您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章的内容主要围绕怎样浅谈分布式ID的实践与应用进行讲述,文章内容清晰易懂,条理清晰,非常适合新手学习,值得大家去阅读。感兴趣的朋友可以跟随小编一起阅读吧。希望大家通过这篇文章有所收获!
在业务系统中很多场景下需要生成不重复的 ID,比如订单编号、支付流水单号、优惠券编号等都需要使用到。小编将介绍分布式 ID 的产生原因,以及目前业界常用的四种分布式 ID 实现方案,并且详细介绍其中两种的实现以及优缺点,
随着业务数据量的增长,存储在数据库中的数据越来越多,当索引占用的空间超出可用内存大小后,就会通过磁盘索引来查找数据,这样就会极大的降低数据查询速度。如何解决这样的问题呢?一般我们首先通过分库分表来解决,分库分表后就无法使用数据库自增 ID 来作为数据的唯一编号,那么就需要使用分布式 ID 来做唯一编号了。
目前,关于分布式 ID ,业界主要有以下四种实现方案:
UUID:使用 JDK 的 UUID#randomUUID() 生成的 ID;
Redis 的原子自增:使用 Jedis#incr(String key) 生成的 ID;
Snowflake 算法:以时间戳机器号和毫秒内并发组成的 64 位 Long 型 ID;
分段步长:按照步长从数据库读取一段可用范围的 ID;
我们总结一下这几种方案的特点:
| 方案 | 顺序性 | 重复性 | 可用性 | 部署方式 | 可用时间 |
|---|---|---|---|---|---|
| UUID | 无序 | 通过多位随机字符达到极低重复概率,但理论上是会重复的 | 一直可用 | JDK 直接调用 | 永久 |
| Redis | 单调递增 | RDB 持久化模式下,会出现重复 | Redis 宕机后不可用 | Jedis 客户端调用 | 永久 |
| Snowflake | 趋势递增 | 不会重复 | 发生时钟回拨并且回拨时间超过等待阈值时不可用 | 集成部署、集群部署 | 69年 |
| 分段步长 | 趋势递增 | 不会重复 | 如果数据库宕机并且获取步长内的 ID 用完后不可用 | 集成部署、集群部署 | 永久 |
前面两种实现方案的用法以及实现大家日常了解较多,就不在此赘述...本文我们会详细介绍 Snowflake 算法以及分段步长方案。
Snowflake 算法可以做到分配好机器号后就可以使用,不依赖任何第三方服务实现本地 ID 生成,依赖的第三方服务越少可用性越高,那么我们先来介绍一下 Snowflake 算法。
长整型数字(即 Long 型数字)的十进制范围是 -2^64 到 2^64-1。
Snowflake 使用的是无符号长整型数字,即从左到右一共 64 位二进制组成,但其第一位是不使用的。所以,在 Snowflake 中使用的是 63bit 的长整型无符号数字,它们由时间戳、机器号、毫秒内并发序列号三个部分组成 :
时间戳位:当前毫秒时间戳与新纪元时间戳的差值(所谓新纪元时间戳就是应用开始使用 Snowflake 的时间。如果不设置新纪元时间,时间戳默认是从1970年开始计算的,设置了新纪元时间可以延长 Snowflake 的可用时间)。41 位 2 进制转为十进制是 2^41,除以(365 天 * 24 小时 * 3600 秒 * 1000 毫秒),约等于 69年,所以最多可以使用 69 年;
机器号:10 位 2 进制转为十进制是 2^10,即 1024,也就是说最多可以支持有 1024 个机器节点;
毫秒内并发序列号:12 位 2 进制转为十进制是 2^12,即 4096,也就是说一毫秒内在一个机器节点上并发的获取 ID,最多可以支持 4096 个并发;
下面我们来看一下各个分段的使用情况:
| 二进制分段 | [1] | [2, 42] | [43, 52] | [53, 64] |
|---|---|---|---|---|
| 说明 | 最高符号位不使用 | 一共41位,是毫秒时间戳位 | 一个10位,是机器号位 | 一共12位,是毫秒内并发序列号,当前请求的时间戳如果和上一次请求的时间戳相同,那么就将毫秒内并发序列号加一 |
那么 Snowflake 生成的 ID 长什么样子呢?下面我们来举几个例子(假设我们的时间戳新纪元是 2020-12-31 00:00:00):
| 时间 | 机器号 | 毫秒并发 | 十进制 Snowflake ID |
|---|---|---|---|
| 2021-01-01 08:33:11 | 1 | 10 | 491031363588106 |
| 2021-01-02 13:11:12 | 2 | 25 | 923887730696217 |
| 2021-01-03 21:22:01 | 3 | 1 | 1409793654796289 |
Snowflake 可以使用三种不同的部署方式来部署,集成分布式部署方式、中心集群式部署方式、直连集群式部署方式。下面我们来分别介绍一下这几种部署方式。
当使用 ID 的应用节点比较少时,比如 200 个节点以内,适合使用集成分布式部署方式。每个应用节点在启动的时候决定了机器号后,运行时不依赖任何第三方服务,在本地使用时间戳、机器号、以及毫秒内并发序列号生成 ID。
下图展示的是应用服务器通过引入 jar 包的方式实现获取分布式 ID 的过程。每一个使用分布式 ID 的应用服务器节点都会分配一个拓扑网络内唯一的机器号。这个机器号的管理存放在 MySQL 或者 ZooKeeper 上。
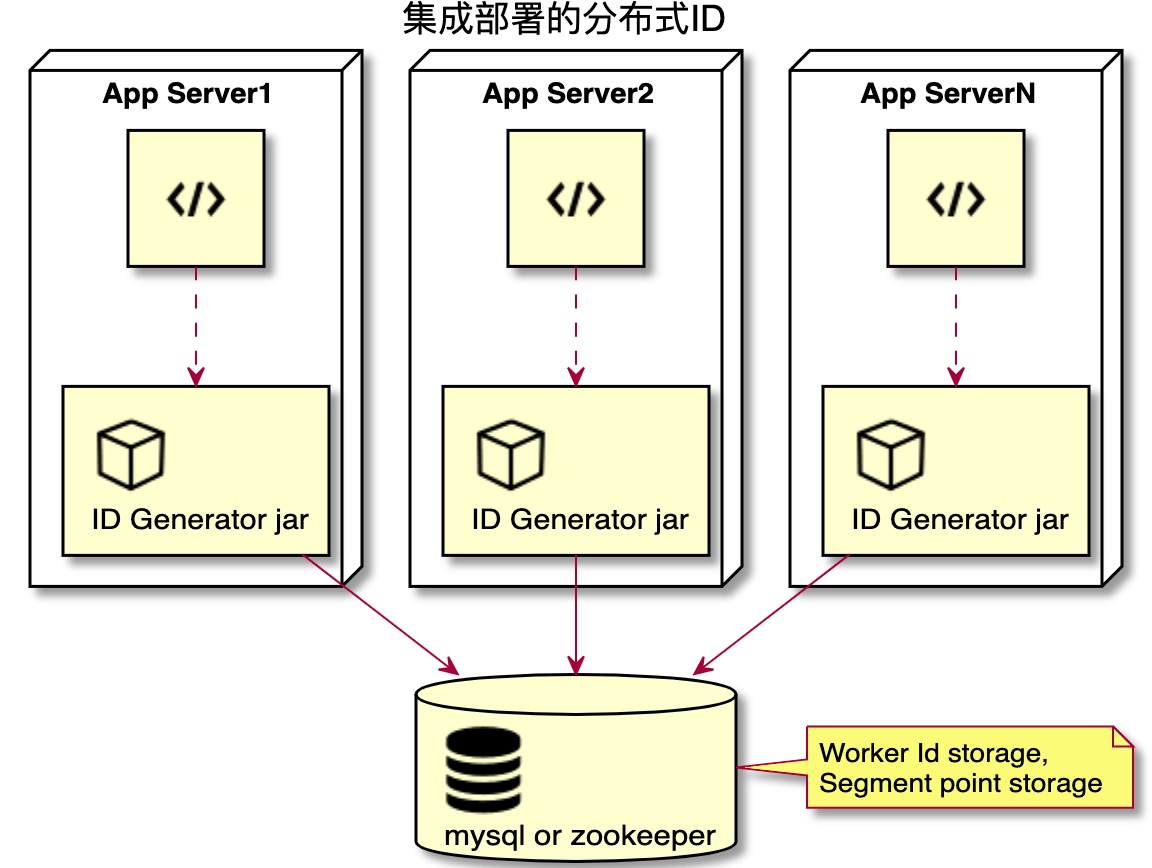
当拓扑网络内使用分布式 ID 的机器节点很多,例如超过 1000 个机器节点时,使用集成部署的分布式 ID 就不合适了,因为机器号位一共是 10 位,即最多支持 1024 个机器号。当机器节点超过 1000 个机器节点时,可以使用下面要介绍的中心集群式部署方式。
中心集群式部署需要新增用来做请求转发的 ID 网关,比如使用 nginx 反向代理(即下图中的 ID REST API Gateway)。
使用 ID 网关组网后,应用服务器通过 HTTP 或 RPC 请求 ID 网关获取分布式 ID。这样相比于上面的集成分布式部署方式,就可以支撑更多的应用节点使用分布式 ID 了。
如图所示,机器号的分配只是分配给下图中的 ID Generator node 节点,应用节点是不需要分配机器号的。
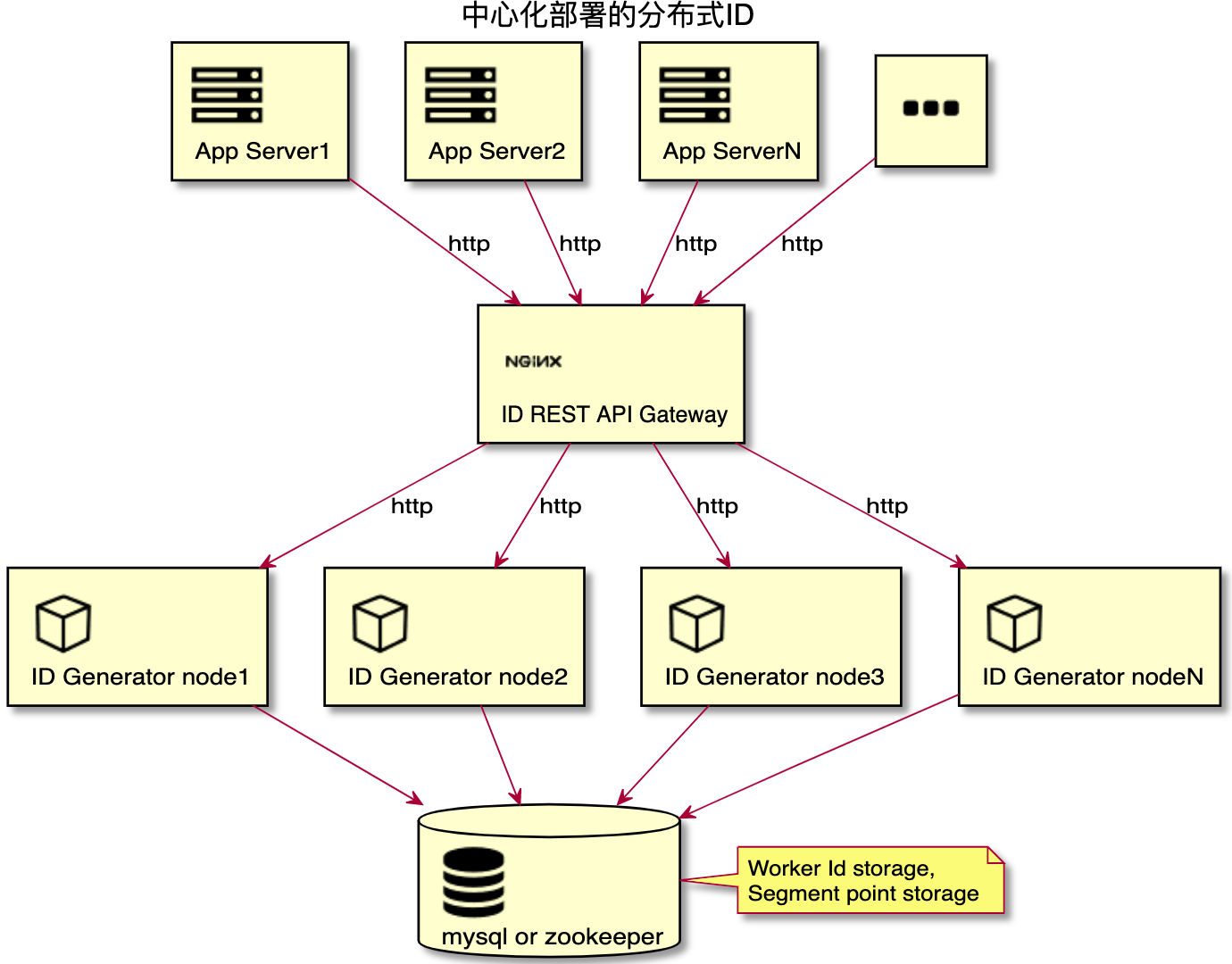
使用中心集群式部署方式需要引入新的 nginx 反向代理做网关,增加了系统的复杂性,降低了服务的可用性。那么我们下面再介绍一种不需要引入 nginx 又可以支持超过 1000 个应用节点的直连集群部署方式。
相比于中心集群部署方式,直连集群部署方式可以去掉中间的 ID 网关,提高服务的可用性。
在使用 ID 网关的时候,我们需要把 ID generator node 的服务地址配置在 ID 网关中。而在使用直连集群式部署方式时,ID generator node 的服务地址可以配置在应用服务器本地配置文件中,或者配置在配置中心。应用服务器获取到服务地址列表后,需要实现服务路由,直连 ID 生成器获取 ID。
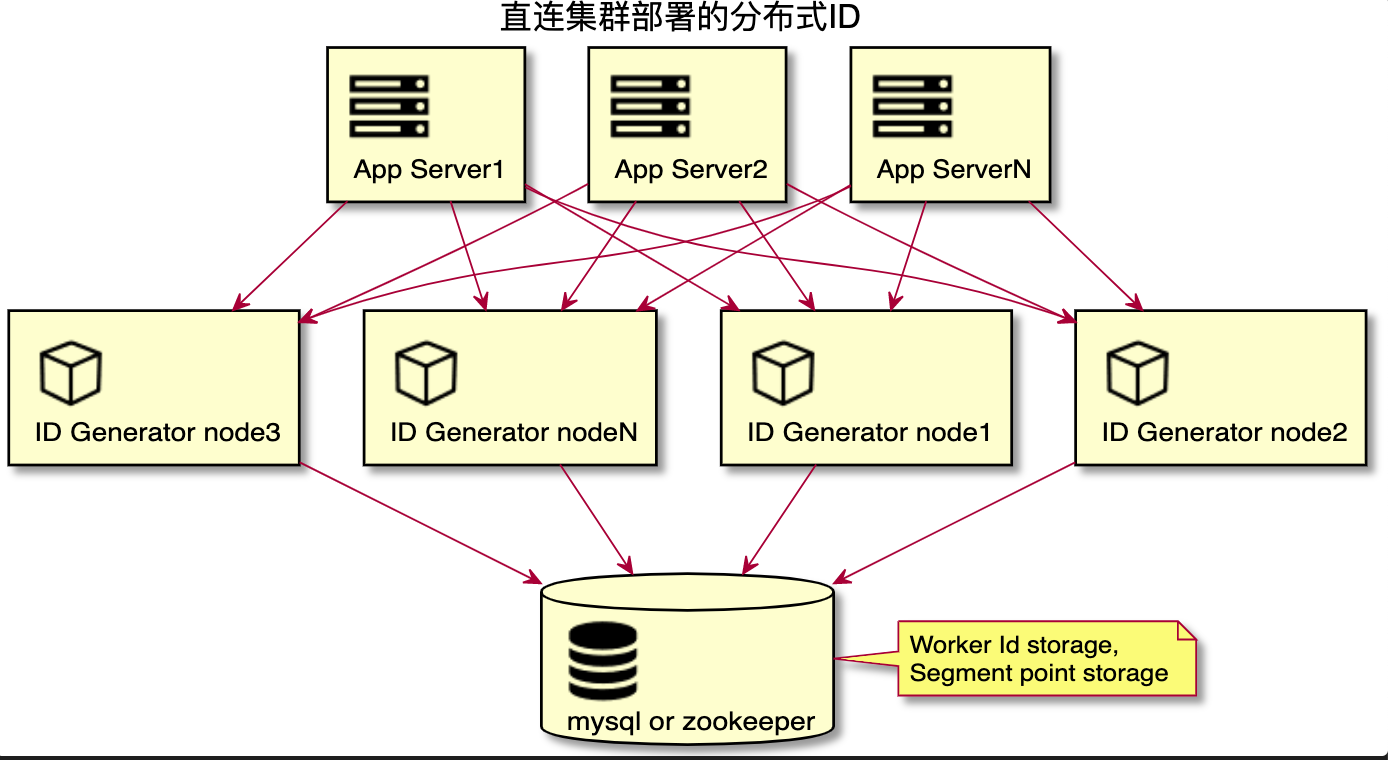
Snowflake 算法是强依赖时间戳的算法,如果一旦发生时钟回拨就会产生 ID 重复的问题。那么时钟回拨是怎么产生的,我们又需要怎么去解决这个问题呢?
NTP(Network Time Protocol)服务自动校准可能导致时钟回拨。我们身边的每一台计算机都有自己本地的时钟,这个时钟是根据 CPU 的晶振脉冲计算得来的,然而随着运行时间的推移,这个时间和世界时间的偏差会越来越大,那么 NTP 就是用来做时钟校准的服务。
一般情况下发生时钟回拨的概率也非常小,因为一旦出现本地时间相对于世界时间需要校准,但时钟偏差值小于 STEP 阈值(默认128毫秒)时,计算机会选择以 SLEW 的方式进行同步,即以 0.5 毫秒/秒的速度差调整时钟速度,保证本地时钟是一直连续向前的,不产生时钟回拨,直到本地时钟和世界时钟对齐。
然而如果本地时钟和世界时钟相差大于 STEP 阈值时,就会发生时钟回拨。这个 STEP 阈值是可以修改的,但是修改的越大,在 SLEW 校准的时候需要花费的校准时间就越长,例如 STEP 阈值设置为 10 分钟,即本地时钟与世界时钟偏差在 10 分钟以内时都会以 SLEW 的方式进行校准,这样最多会需要 14 天才会完成校准。
为了避免时钟回拨导致重复 ID 的问题,可以使用 128 毫秒的 STEP 阈值,同时在获取 SnowflakeID 的时候与上一次的时间戳相比,判断时钟回拨是否在 1 秒钟以内,如果在 1 秒钟以内,那么等待 1 秒钟,否则服务不可用,这样可以解决时钟回拨 1 秒钟的问题。
Snowflake 由于是将时间戳作为长整形的高位,所以导致生成的最小数字也非常大。比如超过时间新纪元 1 秒钟,机器号为 1,毫秒并发序列为 1 时,生成的 ID 就已经到 4194308097 了。那么有没有一种方法能够实现在初始状态生成数字较小的 ID 呢?答案是肯定的,下面来介绍一下分段步长 ID 方案。
使用分段步长来生成 ID 就是将步长和当前最大 ID 存在数据库中,每次获取 ID 时更新数据库中的 ID 最大值增加步长。
数据库核心表结构如下所示:
CREATE TABLE `segment_id` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `biz_type` varchar(64) NOT NULL DEFAULT '', // 业务类型 `max` bigint(20) DEFAULT '0', // 当前最大 ID 值 `step` bigint(20) DEFAULT '10000', // ID 步长 PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
在获取 ID 时,使用开启事务,利用行锁保证读取到当前更新的最大 ID 值:
start transaction; update segment_id set max = max + step where biz_type = 'ORDER'; select max from segment_id where biz_type = 'ORDER'; commit
分段步长 ID 生成方案的优缺点:
优点:ID 生成不依赖时间戳,ID 生成初始值可以从 0 开始逐渐增加;
缺点:当服务重启时需要将最大 ID 值增加步长,频繁重启的话就会浪费掉很多分段。
上文介绍了 Snowflake 算法以及分段步长方案,他们各有优缺点,针对他们各自的情况我们在本文也给出相应的优化方案。
为了提高 SnowflakeID 的并发性能和可用性,可以使用 ID 缓冲环(即 ID Buffer Ring)。提高并发性提现在通过使用缓冲环能够充分利用毫秒时间戳,提高可用性提现在可以相对缓解由时钟回拨导致的服务不可用。缓冲环是通过定长数组加游标哈希实现的,相比于链表会不需要频繁的内存分配。
在 ID 缓冲环初始化的时候会请求 ID 生成器将 ID 缓冲环填满,当业务需要获取 ID 时,从缓冲环的头部依次获取 ID。当 ID 缓冲环中剩余的 ID 数量少于设定的阈值百分比时,比如剩余 ID 数量少于整个 ID 缓冲环的 30% 时,触发异步 ID 填充加载。异步 ID 填充加载会将新生成的 ID 追加到 ID 缓冲环的队列末尾,然后按照哈希算法映射到 ID 缓冲环上。另外有一个单独的定时器异步线程来定时填充 ID 缓冲环。
下面的动画展示了 ID 缓冲环的三个阶段:ID 初始化加载、ID 消费、ID 消费后填充:
Buffer Ring Initialize load,ID 缓冲环初始化加载:从 ID generator 获取到 ID 填充到 ID 缓冲环,直到 ID 缓冲环被填满;
Buffer Ring consume,ID 缓冲环消费:业务应用从 ID 缓冲环获取 ID;
Async reload,异步加载填充 ID 缓冲环:定时器线程负责异步的从 ID generator 获取 ID 添加到 ID 缓冲队列,同时按照哈希算法映射到 ID 缓冲环上,当 ID 缓冲环被填满时,异步加载填充结束;
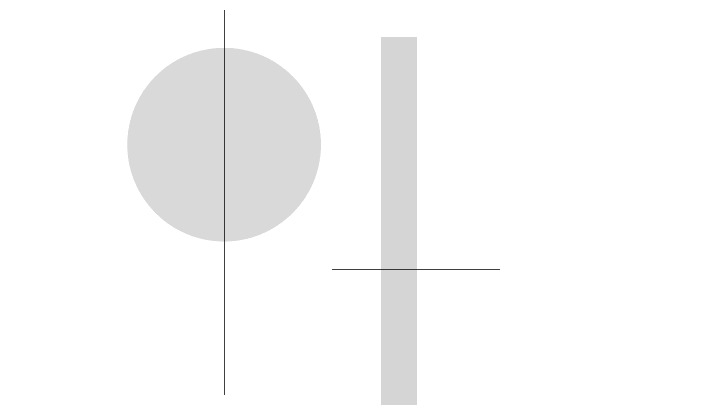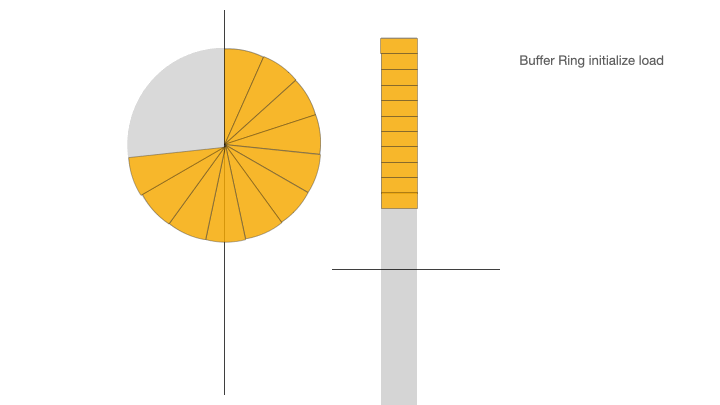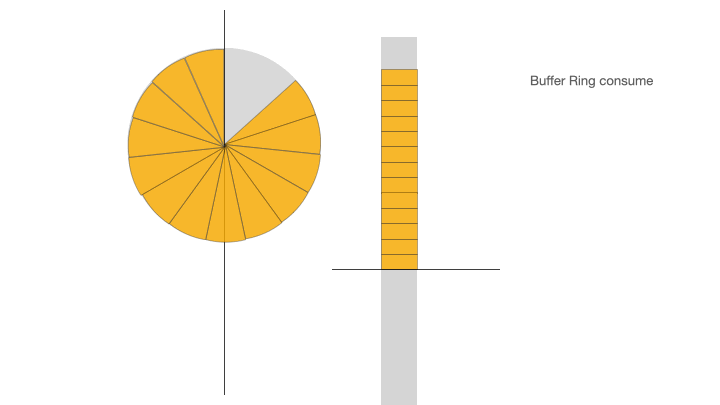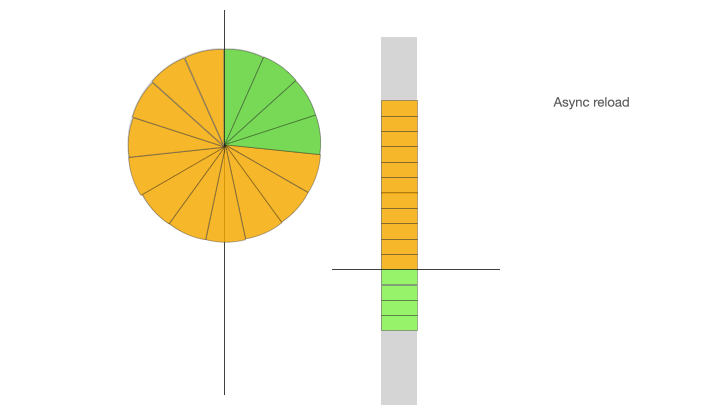
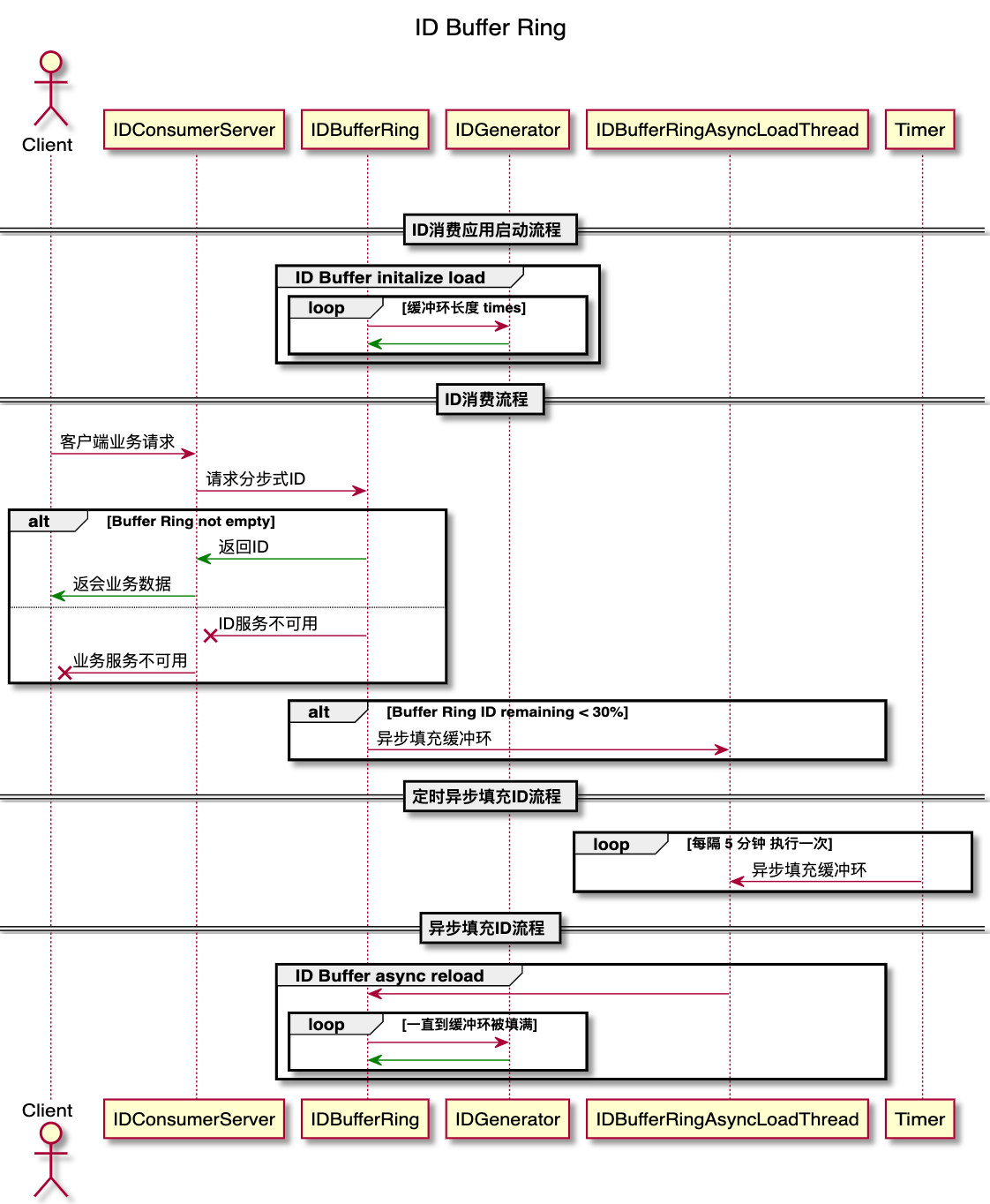
下面的流程图展示了 ID 缓冲环的运行的整个生命周期,其中:
IDConsumerServer:表示使用分布式 ID 的业务系统;
IDBufferRing:ID 缓冲环;
IDGenerator:ID 生成器;
IDBufferRingAsyncLoadThread:异步加载 ID 到缓冲环的线程;
Timer:负责定时向异步加载线程添加任务来装载 ID;
ID 消费流程:即 上面提到的 Buffer Ring consume;
整体流程:客户端业务请求到应用服务器,应用服务器从 ID 缓冲环获取 ID,如果 ID 缓冲环内空了那么抛出服务不可用;如果 ID 缓冲环内存有 ID 那么就消费一个 ID 。同时在消费 ID 缓冲环中的 ID 时,如果发现 ID 缓冲环中存留的 ID 数量少于整个 ID 缓冲环容量的 30% 时触发异步加载填充 ID 缓冲环。
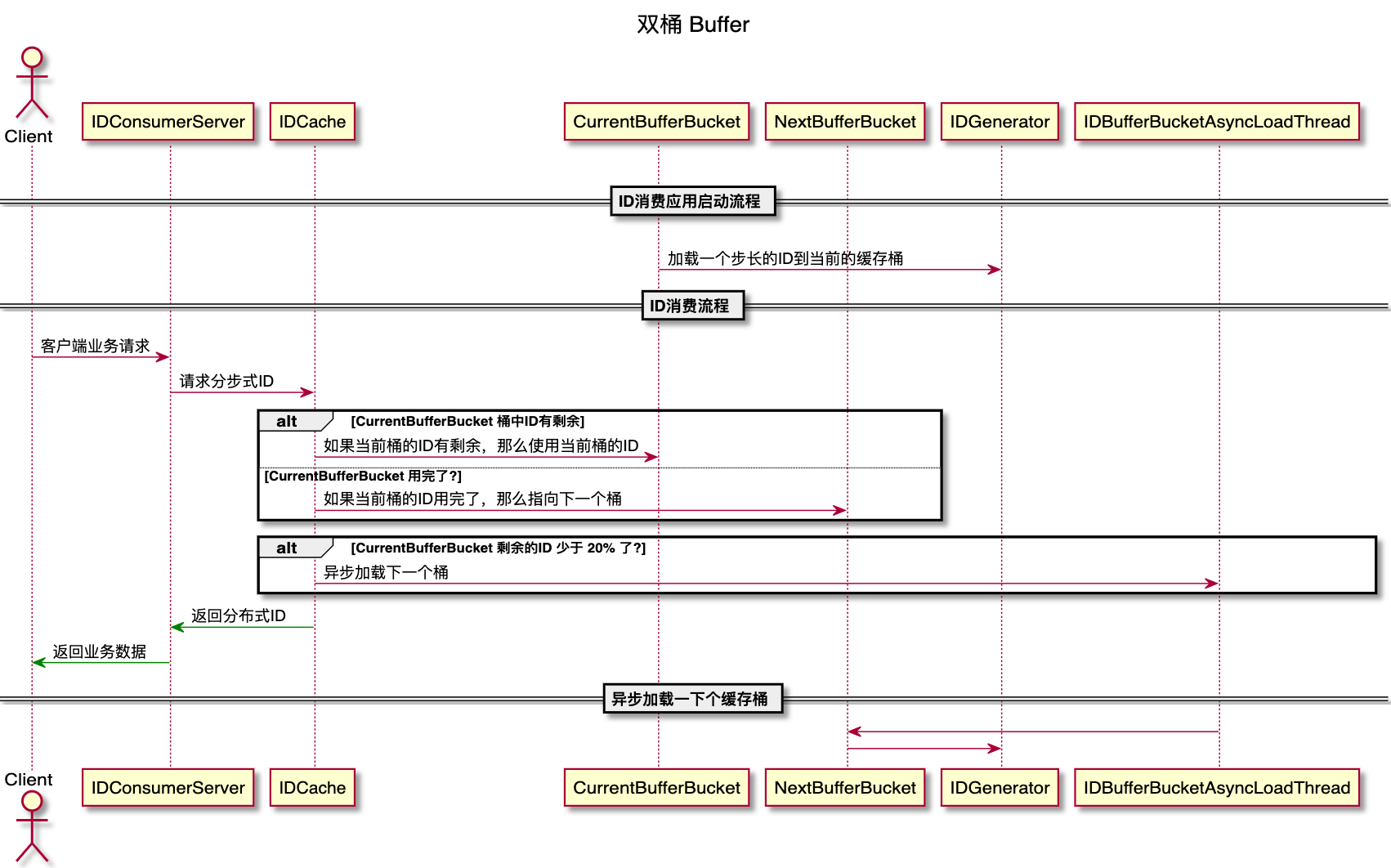
在使用分段步长 ID 时,如果该分段的 ID 用完了,需要更新数据库分段最大值再继续提供 ID 生成服务,为了减少数据库更新查询可能带来的延时对 ID 服务的性能影响,可以使用双桶缓存方案来提高 ID 生成服务的可用性。
其主要原理:设计两个缓存桶:currentBufferBucket 和 nextBufferBucket,每个桶都存放一个步长这么多的 ID,如果当前缓存桶的 ID 用完了,那么就将下一个缓存桶设置为当前缓存桶。
下面的动画展示了双桶缓存初始化、异步加载预备桶和将预备桶切换成当前桶的全过程:
Current bucket initial load:初始化当前的缓存桶,即更新 max = max + step,然后获取更新后的 max 值,比如步长是 1000,更新后的 max 值是 1000,那么桶的高度就是步长即 1000,桶 min = max - step + 1 = 1,max = 1000;
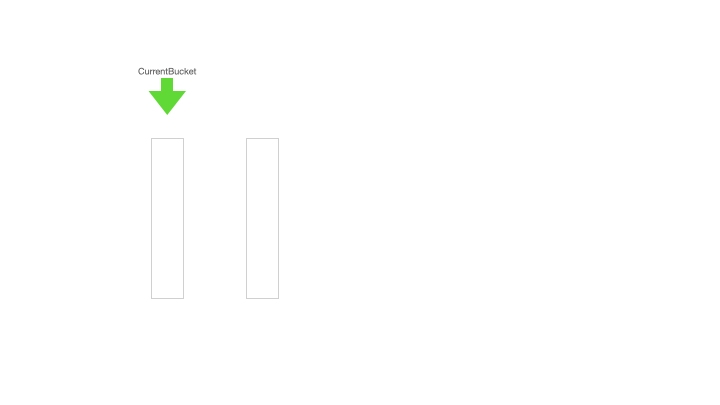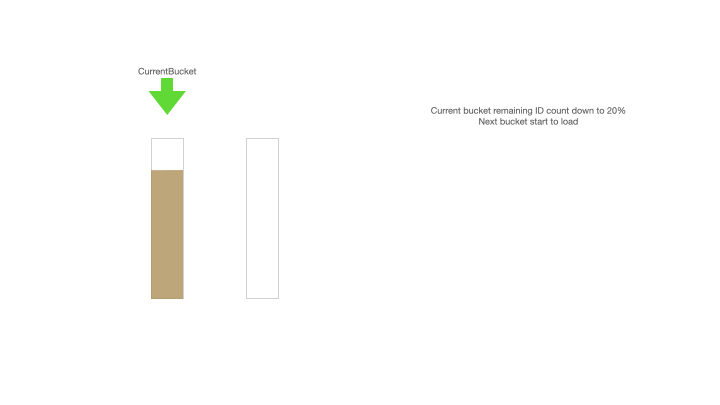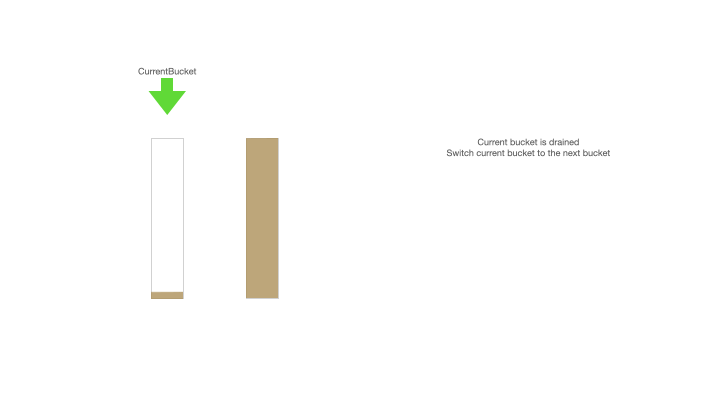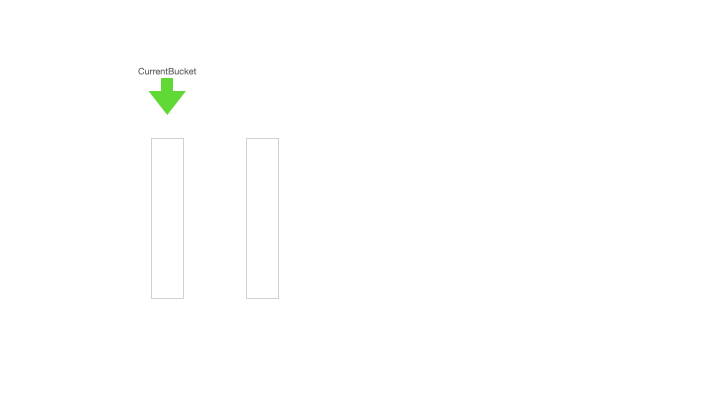
Current bucket remaining id count down to 20%,Next bucket start to load。当前缓存桶的 ID 剩余不足 20% 的时候可以加载下一个缓存桶,即更新 max = max + step,后获取更新后的 max 值,此时更新后的 max 值是 2000,min = max - step + 1 = 1001, max = 2000;
Current bucket is drained,Switch current bucket to the next bucket,如果当前桶的 ID 全部用完了,那么就将下一个 ID 缓存桶设置为当前桶;
下面是双桶 Buffer 的流程图:
感谢你的阅读,相信你对“怎样浅谈分布式ID的实践与应用”这一问题有一定的了解,快去动手实践吧,如果想了解更多相关知识点,可以关注亿速云网站!小编会继续为大家带来更好的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。