ёе ҶеҶ…еӯҳзҡ„дёҖеҚҠ
ж–°з”ҹд»Јзҡ„з©әй—ҙеҲ’еҲҶжҜ”дҫӢдёәд»Җд№ҲжҳҜжҜ”дҫӢдёә8пјҡ1пјҡ1пјҲдёҚжҳҜжҢүз…§дёҠйқўз®—жі•дёӯиҜҙзҡ„1пјҡ1пјүпјҹ
ж–°еҲӣе»әзҡ„еҜ№иұЎйғҪжҳҜж”ҫеңЁEdenз©әй—ҙпјҢиҝҷжҳҜеҫҲйў‘з№Ғзҡ„пјҢе°Өе…¶жҳҜеӨ§йҮҸзҡ„еұҖйғЁеҸҳйҮҸдә§з”ҹзҡ„дёҙж—¶еҜ№ иұЎпјҢиҝҷдәӣеҜ№иұЎз»қеӨ§йғЁеҲҶйғҪеә”иҜҘ马дёҠиў«еӣһ收пјҢиғҪеӯҳжҙ»дёӢжқҘиў«иҪ¬з§»еҲ°survivorз©әй—ҙзҡ„еҫҖеҫҖдёҚ еӨҡгҖӮжүҖд»ҘпјҢи®ҫзҪ®иҫғеӨ§зҡ„Edenз©әй—ҙе’Ңиҫғе°Ҹзҡ„Survivorз©әй—ҙжҳҜеҗҲзҗҶзҡ„пјҢеӨ§еӨ§жҸҗй«ҳдәҶеҶ…еӯҳзҡ„дҪҝ з”ЁзҺҮпјҢзј“и§ЈдәҶCopyingз®—жі•зҡ„зјәзӮ№гҖӮ 8пјҡ1пјҡ1е°ұжҢәеҘҪзҡ„пјҢеҪ“然иҝҷдёӘжҜ”дҫӢжҳҜеҸҜд»Ҙи°ғж•ҙзҡ„пјҢеҢ…жӢ¬дёҠйқўзҡ„ж–°з”ҹд»Је’ҢиҖҒе№ҙд»Јзҡ„1пјҡ2зҡ„ жҜ”дҫӢд№ҹжҳҜеҸҜд»Ҙи°ғж•ҙзҡ„гҖӮ
Edenз©әй—ҙе’ҢдёӨеқ—Survivorз©әй—ҙзҡ„е·ҘдҪңжөҒзЁӢжҳҜжҖҺж ·зҡ„пјҹ
е…·дҪ“зҡ„жү§иЎҢиҝҮзЁӢжҳҜжҖҺж ·зҡ„пјҹ
еҒҮи®ҫжңүзұ»дјјеҰӮдёӢзҡ„еј•з”Ёжғ…еҶөпјҡ
+----- AеҜ№иұЎ | ж №еҜ№иұЎ----+----- BеҜ№иұЎ ------ EеҜ№иұЎ | +----- CеҜ№иұЎ ----+---- FеҜ№иұЎ | +---- GеҜ№иұЎ ----- HеҜ№иұЎ DеҜ№иұЎ
еңЁжү§иЎҢScavengeд№ӢеүҚпјҢFromеҢәй•ҝиҝҷе№…жЁЎж ·:
+---+---+---+---+---+---+---+---+--------+| A | B | C | D | E | F | G | H | | +---+---+---+---+---+---+---+---+--------+
йӮЈд№ҲйҰ–е…Ҳе°Ҷж №еҜ№иұЎиғҪеҲ°иҫҫзҡ„ABCеҜ№иұЎеӨҚеҲ¶еҲ°ToеҢәпјҢдәҺжҳҜд№ҺToеҢәе°ұеҸҳжҲҗдәҶиҝҷдёӘж ·еӯҗпјҡ
allocationPtr вҶ“ +---+---+---+----------------------------+| A | B | C | | +---+---+---+----------------------------+ вҶ‘ scanPtr
жҺҘдёӢжқҘиҝӣе…ҘеҫӘзҺҜпјҢжү«жҸҸscanPtrжүҖжҢҮзҡ„AеҜ№иұЎпјҢеҸ‘зҺ°е…¶жІЎжңүжҢҮй’ҲпјҢдәҺжҳҜд№ҺscanPtr移еҠЁпјҢеҸҳжҲҗеҰӮдёӢиҝҷж ·
allocationPtr вҶ“ +---+---+---+----------------------------+| A | B | C | | +---+---+---+----------------------------+ вҶ‘ scanPtr
жҺҘдёӢжқҘжү«жҸҸBеҜ№иұЎпјҢеҸ‘зҺ°е…¶жңүжҢҮеҗ‘EеҜ№иұЎзҡ„жҢҮй’ҲпјҢдё”EеҜ№иұЎеңЁFromеҢәпјҢйӮЈд№ҲжҲ‘们йңҖиҰҒе°ҶEеҜ№иұЎеӨҚеҲ¶еҲ°allocationPtrжүҖжҢҮзҡ„ең°ж–№е№¶з§»еҠЁallocationPtrжҢҮй’Ҳпјҡ
allocationPtr вҶ“ +---+---+---+---+------------------------+| A | B | C | E | | +---+---+---+---+------------------------+ вҶ‘ scanPtr
дёӯй—ҙиҝҮзЁӢзңҒз•ҘпјҢе…·дҪ“еҸӮиҖғ[ж–°з”ҹд»Јзҡ„еһғеңҫеӣһ收具дҪ“зҡ„жү§иЎҢиҝҮзЁӢ][3] FromеҢәе’ҢToеҢәеңЁеӨҚеҲ¶е®ҢжҲҗеҗҺзҡ„з»“жһңпјҡ
//FromеҢә +---+---+---+---+---+---+---+---+--------+| A | B | C | D | E | F | G | H | | +---+---+---+---+---+---+---+---+--------+//ToеҢә +---+---+---+---+---+---+---+------------+| A | B | C | E | F | G | H | | +---+---+---+---+---+---+---+------------+
жңҖз»ҲеҪ“scanPtrе’ҢallocationPtrйҮҚеҗҲпјҢиҜҙжҳҺеӨҚеҲ¶з»“жқҹгҖӮ жіЁж„ҸпјҡеҰӮжһңжҢҮеҗ‘иҖҒз”ҹд»ЈжҲ‘们е°ұдёҚеҝ…иҖғиҷ‘е®ғдәҶгҖӮпјҲйҖҡиҝҮеҶҷеұҸйҡңпјү
еҜ№иұЎдҪ•ж—¶жҷӢеҚҮпјҹ
1.еҪ“дёҖдёӘеҜ№иұЎз»ҸиҝҮеӨҡж¬Ўж–°з”ҹд»Јзҡ„жё…зҗҶдҫқж—§е№ёеӯҳгҖӮ 2.еҰӮжһңToз©әй—ҙе·Із»Ҹиў«дҪҝз”ЁдәҶи¶…иҝҮ25%пјҲеҗҺйқўиҝҳиҰҒиҝӣжқҘи®ёеӨҡж–°еҜ№иұЎпјҢдёҚж•ўеҚ з”ЁеӨӘеӨҡпјү 3.еӨ§еҜ№иұЎ пјҲе…¶е®һиҝҷйғЁеҲҶпјҢеҢ…жӢ¬ж¬Ўж•°пјҢжҜ”дҫӢзӯүпјҢжҳҜи§Ҷжғ…еҶөи®ҫзҪ®зҡ„гҖӮпјү
2.иҖҒз”ҹд»Јеӣһ收
Mark-SweepпјҲж Үи®°жё…йҷӨпјү
ж Үи®°жё…йҷӨеҲҶдёәж Үи®°е’Ңжё…йҷӨдёӨдёӘйҳ¶ж®өгҖӮ дё»иҰҒжҳҜж Үи®°жё…йҷӨеҸӘжё…йҷӨжӯ»дәЎеҜ№иұЎпјҢиҖҢжӯ»дәЎеҜ№иұЎеңЁиҖҒз”ҹд»ЈдёӯеҚ з”Ёзҡ„жҜ”дҫӢеҫҲе°ҸпјҢжүҖд»Ҙж•ҲзҺҮиҫғй«ҳгҖӮ
Mark-CompactпјҲж Үи®°ж•ҙзҗҶпјү
ж Үи®°ж•ҙзҗҶжӯЈжҳҜдёәдәҶи§ЈеҶіж Үи®°жё…йҷӨжүҖеёҰжқҘзҡ„еҶ…еӯҳзўҺзүҮзҡ„й—®йўҳгҖӮ еӨ§дҪ“иҝҮзЁӢе°ұжҳҜ еҸҢз«ҜйҳҹеҲ—ж Үи®°й»‘пјҲйӮ»жҺҘеҜ№иұЎе·Із»Ҹе…ЁйғЁеӨ„зҗҶпјүпјҢзҷҪпјҲеҫ…йҮҠж”ҫеһғеңҫпјүпјҢзҒ°пјҲйӮ» жҺҘеҜ№иұЎе°ҡжңӘе…ЁйғЁеӨ„зҗҶпјүдёүз§ҚеҜ№иұЎ. ж Үи®°з®—жі•зҡ„ж ёеҝғе°ұжҳҜж·ұеәҰдјҳе…Ҳжҗңзҙў.
иЎҘе……жҰӮеҝөж–№дҫҝзҗҶи§Ј
1.и§ҰеҸ‘GCпјҲдҪ•ж—¶еҸ‘з”ҹеһғеңҫеӣһ收пјҹпјү
дёҖиҲ¬йғҪжҳҜеҶ…еӯҳж»ЎдәҶе°ұеӣһ收пјҢдёӢйқўеҲ—дёҫеҮ дёӘеёёи§ҒеҺҹеӣ пјҡ GC_FOR_MALLOC: иЎЁзӨәжҳҜеңЁе ҶдёҠеҲҶй…ҚеҜ№иұЎж—¶еҶ…еӯҳдёҚи¶іи§ҰеҸ‘зҡ„GCгҖӮ GC_CONCURRENT: еҪ“жҲ‘们еә”з”ЁзЁӢеәҸзҡ„е ҶеҶ…еӯҳиҫҫеҲ°дёҖе®ҡйҮҸпјҢжҲ–иҖ…еҸҜд»ҘзҗҶи§Јдёәеҝ«иҰҒж»Ўзҡ„ж—¶еҖҷпјҢзі»з»ҹдјҡиҮӘеҠЁи§ҰеҸ‘GCж“ҚдҪңжқҘйҮҠж”ҫеҶ…еӯҳгҖӮ GC_EXPLICIT: иЎЁзӨәжҳҜеә”з”ЁзЁӢеәҸи°ғз”ЁSystem.gcгҖҒVMRuntime.gcжҺҘеҸЈжҲ–иҖ…收еҲ°SIGUSR1дҝЎеҸ·ж—¶и§ҰеҸ‘зҡ„GCгҖӮ GC_BEFORE_OOM: иЎЁзӨәжҳҜеңЁеҮҶеӨҮжҠӣOOMејӮеёёд№ӢеүҚиҝӣиЎҢзҡ„жңҖеҗҺеҠӘеҠӣиҖҢи§ҰеҸ‘зҡ„GCгҖӮ
2.еҶҷеұҸйҡңпјҲдёҖдёӘиҖҒе№ҙд»Јзҡ„еҜ№иұЎйңҖиҰҒеј•з”Ёе№ҙиҪ»д»Јзҡ„еҜ№иұЎпјҢиҜҘжҖҺд№ҲеҠһпјҹпјү
еҰӮжһңж–°з”ҹд»Јдёӯзҡ„дёҖдёӘеҜ№иұЎеҸӘжңүдёҖдёӘжҢҮеҗ‘е®ғзҡ„жҢҮй’ҲпјҢиҖҢиҝҷдёӘжҢҮй’ҲеңЁиҖҒз”ҹд»ЈдёӯпјҢжҲ‘们еҰӮдҪ•еҲӨж–ӯ иҝҷдёӘж–°з”ҹд»Јзҡ„еҜ№иұЎжҳҜеҗҰеӯҳжҙ»пјҹдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢйңҖиҰҒе»әз«ӢдёҖдёӘеҲ—иЎЁз”ЁжқҘи®°еҪ•жүҖжңүиҖҒз”ҹд»Ј еҜ№иұЎжҢҮеҗ‘ж–°з”ҹд»ЈеҜ№иұЎзҡ„жғ…еҶөгҖӮжҜҸеҪ“жңүиҖҒз”ҹд»ЈеҜ№иұЎжҢҮеҗ‘ж–°з”ҹд»ЈеҜ№иұЎзҡ„ж—¶еҖҷпјҢжҲ‘们е°ұи®°еҪ•дёӢ жқҘгҖӮ еҪ“еһғеңҫеӣһ收еҸ‘з”ҹеңЁе№ҙиҪ»д»Јж—¶пјҢеҸӘйңҖеҜ№иҝҷеј иЎЁиҝӣиЎҢжҗңзҙўд»ҘзЎ®е®ҡжҳҜеҗҰйңҖиҰҒиҝӣиЎҢеһғеңҫеӣһ收пјҢиҖҢдёҚ жҳҜжЈҖжҹҘиҖҒе№ҙд»Јдёӯзҡ„жүҖжңүеҜ№иұЎеј•з”ЁгҖӮ
3.ж·ұеәҰгҖҒе№ҝеәҰдјҳе…ҲжҗңзҙўпјҲдёәд»Җд№Ҳж–°з”ҹд»Јз”Ёе№ҝеәҰжҗңзҙўпјҢиҖҒз”ҹд»Јз”Ёж·ұеәҰжҗңзҙўпјү
ж·ұеәҰдјҳе…ҲDFSдёҖиҲ¬йҮҮз”ЁйҖ’еҪ’ж–№ејҸе®һзҺ°пјҢеӨ„зҗҶtracingзҡ„ж—¶еҖҷпјҢеҸҜиғҪдјҡеҜјиҮҙж Ҳз©әй—ҙжәўеҮәпјҢжүҖд»ҘдёҖиҲ¬йҮҮз”Ёе№ҝеәҰдјҳе…ҲжқҘе®һзҺ°tracingпјҲйҖ’еҪ’жғ…еҶөдёӢе®№жҳ“зҲҶж ҲпјүгҖӮ е№ҝеәҰдјҳе…Ҳзҡ„жӢ·иҙқйЎәеәҸдҪҝеҫ—GCеҗҺеҜ№иұЎзҡ„з©әй—ҙеұҖйғЁжҖ§пјҲmemory localityпјүеҸҳе·®пјҲзӣёе…іеҸҳйҮҸж•ЈејҖдәҶпјүгҖӮ е№ҝеәҰдјҳе…Ҳжҗңзҙўжі•дёҖиҲ¬ж— еӣһжәҜж“ҚдҪңпјҢеҚіе…Ҙж Ҳе’ҢеҮәж Ҳзҡ„ж“ҚдҪңпјҢжүҖд»ҘиҝҗиЎҢйҖҹеәҰжҜ”ж·ұеәҰдјҳе…Ҳжҗңзҙўз®—жі•жі•иҰҒеҝ«дәӣгҖӮ ж·ұеәҰдјҳе…Ҳжҗңзҙўжі•еҚ еҶ…еӯҳе°‘дҪҶйҖҹеәҰиҫғж…ўпјҢе№ҝеәҰдјҳе…Ҳжҗңзҙўз®—жі•еҚ еҶ…еӯҳеӨҡдҪҶйҖҹеәҰиҫғеҝ«гҖӮ з»“еҗҲж·ұжҗңе’Ңе№ҝжҗңзҡ„е®һзҺ°пјҢд»ҘеҸҠж–°з”ҹ代移еҠЁж•°йҮҸе°ҸпјҢиҖҒз”ҹд»Јж•°йҮҸеӨ§зҡ„жғ…еҶөпјҢжҲ‘们еҸҜд»Ҙеҫ—еҲ°дәҶи§Јзӯ”гҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№goиҜӯиЁҖдёӯеһғеңҫеӣһ收жңәеҲ¶зҡ„еҺҹзҗҶжҳҜд»Җд№ҲжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ