жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңkubernetesеҰӮдҪ•жҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңkubernetesеҰӮдҪ•жҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮвҖқеҗ§!
е…¬жңүдә‘зҡ„еҸ‘еұ•дёәдёҡеҠЎзҡ„зЁіе®ҡжҖ§гҖҒеҸҜжӢ“еұ•жҖ§гҖҒдҫҝеҲ©жҖ§еёҰжқҘдәҶжһҒеӨ§её®еҠ©гҖӮиҝҷз§Қз”Ёз§ҹд»Јжӣҝд№°гҖҒ并且жҸҗдҫӣе®Ңе–„зҡ„жҠҖжңҜж”ҜжҢҒе’Ңдҝқйҡңзҡ„жңҚеҠЎпјҢзҗҶеә”дёәдёҡеҠЎеёҰжқҘйҷҚжң¬еўһж•Ҳзҡ„ж•ҲжһңгҖӮдҪҶе®һйҷ…дёҠдёҡеҠЎдёҠдә‘并дёҚж„Ҹе‘ізқҖжҲҗжң¬дёҖе®ҡиҫғе°‘пјҢиҝҳйңҖйҖӮй…Қдә‘дёҠдёҡеҠЎзҡ„еә”з”ЁејҖеҸ‘гҖҒжһ¶жһ„и®ҫи®ЎгҖҒз®ЎзҗҶиҝҗз»ҙгҖҒеҗҲзҗҶдҪҝз”ЁзӯүеӨҡж–№йқўи§ЈеҶіж–№жЎҲпјҢжүҚиғҪзңҹжӯЈеҠ©еҠӣдёҡеҠЎзҡ„йҷҚжң¬еўһж•ҲгҖӮеңЁгҖҠKubernetes йҷҚжң¬еўһж•Ҳж ҮеҮҶжҢҮеҚ—гҖӢзі»еҲ— зҡ„дёҠдёҖзҜҮж–Үз« гҖҠе®№еҷЁеҢ–и®Ўз®—иө„жәҗеҲ©з”ЁзҺҮзҺ°иұЎеү–жһҗгҖӢдёӯеҸҜзңӢеҲ°пјҢIDC дёҠдә‘еҗҺиө„жәҗеҲ©з”ЁзҺҮжҸҗй«ҳжңүйҷҗпјҢеҚідҪҝе·Із»Ҹе®№еҷЁеҢ–пјҢиҠӮзӮ№зҡ„е№іеқҮеҲ©з”ЁзҺҮдҫқж—§д»…еңЁ 13% е·ҰеҸіпјҢиө„жәҗеҲ©з”ЁзҺҮзҡ„жҸҗеҚҮд»»йҮҚйҒ“иҝңгҖӮ
жң¬зҜҮж–Үз« е°ҶеёҰдҪ дәҶи§Јпјҡ дёәд»Җд№Ҳ Kubernetes йӣҶзҫӨдёӯзҡ„ CPU е’ҢеҶ…еӯҳиө„жәҗеҲ©з”ЁзҺҮ йҖҡеёёйғҪеҰӮжӯӨд№ӢдҪҺпјҹ зҺ°йҳ¶ж®өеңЁ TKE дёҠйқўжңүе“Әдәӣдә§е“ҒеҢ–зҡ„ж–№жі•еҸҜд»ҘиҪ»жқҫжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮпјҹ
дёәдҪ•иө„жәҗеҲ©з”ЁзҺҮйҖҡеёёйғҪеҰӮжӯӨд№ӢдҪҺпјҹйҰ–е…ҲеҸҜд»ҘзңӢзңӢеҮ дёӘдёҡеҠЎзҡ„е®һйҷ…дҪҝз”Ёиө„жәҗеңәжҷҜпјҡ
Kubernetes дёӯзҡ„ Request(иҜ·жұӮ) еӯ—ж®өз”ЁдәҺз®ЎзҗҶе®№еҷЁеҜ№ CPU е’ҢеҶ…еӯҳиө„жәҗйў„з•ҷзҡ„жңәеҲ¶пјҢдҝқиҜҒе®№еҷЁиҮіе°‘еҸҜд»ҘиҫҫеҲ°зҡ„иө„жәҗйҮҸпјҢиҜҘйғЁеҲҶиө„жәҗдёҚиғҪиў«е…¶д»–е®№еҷЁжҠўеҚ пјҢе…·дҪ“еҸҜжҹҘзңӢгҖӮеҪ“ Request и®ҫзҪ®иҝҮе°ҸпјҢж— жі•дҝқиҜҒдёҡеҠЎзҡ„иө„жәҗйҮҸпјҢеҪ“дёҡеҠЎзҡ„иҙҹиҪҪеҸҳй«ҳж—¶ж— еҠӣжүҝиҪҪпјҢеӣ жӯӨз”ЁжҲ·йҖҡеёёд№ жғҜе°Ҷ Request и®ҫзҪ®еҫ—еҫҲй«ҳпјҢд»ҘдҝқиҜҒжңҚеҠЎзҡ„еҸҜйқ жҖ§гҖӮдҪҶе®һйҷ…дёҠпјҢдёҡеҠЎеңЁеӨ§еӨҡж•°ж—¶ж®өж—¶иҙҹиҪҪдёҚдјҡеҫҲй«ҳгҖӮд»Ҙ CPU дёәдҫӢпјҢдёӢеӣҫжҳҜжҹҗдёӘе®һйҷ…дёҡеҠЎеңәжҷҜдёӢе®№еҷЁзҡ„иө„жәҗйў„з•ҷпјҲRequestпјүе’Ңе®һйҷ…дҪҝз”ЁйҮҸпјҲCPU_Usageпјүе…ізі»еӣҫпјҡиө„жәҗйў„з•ҷиҝңеӨ§дәҺе®һйҷ…дҪҝз”ЁйҮҸпјҢдёӨиҖ…д№Ӣй—ҙе·®еҖјжүҖеҜ№еә”зҡ„иө„жәҗдёҚиғҪиў«е…¶д»–иҙҹиҪҪдҪҝз”ЁпјҢеӣ жӯӨ Request и®ҫзҪ®иҝҮеӨ§еҠҝеҝ…дјҡйҖ жҲҗиҫғеӨ§зҡ„иө„жәҗжөӘиҙ№гҖӮ 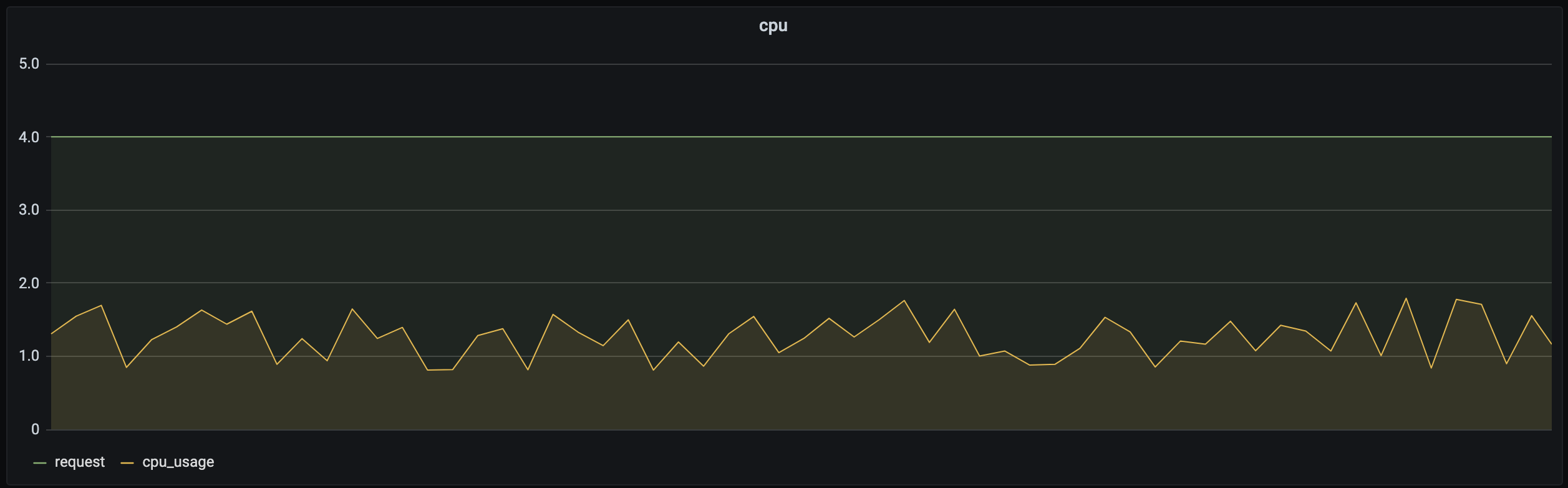
еҰӮдҪ•и§ЈеҶіиҝҷж ·зҡ„й—®йўҳпјҹзҺ°йҳ¶ж®өйңҖиҰҒз”ЁжҲ·иҮӘе·ұж №жҚ®е®һйҷ…зҡ„иҙҹиҪҪжғ…еҶөи®ҫзҪ®жӣҙеҗҲзҗҶзҡ„ RequestгҖҒд»ҘеҸҠйҷҗеҲ¶дёҡеҠЎеҜ№иө„жәҗзҡ„ж— йҷҗиҜ·жұӮпјҢйҳІжӯўиө„жәҗиў«жҹҗдәӣдёҡеҠЎиҝҮеәҰеҚ з”ЁгҖӮиҝҷйҮҢеҸҜд»ҘеҸӮиҖғеҗҺж–Үдёӯзҡ„ Request Quota е’Ң Limit Ranges зҡ„и®ҫзҪ®гҖӮ жӯӨеӨ–пјҢTKE е°ҶжҺЁеҮә Request жҺЁиҚҗдә§е“ҒпјҢеё®еҠ©з”ЁжҲ·жҷәиғҪзј©е°Ҹ Request е’Ң Usage д№Ӣй—ҙзҡ„е·®еҖјпјҢеңЁдҝқйҡңдёҡеҠЎзҡ„зЁіе®ҡжҖ§зҡ„жғ…еҶөдёӢжңүж•ҲжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮ
еӨ§еӨҡж•°дёҡеҠЎеӯҳеңЁжіўеі°жіўи°·пјҢдҫӢеҰӮе…¬дәӨзі»з»ҹйҖҡеёёеңЁзҷҪеӨ©иҙҹиҪҪеўһеҠ пјҢеӨңжҷҡиҙҹиҪҪеҮҸе°‘пјӣжёёжҲҸдёҡеҠЎйҖҡеёёеңЁе‘Ёдә”жҷҡдёҠејҖе§ӢеҮәзҺ°жіўеі°пјҢеңЁе‘Ёж—ҘжҷҡејҖе§ӢеҮәзҺ°жіўи°·гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡеҗҢдёҖдёҡеҠЎеңЁдёҚеҗҢзҡ„ж—¶й—ҙж®өеҜ№иө„жәҗзҡ„иҜ·жұӮйҮҸдёҚеҗҢпјҢеҰӮжһңз”ЁжҲ·и®ҫзҪ®зҡ„жҳҜеӣәе®ҡзҡ„ RequestпјҢfеңЁиҙҹиҪҪиҫғдҪҺж—¶еҲ©з”ЁзҺҮеҫҲдҪҺгҖӮ 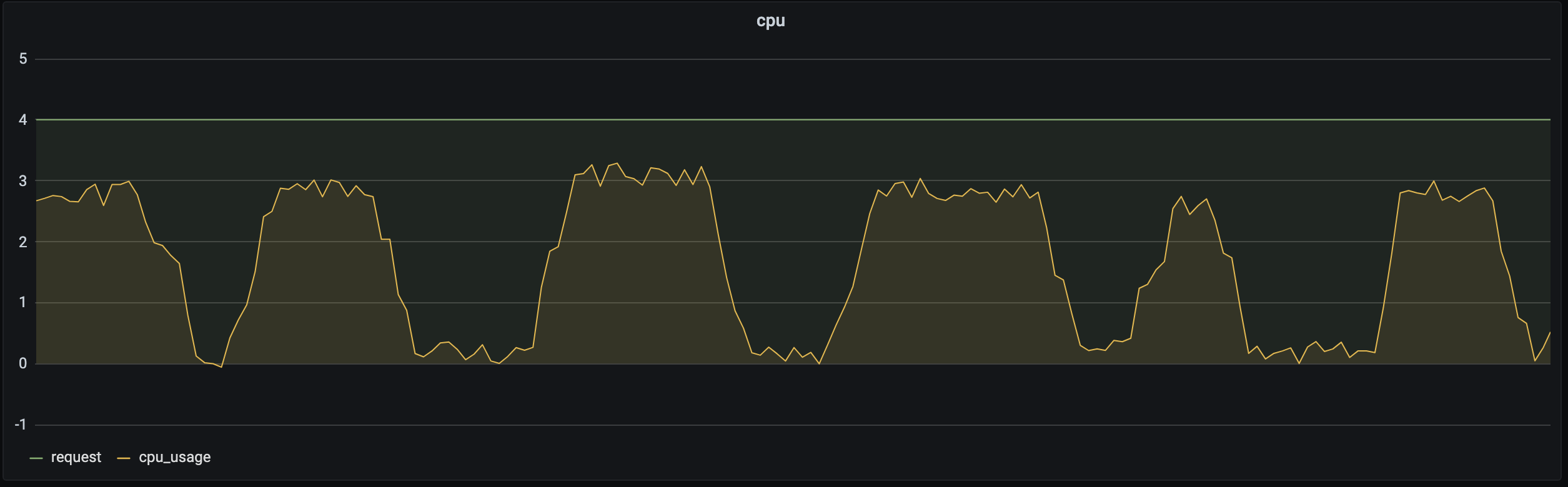
иҝҷж—¶еҸҜд»ҘйҖҡиҝҮеҠЁжҖҒи°ғж•ҙеүҜжң¬ж•°д»Ҙй«ҳиө„жәҗеҲ©з”ЁзҺҮжүҝиҪҪдёҡеҠЎзҡ„жіўеі°жіўи°·пјҢеҸҜд»ҘеҸӮиҖғеҗҺж–Үдёӯзҡ„ HPA гҖҒHPCгҖҒCAгҖӮ
еңЁзәҝдёҡеҠЎйҖҡеёёзҷҪеӨ©иҙҹиҪҪиҫғй«ҳпјҢеҜ№ж—¶е»¶иҰҒжұӮиҫғй«ҳпјҢеҝ…йЎ»дјҳе…Ҳи°ғеәҰе’ҢиҝҗиЎҢпјӣиҖҢзҰ»зәҝзҡ„и®Ўз®—еһӢдёҡеҠЎйҖҡеёёеҜ№иҝҗиЎҢж—¶ж®өе’Ң时延иҰҒжұӮзӣёеҜ№иҫғдҪҺпјҢзҗҶи®әдёҠеҸҜд»ҘеңЁеңЁзәҝдёҡеҠЎжіўи°·ж—¶иҝҗиЎҢгҖӮжӯӨеӨ–пјҢжңүдәӣдёҡеҠЎеұһдәҺи®Ўз®—еҜҶйӣҶеһӢпјҢеҜ№ CPU иө„жәҗж¶ҲиҖ—иҫғеӨҡпјҢиҖҢжңүдәӣдёҡеҠЎеұһдәҺеҶ…еӯҳеҜҶйӣҶеһӢпјҢеҜ№еҶ…еӯҳж¶ҲиҖ—иҫғеӨҡгҖӮ
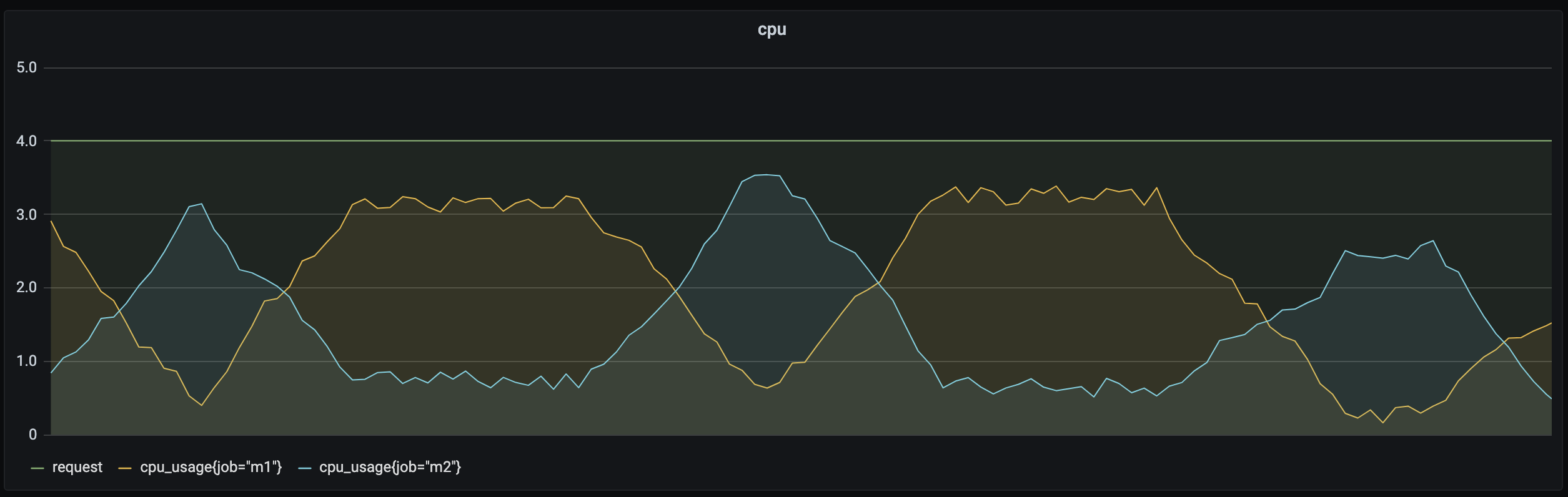
еҰӮдёҠеӣҫжүҖзӨәпјҢйҖҡиҝҮеңЁзҰ»зәҝж··йғЁеҸҜд»ҘеҠЁжҖҒи°ғеәҰзҰ»зәҝдёҡеҠЎе’ҢеңЁзәҝдёҡеҠЎпјҢи®©дёҚеҗҢзұ»еһӢдёҡеҠЎеңЁдёҚеҗҢзҡ„ж—¶й—ҙж®өиҝҗиЎҢд»ҘжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮеҜ№дәҺи®Ўз®—еҜҶйӣҶеһӢдёҡеҠЎе’ҢеҶ…еӯҳеҜҶйӣҶеһӢдёҡеҠЎпјҢеҸҜд»ҘдҪҝз”ЁдәІе’ҢжҖ§и°ғеәҰпјҢдёәдёҡеҠЎеҲҶй…ҚжӣҙеҗҲйҖӮзҡ„иҠӮзӮ№пјҢжңүж•ҲжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮе…·дҪ“ж–№ејҸеҸҜеҸӮиҖғеҗҺж–Үдёӯзҡ„зҰ»еңЁзәҝж··йғЁе’ҢдәІе’ҢжҖ§и°ғеәҰгҖӮ
и…ҫи®Ҝдә‘е®№еҷЁжңҚеҠЎ TKE еҹәдәҺеӨ§йҮҸзҡ„з”ЁжҲ·е®һйҷ…дёҡеҠЎпјҢе·Із»Ҹдә§е“ҒеҢ–дәҶдёҖзі»еҲ—е·Ҙе…·пјҢеё®еҠ©з”ЁжҲ·иҪ»жқҫжңүж•Ҳзҡ„жҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮдё»иҰҒд»ҺдёӨж–№йқўзқҖжүӢпјҡдёҖжҳҜеҲ©з”ЁеҺҹз”ҹзҡ„ Kubernetes иғҪеҠӣжүӢеҠЁиҝӣиЎҢиө„жәҗзҡ„еҲ’еҲҶе’ҢйҷҗеҲ¶пјӣдәҢжҳҜз»“еҗҲдёҡеҠЎзү№жҖ§зҡ„иҮӘеҠЁеҢ–ж–№жЎҲгҖӮ 
и®ҫжғіпјҢдҪ жҳҜдёӘйӣҶзҫӨз®ЎзҗҶе‘ҳпјҢзҺ°еңЁжңү4дёӘдёҡеҠЎйғЁй—ЁдҪҝз”ЁеҗҢдёҖдёӘйӣҶзҫӨпјҢдҪ зҡ„иҙЈд»»жҳҜдҝқиҜҒдёҡеҠЎзЁіе®ҡжҖ§зҡ„еүҚжҸҗдёӢпјҢи®©дёҡеҠЎзңҹжӯЈеҒҡеҲ°иө„жәҗзҡ„жҢүйңҖдҪҝз”ЁгҖӮдёәдәҶжңүж•ҲжҸҗеҚҮйӣҶзҫӨж•ҙдҪ“зҡ„иө„жәҗеҲ©з”ЁзҺҮпјҢиҝҷж—¶е°ұйңҖиҰҒйҷҗеҲ¶еҗ„дёҡеҠЎдҪҝз”Ёиө„жәҗзҡ„дёҠйҷҗпјҢд»ҘеҸҠйҖҡиҝҮдёҖдәӣй»ҳи®ӨеҖјйҳІжӯўдёҡеҠЎиҝҮйҮҸдҪҝз”ЁгҖӮ
зҗҶжғіжғ…еҶөдёӢпјҢдёҡеҠЎеә”иҜҘж №жҚ®е®һйҷ…жғ…еҶөпјҢи®ҫзҪ®еҗҲзҗҶзҡ„ Request е’Ң LimitгҖӮпјҲRequest з”ЁдәҺеҜ№иө„жәҗзҡ„еҚ дҪҚпјҢиЎЁзӨәе®№еҷЁиҮіе°‘еҸҜд»ҘиҺ·еҫ—зҡ„иө„жәҗпјӣLimit з”ЁдәҺеҜ№иө„жәҗзҡ„йҷҗеҲ¶пјҢиЎЁзӨәе®№еҷЁиҮіеӨҡеҸҜд»ҘиҺ·еҫ—зҡ„иө„жәҗгҖӮпјүиҝҷж ·жӣҙеҲ©дәҺе®№еҷЁзҡ„еҒҘеә·иҝҗиЎҢгҖҒиө„жәҗзҡ„е……еҲҶдҪҝз”ЁгҖӮдҪҶе®һйҷ…дёҠз”ЁжҲ·з»Ҹеёёеҝҳи®°и®ҫзҪ®е®№еҷЁеҜ№иө„жәҗзҡ„ Request е’Ң LimitгҖӮжӯӨеӨ–пјҢеҜ№дәҺе…ұдә«дҪҝз”ЁдёҖдёӘйӣҶзҫӨзҡ„еӣўйҳҹ/йЎ№зӣ®жқҘиҜҙпјҢ他们йҖҡеёёйғҪе°ҶиҮӘе·ұе®№еҷЁзҡ„ Request е’Ң Limit и®ҫзҪ®еҫ—еҫҲй«ҳд»ҘдҝқиҜҒиҮӘе·ұжңҚеҠЎзҡ„зЁіе®ҡжҖ§гҖӮеҰӮжһңдҪ дҪҝз”Ёзҡ„жҳҜ TKE зҡ„жҺ§еҲ¶еҸ°пјҢеҲӣе»әиҙҹиҪҪж—¶дјҡз»ҷжүҖжңүзҡ„е®№еҷЁи®ҫзҪ®еҰӮдёӢй»ҳи®ӨеҖјгҖӮиҜҘй»ҳи®ӨеҖјжҳҜ TKE ж №жҚ®зңҹе®һдёҡеҠЎеҲҶжһҗйў„дј°еҫ—еҮәпјҢе’Ңе…·дҪ“зҡ„дёҡеҠЎйңҖжұӮд№Ӣй—ҙеҸҜиғҪеӯҳеңЁеҒҸе·®гҖӮ
| Request | Limit | |
|---|---|---|
| CPU(ж ё) | 0.25 | 0.5 |
| Memory(MiB) | 256 | 1024 |
дёәдәҶжӣҙз»ҶзІ’еәҰзҡ„еҲ’еҲҶе’Ңз®ЎзҗҶиө„жәҗпјҢеҸҜд»ҘеңЁ TKE дёҠи®ҫзҪ®е‘ҪеҗҚз©әй—ҙзә§еҲ«зҡ„ Resource Quota д»ҘеҸҠ Limit RangesгҖӮ
еҰӮжһңдҪ з®ЎзҗҶзҡ„жҹҗдёӘйӣҶзҫӨжңү4дёӘдёҡеҠЎпјҢдёәдәҶе®һзҺ°дёҡеҠЎй—ҙзҡ„йҡ”зҰ»е’Ңиө„жәҗзҡ„йҷҗеҲ¶пјҢдҪ еҸҜд»ҘдҪҝз”Ёе‘ҪеҗҚз©әй—ҙе’Ң Resource Quota
Resource Quota з”ЁдәҺи®ҫзҪ®е‘ҪеҗҚз©әй—ҙиө„жәҗзҡ„дҪҝз”Ёй…ҚйўқпјҢе‘ҪеҗҚз©әй—ҙжҳҜ Kubernetes йӣҶзҫӨйҮҢйқўзҡ„дёҖдёӘйҡ”зҰ»еҲҶеҢәпјҢдёҖдёӘйӣҶзҫӨйҮҢйқўйҖҡеёёеҢ…еҗ«еӨҡдёӘе‘ҪеҗҚз©әй—ҙпјҢдҫӢеҰӮ Kubernetes з”ЁжҲ·йҖҡеёёдјҡе°ҶдёҚеҗҢзҡ„дёҡеҠЎж”ҫеңЁдёҚеҗҢзҡ„е‘ҪеҗҚз©әй—ҙйҮҢпјҢдҪ еҸҜд»ҘдёәдёҚеҗҢзҡ„е‘ҪеҗҚз©әй—ҙи®ҫзҪ®дёҚеҗҢзҡ„ Resource QuotaпјҢд»ҘйҷҗеҲ¶дёҖдёӘе‘ҪеҗҚз©әй—ҙеҜ№йӣҶзҫӨж•ҙдҪ“иө„жәҗзҡ„дҪҝз”ЁйҮҸпјҢиҫҫеҲ°йў„еҲҶй…Қе’ҢйҷҗеҲ¶зҡ„ж•ҲжһңгҖӮResource Quota дё»иҰҒдҪңз”ЁдәҺеҰӮдёӢж–№йқўпјҢе…·дҪ“еҸҜжҹҘзңӢгҖӮ
и®Ўз®—иө„жәҗпјҡжүҖжңүе®№еҷЁеҜ№ CPU е’Ң еҶ…еӯҳзҡ„ Request д»ҘеҸҠ Limit зҡ„жҖ»е’Ң
еӯҳеӮЁиө„жәҗпјҡжүҖжңү PVC зҡ„еӯҳеӮЁиө„жәҗиҜ·жұӮжҖ»е’Ң
еҜ№иұЎж•°йҮҸпјҡPVC/Service/Configmap/Deploymentзӯүиө„жәҗеҜ№иұЎж•°йҮҸзҡ„жҖ»е’Ң
з»ҷдёҚеҗҢзҡ„йЎ№зӣ®/еӣўйҳҹ/дёҡеҠЎеҲҶй…ҚдёҚеҗҢзҡ„е‘ҪеҗҚз©әй—ҙпјҢйҖҡиҝҮи®ҫзҪ®жҜҸдёӘе‘ҪеҗҚз©әй—ҙиө„жәҗзҡ„ Resource Quota д»ҘиҫҫеҲ°иө„жәҗеҲҶй…Қзҡ„зӣ®зҡ„
и®ҫзҪ®дёҖдёӘе‘ҪеҗҚз©әй—ҙзҡ„иө„жәҗдҪҝз”Ёж•°йҮҸзҡ„дёҠйҷҗд»ҘжҸҗй«ҳйӣҶзҫӨзҡ„зЁіе®ҡжҖ§пјҢйҳІжӯўдёҖдёӘе‘ҪеҗҚз©әй—ҙеҜ№иө„жәҗзҡ„еӨҡеәҰдҫөеҚ е’Ңж¶ҲиҖ—
TKE дёҠе·Із»Ҹе®һзҺ°еҜ№ Resource Quota зҡ„дә§е“ҒеҢ–пјҢдҪ еҸҜд»ҘзӣҙжҺҘеңЁжҺ§еҲ¶еҸ°еҲ©з”Ё Resource Quota йҷҗеҲ¶дёҖдёӘе‘ҪеҗҚз©әй—ҙзҡ„иө„жәҗдҪҝз”ЁйҮҸпјҢе…·дҪ“еҸҜеҸӮиҖғж–ҮжЎЈгҖӮ 
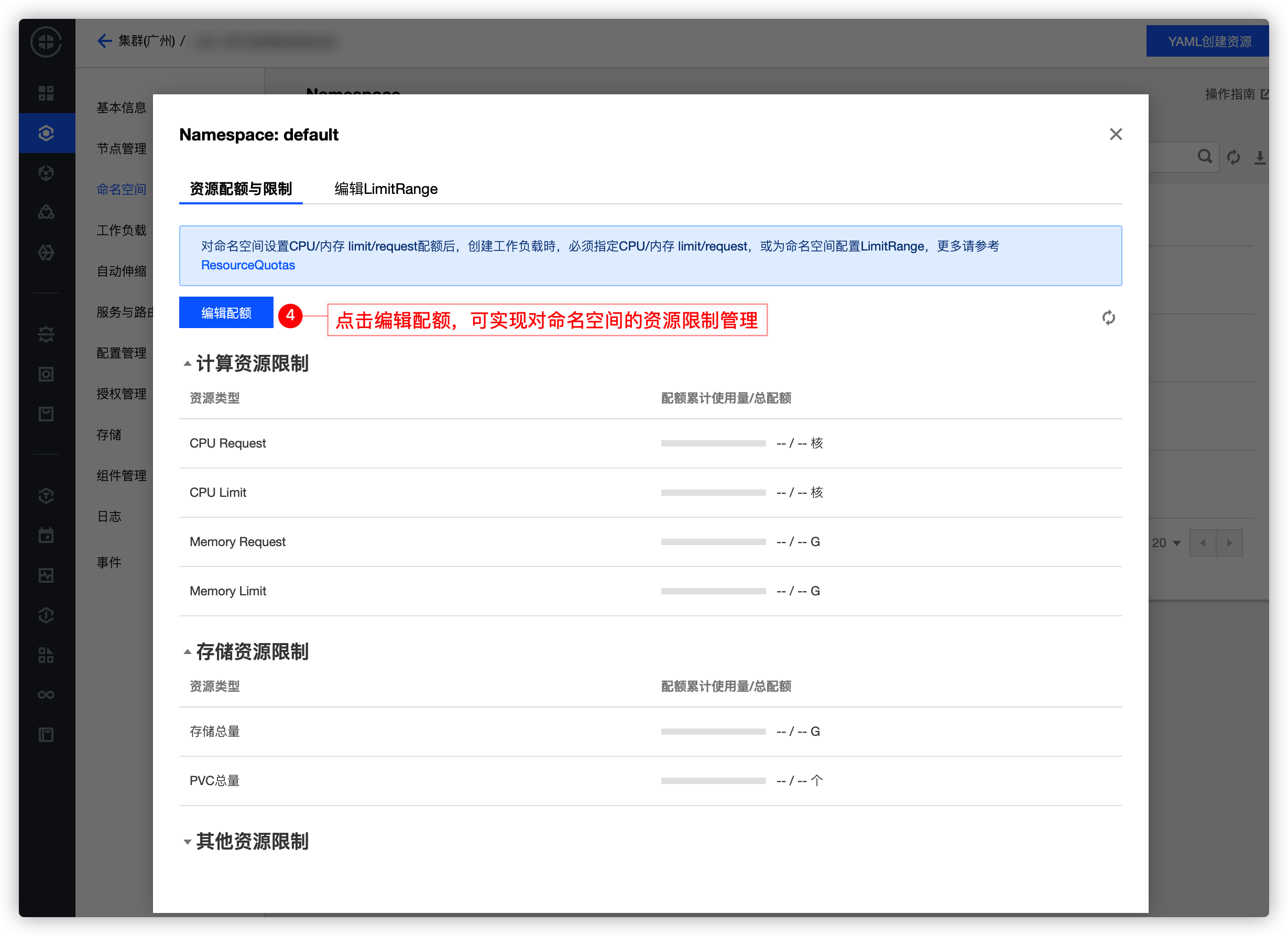
з”ЁжҲ·з»Ҹеёёеҝҳи®°и®ҫзҪ®иө„жәҗзҡ„ Request е’Ң LimitпјҢжҲ–иҖ…е°ҶеҖји®ҫзҪ®еҫ—еҫҲеӨ§жҖҺд№ҲеҠһпјҹдҪңдёәз®ЎзҗҶе‘ҳпјҢеҰӮжһңеҸҜд»ҘдёәдёҚеҗҢзҡ„дёҡеҠЎи®ҫзҪ®дёҚеҗҢиө„жәҗдҪҝз”Ёй»ҳи®ӨеҖјд»ҘеҸҠиҢғеӣҙпјҢеҸҜд»Ҙжңүж•ҲеҮҸе°‘дёҡеҠЎеҲӣе»әж—¶зҡ„е·ҘдҪңйҮҸеҗҢж—¶пјҢйҷҗеҲ¶дёҡеҠЎеҜ№иө„жәҗзҡ„иҝҮеәҰдҫөеҚ гҖӮ
дёҺ Resource Quota еҜ№е‘ҪеҗҚз©әй—ҙж•ҙдҪ“зҡ„иө„жәҗйҷҗеҲ¶дёҚеҗҢпјҢLimit Ranges йҖӮз”ЁдәҺдёҖдёӘе‘ҪеҗҚз©әй—ҙдёӢзҡ„еҚ•дёӘе®№еҷЁгҖӮеҸҜд»ҘйҳІжӯўз”ЁжҲ·еңЁе‘ҪеҗҚз©әй—ҙеҶ…еҲӣе»әеҜ№иө„жәҗз”іиҜ·иҝҮе°ҸжҲ–иҝҮеӨ§е®№еҷЁпјҢйҳІжӯўз”ЁжҲ·еҝҳи®°и®ҫзҪ®е®№еҷЁзҡ„ Request е’Ң LimitгҖӮLimit Ranges дё»иҰҒдҪңз”ЁдәҺеҰӮдёӢж–№йқўпјҢе…·дҪ“еҸҜжҹҘзңӢгҖӮ
и®Ўз®—иө„жәҗпјҡеҜ№жүҖжңүе®№еҷЁи®ҫзҪ® CPU е’ҢеҶ…еӯҳдҪҝз”ЁйҮҸзҡ„иҢғеӣҙ
еӯҳеӮЁиө„жәҗпјҡеҜ№жүҖжңү PVC иғҪз”іиҜ·зҡ„еӯҳеӮЁз©әй—ҙзҡ„иҢғеӣҙ
жҜ”дҫӢи®ҫзҪ®пјҡжҺ§еҲ¶дёҖз§Қиө„жәҗ Request е’Ң Limit д№Ӣй—ҙжҜ”дҫӢ
й»ҳи®ӨеҖјпјҡеҜ№жүҖжңүе®№еҷЁи®ҫзҪ®й»ҳи®Өзҡ„ Request/LimitпјҢеҰӮжһңе®№еҷЁжңӘжҢҮе®ҡиҮӘе·ұзҡ„еҶ…еӯҳиҜ·жұӮе’ҢйҷҗеҲ¶пјҢе°Ҷдёәе®ғжҢҮе®ҡй»ҳи®Өзҡ„еҶ…еӯҳиҜ·жұӮе’ҢйҷҗеҲ¶
и®ҫзҪ®иө„жәҗдҪҝз”Ёй»ҳи®ӨеҖјпјҢд»ҘйҳІз”ЁжҲ·йҒ—еҝҳпјҢд№ҹеҸҜд»ҘйҒҝе…Қ QoS й©ұйҖҗйҮҚиҰҒзҡ„ Pod
дёҚеҗҢзҡ„дёҡеҠЎйҖҡеёёиҝҗиЎҢеңЁдёҚеҗҢзҡ„е‘ҪеҗҚз©әй—ҙйҮҢпјҢдёҚеҗҢзҡ„дёҡеҠЎйҖҡеёёиө„жәҗдҪҝз”Ёжғ…еҶөдёҚеҗҢпјҢдёәдёҚеҗҢзҡ„е‘ҪеҗҚз©әй—ҙи®ҫзҪ®дёҚеҗҢзҡ„ Request/Limit еҸҜд»ҘжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮ
йҷҗеҲ¶е®№еҷЁдёӘеҜ№иө„жәҗдҪҝз”Ёзҡ„дёҠдёӢйҷҗпјҢдҝқиҜҒе®№еҷЁжӯЈеёёиҝҗиЎҢзҡ„жғ…еҶөдёӢпјҢйҷҗеҲ¶е…¶иҜ·жұӮиҝҮеӨҡиө„жәҗ
TKE дёҠе·Із»Ҹе®һзҺ°еҜ№ Limit Ranges зҡ„дә§е“ҒеҢ–пјҢдҪ еҸҜд»ҘзӣҙжҺҘеңЁжҺ§еҲ¶еҸ°з®ЎзҗҶе‘ҪеҗҚз©әй—ҙзҡ„ Limit RangesпјҢе…·дҪ“еҸҜеҸӮиҖғж–ҮжЎЈгҖӮ 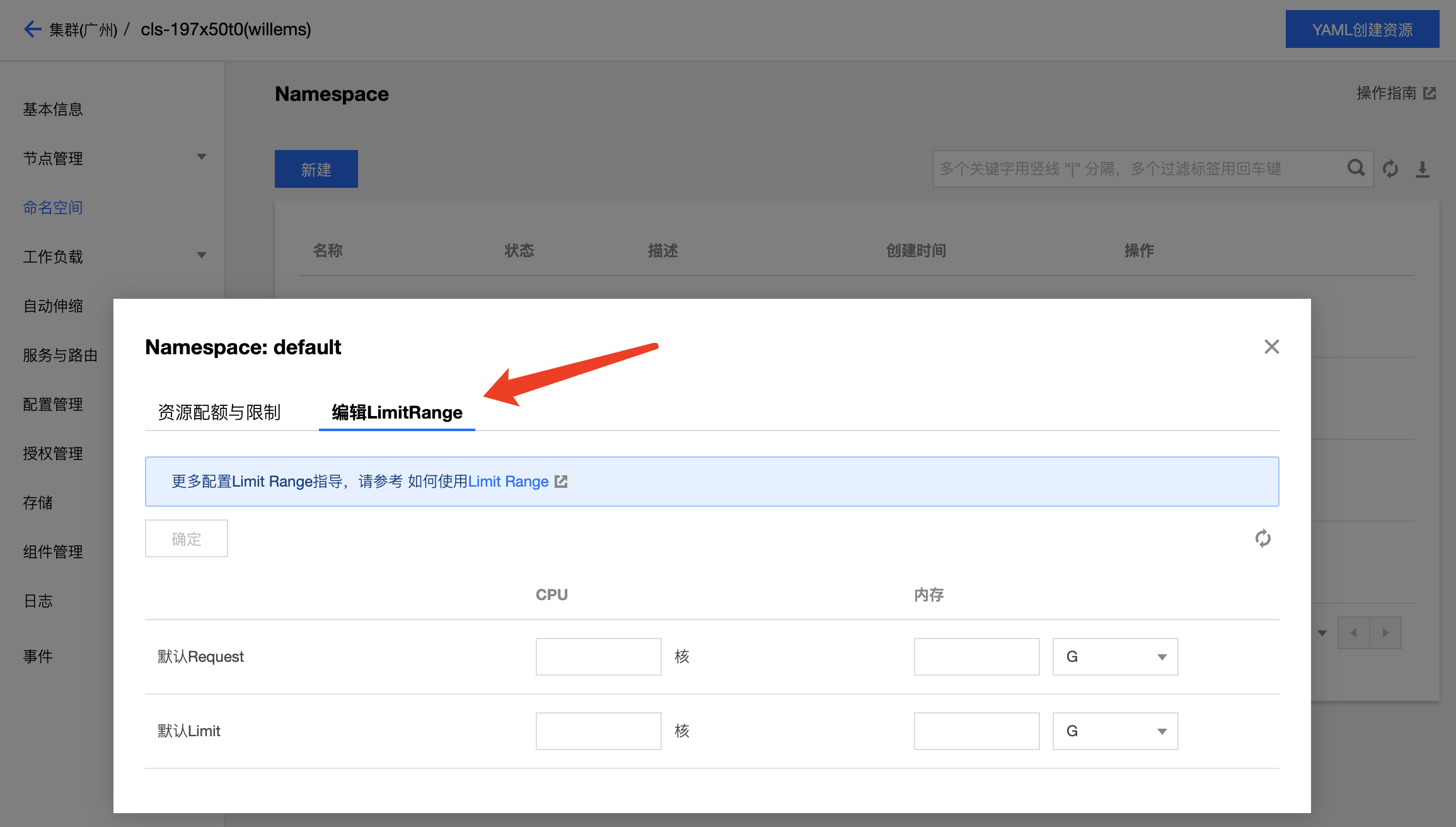
дёҠйқўжҸҗеҲ°зҡ„еҲ©з”Ё Resource Quota е’Ң Limit Ranges жқҘеҲҶй…Қе’ҢйҷҗеҲ¶иө„жәҗзҡ„ж–№жі•дҫқиө–з»ҸйӘҢе’ҢжүӢе·ҘпјҢдё»иҰҒи§ЈеҶізҡ„жҳҜиө„жәҗиҜ·жұӮе’ҢеҲҶй…ҚдёҚеҗҲзҗҶгҖӮеҰӮдҪ•жӣҙиҮӘеҠЁеҢ–зҡ„еҠЁжҖҒи°ғж•ҙд»ҘжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮжҳҜз”ЁжҲ·жӣҙе…іеҝғзҡ„й—®йўҳпјҢжҺҘдёӢжқҘд»Һеј№жҖ§дјёзј©гҖҒи°ғеәҰгҖҒеңЁзҰ»зәҝж··йғЁдёүеӨ§дә§е“ҒеҢ–зҡ„ж–№еҗ‘пјҢиҜҰиҝ°еҰӮдҪ•жҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮ
еҰӮдёҠйқўиө„жәҗжөӘиҙ№еңәжҷҜ2жүҖиҜҙпјҢеҰӮжһңдҪ зҡ„дёҡеҠЎжҳҜеӯҳеңЁжіўеі°жіўи°·зҡ„пјҢеӣәе®ҡзҡ„иө„жәҗ Request жіЁе®ҡеңЁжіўи°·ж—¶дјҡйҖ жҲҗиө„жәҗжөӘиҙ№пјҢй’ҲеҜ№иҝҷж ·зҡ„еңәжҷҜпјҢеҰӮжһңжіўеі°зҡ„ж—¶еҖҷеҸҜд»ҘиҮӘеҠЁеўһеҠ дёҡеҠЎиҙҹиҪҪзҡ„еүҜжң¬ж•°йҮҸпјҢжіўи°·зҡ„ж—¶еҖҷеҸҜд»ҘиҮӘеҠЁеҮҸе°‘дёҡеҠЎиҙҹиҪҪзҡ„еүҜжң¬ж•°йҮҸпјҢе°Ҷжңүж•ҲжҸҗеҚҮиө„жәҗж•ҙдҪ“еҲ©з”ЁзҺҮгҖӮ
HPAпјҲHorizontal Pod AutoscalerпјүеҸҜд»ҘеҹәдәҺдёҖдәӣжҢҮж ҮпјҲдҫӢеҰӮ CPUгҖҒеҶ…еӯҳзҡ„еҲ©з”ЁзҺҮпјүиҮӘеҠЁжү©зј© Deployment е’Ң StatefulSet дёӯзҡ„ Pod еүҜжң¬зҡ„ж•°йҮҸпјҢиҫҫеҲ°е·ҘдҪңиҙҹиҪҪзЁіе®ҡзҡ„зӣ®зҡ„пјҢзңҹжӯЈеҒҡеҲ°жҢүйңҖдҪҝз”ЁгҖӮ
жөҒйҮҸзӘҒеҸ‘пјҡзӘҒ然жөҒйҮҸеўһеҠ пјҢиҙҹиҪҪиҝҮиҪҪж—¶дјҡиҮӘеҠЁеўһеҠ Pod ж•°йҮҸд»ҘеҸҠж—¶е“Қеә”
иҮӘеҠЁзј©е®№пјҡжөҒйҮҸиҫғе°‘ж—¶пјҢиҙҹиҪҪеҜ№иө„жәҗзҡ„еҲ©з”ЁзҺҮиҝҮдҪҺж—¶дјҡиҮӘеҠЁеҮҸе°‘ Pod зҡ„ж•°йҮҸд»ҘйҒҝе…ҚжөӘиҙ№
TKE еҹәдәҺ Custom Metrics API ж”ҜжҢҒи®ёеӨҡз”ЁдәҺеј№жҖ§дјёзј©зҡ„жҢҮж ҮпјҢж¶өзӣ– CPUгҖҒеҶ…еӯҳгҖҒзЎ¬зӣҳгҖҒзҪ‘з»ңд»ҘеҸҠ GPU зӣёе…ізҡ„жҢҮж ҮпјҢиҰҶзӣ–з»қеӨ§еӨҡж•°зҡ„ HPA еј№жҖ§дјёзј©еңәжҷҜпјҢиҜҰз»ҶеҲ—иЎЁиҜ·еҸӮи§Ғ иҮӘеҠЁдјёзј©жҢҮж ҮиҜҙжҳҺгҖӮжӯӨеӨ–пјҢй’ҲеҜ№дҫӢеҰӮеҹәдәҺдёҡеҠЎеҚ•еүҜжң¬ QPS еӨ§е°ҸжқҘиҝӣиЎҢиҮӘеҠЁжү©зј©е®№зӯүеӨҚжқӮеңәжҷҜпјҢеҸҜйҖҡиҝҮе®үиЈ… prometheus-adapter жқҘе®һзҺ°иҮӘеҠЁжү©зј©е®№пјҢе…·дҪ“еҸҜеҸӮиҖғж–ҮжЎЈгҖӮ 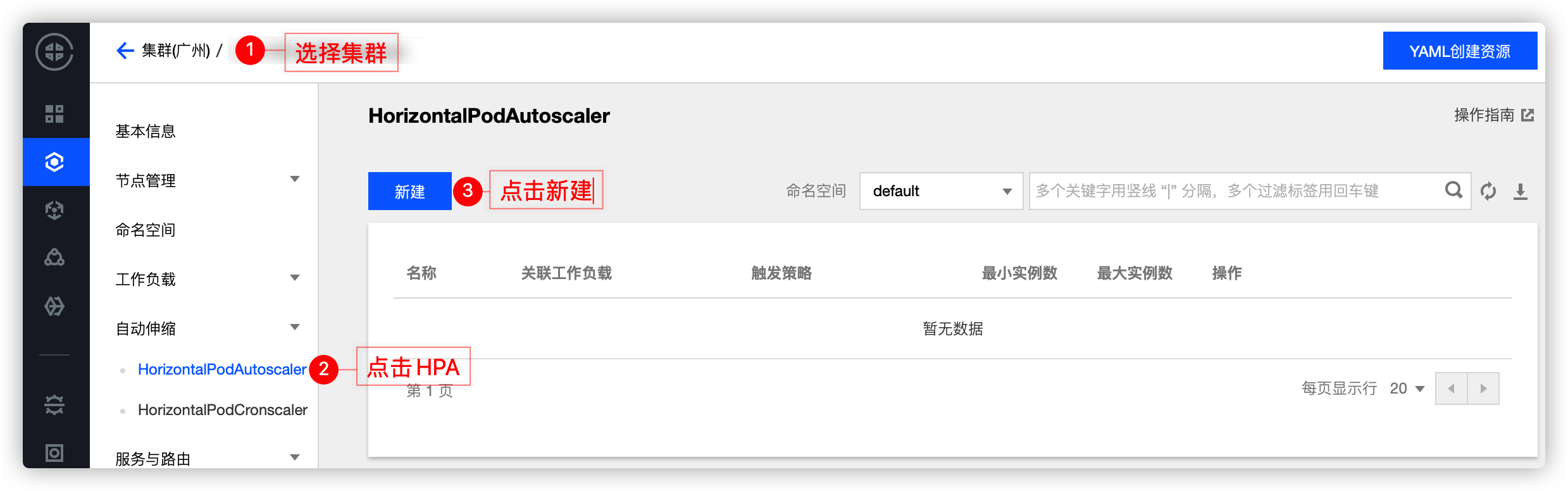
еҒҮи®ҫдҪ зҡ„дёҡеҠЎжҳҜз”өе•Ҷе№іеҸ°пјҢеҸҢеҚҒдёҖиҰҒиҝӣиЎҢдҝғй”Җжҙ»еҠЁпјҢиҝҷж—¶еҸҜд»ҘиҖғиҷ‘дҪҝз”Ё HPA иҮӘеҠЁжү©зј©е®№гҖӮдҪҶжҳҜ HPA йңҖиҰҒе…Ҳзӣ‘жҺ§еҗ„йЎ№жҢҮж ҮеҗҺпјҢеҶҚиҝӣиЎҢеҸҚеә”пјҢеҸҜиғҪжү©е®№йҖҹеәҰдёҚеӨҹеҝ«пјҢж— жі•еҸҠж—¶жүҝиҪҪй«ҳжөҒйҮҸгҖӮй’ҲеҜ№иҝҷз§Қжңүйў„жңҹзҡ„жөҒйҮҸжҡҙеўһпјҢеҰӮжһңиғҪжҸҗеүҚеҸ‘з”ҹеүҜжң¬жү©е®№пјҢе°Ҷжңүж•ҲжүҝиҪҪжөҒйҮҸдә•е–·гҖӮ HPCпјҲHorizontalPodCronscalerпјүжҳҜ TKE иҮӘз ”з»„д»¶пјҢж—ЁеңЁе®ҡж—¶жҺ§еҲ¶еүҜжң¬ж•°йҮҸпјҢд»ҘиҫҫеҲ°жҸҗеүҚжү©зј©е®№гҖҒе’ҢжҸҗеүҚи§ҰеҸ‘еҠЁжҖҒжү©е®№ж—¶иө„жәҗдёҚи¶ізҡ„еҪұе“ҚпјҢзӣёиҫғзӨҫеҢәзҡ„ CronHPAпјҢйўқеӨ–ж”ҜжҢҒпјҡ
дёҺ HPA з»“еҗҲпјҡеҸҜд»Ҙе®һзҺ°е®ҡж—¶ејҖеҗҜе’Ңе…ій—ӯ HPAпјҢи®©дҪ зҡ„дёҡеҠЎеңЁй«ҳеі°ж—¶жӣҙеј№жҖ§
дҫӢеӨ–ж—Ҙжңҹи®ҫзҪ®пјҡдёҡеҠЎзҡ„жөҒйҮҸдёҚеӨӘеҸҜиғҪж°ёиҝңйғҪжҳҜ规еҫӢзҡ„пјҢи®ҫзҪ®дҫӢеӨ–ж—ҘжңҹеҸҜд»ҘеҮҸе°‘жүӢе·Ҙи°ғж•ҙ HPC
еҚ•ж¬Ўжү§иЎҢпјҡд»ҘеҫҖзҡ„ CronHPA йғҪжҳҜж°ёд№…жү§иЎҢпјҢзұ»дјј CronjobпјҢеҚ•ж¬Ўжү§иЎҢеҸҜд»ҘжӣҙзҒөжҙ»зҡ„еә”еҜ№еӨ§дҝғеңәжҷҜ
д»ҘжёёжҲҸжңҚеҠЎдёәдҫӢпјҢд»Һе‘Ёдә”жҷҡдёҠеҲ°е‘Ёж—ҘжҷҡдёҠпјҢжёёжҲҸзҺ©е®¶ж•°йҮҸжҡҙеўһгҖӮеҰӮжһңеҸҜд»Ҙе°ҶжёёжҲҸжңҚеҠЎеҷЁеңЁжҳҹжңҹдә”жҷҡдёҠеүҚжү©еӨ§и§„жЁЎпјҢ并еңЁжҳҹжңҹж—ҘжҷҡдёҠеҗҺзј©ж”ҫдёәеҺҹе§Ӣ规模пјҢеҲҷеҸҜд»ҘдёәзҺ©е®¶жҸҗдҫӣжӣҙеҘҪзҡ„дҪ“йӘҢгҖӮеҰӮжһңдҪҝз”Ё HPAпјҢеҸҜиғҪеӣ дёәжү©е®№йҖҹеәҰдёҚеӨҹеҝ«еҜјиҮҙжңҚеҠЎеҸ—еҪұе“ҚгҖӮ
TKE дёҠе·Із»Ҹе®һзҺ°еҜ№ HPC зҡ„дә§е“ҒеҢ–пјҢдҪҶдҪ йңҖиҰҒжҸҗеүҚеңЁвҖқ组件管зҗҶвҖңйҮҢйқўе®үиЈ… HPCпјҢHPC дҪҝз”Ё CronTab иҜӯжі•ж јејҸгҖӮ
е®үиЈ…пјҡ 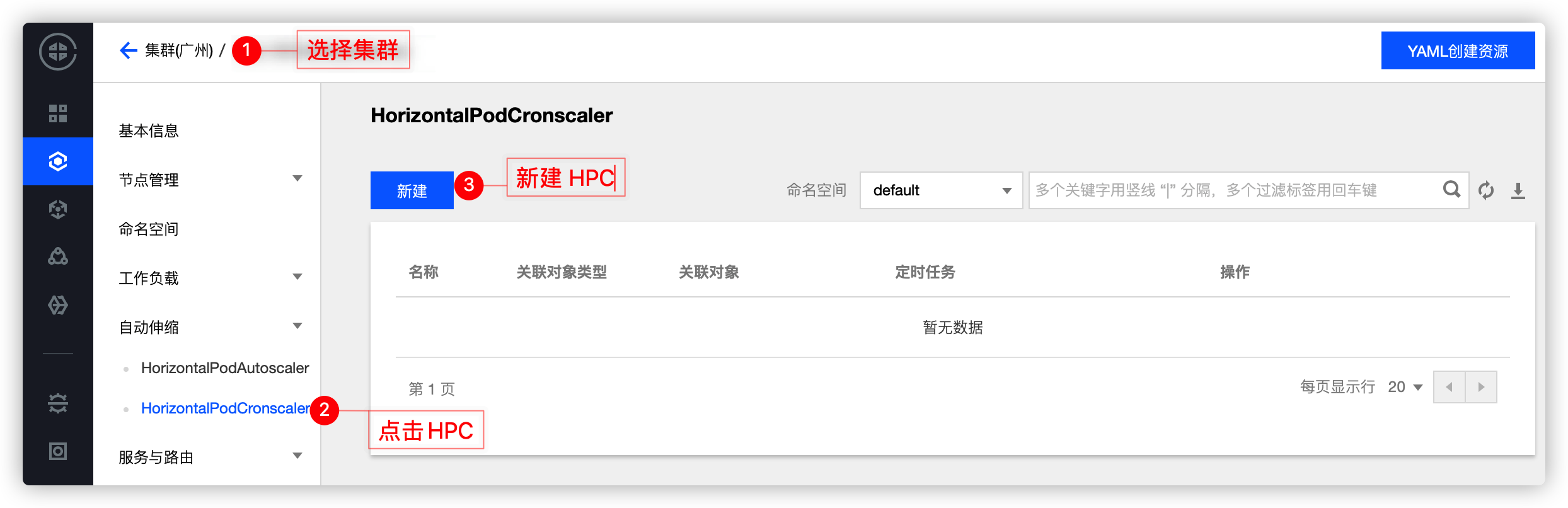
дҪҝз”Ёпјҡ 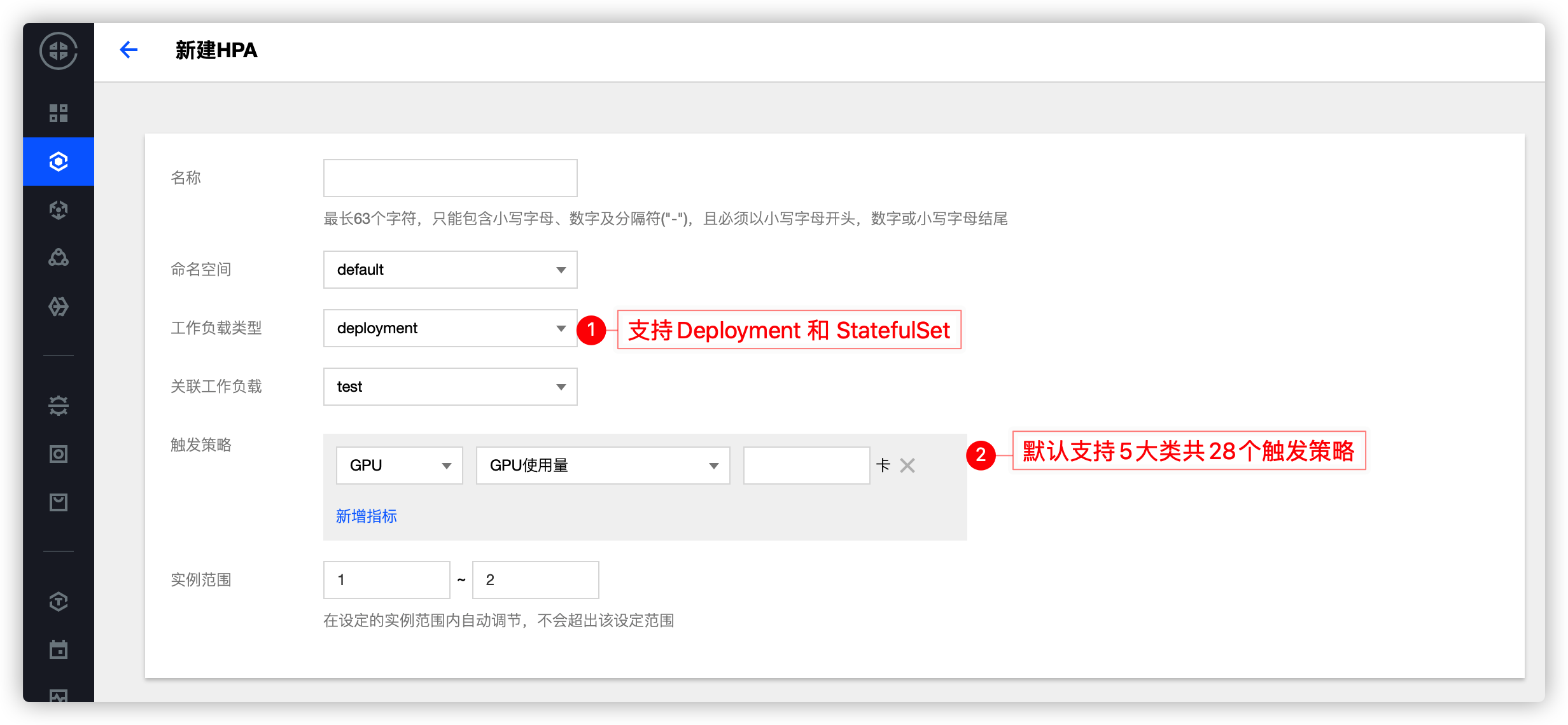
дёҠйқўжҸҗеҲ°зҡ„ HPA е’Ң HPCпјҢйғҪжҳҜеңЁдёҡеҠЎиҙҹиҪҪеұӮйқўзҡ„иҮӘеҠЁжү©зј©еүҜжң¬ж•°йҮҸпјҢд»ҘзҒөжҙ»еә”еҜ№жөҒйҮҸзҡ„жіўеі°жіўи°·пјҢжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮдҪҶжҳҜеҜ№дәҺйӣҶзҫӨж•ҙдҪ“иҖҢиЁҖпјҢиө„жәҗжҖ»ж•°жҳҜеӣәе®ҡзҡ„пјҢHPA е’Ң HPC еҸӘжҳҜи®©йӣҶзҫӨжңүжӣҙеӨҡз©әдҪҷзҡ„иө„жәҗпјҢжҳҜеҗҰжңүдёҖз§Қж–№жі•пјҢиғҪеңЁйӣҶзҫӨж•ҙдҪ“иҫғвҖңз©әвҖқж—¶еӣһ收йғЁеҲҶиө„жәҗпјҢиғҪеңЁйӣҶзҫӨж•ҙдҪ“иҫғвҖңж»ЎвҖқж—¶жү©е……йӣҶзҫӨж•ҙдҪ“иө„жәҗпјҹеӣ дёәйӣҶзҫӨж•ҙдҪ“иө„жәҗзҡ„дҪҝз”ЁйҮҸзӣҙжҺҘеҶіе®ҡдәҶиҙҰеҚ•иҙ№з”ЁпјҢиҝҷз§ҚйӣҶзҫӨзә§еҲ«зҡ„еј№жҖ§жү©зј©е°ҶзңҹжӯЈеё®еҠ©дҪ иҠӮзңҒдҪҝз”ЁжҲҗжң¬гҖӮ
CAпјҲCluster Autoscalerпјүз”ЁдәҺиҮӘеҠЁжү©зј©йӣҶзҫӨиҠӮзӮ№ж•°йҮҸпјҢд»ҘзңҹжӯЈе®һзҺ°иө„жәҗеҲ©з”ЁзҺҮзҡ„жҸҗеҚҮпјҢ并зӣҙжҺҘдҪңз”ЁдәҺз”ЁжҲ·зҡ„иҙ№з”ЁпјҢжҳҜйҷҚжң¬еўһж•Ҳзҡ„е…ій”®гҖӮ
еңЁдёҡеҠЎжіўеі°ж—¶пјҢж №жҚ®дёҡеҠЎзӘҒеўһзҡ„иҙҹиҪҪжү©е®№еҗҲйҖӮзҡ„иҠӮзӮ№
еңЁдёҡеҠЎжіўи°·ж—¶пјҢж №жҚ®иө„жәҗзҡ„з©әй—Іжғ…еҶөйҮҠж”ҫеӨҡдҪҷзҡ„иҠӮзӮ№
TKE дёҠзҡ„ CA жҳҜд»ҘиҠӮзӮ№жұ зҡ„еҪўжҖҒжқҘи®©з”ЁжҲ·дҪҝз”Ёзҡ„пјҢCA жҺЁиҚҗе’Ң HPA дёҖиө·дҪҝз”ЁпјҡHPA иҙҹиҙЈеә”з”ЁеұӮзҡ„жү©зј©е®№пјҢCA иҙҹиҙЈиө„жәҗеұӮпјҲиҠӮзӮ№еұӮпјүзҡ„жү©зј©е®№пјҢеҪ“ HPA жү©е®№йҖ жҲҗйӣҶзҫӨж•ҙдҪ“иө„жәҗдёҚи¶іж—¶пјҢдјҡеј•еҸ‘ Pod зҡ„ PendingпјҢPod Pending дјҡи§ҰеҸ‘ CA жү©е……иҠӮзӮ№жұ д»ҘеўһеҠ йӣҶзҫӨж•ҙдҪ“иө„жәҗйҮҸпјҢж•ҙдҪ“жү©е®№йҖ»иҫ‘еҸҜеҸӮиҖғдёӢеӣҫпјҡ
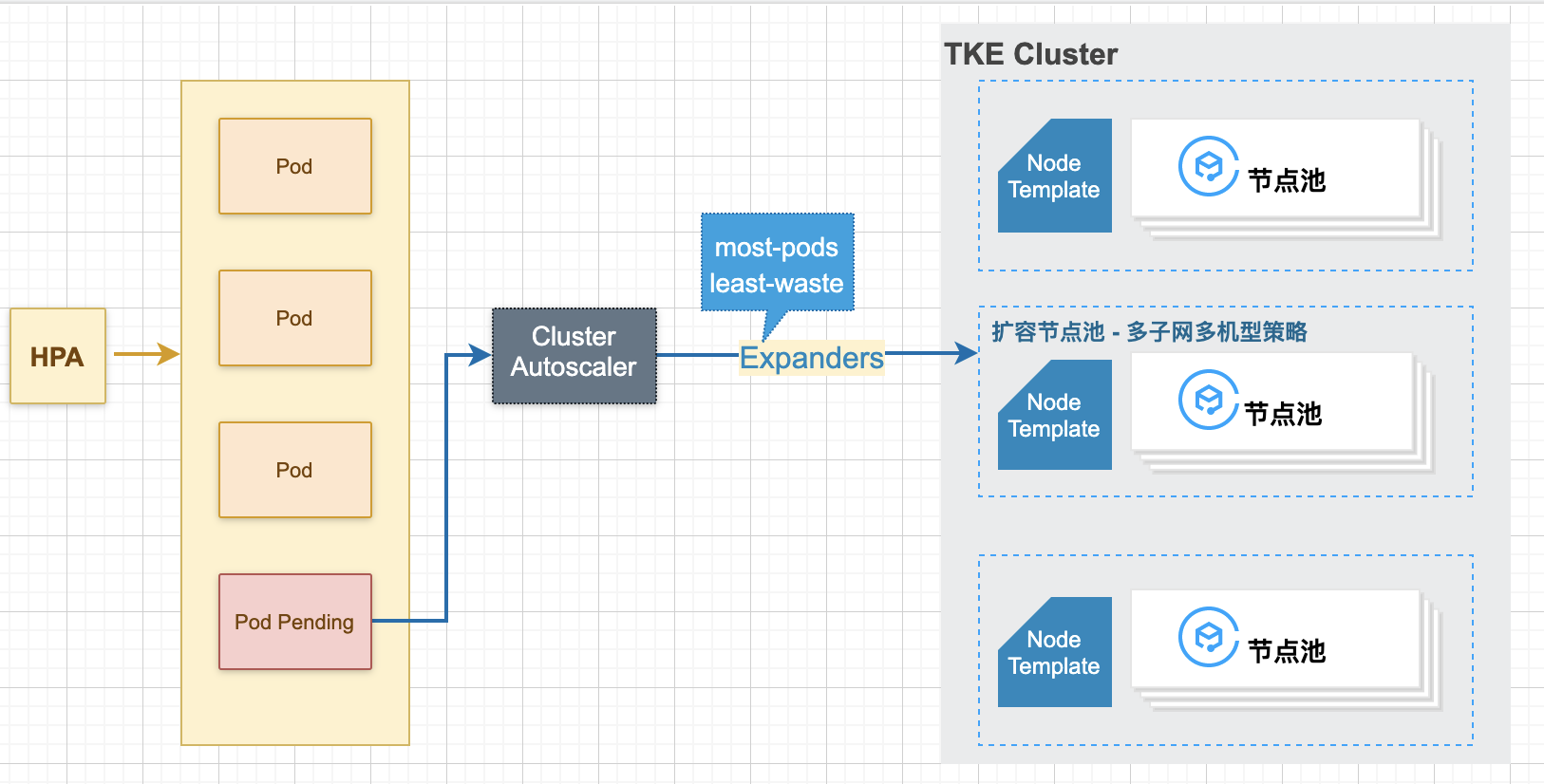 е…·дҪ“зҡ„еҸӮж•°й…ҚзҪ®ж–№ејҸд»ҘеҸҠеә”з”ЁеңәжҷҜеҸҜеҸӮиҖғгҖҠеғҸз®ЎзҗҶ Pod дёҖж ·з®ЎзҗҶ NodeгҖӢпјҢжҲ–иҖ…еҸҜеҸӮиҖғи…ҫи®Ҝдә‘е®№еҷЁжңҚеҠЎе®ҳж–№ж–ҮжЎЈгҖӮ
е…·дҪ“зҡ„еҸӮж•°й…ҚзҪ®ж–№ејҸд»ҘеҸҠеә”з”ЁеңәжҷҜеҸҜеҸӮиҖғгҖҠеғҸз®ЎзҗҶ Pod дёҖж ·з®ЎзҗҶ NodeгҖӢпјҢжҲ–иҖ…еҸҜеҸӮиҖғи…ҫи®Ҝдә‘е®№еҷЁжңҚеҠЎе®ҳж–№ж–ҮжЎЈгҖӮ
Kubernetes и°ғеәҰжңәеҲ¶жҳҜ Kubernetes еҺҹз”ҹжҸҗдҫӣзҡ„дёҖз§Қй«ҳж•Ҳдјҳйӣ…зҡ„иө„жәҗеҲҶй…ҚжңәеҲ¶пјҢе®ғзҡ„ж ёеҝғеҠҹиғҪжҳҜдёәжҜҸдёӘ Pod жүҫеҲ°жңҖйҖӮеҗҲе®ғзҡ„иҠӮзӮ№пјҢеңЁ TKE еңәжҷҜдёӢпјҢи°ғеәҰжңәеҲ¶её®еҠ©е®һзҺ°дәҶеә”з”ЁеұӮеј№жҖ§дјёзј©еҲ°иө„жәҗеұӮеј№жҖ§дјёзј©зҡ„иҝҮжёЎгҖӮйҖҡиҝҮеҗҲзҗҶеҲ©з”Ё Kubernetes жҸҗдҫӣзҡ„и°ғеәҰиғҪеҠӣпјҢж №жҚ®дёҡеҠЎзү№жҖ§й…ҚзҪ®еҗҲзҗҶзҡ„и°ғеәҰзӯ–з•ҘпјҢд№ҹиғҪжңүж•ҲжҸҗй«ҳйӣҶзҫӨдёӯзҡ„иө„жәҗеҲ©з”ЁзҺҮгҖӮ
еҖҳиӢҘдҪ зҡ„жҹҗдёӘдёҡеҠЎжҳҜ CPU еҜҶйӣҶеһӢпјҢдёҚе°Ҹеҝғиў« Kubernetes зҡ„и°ғеәҰеҷЁи°ғеәҰеҲ°еҶ…еӯҳеҜҶйӣҶеһӢзҡ„иҠӮзӮ№дёҠпјҢеҜјиҮҙеҶ…еӯҳеҜҶйӣҶеһӢзҡ„ CPU иў«еҚ ж»ЎпјҢдҪҶеҶ…еӯҳеҮ д№ҺжІЎжҖҺд№Ҳз”ЁпјҢдјҡйҖ жҲҗиҫғеӨ§зҡ„иө„жәҗжөӘиҙ№гҖӮеҰӮжһңдҪ иғҪдёәиҠӮзӮ№и®ҫзҪ®дёҖдёӘж Үи®°пјҢиЎЁжҳҺиҝҷжҳҜдёҖдёӘ CPU еҜҶйӣҶеһӢзҡ„иҠӮзӮ№пјҢ然еҗҺеңЁеҲӣе»әдёҡеҠЎиҙҹиҪҪж—¶д№ҹи®ҫзҪ®дёҖдёӘж Үи®°пјҢиЎЁжҳҺиҝҷдёӘиҙҹиҪҪжҳҜдёҖдёӘ CPU еҜҶйӣҶеһӢзҡ„иҙҹиҪҪпјҢKubernetes зҡ„и°ғеәҰеҷЁдјҡе°ҶиҝҷдёӘиҙҹиҪҪи°ғеәҰеҲ° CPU еҜҶйӣҶеһӢзҡ„иҠӮзӮ№дёҠпјҢиҝҷз§ҚеҜ»жүҫжңҖеҗҲйҖӮзҡ„иҠӮзӮ№зҡ„ж–№ејҸпјҢе°Ҷжңүж•ҲжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮ
еҲӣе»ә Pod ж—¶пјҢеҸҜд»Ҙи®ҫзҪ®иҠӮзӮ№дәІе’ҢжҖ§пјҢеҚіжҢҮе®ҡ Pod жғіиҰҒи°ғеәҰеҲ°е“ӘдәӣиҠӮзӮ№дёҠпјҲиҝҷдәӣиҠӮзӮ№жҳҜйҖҡиҝҮ K8s LabelпјүжқҘжҢҮе®ҡзҡ„гҖӮ
иҠӮзӮ№дәІе’ҢжҖ§йқһеёёйҖӮеҗҲеңЁдёҖдёӘйӣҶзҫӨдёӯжңүдёҚеҗҢиө„жәҗйңҖжұӮзҡ„е·ҘдҪңиҙҹиҪҪеҗҢж—¶иҝҗиЎҢзҡ„еңәжҷҜгҖӮжҜ”еҰӮиҜҙпјҢи…ҫи®Ҝдә‘зҡ„ CVMпјҲиҠӮзӮ№пјү жңү CPU еҜҶйӣҶеһӢзҡ„жңәеҷЁпјҢд№ҹжңүеҶ…еӯҳеҜҶйӣҶеһӢзҡ„жңәеҷЁгҖӮеҰӮжһңжҹҗдәӣдёҡеҠЎеҜ№ CPU зҡ„йңҖжұӮиҝңеӨ§дәҺеҶ…еӯҳпјҢжӯӨж—¶дҪҝз”Ёжҷ®йҖҡзҡ„ CVM жңәеҷЁпјҢеҠҝеҝ…дјҡеҜ№еҶ…еӯҳйҖ жҲҗиҫғеӨ§жөӘиҙ№гҖӮжӯӨж—¶еҸҜд»ҘеңЁйӣҶзҫӨйҮҢж·»еҠ дёҖжү№ CPU еҜҶйӣҶеһӢзҡ„ CVMпјҢ并且жҠҠиҝҷдәӣеҜ№ CPU жңүиҫғй«ҳйңҖжұӮзҡ„ Pod и°ғеәҰеҲ°иҝҷдәӣ CVM дёҠпјҢиҝҷж ·еҸҜд»ҘжҸҗеҚҮ CVM иө„жәҗзҡ„ж•ҙдҪ“еҲ©з”ЁзҺҮгҖӮеҗҢзҗҶпјҢиҝҳеҸҜд»ҘеңЁйӣҶзҫӨдёӯз®ЎзҗҶејӮжһ„иҠӮзӮ№пјҲжҜ”еҰӮ GPU жңәеҷЁпјүпјҢеңЁйңҖиҰҒ GPU иө„жәҗзҡ„е·ҘдҪңиҙҹиҪҪдёӯжҢҮе®ҡйңҖиҰҒGPUиө„жәҗзҡ„йҮҸпјҢи°ғеәҰжңәеҲ¶еҲҷдјҡеё®еҠ©дҪ еҜ»жүҫеҗҲйҖӮзҡ„иҠӮзӮ№еҺ»иҝҗиЎҢиҝҷдәӣе·ҘдҪңиҙҹиҪҪгҖӮ
TKE жҸҗдҫӣдёҺеҺҹз”ҹ Kubernetes е®Ңе…ЁдёҖиҮҙзҡ„дәІе’ҢжҖ§дҪҝз”Ёж–№ејҸпјҢдҪ еҸҜйҖҡиҝҮжҺ§еҲ¶еҸ°жҲ–й…ҚзҪ® YAML зҡ„ж–№ејҸдҪҝз”ЁжӯӨйЎ№еҠҹиғҪпјҢе…·дҪ“еҸҜеҸӮиҖғгҖӮ
еҺҹз”ҹзҡ„ Kubernetes и°ғеәҰзӯ–з•ҘеҖҫеҗ‘дәҺи°ғеәҰpodеҲ°иҠӮзӮ№еү©дҪҷиө„жәҗиҫғеӨҡзҡ„иҠӮзӮ№дёҠпјҢ жҜ”еҰӮй»ҳи®Өзҡ„ LeastRequestedPriority зӯ–з•ҘгҖӮдҪҶжҳҜеҺҹз”ҹи°ғеәҰзӯ–з•ҘеӯҳеңЁдёҖдёӘй—®йўҳпјҡиҝҷж ·зҡ„иө„жәҗеҲҶй…ҚжҳҜйқҷжҖҒзҡ„пјҢRequest дёҚиғҪд»ЈиЎЁиө„жәҗзңҹе®һдҪҝз”Ёжғ…еҶөпјҢеӣ жӯӨдёҖе®ҡдјҡеӯҳеңЁдёҖе®ҡзЁӢеәҰзҡ„жөӘиҙ№гҖӮеӣ жӯӨпјҢеҰӮжһңи°ғеәҰеҷЁеҸҜд»ҘеҹәдәҺиҠӮзӮ№зҡ„е®һйҷ…иө„жәҗеҲ©з”ЁзҺҮиҝӣиЎҢи°ғеәҰпјҢе°ҶдёҖе®ҡзЁӢеәҰдёҠи§ЈеҶіиө„жәҗжөӘиҙ№зҡ„й—®йўҳгҖӮ
TKE иҮӘз ”зҡ„еҠЁжҖҒи°ғеәҰеҷЁжүҖеҒҡзҡ„е°ұжҳҜиҝҷж ·зҡ„е·ҘдҪңгҖӮеҠЁжҖҒи°ғеәҰеҷЁзҡ„ж ёеҝғеҺҹзҗҶеҰӮдёӢпјҡ 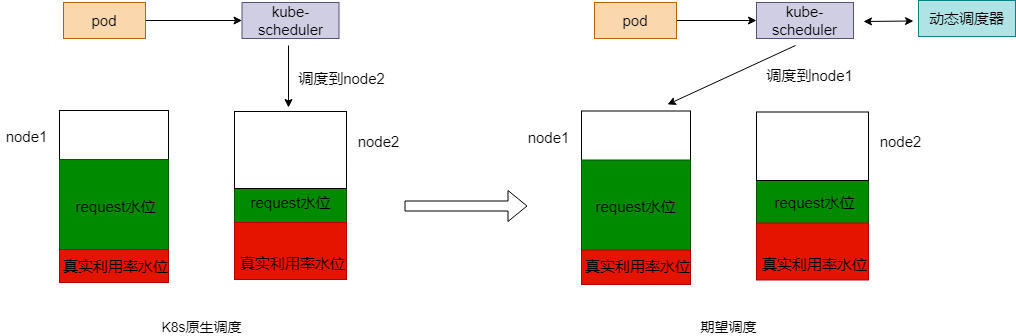
йҷӨдәҶйҷҚдҪҺиө„жәҗжөӘиҙ№пјҢеҠЁжҖҒи°ғеәҰеҷЁиҝҳеҸҜд»ҘеҫҲеҘҪзҡ„зј“и§ЈйӣҶзҫӨи°ғеәҰзғӯзӮ№зҡ„й—®йўҳгҖӮ
еҠЁжҖҒи°ғеәҰеҷЁдјҡз»ҹи®ЎиҝҮеҺ»дёҖж®өж—¶й—ҙи°ғеәҰеҲ°иҠӮзӮ№зҡ„ Pod ж•°зӣ®пјҢйҒҝе…ҚеҫҖеҗҢдёҖиҠӮзӮ№дёҠи°ғеәҰиҝҮеӨҡзҡ„ Pod
еҠЁжҖҒи°ғеәҰеҷЁж”ҜжҢҒи®ҫзҪ®иҠӮзӮ№иҙҹиҪҪйҳҲеҖјпјҢеңЁи°ғеәҰйҳ¶ж®өиҝҮж»ӨжҺүи¶…иҝҮйҳҲеҖјзҡ„иҠӮзӮ№гҖӮ
дҪ еҸҜд»ҘеңЁжү©еұ•з»„件йҮҢйқўе®үиЈ…е’ҢдҪҝз”ЁеҠЁжҖҒи°ғеәҰеҷЁпјҡ 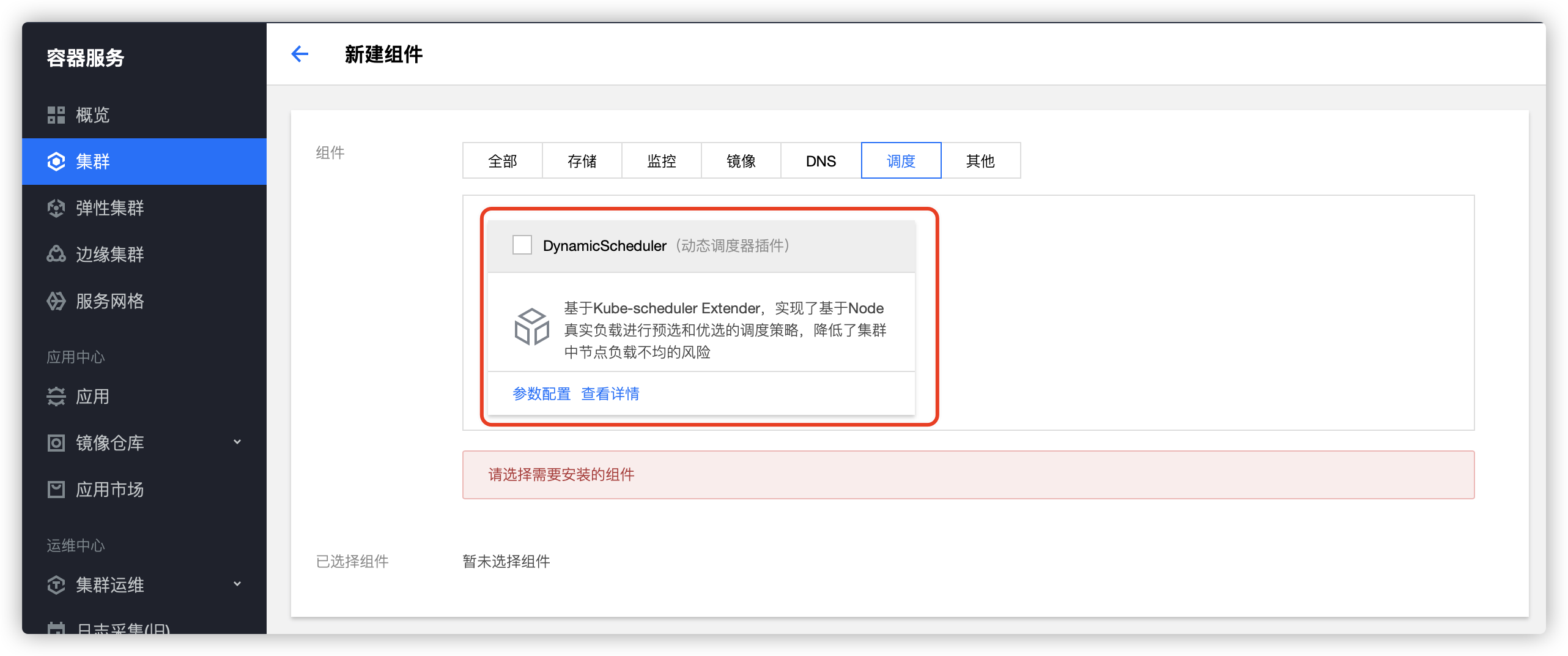 жӣҙеӨҡе…ідәҺеҠЁжҖҒи°ғеәҰеҷЁзҡ„дҪҝз”ЁжҢҮеҚ—пјҢеҸҜд»ҘеҸӮиҖғ гҖҠTKE йҮҚзЈ…жҺЁеҮәе…Ёй“ҫи·Ҝи°ғеәҰи§ЈеҶіж–№жЎҲгҖӢ е’Ңе®ҳж–№ж–ҮжЎЈгҖӮ
жӣҙеӨҡе…ідәҺеҠЁжҖҒи°ғеәҰеҷЁзҡ„дҪҝз”ЁжҢҮеҚ—пјҢеҸҜд»ҘеҸӮиҖғ гҖҠTKE йҮҚзЈ…жҺЁеҮәе…Ёй“ҫи·Ҝи°ғеәҰи§ЈеҶіж–№жЎҲгҖӢ е’Ңе®ҳж–№ж–ҮжЎЈгҖӮ
еҰӮжһңдҪ ж—ўжңүеңЁзәҝ Web жңҚеҠЎдёҡеҠЎпјҢеҸҲжңүзҰ»зәҝзҡ„и®Ўз®—жңҚеҠЎдёҡеҠЎпјҢеҖҹеҠ© TKE зҡ„еңЁзҰ»зәҝдёҡеҠЎж··йғЁжҠҖжңҜеҸҜд»ҘеҠЁжҖҒи°ғеәҰе’ҢиҝҗиЎҢдёҚеҗҢзҡ„дёҡеҠЎпјҢжҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮгҖӮ
еңЁдј з»ҹжһ¶жһ„дёӯпјҢеӨ§ж•°жҚ®дёҡеҠЎе’ҢеңЁзәҝдёҡеҠЎеҫҖеҫҖйғЁзҪІеңЁдёҚеҗҢзҡ„иө„жәҗйӣҶзҫӨдёӯпјҢиҝҷдёӨйғЁеҲҶдёҡеҠЎзӣёдә’зӢ¬з«ӢгҖӮдҪҶеӨ§ж•°жҚ®дёҡеҠЎдёҖиҲ¬жӣҙеӨҡзҡ„жҳҜзҰ»зәҝи®Ўз®—зұ»дёҡеҠЎпјҢеңЁеӨңй—ҙеӨ„дәҺдёҡеҠЎй«ҳеі°пјҢиҖҢеңЁзәҝдёҡеҠЎжҒ°жҒ°зӣёеҸҚеӨңй—ҙеёёеёёеӨ„дәҺз©әиҪҪзҠ¶жҖҒгҖӮдә‘еҺҹз”ҹжҠҖжңҜеҖҹеҠ©е®№еҷЁе®Ңж•ҙ(CPUпјҢеҶ…еӯҳпјҢзЈҒзӣҳIOпјҢзҪ‘з»ңIOзӯү)зҡ„йҡ”зҰ»иғҪеҠӣпјҢеҸҠ Kubernetes ејәеӨ§зҡ„зј–жҺ’и°ғеәҰиғҪеҠӣпјҢе®һзҺ°еңЁзәҝе’ҢзҰ»зәҝдёҡеҠЎж··еҗҲйғЁзҪІпјҢд»ҺиҖҢдҪҝеңЁзҰ»зәҝдёҡеҠЎе……еҲҶеҲ©з”ЁеңЁзәҝдёҡеҠЎз©әй—Іж—¶ж®өзҡ„иө„жәҗпјҢд»ҘжҸҗй«ҳиө„жәҗеҲ©з”ЁзҺҮгҖӮ
еңЁ Hadoop жһ¶жһ„дёӢпјҢзҰ»зәҝдҪңдёҡе’ҢеңЁзәҝдҪңдёҡеҫҖеҫҖеҲҶеұһдёҚеҗҢзҡ„йӣҶзҫӨпјҢ然иҖҢеңЁзәҝдёҡеҠЎгҖҒжөҒејҸдҪңдёҡе…·жңүжҳҺжҳҫзҡ„жіўеі°жіўи°·зү№жҖ§пјҢеңЁжіўи°·ж—¶ж®өпјҢдјҡжңүеӨ§йҮҸзҡ„иө„жәҗеӨ„дәҺй—ІзҪ®зҠ¶жҖҒпјҢйҖ жҲҗиө„жәҗзҡ„жөӘиҙ№е’ҢжҲҗжң¬зҡ„жҸҗеҚҮгҖӮеңЁзҰ»зәҝж··йғЁйӣҶзҫӨпјҢйҖҡиҝҮеҠЁжҖҒи°ғеәҰеүҠеі°еЎ«и°·пјҢеҪ“еңЁзәҝйӣҶзҫӨзҡ„дҪҝз”ЁзҺҮеӨ„дәҺжіўи°·ж—¶ж®өпјҢе°ҶзҰ»зәҝд»»еҠЎи°ғеәҰеҲ°еңЁзәҝйӣҶзҫӨпјҢеҸҜд»Ҙжҳҫи‘—зҡ„жҸҗй«ҳиө„жәҗзҡ„еҲ©з”ЁзҺҮгҖӮ然иҖҢпјҢHadoop Yarn зӣ®еүҚеҸӘиғҪйҖҡиҝҮ NodeManager дёҠжҠҘзҡ„йқҷжҖҒиө„жәҗжғ…еҶөиҝӣиЎҢеҲҶй…ҚпјҢж— жі•еҹәдәҺеҠЁжҖҒиө„жәҗи°ғеәҰпјҢж— жі•еҫҲеҘҪзҡ„ж”ҜжҢҒеңЁзәҝгҖҒзҰ»зәҝдёҡеҠЎж··йғЁзҡ„еңәжҷҜгҖӮ
еңЁзәҝдёҡеҠЎе…·жңүжҳҺжҳҫзҡ„жіўеі°жөӘи°·зү№еҫҒпјҢиҖҢ且规еҫӢжҜ”иҫғжҳҺжҳҫпјҢе°Өе…¶жҳҜеңЁеӨңй—ҙпјҢиө„жәҗеҲ©з”ЁзҺҮжҜ”иҫғдҪҺпјҢиҝҷж—¶еҖҷеӨ§ж•°жҚ®з®ЎжҺ§е№іеҸ°еҗ‘ Kubernetes йӣҶзҫӨдёӢеҸ‘еҲӣе»әиө„жәҗзҡ„иҜ·жұӮпјҢеҸҜд»ҘжҸҗй«ҳеӨ§ж•°жҚ®еә”з”Ёзҡ„з®—еҠӣпјҢе…·дҪ“еҸҜеҸӮиҖғгҖӮ
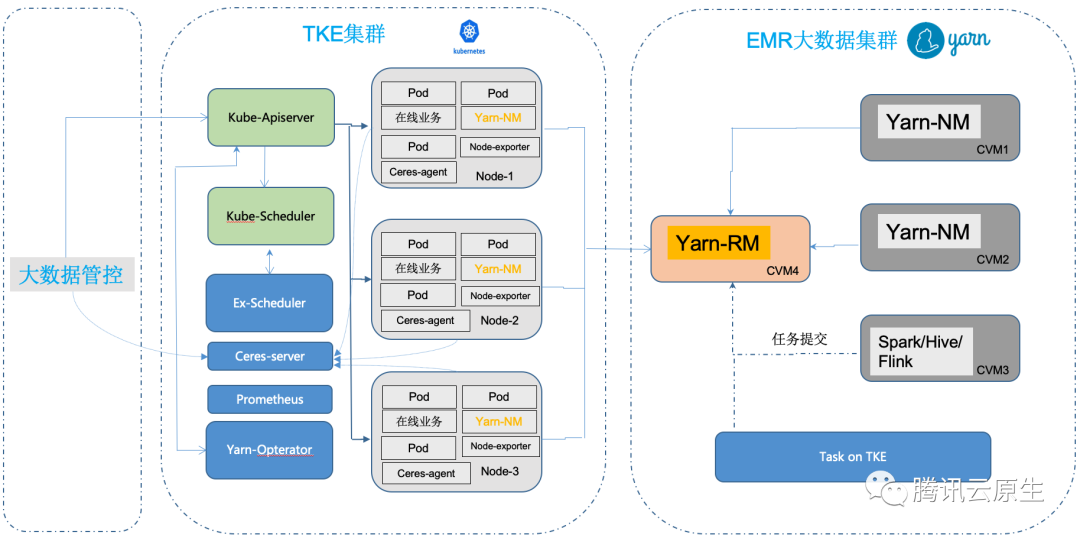
еңЁдјҒдёҡзҡ„иҝҗз»ҙе·ҘдҪңдёӯпјҢйҷӨдәҶжҲҗжң¬пјҢзі»з»ҹзҡ„зЁіе®ҡжҖ§д№ҹжҳҜеҚҒеҲҶйҮҚиҰҒзҡ„жҢҮж ҮгҖӮеҰӮдҪ•еңЁдёӨиҖ…й—ҙиҫҫеҲ°е№іиЎЎпјҢеҸҜиғҪжҳҜеҫҲеӨҡиҝҗз»ҙдәәе‘ҳеҝғдёӯзҡ„вҖңз—ӣзӮ№вҖқгҖӮдёҖж–№йқўпјҢдёәдәҶйҷҚдҪҺжҲҗжң¬пјҢиө„жәҗеҲ©з”ЁзҺҮеҪ“然жҳҜи¶Ҡй«ҳи¶ҠеҘҪпјҢдҪҶжҳҜиө„жәҗеҲ©з”ЁзҺҮиҫҫеҲ°дёҖе®ҡж°ҙдҪҚеҗҺпјҢиҙҹиҪҪиҝҮй«ҳжһҒжңүеҸҜиғҪеҜјиҮҙдёҡеҠЎ OOM жҲ– CPU жҠ–еҠЁзӯүй—®йўҳгҖӮ дёәдәҶеҮҸе°ҸдјҒдёҡжҲҗжң¬жҺ§еҲ¶д№Ӣи·ҜдёҠзҡ„йЎҫиҷ‘пјҢTKE иҝҳжҸҗдҫӣдәҶвҖңе…ңеә•зҘһеҷЁвҖң - йҮҚи°ғеәҰеҷЁ жқҘдҝқйҡңйӣҶзҫӨиҙҹиҪҪж°ҙдҪҚеңЁеҸҜжҺ§иҢғеӣҙеҶ…гҖӮ йҮҚи°ғеәҰеҷЁжҳҜеҠЁжҖҒи°ғеәҰеҷЁжҳҜдёҖеҜ№еҘҪжҗӯжЎЈпјҲе®ғ们зҡ„е…ізі»еҸҜд»ҘеҸӮиҖғдёӢеӣҫпјүпјҢе°ұеғҸе®ғзҡ„еҗҚеӯ—дёҖж ·пјҢе®ғдё»иҰҒиҙҹиҙЈвҖңдҝқжҠӨвҖқиҠӮзӮ№дёӯе·Із»ҸиҙҹиҪҪжҜ”иҫғвҖңеҚұйҷ©вҖқзҡ„иҠӮзӮ№пјҢ дјҳйӣ…й©ұйҖҗиҝҷдәӣиҠӮзӮ№дёҠзҡ„дёҡеҠЎгҖӮ 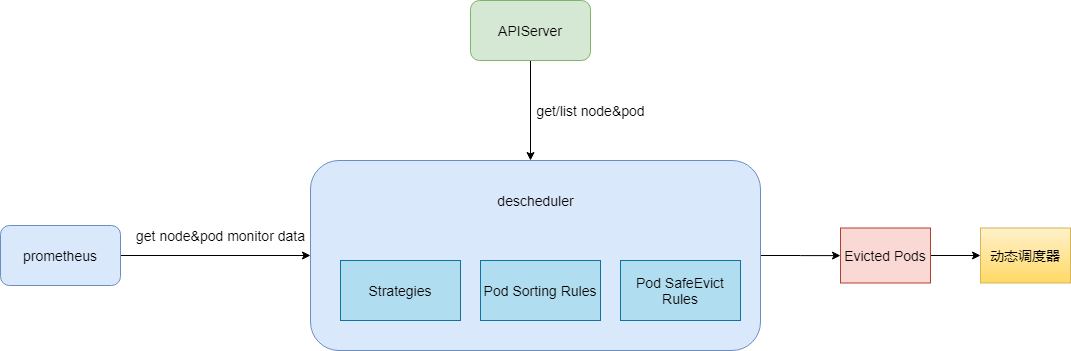
еҸҜд»ҘеңЁжү©еұ•з»„件йҮҢйқўе®үиЈ…е’ҢдҪҝз”ЁйҮҚи°ғеәҰеҷЁпјҡ 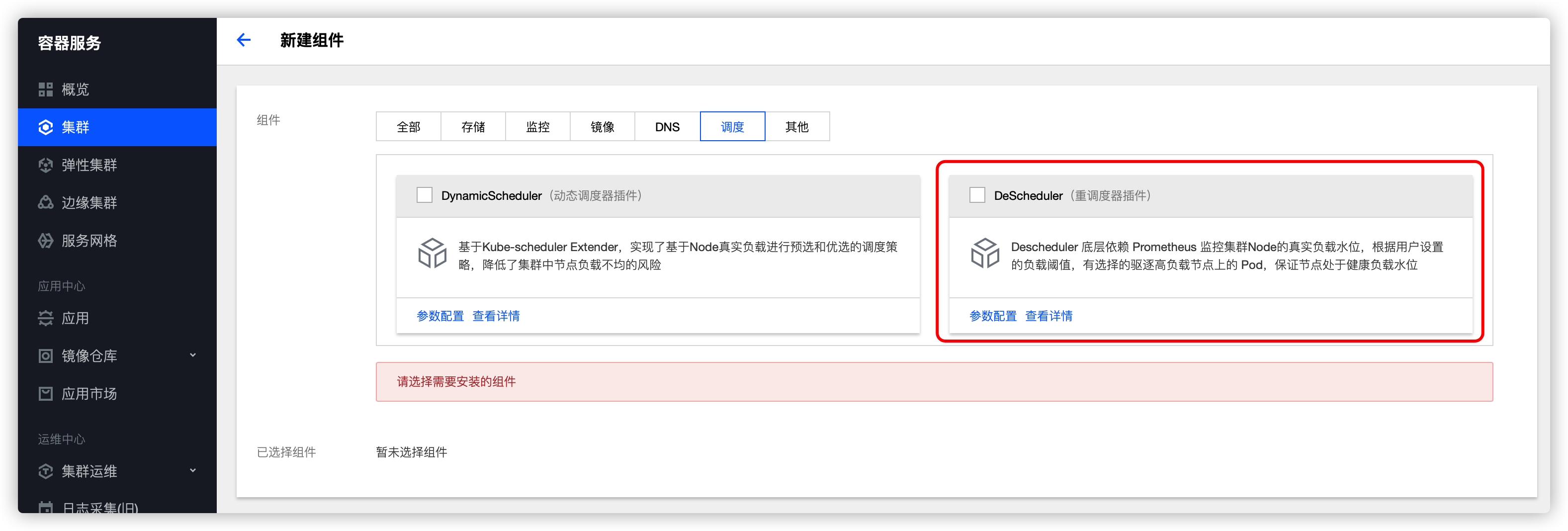
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңkubernetesеҰӮдҪ•жҸҗеҚҮиө„жәҗеҲ©з”ЁзҺҮвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ