您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“如何使用MQTT与函数计算做热力图”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1. 数据通道的连接能力:数据通道随着业务的扩展,机器人的投放也会同步增加,对于数据通道有足够的扩展灵活性,可以按需进行扩展,同时连接的级别能够支持10W+级别的扩展。
2. 简洁数据清洗的能力:对于数据的处理,本质上就是对数据的归纳统计,逻辑实现上并不复杂。对于数据本身的峰谷变化,能有最简单有效的匹配扩缩处理能力即可,在清洗上不希望为此引入复杂的传统大数据级别的笨重方案。
3. 弹性数据访问的能力:这里提到的的热力图信息,以后会考虑开放给终端用户访问,访问量都是动态变化的,随着不同的时间、节日、突发事件等都会有不可预知的幅度变化,所以在此业务中要求有弹性的访问能力。业务方不希望通过限流方式来实现,因为会对业务量本身造成影响。
4. 性能优越的存储能力:此场景下,数据写入与读取并发量都高,客户希望使用NoSQL的方式进行存储。NoSQL 类型能最好支持排序的功能,本文介绍的方案中使用Redis,不再做更多的分析介绍。
数据通道的连接能力
自建Kafka
优点:
Kafka作为通用的数据收集信息通道,使用面广泛,接入方式多样化。社区完善,学习成本低。
Kafka本身搭建容易,与下游的大数据处理产品协调方案成熟。
缺点:
动态处理Kafka的扩容复杂。
需要搭建额外处理集群的稳定性配套方案。
外网网络流量管理需要配合额外的方案。
主流方案是作为连接应用的收集能力,对于终端的连接能力没有规模级别的案例验证。
优点:
支持百万级别的连接,完成可以覆盖业务发展的诉求,为业务留足了扩展空间。
MQTT的协议非常简洁,在端与服务间的传输中有优势。支持各种消息触达的QoS质量。
支持各种客户端接入实现语言。
可实时观测客户端的连接情况,方便发现异常情况。
缺点:
处理大数据的实践没有Kafka成熟,下游产品选型受一定的限制。
弹性数据清洗的能力
大数据方案(Storm、Spark、Flink等)
优点:
开源的通用方案,资料众多,方案成熟。
缺点:
搭建运维复杂,需要提供额外的监控与恢复手段。
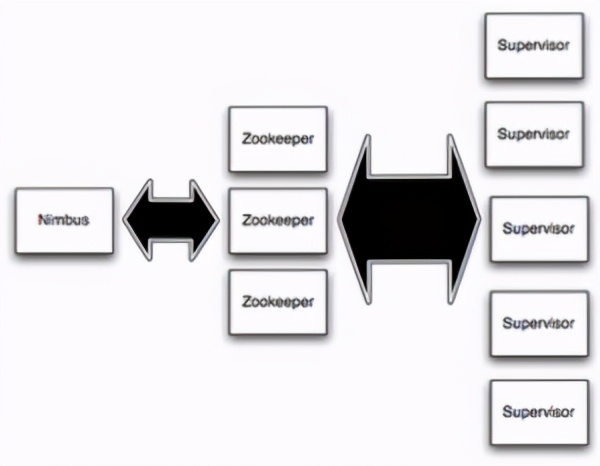
需要学习接受各种组件方式(下图是以Storm为例)。
提前评估资源使用情况,无法按照实时数据量进行相应的扩缩使用。
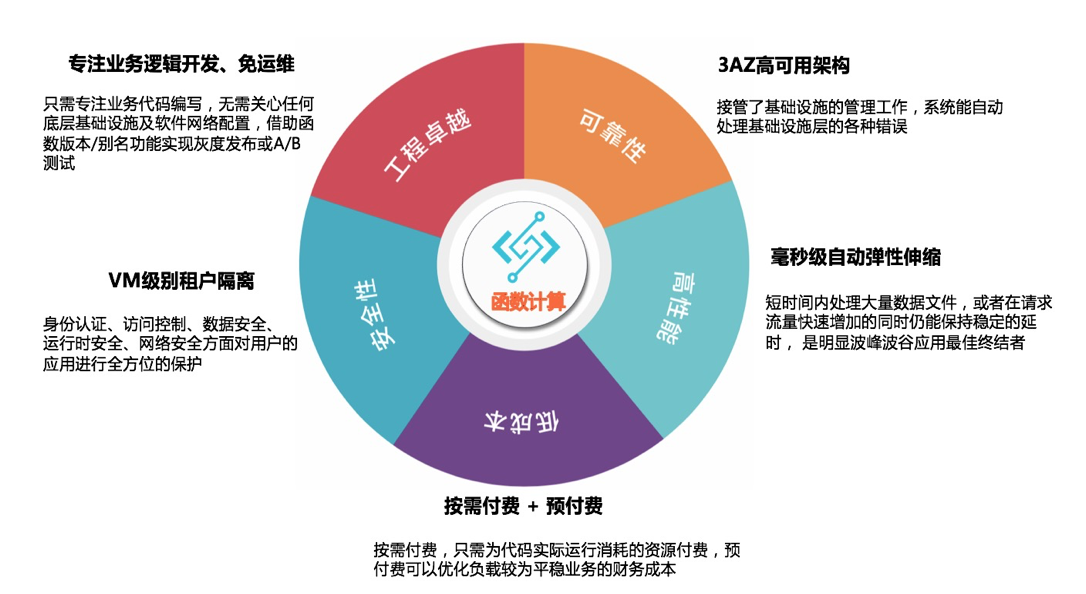
优点:
按需进行扩缩,百毫秒级的伸缩能力,适合数据量的脉冲峰谷变化。
不需要进行清洗环境的管理。
概念简单,学习成本低。
其它优点参考下图:
缺点:
函数计算是各个云厂商的产品。要求一定需要在云上运行。
优点:
作为业务的一部分嵌在某个应用实现中,技术成熟,学习成本低。
缺点:
需要自实现根据业务请求量来进行弹缩处理,或者很多时候采用评估的方式进行资源冗余处理。
优点:
根据客户的请求量实时进行弹缩处理。按需使用,不为高峰时段烦恼,不会闲置付费。
自动附带专业的访问监控大盘。
缺点:
需要少量的学习成本。
在这个热力图信息收集清选与访问业务中,可以参考使用下图的解决方案完美实现。
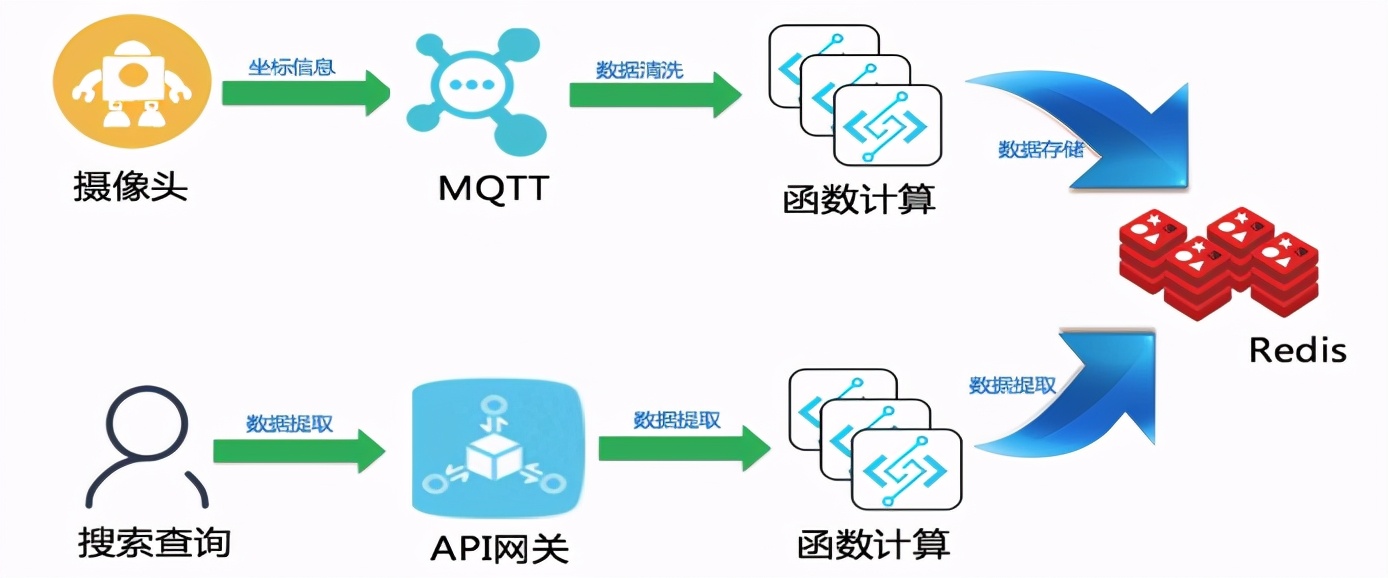
MQTT到函数计算的介绍
请参考函数计算的微消息队列MQTT服务集成方案。

详情请参考API网关函数触发实例。
以Node.js为例:
module.exports.handler = function(event, context, callback) {
var event = JSON.parse(event); var content = {
path: event.path,
method: event.method,
headers: event.headers,
queryParameters: event.queryParameters,
pathParameters: event.pathParameters,
body: event.body // 您可以在这里编写您自己的逻辑。
// 从Redis提取数据的逻辑
} var response = {
isBase64Encoded: false,
statusCode: '200',
headers: { 'x-custom-header': 'header value'},
body: content
};
callback(null, response)
};“如何使用MQTT与函数计算做热力图”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。