您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关网络安全中漏洞自动化分析工具怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
pentestEr_Fully-automatic-scanner为了省去繁琐的手工测试和常用漏洞的搜索工作,提升工作的效率,才有了此工具,工具对于前期的收集采用了市面上大量的工具集合,不漏扫的原则,最大化的提升工具可用性,可扩展性等要求,开发次扫描器。使用方法
可以直接执行 python main.py -d cert.org.cn
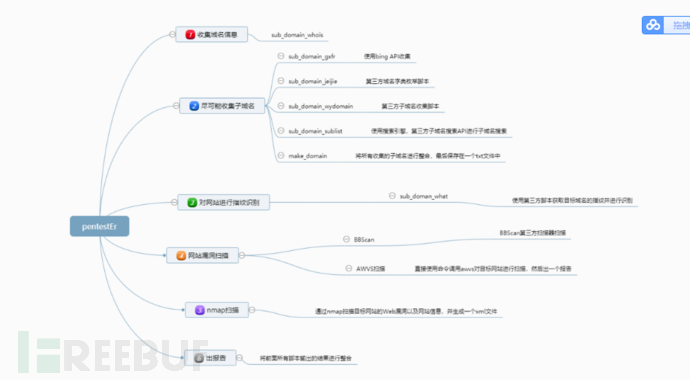
|--dict |--dns_server.txt |--... |--lib |-- __init__.py |--cmdline.py |--... |--listen |--filer.py |--report |--result |--rules |--wahtweb.json |--commom.txt |--subbrute |--thirdlib |--utils |--api.keys |--BBScan.py |--bingAPI |--captcha.py |--config.py |--dnsbrute.py |--gxfr.py |--import1.php |--main.py |--report_all.py |--subDomainBrute.py |--sublist3r.py |--upload.py |--wahtweb.py |--wydomain.py |--启动程序.bat |--wvs.bat
这个目录结构让我感觉很乱,尤其后面一大推py文件,缺少点软件设计的思想,感觉时即兴写出来的代码,很多文件还有错误,注释很少,很多时候需要debug才能知道该段代码实现的功能。
在进行扫描之前,按照惯例需要对目标网站的域名信息进行whois查询,该脚本whois的实现是通过第三方网站查询得到的,不过原查询函数因为日期久远,而网站代码也已经更新了,该函数已经无法准确的获取到目标网站域名信息了
def sub_domain_whois(url_domain):
"""
通过第三方网站查询得到whois结果,然后对网页进行正则匹配,以获取到网页内容中的whois结果
"""
um=[]
a1=requests.get("http://whois.chinaz.com/%s" %(url_domain))
if 'Registration' not in a1.text:
print 'whois error'
else:
print a1.text
# 使用正则匹配想要获取的内容,假如目标网站的前端代码改变了,那么该正则就失效了
out_result=re.findall(r'<pre class="whois-detail">([\s\S]*)</pre>', a1.text.encode("GBK",'ignore'))
out_result_register=re.findall(r'http://(.*?)"', a1.text.encode("GBK",'ignore'))
for x in out_result_register:
if 'reverse_registrant/?query=' in x:
um.append(x)
break
for x in out_result_register:
if 'reverse_mail/?query=' in x:
um.append(x)
break
print um[0], um[1]
print out_result[0]
# 将获取到的结果存放在的一个html文件中,以便最后生成报告
with open('report/whois_email_user.html','w') as fwrite:
fwrite.write('register_user:')
fwrite.write('<a href="http://' + um[0] + '">注册者反查询</a>')
fwrite.write('<br>')
fwrite.write('email:')
fwrite.write('<a href="http://' + um[1] + '">邮箱反查询</a>')
fwrite.write('<br>')
fwrite.write('<pre>')
fwrite.write(out_result[0])
fwrite.write('</pre>')
def sub_domain_whois(url_domain):
import json
a = requests.get("http://api.whoapi.com/?domain={}&r=whois&apikey=demokey".format(url_domain))
result = a.text
r = json.loads(result)
for k,v in r.items():
print(k,v)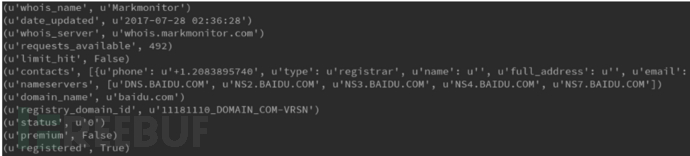
当然如果需要一些详细的信息,可能还是需要对一些网站的内容进行爬取才行。
对于子域名收集,这个系统在实现的时候,为了收集到尽可能多的代码,使用了很多第三方脚本,这里就出现了一个问题,这种使用脚本的方法让代码可读性很差,而且维护困难,很多代码现在已经不适用了。
| 脚本名称 | 介绍 | 使用方法 | 返回内容 |
|---|---|---|---|
| gxfr.py | 使用高级搜索引擎(bing,baidu,google)查询来枚举子域并执行dns查找,这个程序使用的是bing的API对子域名进行收集 | python gxfr.py --bxfr --dns-lookup -o --domain url_domain | 程序会将结果保存到一个domain_gxfr1.txt这样的文件中,api已经不可用 |
| subDomainsBrute.py | 提供的常用的子域名字符串字典,然后通过与域名进行组合,配合DNS服务器确定是否存在组合后的子域名 | python subDomainsBrute.py domain | 将字典枚举组合解析成功后的域名存放在domain_jiejie.txt文件中 |
| wydomain.py | 通过使用互联网上的第三方接口或者爬取查询结果来获取目标的子域名 | python wydomain domain | 通过不同网站获取的结果会存在本地的不同的.json文件中 |
| sublist3r.py | 使用百度,雅虎,bing等第三方引擎对目标域名进行子域名收集,而且还提供字典枚举的功能和端口扫描的功能 | python sublist3r -d doamin -o domain_sublistdir.txt | 将获取到的子域名结果存在本地的txt文件中 |
该py文件是使用bing的API,谷歌的搜索引擎对目标域名的子域名进行查询。主要的两个函数为bxfr函数和gxfr函数。
bxfr函数,使用Bing的API进行子域名解析和查询,该函数需要提供Bing相关功能的API Key。然后访问` https://api.datamarket.azure.com/Data.ashx/Bing/Search/Web?Query=domain&Misplaced &format=json经过测试该API接口已经不可用。通过该API获取子域名结果后,使用lookup_subs函数进行socket函数获取地址并成功后(socket.getaddrinfo(site, 80)`),将结果存储在txt文件中中。
gxfr函数,使用google搜索引擎的hack语法进行查询(site:baidu.com),然后通过正则表达式进行匹配pattern = '>([\.\w-]*)\.%s.+?<' % (domain)。然后获取匹配结果。最后经过lookkup_subs函数验证之后写入txt文件中。
该py文件通过提供的子域名字典,对目标域名的子域名进行枚举然后解析测试,最后输出结果。这里提供了两个字典文件,分别为dict/subnames.txt和dict/next_sub.txt。还有一个dns服务器列表
.114.114.114 .8.8.8 .76.76.76 .5.5.5 .6.6.6
程序简介
def __init__(self, target, names_file, ignore_intranet, threads_num, output):
self.target target.strip()
self.names_file names_file
self.ignore_intranet ignore_intranet
self.thread_count self.threads_num threads_num
self.scan_count self.found_count
self.lock threading.Lock()
self.console_width getTerminalSize()[0]
self.resolvers [dns.resolver.Resolver() _ range(threads_num)]
self._load_dns_servers()
self._load_sub_names()
self._load_next_sub()
outfile target not output output
self.outfile open(outfile, )
self.ip_dict {}
self.STOP_ME False该程序的执行流程就是,先从字典中加载字符串,然后将字符串与目标域名进行拼接得到一个子域名,通过第三方模块dns.resolver对其进行解析,解析成功就保存在txt文件中。关键代码如下:
cur_sub_domain sub self.target answers d.resolvers[thread_id].query(cur_sub_domain) is_wildcard_record False answers: answer answers: self.lock.acquire() answer.address not self.ip_dict: self.ip_dict[answer.address] : self.ip_dict[answer.address] self.ip_dict[answer.address] > : is_wildcard_record True self.lock.release()
该程序是通过调用多个第三方接口对目标域名进行子域名查询,然后将查询结果分别存储在一个json文件中。
fetch_chinaz函数
url .format(self.domain) r http_request_get(url).content subs re.compile(r)
fetch_alexa_cn函数
url .format(self.domain) r http_request_get(url).text sign re.compile(r).findall(r)
class Threatcrowd(object)
url .format(self.website, self.domain) content http_request_get(url).content sub json.loads(content).get():
class Threatminer(object)
url .format(self.website, self.domain) content http_request_get(url).content _regex re.compile(r) sub _regex.findall(content):
class Sitedossier(object)
url .format(self.domain) r self.get_content(url) self.parser(r) 部分代码如下 npage re.search(, response) npage: sub self.get_subdomain(response): self.subset.append(sub) return list(set(self.subset))
class Netcraft(object)
self.site self.cookie self.get_cookie().get() url .format( self.site, self.domain) r http_request_get(url, self.cookie) self.parser(r.text) 部分代码信息 npage re.search(, response) return list(set(self.subset))
class Ilinks(object)
self.url
payload {
: ,
: ,
: ,
: self.domain
}
r http_request_post(self.urlpayload).text
subs re.compile(r)class Chaxunla(object)
self.url url .format( self.url, timestemp, self.domain, timestemp, self.verify) result json.loads(req.get(url).content)
json_data read_json(_burte_file) json_data: subdomains.extend(json_data) ...... subdomains list(set(subdomains)) _result_file os.path.join(script_path, outfile) save_result(_result_file, subdomains)
该文件使用百度,雅虎,bing等第三方引擎对目标域名进行子域名收集,而且还提供字典枚举的功能和端口扫描的功能在该系统中只用到了该程序的子域名收集功能。使用到的模块也与之前的wydomain.py文件有很多重复的地方
该文件的类都是继承至该类,而这个基类也是由作者自定义的一个类。简单解释一下该类的功能
print_banner方法子类通过继承,可以通过该函数打印出该类使用的一些接口的信息
send_req方法发送请求的方法,该方法中自定义了大量的http头部变量,该方法返回的服务器回复的数据
get_response方法从response对象中获取html内容,并返回
check_max_subdomains方法该方法是用来设置寻找子域名最大个数的,如果得到子域名的数量到达该函数设置数量时,程序就会停止继续寻找子域名
check_max_pages方法比如google搜索引擎是需要指定探索的最大页数,否则会无限制的探索下去。
check_response_errors 方法该方法检查对服务器的请求是否成功完成
should_sleep方法在进行子域名收集的时候,为了避免类似于google搜索引擎的机器识别,应该设置休眠时间
enumerate方法通过该方法获取子域名
而以下的子域名检索方法是由enumratorBase类派生出来的,然后根据各自的特点进行修改后形成的类,简单的介绍一下功能
| 类名称 | 实现的功能 |
|---|---|
| GoogleEnum | 通过google搜索引擎检索目标子域名 |
| YahooEnum | 通过雅虎搜索引擎检索目标子域名 |
| AskEnum | 通过http://www.ask.com/web检索子域名 |
| BingEnum | 通过bing检索子域名 |
| BaiduEnum | 通过百度检索子域名 |
| NetcraftEnum | 通过http://searchdns.netcraft.com/?restriction=site+ends+with&host={domain}检测子域名 |
| Virustotal | 通过'https://www.virustotal.com/en/domain/{domain}/information/检索子域名 |
| ThreatCrowd | https://www.threatcrowd.org/searchApi/v2/domain/report/?domain={domain}检索子域名 |
| CrtSearch | 通过https://crt.sh/?q=%25.{domain}检索子域名 |
| PassiveDNS | 通过http://ptrarchive.com/tools/search.htm?label={domain}检索子域名 |
此外该脚本还提供端口扫描功能和字子域名字典枚举的功能,虽然该项系统并未使用这些功能
postscan函数关键代码,使用socket模块去尝试连接目标端口,如果超过2s目标没有回复,则判断目标没有开放该端口
for port in ports: try: s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.settimeout(2) result = s.connect_ex((host, int(port))) if result == 0: openports.append(port)
对与子域名枚举功能,该脚本调用了subbrute.py中的函数,用于对字典中字符串拼成的子域名进行验证操作。 关键代码
bruteforce_list subbrute.print_target(parsed_domain.netloc, record_type, subs, resolvers, process_count, output, json_output, search_list, verbose) print_target函数是subbrute文件中的函数,用于验证子域名是否是可用的
最后通过一个make_domain函数将所有的以.txt为后缀名的文件全部复制到all_reqult.log文件中,通过读取后格式化处理,将结果存储到report/result.txt文件中关键代码如下
os.system() print() list_domain [] f open(, ) ...... f.close() os.system() list_domain list(set((list_domain))) print list_domain, len(list_domain) with open(, ) as outfile: outfile.write(.join(list_domain)) fopen1 open(, ) fopen1.write(.join(list_domain)) fopen1.close()
对于获取Web网页的信息,这里主要是获取网页使用的是什么框架或者CMS,通过本地提供的一个json规则检测文件,对目标网站进行检测和指纹识别json文件中部分规则如下:
{
: [
{
: ,
:
},
{
: ,
: ,
:
}
],
: [
{
: ,
:
},
{
: ,
:
}
],
: [
{
: ,
: ,
:
}
],
: [
{
: ,
: [, ]
}
],
: [
{
: ,
:
}
],
......实现的过程是将report/result.txt中所有的域名根据json文件中的规则进行url拼接,然后对这个特定URL进行访问获取网页内容,再将网页内容与规则进行匹配,最后判断使用cms或者框架名称。关键代码如下
r requests.get(url1 rule[], ) r.encoding r.apparent_encoding r.close() rule and hashlib.md5(r.content).hexdigest() rule[]: print (url1, cms) rule and rule[] r.headers and rule[] r.headers[rule[]]: print (url1, cms) rule: type(rule[]) is list: itext rule[]: itext r.text: print (url1, cms) rule[] r.text: print (url1, cms) rule: type(rule[]) is list: reg rule[]: re.search(reg, r.text): print (url1, cms) re.search(rule[], r.text): print (url1, cms) : print
注意该脚本还引入了一个第三方模块from thirdlib import threadpool 该threadpool是一个简单的实现线程池的框架,方便使用脚本使用多线程。脚本中调用的关键代码
pool threadpool.ThreadPool(self.thread_num) reqs threadpool.makeRequests(self.identify_cms, self.rules, self.log) req reqs: pool.putRequest(req) pool.wait()
在系统的主函数中通过接受该脚本stdout输出的流数据,将数据写入到一个列表中,最后将结果保存到report/whatweb.html。
该系统的漏洞扫描模块是调用的第三方脚本BBScan.py,该文件代码实现了一个轻量级的web漏洞扫描器。使用的规则库为存放在本地的一个txt文件中rules/commom.txt部分规则如下:
/admin/ } /config/ } /manage/ } /backup/ } /backend/ } /admin.php } } /admin.jsp } } /admin.do } } /examples } /examples/servlets/servlet/SessionExample } /manager/html } /db/ } /DB/ } /data/ } /sqlnet.log } } /data/user.txt } } /user.txt } } /phpinfo.php } } /mysql/add_user.php } /cachemonitor/statistics.jsp } } /jmx-console/ } /jmx-console/HtmlAdaptor } /cacti/ } /cacti/cacti.sql } } /../../../../../../../../../../../../../etc/passwd } /config/config_ucenter.php.bak } /shell.php } /shell.jsp } /{hostname}.zip } } /resin-doc/resource/tutorial/jndi-appconfig/test/etc/passwd } /WEB-INF/web.xml } } /WEB-INF/web.xml.bak } } /.svn/ /.svn/entries } } /wp-login.php } } /config.inc }} /config.ini } }
脚本通过从这个文件中读取规则,对目标进行测试,然后根据服务器返回的内容进行判断是否存在该类型的漏洞。代码简介
def __init__(self, url, lock, , ):
self.START_TIME time.time()
self.TIME_OUT timeout
self.LINKS_LIMIT
self.final_severity
self.schema, self.host, self.path self._parse_url(url)
self.max_depth self._cal_depth(self.path)[1] depth
self.check_404()
self._status :
return None
not self.has_404:
print % self.host
self._init_rules()
self.url_queue Queue.Queue()
self.urls_in_queue []
_path, _depth self._cal_depth(self.path)
self._enqueue(_path)
self.crawl_index(_path)
self.lock threading.Lock()
self.results {}方法简介
_parse_url方法:解析URL,如果没有指定通信协议,系统自动添加为http协议。然后判断url中是否存在路径,如果不存在就返回"/",否则返回协议,主机名,和资源路径
return _.scheme, _.netloc, _.path _.path
_cal_depth:该方法是用于计算URL的深度,返回一个元组,url和深度。以//或者javascript开头的URL不做分析,以http开头的URL先对URL进行解析,然后判断hostnane是否为目标的hostname,在判断path路径的深度。关键代码如下
_ urlparse.urlparse(url, ) _.netloc self.host: url _.path 。。。。 url url[: url.rfind()] depth len(url.split())
_init_rules:该方法从文件中加载规则,使用正则表达式从文件中的每一行提取数据,正则表达式如下
p_severity re.compile() p_tag re.compile() p_status re.compile() p_content_type re.compile() p_content_type_no re.compile()
提取数据并进行判断,没有的置为空或者0
_ p_severity.search(url) severity int(_.group(1)) _ _ p_tag.search(url) tag _.group(1) _ _ p_status.search(url) status int(_.group(1)) _ _ p_content_type.search(url) content_type _.group(1) _ _ p_content_type_no.search(url) content_type_no _.group(1) _
最后将重组的规则存放在一个元组中,最后将这个元组追加到一个列表中
self.url_dict.append((url, severity, tag, status, content_type, content_type_no))
_http_request方法:通过该方法获取访问目标url的状态码,返回http头部和html内容部分代码如下
conn.request, url,
{: }
)
resp conn.getresponse()
resp_headers dict(resp.getheaders())
status resp.status_decode_response_text方法:该方法对服务器返回的页面进行解码操作,如果用户没有指定charset类型,那么该方法就会尝试使用'UTF-8', 'GB2312', 'GBK', 'iso-8859-1', 'big5'编码对目标返回的内容进行解码,并将解码后的内容返回部分代码
encodings [, , , , ] _ encodings: try: return rtxt.decode(_) except: pass
check_404方法:检查目标返回的页面的状态码是否为404部分代码如下
self._status, headers, html_doc self._http_request() self._status : print % self.host self.has_404 (self._status ) return self.has_404
_enqueue方法:该方法是判断爬取的URL是否是已经爬取的,如果是一个新的链接就传入队列中,该队列用于爬虫部分代码
url self.urls_in_queue: return False len(self.urls_in_queue) > self.LINKS_LIMIT: return False : self.urls_in_queue.append(url)
还通过该方法将漏洞检测规则对应到URL上,然后组成一个元组,将这个元组传入一个用于扫描漏洞的队列中,代码如下
_ self.url_dict:
full_url url.rstrip() _[0]
url_description {: url.rstrip(), : full_url}
item (url_description, _[1], _[2], _[3], _[4], _[5])
self.url_queue.put(item)crawl_index方法:该方法使用beautifulSoup4爬取页面中的url链接。部分代码如下
soup BeautifulSoup(html_doc, ) links soup.find_all() l links: url l.get(, ) url, depth self._cal_depth(url) depth < self.max_depth: self._enqueue(url)
_update_severity方法:该方法用于更新serverity,如果规则中存在serverty字段,那么就将默认的final_serverity进行修改
severity > self.final_severity: self.final_severity severity
_scan_worker方法:该方法是用于执行漏洞扫描的关键代码如下
try:
item self.url_queue.get.0)
except:
return
try:
url_description, severity, tag, code, content_type, content_type_no item
url url_description[]
prefix url_description[]
except Exception, e:
logging.error( % e)
continue
not item or not url:
break
。。。。
status, headers, html_doc self._http_request(url)
(status [200, , , ]) and (self.has_404 or status!self._status):
code and status ! code:
continue
not tag or html_doc.find(tag) > :
content_type and headers.get(, ).find(content_type) < or \
content_type_no and headers.get(, ).find(content_type_no) >:
continue
self.lock.acquire()
not prefix self.results:
self.results[prefix] []
self.results[prefix].append({:status, : % (self.schema, self.host, url)} )
self._update_severity(severity)
self.lock.release()scan方法:这是一个多线程启动器,用来启动_scan_worker方法,最后返回测试的主机名,测试的结果和严重程度代码如下
i range(threads): t threading.Threadself._scan_worker) threads_list.append(t) t.start() t threads_list: t.join() key self.results.keys(): len(self.results[key]) > : del self.results[key] return self.host, self.results, self.final_severity
通过直接调用nmap对目标进行扫描,扫描结果储存在nmap_port_services.xml中,启动的命令为
nmap banner,http-headers,http-title nmap_port_services.xml
使用命令行调用AWVS对目标网站进行扫描,并在系统中启用一个线程去监测该进程的运行情况,代码如下
not os.path.exists(): time.sleep(20) print print popen subprocess.Popen( , subprocess.PIPE, subprocess.STDOUT) True: next_line popen.stdout.readline() next_line and popen.poll() ! None: break sys.stdout.write(next_line)
wvs.bat的代码如下:
@echo off /p please input wvs path,eg: [D:\Program Files (x86)\Web Vulnerability Scanner ]:: /f %%i (result.txt) ( %%i running %%i ...... /scan %%i /Profile default /SaveFolder d:\wwwscanresult\%pp%\ /save /Verbose )
首先是将nmap生成的XML文件通过import1.php脚本进行格式化后重新输出,核心代码如下:
@file_put_contents(, .., FILE_APPEND);
print .;
foreach (>port as ){
[];
(int)[];
>script[];
>service[];
;
..................;
print ;
@file_put_contents(, , FILE_APPEND);
}最后将所有的结果通过repoert_all函数将结果进行整合,将这些文件的路径汇总到left,html中。代码如下:
html_doc left_html.substitute({: , : ,
: , : ,
: })
with open(, ) as outFile:
outFile.write(html_doc)对于该系统而言只能说是能够满足个人的使用,且后期代码维护难度过大,不易进行扩展,使用第三方脚本时,直接是使用命令执行来获取数据,而不是通过导入模块的方式。不过系统的思路是值得借鉴的,尤其是在前期搜集子域名信息的时候是花了大功夫的,调用了很多第三方脚本,为的是尽可能的将目标的域名下的子域名收集完整,值得学习。而对于漏洞扫描模块而言,即使用了第三方脚本,也是用的AWVS对目标进行扫描,对于BBScan这个扫描储程序的规则设计值得学习,自定义化程度很高。总体来说整个扫描器的设计还是不错的,只是将这些第三方脚本进行整合时就显得有点仓促了。
感谢各位的阅读!关于“网络安全中漏洞自动化分析工具怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。